
Interactions between prenasalized stops and nasal …web.mit.edu/juliets/www/stantonLSA2017.pdf ·...
8
Interactions between prenasalized stops and nasal vowels * Juliet Stanton, MIT ❖ LSA 91 ❖ January 7, 2017 1 Introduction • Broad question: why are phonemic contrasts often restricted to a subset of environments in which they could occur? – Example: many languages (12% of UPSID; Maddieson & Ladefoged 1993) license contrasts between prenasalized stops (NCs), nasals, and oral stops. m Stop inventory with NCs (Ngambay, Nilo-Saharan, Vandame 1963), in (1): m (Why segments, not clusters? Usually for distributional reasons, cf. Riehl 2008, but the segment vs. cluster distinction isn’t so important here.) (1) Bilabial Alveolar Palatal Velar Voiceless p t k Voiced b d é g Prenasalized mb nd ñé Ng Implosive á â Nasal m n – But: distribution of NCs is frequently constrained, with respect to other stops. (2) Language Initial Intervocalic Final Ngambay (Vandame 1963) X X * Kobon (Davies 1980) * X X Naman (Crowley 2006b) X X X • More specific question: what is the explanation for (2)? Put differently: what constraints govern the distribution of NCs? – Stanton (2016a,b): constraints on NC distribution are constraints on the con- trasts between and NCs and their component parts, plain nasal and plain oral consonants (Ns and Cs). – Generalizations regarding the distribution of NCs can be predicted given con- sideration of where NCs are more or less distinct from their component parts. * [email protected]. For helpful feedback I thank Adam Albright, Edward Flemming, Donca Steri- ade, and participants at MIT’s Phonology Circle. All errors are mine. • Example: distribution of cues to the contrast between Ns and NCs (the N–NC contrast) allows us to predict generalizations regarding its distribution. – Cues to the N–NC contrast, established in an identification task with Ikalanga listeners (Beddor & Onsuwan 2003; spectrograms from Stanton 2016b): m Internal cue : presence of NC’s oral closure and release burst. Time (s) 0 0.7235 0 8000 Frequency (Hz) ana /ana/ Time (s) 0 0.7074 0 8000 Frequency (Hz) anda /anda/ · Stronger: anywhere where NCs are released (na–nda, an–and). · Weaker: anywhere where NCs are not released (an–and^). m External cue : minimally, difference in nasal vs. oral CV transitions, where Ns are followed by nasal transitions and NCs by oral transitions. Time (s) 0 0.7235 0 8000 Frequency (Hz) ana /ana/ Time (s) 0 0.7074 0 8000 Frequency (Hz) anda /anda/ · Present: when Ns and NCs are followed by appropriate nasal vs. oral transitions (n˜ a–nda). · Absent: when not followed by appropriate transitions (n˜ a–nd˜ a, an-and). m Internal vs. external : external cues are important to identification of the N–NC contrast, and essential when NCs are voiced (for experimental evi- dence see Beddor & Onsuwan 2003, Kaplan 2008). 1
-
Upload
vuonghuong -
Category
Documents
-
view
216 -
download
1
Transcript of Interactions between prenasalized stops and nasal …web.mit.edu/juliets/www/stantonLSA2017.pdf ·...

Interactions between prenasalized stops and nasal vowels∗
Juliet Stanton, MIT v LSA 91 v January 7, 2017
1 Introduction• Broad question: why are phonemic contrasts often restricted to a subset of
environments in which they could occur?
– Example: many languages (12% of UPSID; Maddieson & Ladefoged 1993)license contrasts between prenasalized stops (NCs), nasals, and oral stops.
m Stop inventory with NCs (Ngambay, Nilo-Saharan, Vandame 1963), in (1):m (Why segments, not clusters? Usually for distributional reasons, cf. Riehl
2008, but the segment vs. cluster distinction isn’t so important here.)
(1)
Bilabial Alveolar Palatal VelarVoiceless p t kVoiced b d é gPrenasalized mb nd ñé NgImplosive á âNasal m n
– But: distribution of NCs is frequently constrained, with respect to other stops.
(2)
Language Initial Intervocalic FinalNgambay (Vandame 1963) X X *Kobon (Davies 1980) * X XNaman (Crowley 2006b) X X X
• More specific question: what is the explanation for (2)? Put differently: whatconstraints govern the distribution of NCs?
– Stanton (2016a,b): constraints on NC distribution are constraints on the con-trasts between and NCs and their component parts, plain nasal and plain oralconsonants (Ns and Cs).
– Generalizations regarding the distribution of NCs can be predicted given con-sideration of where NCs are more or less distinct from their component parts.
∗[email protected]. For helpful feedback I thank Adam Albright, Edward Flemming, Donca Steri-ade, and participants at MIT’s Phonology Circle. All errors are mine.
• Example: distribution of cues to the contrast between Ns and NCs (the N–NCcontrast) allows us to predict generalizations regarding its distribution.
– Cues to the N–NC contrast, established in an identification task with Ikalangalisteners (Beddor & Onsuwan 2003; spectrograms from Stanton 2016b):m Internal cue: presence of NC’s oral closure and release burst.
Time (s)0 0.7235
0
8000
Freq
uenc
y (H
z)
ana/ana/
Time (s)0 0.7074
0
8000
Freq
uenc
y (H
z)
anda/anda/
· Stronger: anywhere where NCs are released (na–nda, an–and).· Weaker: anywhere where NCs are not released (an–and^).
m External cue: minimally, difference in nasal vs. oral CV transitions, whereNs are followed by nasal transitions and NCs by oral transitions.
Time (s)0 0.7235
0
8000
Freq
uenc
y (H
z)
ana/ana/
Time (s)0 0.7074
0
8000
Freq
uenc
y (H
z)
anda/anda/
· Present: when Ns and NCs are followed by appropriate nasal vs. oraltransitions (na–nda).· Absent: when not followed by appropriate transitions (na–nda, an-and).
m Internal vs. external: external cues are important to identification of theN–NC contrast, and essential when NCs are voiced (for experimental evi-dence see Beddor & Onsuwan 2003, Kaplan 2008).
1

• Adopting the hypothesis of licensing by cue (Steriade 1997, (3)), we can makea couple of predictions regarding the distribution of the N–NC contrast (4).
(3) Licensing by cue (Steriade 1997): if two contexts (C1 and C2) differin that some contrast x–y is better-cued in C1 than it is in C2, then thepresence of x–y in C2 implies its presence in C1.
(4) Predictions given (3) and cues to N–NCa. If a language licenses word-final N–NC (an–and), it must li-
cense prevocalic N–NC (na–nda).(Why? External cues to N–NC are present prevocalically but not finally.)
b. If a language allows NC to appear before a nasal vowel (V), itmust allow NC to appear before an oral vowel (V).(Why? NC is maximally distinct from N when it precedes V, but potentiallyconfusable with N before V.)
• Do these predictions hold?
– Evidence in support of (4a): in a sample of 50 languages, all that allow word-final N–NC also allow prevocalic N–NC ((5), Stanton 2016b).
(5)
N–NC / V, N–NC / V, *N–NC / V,N–NC / # *N–NC / # N–NC / #
19 languages, e.g. 31 languages, e.g. 0 languagesAvava (Crowley 2006a) Acehnese (Durie 1985)Naman (Crowley 2006b) Alawa (Sharpe 1972)
Paez (Rojas Curieux 1998) Lua (Boyeldieu 1985)
m Could be described by other theories, i.e. those that recognize *CODANCbut not *ONSETNC as part of CON.· (Actually, even this proposal is insufficient: not all onsets are hospitable
to NCs. Kobon, in (2), allows intervocalic but not initial NCs.)· (For an account of this, see Stanton 2016b.)
m Predicted by a contrast-based approach to phonotactics: N–NC is dispre-ferred in contexts where cues to the contrast are weaker.
– This talk: new evidence in support of (4b) (see also Stanton 2016a).m Section 2: evidence that if a language allows NCV, it also allows NCV.m Section 3: evidence that not all kinds of NCV sequences are created equal.
• Main point: constraints on the distribution of NCs are constraints on contrast.
– The generalizations regarding NCV licensing are just one portion of a greaterbody of evidence for this larger conclusion.
– For a fuller picture of the evidence, see Stanton (thesis in prep).
2 NCV implies NCV• To test the prediction that a language allowing NCV should also allow NCV, I
conducted a survey1 of languages that license both N–NC and V–V contrasts.
– Yield: 24 languages that license both N–NC and V–V.– As shown in Table 1, the prediction in (4b) holds: all languages that license
NCV also license NCV.
Table 1: Results of N–NC and V–V surveyNCV, NCV NCV, *NCV
13 lgs. 11 lgs.Day (Nougayrol 1979) Acehnese (Durie 1985)Kabba (Moser 2004) Apinaye (Oliveira 2005)Lua (Boyeldieu 1985) Gbaya Kara (Monino & Roulon 1972)
Mazatec, Jalapa (Silverman et al. 1995) Gbeya (Samarin 1966)Mbay (Keegan 1996, 1997) Ndumbea (Gordon & Maddieson 1999)
Mbum (Hagege 1970) Nheengatu (Moore et al. 1993)Ngambay (Vandame 1963, 1974) Paez (Jung 2008)
Ngbaka (Thomas 1963; Henrix et al. 2015) Paici (Gordon & Maddieson 2004)Nizaa (Endresen 1991) Sango (Samarin 1967)Tinrin (Osumi 1995) Saramaccan (McWhorter & Good 2012)
Voute (Guarisma 1978) Vai (Welmers 1976)Xaracuu (Lynch 2002)
Yakoma (Boyeldieu 1975)
2.1 Analysis• An analysis of the typology in Table 1, framed in a version of Flemming’s
(2002) Dispersion Theory, requires three constraints:
– A MINDIST constraint (Flemming 2002), which requires that N be followedby a period of vocalic nasality and NC by a period of vocalic orality:
(6) MINDIST N–NC = ∆ CV transitions: assign one violation mark forevery N–NC pair in the output in which N is not followed by a vowelcontaining an initial period of acoustic nasality, and/or NC is not fol-lowed by a vowel containing an initial period of acoustic orality.2
1Some details: the survey was composed mainly of print resources found in MIT’s and Harvard’slibraries, as well as various online resources. The contrastive status of NC was determined by findingminimal or near-minimal N–NC pairs. Arguments for NC’s monosegmental status came from phono-tactics: if NC appears where other clusters (or sonority-violating clusters) can’t, it was counted as asingle segment. The contrastive status of V was determined by locating minimal or near-minimal V–Vpairs. Evidence that a language bans NCV comes in all cases from static phonotactic restrictions in thelexicon (some stated by the authors, some inferred by me).
2The full version of (6) will ultimately provide a definition of what ‘counts’ as a sufficient amountof orality and what ‘counts’ as a significant amount of nasality.
2

m One interpretation of this constraint: cues to N–NC involve the duration ofacoustic nasality vs. orality, which can extend into the following vowel.
m Overlap into the vowel is especially important for voiced NCs, where theoral portion is very short (see e.g. Burton et al. 1992, Maddieson & Lade-foged 1993, Beddor & Onsuwan 2003, Cohn & Riehl 2012).
– *MERGE, which disprefers neutralization (adapted from Padgett 2003):
(7) *MERGE: no output form has multiple input correspondents.
– *NC: assign one violation mark for each NC.
• In languages where N and NC do not contrast before nasal vowels (surfacegeneralization: NV but not NCV is allowed), ∆ CV TRANS� *MERGE.3
– N–NC is only licensed when it the appropriate CV transitions are available.
– Low-ranked *NC explains why result of N–NC neutralization is always N.
(8)
NV1 NCV2 ∆ CV TRANS *MERGE *NCa. NV1 NCV2 *! *
+ b. NV1,2 *c. NCV1,2 * *!
• In languages where N and NC contrast before nasal vowels, *MERGE�∆ CVTRANS; N–NC is licensed despite the absence of ∆ CV transitions.
(9)
NV1 NCV2 *MERGE ∆CV TRANS *NC+ a. NV1 NCV2 * *
b. NV1,2 *!c. NCV1,2 *! *
• Languages with NCV only cannot be derived: there is no possible MINDISTconstraint that prefers NV–NCV (less distinct) to NV–NCV (more distinct).
2.2 The role of nasal vowels• A question: what about a candidate like NV–NCVV, where NC oralizes part of
the following vowel to satisfy ∆ CV TRANS?
– This renders the N–NC contrast more distinct, but has other side effects.
– In particular, oralizing V would compromise cues to the V–V contrast.
3Another way to characterize the distribution in Table 1: V–V is neutralized after NC. There is noevidence from alternations indicating which is correct.
• While exact perceptual correlates of vocalic nasality remain elusive, there isevidence that duration of acoustic nasality plays a role.
– Delattre & Monnot (1968), Whalen & Beddor (1989): for a vowel stimu-lus containing an intermediate degree of nasality, subjects are more likely toidentify it as nasal when the stimulus is long and oral when it’s short.
– Whalen & Beddor (1989) don’t make precise the acoustic factor responsiblefor the perception of vocalic nasality, but hypothesize that nasal vowels aredistinct from oral ones due to a perceptual summation of nasality over time.
• These perceptual findings are paralleled by typological evidence suggestingthat, in languages that license a V–V contrast, short Vs are dispreferred.
– Of the 12 languages included in Maddieson (1984) with contrasts in vowellength and nasality, none license a nasality contrast for short vowels only.
(10)
V–V, V:–V: V:–V:, *V–V V–V, *V:–V:Irish, Hindi-Urdu, Breton, Ojibwa,Lakkia, Navaho, Delaware
Chipewyan, Tolowa,Auca, !Xu
m Implicational generalization: short V–V implies long V–V.
m Predicted under a contrast-based account, under the well-motivated as-sumption that short V is less distinct from an oral vowel than is long V.
– More generally it is common for nasal vowels to be longer than oral vowels(regardless of whether or not there is a length contrast).
m A few examples: Hayu (Sino-Tibetan; Michailovsky 2003), Wari’ (Cha-pakuran; Everett & Kern 1997), Twi (Niger-Congo; Adu Manyah 2003),French (Indo-European; Delattre & Monnot 1968).
m Perhaps surprising, given plausible precedent for the reverse (XV, XV:,XVN, *V:N (as in Japanese, e.g. Yoshida 1990:333); VN→ V).
• Given what we know about the cues to N–NC and V–V, we might expect someNCV sequences to be better-tolerated than others.
– Specifically, we might expect that NCV sequences in which V is long (NCV:)should be preferred to NCV sequences in which V is short.
– Why? Because the longer V is, the more likely it will be able to accommodateNC’s oral transitions while remaining distinct from V.
3
3 *NCV: evidence from the lexicon• To test the prediction that NCV should be dispreferred to NCV:, I analyzed
counts from five dictionaries/lexica.
– Dictionaries: Mbay (Keegan 1996), Ngbaka (Henrix et al. 2015); lexica: Lua(Boyeldieu 1985), Ngambay (Vandame 1974), and Voute (Guarisma 1978).
– This constitutes the entire body of available evidence: these are the onlyNCV-allowing languages that have associated lexica/dictionaries.
• Preview: not all languages exhibit a preference for NCV: over NCV, but nolanguage exhibits the opposite preference.
3.1 Mbay• Keegan’s (1996) Mbay dictionary has 11,544 CV sequences, from 5,558 words.
CV sequences were divided into eight categories, by three parameters (11):
(11)
Form Count Form CountCV 8185 NCV: 259CV: 1300 CV 153NCV 1243 NCV: 52CV: 344 NCV 8
• It appears that NCV(:) sequences are generally rare, and that NCV is even rarer.
– However: there are other factors that need to be controlled for!
– Low incidence of NCV(:) could be due to independent rarity of NCs and Vs.
– Low incidence of NCV could be due to independent rarity of short Vs.
• Is it actually the case that Mbay exhibits a dispreference for NCV? One way tofind out: fit a loglinear model to (11).
– Model is given count data and relevant factors; the goal is to determine which(combinations) of factors are significant predictors of the count data.
m If forms were distributed randomly, we might expect the frequency of allkinds of forms to be roughly equivalent.
m In (11) this clearly this isn’t the case; what is responsible for the skew?
– Three factors included in this model: NC vs. other C, V vs. V, and V: vs. V.All factors were dummy-coded; baseline values were the unmarked ones.
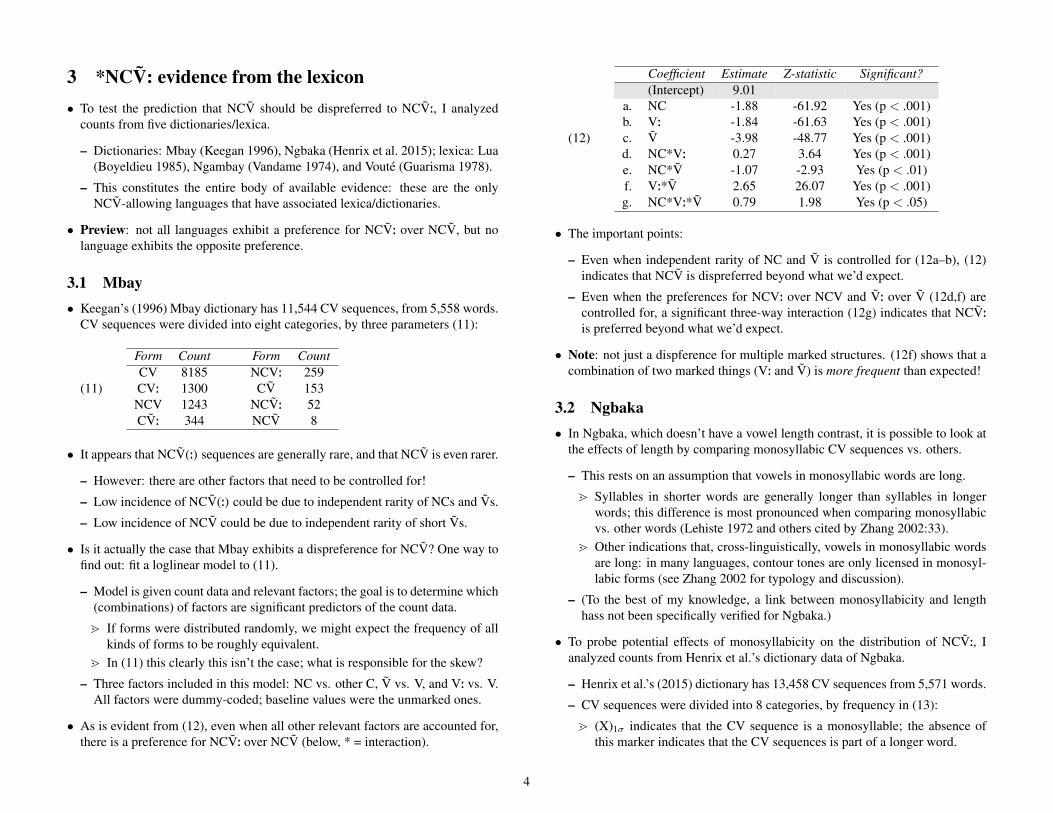
• As is evident from (12), even when all other relevant factors are accounted for,there is a preference for NCV: over NCV (below, * = interaction).
(12)
Coefficient Estimate Z-statistic Significant?(Intercept) 9.01
a. NC -1.88 -61.92 Yes (p < .001)b. V: -1.84 -61.63 Yes (p < .001)c. V -3.98 -48.77 Yes (p < .001)d. NC*V: 0.27 3.64 Yes (p < .001)e. NC*V -1.07 -2.93 Yes (p < .01)f. V:*V 2.65 26.07 Yes (p < .001)g. NC*V:*V 0.79 1.98 Yes (p < .05)
• The important points:
– Even when independent rarity of NC and V is controlled for (12a–b), (12)indicates that NCV is dispreferred beyond what we’d expect.
– Even when the preferences for NCV: over NCV and V: over V (12d,f) arecontrolled for, a significant three-way interaction (12g) indicates that NCV:is preferred beyond what we’d expect.
• Note: not just a dispference for multiple marked structures. (12f) shows that acombination of two marked things (V: and V) is more frequent than expected!
3.2 Ngbaka• In Ngbaka, which doesn’t have a vowel length contrast, it is possible to look at
the effects of length by comparing monosyllabic CV sequences vs. others.
– This rests on an assumption that vowels in monosyllabic words are long.
m Syllables in shorter words are generally longer than syllables in longerwords; this difference is most pronounced when comparing monosyllabicvs. other words (Lehiste 1972 and others cited by Zhang 2002:33).
m Other indications that, cross-linguistically, vowels in monosyllabic wordsare long: in many languages, contour tones are only licensed in monosyl-labic forms (see Zhang 2002 for typology and discussion).
– (To the best of my knowledge, a link between monosyllabicity and lengthhass not been specifically verified for Ngbaka.)
• To probe potential effects of monosyllabicity on the distribution of NCV:, Ianalyzed counts from Henrix et al.’s dictionary data of Ngbaka.
– Henrix et al.’s (2015) dictionary has 13,458 CV sequences from 5,571 words.
– CV sequences were divided into 8 categories, by frequency in (13):
m (X)1σ indicates that the CV sequence is a monosyllable; the absence ofthis marker indicates that the CV sequences is part of a longer word.
4

(13)
Form Count Form CountCV 9906 CV1σ 186NCV 1985 NCV1σ 168CV1σ 618 NCV1σ 13CV 570 NCV 12
• A loglinear model of the counts in (13) indicates that words containing NCVare better-tolerated when monosyllabic, i.e. when NCV is the entire word.
(14)
Coefficient Estimate Z-statistic Significant?(Intercept) 9.20
a. NC -1.61 -65.37 Yes (p < .001)b. 1σ -2.77 -66.92 Yes (p < .001)c. V -2.86 -66.29 Yes (p < .001)d. NC*1σ 0.31 3.37 Yes (p < .001)e. NC*V -2.25 -7.70 Yes (p < .001)f. 1σ*V 1.65 17.59 Yes (p < .001)g. NC*1σ*V 0.89 2.14 Yes (p < .05)
• The important points:
– These results directly mirror the Mbay results: distributions of NC, V, and Vinteract in the same ways with monosyllabicity as they do with vowel length.m For an easy-to-parse visualization, see Figure 1.m Dot = coefficient (or, strength and direction of effect). Bars = standard
error (measure of statistical accuracy). All effects are significant.– Vowel length and monosyllabicity are both proxies for duration.– The fact that they pattern together is predicted by the contrast-based account:
NCV is preferred when V is longer. It doesn’t matter if this length comesfrom being intrinsically long or from being part of a shorter word.
• Upshot: the Mbay and Ngbaka patterns are predicted by a contrast-based ac-count; a long V yields more time for cues to both N–NC and V–V to be realized.
3.3 Lua• So far, we’ve seen that Mbay and Ngbaka gradiently prefer NCV: to NCV.
– Do we find a language that allows NCV:, to the exclusion of NCV?
• Counts in Boyeldieu 1985:159 suggest that NCV: but not NCV is allowed.
(15)V V: V V:
NC 29 26 0 4Other C 310 125 24 43
Figure 1: Comparison of coefficient plots for Mbay and Ngbaka
NC
VV
VN
NC:VV
NC:VN
VV:VN
NC:VV:VN
-4 -2 0 2Value
Coefficient
Mbay Coefficient Plot
NC
MONO
VN
NC:MONO
NC:VN
MONO:VN
NC:MONO:VN
-3 -2 -1 0 1 2Value
Coefficient
Ngbaka Coefficient Plot
5

• Looking in more detail: all attested NCV: sequences are monosyllabic NCV:(but CV: sequences are more widely distributed).
(16)V V1σ V: V:1σ
NC 0 0 4 0Other C 13 11 30 13
• Why this is interesting: it appears that NCV sequences are only tolerated in Luain contexts where V is maximally long.
– Long nasal vowels (V:) are longer than short nasal vowels (V).– Vowels in monosyllabic words maybe longer than vowels in other words.
• A model of the data in (15) indicates however that lack of NCV can be explainedthrough the interaction of other factors (i.e. nasal vowels prefer to be long).4
(17)
Coefficient Estimate Z-statistic Significant?(Intercept) 5.04
a. NC -2.37 -12.20 Yes (p < .001)b. V -2.56 -12.08 Yes (p < .001)c. V: -0.89 -8.47 Yes (p < .001)d. NC:VN -17.24 -0.01 No (p > .05)e. NC*V: 0.78 2.70 Yes (p < .01)f. V*V: 1.48 5.35 Yes (p < .001)g. NC*VN*VV 16.45 0.01 No (p > .05)
• Interaction in (17e) indicates that NCs prefer to be followed by V:s; the prefer-ence for NCV: over NCV cannot be dissociated from a general length effect.
– Not just Lua: interaction is significant for all five corpora.– Why the length effect? Not sure. Pure speculation: maybe long oral vowels
help render NC maximally distinct from N.
4 Discussion and conclusions• This talk provided novel support for two predictions that a contrast-based anal-
ysis makes regarding the distribution of NCs.
– Any language that licenses NCV sequences must also license NCV.– Languages should prefer NCV: over NCV.
4A likelihood ratio test indicates that the model in (17) is not a significantly better fit to the datathan one that excludes the three-way interaction. Fisher’s Exact Tests also indicate that neither theabsence of NCV(:) nor the preference for NCV: over NCV is significant (p > .05 in both cases).
• Beyond this, there are other places to look for evidence that NCV is cross-linguistically dispreferred. . .
– In languages where NCs are typically analyzed as clusters.
m Stanton (2016b): the distributional properties of NCs are not dependent ontheir segment vs. cluster status; the same implicational laws apply.
m We then would expect that languages in which NCs are arguably clustersshould also display a dispreference for NCV(:), especially when V is short.
– In languages where NCs are followed by allophonically nasalized vowels.
m In many languages, NC1VNC2 is dispreferred.· Many languages eliminate the sequence by deleting C1; this alternation
is widely known as Meinhof’s Law (see e.g. Meeussen 1963).· Others delete N2; this is known as the Kwanyama law, but is found in
many Australian languages (see e.g. McConvell 1988).m Why? One explanation: in NC1VNC2, the vowel that intervenes between
the two NCs is nasalized, and renders NC1 insufficiently distinct from N.m Stanton (2016a): a contrast-based account of NC1VNC2 effects predicts a
large number of existing typological generalizations. For example:· *NCVNV→ *NC1VNC2. (Why? Vowels preceding non-prevocalic Ns
are in many languages more nasalized than vowels preceding prevocalicNs, meaning that N–NC1 might be more compromised in NC1VNC2.)· *NT1VNC2 → *ND1VNC2. (Why? NTs are likely more distinct from
Ns than are NDs, due to a longer, louder oral portion. N–NT is likelyless reliant on external cues, i.e. ∆ CV transitions, than is N–ND.)
m Predicted link: all languages that allow NCV should allow NC1VN(C)2.· Assumption: phonemically nasal vowels are more nasal than are allo-
phonically nasal vowels (e.g. Cohn 1990, de Medeiros 2011).· Prediction holds, for all NCV-allowing languages included in the survey.
• Main point: the evidence presented here provides evidence that constraints onthe distribution of NCs are constraints on contrast.
– By appealing to the contexts in which NCs are more or less distinct from theircomponent parts, we can predict generalizations regarding their distribution.
– Part of a much larger body of evidence pointing towards this conclusion.
6

ReferencesAdu Manyah, Kofi (2003). Vowel Quantity Contrasts in Twi. Sole, M.J., D. Recasens &
J. Romero (eds.), Proceedings of the 15th International Congress of Phonetic Sci-ences, Universitat Autonoma de Barcelona, 3185–3188.
Beddor, Patrice S. & Chutamanee Onsuwan (2003). Perception of prenasalized stops. Sole,M.J., D. Recasens & J. Romero (eds.), Proceedings of the 15th International Congressof Phonetic Sciences, Universitat Autonoma de Barcelona, 407–410.
Boyeldieu, Pascal (1975). Etudes yakoma: langue du groupe Oubangien (R.C.A.) ; mor-phologie - synthematique ; notes linguistiques. SELAF, Paris.
Boyeldieu, Pascal (1985). La langue lua (‘niellim’). Cambridge University Press.Burton, Martha, Sheila Blumstein & Kenneth N. Stevens (1992). A phonetic analysis of
prenasalized stops in Moru. Journal of Phonetics 20, 127–142.Cohn, Abigail C. (1990). Phonetic and Phonological Rules of Nasalization. UCLA Working
Papers in Phonetics, 76, Phonetics Laboratory, Department of Linguistics, Universityof California, Los Angeles.
Cohn, Abigail C. & Anastasia K. Riehl (2012). The internal structure of nasal-stop se-quences: Evidence from Austronesian. Butler, Becky & Margaret E. L. Renwick(eds.), Cornell Working Papers in Phonetics and Phonology, vol. 3.
Crowley, Terry (2006a). The Avava language of central Malakula (Vanuatu). Pacific Lin-guistics.
Crowley, Terry (2006b). Naman: a vanishing language of Malakula (Vanuatu). PacificLinguistics.
Davies, H. John (1980). Kobon phonology. Pacific Linguistics Series B, No. 87, Canberra:Australian National University.
Delattre, Pierre & Michel Monnot (1968). The role of duration in the identification ofFrench nasal vowels. International Review of Applied Linguistics in Language Teach-ing 6, 267–288.
Durie, Mark (1985). A grammar of Acehnese on the basis of a dialect of north Aceh. ForisPublications, Leiden.
Endresen, Rolf Thiel (1991). Diachronic aspects of the phonology of Nizaa. Journal ofAfrican languages and linguistics 12, 171–194.
Everett, Daniel Leonard & Barbara Kern (1997). Wari: the Pacaas Novos Language ofWestern Brazil. Routledge, London.
Flemming, Edward (2002). Auditory Representations in Phonology. New York: Routledge.Gordon, Matthew & Ian Maddieson (1999). The phonetics of Ndumbea. Oceanic Linguis-
tics 38, 66–90.Gordon, Matthew J. & Ian Maddieson (2004). The phonetics of Paici vowels. Oceanic
Linguistics 43, 296–310.Guarisma, Gladys (1978). Etudes voute: langue bantoıde du Cameroun: phonologie et
alphabet pratique, synthematique, lexique voute-francais. SELAF.Hagege, Claude (1970). La langue mbum de Nganha (Cameroun): phonologie, grammaire.
SELAF.Henrix, Marcel, Michael Meeuwis & Peter Vanhoutte (2015). Dictionnaire ngbaka-
francais. LINCOM, Muenchen.Jung, Ingrid (2008). Gramatica del paez o nasa yuwe: descripcion de una lengua indıgena
de Colombia. Lincom Europa, Munchen.
Kaplan, Abby (2008). Markedness and phonetic grounding in nasal-stop clusters. Ms.,UCSC.
Keegan, John M. (1996). Dictionary of Mbay. Lincom Europa, Munchen/Newcastle.Keegan, John M. (1997). A reference grammar of Mbay. Lincom Europa, Munchen.Lehiste, Ilse (1972). Timing of utterances and linguistic boundaries. Journal of the Acous-
tical Society of America 51, 2108–2124.Lynch, John (2002). Cemuhı. Lynch, John, Malcolm Ross & Terry Crowley (eds.), The
Oceanic Languages, Curzon Press, 753–764.Maddieson, Ian (1984). Patterns of sounds. Cambridge University Press, Cambridge.Maddieson, Ian & Peter Ladefoged (1993). Partially nasal consonants. Huffman, Marie &
Rena Krakow (eds.), Nasals, Nasalization, and the Velum, Academic Press, 251–301.McConvell, Patrick (1988). Nasal cluster dissimilation and constraints on phonological
variables in Gurundji and related languages. Aboriginal linguistics 1, 135–165.McWhorter, John & Jeff Good (2012). A grammar of Saramaccan Creole, vol. 56. Walter
de Gruyter, Berlin.de Medeiros, Beatriz Raposo (2011). Nasal Coda and Vowel Nasality in Brazilian Por-
tuguese. Alvord, Scott M. (ed.), Selected Proceedings of the 5th Conference onLaboratory Approaches to Romance Phonology, Cascadilla Proceedings Project,Somerville, MA, 33–45.
Meeussen, Achille E. (1963). Meinhof’s Rule in Bantu. African Language Studies 3, 25–29.Michailovsky, Boyd (2003). Hayu. Thurgood, Graham & Randy J. LaPolla (eds.), The
Sino-Tibetan Languages, Routledge, London and New York, 518–532.Monino, Yves & Paulette Roulon (1972). Phonologie du gbaya kara ‘bodoe de Ndongue
Bongowen, region de Bouar, Republique centrafricaine. SELAF.Moore, Denny, Sidney Facundes & Nadia Pires (1993). Nheengatu (Lıngua Geral
Amazonica), its History, and the Effects of Language Contact. Museu Paraense EmılioGoeldi, Brazil.
Moser, Rosmarie (2004). Kabba: A Nilo-Saharan Language of the Central African Repub-lic. No. 43 in LINCOM Studies in African Linguistics, Lincom Europa, Munchen.
Nougayrol, Pierre (1979). Le day de Bouna (Tchad). SELAF, Paris.Oliveira, Christiane Kuna de (2005). Language of the Apinaje people of Central Brazil.
Ph.D. thesis, University of Oregon.Osumi, Midori (1995). Tinrin Grammar. University of Hawai’i Press, Honolulu.Padgett, Jaye (2003). The Emergence of Contrastive Palatalization in Russian. Holt, D. Eric
(ed.), Optimality Theory and Language Change, Kluwer Academic Publishers, Dor-drecht.
Riehl, Anastasia K. (2008). The phonology and phonetics of nasal obstruent sequences.Ph.D. thesis, Cornell University.
Rojas Curieux, Tulio (1998). La lengua paez: una vision de su gramatica. Bogota: Minis-terio de cultura.
Samarin, William (1966). The Gbeya Language: Grammar, Texts, and Vocabularies. Uni-versity of California Press.
Samarin, William J. (1967). A Grammar of Sango. Mouton & Co., The Hague / Paris.Sharpe, Margaret C. (1972). Alawa phonology and grammar. Australian Institute of Abo-
riginal Studies.Silverman, Daniel, Barbara Blankenship, Paul Kirk & Peter Ladefoged (1995). Phonetics
structures in Jalapa Mazatec. Anthropological Linguistics 37, 70–88.
7

Stanton, Juliet (2016a). Effects of allophonic nasalization on NC clusters: a contrast-basedaccount. To appear in NELS 46 Proceedings.
Stanton, Juliet (2016b). Predicting distributional restrictions on prenasalized stops. NaturalLanguage and Linguistic Theory 34, 1089–1133.
Stanton, Juliet (in prep). Constraints on the distribution of nasal-stop sequences.Steriade, Donca (1997). Phonetics in Phonology: The Case of Laryngeal Neutralization.
Ms., University of California, Los Angeles.Thomas, Jacqueline (1963). Le parler ngbaka de Bokanga. Mouton, Paris.Vandame, Charles (1963). Le Ngambay-Moundou: phonologie, grammaire et textes. IFAN.Vandame, Charles (1974). Manuel d’initiation au ngambay. Librairie Notre Dame,
N’Djamena.Welmers, William Everett (1976). A grammar of Vai, vol. 84. University of California
Press, L.A.Whalen, D. H. & Patrice S. Beddor (1989). Connections between Nasality and Vowel Du-
ration and Height: Elucidation of the Eastern Algonquian Intrusive Nasal. Language65, 457–468.
Yoshida, Shohei (1990). A Government-Based Analysis of the ’Mora’ in Japanese. Phonol-ogy 7, 331–351.
Zhang, Jie (2002). The effects of duration and sonority on contour tone distribution. Rout-ledge.
8












![Guaraní Voiceless Stops in Oral versus Nasal Contexts: An ...linguistics.ucla.edu/.../hayes/251VowelHarmony/Readings/Walker_Gu… · duration of voicelessness of the stops [p, t]](https://static.fdocuments.us/doc/165x107/5ead503e6f414f5ae628d2fa/guaran-voiceless-stops-in-oral-versus-nasal-contexts-an-duration-of-voicelessness.jpg)





