
Creating an ArcGIS Engine Application With C-Sharp and OpenGL
Upload
mahendra-kariyaCategory
view
2.007download
0
Information Retrieval:Creating a Search
Engine

Agenda• Introduction
• Basic Text Processing
• IR Basics
• Term Frequency Weighting
• Inverse Document Frequency Weighting
• TF – IDF Score
• Activity

Agenda• Introduction
• Basic Text Processing
• IR Basics
• Term Frequency Weighting
• Inverse Document Frequency Weighting
• TF – IDF Score
• Activity

IntroductionInformation Retrieval (IR) is finding material (usually documents) of an unstructured nature (usually text) that satisfies an information need from within large collections.
- C Manning, P Raghavan, Hinrich

Agenda• Introduction
• Basic Text Processing
• IR Basics
• Term Frequency Weighting
• Inverse Document Frequency Weighting
• TF – IDF Score
• Activity

Basic Text Processing
Word Tokenization:(Dividing a sentence into words.)
• Hey, where have you been last week?
• I flew from New York to Illinois and finally landed in Jammu & Kashmir.
• Long Journey, huh?

Issues in Tokenization
• New York One Token or Two?
• Jammu & Kashmir One Token or Three?
• Huh, Hmmm, Uh ??
• India’s Economy India? Indias? India’s?
• Won’t, isn’t Will not? Is not? Isn’t?
• Mother-in-law Mother in Law?
• Ph.D. PhD? Ph D ? Ph.D.?

Language Issues in Tokenization
German Noun Compounds are not segmented
• Lebensversicherungsgesellschaftsangesteller
• ‘life insurance company employee’
Example from Foundations of Natural Language Processing; C. Manning, Henrich S

Language Issues in Tokenization
• There is no space between words in Chinese and Japanese.
• In Japanese, multiple alphabets are intermingled.
• Arabic (or Hebrew) is basically written right to left, but certain items like numbers are written left to right.

Regular Expressions
• Regular Expressions are a way to represent patterns in text.

Regular Expressions
• Regular Expressions are a way to represent patterns in text.

Agenda• Introduction
• Basic Text Processing
• IR Basics
• Term Frequency Weighting
• Inverse Document Frequency Weighting
• TF – IDF Score
• Activity

Basic Search Model
User Needs Info
Query
ResultsQuery Refining

IR System Evaluation
• Precision: How many documents retrieved are relevant to user’s information need?
• Recall: How many relevant documents in collection are retrieved?
• F Score: Harmonic Mean of precision and recall

Ranked IR
• How to rank the retrieved documents?
• We assign a score to each document.
• This score should measure how good is the “query – document” pair.

Agenda• Introduction
• Basic Text Processing
• IR Basics
• Term Frequency Weighting
• Inverse Document Frequency Weighting
• TF – IDF Score
• Activity

• We need a way to assign score to each “query – document” pair.
• More frequent the query term in the document, the higher should be the score.
• If a query term doesn’t occur in document: score should be 0.

Term FrequencyHitchhiker’s
Guide to Galaxy
Last Chance to
See
Life, Universe & Everything
Restaurant at End of Universe
So Long &Thanks for all the Fish
Starship Titanic
galaxy 62 0 51 49 24 29
zaphod 214 0 88 405 2 0
ship 59 2 85 126 27 119
arthur 347 0 376 236 313 0
fiordland 0 9 0 0 0 0
santorini 0 0 3 0 0 0
wordlings 0 0 0 0 1 0

Term Frequency
• How to use tf for computing the query-document match score?
• A document with 85 occurrences of a term is more relevant than a document with 1 occurrences.
• But NOT 85 times more relevant!
• Relevance don’t increase linearly with frequency!
• Raw term frequency will not help!

Log-tf Weighting
• Log term frequency weight of term t in document d is
wt,d = 1 + log10tf , if tf > 00 , if tf <= 0

tf Score
Sq,d =∑t in q∩d 1 + log10tf

Term FrequencyHitchhiker’s
Guide to Galaxy
Last Chance to
See
Life, Universe & Everything
Restaurant at End of Universe
So Long &Thanks for all the Fish
Starship Titanic
galaxy 62 0 51 49 24 29
zaphod 214 0 88 405 2 0
ship 59 2 85 126 27 119
arthur 347 0 376 236 313 0
fiordland 0 9 0 0 0 0
santorini 0 0 3 0 0 0
wordlings 0 0 0 0 1 0

Term Frequency Weight
Hitchhiker’s Guide to Galaxy
Last Chance to
See
Life, Universe & Everything
Restaurant at End of Universe
So Long &Thanks for all the Fish
Starship Titanic
galaxy 2.79 0 2.71 2.69 2.38 2.46
zaphod 3.33 0 2.94 3.61 1.30 0
ship 2.77 1.30 1.93 3.10 2.43 3.08
arthur 3.54 0 3.58 3.37 3.50 0
fiordland 0 1.95 0 0 0 0
santorini 0 0 1.47 0 0 0
wordlings 0 0 0 0 1.00 0

Term Frequency
• Problem: all terms are considered equally important.
• Certain terms are of no use when determining relevance.

Term Frequency
• Rare terms are more informative than frequent terms in the document. information retrieval
• Frequent terms are less informative than rare terms (eg man, house, cat)
• Document containing frequent term is likely to be relevant But relevance is not guaranteed.
• Frequent terms should get +ve weights, but lower than rare terms.

Agenda• Introduction
• Basic Text Processing
• IR Basics
• Term Frequency Weighting
• Inverse Document Frequency Weighting
• TF – IDF Score
• Activity

Document Frequency
• We use document frequency (df)
• dft is the number of documents in the collection that contains the term t.
• Lower the dft, rarer is the term, and higher the importance.

Inverse Document Frequency
• We take inverse document frequency (idf) of t
idft = log10(N/dft)
• N is the number of documents in the collection

idf exampledf idf
1 7
10 6
100 5
1000 4
10000 3
100000 2
1000000 1
10000000 0
idft = log10(N/dft), suppose N = 107
There is only one value for each term in the collection.

idf weightsTerm df idf
galaxy 5 0.079
zaphod 4 0.176
ship 6 0
arthur 4 0.176
fiordland 1 0.778
santorini 1 0.778
wordlings 1 0.778
idft = log10(N/dft), here N = 6

Agenda• Introduction
• Basic Text Processing
• IR Basics
• Term Frequency Weighting
• Inverse Document Frequency Weighting
• TF – IDF Score
• Activity

tf-idf Weighting
• tf-idf weight is simple the product of tf and idfweight.
Wt,d = (1 + log10 tft,d) x log10(N/dft)
• Increases with number of occurrences within document.
• Increases with rarity of term in collection.

tf-idf Score
• Final ranking of a document d for a query q depends on
Score(q,d) =∑ Wt,d

Term Frequency WeightHitchhiker’s
Guide to Galaxy
Last Chance to
See
Life, Universe & Everything
Restaurant at End of Universe
So Long &Thanks for all the Fish
Starship Titanic
galaxy 2.79 0 2.71 2.69 2.38 2.46
zaphod 3.33 0 2.94 3.61 1.30 0
ship 2.77 1.30 1.93 3.10 2.43 3.08
arthur 3.54 0 3.58 3.37 3.50 0
fiordland 0 1.95 0 0 0 0
santorini 0 0 1.47 0 0 0
wordlings 0 0 0 0 1.00 0

idf weightsTerm df idf
galaxy 5 0.079
zaphod 4 0.176
ship 6 0
arthur 4 0.176
fiordland 1 0.778
santorini 1 0.778
wordlings 1 0.778
idft = log10(N/dft), here N = 6
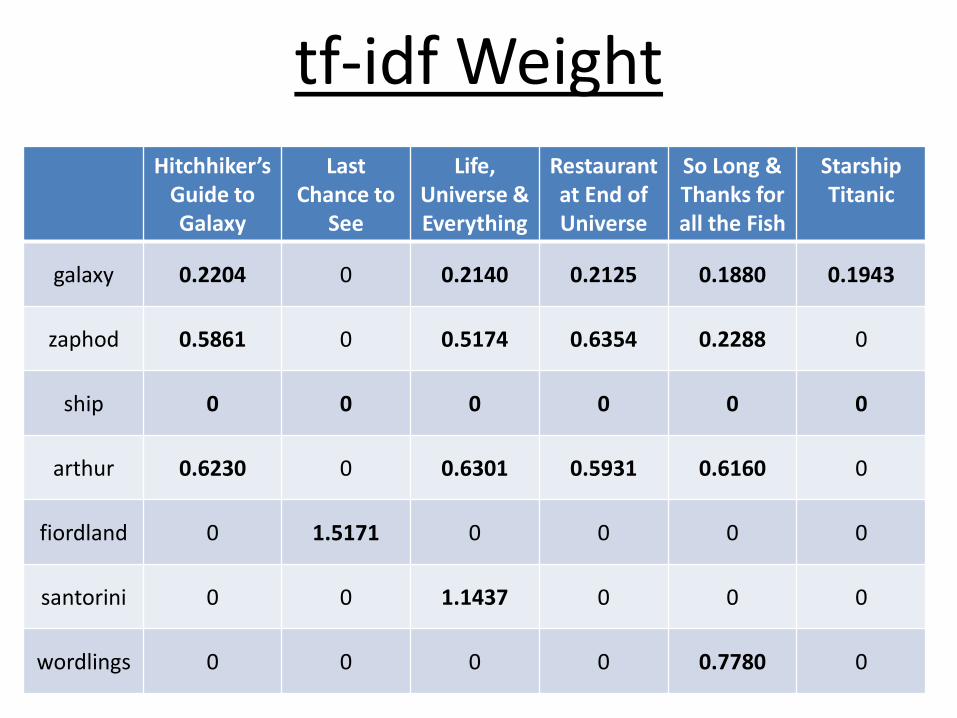
tf-idf WeightHitchhiker’s
Guide to Galaxy
Last Chance to
See
Life, Universe & Everything
Restaurant at End of Universe
So Long &Thanks for all the Fish
Starship Titanic
galaxy 0.2204 0 0.2140 0.2125 0.1880 0.1943
zaphod 0.5861 0 0.5174 0.6354 0.2288 0
ship 0 0 0 0 0 0
arthur 0.6230 0 0.6301 0.5931 0.6160 0
fiordland 0 1.5171 0 0 0 0
santorini 0 0 1.1437 0 0 0
wordlings 0 0 0 0 0.7780 0

Agenda• Introduction
• Basic Text Processing
• IR Basics
• Term Frequency Weighting
• Inverse Document Frequency Weighting
• TF – IDF Score
• Activity: Spelling Correction

Using a Dictionary
• How to tell if a word’s spelling is correct or not?
• Maybe, use a dictionary? Like Oxford’s Dictionary
• Then what about terms like “Accenture” or “Brangelina” or “Paani da Rang”?
• Any dictionary definitely doesn’t contain words like this.
• Such terms will be flagged as spelling errors. But this should not be the case!

Using a Corpus
• So, we use a collection of documents.
• This collection is used as a basis for spell correction.
• To correct the spelling
we find a word in the collection which is nearest to the wrongly spelled word.
Replace the wrong word with the new word we just found.

Minimum Edit Distance
• Minimum number of edit operations Insertion (add a letter)
Deletion (remove one letter)
Substitution (change one letter to another)
Transposition (swap adjacent letters)
needed to transform one word into the other.

Minimum Edit Distance (Example)
* B I O G R A P H Y
A U T O G R A P H *
i s s d
• Let cost of each operation be 1
Total edit distance between these words = 4

Spelling Correction
• For a given word, find all words at edit distance 1 and 2.
• Which of these words is the most likely spelling correction for the given word?
• The one that occurs the maximum time in the corpus. That’s the answer!

Minimum Edit Distance
• Finding all words at edit distance 1, will result in a huge collection.
• For a word of length n, Insertions: 26(n + 1)
Deletions: n
Substitution: 26n
Transposition: n – 1
TOTAL: 54n + 25
• Few of these might be duplicates
• Number of words at edit distance 2 will be obviously more than 54n + 25.

Complete Algorithm
1. Calculate the frequency of each word in the corpus.
2. Input a word to be corrected.
3. If input word is present in corpus, return that word.
4. Else, find all words at an edit distance 1 and 2.
5. Among these words, return the word which occurs the
maximum time in the corpus.
6. If none of these words occur in corpus, return the original word.

Evaluation
number of words successfully corrected
number of input wordsAccuracy =

You’re Given
• A collection of documents (corpus) Public domain books from Project Gutenberg
List of most frequent words from Wikitionary
British National Corpus
put together by Peter Norvig.
• Starter code in Java, Python and C# Contains code for reading corpus and calculating accuracy.
• A test set from Roger Mitton’s Birckbeck Spelling Error Corpus (slightly modified) To test your algorithm.

TODO
• Implement the algorithm in Java, Python or C#
Successful implementation will result in accuracy of ~31.50%
• Modify the given algorithm to increase the accuracy to 50%
• Going beyond 50% for the given test set is a bit challenging task.

Information Retrieval:
1. http://nlp.stanford.edu/fsnlp/
2. http://nlp.stanford.edu/IR-book/
3. https://class.coursera.org/nlp/class/index
4. http://en.wikipedia.org/wiki/Tf*idf
5. http://www.stanford.edu/class/cs276/handouts/lecture6-tfidf.ppt
6. http://research.google.com/pubs/InformationRetrievalandtheWeb.html
7. http://norvig.com/
8. http://nlp.stanford.edu/IR-book/html/htmledition/scoring-term-weighting-and-the-vector-space-model-1.html
9. http://ocw.mit.edu/courses/electrical-engineering-and-computer-science/6-864-advanced-natural-language-processing-fall-2005/index.htm
10. http://www.slideshare.net/butest/search-engines-3859807
Further Reading

Spelling Correction:
1. http://acl.ldc.upenn.edu/D/D07/D07-1090.pdf
2. http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.49.1392
3. http://www.stanford.edu/class/cs276/handouts/spelling.pptx
4. http://alias-i.com/lingpipe/demos/tutorial/querySpellChecker/read-me.html
5. http://portal.acm.org/citation.cfm?id=146380
6. http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.18.9400
7. http://static.googleusercontent.com/external_content/untrusted_dlcp/research.google.com/en/us/pubs/archive/36180.pdf
8. http://citeseerx.ist.psu.edu/viewdoc/download;jsessionid=52A3B869596656C9DA285DCE83A0339F?doi=10.1.1.146.4390&rep=rep1&type=pdf
Further Reading















![[Snia 2013] indexing and retrieval engine wahyu hidayat](https://static.fdocuments.us/doc/165x107/55ba5b8bbb61eb1c348b47da/snia-2013-indexing-and-retrieval-engine-wahyu-hidayat.jpg)


