
kay/papers/ccgrid2008_stable_broadcast.pdf
43
A Stable Broadcast Algorithm Kei Takahashi Hideo Saito Takeshi Shibata Kenjiro Taura (The University of Tokyo, Japan) 1 2008 - , CCGr i d Ly o n France
-
Upload
hiroshi-ono -
Category
Technology
-
view
376 -
download
0
Transcript of kay/papers/ccgrid2008_stable_broadcast.pdf

A Stable Broadcast Algorithm Kei Takahashi Hideo Saito
Takeshi Shibata Kenjiro Taura (The University of Tokyo, Japan)
1 2008 - , CCGr i d Lyon Franc e
To distribute the same, but large data to many nodesEx: content delivery
Widely used in parallel processing
2
Broadcasting Large Messages
Data Data Data Data Data
< A Stable Broadcast Algorithm >Kei Takahashi, Hideo Saito, Takeshi Shibata and Kenjiro Taura
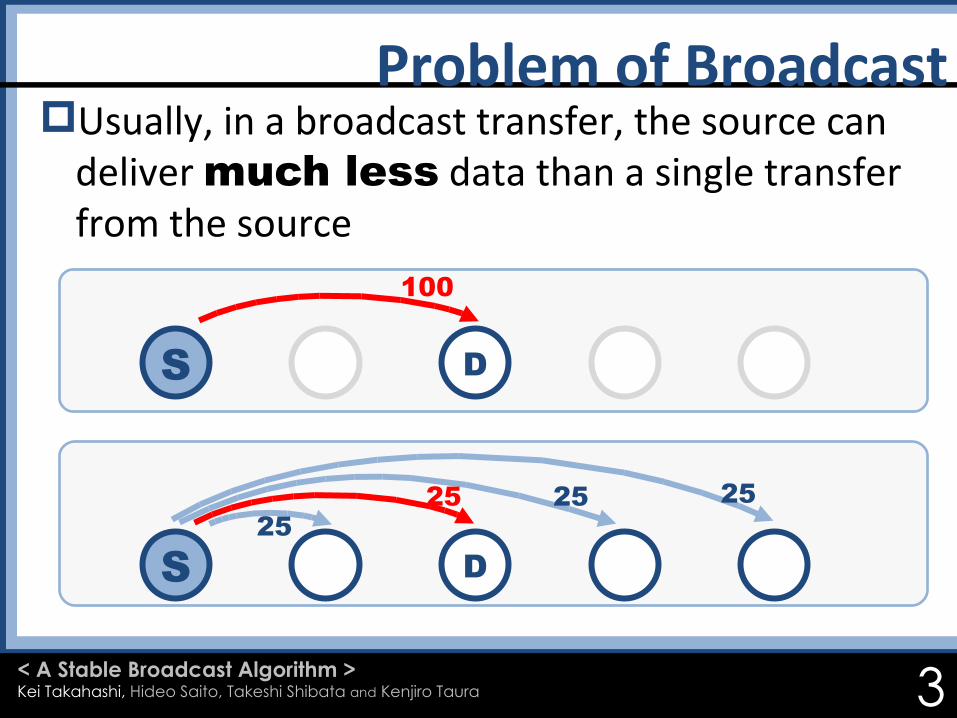
Usually, in a broadcast transfer, the source can deliver much less data than a single transfer from the source
3
Problem of Broadcast
S D
S D
100
2525
25 25
< A Stable Broadcast Algorithm >Kei Takahashi, Hideo Saito, Takeshi Shibata and Kenjiro Taura

Pipeline-manner transfers improve the performance
Even in a pipeline transfer, nodes with small bandwidth (slow nodes) may degrade receiving bandwidth of all other nodes
4
Problem of Slow Nodes
10 10
100
100 10010 10

p Propose an idea of Stable BroadcastIn a stable broadcast:Slow nodes never degrade receiving bandwidth to
other nodes
All nodes receive the maximum possible amount of data
Contributions
5

p Propose a stable broadcast algorithm for tree topologiesProved to be stable in a theoretical model
Improve performances in general graph networks
p In a real-machine experiment, our algorithm achieved 2.5 times the aggregate bandwidth
than the previous algorithm (FPFR)
Contributions (cont.)
6

IntroductionProblem SettingsRelated WorkProposed AlgorithmEvaluationConclusion
7
Agenda
< A Stable Broadcast Algorithm >Kei Takahashi, Hideo Saito, Takeshi Shibata and Kenjiro Taura

1. Target: large message broadcast
p Only computational nodes handle messages
8
Problem Settings
< A Stable Broadcast Algorithm >Kei Takahashi, Hideo Saito, Takeshi Shibata and Kenjiro Taura

1. Only bandwidth matters for large messages
(Transfer time) = (Latency) +
4. Bandwidth is only limited by link capacitiesAssume that nodes and switches have enough
processing throughput
9
Problem Settings (cont.)
(Message Size)(Bandwidth)50msec1Gbps
1GB
99%

1. Bandwidth-annotated topologies are given in advanceBandwidth and topologies can be rapidly inferred
- Shirai et al. A Fast Topology Inference - A building block for network-aware parallel computing. (HPDC 2007)
- Naganuma et al. Improving Efficiency of Network Bandwidth EstimationUsing Topology Information (SACSIS 2008, Tsukuba, Japan)
10
Problem Settings (cont.)
100 10
80
40 30

Previous algorithms evaluated broadcast by completion time
However, it cannot evaluate the effect of slowly receiving nodesIt is desirable that each node receives as much data
as possible
Aggregate Bandwidth is a more reasonable evaluation criterion in many cases
Evaluation of Broadcast
11

All nodes receive maximum possible bandwidthReceiving bandwidth for each node does not lessen
by adding other nodes to the broadcast
12
Definition of Stable Broadcast
D0 D1 D2 D3100 10 120 100
D2120Single
Transfer
Broadcast

Maximize aggregate bandwidth
Minimize completion time
13
Properties of Stable broadcast

IntroductionProblem SettingsRelated WorkProposed AlgorithmEvaluationConclusion
14
Agenda
< A Stable Broadcast Algorithm >Kei Takahashi, Hideo Saito, Takeshi Shibata and Kenjiro Taura
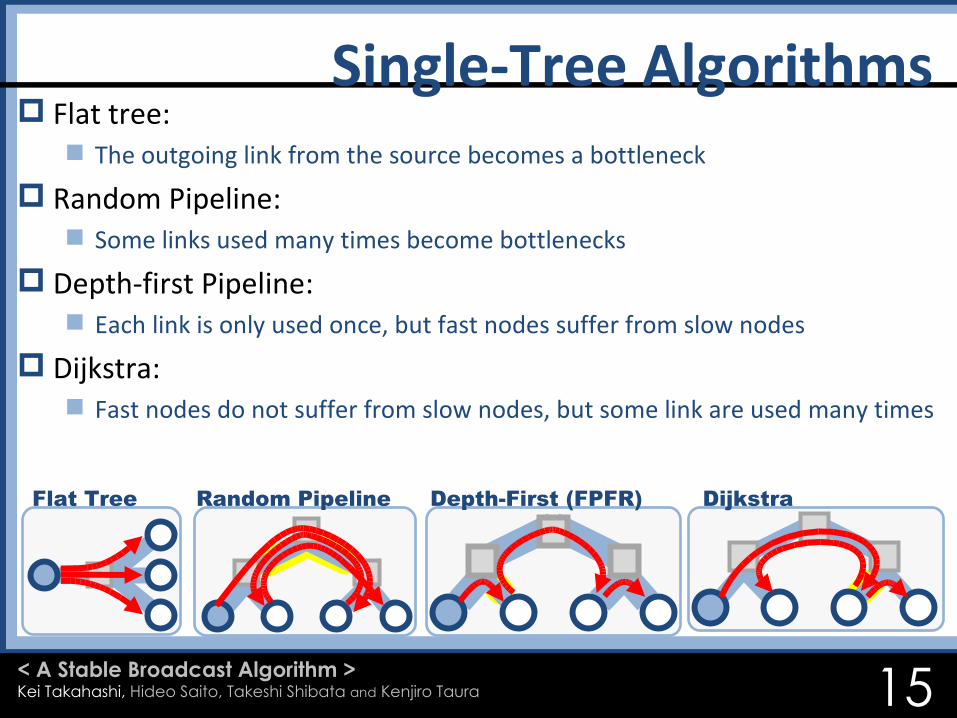
Flat tree: The outgoing link from the source becomes a bottleneck
Random Pipeline: Some links used many times become bottlenecks
Depth-first Pipeline: Each link is only used once, but fast nodes suffer from slow nodes
Dijkstra: Fast nodes do not suffer from slow nodes, but some link are used many times
Single-Tree Algorithms
15
Flat Tree Random Pipeline DijkstraDepth-First (FPFR)
< A Stable Broadcast Algorithm >Kei Takahashi, Hideo Saito, Takeshi Shibata and Kenjiro Taura

FPFR (Fast Parallel File Replication) has improved the aggregate bandwidth from algorithms that use only one tree
Idea: (1) Construct multiple spanning trees
(2) Use these trees in parallel
FPFR Algorithm [†]
16[†] Izmailov et al. Fast Parallel File Replication in Data Grid. (GGF-10, March 2004.)
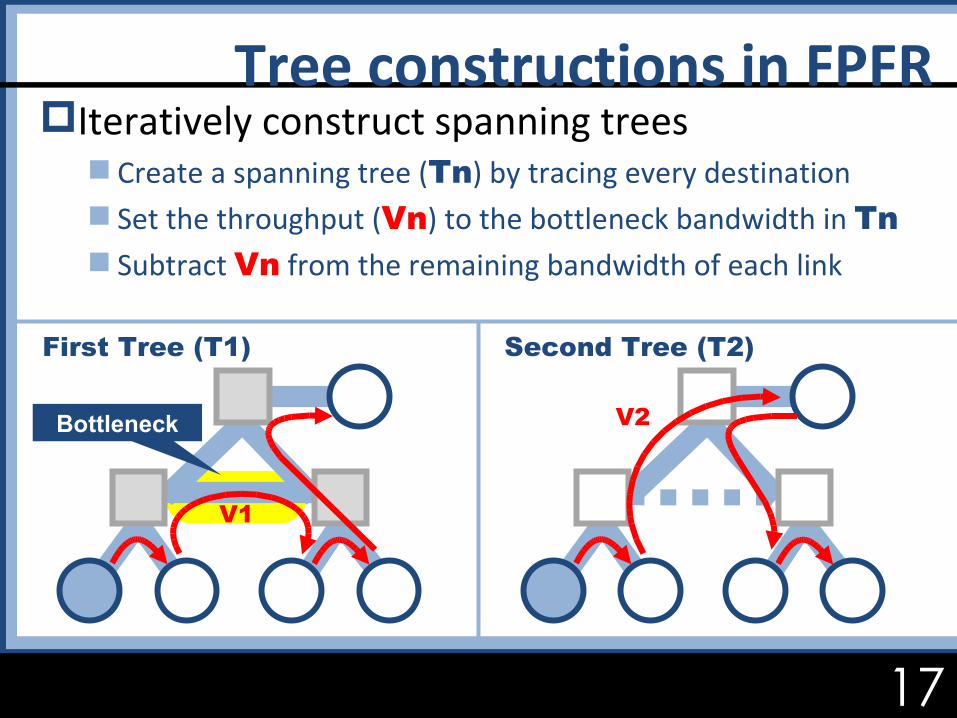
Iteratively construct spanning trees Create a spanning tree (Tn) by tracing every destination Set the throughput (Vn) to the bottleneck bandwidth in Tn Subtract Vn from the remaining bandwidth of each link
Second Tree (T2)
17
Tree constructions in FPFR
Bottleneck
First Tree (T1)
V1
V2
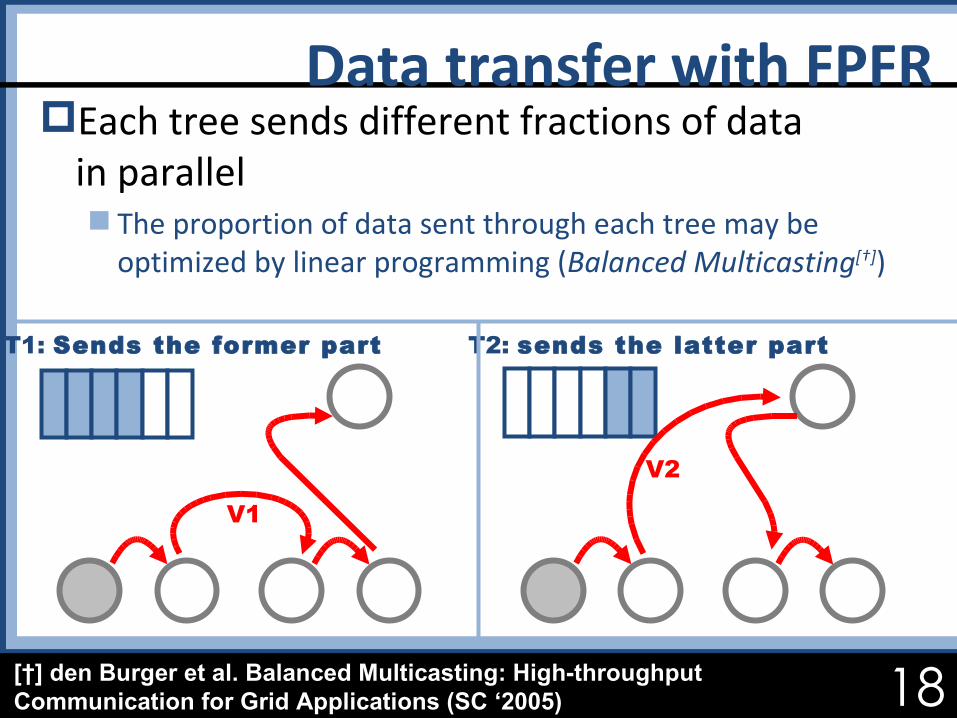
Each tree sends different fractions of data in parallel The proportion of data sent through each tree may be
optimized by linear programming (Balanced Multicasting[†])
18
Data transfer with FPFR
T1: Sends the former part T2: sends the latter part
[†] den Burger et al. Balanced Multicasting: High-throughput Communication for Grid Applications (SC ‘2005)
V1
V2

In FPFR, slow nodes degrade receiving bandwidth to other nodes
For tree topologies, FPFR only outputs one depth-first pipeline, which cannot utilize the potential network performance
Problems of FPFR
19
Bottleneck

IntroductionProblem SettingsRelated WorkOur AlgorithmEvaluationConclusion
20
Agenda
< A Stable Broadcast Algorithm >Kei Takahashi, Hideo Saito, Takeshi Shibata and Kenjiro Taura

Modify FPFR algorithmCreate both spanning trees and partial trees
Stable for tree topologies whose links have the same bandwidth in both directions
21
Our Algorithm
V
V
< A Stable Broadcast Algorithm >Kei Takahashi, Hideo Saito, Takeshi Shibata and Kenjiro Taura

22
T3: Third Tree(Partial Tree)
S A B C
T1: First Tree(Spanning)
S A B C
T2: Second Tree(Partial Tree)
S A B C
Iteratively construct trees Create a tree Tn by tracing
every destination Set the throughput Vn to the
bottleneck in Tn Subtract Vn from the
remaining capacities
Tree Constructions
V1
V2 V3
Throughputof T1

Send data proportional to the tree throughput VnExample:
Stage1: use T1, T2 and T3 Stage2: use T1 and T2 to send data previously sent by T3Stage3: use T1 to send data previously sent by T2
Data Transfer
23
A BS CT1
T2
T3
A BS CT1
T2
A BS CT1(V1)
(V2)
(V3)

p Our algorithm is Stable for tree topologies (whose links have the same capacities in both directions) Every node receives maximum bandwidth
p For any topology, it achieves greater aggregate bandwidth than the baseline algorithm (FPFR) Fully utilize link capacity by using partial trees
4. It has small calculation cost to create a broadcast plan
Properties of Our Algorithm
24

IntroductionProblem SettingsRelated WorkProposed AlgorithmEvaluationConclusion
25
Agenda
< A Stable Broadcast Algorithm >Kei Takahashi, Hideo Saito, Takeshi Shibata and Kenjiro Taura

Simulated 5 broadcast algorithms using a real topology
Compared the aggregate bandwidth of each methodMany bandwidth distributionsBroadcast to 10, 50, and 100 nodes10 kinds of conditions (src, dest)
(1) Simulations
26
… …
… …110 nodes 81 nodes
36 nodes 4 nodes
< A Stable Broadcast Algorithm >Kei Takahashi, Hideo Saito, Takeshi Shibata and Kenjiro Taura

Compared Algorithms
27
Flat Tree Random
Dijkstra Depth-First (FPFR)
… and OURS

Mixed two kinds of Links (100 and 1000) Vertical axis: speedup from FlatTree 40 times more than random,
3 times more than depth-first (FPFR) with 100 nodes
Result of Simulations
28
100
100 100
1000
1000 1000

Tested 8 bandwidth distributions Uniform distribution (500-1000) Uniform distribution (100-1000) Mixed 100 and 1000 links Uniform distribution (500-100) between switches
(for each distribution, tested two conditions that bandwidth of both directions are the same and different)
Our method achieved the largest bandwidth in 7/8 cases Large improvement especially in large bandwidth variance In a uniform distribution (100-1000) and link bandwidth in two
directions are different, Dijkstra achieved 2% more aggregate bandwidth
Result of Simulations (cont.)
29

Performed broadcasts in 4 clustersNumber of destinations:10, 47 and 105 nodesBandwidths of each link: (10M - 1Gbps)
Compared the aggregate bandwidth in 4 algorithms1.Our algorithm
2.Depth-first (FPFR)
3.Dijkstra
4.Random (Best among 100 trials)
(2) Real Machine Experiment
30

Theoretical Maximum Aggregate Bandwidth
31
Also, we calculated the theoretical maximum aggregate bandwidthThe total of the receiving bandwidth in a case of
separate direct transfer from the source to each destination
D0 D1 D2 D3100 10 120 100
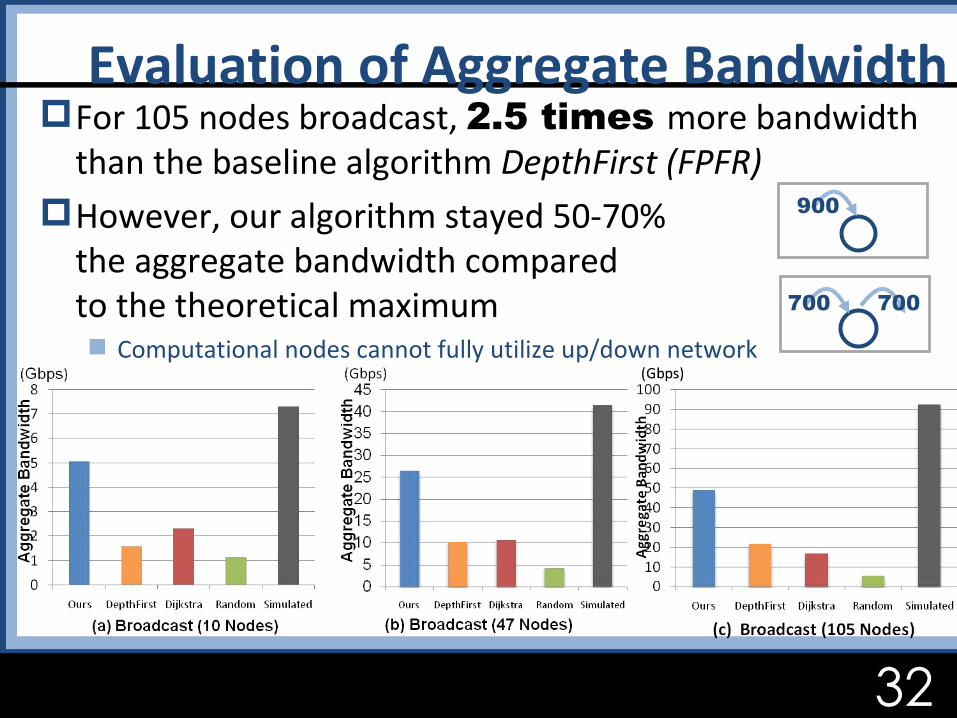
For 105 nodes broadcast, 2.5 times more bandwidth than the baseline algorithm DepthFirst (FPFR)
However, our algorithm stayed 50-70% the aggregate bandwidth compared to the theoretical maximum Computational nodes cannot fully utilize up/down network
Evaluation of Aggregate Bandwidth
32
700 700
900

Compared aggregate bandwidth of 9 nodes before/after adding one slow node Unlike DepthFirst(FPFR), existing nodes do not
suffer from adding a slow node in our algorithm Achieved 1.6 times bandwidth than Dijkstra
Evaluation of Stability
33
Slow

IntroductionProblem SettingsRelated WorkOur AlgorithmEvaluationConclusion
34
Agenda
< A Stable Broadcast Algorithm >Kei Takahashi, Hideo Saito, Takeshi Shibata and Kenjiro Taura

Introduced the notion of Stable BroadcastSlow nodes never degrade receiving bandwidth of
fast nodes
Proposed a stable broadcast algorithm for tree topologiesTheoretically proved2.5 times the aggregate bandwidth
in real machine experimentsConfirmed speedup in simulations
with many different conditions
35
Conclusion
< A Stable Broadcast Algorithm >Kei Takahashi, Hideo Saito, Takeshi Shibata and Kenjiro Taura

Algorithm that maximizes aggregate bandwidth in general graph topologies
Algorithm that changes relay schedule by detecting bandwidth fluctuations
Future Work
36< A Stable Broadcast Algorithm >Kei Takahashi, Hideo Saito, Takeshi Shibata and Kenjiro Taura

Algorithm that maximizes aggregate bandwidth in general graph topologies
Algorithm that changes relay schedule by detecting bandwidth fluctuations
Future work
37

All the graphs
38
0
10
20
30
40
50
60
70
80
10 50 100
Relative Performance
Number of Destinations
(a) [Low Bandwidth Variance](Symmetric)
OursDepthfirst DijkstraRandom (best)Random (avg)
0
5
10
15
20
25
30
35
40
10 50 100
Relative Performance
Number of Destinations
(g) [Random Bandwidth among Clusters](Symmetric)
OursDepthfirst DijkstraRandom (best)Random (avg)
0
5
10
15
20
25
30
35
10 50 100
Relative Perforamance
Number of Destinations
OursDepthfirst DijkstraRandom (best)Random (avg)
(h) [Random Bandwidth among Clusters](Asymmetric)
0
10
20
30
40
50
60
70
10 50 100
Relative Performance
Number of Destinations
(b) [Low Bandwidth Variance](Asymmetric)
OursDepthfirst DijkstraRandom (best)Random (avg)
0
5
10
15
20
25
30
35
40
45
10 50 100
Relative Performance
Number of Destinations
(c) [High Bandwidth Variance](Symmetric)
OursDepthfirst DijkstraRandom (best)Random (avg)
0
5
10
15
20
25
10 50 100
Relative Performance
Number of Destinations
(d) [High Bandwidth Variance](Asymmetric)
OursDepthfirst DijkstraRandom (best)Random (avg)
0
5
10
15
20
25
30
35
40
45
10 50 100
Relative Performance
Number of Destinations
(e) [Mixed Fast and Slow links](Symmetric)
OursDepthfirst DijkstraRandom (best)Random (avg)
0246
8101214
161820
10 50 100
Relative Performance
Number of Destinations
(f) [Mixed Fast and Slow links](Asymmetric)
OursDepthfirst DijkstraRandom (best)Random (avg)
0
2
4
6
8
10
12
(1,10) (2,20) (3,30) (4,40) (5,50)
Relative Performam
OursDepthfirst Dijkstra
(# of srcs, # of dests)
(i) [Mulrtiple Souces](Low Bandwidth Variance,Symmetric)
Random (best)Random (avg)

BitTorrent gradually improves the transfer schedule by adaptively choosing the parent node
Since relaying structure created by BitTorrent has many branches, these links may become bottlenecks
39
Broadcast with BitTorrent [†]
[†] Wei et al. Scheduling Independent Tasks Sharing Large Data Distributed with BitTorrent. (In GRID ’05)
Transfer tree snapshot
BottleneckLink

Uniform distribution (100-1000) between switches Vertical axis: speedup from FlatTree 36 times more than FlatTree,
1.2 times more than DepthFirst (FPFR) for 100-nodes broadcast
Simulation 1
40
1000 1000
100~1000 100~1000

Trace all the destinations from the sourceSome links used by many transfers
become bottlenecks
41
Topology-unaware pipeline
Bottleneck

Construct a depth-first pipeline by using topology information Avoid link sharing by using each link only once Minimize the completion time in a tree topology
Slow nodes degrade the performance of other nodes
42
Depth-first Pipeline
Slow Node
[†] Shirai et al. A Fast Topology Inference - A building block for network-aware parallel computing. (HPDC 2007)

Construct a relaying structure in a greedy manner Add a node reachable in the maximum bandwidth one by one Effects of slow nodes are small
Some links may be used by many transfers, may become bottlenecks
Dijkstra Algorithm [†]
43[†] Wang et al. A novel data grid coherence protocol using pipeline-based aggressive copy method. (GPC, pages 484–495, 2007)
Bottleneck Link


















