
Introduction to big data
18
INTRODUCTION TO BIG DATA SITARAM KOTNIS P. DATE: 20/10/2014
-
Upload
sitaram-kotnis -
Category
Technology
-
view
113 -
download
1
Transcript of Introduction to big data

INTRODUCTION TO BIG DATA
S I T A R A M K O T N I S P .
D A T E : 2 0 / 1 0 / 2 0 1 4
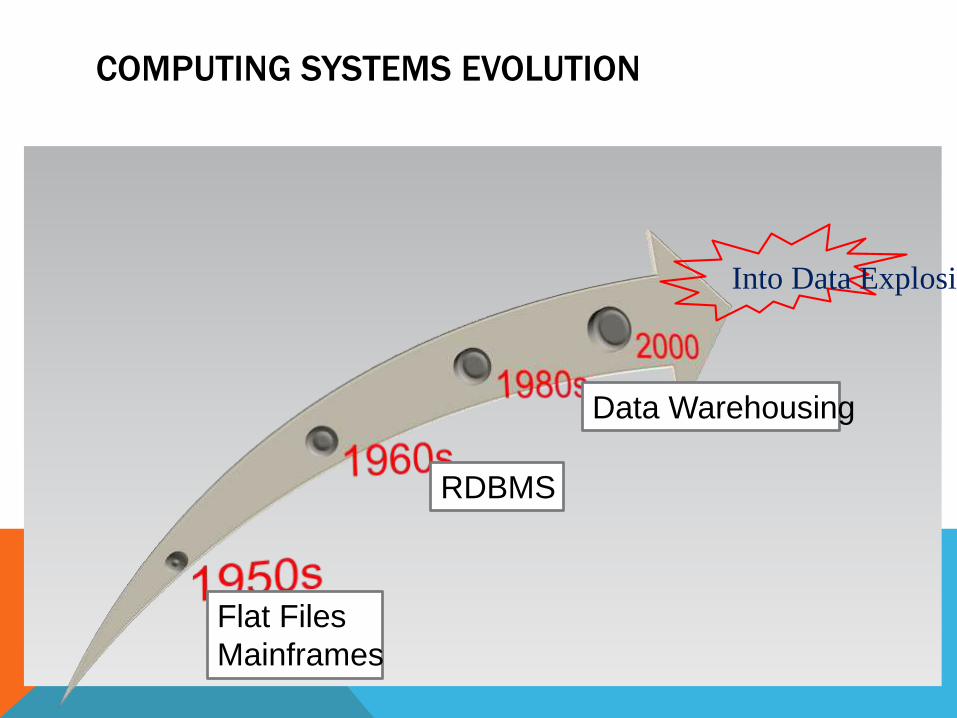
COMPUTING SYSTEMS EVOLUTION
Flat Files
Mainframes
RDBMS
Data Warehousing
Into Data Explosion


BIG DATA
Volume
Scale of Data
VeracityAccuracy of Data
Velocity
Analysis of Streaming
Data
Variety
Different Forms of
Data
What is BIG DATA?
“data sets that are too large and
complex to manipulate or
interrogate with standard methods
or tools.”
The challenges include
analysis, capture, curation,
search, sharing, storage,
transfer, visualization, and
privacy violations.
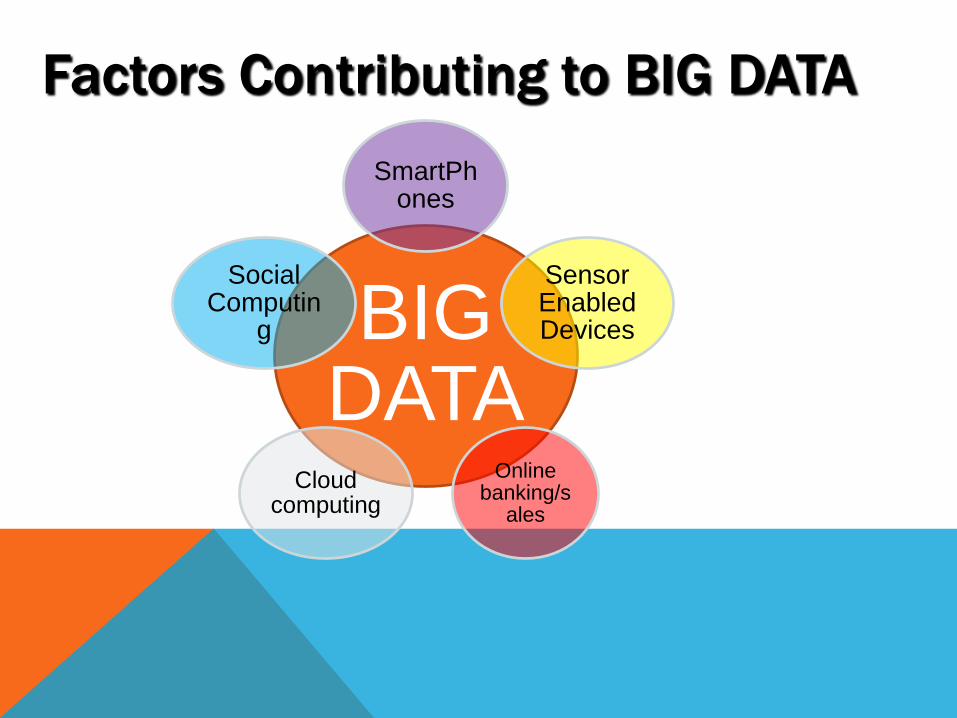
BIG DATA
SmartPhones
Sensor Enabled Devices
Online banking/s
ales
Cloud computing
Social Computin
g
Factors Contributing to BIG DATA

SOME STATISTICS…
Everyday 247 billion emails are exchanged in the world in which
80% are spam.
YouTube users upload 48 hours of new video every minute of the
day.
Upto 2003 we stored 5 Exabytes of data. Today everyday we
generated more than 5EB.
There are 30 billion pieces of content shared on Facebook every
month.
People wishing happy new year generated 80TB of data in 2011.
Number of webpages Google indexes is more than 55 billion.

Data is increasing at accelerating speeds day by day
Revolutionary changes in statistical and computational methods
Everyone wants to find insights from the pile of data
Some of the patterns discovered in BIG DATA would not be seen with small sets of data.
Sentiment Analysis, Market Study, Automated Traffic controls, System monitored health care and many more
BIG DATA IS BIG DEAL!!!

WHERE IS IT USED?
Science and Research – meteorology, genomic studies, LHC,
NASA etc..
Government – NSA, Adhar
Private Enterprises
Google, Facebook, Twitter, Yahoo, Ebay and more
Politics -----)

Why is it used?--> To make decisions i.e. Analytics
Descriptive Analytics
Vanilla BI reports
Predictive Analytics
Linkedln Recommendations
Credit card ratings.
Prescriptive Analytics
Health care
Oil and Gas explorations.

TYPES OF APPLICATIONS
Nanosecond Data latencyDays/Weeks Data latency

TYPE 1: MAPREDUCE
MapReduce is a programming model designed for processing large volumes of data in parallel by dividing the work into a set of independent tasks.
.
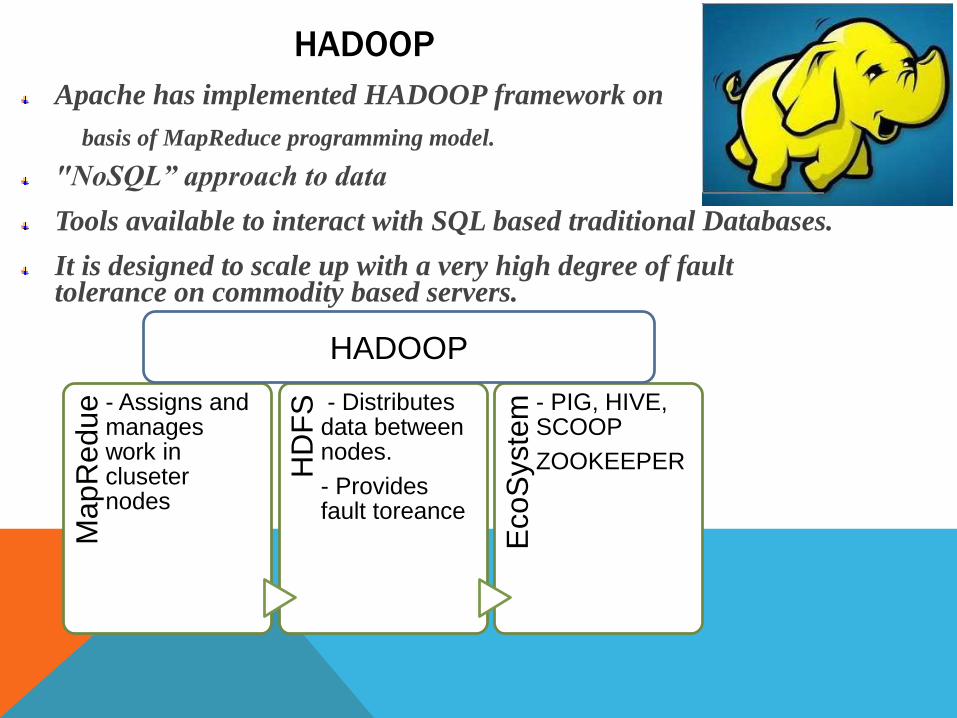
HADOOP
Apache has implemented HADOOP framework on
basis of MapReduce programming model.
"NoSQL” approach to data
Tools available to interact with SQL based traditional Databases.
It is designed to scale up with a very high degree of fault tolerance on commodity based servers.
Ma
pR
ed
ue - Assigns and
manages work in cluseternodes
HD
FS - Distributes
data between nodes.
- Provides fault toreance
Eco
Syste
m - PIG, HIVE, SCOOP
ZOOKEEPER
HADOOP

TYPE 2 :REAL-TIME ANALYTICS–WITH ADVANCED FEATURES IN RDBMS/ NOSQL
DATABASES
In-memory data and computing
Columnar Data
Write(Insert) operations in to Delta
Partitioning and many more

In memory (or main memory) databaseIs a database management system that primarily relies on main memory for computer data storage.
SAP HANA, IBM Netezza, HP Vertica

memory address
$
$
A 10 € B 35 $ C 2 € D 40 € E 12
A B C D E 10 35 2 40 12 € $ € €
organize by row
organize by column
Values of a column are stored contiguously in memory.
Columnar database tables can better suit to OLAP
Enable faster throughput for Aggregations, selelctions, calculations.
Suitable for NoSQL databases too.
Columnar databases
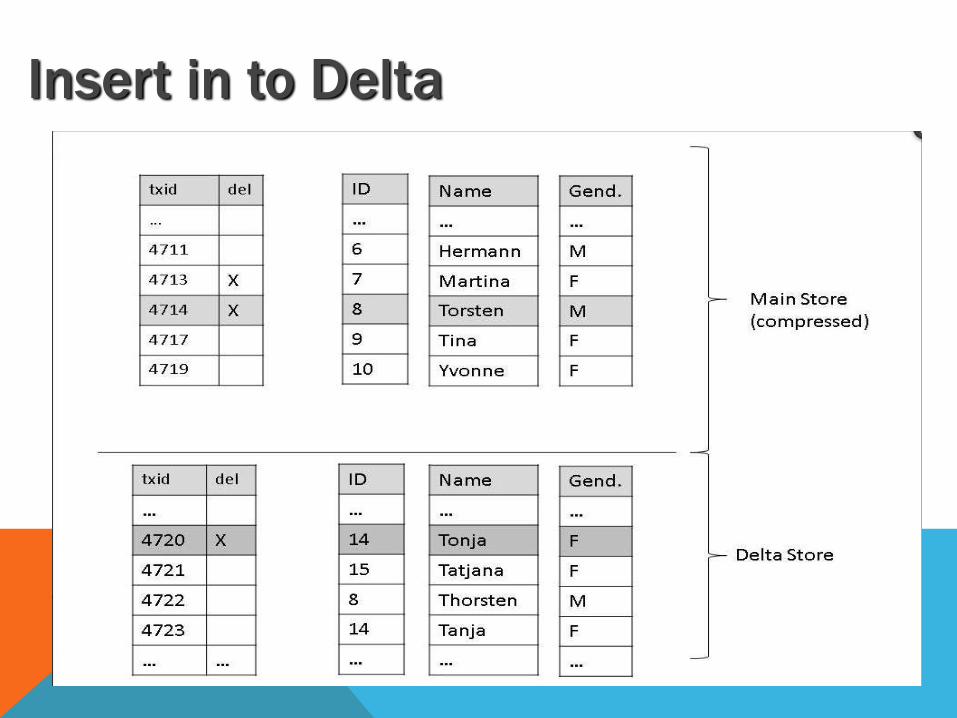
Insert in to Delta

TYPE 3: COMPLEX EVENT PROCESSING
Most Real-Time of all with nano-second data latency.
Smart Trade solutions
Fraud Detection systems
Driverless Cars

BIG DATA concept is old but caught attention in recent years.
Private Enterprises, Public Sector Agencies, Financial Institutions are eagerly looking to take advantage of BIG DATA solutions.
Various products, frameworks and solutions are available in the market and they keep growing.
Huge market opportunities for IT services and analytics firms.
CONCLUSION


















