
Introduction Big data
28
Prepared By: Marwan A. Al-Wajeeh Big Data 1
-
Upload
- -
Category
Technology
-
view
112 -
download
9
Transcript of Introduction Big data

Prepared By: Marwan A. Al-Wajeeh
Big Data
1

2
3
Outline
Big Data an OverviewBig Data Sources What Is Big DataBig Data Challenges Big Data Analytics
4
More than 2.5 billion bytes of data are created EVERY DAY IBM: 90 percent world’s Data today was produced in the last
two years80% of world data is unstructuredFacebook Process 500 TB per day.Lots and Lots of Web Pages (20 billion web pages in google)A billion Facebook UsersBillions+ Facebook PagesHundreds of Million Twitters AccountHundreds of Million Twitters per DayBillions Google Queries per DayMillions of servers, Beta Bytes of Data
Big Data an Overview

5
Big Data
6
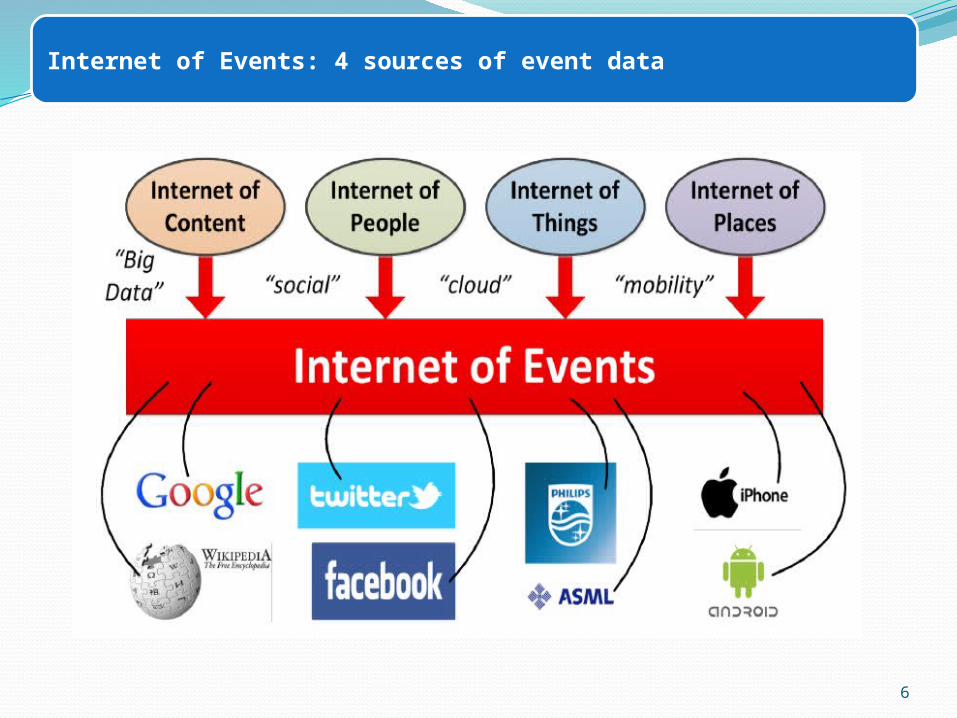
Internet of Events: 4 sources of event data

7
Big Data Sources

8
Big Data is a collection of data sets that are large and complex in nature.
Big Data is any data that is expensive to manage and hard to extract value from.
They constitute both structure and un structured data they grow large so fast that they are not manageable by traditional relational database systems or congenital statistical tools.
What Is Big Data?

9
Volume: the size of data Google Example:
10 Billions web pages Average size of web pages = 200KB 10 billion * 20KB= 200 TB Disk read bandwidth = 50MB/Sec Time to read= 4 million seconds= 46+ Day
Airbus A380 Example: Each A380 four engine generates 1 PB of data on a flight,
for example, from London (LHR) to Singapore (SIN)
Big Data: Four Challenges (4 V’s)

10
Velocity (speed of change). we are not only generating a lot amount of data but the data is
continuously being added and things are changing very rapidly.
Verity (different types of data source). The diversity of sources, format, quality, and structure
Veracity (uncertainty of data). that means that you cannot completely sure that we have
recorded incompletely sure.
Big Data: Four Challenges (4 V’s)
11
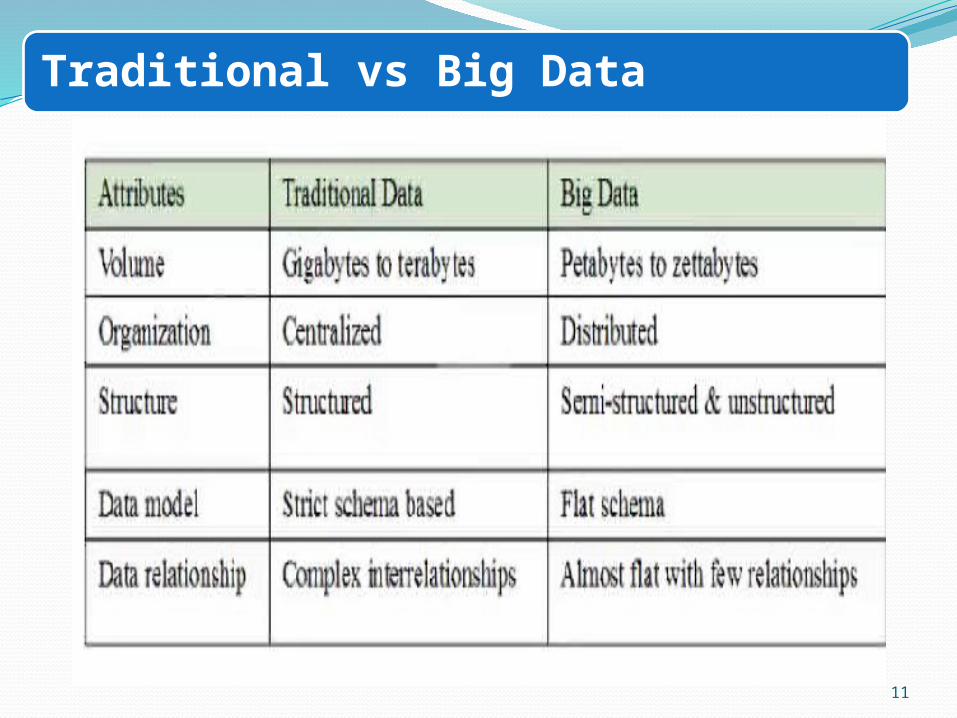
Traditional vs Big Data

12
Big data analytics is the process of:Collecting Organizing and Analyzing
Of large set of data “big data” to Discover patterns andOther useful information
Big Data Analytics

13
Traditional Analytics Big Data Analytics
Analytics using known data which is well understood
Not well understood data format from it largely being unstructured and semi-structured
Built based on relational data models
Big data comes in various form and formats from multiple disconnected systems. They are almost flat with no relation ship.
Traditional vs Big Data Analytics

14
Traditional RDBMS Fails to handle Big DataBig Data (terabytes) can not fit in the
memory for a single computerProcessing of Big Data in single computer
will take a lot of timeScaling with the traditional RDBMS is
expensive.
Analytical Challenges with Big Data
15
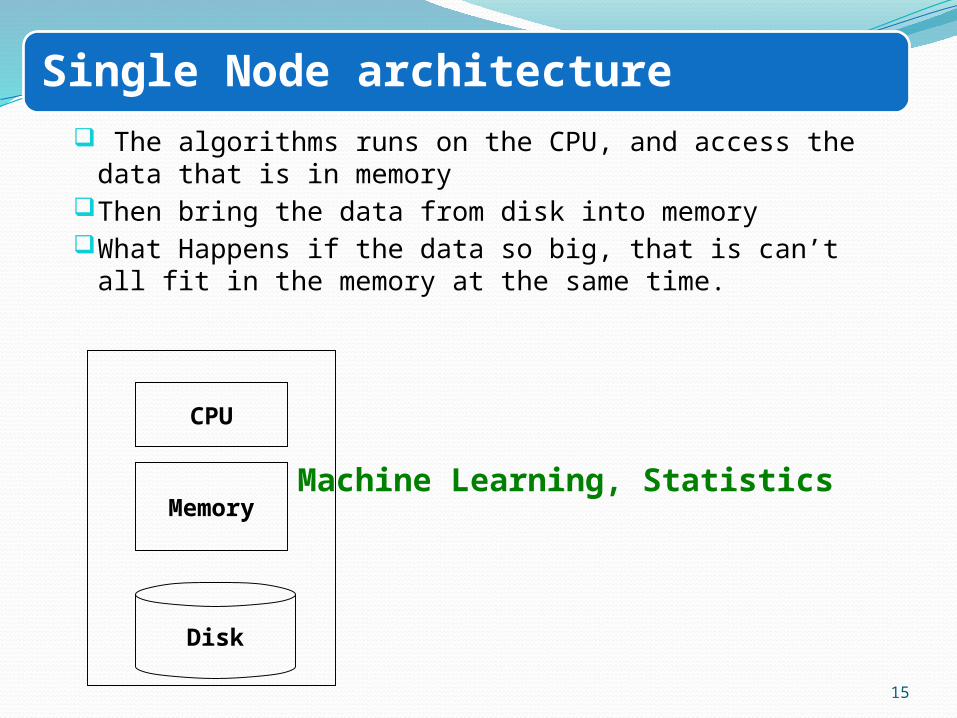
Memory
Disk
CPU
Machine Learning, Statistics
The algorithms runs on the CPU, and access the data that is in memory
Then bring the data from disk into memoryWhat Happens if the data so big, that is can’t all fit in the memory
at the same time.
Single Node architecture

16
10 billion web pagesAverage size of webpage= 20KB10 billion * 20 KB= 200TBDisk read bandwidth = 50MB/secTime to read = 4 million second= 46+ days
Thus: this is unacceptable, and we need a better solution Clustering Computing emerge as new solutionThe fundamental idea is to split the data into chunks, if we
have 1000 disks and CPUs, the process will done with in hour.
Google Example
17
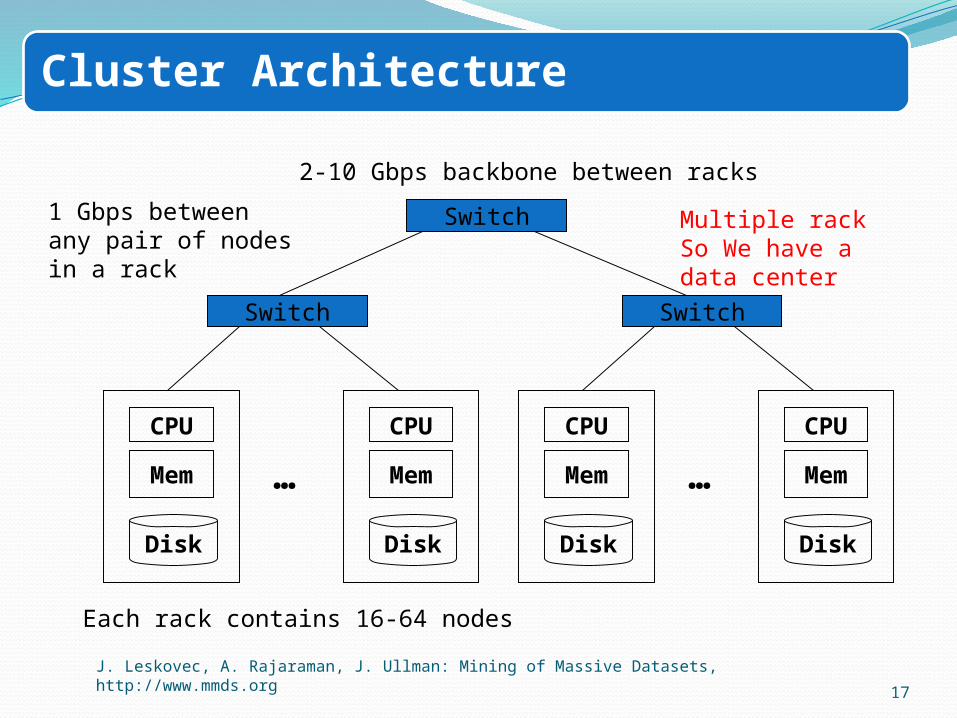
Mem
Disk
CPU
Mem
Disk
CPU
…
Switch
Each rack contains 16-64 nodes
Mem
Disk
CPU
Mem
Disk
CPU
…
Switch
Switch1 Gbps between any pair of nodesin a rack
2-10 Gbps backbone between racks
J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org
Cluster Architecture
Multiple rack So We have a data center

18
Now once we have this kind of cluster
This does not solve the problem completely

J. Leskovec, A. Rajaraman, J. Ullman: Mining of Massive Datasets, http://www.mmds.org
19

20
Node Failure A single server can stay up for 3 years (1000
days)1000 server in the cluster => 1 failure/ dayMillion server in cluster => 1000 failure/day
(Google have approximately million server) how to store data persistently and keep it
available if nodes can fail how to deal with node failure during along
running computation?
Cluster Commuting Challenges

21
Network bottleneckNetwork bandwidth = 1 GbpsMoving 10 TB takes approximately 1 dayComplex computation might need to move a lot of data
and that can slow computation down.We need a framework doesn't move data around so much
while it’s doing computation.Distribution programming is hard!
It is hard to write distributed programs correctly
We need simple model that hides most of complexity of distributed programming
Cluster Commuting Challenges

22
Map- Reduce address the challenges of cluster computingStore date redundantly on multiple nodes for persistence
and availability Move computation close to the data to minimize data
movement Simple programming model to hide complexity of all this
magic
Map-Reduce

23
Hadoop= MapReduce + HDFS
Pig HiveHBas
e
Flume
Rhadoop
Spoop
Oozie
Avro
Zoo Keepe
r
Big Data Analytics Tools and Technologies

24
Thank You

25
4 Types of AnalyticsDescriptive: What happened?Diagnostics: Why did it happen?Predictive: what will happen?Prescriptive: what is the best that can happen
Analytics Tools:SAS IBM SPSSStataRMATLAb
26
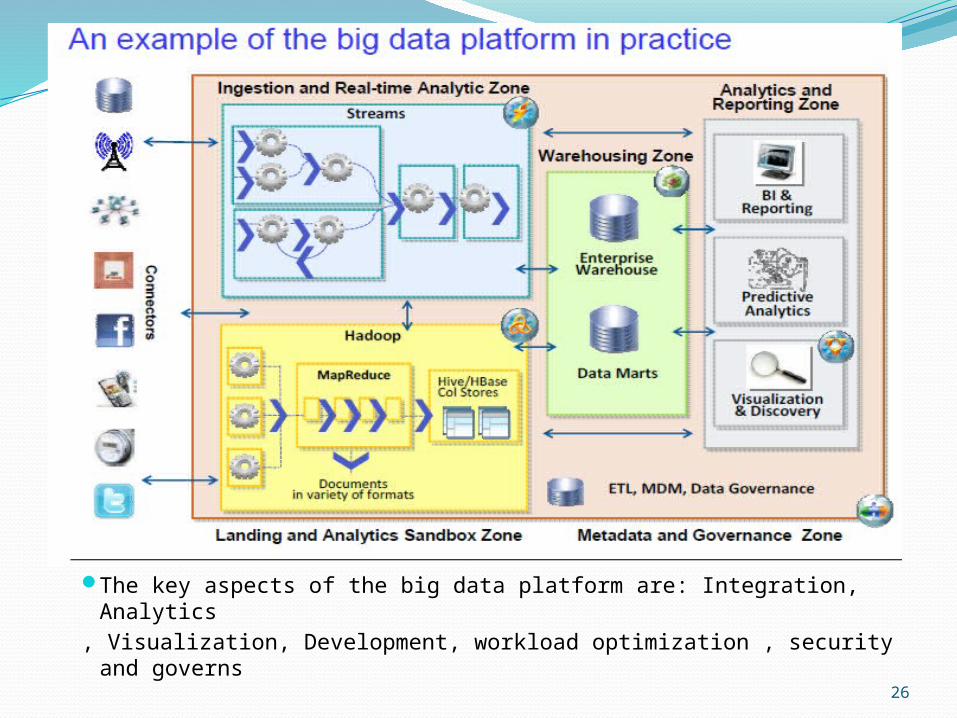
The key aspects of the big data platform are: Integration, Analytics, Visualization, Development, workload optimization , security and
governs

27
The 5 High Value Big Data Use Cases

28
Thank You


















