
Learning and Multiagent Reasoning for Autonomous...
45
Learning and Multiagent Reasoning for Autonomous Agents Prof. Peter Stone Director, Learning Agents Research Group Department of Computer Sciences The University of Texas at Austin IJCAI 2007 Computers and Thought Lecture
Transcript of Learning and Multiagent Reasoning for Autonomous...

Learning and Multiagent Reasoningfor Autonomous Agents
Prof. Peter Stone
Director, Learning Agents Research GroupDepartment of Computer Sciences
The University of Texas at Austin
IJCAI 2007 Computers and Thought Lecture

A Goal of AIRobust, fully autonomousagents in the real world
How?• Build complete solutions to relevant challenge tasks
Complete agents: sense, decide, and act — closed loopChallenge tasks: specific, concrete objectives
• Drives research on component algorithms, theory
− Improve from experience (Machine learning)− Interact with other agents (Multiagent systems)
• A top-down, empirical approach
c© 2007 Peter Stone

Bottom-Up Metaphors
Russell, ’95“Theoreticians can produce the AI equivalent of bricks,beams, and mortar with which AI architects can build theequivalent of cathedrals.”
Koller, ’01“In AI . . . we have the tendency to divide a problem intowell-defined pieces, and make progress on each one.. . . Part of our solution to the AI problem must involvebuilding bridges between the pieces.”
c© 2007 Peter Stone
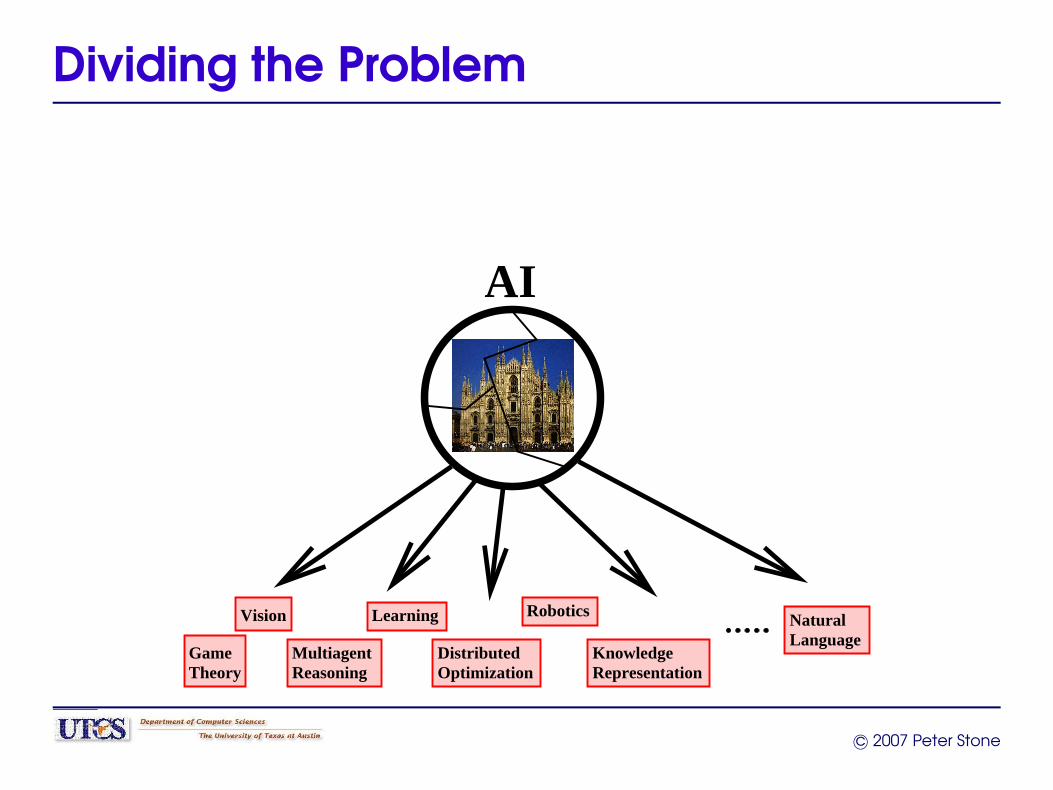
Dividing the Problem
Vision
MultiagentReasoning
GameTheory
Learning Robotics
RepresentationKnowledgeDistributed
Optimization
NaturalLanguage
AI
c© 2007 Peter Stone
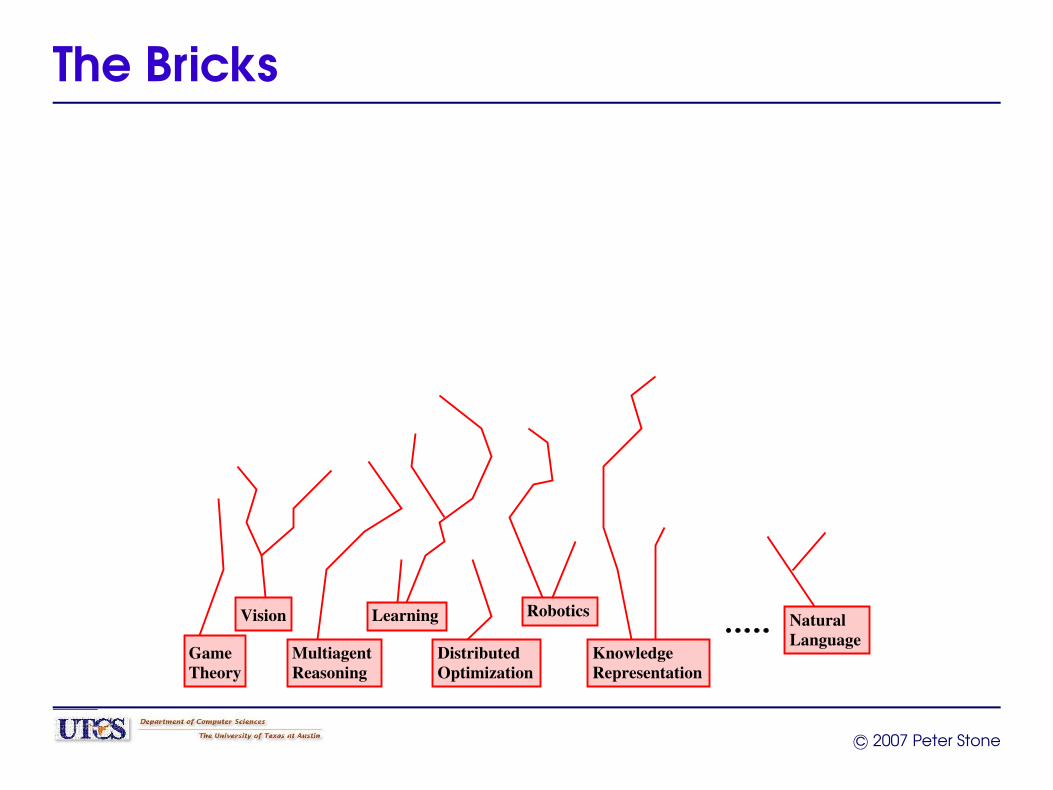
The Bricks
Vision
MultiagentReasoning
GameTheory
Learning Robotics
RepresentationKnowledgeDistributed
Optimization
NaturalLanguage
c© 2007 Peter Stone
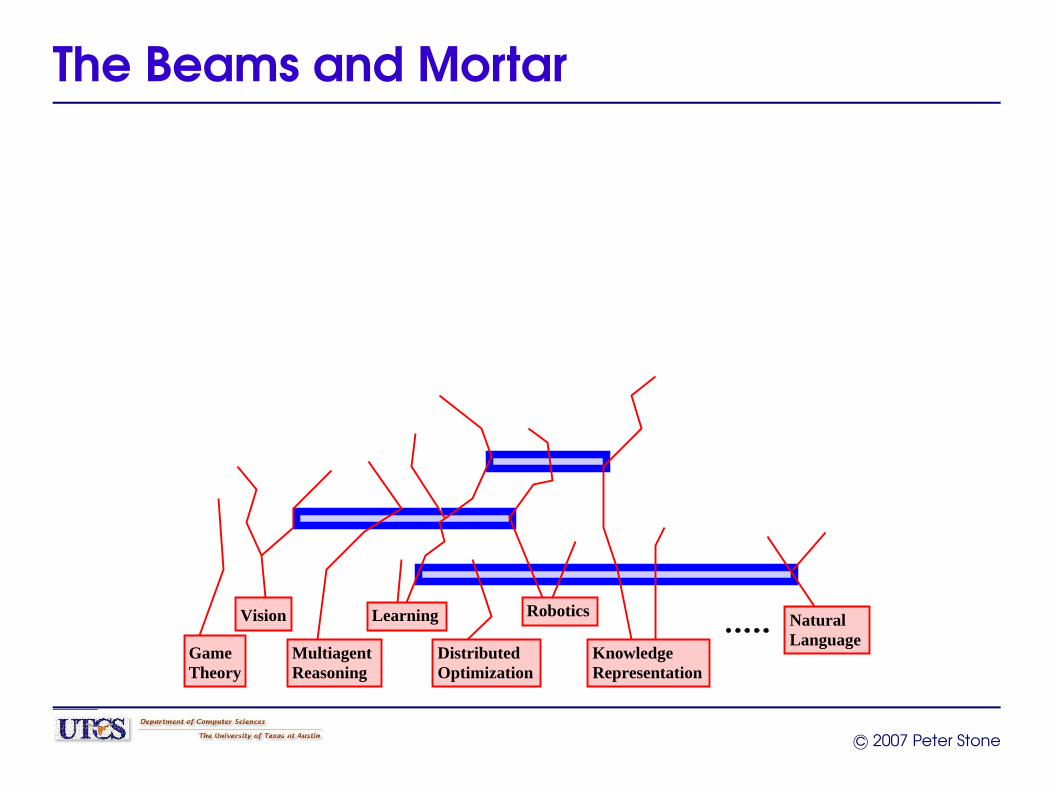
The Beams and Mortar
Vision
MultiagentReasoning
GameTheory
Learning Robotics
RepresentationKnowledgeDistributed
Optimization
NaturalLanguage
c© 2007 Peter Stone
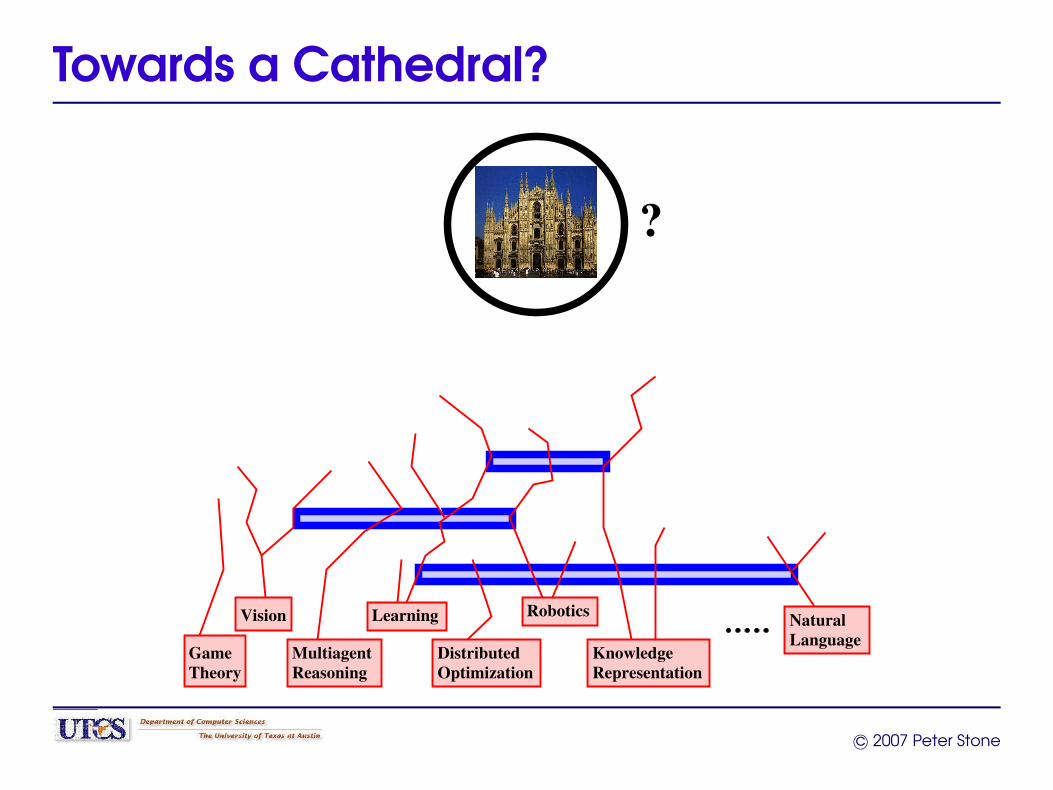
Towards a Cathedral?
?
Vision
MultiagentReasoning
GameTheory
Learning Robotics
RepresentationKnowledgeDistributed
Optimization
NaturalLanguage
c© 2007 Peter Stone
Or Something Else?
Vision
MultiagentReasoning
GameTheory
Learning Robotics
RepresentationKnowledgeDistributed
Optimization
NaturalLanguage
?
c© 2007 Peter Stone

A Different Problem Division
AI
c© 2007 Peter Stone
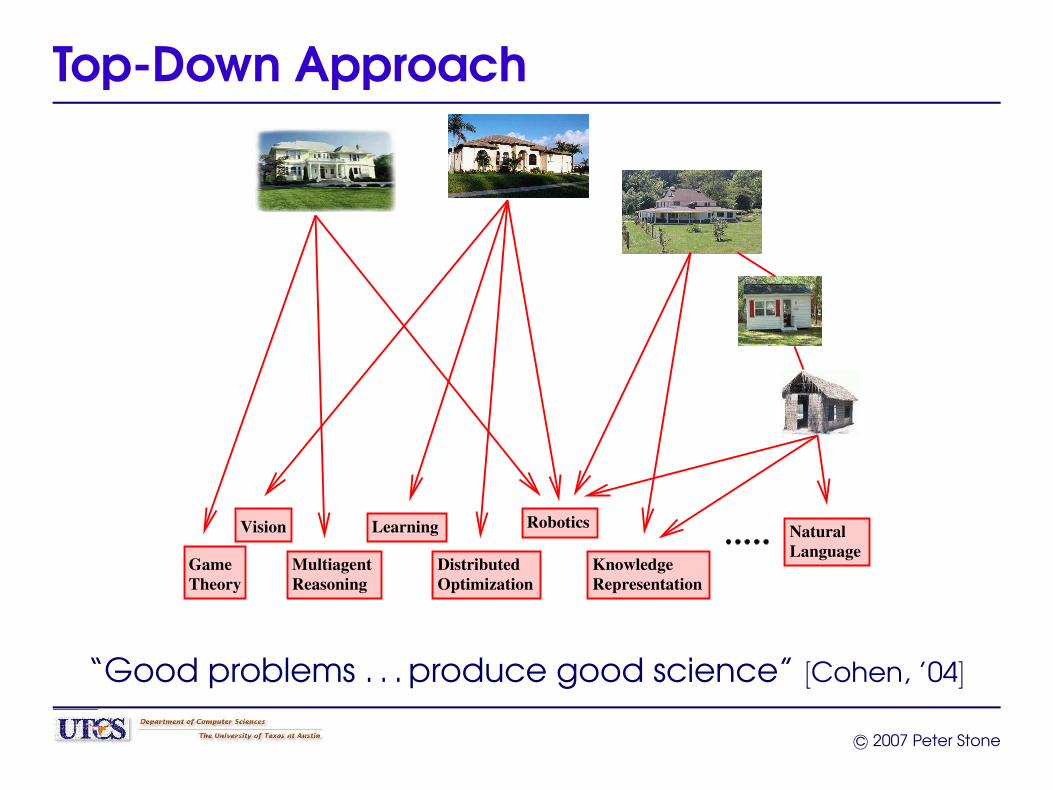
Top-Down Approach
Vision
MultiagentReasoning
GameTheory
Learning Robotics
RepresentationKnowledgeDistributed
Optimization
NaturalLanguage
“Good problems . . . produce good science” [Cohen, ’04]
c© 2007 Peter Stone
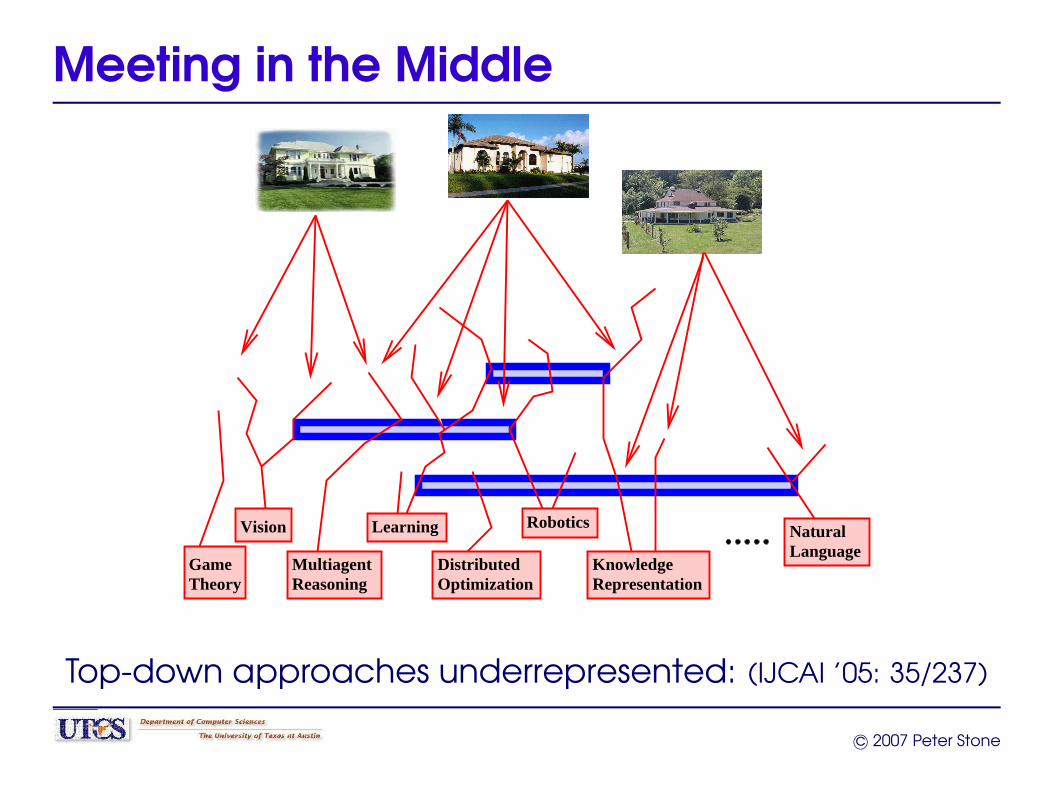
Meeting in the Middle
Vision
MultiagentReasoning
GameTheory
Learning Robotics
RepresentationKnowledgeDistributed
Optimization
NaturalLanguage
Top-down approaches underrepresented: (IJCAI ’05: 35/237)
c© 2007 Peter Stone

Choosing the Challenge• Features of good challenges: [Cohen, ’04]
− Frequent tests; Graduated series of challenges− Accept poor performance; Complete agents
• Closed loop + specific goal (beyond [Brooks, ’91])
• 50-year technical, scientific goals− Beyond commercial applications — not possible now− Moore’s law not enough
• There are many — choose one that inspires you
− Leverage “bricks and mortar” from past− Hybrid symbolic/probabilistic methods
[Richardson & Domingos, ’06]
c© 2007 Peter Stone

Good Problems Produce Good Science
Manned flight Apollo mission
Manhattan project RoboCup soccer
Goal: By the year 2050, a team of humanoid robotsthat can beat the human World Cup champion team.[Kitano, ’97]
c© 2007 Peter Stone

RoboCup Soccer
• Still in the early stages (small houses)
• Many virtues:
− Incremental challenges, closed loop at each stage− Relatively easy entry− Multiple robots possible− Inspiring to many
• Visible progress
Vision
MultiagentReasoning
GameTheory
Learning Robotics
RepresentationKnowledgeDistributed
Optimization
NaturalLanguage
c© 2007 Peter Stone

The Early Years
c© 2007 Peter Stone

A Decade Later
c© 2007 Peter Stone

Advances due to RoboCup
• Drives research in many areas:
− Control algorithms; computer vision, sensing; localization;− Distributed computing; real-time systems;− Knowledge representation; mechanical design;− Multiagent systems; machine learning; robotics
Vision
MultiagentReasoning
GameTheory
Learning Robotics
RepresentationKnowledgeDistributed
Optimization
NaturalLanguage
• 200+ publications from simulation league alone
• 200+ from 4-legged league
• 15+ Ph.D. theses
c© 2007 Peter Stone
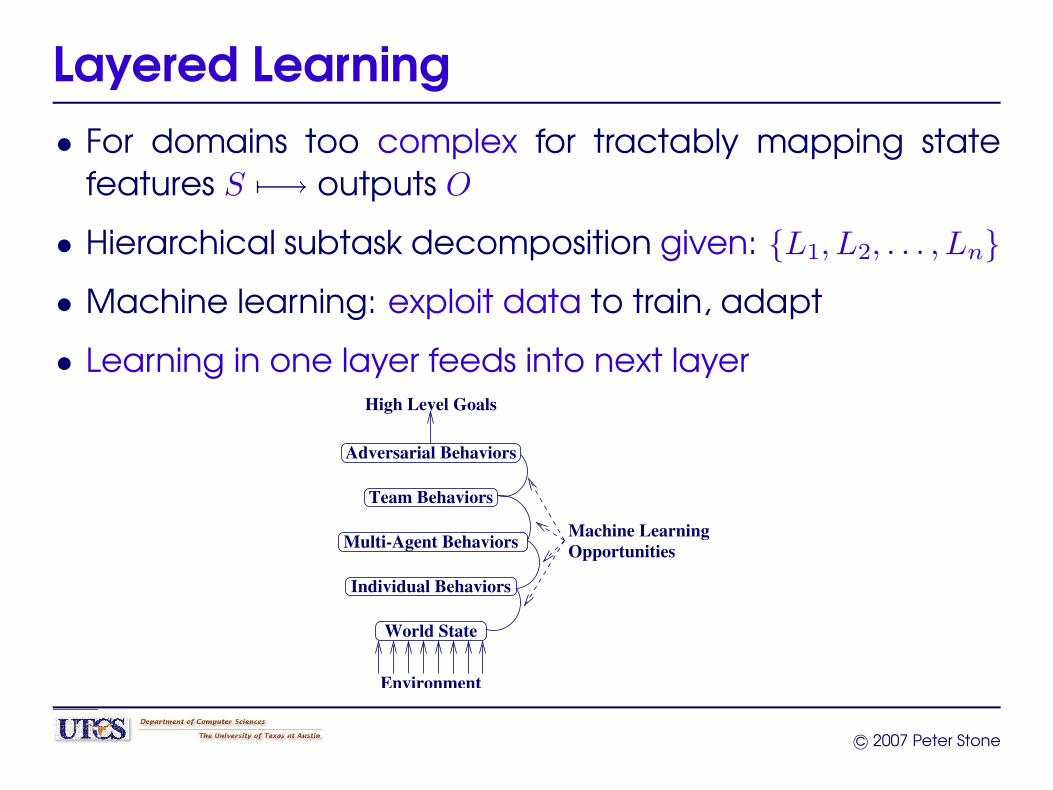
Layered Learning• For domains too complex for tractably mapping state
features S 7−→ outputs O
• Hierarchical subtask decomposition given: {L1, L2, . . . , Ln}
• Machine learning: exploit data to train, adapt
• Learning in one layer feeds into next layer
Individual Behaviors
Team Behaviors
Adversarial Behaviors
Environment
High Level Goals
OpportunitiesMachine LearningMulti-Agent Behaviors
World State
c© 2007 Peter Stone
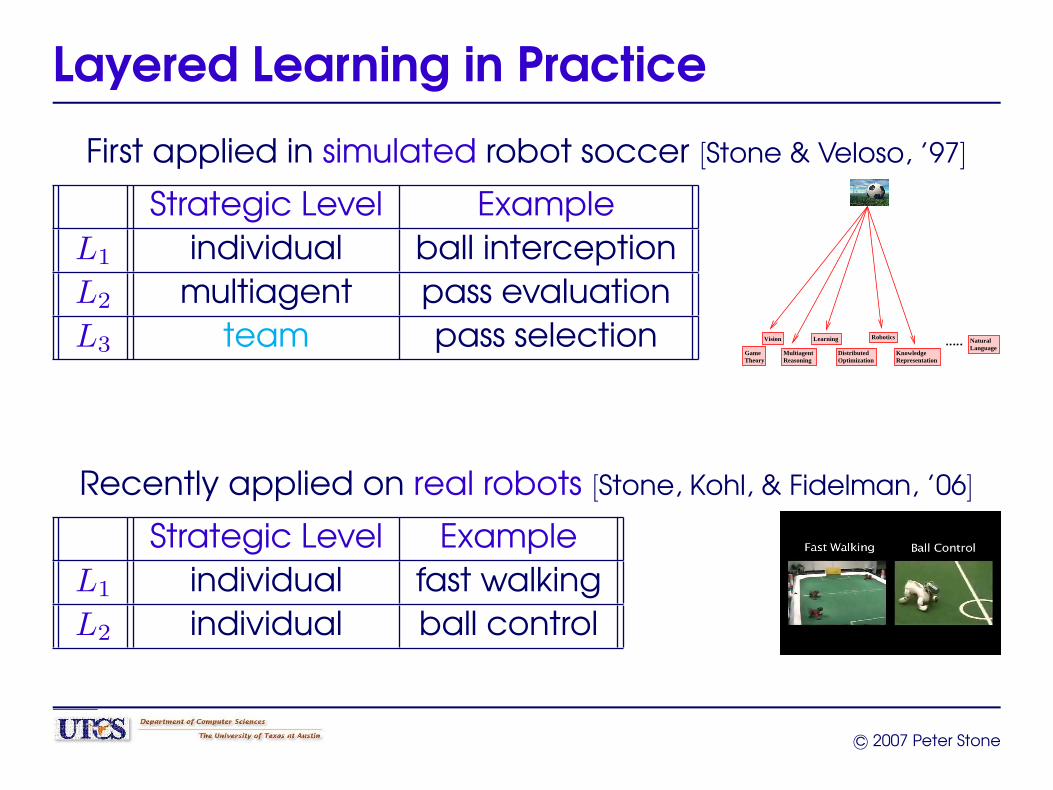
Layered Learning in Practice
First applied in simulated robot soccer [Stone & Veloso, ’97]
Strategic Level ExampleL1 individual ball interceptionL2 multiagent pass evaluationL3 team pass selection Vision
MultiagentReasoning
GameTheory
Learning Robotics
RepresentationKnowledgeDistributed
Optimization
NaturalLanguage
Recently applied on real robots [Stone, Kohl, & Fidelman, ’06]
Strategic Level ExampleL1 individual fast walkingL2 individual ball control
c© 2007 Peter Stone

Robot Vision• Great progress in computer vision− Shape modeling, object recognition, face detection. . .
• Robot vision offers new challenges− Mobile camera, limited computation, color features
• Autonomous color learning [Sridharan & Stone, ’05]
− Learns color map based on known object locations− Recognizes and reacts to illumination changes
− Object detection in real-time, on-board a robot
Vision
MultiagentReasoning
GameTheory
Learning Robotics
RepresentationKnowledgeDistributed
Optimization
NaturalLanguage
c© 2007 Peter Stone

Other Good AI Challenges
Trading agents
Autonomous vehicles
Autonomic computing
Socially assistive robots
c© 2007 Peter Stone
Challenge Problems Drive Research
Vision
MultiagentReasoning
GameTheory
Learning Robotics
RepresentationKnowledgeDistributed
Optimization
NaturalLanguage
c© 2007 Peter Stone
Learning and Multiagent Reasoning
Vision
GameTheory
Robotics
RepresentationKnowledgeDistributed
Optimization
NaturalLanguage
MultiagentReasoning
Learning
c© 2007 Peter Stone
Outline
• Build complete solutions to relevant challenge tasks
− Drives research on component algorithms, theory
• Learning Agents
− Scaling up Reinforcement Learning− Adaptive representations
• Multiagent reasoning
− Prepare for the unexpected− Adaptive interaction protocols
Vision
GameTheory
Robotics
RepresentationKnowledgeDistributed
Optimization
NaturalLanguage
MultiagentReasoning
Learning
c© 2007 Peter Stone
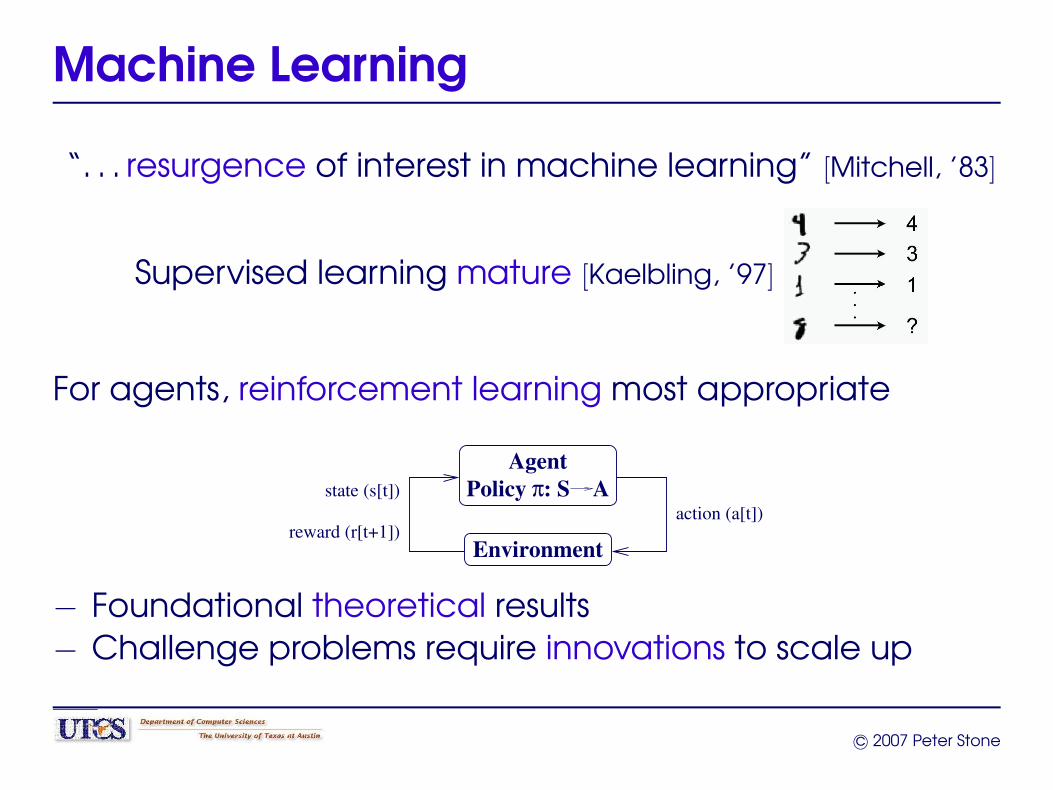
Machine Learning
“. . . resurgence of interest in machine learning” [Mitchell, ’83]
Supervised learning mature [Kaelbling, ’97]
For agents, reinforcement learning most appropriate
Environment
AgentπPolicy : S A
action (a[t])state (s[t])
reward (r[t+1])
− Foundational theoretical results− Challenge problems require innovations to scale up
c© 2007 Peter Stone
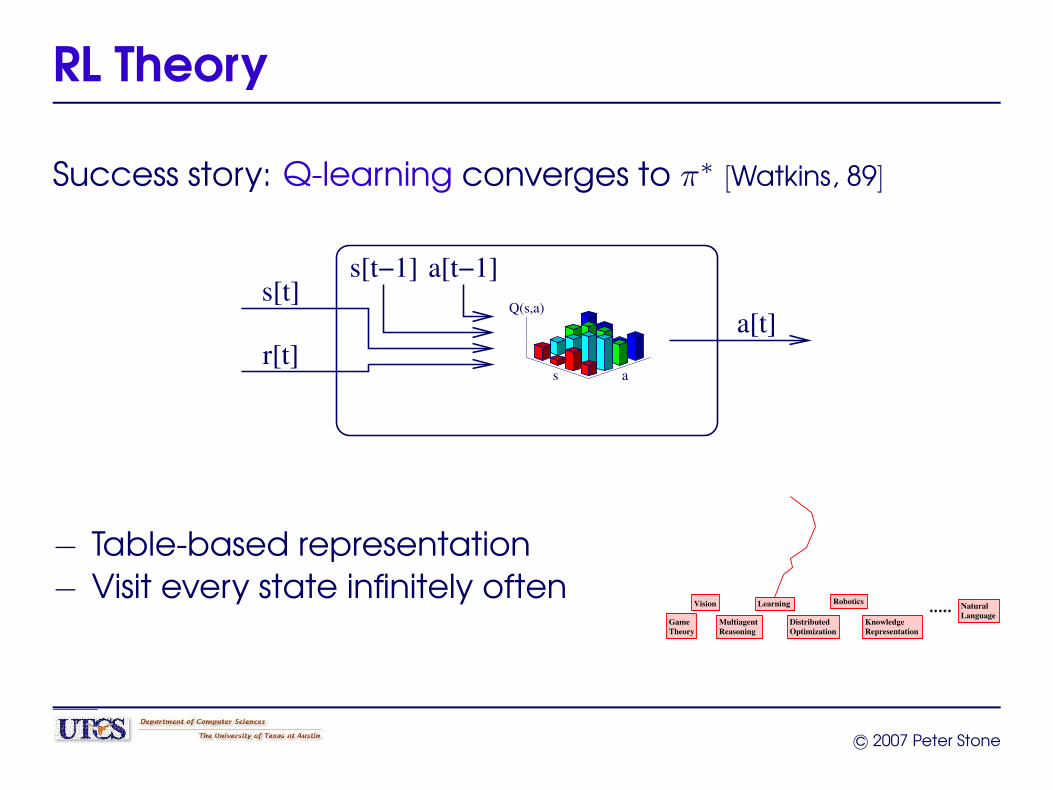
RL Theory
Success story: Q-learning converges to π∗ [Watkins, 89]
s[t]
r[t]
a[t−1]
s a
Q(s,a)
s[t−1]
a[t]
− Table-based representation− Visit every state infinitely often
Vision
MultiagentReasoning
GameTheory
Learning Robotics
RepresentationKnowledgeDistributed
Optimization
NaturalLanguage
c© 2007 Peter Stone
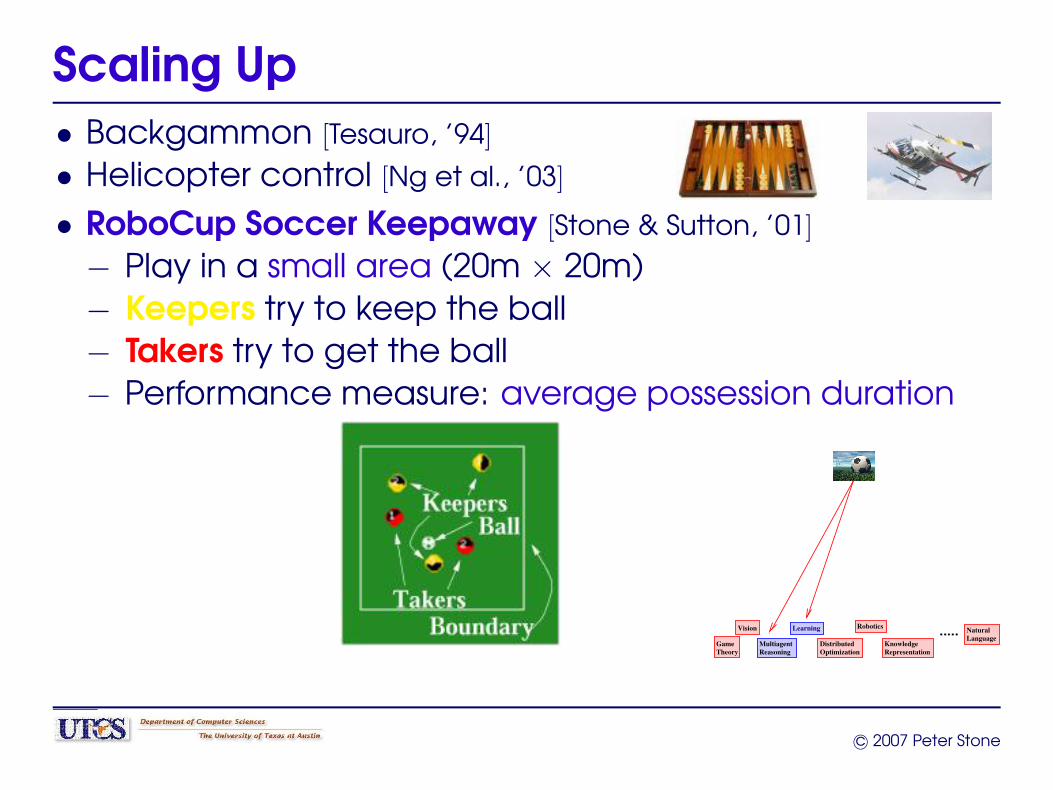
Scaling Up• Backgammon [Tesauro, ’94]
• Helicopter control [Ng et al., ’03]
• RoboCup Soccer Keepaway [Stone & Sutton, ’01]
− Play in a small area (20m × 20m)− Keepers try to keep the ball− Takers try to get the ball− Performance measure: average possession duration
Vision
GameTheory
Robotics
RepresentationKnowledgeDistributed
Optimization
NaturalLanguage
MultiagentReasoning
Learning
c© 2007 Peter Stone
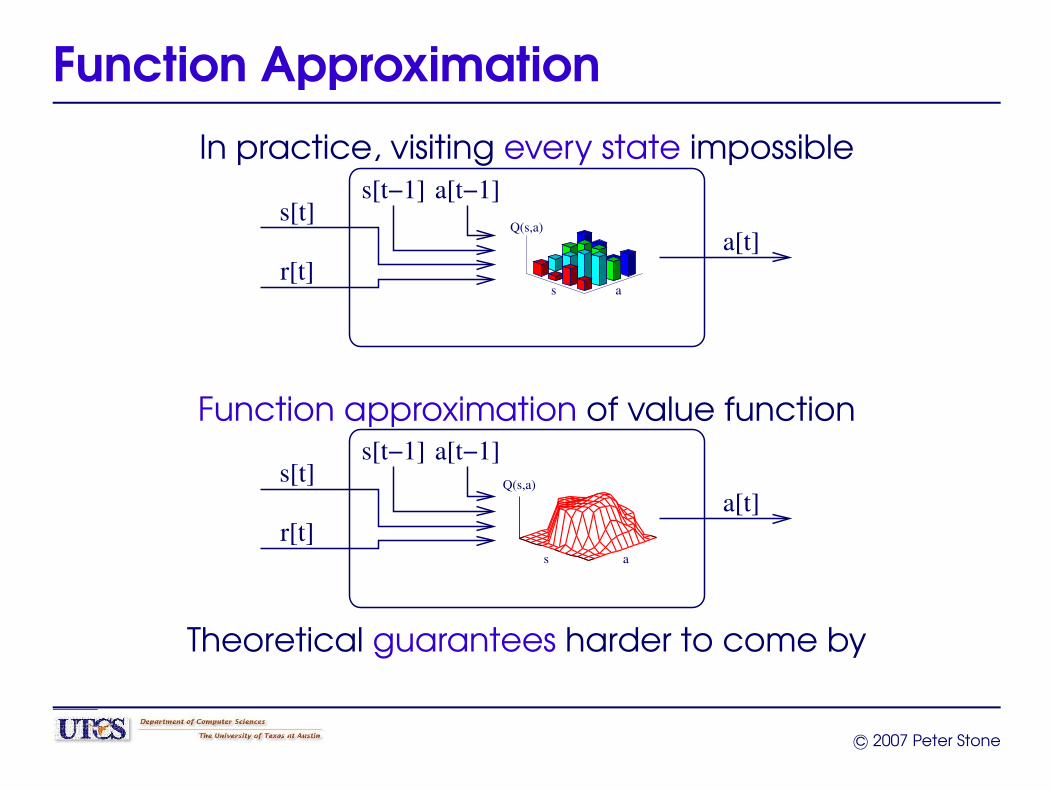
Function Approximation
In practice, visiting every state impossible
s[t]
r[t]
a[t−1]
s a
Q(s,a)
s[t−1]
a[t]
Function approximation of value function
s[t]
a[t]
s[t−1]
s a
Q(s,a)
r[t]
a[t−1]
Theoretical guarantees harder to come by
c© 2007 Peter Stone
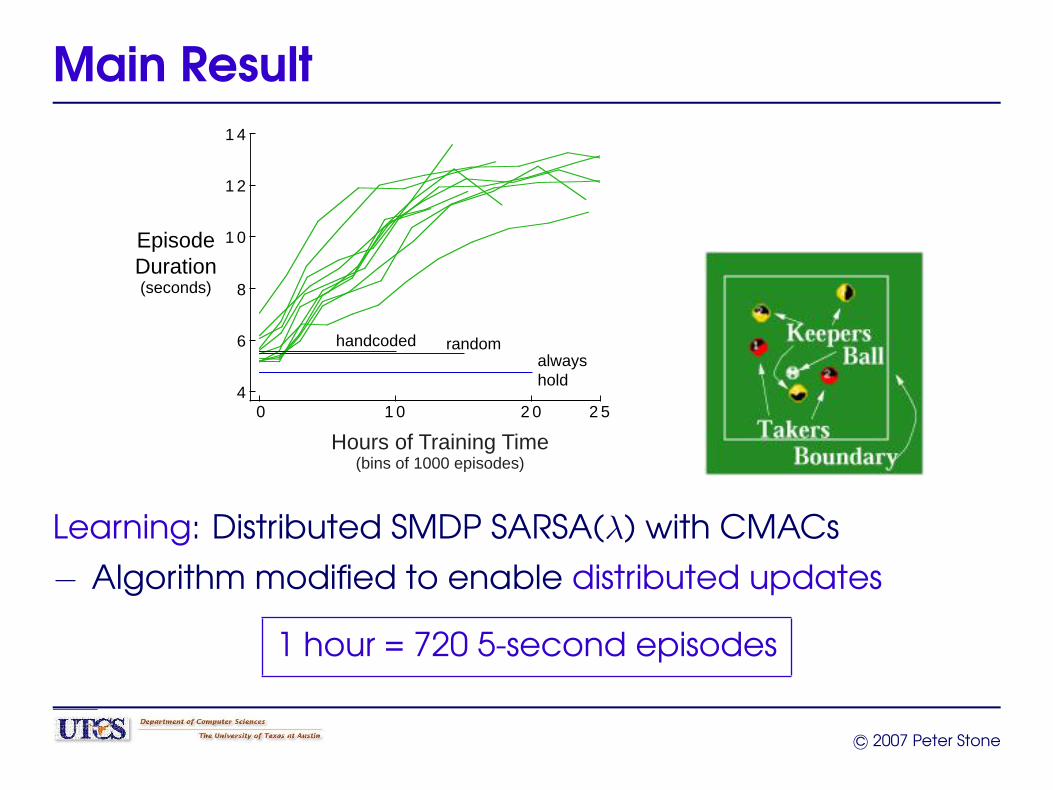
Main Result
0 1 0 2 0 2 54
6
8
1 0
1 2
1 4
EpisodeDuration(seconds)
Hours of Training Time(bins of 1000 episodes)
handcoded randomalwayshold
Learning: Distributed SMDP SARSA(λ) with CMACs
− Algorithm modified to enable distributed updates
1 hour = 720 5-second episodes
c© 2007 Peter Stone
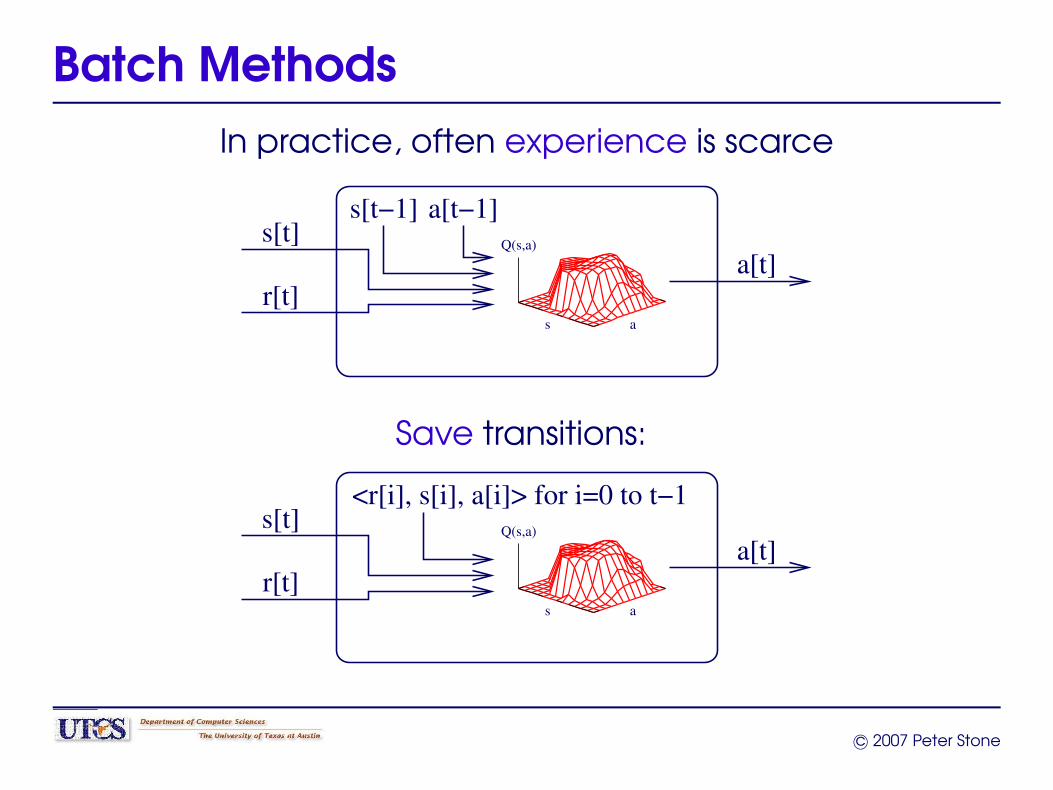
Batch MethodsIn practice, often experience is scarce
s[t]
a[t]
s[t−1]
s a
Q(s,a)
r[t]
a[t−1]
Save transitions:
s[t]
r[t]
a[t]
s a
Q(s,a)
<r[i], s[i], a[i]> for i=0 to t−1
c© 2007 Peter Stone
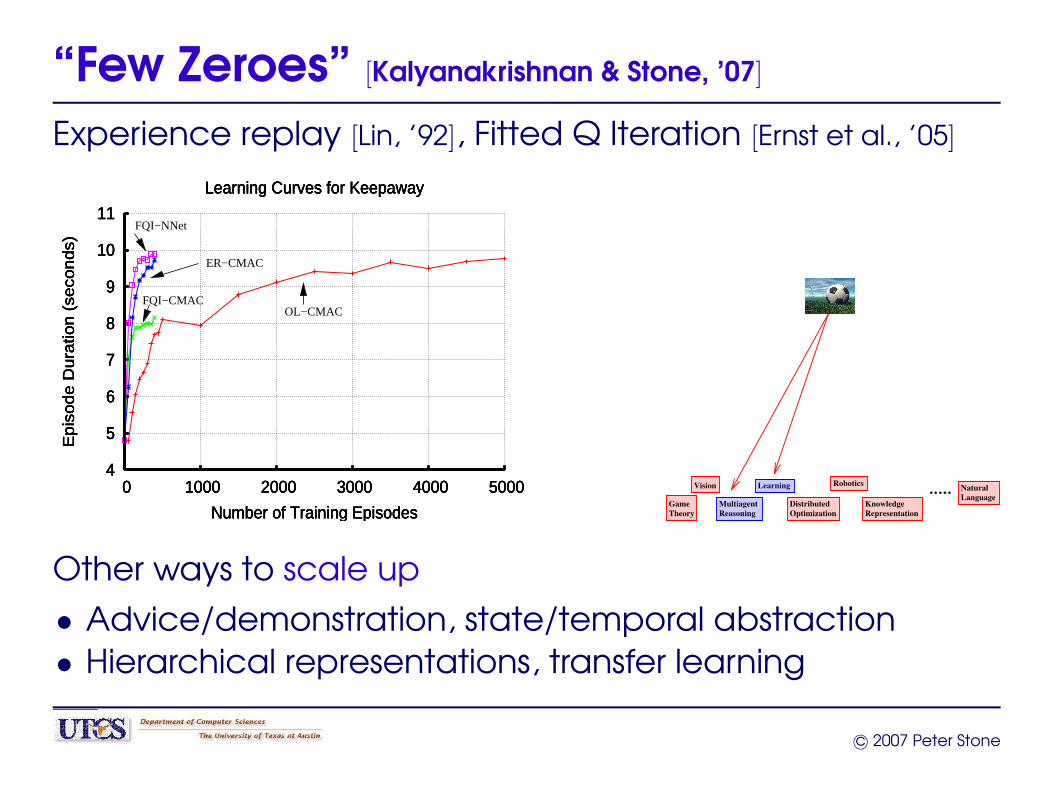
“Few Zeroes” [Kalyanakrishnan & Stone, ’07]
Experience replay [Lin, ’92], Fitted Q Iteration [Ernst et al., ’05]
4
5
6
7
8
9
10
11
0 1000 2000 3000 4000 5000
Epis
ode D
ura
tion (
seco
nds)
Number of Training Episodes
Learning Curves for Keepaway
4
5
6
7
8
9
10
11
0 1000 2000 3000 4000 5000
Epis
ode D
ura
tion (
seco
nds)
Number of Training Episodes
Learning Curves for Keepaway
4
5
6
7
8
9
10
11
0 1000 2000 3000 4000 5000
Epis
ode D
ura
tion (
seco
nds)
Number of Training Episodes
Learning Curves for Keepaway
4
5
6
7
8
9
10
11
0 1000 2000 3000 4000 5000
Epis
ode D
ura
tion (
seco
nds)
Number of Training Episodes
Learning Curves for Keepaway
FQI−NNet
FQI−CMAC
ER−CMAC
OL−CMAC
Vision
GameTheory
Robotics
RepresentationKnowledgeDistributed
Optimization
NaturalLanguage
MultiagentReasoning
Learning
Other ways to scale up
• Advice/demonstration, state/temporal abstraction• Hierarchical representations, transfer learning
c© 2007 Peter Stone
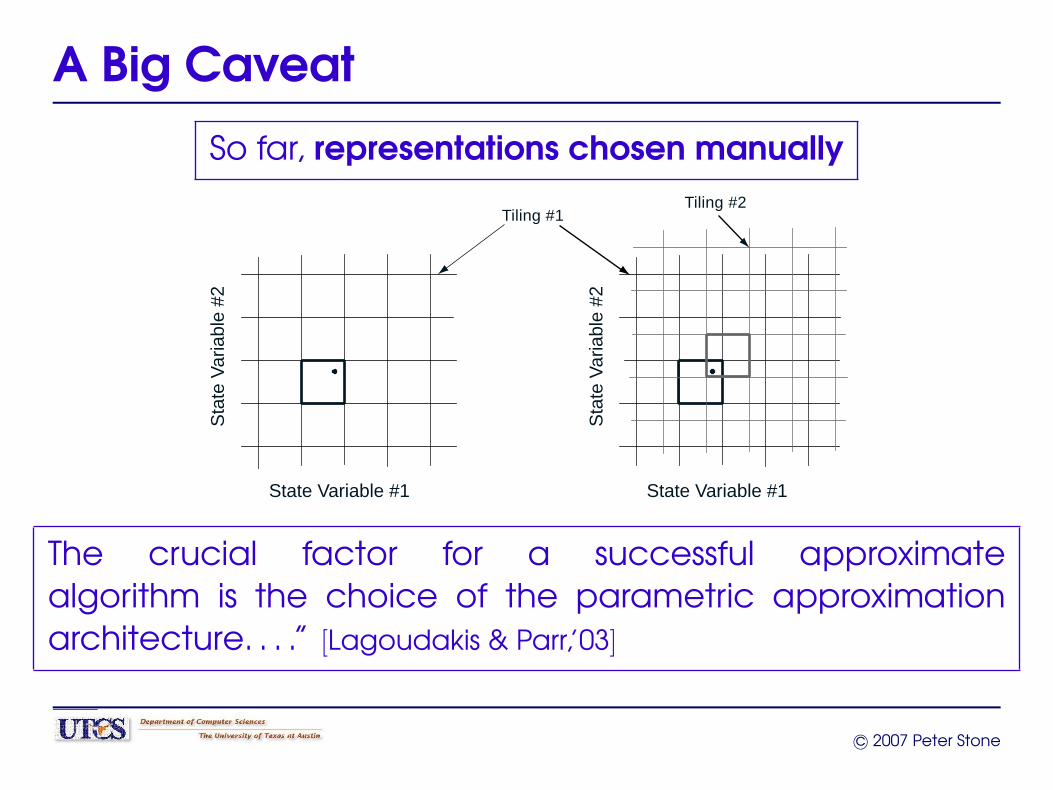
A Big Caveat
So far, representations chosen manually
Tiling #1
State Variable #1
Tiling #2
State Variable #1
Sta
te V
aria
ble
#2
Sta
te V
aria
ble
#2
The crucial factor for a successful approximatealgorithm is the choice of the parametric approximationarchitecture. . . .” [Lagoudakis & Parr,’03]
c© 2007 Peter Stone

Representations for RL
Can RL agents automatically learneffective representations?
Vision
GameTheory
Robotics
RepresentationKnowledgeDistributed
Optimization
NaturalLanguage
MultiagentReasoning
Learning
c© 2007 Peter Stone
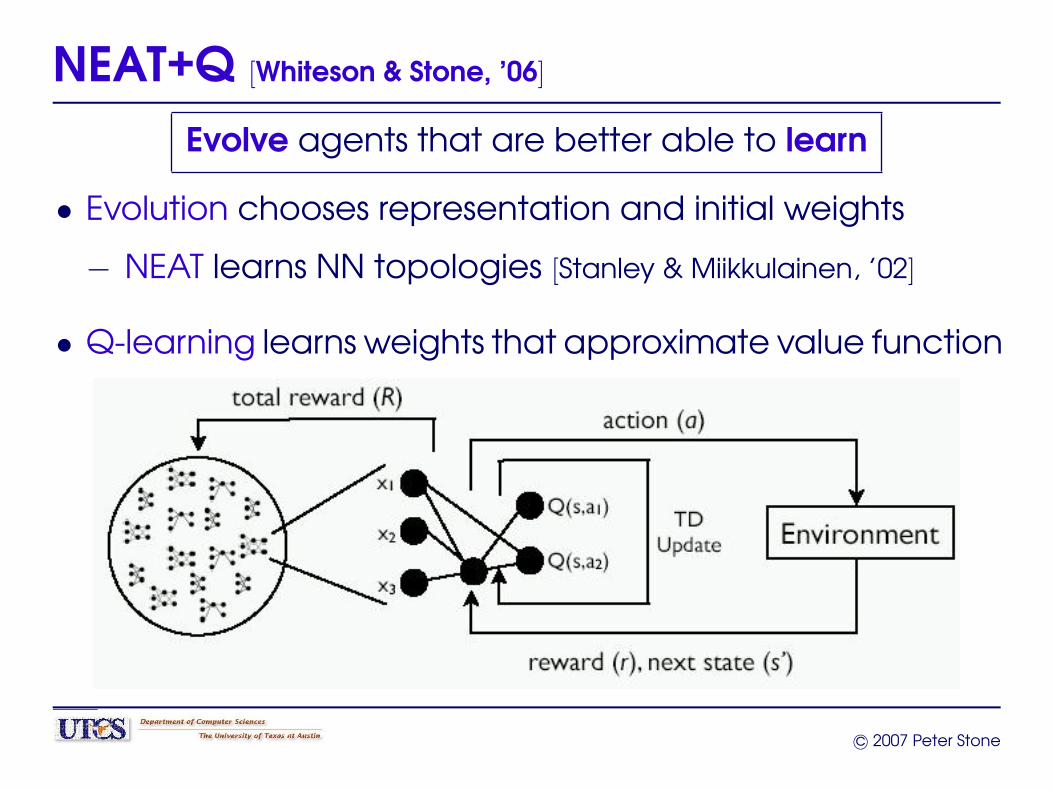
NEAT+Q [Whiteson & Stone, ’06]
Evolve agents that are better able to learn
• Evolution chooses representation and initial weights
− NEAT learns NN topologies [Stanley & Miikkulainen, ’02]
• Q-learning learns weights that approximate value function
c© 2007 Peter Stone
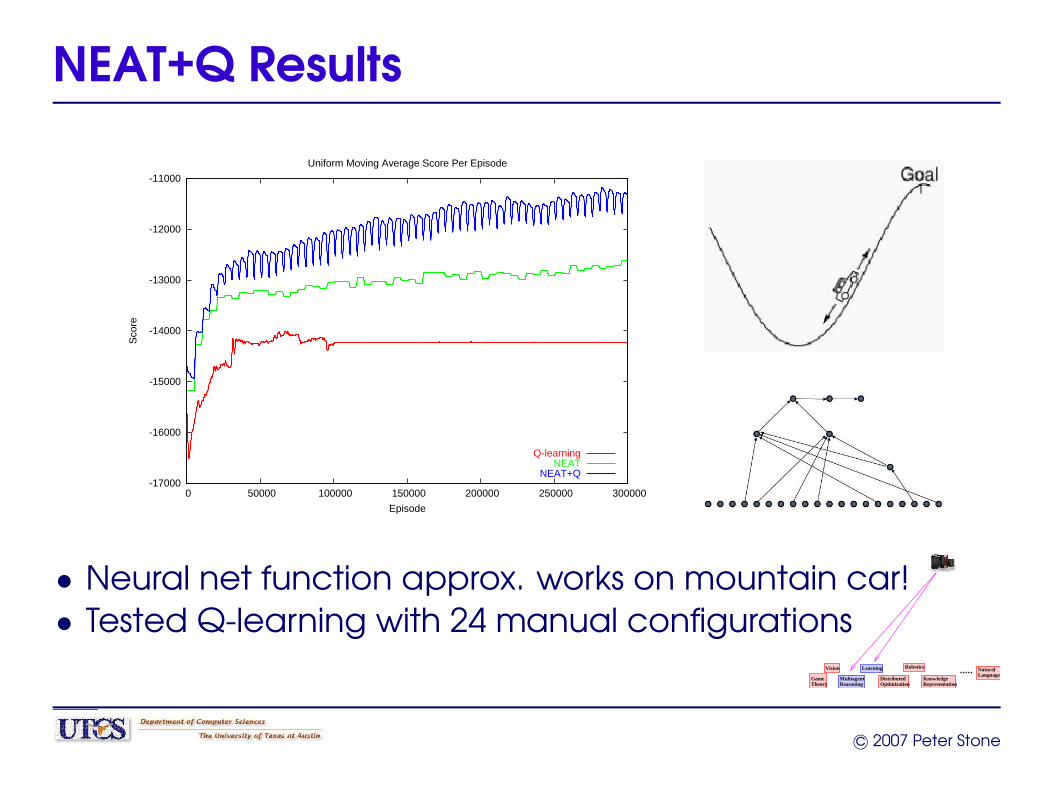
NEAT+Q Results
-17000
-16000
-15000
-14000
-13000
-12000
-11000
0 50000 100000 150000 200000 250000 300000
Sco
re
Episode
Uniform Moving Average Score Per Episode
Q-learningNEAT
NEAT+Q
• Neural net function approx. works on mountain car!• Tested Q-learning with 24 manual configurations
Vision
GameTheory
Robotics
RepresentationKnowledgeDistributed
Optimization
NaturalLanguage
MultiagentReasoning
Learning
c© 2007 Peter Stone
Outline
• Build complete solutions to relevant challenge tasks
− Drives research on component algorithms, theory
• Learning Agents
− Scaling up Reinforcement Learning− Adaptive representations
• Multiagent reasoning
− Prepare for the unexpected− Adaptive interaction protocols
Vision
GameTheory
Robotics
RepresentationKnowledgeDistributed
Optimization
NaturalLanguage
MultiagentReasoning
Learning
c© 2007 Peter Stone

Multiagent ReasoningRobust, fully autonomousagents in the real world
• Once there is one, there will soon be many• To coexist, agents need to interact• Example: autonomous vehicles− DARPA “Grand Challenge” was a great first step− Urban Challenge continues in the right direction− Traffic lights and stop signs still best? [Dresner & Stone, ’04]
Vision
GameTheory
Robotics
RepresentationKnowledgeDistributed
Optimization
NaturalLanguage
MultiagentReasoning
Learning
c© 2007 Peter Stone
Autonomous Bidding Agents
Agent
Agent
Agent
AgentAgent
Agent
Market
• Usual assumption: rational agentsVision
MultiagentReasoning
GameTheory
Learning Robotics
RepresentationKnowledgeDistributed
Optimization
NaturalLanguage
• In practice, must prepare for the unexpected
− Other agents created by others− Teammate/opponent modeling− Especially in competition scenarios
c© 2007 Peter Stone

Trading Agent Competitions
ATTac: champion travel agent [Stone et al., ’02]
− Learns model of auction closing prices from past data− Novel algorithm for conditional density estimation
TacTex: champion SCM agent [Pardoe & Stone, ’06]
− Adapts procurement strategy based on recent data− Predictive planning and scheduling algorithms
Common multiagent tradeoff:learn detailed static model vs.adapt minimally on-line
Vision
GameTheory
Robotics
RepresentationKnowledgeDistributed
Optimization
NaturalLanguage
MultiagentReasoning
Learning
c© 2007 Peter Stone
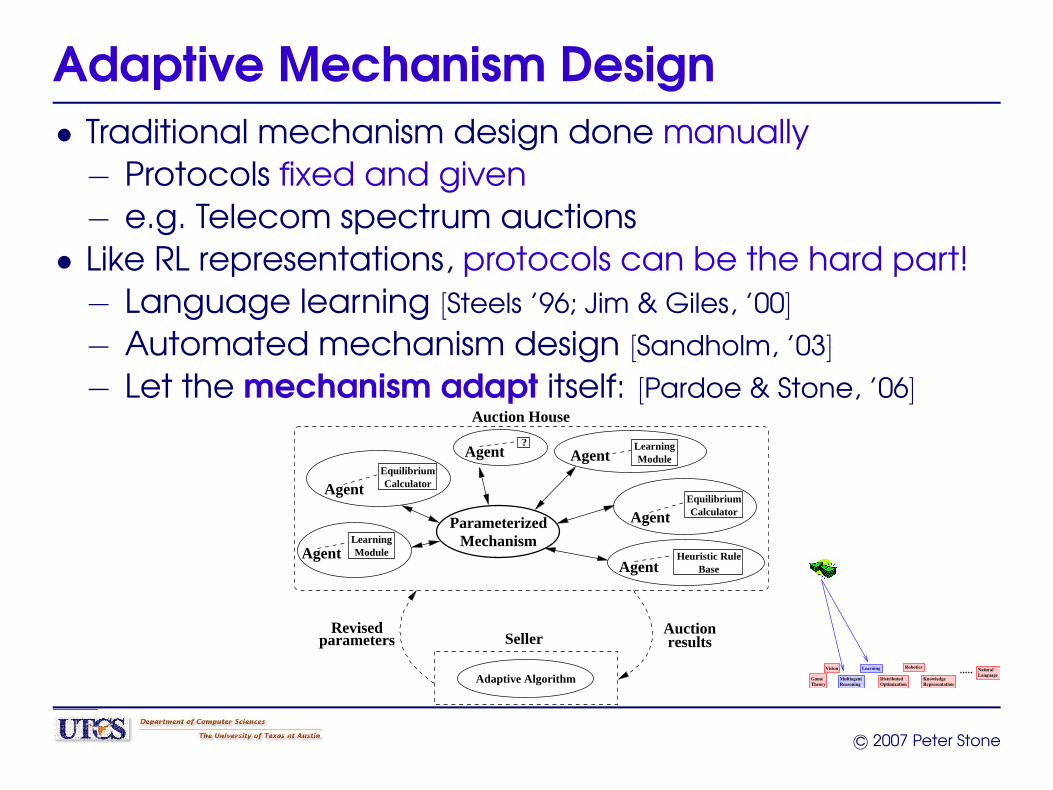
Adaptive Mechanism Design• Traditional mechanism design done manually− Protocols fixed and given− e.g. Telecom spectrum auctions
• Like RL representations, protocols can be the hard part!− Language learning [Steels ’96; Jim & Giles, ’00]
− Automated mechanism design [Sandholm, ’03]
− Let the mechanism adapt itself: [Pardoe & Stone, ’06]
Auctionparameters
Revised
ModuleLearning
BaseHeuristic Rule
ModuleLearning?
CalculatorEquilibrium
AgentParameterizedMechanism
Adaptive Algorithm
Auction House
Seller
Agent
AgentAgent
AgentAgent
Calculator
results
Equilibrium
Vision
GameTheory
Robotics
RepresentationKnowledgeDistributed
Optimization
NaturalLanguage
MultiagentReasoning
Learning
c© 2007 Peter Stone
Outline• Build complete solutions to relevant challenge tasks
− Drives research on component algorithms, theory
• Learning Agents
− Scaling up Reinforcement Learning− Adaptive representations
• Multiagent reasoning
− Prepare for the unexpected− Adaptive interaction protocols
• Implications Vision
GameTheory
Robotics
RepresentationKnowledgeDistributed
Optimization
NaturalLanguage
MultiagentReasoning
Learning
c© 2007 Peter Stone

A Goal of AI
Robust, fully autonomousagents in the real world
What happens when we achieve this goal
? ?
• Question: Would you rather live− 50 years ago? Or 50 years in the future?
• Not clear — world changing in many ways for the worse
AI can be a part of the solution
c© 2007 Peter Stone

Acknowledgments• Manuela Veloso• Collaborators on this research: János Csirik, Kurt Dresner,
Peggy Fidelman, Shivaram Kalyanakrishnan, Nate Kohl, Gregory
Kuhlmann, David McAllester, David Pardoe, Michael Littman, Patrick
Riley, Richard Sutton, Robert Schapire, Mohan Sridharan, Manuela
Veloso, Shimon Whiteson
• Help preparing the talk: Dana Ballard, Kristen Grauman, Nicholas
Jong, Nate Kohl, Gregory Kuhlmann, Ben Kuipers, Vladimir Lifschitz,
Risto Miikkulainen, Ray Mooney, Bruce Porter, Elaine Rich, Astro Teller,
Shimon Whiteson
• Other contributors: Mazda Ahmadi, Bikramjit Banerjee, Daniel
Stronger, Mathhew Taylor, Jonathan Wildstrom, Yaxin Liu
• Sponsors: NSF, DARPA, ONR, Sloan Foundation, IBM, NASA
• AI researchers over the past 50 years
c© 2007 Peter Stone

Additional Technical Details• Learned robot vision [Sridharan & Stone] (Wed., 2:40pm)
• Autonomic computing [Wildstrom & Stone] (Wed., 3:00pm)
• Intersection management [Dresner & Stone] (Thurs., 3:00pm)
• Transfer learning [Banerjee & Stone] (Thurs., 5:00pm)Original subtree
Lowest−level coalescing(intermediate step)
Mid−level coalescing(final step)producing a feature
c© 2007 Peter Stone
SummaryRobust, fully autonomousagents in the real world
• Build complete solutions to relevant challenge tasks
− Good problems drive research
Combine algorithmic research,problem-oriented approaches
Vision
GameTheory
Robotics
RepresentationKnowledgeDistributed
Optimization
NaturalLanguage
MultiagentReasoning
Learning
• Current challenges need learning, multiagent reasoning− Adaptive representations− Adaptive interaction protocols
c© 2007 Peter Stone















![Recurrent Deep Multiagent Q-Learning for Autonomous Agents ...ifaamas.org/Proceedings/aamas2018/pdfs/p2136.pdf · REFERENCES [1] Angelos Angelidakis and Georgios Chalkiadakis. 2015.](https://static.fdocuments.us/doc/165x107/5e0edb630fe4390d7e01f805/recurrent-deep-multiagent-q-learning-for-autonomous-agents-references-1-angelos.jpg)


