Improving the descriptors extracted from the co-occurrence...
12
Expert Systems With Applications 42 (2015) 8989–9000 Contents lists available at ScienceDirect Expert Systems With Applications journal homepage: www.elsevier.com/locate/eswa Improving the descriptors extracted from the co-occurrence matrix using preprocessing approaches Loris Nanni a,∗ , Sheryl Brahnam b , Stefano Ghidoni a , Emanuele Menegatti a a Department of Information Engineering, University of Padua, Via Gradenigo, 6, 35131 Padova, Italy b Department of Computer Information Systems, Missouri State University, 901 S. National, Springfield, MO 65804, USA article info Keywords: Co-occurrence matrix Texture descriptors Preprocessing Local approaches Multi-scale abstract In this paper, we investigate the effects that different preprocessing techniques have on the performance of features extracted from Haralick’s co-occurrence matrix, one of the best known methods for analyzing image texture. In addition, we compare and combine different strategies for extracting descriptors from the co- occurrence matrix. We propose an ensemble of different preprocessing methods, where, for each descriptor, a given Support Vector Machine (SVM) classifier is trained. The set of classifiers is then combined by weighted sum rule. The best result is obtained by combining the extracted descriptors using the following preprocess- ing methods: wavelet decomposition, local phase quantization, orientation, and the Weber law descriptor. Texture descriptors are extracted from the entire co-occurrence matrix, as well as from sub-windows, and evaluated at multiple scales. We validate our approach on eleven image datasets representing different im- age classification problems using the Wilcoxon signed rank test. Results show that our approach improves the performance of standard methods. All source code for the approaches tested in this paper will be available at: https://www.dei.unipd.it/node/2357 © 2015 Elsevier Ltd. All rights reserved. 1. Introduction Medical imaging is experiencing rapid technological develop- ments and, as a result, is producing unprecedented amounts of data that are now being warehoused in specialized medical re- search databases around the world 1 . It is generally agreed that these databases contain information that, if appropriately harnessed, could potentially revolutionize scientific knowledge in medicine. What is needed to make this dream a reality is the development of more so- phisticated and robust machine vision algorithms. Texture analysis is essential for many image classification tasks. Some of the best-performing methods rely on features that encap- sulate specific information about the elementary characteristics inherent in a given input image. A feature extractor algorithm ob- tains a vector of numbers, called a “descriptor”, from an image that provides a specific description of that image. Features that are widely used in the computer vision and robotics communities include the Scale-Invariant Feature Transform (SIFT) (Lowe, 2004), Speeded Up ∗ Corresponding author. Tel.: +39 3493511673. E-mail addresses: [email protected], [email protected] (L. Nanni), sbrahnam@ missouristate.edu (S. Brahnam), [email protected] (S. Ghidoni), [email protected] (E. Menegatti). 1 For instance, Biograph, mGen, PathogenPortal, and ConsensusPathDB Robust Feature (SURF) (Bay, Tuytelaars, & Gool, 2006), Histogram of Oriented Gradients (HOG) (Dalal & Triggs, 2005), Gradient Location and Orientation Histogram (GLOH) (Mikolajczyk & Schmid, 2005), Region Covariance Matrix (RCM) (Tuzel, Porikli, & Meer, 2006), Edgelet (Wu & Nevatia, 2005), Gray Level Co-occurrence Matrix (GLCM) (Haralick, Shanmugam, & Dinstein, 1973), Local Binary Patterns (LBP) (Ojala, Pietikäinen, & Harwood, 1996), non-binary encodings (Paci, Nanni, Lathi, Aalto-Setälä, & Hyttinen, 2013), Color CorreloGram (CCG) (Huang, Kumar, Mitra, Zhu, & Zabih, 1997), Color Coherence Vectors (CCV) (Pass, Zabih, & Miller, 1996), color indexing (Swain & Ballard, 1991), steerable filters (Freeman & Adelson, 1991), and Gabor filters (Jain & Farrokhnia, 1991). An especially powerful feature extractor is the Local Binary Pattern (LBP) operator (Ojala, Pietikainen, & Maeenpaa, 2002), which stands out because of its simplicity, effectiveness, and robustness. It has proven to be a powerful discriminator in a number of im- age classification problems, e.g., in discriminating endoscopical images of pediatric celiac diseases (Vécsei, Amann, Hegenbart, Liedlgruber, & Uhl, 2011) and in distinguishing real masses from normal parenchyma in mammographic images (Oliver, Lladó, Freixenet, & Martí, 2007). LBP is also useful in data mining, where it has been combined with other descriptors, for instance, to classify brain magnetic resonance data (Unay & Ekin, 2008) and different cell phenotypes (Nanni & Lumini, 2008). http://dx.doi.org/10.1016/j.eswa.2015.07.055 0957-4174/© 2015 Elsevier Ltd. All rights reserved.
Transcript of Improving the descriptors extracted from the co-occurrence...

Expert Systems With Applications 42 (2015) 8989–9000
Contents lists available at ScienceDirect
Expert Systems With Applications
journal homepage: www.elsevier.com/locate/eswa
Improving the descriptors extracted from the co-occurrence matrix
using preprocessing approaches
Loris Nanni a,∗, Sheryl Brahnam b, Stefano Ghidoni a, Emanuele Menegatti a
a Department of Information Engineering, University of Padua, Via Gradenigo, 6, 35131 Padova, Italyb Department of Computer Information Systems, Missouri State University, 901 S. National, Springfield, MO 65804, USA
a r t i c l e i n f o
Keywords:
Co-occurrence matrix
Texture descriptors
Preprocessing
Local approaches
Multi-scale
a b s t r a c t
In this paper, we investigate the effects that different preprocessing techniques have on the performance of
features extracted from Haralick’s co-occurrence matrix, one of the best known methods for analyzing image
texture. In addition, we compare and combine different strategies for extracting descriptors from the co-
occurrence matrix. We propose an ensemble of different preprocessing methods, where, for each descriptor,
a given Support Vector Machine (SVM) classifier is trained. The set of classifiers is then combined by weighted
sum rule. The best result is obtained by combining the extracted descriptors using the following preprocess-
ing methods: wavelet decomposition, local phase quantization, orientation, and the Weber law descriptor.
Texture descriptors are extracted from the entire co-occurrence matrix, as well as from sub-windows, and
evaluated at multiple scales. We validate our approach on eleven image datasets representing different im-
age classification problems using the Wilcoxon signed rank test. Results show that our approach improves the
performance of standard methods. All source code for the approaches tested in this paper will be available
at: https://www.dei.unipd.it/node/2357
© 2015 Elsevier Ltd. All rights reserved.
1
m
d
s
d
p
n
p
S
s
i
t
p
u
S
m
(
R
O
a
R
E
(
P
e
C
C
(
a
P
s
I
a
i
h
0
. Introduction
Medical imaging is experiencing rapid technological develop-
ents and, as a result, is producing unprecedented amounts of
ata that are now being warehoused in specialized medical re-
earch databases around the world1. It is generally agreed that these
atabases contain information that, if appropriately harnessed, could
otentially revolutionize scientific knowledge in medicine. What is
eeded to make this dream a reality is the development of more so-
histicated and robust machine vision algorithms.
Texture analysis is essential for many image classification tasks.
ome of the best-performing methods rely on features that encap-
ulate specific information about the elementary characteristics
nherent in a given input image. A feature extractor algorithm ob-
ains a vector of numbers, called a “descriptor”, from an image that
rovides a specific description of that image. Features that are widely
sed in the computer vision and robotics communities include the
cale-Invariant Feature Transform (SIFT) (Lowe, 2004), Speeded Up
∗ Corresponding author. Tel.: +39 3493511673.
E-mail addresses: [email protected], [email protected] (L. Nanni), sbrahnam@
issouristate.edu (S. Brahnam), [email protected] (S. Ghidoni), [email protected]
E. Menegatti).1 For instance, Biograph, mGen, PathogenPortal, and ConsensusPathDB
L
n
F
h
b
p
ttp://dx.doi.org/10.1016/j.eswa.2015.07.055
957-4174/© 2015 Elsevier Ltd. All rights reserved.
obust Feature (SURF) (Bay, Tuytelaars, & Gool, 2006), Histogram of
riented Gradients (HOG) (Dalal & Triggs, 2005), Gradient Location
nd Orientation Histogram (GLOH) (Mikolajczyk & Schmid, 2005),
egion Covariance Matrix (RCM) (Tuzel, Porikli, & Meer, 2006),
dgelet (Wu & Nevatia, 2005), Gray Level Co-occurrence Matrix
GLCM) (Haralick, Shanmugam, & Dinstein, 1973), Local Binary
atterns (LBP) (Ojala, Pietikäinen, & Harwood, 1996), non-binary
ncodings (Paci, Nanni, Lathi, Aalto-Setälä, & Hyttinen, 2013), Color
orreloGram (CCG) (Huang, Kumar, Mitra, Zhu, & Zabih, 1997), Color
oherence Vectors (CCV) (Pass, Zabih, & Miller, 1996), color indexing
Swain & Ballard, 1991), steerable filters (Freeman & Adelson, 1991),
nd Gabor filters (Jain & Farrokhnia, 1991).
An especially powerful feature extractor is the Local Binary
attern (LBP) operator (Ojala, Pietikainen, & Maeenpaa, 2002), which
tands out because of its simplicity, effectiveness, and robustness.
t has proven to be a powerful discriminator in a number of im-
ge classification problems, e.g., in discriminating endoscopical
mages of pediatric celiac diseases (Vécsei, Amann, Hegenbart,
iedlgruber, & Uhl, 2011) and in distinguishing real masses from
ormal parenchyma in mammographic images (Oliver, Lladó,
reixenet, & Martí, 2007). LBP is also useful in data mining, where it
as been combined with other descriptors, for instance, to classify
rain magnetic resonance data (Unay & Ekin, 2008) and different cell
henotypes (Nanni & Lumini, 2008).

8990 L. Nanni et al. / Expert Systems With Applications 42 (2015) 8989–9000
p
O
u
l
c
e
s
t
w
p
f
a
i
c
d
e
d
e
m
a
a
a
e
c
w
b
o
I
c
e
o
w
e
t
t
a
e
w
t
a
2
w
H
d
This paper is a continuation of our research group’s previous
explorations (Nanni, Brahnam, Ghidoni, & Menegatti, 2013d; Nanni,
Brahnam, Ghidoni, Menegatti, & Barrier, 2013b; Nanni, Ghidoni,
& Menegatti, 2013c; Nanni, Paci, Brahnam, Ghidoni, & Menegatti,
2013a) for improving one of the first methods for analyzing texture,
the GLCM, which was first proposed by Haralick, (1979) for analyzing
satellite images. The GLCM is one of the most studied and most
extensively used texture analysis techniques: its application ranges
from visual inspection for industrial production (Zhao et al., 2014) to
analysis of microscopy imagery (Pantic et al., 2014). An alternative
version of the co-occurrence matrix capable of dealing with color
is proposed in Subrahmanyam, Wu, Maheshwari, and Balasubra-
manian (2013); the formulation they offer takes into account the
inter-correlation between the different color channels of a RGB
(Red-Green-Blue) color image.
The GLCM is usually analyzed by means of a set of descriptors,
commonly referred to as Haralick descriptors, that are evaluated by
means of a process that provides a single value for each single de-
scriptor starting from the whole matrix (as it happens when mean
and variance are evaluated from a probability distribution). Within
the last few years, the GLCM has become the focus of several re-
search groups whose aim is to discover novel methods for extract-
ing yet more information from the GLCM. Some important work in
this area includes that of Gelzinis, Verikas, & Bacauskiene (2007),
where different values of the distance parameter influencing the
GLCM are considered; (Walker, Jackway, & Longstaff, 2003), where
features are extracted from areas presenting high discrimination us-
ing the weighted summation of GLCM elements; (Chen, Chengdong,
Chen, & Tan, 2009), where descriptors are obtained from the gray
level-gradient co-occurrence matrix by calculating the gradient value
of each pixel in the neighborhood of interest points; and (Mitrea,
Mitrea, Nedevschi, Badea, & Lupsor, 2012), where the GLCM is com-
bined with the edge orientation co-occurrence matrix of superior or-
der (see, Akono, Tankam, & Tonye, 2005) by taking into considera-
tion the gray levels of the image pixels and some local features such
as edges. In addition, multi-scale analysis has been performed using
the GLCM, where descriptors are extracted from each rescaling opera-
tion. For instance, in Rakwatin, Longepe, Isoguchi, Shimada, and Uryu
(2010) the image is rescaled to different sizes, and in Hu, (2009) and
Pacifici and Chini (2008) multiple scales are investigated by chang-
ing the window size used to extract GLCM descriptors. In some very
recent work, LBP has been combined with the GLCM. In Sastry, Ku-
mari, Rao, Mallika, and Lakshminarayana (2012), for instance, the
GLCM is constructed after applying LBP to the image, and features
are extracted from second-order statistical parameters from the re-
sulting matrix. In Sun, Wang, Chen, She, and Kong (2012), GLCM is
constructed from an LBP image produced after the application of a
Gaussian filtering pyramid preprocessing step.
A major difficulty encountered when analyzing texture is the
strong dependency some texture analysis methods have on image
resolution and scale. Several researchers have recently reported the
effectiveness of combining more than one multi-scale approach
along with LBP descriptors to overcome this problem (see, for in-
stance, Ren, Wang, & Zhao, 2012). In Nanni et al. (2013c) and Nanni
et al. (2013d), our group applied this idea to the co-occurrence
matrix, demonstrating that results can be enhanced when different
descriptors extracted from the co-occurrence matrix are combined
with a multi-scale approach.
In addition to combine the GLCM with texture descriptors and the
multi-scale approach, our main intention in this paper is to com-
pare and to combine (for the first time) the application of differ-
ent preprocessing techniques to each image before calculating the
co-occurrence matrix. An extensive study comparing and combining
preprocessing methods with the GLCM is important in order to clar-
ify which combinations of methods offer the best performance gain
using a system based on the co-occurrence matrix. The different pre-
rocessing methods explored in this paper are detailed in Section 3.
ur best result is obtained by combining extracted GLCM descriptors
sing the following preprocessing methods: wavelet decomposition,
ocal phase quantization, orientation, and the Weber law descriptor.
As in our previous work (Nanni et al., 2013b) (which did not in-
lude preprocessing methods), we utilize the following methods for
xtracting features:
• The standard approach proposed by Haralick (1979);• A set of 3D features that consider the co-occurrence matrix as a
3D shape (Nanni et al., 2013c);• Gray-level run-length features (Tang, 1998), that consider groups
of consecutive pixels with the same gray level, and measure their
lengths. In this paper, the gray-level run-length features (GL) are
evaluated on the GLCM, and it is important to distinguish GL from
the GLCM. As noted in Section 2.1, the GLCMs are calculated at
different values of d (the distance between the two pixels that are
compared) and θ (the direction they are aligned). As described in
more detail in Section 2.4, the GL approach has its own orientation
(labelled θGL). For each GLCM, the GL descriptor is extracted for all
values of θGL.
We also examine for the first time a novel approach for repre-
enting the co-occurrence matrix using Spatial Diversity (SD) fea-
ures (Geraldo Junior, da Rocha, Gattass, Silva, & de Paiva, 2013). SD
orks poorly when applied to the whole co-occurrence matrix, but
erforms quite well when applied to a set of sub-windows extracted
rom the co-occurrence matrix, i.e., the GLCM considered only on
subset of its 256 × 256 domain. This is an important point, as
t demonstrates that multiple descriptors, if appropriately applied,
an be useful in describing the co-occurrence matrix: this, in turn,
emonstrates our idea that the co-occurrence matrix can be consid-
red as a texture image. Hence, it is possible to apply standard texture
escriptors (e.g., SD, GL, …) to the GLCM to extract information.
In this study we also improve the performance of the feature
xtraction algorithms by extracting features from the co-occurrence
atrix applied to the original image as well as to the image after
gaussian filtering at multiple scales. The co-occurrence matrix is
lso divided into different sub-windows, from which feature sets
re also extracted. Separate SVM classifiers are trained, one for
ach sub-window. The overall classification outcome is obtained by
ombining the separate SVMs decisions using either a sum rule or a
eighted sum rule.
In Nanni et al. (2013b) only the standard approach proposed
y Haralick (1979) and a set of 3D features considering the co-
ccurrence matrix as a 3D shape are used for describing the GLCM.
n this work we test four different approaches for describing the
o-occurrence matrix, adding as well the innovation of combining
ach approach with a set of preprocessing methods. Moreover, in
ur previous work, our approach was validated only on five datasets,
hereas in this study we employ a set of eleven datasets.
The remainder of this paper is organized as follows. The feature
xtractors used in our experiments are described in Section 2, and
he preprocessing methods (and resulting processed images) are de-
ailed in Section 3. The eleven datasets used to evaluate our approach
nd our rationale for using them are presented in Section 4, and the
xperimental results are reported and discussed in Section 5. Finally,
e conclude in Section 6 with some remarks on the limitations of
his study; we also highlight the importance of studying the GLCM
nd offer some suggestions for future investigations.
. Feature extractors
As mentioned in the introduction, in Nanni et al. (2013c, 2013d),
e showed how it is possible to enhance the performance of
aralick’s features by applying the multi-scale approach. We also
emonstrated the effectiveness of combining features extracted from

L. Nanni et al. / Expert Systems With Applications 42 (2015) 8989–9000 8991
d
m
G
t
p
i
u
fi
a
d
w
m
w
o
h
2
m
M
e
t
i
F
t
p
l
r
p
(
a
p
e
t
t
m
s
a
2
f
f
1
1
1
1
m
d
e
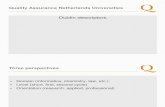
Fig. 1. Illustration of the co-occurrence matrix as a 3D function. A set of planes is in-
tersected with the GLCM to obtain a set of level curves that are analyzed to measure
the shape of the GLCM.
2
c
i
m
z
t
t
d
s
t
o
o
a
s
o
g
e
e
L
h
2 Here we report only the best configuration to reduce the size of the tables report-
ing experimental results.3 The weight of the SVMs trained using features extracted from the original image is
4; the other SVMs have a weight of 1.
ifferent sub-windows of the co-occurrence matrix. In brief, the
ulti-scale approach generates images by applying a 2D symmetric
aussian lowpass filter of kernel size k (we use k = 3 and k = 5 in
his work) with standard deviation 1.
Described in this section are each of the feature extraction ap-
roaches used in the experiments reported in Section 5. In all exper-
ments, SVM (Vapnik & Chervonenkis, 1964; Vapnik & Lerner, 1963),
sing both linear and radial basis function kernels, is the base classi-
er. The best kernel and the best set of parameters for each dataset
re chosen using a 5-fold cross-validation approach on the training
ata. The parameters of the fusions are chosen based on criteria that
ill be detailed below and that were empirically discovered to maxi-
ize the performance obtained by the descriptors extracted from the
hole image and from the sub-windows. It should be noted that in
ur experiments the same weights are always used without any ad-
oc dataset tuning.
.1. The gray level dependency matrix (GLCM)
The Gray Level Co-occurrence Matrix (GLCM) (Haralick, 1979) is a
atrix that is obtained as a histogram on a 2D domain of dimension
×M, where M is the number of gray levels in the image (in our case
qual to 256). The GLCM counts the number of pixel transitions be-
ween two pixel values. In other words, the bin of the histogram is
ncremented whose indices are equal to the values of the two pixels.
or example, a pixel transition between two adjacent pixels from 20
o 30 will increment the GLCM matrix at indices (20, 30). Since the
ixels of the input image take values in the range (0, 255), the gray
evel dependency matrix has size 256×256; each bin at indices (also
eferred to as coordinates) (i, j) represents the number of pixel cou-
les showing the transition from gray level i to gray level j.
The way pixel couples are created depends on two parameters: d
the distance between the two pixels) and θ (the direction they are
ligned). A value of d = 1 and θ = 0, for instance, would result in
ixel couples that are adjacent to each other on the same row. In our
xperiments, we consider four directions: the horizontal (H), the ver-
ical (V), the diagonal top left-bottom right, or right-down (RD), and
he top right-bottom left, or left-down (LD).
In this study the GLCM is processed both by considering the whole
atrix, as well as by restricting to some subsets of its domain (called
ub-window): this means that only a subset of the pixel transitions
re considered at a time.
.2. The standard Haralick statistics (HAR)
Haralick (1979) was the first to consider the idea of using a set of
eatures to extract information from the co-occurrence matrix. The
ollowing Haralick features are considered in our tests:
1. Energy
2. Correlation
3. Inertia
4. Entropy
5. Inverse difference moment
6. Sum average
7. Sum variance
8. Sum entropy
9. Difference average
0. Difference variance
1. Difference entropy
2. Information measure of correlation 1
3. Information measure of correlation 2
In HAR a set of 13 features is calculated from each co-occurrence
atrix evaluated at θ = {0°, 45°, 90°, 135°} and d = {1, 3}. A global
escriptor is obtained by concatenating the descriptors obtained for
ach distance and orientation value.
We also evaluated the performance of the following HAR variants:
• HR, in which features are extracted from the entire image only;• HRsub, in which a feature set is extracted from the entire co-
occurrence matrix plus from four sub-windows defined2 using
the coordinates (0, 0) to (127, 127); (128, 128) to (255, 255),
(0, 128) to (255, 128), and (0, 128) to (128, 255); these are the
coordinates that provided the best experimental results in Nanni
et al. (2013d). Each set of extracted features is then used to train
a separate SVM, with the results combined by weighted sum
rule. The weights are 1 for each SVM running on the feature
evaluated on a sub-window, and 4 for the SVM analyzing the
data extracted from the whole image: this choice reflects the fact
that each sub-window has an area that is ¼ the area of the entire
co-occurrence matrix;• HRsca, in which features are extracted from the original image
and two filtered images. In other words, the feature sets are ex-
tracted from the entire co-occurrence matrix and from the four
sub-windows defined in HRsub as well as from the original image
and from the two filtered images. In this way 15 sets are obtained,
and the 15 SVMs are combined by weighted sum rule3.
.3. Shape
This approach explores the shape of the co-occurrence matrix by
onsidering it as a 3D function. SHAPE has been described in detail
n Ghidoni, Cielniak, and Menegatti (2012); Nanni et al. (2013d). The
ain idea behind SHAPE is to intersect the GLCM with a set of hori-
ontal planes defined by some given height values (see Fig. 1) to ob-
ain a set of level curves (which are curves that describe the shape of
he 3D GLCM at given height values). These level curves are used to
erive a set of features.
Each level curve can be composed of more than one blob. The
hape shown in Fig. 1 is the ideal configuration, but spikes can occur
owards the edge of the histogram. To filter these spikes out so that
nly the main component that is representative of the overall texture
f the image is considered, the main blob (the one with the largest
rea) is selected for the feature extraction process. To ease the analy-
is, it is approximated by fitting it to an ellipse (with only a small loss
f information).
Starting at the base of the co-occurrence matrix with height 1 and
oing up by a distance of 2, level curves are progressively consid-
red until height 19. The maximum height value of 19 is based on
xperimental observation of the effects of the different level curves.
evel curves that have the most information lie at a relatively low
eight because the lower regions of the co-occurrence matrix are

8992 L. Nanni et al. / Expert Systems With Applications 42 (2015) 8989–9000
w
e
w
r
o
m
S
G
w
t
t
t
i
w
very stable, unlike the upper regions, which are less stable due to im-
age noise. To understand the impact of noise in the upper regions,
consider input images of similar texture content, say two consecutive
frames of a video in which no perceivable changes occur; the level
curves evaluated on the two images, or video frames, would show
more significant difference when in fact there is very little difference
in the two images because of the noise in the higher level curves.
This is an unwanted influence of the noise affecting the image pixel.
The exact size chosen for the height values also depends on the im-
age size. The values mentioned above were chosen for images of size
640×480, but they are suitable also for smaller and larger images, as
shown in the experimental section. Finally, it should be mentioned
that the co-occurrence matrix is not normalized because normaliza-
tion to the highest bin would introduce instabilities. Certainly, it is
the case that other types of normalization could be performed with
respect to the total volume of the co-occurrence matrix; however, this
volume is actually the total number of pixel couples in the image and
depends on the image dimensions, which is constant for a given video
flow. Normalizing using a constant would just scale the values, mak-
ing the normalization irrelevant.
A set of features extracted from the ellipses obtained as described
above is evaluated at each level. The features describing all levels are
then analyzed together, and a set of nine features are extracted that
describe the evolution of the level curves (see Ghidoni et al., 2012,
and Nanni et al., 2013d, for details). These features provide a charac-
terization of the input image that can be directly used as the input to
a classifier.
The features in SHAPE, as defined in this paper, are evaluated on
the entire co-occurrence matrix as well as on 12 sub-windows (#1-
#12) of the GLCM, which are defined by the following index ranges:
#1: (0, 0) to (127, 127), #2: (128, 128) to (255, 255), #3: (0, 0) to (191,
191), #4: (64, 64) to (255, 255), #5: (0, 0) to (95, 95), #6: (31, 31)
to (95, 95), #7: (63, 63) to (127, 127), #8: (95, 95) to (159, 159), #9:
(127, 127) to (191, 191), #10: (159, 159) to (223, 223), #11: (191, 191)
to (255, 255), and #12: (63, 63) to (191, 191). In SHAPE we extract
more sub-windows than the four previously used because, differently
from that case, the performance of SHAPE improves when smaller
sub-windows are used, as described in (Nanni et al., 2013c). The di-
vision of sub-windows follows the same process carried out in Nanni
et al. (2013c), which proved to be the most effective solution when
dealing with image classification based on Haralick’s features.
For each of these 13 windows (counting the whole GLCM and the
12 sub-windows), a different feature vector is extracted and used as
the input for a separate SVM. Results of the 13 SVMs are combined by
weighted sum rule. A weight of 1 is given to the first five descriptors
and a weight of 0.5 is assigned to the remainder.
Each set of 13 descriptors is derived from the co-occurrence ma-
trices evaluated at θ = {0°, 45°, 90°, 135°} and d = {1, 3} (in the case
where multiple values are used for the distance). The feature vec-
tor is the concatenation of the features extracted for each value of
the distance. In the experimental section, SH denotes the case where
features are extracted only from the entire co-occurrence matrix.
SHsub denotes the method that extracts features from all 13 windows.
SHsca3 is the approach that combines SHsub with the multi-scale
approach.
2.4. Gray-level run-length features (GL)
GL (Tang, 1998) derives features from a run-length matrix that is
calculated using the characteristics of gray level runs (a set of con-
secutive pixels with the same value). The run length is determined
by the number of pixels in the set. Accordingly, the run-length matrix
P contains in each location P(i, j) the number of runs of length j of a
given gray level i. The run length can be evaluated following four dif-
ferent orientations (horizontal, vertical and diagonal), described by
means of the angle θ = {0◦, 45◦, 90◦, 135◦}.
GLIn this work, the run-length matrix is used in a slightly different
ay: instead of measuring the pixel gray levels of a given image, it is
mployed to measure the height of the bins of the GLCM: in other
ords, the GLCM is considered by the run-length evaluation algo-
ithm like an image of size 256×256 whose “pixels” (namely the bins
f the histogram) can have a value above 256.
The run-length matrix is a tool capable of evaluating the unifor-
ity of the images, that is, the areas showing the same gray level.
uch tool is employed in this study to measure this aspect of the
LCM histograms: the run-level matrix is a complementary aspect
ith respect to the SHAPE features described in Section 2.3: while
he former is focused on the uniform regions, the latter is focused on
he variations of the GLCM peaks.
It is possible to evaluate several features from the run-length ma-
rix; in our experiments, we consider the following ones, described
n (Tang, 1998):
• Short Run Emphasis (SRE), evaluated as:
SRE = 1
nr
M∑i=1
N∑j=1
P(i, j)
j2(1)
• where nr is the total number of runs, M the number of gray levels,
and N the maximum run length;• Long Run Emphasis (LRE):
LRE = 1
nr
M∑i=1
N∑j=1
P(i, j) · j2 (2)
• Gray Level Nonuniformity (GLN):
GLN = 1
nr
M∑i=1
(N∑
j=1
P(i, j)
)2
(3)
• Run Length Nonniformity (RLN):
RLN = 1
nr
N∑j=1
(M∑
i=1
P(i, j)
)2
(4)
• Run Percentage (RP):
RP = nr
np(5)
here np is the total number of pixels in the image;
• Low Grey-Level Run Emphasis (LGRE):
LGRE = 1
nr
M∑i=1
N∑j=1
P(i, j)
i2(6)
• High Grey-Level Run Emphasis (HGRE):
HGRE = 1
nr
M∑i=1
N∑j=1
P(i, j) · i2 (7)
• Short Run Low Grey Level Emphasis (SRLGE):
SRLGE = 1
nr
M∑i=1
N∑j=1
P(i, j)
i2 · j2(8)
• Short Run High Grey Level Emphasis (SRHGE):
SRHGE = 1
nr
M∑i=1
N∑j=1
P(i, j) · i2
j2(9)
• Long Run Low Grey Level Emphasis (LRLGE):
LRLGE = 1
nr
M∑i=1
N∑j=1
P(i, j) · j2
i2(10)

L. Nanni et al. / Expert Systems With Applications 42 (2015) 8989–9000 8993
A
p
p
G
a
d
o
a
e
t
G
o
u
e
i
i
p
G
2
o
a
h
c
b
g
e
t
e
t
s
i
i
w
d
t
p
i
H
T
w
M
T
w
H
T
a
T
T
D
T
q
B
A
f
l
H
i
H
T
i
B
F
w
f
E
W
3
i
i
c
a
(
m
m
v
t
p
e
(
r
p
4 In order to better visualize the processed images (PI), the PI are resized to the size
of the original image.
• Long Run High Grey Level Emphasis (LRHGE):
LRHGE = 1
nr
M∑i=1
N∑j=1
P(i, j) · i2 · j2 (11)
ll the above features are evaluated for all the four orientations of θGL
reviously described.
In this study, the run-length matrix is not used to analyze the in-
ut image, as it is often the case, instead it is used to analyze the
LCM (which is a matrix, and can therefore be analyzed using im-
ge processing techniques). In particular, we exploit the descriptors
efined in Eqs. (1)–(11) from a run-length matrix that is evaluated
n the GLCM. As noted in Section 2.1, several GLCMs are calculated
t different values of d = {1, 3} (the distance between the two pix-
ls) and θ = {0°, 45°, 90°, 135°} (the direction they are aligned). To
ake into account all the combinations of such parameters, a single
L descriptor concatenates all the described features (1)–(11). A set
f GLCMs is then evaluated using the four values of θ and the two val-
es of d, listed in Section 2.2, for a total of eight GLCMs. For each of the
ight GLCMs a given GL feature set is extracted. The GL approach has
n turn its own set of orientations: θGL = {0°, 45°, 90°, 135°}, which
ncludes all the values originally considered in Tang (1998). In the ex-
erimental section, we also explore the performance of the following
L variants:
• GR, as in HR but using the GL features;• GRsub, as in HRsub but using the GL features;• GRsca, as in HRsca but using the GL features.
.5. Spatial diversity (SD)
The concept of diversity comes from the field of ecology and is one
f its central themes. Diversity represents a measure of how species
re present in the environment and, more specifically, in different
abitats and communities. The analysis of diversity considers con-
epts like population, diffusion, and diversification and is performed
y means of indices that analyze the presence of a species within a
iven environment.
To apply diversity analysis to pattern recognition, it is first nec-
ssary to express the data to be analyzed (in this case, images) in
erms of population, species, and related concepts. In Geraldo Junior
t al. (2013), the population P is defined as the set of all Np pixels in
he image, while the gray level values constitute the different species
(i); the total number of species is S, which can be smaller than 256
f some gray level values are not present in the image. The number of
ndividuals of a species s(i) is the number n(i) of pixels in the image
ith a given gray level. Finally, the relative frequency for a species is
efined as: p(i) = n(i)/Np. Given this model it is possible to exploit
he indices commonly used to measure population diversity and ap-
ly them to pattern recognition.
The richness of a population is defined as the Shannon–Wiener
ndex, which is defined as:
= −S−1∑i=0
p(i) ln p(i) (12)
his value increases with higher heterogeneity levels.
Another measure of diversity is provided by the McIntosh index,
hich is defined as:
c = Np −√∑S−1
i=0 n(i)2
Np −√
Np
(13)
he Brillouin index, yet another measure of diversity, is best suited
hen the randomness of the population is not guaranteed:
b = 1
Np
(ln (Np!) −
S−1∑i=0
ln (n(i)!)
)(14)
he total diversity index measures species variation, and is defined
s:
d =S−1∑i=0
1
n(i)(p(i)(1 − p(i))) (15)
he Simpson index is a second order statistics, and is defined as:
s =∑S−1
i=0 n(i)(n(i) − 1)
Np(Np − 1)(16)
he Berger–Parker index is the relative frequency of the most fre-
uent species:
p = maxi
p(i). (17)
dditional indices can be defined based on those above. The J index,
or example, compares the value of the H index for the current popu-
ation to the same index provided by a maximally diverse population:′: J = H/H′, with H′ = ln S. The same concept applied to the Simpson
ndex leads to the Ed index: d = Ds/Ds′ .
The Hill index is defined as:
ill =1
Ds−1
eH − 1(18)
he Buzas–Gibson index measures the uniformity of the Shannon
ndex:
g = eH
S(19)
inally, the last index considered in this work is the Camargo index,
hich compares the relative frequencies of the different species as
ollows:
= 1 −(
S−1∑i=0
S−1∑j=i+1
p(i) − p( j)
S
)(20)
e also explore the performance of the following SD variants:
• SD, as in HR but using the SD features;• SDsub, as in HRsub but using the SD features;• SDsca, as in HRsca but using the SD features.
. Preprocessing methods
The primary aim of this work is to improve performance us-
ng different methods for preprocessing the images before extract-
ng features from the co-occurrence matrix. Before calculating the
o-occurrence matrix, however, we normalize the preprocessed im-
ge I to [0, 255], such that each element becomes I’ = [(I – min) ./
max –min)].×255, where max and min represent the maximum and
inimum values found in the images used for training, respectively;
oreover, .× and ./ represent the per-element multiplication and di-
ision, respectively.
In Fig. 2,4 we provide some example images derived by applying
he preprocessing techniques mentioned above. After the set of pre-
rocessed images is available, a set of descriptors is extracted from
ach one: this set is then fed into an SVM. The outputs of the SVMs
one for each preprocessing technique) are finally combined by sum
ule. Below we briefly describe all the preprocessing methods ex-
lored in this work.

8994 L. Nanni et al. / Expert Systems With Applications 42 (2015) 8989–9000
Fig. 2. Examples of preprocessing of a given input image (acronyms are explained be-
low). For WAV we report the approximation coefficients matrix.
,
3
p
l
p
L
w
t
e
t
n
n
a
m
t
b
s
T
c
t
b
T
L
I
a
a
e
3
e
e
c
t
d
a
∇
T
(
c
T
3.1. Wavelet (WAV)
A common operation used in many vision problems is the Wavelet
transform. WAV (Mallat, 1989) performs a single-level 2-D wavelet
decomposition, which requires a 2-D scaling function, ζ (x, y), and
three 2-D wavelets, ψ i(x, y), where the index i = {H, V, D} is a super-
script representing intensity variations along columns, or horizon-
tal edges (ψH), along rows, or vertical edges (ψV), and along diago-
nals (ψD). Given the separable scaling function and the three wavelet
functions, we first define the scaled and translated basis functions as
follows:
ζ j,s1,s2(x, y) = 2 j/2ζ(2 jx − s1, 2 jy − s2
),
ψ ij,s1,s2(x, y) = 2 j/2ψ i
(2 jx − s1, 2 jy − s2
), i = {H,V, D} (21)
The discrete wavelet transform of function f(x, y) of size S1 × S2 is
then:
Wζ ( j0, s1, s2) = 1√S1×S2
S1−1∑x=0
S2−1∑y=0
f (x, y)ζ j0,s1,s2(x, y),
W iψ( j, s1, s2) = 1√
S1×S2
S1−1∑x=0
S2−1∑y=0
f (x, y)ψ ij,s1,s2(x, y) i = {H,V, D}
(22)
where j0 is an arbitrary starting scale and the Wζ (j0, s1, s2) coeffi-
cients define the approximation of f(x, y) at scale j0. The W iψ( j, s1, s2)
coefficients add horizontal, vertical, and diagonal details for scales j
≥ j0.
In our experiments, we use the Daubechies wavelet with four van-
ishing moments, single scale decomposition (i.e. j = 1 and j0 = 1). The
four preprocessing images are the approximation coefficient matrix
and the three detail coefficient matrices (horizontal, vertical, and di-
agonal). The preprocessed images are thus Wζ and W iψ
, i = {H,V, D}.
Notice that the processed images have a size that differs from that of
the original image. Let us define sx × sy the size of the original image
and lf the length of the wavelet filter (here lf = 7) then the size of the
processed image is floor((sx + lf − 1)/2) × floor((sx + lf − 1)/2).
.2. Local binary patterns (LBP)
The canonical LBP operator (Ojala et al., 2002) is computed at each
ixel location of an image by considering the values of a small circu-
ar neighborhood (with radius R pixels) around the value of a central
ixel Ic:
BP(N, R) =N−1∑n=0
s(In − Ic)2n (23)
here N is the number of pixels in the circular neighborhood, R is
he radius, In are the pixels in the current neighborhood (the varying
lement in the sum) and s(x) = 1 if x ≥ 0, otherwise s(x) = 0.
LBP has proven to be highly discriminative and invariant to mono-
onic gray level changes. Unfortunately, it is not very robust to the
oise present in images when the gray-level changes result from
oise that is not monotonic (Tan & Triggs, 2007). Therefore, we use
well-known variant based on ternary coding (Paci et al., 2013) that
akes it more robust to noise. The ternary coding is achieved by in-
roducing the threshold τ (in this work τ = 3) so that the s(x) function
ecomes:
(x) =
⎧⎨⎩
1, x ≥ τ
0, |x| ≤ τ
−1, x ≤ −τ
(24)
he ternary code obtained by the s(x) function is split into two binary
odes by considering its positive and negative components according
o the following binary function bv(s(x)):
v(s(x)) ={
1 s(x) = v0 otherwise
v ∈ {−1, 1}. (25)
hus, the LTPv operator for v∈{−1, 1} is:
TPv(N, R) =N−1∑n=0
bv(s(In − Ic))2n. (26)
n this work we use (R = 1; N = 8) and (R = 2, N = 16). Four codes
re produced for each pixel (the two sets of parameters and, for both,
positive and a negative LBP code), resulting in four images (one for
ach code). The size of the processed image is (sx - R) × (sy – R).
.3. Gradients (GRA)
Gradient is a common image operation typically used to detect
dges. A gradient magnitude image is defined as an image in which
ach pixel measures the change in intensity in a given direction of a
orresponding point in the original image. GRA calculates the magni-
ude of the gradients of each pixel in the x (horizontal) and y (vertical)
irections based on its neighbors.
For a function f(x, y) the gradient of f at coordinates (x, y) is defined
s the 2D column vector:
F =[
Gx
Gy
]=
⎡⎢⎣
∂ f
∂x
∂ f
∂y
⎤⎥⎦ (27)
he processed image used for extracting the co-occurrence matrix at
x, y) is given by the magnitude of the gradient vector at the same
oordinates and is defined as:
∇ f = mag(∇F) =[Gx
2 + Gy2]1/2 =
[(∂ f
∂x
)2
+(
∂ f
∂y
)2]1/2
.
(28)
he size of the processed image is the same of the original image.

L. Nanni et al. / Expert Systems With Applications 42 (2015) 8989–9000 8995
3
o
u
e
θ
w
t
3
u
o
i
e
2
p
o
t
(
l
o
i
n
d
v
w
t
o
e
G
T
d
ξ
W
t
t
3
o
i
a
a
s
H
f
v
i
t
p
∠
E
t
m
a
S
n
i
F
w
2
s
u
l
H
I
W
T
m
t
H
b
G
g
c
t
t
q
w
c
c
b
T
p
u
fi
c
3
u
n
t
t
w
G
m
.4. Orientation (OR)
In OR the image gradient is soft quantized (Vu, 2013) using three
rientations, which result in three processed images. This method is
sed to reduce the noise and other forms of degradation in an image.
Given the gray level of a pixel p(i) at (x, y) in the gradient image
valuated for the orientation of p(i):
(x, y) = atan2(Gy, Gx), (29)
here θ(x, y) = θ(x, y) + π in the case where θ (x, y) ≥ 0.
OR is the magnitude of p(i) distributed over n discretized orienta-
ions as detailed in Vu, (2013).
The size of the processed image is the same of the original image.
.5. Weber law descriptor (WLD)
WLD is based on Weber’s law which states that a change of stim-
lus that is just noticeable for human beings is a constant ratio of the
riginal stimulus; if the change is less than this constant ratio then
t is considered background noise. WLD has two components: differ-
ntial excitation and orientation (Chen, Shan, He, Zhao, & Pietikäinen,
010). For a given pixel, the differential excitation component is com-
uted based on the ratio between (1) the relative intensity differences
f a current pixel compared to its neighbors and (2) the intensity of
he current pixel. The neighborhood is defined as a square of size LNE
we use LNE = 3). From the differential excitation component, both the
ocal salient patterns in the input image and the gradient orientation
f the current pixel is computed. We use the differential excitation
mage for extracting the co-occurrence matrix, and adopt the same
otation proposed in (Chen et al., 2010).
To compute a differential excitation ξ (Ic) of a current pixel Ic, the
ifferences between its neighbors must be calculated:
00s =
L2NE−1∑i=0
(Ii − Ic), (30)
here Ii(i = 0, 1, . . . L2NE − 1) defines the ith neighbors of Ic and L2
NE is
he number of neighbors. The ratio of the differences to the intensity
f the current point of both the original image v01s and the differential
xcitation image v00s is calculated by:
ratio(Ic) = v00s
v01s
. (31)
he arctangent function is then employed on Gratio(∗) to calculate the
ifferential excitation ξ (Ic):
(Ic) = arctan
[v00
s
v01s
]= arctan
[L2
NE−1∑i=0
(Ii − Ic
Ic
)]. (32)
hen ξ (Ic) is positive, it simulates surroundings that are lighter than
he current pixel; when ξ (Ic) is negative, it simulates surroundings
hat are darker than the current pixel.
The size of the processed image is (sx − 1) × (sy − 1).
.6. Local phase quantization (LPQ)
LPQ (Ojansivu & Heikkila, 2008) is based on the blur invariance
f the Fourier Transform Phase. The spatially invariant blurring of an
mage f(x) results in the blurred image, g(x), which can be expressed
s g(x) = f(x)∗h(x), where x = [x,y]T is the spatial coordinate vector
nd h(x) is the point spread function. What this means in the Fourier
pace can be expressed as G(u) = F(u) · H(u), where G(u), F(u), and
(u) are the Discrete Fourier Transforms (DFT) of the blurred g(x),
(x) and h(x), respectively, and u = [u, v]T is the frequency coordinate
ector. The magnitude and phase aspects can be separated resulting
n |G(u)| = |F(u)| · |H(u)| and �G(u) = �F(u) + �H(u). The Fourier
ransform is always real-valued if h(x) is centrally symmetric, and its
hase is a two-valued function given by
H(u) ={
0, H(u) ≥ 0π, H(u) < 0
(33)
q. (32) means that �G(u) = �F(u) for all H(u) ≥ 0; in other words,
he phase of the observed image �G(u) is invariant to centrally sym-
etric blur at the frequencies where H(u) ≥ 0. LPQ is blur invari-
nt because it uses the local phase information obtained from the
hort Time Fourier Transform (STFT) computed over a rectangular
eighborhood Nx of size LNE×LNE at each pixel position x of the
mage f(x):
(u, x) =∑y∈Nx
f (x − y)e− j2πuT y = wuT f x (34)
here y is a spatial coordinate vector; wu is the basis vector of the
-D DFT at frequency u, and fx is a vector containing all the image
amples from Nx.
LPQ considers four frequency vectors: u1 = [a,0]T, u2 = [0, a]T,
3 = [a, a]T, and u4 = [a, a]T, where a is small enough to reside be-
ow the first zero crossing of H(u) that satisfies �G(u) = �F(u) for all
(u) ≥ 0.
If we let Fcx = [F(u1,x), F(u2,x), F(u3,x), F(u4,x)] and Fx = [Re{Fc
x},
m{Fcx}]T, then the corresponding transform matrix is:
= [Re{wu1, wu2, wu3, wu4,}, Im{wu1, wu2, wu3, wu4, }]T
hus, Fx = W fx.
The coefficients need to be decorrelated before quantization to
aximally preserve the information; after decorrelation the samples
o be quantized are statistically independent. For details, see Rahtu,
eikkilä, Ojansivu, and Ahonen (2012). Assuming a Gaussian distri-
ution, a whitening transform can achieve independence, such that
x = VTFx, where V is an orthonormal matrix derived from the sin-
ular value decomposition of the covariance matrix of the transform
oefficient vector Fx. After computing Gx for all the image positions,
he resulting vectors are quantized using the following scalar quan-
izer:
j ={
1, Gj ≥ 00, Gj ≤ 0
, (36)
here Gj represent the jth component of Gx. These quantized coeffi-
ients are represented as integers between 0 and 255 using the binary
oding
=8∑
j=1
qj2j−1 (37)
he image that contains the integers obtained with Eq. (36) is the
reprocessed image. In this work, two sizes for the local window are
sed (LNE = 3 and LNE = 5), both with Gaussian derivative quadrature
lter pairs for local frequency estimation. In this way, two prepro-
essed images are obtained.
The size of the processed image is (sx + 1 − LNE) × (sy +1 − LNE).
.7. Minimum paths by Dijkstra’s algorithm (DJ)
DJ (De Mesquita Sá Junior, Backes, & Cortez, 2013) models images
sing a graph where each pixel corresponds to a node that is con-
ected to its 4-neighbors. The cost, we(x, y), of a transition between
wo connected nodes at locations (x, y) and (x′, y′) is determined by
heir gray levels I(x, y) and I(x′, y′), such that:
e(x, y) = |I(x, y) − I(x′, y′)| + I(x, y) + I(x′, y′)2
(38)
iven this model, the image texture is measured by evaluating the
inimum cost for connecting four point pairs: (i) the central points

8996 L. Nanni et al. / Expert Systems With Applications 42 (2015) 8989–9000
Table 1
Descriptive summary of the datasets.
Name Abreviation #Classes #Samples Sample size Download
Histopatology HI 4 2828 Various http://www.informed.unal.edu.co/histologyDS
Pap smear PAP 2 917 Various http://labs.fme.aegean.gr/decision/downloads
Virus types classification VIR 15 1500 41 × 41 http://www.cb.uu.se/∼gustaf/virustexture
Breast cancer BC 2 584 various upon request to Geraldo Braz Junior [[email protected]]
Protein classification PR 2 349 various upon request to Loris Nanni [[email protected]]
Chinese Hamster Ovary CHO 5 327 512 × 382 http://ome.grc.nia.nih.gov/iicbu2008/hela/index.html#cho
2D HeLa HE 10 862 512 × 382 http://ome.grc.nia.nih.gov/iicbu2008/hela/index.html
Locate Endegenous LO 10 502 768 × 512 http://locate.imb.uq.edu.au/downloads.shtml
Brodatz BR 13 2080 205 × 205 http://dismac.dii.unipg.it/rico/data.html
Pictures PI 13 903 Various http://imagelab.ing.unimo.it/files/bible_dataset.zip
Painting PA 13 2338 Various http://www.cat.uab.cat/∼joost/painting91.html
p
d
d
e
o
f
e
m
d
t
b
m
e
c
d
f
t
L
2
c
5
d
of the first and last column (p0); (ii) the lower left and upper right
corner (p45); (iii) the central points of the upper and lower row (p90);
and (iv) the lower right and upper left corner (p135). To find the min-
imum paths, Dijkstra’s algorithm (Dijkstra, 1959) is exploited since
link costs cannot be negative.
The cost w depends on two elements: the difference in the gray
levels of the two pixels and their average value. The cost of the four
paths (i–iv described above) will then be higher if a large number of
strong transitions is present in the paths; this links the path costs to
image texture.
In our experimental section, we divide each image into patches of
4 × 4 pixels. For each patch the four minimum cost paths are calcu-
lated. For each of the four paths (i–iv), a different image is built where
the cost path of patch (i,j) of the original image becomes the (i,j) ele-
ment of the new processed image. Since we have four different cost
paths, we process the image in four different ways. Notice that, since
we use patches of 4 × 4 pixels, the size of the processed image is 25%
of the size of the original image (one pixel for each patch).
4. Datasets
To assess our system, we validate it across eleven image datasets,
representing several different computer vision problems. Table 1 pro-
vides a short descriptive summary of each of the following datasets:
• PAP: the pap smear dataset in Jantzen, Norup, Dounias, and
Bjerregaard (2005), containing images representing cells used in
cervical cancer diagnosis.• VIR: the virus dataset in Kylberg, Uppström, and Sintorn (2011),
containing images of viruses extracted by negative stain transmis-
sion electron microscopy. We use the same 10-fold validation di-
vision of images, which we obtained from the authors of Kylberg
et al. (2011). However, rather than use the mask provided in VIR
for background subtraction, we use the entire image for extracting
features since we found this method performs better.• HI: the histopatology dataset in Cruz-Roa, Caicedo, and González
(2011), containing images taken from different organs that repre-
sent the four fundamental tissues.• BC: the breast cancer dataset in Junior, Cardoso, de Paiva, Silva,
and Muniz de Oliveira (2009), containing 273 malignant and 311
benign breast cancer images.• PR: the protein dataset in Nanni, Shi, Brahnam, and Lumini (2010),
containing 118 DNA-binding Proteins and 231 Non-DNA-binding
proteins, with texture descriptors extracted from the 2D distance
matrix that represents each protein. The 2D matrix is obtained
from the 3D tertiary structure of a given protein by considering
only atoms that belong to the protein backbone (see Nanni et al.,
2010, for details).• CHO: the Chinese hamster ovary cell dataset in Boland, Markey,
and Murphy (1998), containing 327 fluorescent microscopy im-
ages of ovary cells belonging to five different classes. Images are
16 bit grayscale of size 512 × 382 pixels.
• HE: the 2D HeLa dataset (Boland & Murphy, 2001), containing 862
single cell images divided into 10 staining classes taken from flu-
orescence microscope acquisitions on HeLa cells.• LO: the LOCATE ENDOGENOUS mouse sub-cellular organelles
dataset (Fink et al., 2006), containing 502 images unevenly dis-
tributed among 10 classes of endogenous proteins or features of
specific organelles.• BR: the exact same set of textures used in Gonzalez, Fernandez,
and Bianconi (2014), composed of 13 texture classes (2080 images
with different rotations) taken from the Brodatz’s album (Brodatz,
1966). The image with rotation 0° are used in the training set, and
the rotated images belong to the testing set.• PI: the dataset in Borghesani, Grana, and Cucchiara (2014), con-
taining pictures extracted from digitalized pages of the Holy Bible
of Borso d’Este, duke of Ferrara (Italy) from 1450 A.D. to 1471 A.D.
The dataset PI is composed of 13 classes that are characterized by
clear semantic meaning and significant search relevance.• PA: the dataset in Khan, Beigpour, Weijer, and Felsberg (2014),
containing 2338 paintings by 50 painters, representative of 13 dif-
ferent painting styles: abstract expressionism, baroque, construc-
tivism, cubism, impressionism, neo-classical, pop art, post im-
pressionism, realism, renaissance, romanticism, surrealism, and
symbolism. All experiments on PA use the same training and test-
ing sets that were used in Khan et al. (2014) (these sets were pro-
vided by the authors).
An important goal in our research efforts is to produce general-
urpose systems that perform well across very different image
atasets and problems. For this reason we test our algorithms on
atasets, such as those listed above, that are intentionally very gen-
ral and different from each other. The presence of too many datasets
f the same kind would have polarized the overall results. Moreover,
or a system to be truly general-purpose, it is essential that all param-
ters and weights remain constant across all datasets in our experi-
ental section. This is crucial in order to avoid overfitting on single
atasets.
The weights of the different weighted sum rules proposed in
his paper are obtained using a grid search (where each weight
etween 0 and 5 is tested in increments of 0.5) for maxi-
izing the performance in the three datasets used in Nanni
t al. (2013b); Nanni et al. (2013c). Also the parameters of the prepro-
essing methods are obtained in a similar way. The results on these
atasets are not reported in this paper since these datasets were used
or parameter selection only. The three datasets used to determine
he weighted sum rules are the Smoke datasets (Feiniu, 2011), the
ocate Transfected dataset (Hamilton, Pantelic, Hanson, & Teasdale,
007), and RNAi, a dataset of fluorescence microscopy images of fly
ells (Zhang & Pham, 2011).
. Experimental results
We used the 5-fold cross-validation protocol to test each texture
escriptor, except for the VIR, PR, and PA datasets, which require the

L. Nanni et al. / Expert Systems With Applications 42 (2015) 8989–9000 8997
Table 2
Usefulness of the preprocessing methods.
HR WAV LBP GRA OR WLD LPQ DJ F1 F2 F3 F4
PAP 89.2 90.3 84.3 87.3 87.8 90.2 84.6 89.1 90.6 90.1 89.3
VIR 96.6 96.7 93.1 96.0 96.8 96.4 89.5 97.8 98.0 98.1 98.1
CHO 99.8 99.9 99.3 99.8 99.9 99.1 99.8 99.9 99.9 99.9 99.9
HI 89.6 90.2 85.1 88.9 89.8 87.3 86.6 90.3 90.6 90.8 90.9
BC 94.2 89.9 90.3 95.4 93.3 91.9 80.4 95.3 94.5 95.4 94.6
PR 89.9 82.1 87.9 88.6 84.0 79.8 85.3 90.1 87.8 88.5 89.8
HE 97.4 98.2 97.2 97.8 96.4 96.4 97.3 97.6 97.8 98.1 98.3
LO 99.5 99.3 98.6 99.2 98.0 98.2 98.9 99.4 99.4 99.4 99.5
BR 92.1 86.9 86.7 91.7 87.5 89.3 94.4 90.1 90.9 91.5 93.3
PI 87.9 81.1 85.6 87.8 85.5 86.7 87.1 88.0 88.1 88.1 88.1
PA 83.8 78.5 83.2 84.1 83.6 83.7 83.4 85.0 85.4 85.6 85.6
Av 92.7 90.2 90.1 92.4 91.1 90.8 89.7 92.9 93.0 93.2 93.4
SH WAV LBP GRA OR WLD LPQ DJ F1 F2 F3 F4
PAP 85.2 84.2 83.0 83.9 88.9 86.7 85.9 88.6 89.2 88.5 89.3
VIR 90.6 92.0 86.9 87.6 93.3 92.0 59.8 95.5 95.6 95.7 95.3
CHO 99.5 99.5 99.6 99.6 97.6 98.1 99.5 99.7 99.6 99.9 99.9
HI 84.2 85.2 83.1 85.6 87.8 76.9 81.9 89.4 89.3 90.2 90.7
BC 90.7 89.4 82.8 83.8 95.1 94.5 78.1 95.3 96.0 95.8 94.5
PR 89.3 82.0 85.7 90.2 87.2 79.0 85.0 91.3 90.2 91.6 91.7
HE 96.6 94.7 96.4 97.1 93.1 91.6 96.0 96.8 96.7 97.7 98.0
LO 98.8 88.4 98.9 98.4 96.8 95.0 93.1 99.1 99.0 99.3 99.2
BR 91.7 88.1 93.7 89.0 93.6 85.6 94.9 93.8 93.2 92.7 94.3
PI 80.5 74.5 80.2 81.0 81.1 76.5 76.5 82.7 82.8 83.1 83.0
PA 78.6 73.2 77.5 78.1 78.0 75.3 74.5 79.1 79.6 80.0 80.1
Av 89.6 86.4 87.9 88.5 90.2 86.4 84.1 91.9 91.9 92.2 92.3
GR WAV LBP GRA OR WLD LPQ DJ F1 F2 F3 F4
PAP 87.6 89.6 73.9 81.2 86.0 91.0 87.0 88.4 90.3 89.9 90.8
VIR 94.3 95.0 88.6 93.8 94.9 95.9 86.1 96.6 97.2 97.4 97.3
CHO 97.9 99.9 96.9 98.1 99.9 99.9 98.8 99.9 99.9 99.9 99.9
HI 86.9 90.4 81.0 83.9 87.6 86.9 85.0 89.8 91.4 91.5 91.8
BC 95.3 96.8 86.8 94.8 97.3 96.7 77.7 97.8 98.1 98.3 97.4
PR 89.9 91.7 83.4 87.6 90.1 89.8 87.1 92.6 93.3 93.0 93.5
HE 96.4 97.8 95.7 97.2 97.4 96.4 97.7 97.9 98.2 98.5 98.8
LO 98.8 99.6 96.5 98.0 99.1 98.8 98.7 99.6 99.6 99.6 99.6
BR 90.4 94.2 90.6 93.2 93.8 90.3 91.4 93.4 94.4 94.9 94.8
PI 80.5 81.4 79.5 81.1 80.7 78.4 78.5 92.8 93.0 83.2 83.2
PA 79.2 78.2 78.0 79.8 78.5 77.5 77.1 81.5 81.9 82.1 82.0
Av 90.6 92.2 86.4 89.8 91.3 91.0 87.7 93.6 94.3 93.4 93.5
SD WAV LBP GRA OR WLD LPQ DJ F1 F2 F3 F4
PAP 87.9 88.9 80.4 84.9 88.5 89.4 81.0 88.7 89.8 89.6 89.3
VIR 92.0 93.5 83.4 89.5 94.0 93.4 75.8 95.6 96.1 96.0 95.9
CHO 99.6 99.8 98.6 99.8 99.7 99.5 95.0 99.9 99.9 99.9 99.9
HI 85.6 87.0 80.4 84.9 86.8 84.3 79.6 88.6 89.8 90.4 90.4
BC 95.0 94.4 90.0 91.0 94.0 96.1 76.4 96.4 96.9 96.8 95.8
PR 90.3 87.2 88.2 90.7 84.8 85.7 77.6 90.5 90.5 91.3 90.7
HE 97.3 96.7 94.8 97.3 96.1 96.0 96.5 97.8 97.9 98.5 98.5
LO 99.3 99.1 98.3 99.4 98.2 97.4 97.1 99.3 99.3 99.5 99.5
BR 91.3 93.4 88.9 90.1 86.9 90.4 93.4 90.3 91.7 92.1 93.6
PI 80.0 81.5 81.2 81.0 79.5 78.6 77.2 82.2 82.8 83.2 83.2
PA 79.2 78.6 78.4 79.7 77.2 79.1 76.5 81.5 82.0 82.1 82.0
Av 90.6 90.9 87.5 89.8 89.6 89.9 84.1 91.8 92.4 92.6 92.6
o
u
p
m
w
t
c
(
a
m
p
e
t
p
t
S
i
fi
w
riginal testing protocols that were detailed in Section 4. The area
nder the ROC curve (AUC)5 is the performance indication since it
rovides a better overview of classification results. AUC is a scalar
easure that can be interpreted as the probability that the classifier
ill assign a higher score to a randomly picked positive sample than
o a randomly picked negative sample (Fawcett, 2004). In the multi-
lass problem, AUC is calculated using the one-versus-all approach
i.e., a given class is considered “positive” while all the other classes
re considered “negative”) and the average AUC is reported.
The aim of the first experiment, reported in Table 2, is to deter-
ine the usefulness of the different preprocessing techniques ap-
lied to the image before creating the co-occurrence matrix. In this
xperiment all three feature extraction approaches (see Section 2) are
ested. In addition, the following fusions are reported:
5 AUC is implemented as in dd_tools 0.95 [email protected].
a
t
d
F1: WAV + WLD;
F2: WAV + WLD + LPQ;
F3: WAV + WLD+LPQ + OR;
F4: WAV + WLD+LPQ + OR + DJ.
A method represented above as A + B is the sum rule between ap-
roaches A and B. Before fusion, the scores of A and B are normalized
o mean 0 and standard deviation 1.
For feature extractors that we tested are HRsca, SHsca, GRsca and
Dsca. When a given preprocessing method produces more than one
mage (e.g., wavelet produces four different images), a SVM classi-
er is applied separately to each processed image. For instance, with
avelet we train one SVM using the approximation coefficient matrix
nd three SVMs using the three detail coefficient matrices (horizon-
al, vertical, and diagonal). This set of SVMs is combined by sum rule.
Notice that we report only the best ensemble (average in the four
escriptors) built by 2, 3, 4, and 5 preprocessing approaches. We want

8998 L. Nanni et al. / Expert Systems With Applications 42 (2015) 8989–9000
Table 3
Performance gains using the proposed ensemble.
AUC HR HRsca HRp HRsca+ 2×HRp SH SHsca SHp SHsca+ 2×SHp GR GRsca GRp GRsca+ 2×GRp SD SD sca SDp SDsca+ 2× SDp
PAP 89.4 92.5 90.1 92.4 82.5 86.5 88.5 89.9 84.1 85.9 89.9 89.9 84.8 86.7 89.6 89.6
VIR 95.9 96.7 98.1 98.4 84.6 92.1 95.7 96.7 88.8 94.1 97.4 97.7 76.8 88.4 96.0 96.4
CHO 99.4 99.5 99.9 99.9 99.5 99.8 99.9 99.9 98.6 97.9 99.9 99.9 98.7 99.4 99.9 99.9
HI 87.7 89.5 90.8 91.6 83.2 89.6 90.2 91.7 87.3 89.6 91.5 92.8 81.2 87.1 90.4 90.7
BC 92.7 93.8 95.4 95.6 88.8 92.3 95.8 95.8 84.9 93.8 98.3 98.0 89.4 91.5 96.8 95.9
PR 90.6 91.0 88.5 91.0 84.8 87.6 91.6 91.0 85.7 92.7 93.0 94.2 79.2 85.7 91.3 90.6
HE 96.1 97.2 98.0 98.1 94.1 96.7 97.7 98.0 92.2 97.0 98.5 98.7 95.3 97.7 98.5 98.8
LO 98.1 99.1 99.2 99.5 95.4 98.1 99.3 99.3 98.4 99.0 99.6 99.6 97.6 98.8 99.5 99.6
BR 88.9 91.3 93.3 91.8 92.7 96.6 92.7 94.9 89.9 93.1 94.9 95.3 88.8 93.2 92.1 93.0
PI 87.7 90.4 88.1 88.3 81.0 85.0 83.1 85.1 81.1 85.7 83.2 85.9 81.0 85.1 83.2 86.0
PA 84.1 87.5 85.6 87.6 78.1 83.4 80.0 84.0 79.8 84.1 82.1 84.8 79.7 83.9 82.1 84.8
Av 91.8 93.5 93.3 94.0 87.7 91.6 92.2 93.3 88.2 92.0 93.4 94.2 86.5 90.6 92.6 93.2
Table 4
Performance of fusion approaches.
AUC HR NanniA NanniB NanniC SUMdiv SUM WEI
PAP 89.4 89.5 92.5 91.8 91.6 91.7 91.8
VIR 95.9 96.0 96.4 96.5 97.9 98.1 98.2
CHO 99.4 99.5 99.9 99.9 99.9 100 99.9
HI 87.7 88.0 90.7 92.4 93.5 93.5 93.6
BC 92.7 92.8 94.9 95.1 97.2 97.1 97.1
PR 90.6 90.6 89.1 92.1 93.0 92.8 93.0
HE 96.1 96.5 97.8 98.3 98.8 98.6 98.7
LO 98.1 98.8 99.4 99.5 99.6 99.6 99.6
BR 88.9 90.0 93.3 94.9 94.1 94.7 94.6
PA 84.1 85.1 85.5 86.2 87.8 88.0 88.1
PI 87.8 88.2 88.8 89.2 90.2 90.4 90.8
Av 91.9 92.3 93.5 94.2 94.9 94.9 95.0
Table 5
Fusion approaches.
AUC LBP LTP LPQ CLBP MT W1 ENS
PAP 87.7 86.1 90.2 92.5 90.0 92.6 92.0
VIR 89.8 91.6 94.9 94.8 93.7 96.5 98.2
CHO 99.9 100 99.2 99.9 100 100 100
HI 92.5 92.8 92.0 91.8 93.4 94.1 94.3
BC 92.4 95.6 95.7 95.8 96.0 97.3 97.7
PR 79.8 87.8 86.2 86.6 88.4 93.2 93.6
HE 98.0 98.6 97.2 98.1 98.3 98.7 98.8
LO 98.6 99.5 97.6 98.5 99.6 99.6 99.7
BR 86.5 90.9 91.7 90.2 95.6 96.7 96.5
PA 87.3 89.0 88.3 93.2 90.1 90.3 90.8
PI 90.1 92.9 90.7 88.6 93.2 93.5 93.9
Av 91.1 93.2 93.1 93.6 94.4 95.7 96.0
i
f
i
e
i
l
S
p
f
6 For LBP, LTP, CLBP, and MT, we use uniform bins with (P = 8, R = 1) and (P = 16,
R = 2); for LPQ the size of the local window was {3, 5}.
to stress that it is well known in the literature that a good ensemble
is obtained by considering a tradeoff between the performance and
the diversity of the individual classifiers that make up the ensemble
(Kuncheva, 2014). For this reason, LBP is not used in any ensemble
due to its lower diversity with respect to WLD and LPQ.
Examining Table 2, we see that the performance of F3 and F4 are
similar. In F3, the DJ preprocessing method, which is computationally
expensive, is not used. In the tests that follow, therefore, we use F3 to
reduce computation time.
The goal of the second experiment, reported in Table 3, is to show
the performance improvements obtainable when the features ex-
tracted from the original image are combined with the preprocessed
images. The following methods are compared in Table 3:
• {HR, SH, GR, SD} is the performance of the descriptors {HR, SH, GR,
SD} extracted from the whole original image only;• {HRsca, SHsca, GRsca, SDsca} is the performance of the descriptors
{HRsca, SHsca, GRsca, SDsca};• {HRp, SHp, GRp, SDp} is the best fusion reported
(WAV+WLD+LPQ+OR) in Table 2 by varying the types of fea-
tures extracted from the processed images;• A + K × B is the fusion by weighted sum rule between A and B
(weight of B is K). Before fusion, the scores of A and B are normal-
ized to mean 0 and standard deviation 1.
Examining Table 3, we see that the weighted sum rule outper-
forms all the other approaches. It is interesting to note the improve-
ment obtained with respect to the baseline approaches, i.e., where
the features are extracted from the whole co-occurrence matrix us-
ing the original image only (i.e., HR, SH, GR and SD).
To statistically validate our experiments, we used the Wilcoxon
signed rank test (Demšar, 2006), which confirms (p-value 0.05) that
the proposed fusion outperforms the standard approaches HR, SH,
GR, and SD.
The aim of the third experiment, reported in Table 4, is to exam-
ne the performance gained by fusing different descriptors extracted
rom the co-occurrence matrix. The methods compared in this exper-
ment are the following:
• NanniA: the best ensemble proposed in Nanni et al. (2013b);• NanniB: the best ensemble proposed in Nanni et al. (2013c);• NanniC: the best ensemble proposed in Nanni et al. (2013d);• SUMdiv: proposed in this paper as the sum rule fusion of
HRsca + 2 × HRp, GRsca + 2 × GRp and DIsca + 2 × DIp.• SUM: proposed in this paper as the sum rule fusion of
HRsca + 2 × HRp, GRsca + 2 × GRp, and SHsca + 2 × SHp.• WEI: proposed in this paper as the sum rule fusion of
HRsca + 2 × HRp (weight 2), GRsca + 2 × GRp (weight 2), and
SHsca + 2 × SHp (weight 1).
Examining Table 4, we find WEI outperforming all our previous
nsembles, NanniA, NanniB and NanniC, with a p-value of 0.05 us-
ng Wilcoxon signed rank test. SUMdiv obtains a performance simi-
ar to SUM. In our experiments, we tried to improve WEI by adding
Dsca + 2 × SDp to the ensemble but obtained no improvement in
erformance.
Finally, in Table 5, we report the results of some of the best per-
orming texture descriptors reported in the literature:
• Local binary patterns (LBP)6 (Ojala et al., 2002).• Local ternary patterns (LTP) (Tan & Triggs, 2007).• Multi-threshold local quinary coding (MT) (Paci et al., 2013).• Local phase quantization (LPQ) (Rahtu et al., 2012).• Completed Local binary patterns (CLBP) (Guo, Zhang, & Zhang,
2010).• W1: an ensemble of descriptors proposed in Nanni et al. (2013d).

L. Nanni et al. / Expert Systems With Applications 42 (2015) 8989–9000 8999
f
6
m
i
W
t
f
T
s
i
s
c
c
t
w
p
H
f
b
s
p
t
a
t
p
t
p
c
f
p
s
s
p
t
w
G
m
L
R
A
B
B
B
B
B
C
C
C
D
D
D
D
F
F
F
F
G
G
G
G
G
H
H
H
H
H
J
J
J
K
K
K
L
M
M
M
N
N
N
N
Moreover we report the following fusion:
• ENS: sum rule between MT and WEI.
Examining Table 5, we see that the proposed system ENS outper-
orms the other approaches.
. Conclusion
In this study we improved the performance of the co-occurrence
atrix by examining different preprocessing techniques applied to
mages before extracting features from the co-occurrence matrix.
e also compared and combined strategies for extending the tex-
ure descriptors extracted from the co-occurrence matrix after trans-
orming the original image with different preprocessing methods.
hese methods are then improved by combining them with a multi-
cale approach that is based on Gaussian filtering and on extract-
ng features from both the entire co-occurrence matrix and a set of
ub-windows. For all experiments, the SVM was used as the base
lassifier.
Our proposed system was validated across several image classifi-
ation problems, with very different images, thereby demonstrating
he generalizability of our approach. We also compared our results
ith some state-of-the-art descriptors. In our opinion, the results re-
orted in this paper are very useful for practitioners; rather than use
aralick’s descriptors, they can now use our more powerful set of
eatures extracted from the GLCM. The code of the proposed ensem-
le is available at https://www.dei.unipd.it/node/2357. Moreover, our
tudy shows the value of exploring novel methods for deriving more
owerful descriptors from the co-occurrence matrix.
Because one of our goals was to create a general-purpose system
hat is capable of working with many image problems and databases,
limitation of this work could be the number of tested datasets. In
he future we plan on expanding tests so that our systems are com-
ared on at least 15 datasets representing different image classifica-
ion problems. This expansion would provide a more reliable com-
arison. Another limitation of our proposed system has to do with
omputation time: the standard approach based on the Haralick’s
eatures is considerably less expensive, computationally, than our
roposed system since it requires the training of several SVMs. It
hould be pointed out, however, that each SVM in our proposed en-
emble is trained independently from the others, so the proposed ap-
roach is well suited for modern multi-core architectures.
As a follow-up to this work, we plan on exploring recent methods
hat boost the performance of texture descriptors, e.g., approaches
here each image is split into different subimages (Vu, Nguyen, &
arcia, 2014). We will also examine new methods for choosing the
ost powerful set of state-of-the-art texture descriptors (such as,
TP+LQP) that can be extracted from the co-occurrence matrix.
eferences
kono, A., Tankam, N. T., & Tonye, E. (2005). Nouvel algorithme d’evaluation de texture
d’ordre n sur la classification de l’ocupation des sols de la region volcanique dumont Cameroun. Teledetection, 5, 227–244.
ay, H., Tuytelaars, T., & Gool, L. V. (2006). SURF: speeded up robust features. EuropeanConference on Computer Vision, 1, 404–417.
oland, M. V., Markey, M. K., & Murphy, R. F. (1998). Automated recognition of pat-
terns characteristic of subcellular structures in fluorescence microscopy images.Cytopathology, 33, 366–375.
oland, M. V., & Murphy, R. F. (2001). A neural network classifier capable of recognizingthe patterns of all major subcellular structures in fluorescence microscope images
of HeLa cells. Bioinformatics, 17(12), 1213–1223.orghesani, D., Grana, C., & Cucchiara, R. (2014). Miniature illustrations retrieval and
innovative interaction for digital illuminated manuscripts in multimedia systems.Multimedia Systems, 20, 65–79.
rodatz, P. (1966). Textures: a photographic album for artists and designers. New York,
USA: Dover Publications.hen, S., Chengdong, W., Chen, D., & Tan, W. (2009). Scene classification based on gray
level-gradient co-occurrence matrix in the neighborhood of interest points. In Pro-ceedings of the ieee international conference on intelligent computing and intelligent
systems 2009 (pp. 482–485).
hen, J., Shan, S., He, C., Zhao, G., & Pietikäinen, M. (2010). WLD: a robust local im-age descriptor. IEEE Transactions on Pattern Analysis and Machine Intelligence, 32(9),
1705–1720.ruz-Roa, A., Caicedo, J. C., & González, F. A. (2011). Visual pattern mining in histology
image collections using bag of features. Artificial Intelligence in Medicine, 52(2), 91–106.
alal, N., & Triggs, B. (2005). Histograms of oriented gradients for human detection. InProceedings of the 9th European Conference on Computer Vision (pp. 886–893).
e Mesquita Sá Junior, J. J., Backes, A. R., & Cortez, P. C. (2013). Texture analysis and
classification using shortest paths in graphs. Pattern Recognition Letters, 34, 1314–1319.
emšar, J. (2006). Statistical comparisons of classifiers over multiple data sets. Journalof Machine Learning Research, 7, 1–30.
ijkstra, E. W. (1959). A note on two problems in connexion with graph. NumerischeMathematik, 1, 269–271.
awcett, T. (2004). ROC graphs: notes and practical considerations for researchers. Palo
Alto, USA: HP Laboratories.einiu, Y. (2011). Video-based smoke detection with histogram sequence of LBP and
LBPV pyramids. Fire Safety Journal, 46(3), 132–139.ink, J. L., Aturaliya, R. N., Davis, M. J., Zhang, F., Hanson, K., Teasdale, M. S., et al. (2006).
LOCATE: a mouse protein subcellular localization database. Nucleic Acids Research,34, 213–217.
reeman, W. T., & Adelson, E. H. (1991). The design and use of steerable filters. IEEE
Transactions on Pattern Analysis and Machine Intelligence, 13, 891–906.elzinis, A., Verikas, A., & Bacauskiene, M. (2007). Increasing the discrimination
power of the co-occurrence matrix-based features. Pattern Recognition, 40, 2367–2372.
eraldo Junior, B., da Rocha, S. V., Gattass, M., Silva, A. C., & de Paiva, A. C. (2013). A massclassification using spatial diversity approaches in mammography images for false
positive reduction. Expert System with Applications, 40, 7534–7543.
hidoni, S., Cielniak, G., & Menegatti, E. (2012). Texture-based crowd detection andlocalisation. In International Conference on Intelligent Autonomous Systems 2012: 193
(pp. 725–736).onzalez, E., Fernandez, A., & Bianconi, F. (2014). General framework for rotation in-
variant texture classification through co-occurrence of patterns. Journal of Mathe-matical Imaging and Vision, 50(3), 300–313.
uo, Z., Zhang, L., & Zhang, D. (2010). A completed modeling of local binary pattern op-
erator for texture classification. IEEE Trans. on Image Processing, 19(6), 1657–1663.amilton, N., Pantelic, R., Hanson, K., & Teasdale, R. D. (2007). Fast automated cell phe-
notype classification. BMC Bioinformatics, 8–110.aralick, R. M., Shanmugam, K., & Dinstein, I. (1973). Textural features for image clas-
sification. IEEE Transactions on Systems, Man, and Cybernetics, 3, 610–621.aralick, R. M. (1979). Statistical and structural approaches to texture. In Proceedings of
the IEEE: 67 (pp. 786–804).
u, Y. (2009). Unsupervised texture classification by combining multi-scale featuresand k-means classifier. In Proceedings of the Chinese Conference on Pattern Recogni-
tion (pp. 1–5).uang, J., Kumar, S. R., Mitra, M., Zhu, W. J., & Zabih, R. (1997). Image indexing using
color correlograms. In Proceedings of the IEEE Conference on Computer Vision andPattern Recognition (pp. 762–768).
ain, A. K., & Farrokhnia, F. (1991). Unsupervised texture segmentation using gabor fil-ters. Pattern Recognition Letters, 24, 1167–1186.
antzen, J., Norup, J., Dounias, G., & Bjerregaard, B. (2005). Pap-smear benchmark data
for pattern classification. Nature inspired Smart Information Systems, 1, 1–9.unior, G. B., Cardoso de Paiva, A., Silva, A. C., & Muniz de Oliveira, A. C. (2009). Clas-
sification of breast tissues using Moran’s index and Geary’s coefficient as texturesignatures and SVM. Computers in Biology and Medicine, 39, 1063–1072.
han, F., Beigpour, S., Weijer, J., & Felsberg, M. (2014). Painting-91: a large scaledatabase for computational painting categorization. Machine Vision and Applica-
tions, 25, 1385–1397.
uncheva, I. L. (2014). Combining pattern classifiers: methods and algorithms (2nd Edi-tion). New York: Wiley, ISBN: 987-1-118-31523-1, 384 pages, October 2014.
ylberg, G., Uppström, M., & Sintorn, I.-M. (2011). Virus texture analysis using localbinary patterns and radial density profiles. In Proceedings of the 18th Iberoamerican
Congress on Pattern Recognition (pp. 573–580).owe, D. G. (2004). Distinctive image features from scale-invariant keypoints. Interna-
tional Journal of Computer Vision, 60, 91–110.
allat, S. (1989). A theory for multiresolution signal decomposition. IEEE Transactionson Pattern Analysis and Machine Intelligence, 11, 674–693.
ikolajczyk, K., & Schmid, C. (2005). A performance evaluation of local descriptors.IEEE Transactions on Pattern Analysis and Machine Intelligence, 29, 1615–1630.
itrea, D., Mitrea, P., Nedevschi, S., Badea, R., Lupsor, M., et al. (2012). Abdominal tu-mor characterization and recognition using superior-order cooccurrence matrices,
based on ultrasound images. Computational and Mathematical Methods in Medicine,
2012, 1–17.anni, L., & Lumini, A. (2008). A reliable method for cell phenotype image classification.
Artificial Intelligence in Medicine, 43, 87–97.anni, L., Shi, J.-Y., Brahnam, S., & Lumini, A. (2010). Protein classification using tex-
ture descriptors extracted from the protein backbone image. Journal of TheoreticalBiology, 3, 1024–1032.
anni, L., Paci, M., Brahnam, S., Ghidoni, S., & Menegatti, E. (2013a). Virus image classi-
fication using different texture descriptors. In The 14th International Conference onBioinformatics and Computational Biology (pp. 56–61).
anni, L., Brahnam, S., Ghidoni, S., Menegatti, E., & Barrier, T. (2013b). A comparison ofmethods for extracting information from the co-occurrence matrix for subcellular
classification. Expert Systems with Applications, 40(18), 7457–7467.

9000 L. Nanni et al. / Expert Systems With Applications 42 (2015) 8989–9000
S
S
S
T
T
T
U
V
V
V
V
V
W
W
Z
Z
Nanni, L., Ghidoni, S., & Menegatti, E. (2013c). A comparison of multi-scale approachesfor extracting image descriptors from the co-occurrence matrix. Computer Commu-
nication & Collaboration, 1(1), 1–18.Nanni, L., Brahnam, S., Ghidoni, S., & Menegatti, E. (2013d). Different approaches for
extracting information from the co-occurrence matrix. PLoS ONE, 8(12), e83554.doi:10.1371/journal.pone.0083554.
Ojala, T., Pietikäinen, M., & Harwood, D. (1996). A comparative study of texture mea-sures with classification based on featured distribution. Pattern Recognition Letters,
29, 51–59.
Ojala, T., Pietikainen, M., & Maeenpaa, T. (2002). Multiresolution gray-scale and rota-tion invariant texture classification with local binary patterns. IEEE Transactions on
Pattern Analysis and Machine Intelligence, 24, 971–987.Ojansivu, V., & Heikkila, J. (2008). Blur insensitive texture classification using lo-
cal phase quantization. In International Conference on Image and Signal Processing(pp. 236–243).
Oliver, A., Lladó, X., Freixenet, J., & Martí, J. (2007). False positive reduction in mammo-
graphic mass detection using local binary patterns. Medical Image Computing andComputer-Assisted Intervention, 4791, 286–293.
Paci, M., Nanni, L., Lathi, A., Aalto-Setälä, K., & Hyttinen, J. (2013). Non-binary codingfor texture descriptors in sub-cellular and stem cell image classification. Current
Bioinformatics, 8, 208–219.Pacifici, F., & Chini, M. (2008). Urban land-use multi-scale textural analysis. In Proceed-
imgs of the ieee international geoscience and remote sensing symposium (pp. 342–
345).Pantic, I., Dacic, S., Brkic, P., Lavrnja, I., Pantic, S., & Jovanovic, T. (2014). Application
of fractal and grey level co-occurrence matrix analysis in evaluation of brain cor-pus callosum and cingulum architecture. Microscopy and Microanalysis: The Official
Journal of Microscopy Society of America, Microbeam Analysis Society, MicroscopicalSociety of Canada, 20(5), 1373–1381.
Pass, G., Zabih, R., & Miller, J. (1996). Comparing images using color coherence vectors.
ACM International Conference on Multimedia, 65–73.Rahtu, E., Heikkilä, J., Ojansivu, V., & Ahonen, T. (2012). Local phase quantization for
blur-insensitive image analysis. Image and Vision Computing, 30(8), 501–512.Rakwatin, P., Longepe, N., Isoguchi, O., Shimada, M., & Uryu, Y. (2010). Mapping tropical
forest using ALOS PALSAR 50 m resolution data with multiscale GLCM analysis.In Proceedings of the ieee international geoscience and remote sensing symposium
(pp. 1234–1237).
Ren, X.-M., Wang, X.-F., & Zhao, Y. (2012). An efficient multi-scale overlapped blockLBP approach for leaf image recognition. In Proceedings of the intelligent computing
theories and applications (pp. 237–243).Sastry, S. S., Kumari, T. V., Rao, C. N., Mallika, K., & Lakshminarayana, S. (2012). Transi-
tion temperatures of thermotropic liquid crystals from the local binary gray levelco-occurrence matrix. Advances in Condensed Matter Physics, 2012, 1–9.
ubrahmanyam, M. J., Wu, Q. M., Maheshwari, R. P., & Balasubramanian, R. (2013). Mod-ified color motif co-occurrence matrix for image indexing and retrieval. Computers
& Electrical Engineering, 39(3), 762–774.un, X., Wang, J., Chen, R., She, M. F. H., & Kong, L. (2012). Multi-scale local pattern co-
occurrence matrix for textural image classification. In Proceedings of the ieee worldcongress on computational intelligence (pp. 1–7).
wain, M. J., & Ballard, D. H. (1991). Color indexing. International Journal of ComputerVision, 7, 11–32.
an, X., & Triggs, B. (2007). Enhanced local texture feature sets for face recognition un-
der difficult lighting conditions. Analysis and Modelling of Faces and Gestures LNCS,4778, 168–182.
ang, X. (1998). Texture information in run-length matrices. IEEE Transactions On ImageProcessing, 7(11), 1602–1609.
uzel, O., Porikli, F., & Meer, P. (2006). Region covariance: a fast descriptor for detectionand classification. In Proceedings of the 9th european conference on computer vision
(pp. 589–600).
nay, D., & Ekin, A. (2008). Intensity versus texture for medical image search and re-trieval. In Proceedings of the 5th ieee international symposium on biomedical imaging:
from nano to macro (pp. 241–244).apnik, V., & Lerner, A. (1963). Pattern recognition using generalized portrait method.
Automation and Remote Control, 24, 774–780.apnik, V., & Chervonenkis, A. (1964). A note on one class of perceptrons. Automation
and Remote Control, 25.
écsei, A., Amann, G., Hegenbart, S., Liedlgruber, M., & Uhl, A. (2011). Automatedmarsh-like classification of celiac disease in children using local texture operators.
Computers in Biology and Medicine, 41, 313–325.u, N.-S. (2013). Exploring patterns of gradient orientations and magnitudes for
face recognition. IEEE Transactions on Information Forensics and Security, 8, 295–304.
u, N., Nguyen, T., & Garcia, C. (2014). Improving texture categorization with
biologically-inspired filtering. Image and Vision Computing, 32(6–7), 424–436.
alker, R., Jackway, P., & Longstaff, D. (2003). Genetic algorithm optimization of adap-tive multi-scale GLCM features. International Journal of Pattern Recognition and Ar-
tificial Intelligence, 17, 17–39.u, B., & Nevatia, R. (2005). Detection of multiple, partially occluded humans in a sin-
gle image by bayesian combination of edgelet part detectors. In Proceedings of the
IEEE International Conference on Computer Vision (pp. 90–97).hang, B., & Pham, T. D. (2011). Phenotype recognition with combined fea-
tures and random subspace classifier ensemble. BMC Bioinformatics, 12(1),128.
hao, L., Peng, T., Han, H., Cao, W., Lou, Y., & Xie, X. (2014). Fault condition recognitionbased on multi-scale co-occurrence matrix for copper flotation process. In Proceed-
ings of the 19th world congress of the international federation of automatic control
(pp. 7091–7097).