
High Availability and Disaster Recovery with Libelle … Availability and Disaster Recovery with...
22
© Libelle AG. All rights reserved. WHITE PAPER High Availability and Disaster Recovery with Libelle BusinessShadow ® Libelle AG has been providing High Availability (HA) and Disaster Recovery (DR) Solutions to the enterprise market for over a decade. With more than 1,000 insta- llations at almost 400 customer sites worldwide, Libelle demonstrated its ability to successfully serve the most complex requirements. This White Paper presents the basics of High Availability and Disaster Recovery and the technology that supports the flagship Libelle mirroring solution BusinessShadow ® for HA and DR. It includes an overview on how the solution is positioned in the enterprise market as well as important considerations for setting up replication solutions for the Enterprise IT.
Transcript of High Availability and Disaster Recovery with Libelle … Availability and Disaster Recovery with...

©Libelle AG. All rights reserved.
WHITE PAPER
High Availability and Disaster Recovery with Libelle Business Shadow®
Libelle AG has been providing High Availability (HA) and Disaster Recovery (DR) Solutions to the enterprise market for over a decade. With more than 1,000 insta-llations at almost 400 customer sites worldwide, Libelle demonstrated its ability to successfully serve the most complex requirements.
This White Paper presents the basics of High Availability and Disaster Recovery and the technology that supports the flagship Libelle mirroring solution Business Shadow® for HA and DR. It includes an overview on how the solution is positioned in the enterprise market as well as important considerations for setting up replication solutions for the Enterprise IT.

WHITE PAPER
©Libelle AG. All rights reserved. April 18 2 / 22
1. Introduction
High Availability and Disaster Recovery are often used as loose terms within IT specifi-cations, designs and solutions. To level the playing field, this White Paper first outlines the framework of terms and our perspective of methods to give a better understanding of the information presented.
1.1. Terminology The terms ‘High Availability’ (HA) and ‘Disaster Recovery’ (DR) will be extensively used in this White Paper. The architectures we are developing throughout this document are presenting both, HA and DR scenarios. Our experience shows that even professionals are sometimes unclear about a terms’ reach or even mix them up altogether. As the terms define the scope of projects we want to be clear about the specifics:
• High Availability (HA) includes all tools, policies, and procedures to ensure local availability of computer systems including the protection against local hardware failures and software/user error. Tools to provide HA are typically Server or Database Clusters, redundant components, Storage Area Networks for hardware failures and backup/recover standby database for software errors, user errors, or data corruption.
• Disaster Recovery (DR) includes all tools, policies, and procedures to ensure IT operation after a total or partial site failure. Tools providing DR capabilities are typically backup and recovery with access to a new location (‘cold standby’) or live data replication and failover to a pre-configured secondary site (‘warm standby’ or ‘hot standby’).
• In addition, the term ‘Business Continuity Planning’ (BCP) is used as a term for the organizational side of Disaster Recovery: Roles, responsibility and the organizational model including a preceding Business Impact Analysis.
The Libelle Business Shadow software solution addresses both HA and DR requirements and we outline possible scenarios for each next.
1.2. High Availability Generally, High Availability scenarios can be categorized into two groups: Hardware-related issues and software/user related issues causing potential system downtime. On the hardware side, downtime became less of an issue as hardware technology evolved into providing nearly fault-tolerant systems.
However, hardware availability has less to do with availability of the critical applications themselves. A hardware or database cluster may provide failover capabilities between systems within seconds, but the application might take a while to be fully available again.
Software- and user-related incidents are a cause for concern as they often cause a majority of downtime incidents. Especially with growing complexity of inter-dependent hardware and software components, the overall availability of systems is constantly at risk. Based on our experience we say that IT systems are far from 99.999% available.

WHITE PAPER
©Libelle AG. All rights reserved. April 18 3 / 22
1.3. Disaster Recovery In addition to local issues such as server issues or software/user issues, the Disaster Recovery Scenario is targeting events like fire, flood, terrorist attacks, or wide-spread te-lecommunication and power outages.
Disaster Recovery and High Availability are seen as diametrically proportional in regards to their probability and impact: Local issues (HA) might happen quite often, but can be covered and fixed fairly quickly with minimum impacts. On the other hand, a Disaster Re-covery incident has low probability, but presents tremendous impacts as the complete production site becomes unavailable.
2. Scoping HA and DR
This White Paper focuses on the Technical Architecture of High Availability and Disaster Recovery Solutions. Before outlining the architecture, a clear project scope needs to be defined.
2.1. Enterprise IT Architecture Generally, Enterprise IT is the sum of a variety of infrastructure, networking, storage, and server components to support Enterprise Applications such as ERP solutions from SAP AG, Oracle, Microsoft, Infor and many more with typically hundreds or thousands of users. The foundation of these applications are mainly medium to high-end UNIX or Windows Server running databases such as IBM DB2, MaxDB, MySQL, Microsoft SQL Server, and Oracle.
The Enterprise IT Archi-tecture illustrates the critical components for both High Availability and Disaster Recovery.
From a Disaster Recovery perspective, all components to support the business process-es must be made partially or fully available at an alternate site. Except for infrastructure and the Business Components detailed different approaches on protecting each component will be presented later on.

WHITE PAPER
©Libelle AG. All rights reserved. April 18 4 / 22
From a High Availability perspective, many factors come into play. First line of defense to provide 24/7 availability is the provision of redundancy. Many medium- and high end components can provide built-in redundancy so that a failure of a storage controller, a CPU, or a single disk, won’t even be noticeable.
The second step for High Availability is to provide the same component twice, even if they are already have redundancy built in. For example a Cluster Software Solutions provides server failover capabilities in case of a total server failure. Combining such a solution with locally mirrored storage and redundant paths between server and storage, the failover to new systems can happen within a relatively short period of time. Middleware, databases, and applications became relatively cluster-aware, so that an application can be made available on different hardware typically within less than five to ten minutes depending on the application.
However, Hardware Redundancy will not protect against the number one downtime cause of user and software errors as data corruption and faulty operation/configurations will spread throughout the landscape.
2.2. Recovery Point Objectives Both, HA and DR projects start with the question of the potential data loss in case of an incident (Recovery Point Objective or “RPO”) and the time necessary to have the sys-tems up and running on the Mirror System (Recovery Time Objective or “RTO”). The dif-ference between HA and DR is that local failures have typically faster response and failover times as the servers are locally available and in the same network.
Recovery Point Objectives can range from zero in a synchronous replication setup, to a couple of minutes in an asynchronous replication setup or with log shipping.
2.3. Recovery Time Objectives The Recovery Time Objective is the amount of time it takes until the application is made available after a component failure. Failover may happen automatically in HA settings or partially automated after a Disaster Declaration in DR settings.
For an HA scenario, RTO’s can be zero or near-zero, if the application allows redundant components such as multiple database servers in a RAC setting or multiple application servers where users log on to the next available server. However, many applications require a reboot after starting on a different server and RTO can range between 5 and 15 minutes.
For a DR scenario, RTO’s are typically higher because a complete data center with inter-dependent systems is moved to a new site and in many cases into a separate network segment. With hot-standby mirrors it is possible to reach 2-4 hours Recovery Time Objectives if the procedures and technologies are in place.
2.4. Recovery Consistency Objectives A third, more recent addition to traditional RTO and RPO goals, is the Recovery Consistency Objective. RCO applies data consistency objectives to the DR and HA architecture. Following the definitions for RPO and RTO, RCO defines a measurement for the consistency of distributed business data within interlinked systems after a disaster incident. The next illustration outlines the relation between RPO, RTO, and RCO.

WHITE PAPER
©Libelle AG. All rights reserved. April 18 5 / 22
Recovery Point, Recov-ery Time, and Recovery Consistency Objectives compared
3. Replication Basics
The general concept of any replication solution is to provide copies of critical production data and applications to one or multiple Mirror Systems in the same location (High Avai-lability) or at a different location (Disaster Recovery). In an emergency situation, the Mir-ror Systems are taking over the applications and users can login to the Mirror System.
Most replication solu-tions are setup to have one active and one passive node.
There are active/active replication solutions, but as long as the applicati-on itself is not designed to support such a setup the requirement is active/passive.

WHITE PAPER
©Libelle AG. All rights reserved. April 18 6 / 22
3.1. Database Layer, File Layer, and Storage Layer Applications are primarily based on databases and dedicated flat files (application binaries, configuration data, and any critical data not stored in a database). The database itself is again based on flat files which are managed by the database software. A layer below, a storage controller and/or storage systems are managing how these files are stored and retrieved from the storage systems.
Different Methodologies mirror systems on dif-ferent layers.
Database Layers for example guarantee Database-Level Integrity while Storage-Layer only guarantee Storage-Level Integrity
Next, we apply this layer model to synchronous and asynchronous replication and compare different layers of mirroring methods. It is crucial to understand how applications operate and store their data throughout the layers in order to have usable applications and application data upon failover. Replication can be done on any of these layers. A storage replication would focus on mirroring and integrity of Storage Blocks, while a File Replication would do the same for files, and a Database Replication Solution would focus on the database.
3.2. Synchronous Replication With a guaranteed 100% synchronous replication, the layer on which data gets replicated is relatively irrelevant as e.g. synchronicity on a storage level will propagate all the way to the application level.1 This makes local High Availability Solutions such as Server Clusters with redundant storage a very popular solution. There are varying concepts such as Hardware Cluster (e.g. IBM HACMP, HP MC/SG, etc.), Database Cluster (Real Application Cluster, Direct Partitioning Features), Application-based dual-writes of data or a combination of them.
For DR, 100% Synchronous Replication is many times neither achievable (because of high network latency and bandwidth restraints when mirroring over large distances) nor desirable (adding complex infrastructure and performance restraints on the Production System). DR architectures are typically based on Asynchronous Replication.
1 There are various, more detailed considerations for the local failover with synchronous replications which we do not elaborate on for simplicity reasons.

WHITE PAPER
©Libelle AG. All rights reserved. April 18 7 / 22
As for High Availability, synchronous replication is not covering the software/user error, or data corruption. This is the reason why customers implement time-delayed mirroring to cover these incidents. The differences are illustrated in the following table:
Synchronous Replication Time-Delayed Replication Covering Hardware Errors?
yes yes
Covering Software Errors?
no yes
Covering User/ Op-erating Errors?
no yes
Covering Data Cor-ruptions?
no Yes
3.3. Asynchronous Replication The moment we start to replicate data asynchronously, it is of uttermost importance on which layer (Application/Database/File/Storage Layer) the replication is operating and if any consistency considerations on the Application Level are in place. Asynchronously mirrored storage blocks for example won’t make a file-consistent, database-consistent or application-consistent replication. With a block-based, asynchronous Replication the Mirror System is almost guaranteed to be in an inconsistent state from an Application Perspective:
1. Assume storage blocks are mirrored with storage-level consistency points. 2. Files consist of multiple storage blocks: Files might be inconsistent. 3. Databases consist of multiple files: Database is likely to be inconsistent. 4. Applications consist of multiple databases: Application is likely to be inconsistent. 5. Business Processes consist of multiple applications: Processes will be inconsistent.
Bottom line is, no block-level consistent asynchronous replication will make an applica-tion-level consistent mirror.
4. Business Shadow® Overview
Libelle Business Shadow is a software solution to mirror applications on the Database Layer (DBShadow) and File Layer (FSShadow). It is extended with automating the Appli-cation Failover (Switch Application) and a special edition for WAN Replication (Option Long Distance). Business Shadow is used for High Availability, Disaster Recovery, and various combinations of both.
4.1. Software Components Libelle Business Shadow is a wrapper term for the core mirroring components. In detail, these components are:
• DBShadow provides dedicated Editions for IBM DB2, MaxDB, Microsoft SQL Server, MySQL, and Oracle. It is used to mirror the core Application Databases.

WHITE PAPER
©Libelle AG. All rights reserved. April 18 8 / 22
• FSShadow is used to mirror critical Application Data not held in the Database for example Application Binaries, profile data, EDI interface data, or other application-specific flat files.
• Switch Application is used to activate and de-activate application IP addresses, host-names, and can automate other application-specific failover tasks.
• Option Long Distance extends the basic mirroring capabilities functionality of DBShadow and FSShadow to support Wide Area Network settings.
Overview of the core Business Shadow Com-ponents
All components are available specific to the respective Operating System which can be HP-UX, IBM AIX, Solaris, Tru64 UNIX, most Linux Distributions, and all Windows Plat-forms. The majority of implementations by Libelle AG are mirroring applications by SAP AG with a special Business Shadow Edition for SAP Solutions. Other implementations include Oracle, Microsoft Dynamics, ERP Solutions by Infor Global Solutions, and many other applications.
4.2. Solution Design
4.2.1. DBShadow and FSShadow
The architecture of the main Business Shadow components DBShadow and FSShadow are designed that each single mirror consists of one Production System and one or more Mirror System.

WHITE PAPER
©Libelle AG. All rights reserved. April 18 9 / 22
DBShadow and FSShadow Server Agents are commu-nicating with each other and a GUI which allows central management and monitoring of operation.
After a replication is built initially between the two systems with an ‘Initial Copy’, an ‘Archiver’ process picks up database and flat file changes from the Production System and ships them to the Mirror System using the Libelle TCP/IP stacks. The Archiver is customized to application requirements and Recovery Point Objectives. It can be set to kick in e.g. every 5 or 10 minutes. A Recovery Process running on the Mirror System is applying the changes it receives from the Archiver process and applies them into a mirror database (DBShadow) or into a mirror file system (FSShadow). All processes can operating independently if one or the other system is temporarily unavailable and will pick up as soon as the link is re-established, but generally depend on each other for a coherent HA and DR operation.
The software itself is based on low foot-print Server Agents (Shared Memory for UNIX, Services for Windows) residing on each host. The Agents are communicating with each other via specialized network sockets. A secure Libelle GUI can intercept the communi-cation and manages one or multiple mirrors across an Application Landscape.
The day-to-day replication operation is then based on the Archiver and Recover Proces-ses running continuously which are monitored by the GUI. Irregularities in operation will be logged on the server and sent to GUI and/or other System Management tools.
4.2.2. Option Long Distance
An additional component of Business Shadow is the Option Long Distance to extend the basic TCP/IP compressed data transfer with additional compression, parallelism and packet configurations to suit large distances between a production and a mirror system with typically high network latency.
4.2.3. Switch Application
Finally, the component Switch Application can manage the failover of IP-Addresses between the two systems, so that an additional virtual Hostname or IP Address on a Pro-duction System is moved seamlessly to a Mirror System as part of the failover process.

WHITE PAPER
©Libelle AG. All rights reserved. April 18 10 / 22
Switch Application provides a solution to add and remove Virtual IPs and Hostnames automatically upon failover of DBShadow or FSShadow.
4.2.4. Graphical User Interface (GUI) Management C onsole
To allow a single point of control for the administrator, Libelle provides a Graphical User Interface (GUI) which communicates to any number of Server Agents. The GUI is the central component to setup, control, and operate mirrors. It also provides a simple gra-phical interface to perform Emergency Failovers or Disaster Recovery Tests. As the Server Agents are doing the replication tasks, the GUI is only for monitoring and opera-tion, but not an active part of the replication process.
The Libelle Server Agents themselves act independently and can send out SMTP traps or other messages and are manageable by Command Line, as well.
Business Shadow GUI
This example displays six system groups on the left, with the ‘Production’ group in the middle.
Each group holds multi-ple mirrors.
The green checkmark an ‘ok’ status. The red X illustrates ‘errors’ (e.g. database down). Yellow explanation mark illus-trate ‘warnings’ (e.g. running out of disk space),

WHITE PAPER
©Libelle AG. All rights reserved. April 18 11 / 22
4.3. High Availability Scenarios Business Shadow for High Availability can provide a locally replicated Mirror Systems for any Production System. The software can be used as a no-data loss failover solution to a Mirror System with a shared storage, or minimum data loss solution without a shared storage.
The primary HA Business Shadow implementation is the concept of a time-delayed mir-ror to protect against Software and User Errors. The architecture is based on an intenti-onally time-delayed mirror between the two systems. Changes of a Production System are applied to the Mirror System with a time-delay of e.g. 2 or 4 hours to allow a reaction window in case of corruption caused by Software Errors, User Errors, Configuration Errors, poorly planned or executed System Updates, and other situations leading to corrupt or unusable data.
DBShadow and FSShadow during normal operation. Transactions are queued on the Mirror System before they are applied to allow a reaction window for corrupt data
Now if a software or user error is corrupting e.g. the Production Database, the Mirror Database is still e.g. four hours behind and has a queue of four hours waiting in the Mirror System’s File System. For a fast restore, the Administrator will use the Business Shadow GUI or the Shell Interface for an automated recovery up to any time-stamp before the error occurred. Four hours’ worth of transactions can typically be applied within less than 20 minutes depending on the hardware performance. Comparing this to the alternative of a full restore from tape, this methodology is the fastest possible way to restore a system after corruption.
DBShadow and FSShadow during emer-gency operation caused by data corruption
The Mirror System provides the Application with pre-corruption data in a consistent state.
Generally we are targeting Recovery Time Objectives (failover time) which includes restarting the application of less than 25-40 minutes in case of a corrupted Production

WHITE PAPER
©Libelle AG. All rights reserved. April 18 12 / 22
System caused by software or user errors with a typical 4 hours delay. For no-time delay implementations, Recovery Time Objectives are typically less than 10-15 minutes.
Recovery Point Objectives (data loss) are again varying depending on the time-delay. For a Software Error, our intention is to go back in time, so it can range from up to the last e.g. five minutes to up to 4 hours. Whatever the Libelle Administrator wants or does not want to recover. Once the administrator decided on the time-stamp, all database re-lated tasks (recovery, database rename, locally managed tablespaces, etc.) are fully automated.
For a no-data-loss failover, the last 5 or 10 minutes of Online Logs which may not be shipped are located on a shared storage which the Mirror System can access.
4.4. Disaster Recovery Scenarios The second application of Business Shadow is to serve as a full-fledged Disaster Reco-very solution. The low-impact Server Agents and low network requirement makes the solution suitable to mirror any size environment to a remote location. Libelle installations for Disaster Recovery range from a single Application Mirror with e.g. 400 GB mirrored over a 3Mbit/s VPN network to large 20-30 TB landscapes with dozens of applications mirrored across a dedicated 100 Mbit/s WAN link.
The methodology is similar to a High Availability Implementation except that the time-delay is less significant. The Archiver is usually set low enough to meet given Recovery Point Objectives (e.g. maximum data loss of 10-15 minutes in case of a site failure), but also high enough not to impact performance on the Production System (synchronously updating the mirror system would require too much performance overhead on Network and Server).
Either way, with Business Shadow mirroring the Application Landscape for any number of Systems, a comprehensive Disaster Recovery Standby System is in place and constantly updated with fresh production data. Failover during emergencies and yearly Disaster Recovery tests are highly automated.
4.5. Integration in SAP Solutions
4.5.1. Libelle’s Commitment to the SAP Market
Libelle has been providing its software solutions to the SAP market since the late 90s. The very first supported database has been Oracle 6 and as a company located in Germany we had always access to a large base of SAP customers early on. After adding support for IBM’s DB2, MaxDB, and Microsoft’s SQL Server, Libelle supports all common SAP environments. SAP Applications now make 80% of Libelle’s customer base. In 2009, Libelle acquired a majority interest in a Germany-based SAP Basis Consulting firm to boost its exposure in the SAP Basis market.
4.5.2. SAP Landscape Requirements
With the latest NetWeaver architecture, SAP AG provides a highly sophisticated Service Oriented Architecture. Additional functionalities added a high degree of complexity in technical design and operating, especially when comparing it to earlier SAP R/3 based on single-stack ABAP installation with one or two SAP instances.
Unless we implement a 100% synchronous replication, any application-agnostic replica-tion solution (e.g. block-based replication) which is not tightly integrated into the SAP Netweaver Architecture, will cause issues upon failover. Also database-only solutions

WHITE PAPER
©Libelle AG. All rights reserved. April 18 13 / 22
(Log Shipping) will omit the large amount of data stored in flat files and have issues getting a replicated solution up and running on a Mirror System.
The following illustration shows how Libelle Business Shadow is typically integrated into a single SAP Instance. While the illustration shows a single-node Production System, most customer systems are based on two-node cluster systems.
Business Shadow Integration into typical SAP Instance
Finally, most SAP Installations are based on multiple systems. Part of the replication project is to develop and extensively test a blueprint for one installation and then replicate the blueprint across the landscape either by repeating the installation or with an automated deployment process depending on the project size.
5. Business Shadow Technology
5.1. Core Server Agents The core components of Libelle Business Shadow are based on low foot-print Server Agents running on the Production and Mirror System. The Libelle Agents are hard-coded in C and C++ and run as Shared Memory Process in UNIX environments and as Service for Windows Systems.
The agents came to live as basic TCP/IP socket daemons in DBShadow Version 1.0 for Oracle in 1996. Today’s code in Versions 4.5, 4.8, and 5.x are containing over 14 years of development, enhancements, and have been deployed and operating in over 1000 small, medium-sized and high-end installations. Today, they are actively mirroring environments from smaller 100GB database mirrors up to single 18TB database mirrors in either single-instance installations or multi-system landscapes with 50+ servers in all imaginable UNIX and Windows settings.

WHITE PAPER
©Libelle AG. All rights reserved. April 18 14 / 22
DBShadow and FSShadow Server Agents are communica-ting with own TCP/IP sockets.
Illustration shows core processes ‘Initial Copy’, ’Archiver’, and ‘Structure’ Processes on Production and ‘Recover’ Process running on mirror.
After fail-over, the roles are reversed and repli-cation goes into the opposite direction.
The Server agents are managing communication between the two systems and are con-trolled by a Command Line or Graphical User Interface. They hold information about the current activities in the Shared Memory which can be accessed from both sides.
Every process contains ‘main processes’ which are starting, stopping, and managing ‘Son Processes’ that execute dedicated tasks. For example:
• DBShadow for HP-UX Archiver Process starts, stops, and monitors the copy of an Oracle 11i log file to its Mirror System.
• DBShadow for Windows Recover Process applies and monitors the recovery of Transaction Log Files Backups with a certain time-delay into its Mirror System.
• FSShadow for IBM AIX Archiver Process checks the defined flat file list on a Production System every 20 minutes and copies the changes to a its Mirror System.
• DBShadow for Solaris Structure Process checks the Oracle database for no-logging transaction, new data files - or new directories - and updates the Mirror accordingly.
• DBShadow for IBM AIX Recover Process performs a Point-In-Time Recovery for a DB2 database upon failover.

WHITE PAPER
©Libelle AG. All rights reserved. April 18 15 / 22
Illustration shows a GUI screenshot of Shared Memory retrieved from a Mirror System. The same information can be retrieved from the server via a shell command.
As the name implies, the information it is held in memory of both Produc-tion and Mirror System.
This allows continuing Mirror Operation after any interruption as information is held in both systems.
Key to the operation of the Server Agents is their robustness as they run 24/7, 365 days and are designed to survive server reboots, extended network outages, or other typical disturbances in a LAN or WAN operation. In the following paragraphs, we will look in detail into the processes and how they interact with the environment to enable a replication setup.
5.2. Database Mirroring Database Replication with Libelle DBShadow is based on the following steps:
• Create an Initial Copy of a Production Database from the Production System to its Mirror System.
• In customizable intervals, for example every 10 minutes, check the Production Database for changes in form of Offline Log Files and ship changes to the Mirror System with an Archiver Process.
• Continuously apply the changes from the Production Database into the Mirror Database with a customizable time delay.
• In customizable intervals, for example every 2 hours, check the Production Database for new data files, no-logging transactions, new directories, and update the Mirror Database with the changes.
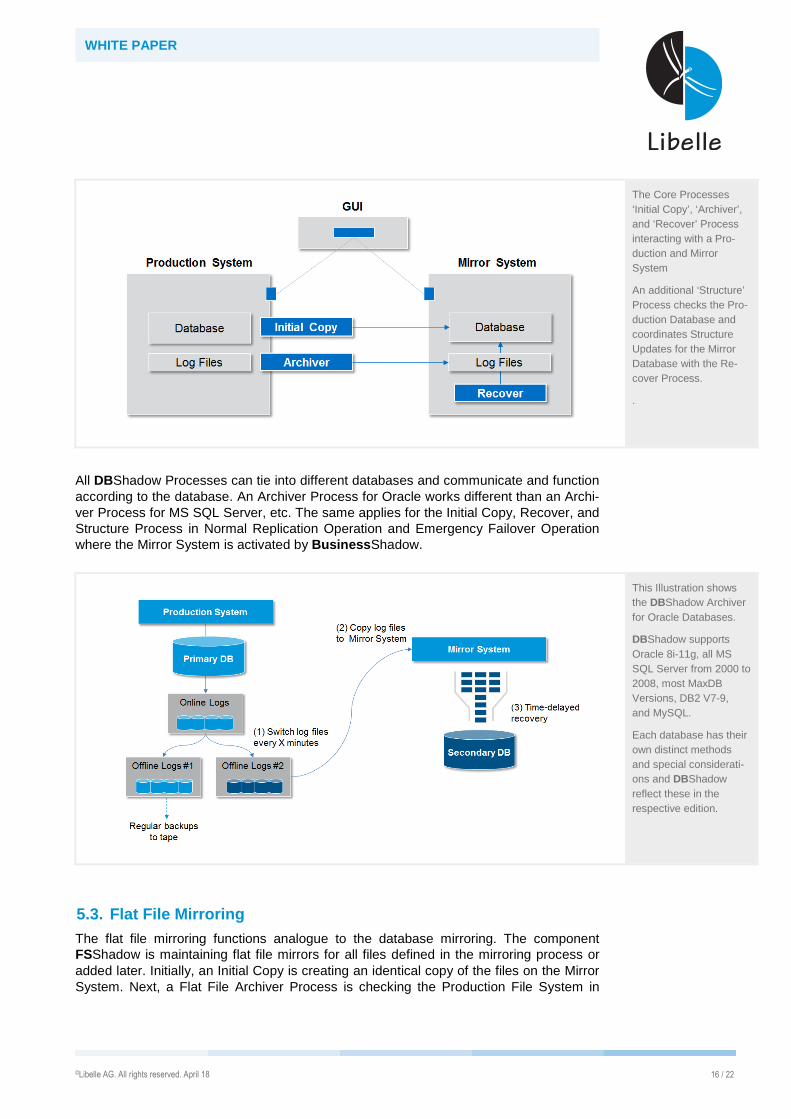
WHITE PAPER
©Libelle AG. All rights reserved. April 18 16 / 22
The Core Processes ‘Initial Copy’, ‘Archiver’, and ‘Recover’ Process interacting with a Pro-duction and Mirror System
An additional ‘Structure’ Process checks the Pro-duction Database and coordinates Structure Updates for the Mirror Database with the Re-cover Process.
.
All DBShadow Processes can tie into different databases and communicate and function according to the database. An Archiver Process for Oracle works different than an Archi-ver Process for MS SQL Server, etc. The same applies for the Initial Copy, Recover, and Structure Process in Normal Replication Operation and Emergency Failover Operation where the Mirror System is activated by Business Shadow.
This Illustration shows the DBShadow Archiver for Oracle Databases.
DBShadow supports Oracle 8i-11g, all MS SQL Server from 2000 to 2008, most MaxDB Versions, DB2 V7-9, and MySQL.
Each database has their own distinct methods and special considerati-ons and DBShadow reflect these in the respective edition.
5.3. Flat File Mirroring The flat file mirroring functions analogue to the database mirroring. The component FSShadow is maintaining flat file mirrors for all files defined in the mirroring process or added later. Initially, an Initial Copy is creating an identical copy of the files on the Mirror System. Next, a Flat File Archiver Process is checking the Production File System in

WHITE PAPER
©Libelle AG. All rights reserved. April 18 17 / 22
customizable intervals, for example every 30 minutes or every 5 minutes, depending on the project, customer requirements, and performance considerations.
Finally, a Recover Process is managing the recovery of the files into the mirror File System. As with DBShadow the architecture has a designated time-delay. Flat files won’t be applied immediately as they reach the Mirror System, but after a designated period of e.g. 4 hours. This allows a reaction window in case of corrupted flat file data for both High Availability and Disaster Recovery.
FSShadow mirrors complete directories or single flat files.
Entries can be defined via GUI or a simple ASCII file directly on the server.
Once setup, the FSShadow initializes the replication, manages data transfer to the Mirror System, and monitors operation.
5.4. Wide Area Network Enhancements: Option Long D istance Both components, DBShadow for databases and FSShadow for flat files, allow an extension of the basic communication services with special features for Wide Area Networks called ‘Option Long Distance’.
General challenges with a Wide Area Network replication setup compared to a Local Area Network mirrors are typically (1) drastically reduced available bandwidth, (2) generally unstable networks with multiple minor line drops during the day, and (3) very high Network Latency with distances larger than 50 miles. To address these issues, the Option Long Distance adjusts the basic Libelle TCP/IP stacks with customizable extensions which include:

WHITE PAPER
©Libelle AG. All rights reserved. April 18 18 / 22
• High Compression: Adding additional compression to standard compression before data is shipped.
• Parallel Archive Shipping: Single Log Files are shipped in parallel. For example, a single 200 MB Log File can be split up in multiple data packets which are then shipped in parallel to the Mirror System and then handed to the Mirror Database.
• Very Large Packets Technology: The option bumps up the default TCP/IP packet size. Standard packet sizes are geared towards Local Area Networks and often unsuitable for WAN replication.
5.5. Application Failover Libelle Business Shadow provides three core components for the Application Failover in case of an emergency:
• Libelle DBShadow and FSShadow Recover Process in Emergency Mode to automatically complete all database and flat file related failover tasks.
• Libelle Switch Application to automatically add or remove server hostnames and IP addresses from/to a Mirror System or Production System
• Libelle DBShadow, FSShadow, and Switch Application User Interfaces to automate pre-defined tasks during failover.
5.5.1. Recover Process in Emergency Mode
During normal replication procedure, the DBShadow and FSShadow Recover Processes are both applying changes they receive from the Archiver Process into the Mirror Database or into the Mirror File System. During an emergency situation where a failover and activation of the Mirror System is necessary, the same Recover Process will operate in ‘Emergency Mode’ and automatically ensures that the Mirror System is in the proper state to take over production.
For the database failover with DBShadow, this includes all database related tasks and includes for example the automated Point-In-Time Recovery to a customizable timestamp. DBShadow would then apply all log files which are not yet applied.
The Recover Process also allows an automated role-switch between a Production- and a Mirror System in case of a planned failover for most databases (for Oracle it would for example fetch the remaining Online Logs from Production and open the mirror with option ‘no reset logs). Finally the process automatically renames the database to the name of the Production Database and performs additional tasks as necessary.
The flat file failover with FSShadow operates similar. With a time-delay configured, customers can specify a time-stamp up to which the flat files should be recovered and then provides the Mirror System with the exact file structure as desired.
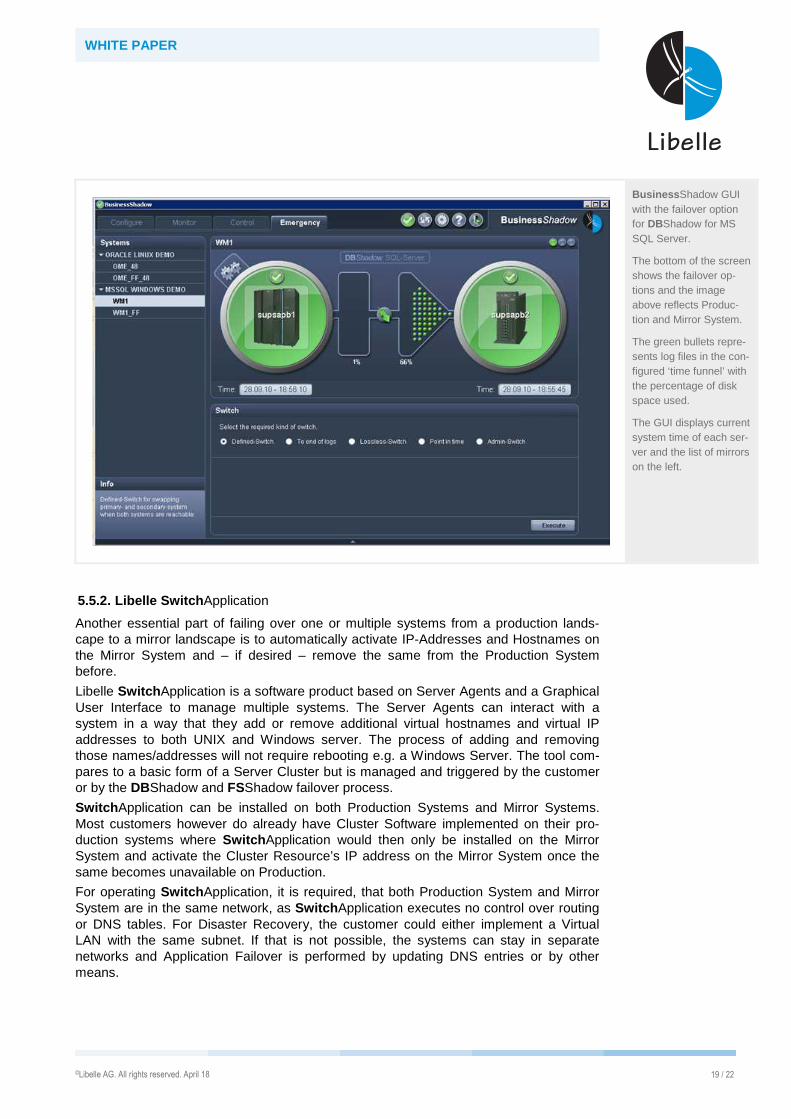
WHITE PAPER
©Libelle AG. All rights reserved. April 18 19 / 22
Business Shadow GUI with the failover option for DBShadow for MS SQL Server.
The bottom of the screen shows the failover op-tions and the image above reflects Produc-tion and Mirror System.
The green bullets repre-sents log files in the con-figured ‘time funnel’ with the percentage of disk space used.
The GUI displays current system time of each ser-ver and the list of mirrors on the left.
5.5.2. Libelle Switch Application
Another essential part of failing over one or multiple systems from a production lands-cape to a mirror landscape is to automatically activate IP-Addresses and Hostnames on the Mirror System and – if desired – remove the same from the Production System before.
Libelle Switch Application is a software product based on Server Agents and a Graphical User Interface to manage multiple systems. The Server Agents can interact with a system in a way that they add or remove additional virtual hostnames and virtual IP addresses to both UNIX and Windows server. The process of adding and removing those names/addresses will not require rebooting e.g. a Windows Server. The tool com-pares to a basic form of a Server Cluster but is managed and triggered by the customer or by the DBShadow and FSShadow failover process.
Switch Application can be installed on both Production Systems and Mirror Systems. Most customers however do already have Cluster Software implemented on their pro-duction systems where Switch Application would then only be installed on the Mirror System and activate the Cluster Resource’s IP address on the Mirror System once the same becomes unavailable on Production.
For operating Switch Application, it is required, that both Production System and Mirror System are in the same network, as Switch Application executes no control over routing or DNS tables. For Disaster Recovery, the customer could either implement a Virtual LAN with the same subnet. If that is not possible, the systems can stay in separate networks and Application Failover is performed by updating DNS entries or by other means.

WHITE PAPER
©Libelle AG. All rights reserved. April 18 20 / 22
The illustration below shows a landscape implementation of Business Shadow with Switch Application implemented on Production- and Mirror System for the Standalone Systems and implemented on the Mirror Systems only for the Clustered Production Systems.
Business Shadow Integration into a multi-system SAP landscape.
SCM shows two DBShadow instances, as the application has typi-cally one MaxDB and one Oracle database.
5.5.3. Failover- and Other User Interfaces
All Business Shadow components come with an extensive set of customizable User Interfaces which are empty at the beginning of an implementation. A standard single-mirror installation is typically requiring only minor additional integrations like failover auto-mation. A multi-mirror implementation however is often extended with a framework of User Interfaces where one main mirror can initiate failover of a group of related appli-cations or other systems automatically.
User Interfaces can execute Offline Tasks (e.g. executing a script) or Online Tasks (exe-cuting a script with feedback options), and can reside on both Production Systems and Mirror Systems. Tasks can be executed as Local Tasks (operate on the same server where they are defined) or Remote Tasks (trigger actions on their mirroring partner).
For the failover itself, a central User Interface triggered during, before, or after DBShadow, or FSShadow completed their failover tasks. Integrations can be as simple as triggering other system failovers up to running through a sophisticated multi-step plan of checking and executing failover tasks which used to be performed manually.
5.6. Graphical User Interface (GUI) The Libelle Business Shadow GUI is the central point where all DBShadow and FSShadow configurations of a landscape are setup, controlled, monitored, and mana-ged. The GUI is a JAVA application and is typically installed on a workstation. The GUI provides a central interface to set up, configure, and activate one or multiple mirrors.

WHITE PAPER
©Libelle AG. All rights reserved. April 18 21 / 22
Business Shadow ‘Configure’ Menu is intended to support an easy setup and confi-guration for each mirror.
The example shows the setup of a MS SQL Server Mirror.
The lower part of the screenshot shows the actual configuration setup divided into ‘Copy’, ‘Archiver’, ‘Recovery’, and ‘Structure’ options as detailed in earlier chapters. ‘Alarm’ is the configuration how the Server Agents should react to disturbances and if Errors or Warnings should be send out by email or SMTP traps. After mirror configura-tions have been set up, the next step is then to allow monitoring of multiple systems, as shown in the next illustration.
Business Shadow Moni-toring allows a per-mirror view, group-view, or list view.
In larger deployments, filter features with green (ok), yellow (warning), or red (error) flags allows easy identification of irregularities in Mirroring Operation.
The GUI also collects and displays server messages for the se-lected system.

WHITE PAPER
©Libelle AG. All rights reserved. April 18 22 / 22
6. Summary
This White Paper points out in detail different mirroring methods for both High Availability and Disaster Recovery. Libelle Business Shadow allows the highest possible grade of Database/Application Level Consistency, as data is mirrored on a database level for all major database technologies. On the other hand it provides a complete solution to mirror different databases on different platforms and provides a sophisticated solution to mirror flat files. Libelle hits a unique spot between application-agnostic storage/block-based replication and database-centric log shipping solutions.
All Libelle solutions come with a sophisticated Implementation Concept and Operating Model to suit any size and any grade of complexity from a single mirror installation up to 100+ server landscapes.
There are a large number of features, advantages and concepts not mentioned in this White Paper. Please contact us and we can have our Solution Architects and Consultants review your landscape to outline a specific solution, implementation, and operational approach for your requirements.
More Information
Headquarter Americas Libelle AG Libelle LLC Gewerbestr. 42 3330 Cumberland Blvd. Suite 500 70565 Stuttgart, Germany Atlanta, GA 30339, USA T +49 711 / 78335-0 T +1 770 / 435 1101 [email protected] [email protected] www.Libelle.com Libelle does not guarantee that the information in this presentation is error-free. The liability for consequential or indirect damages arising out of the reading or the use of this information is not warranted by Libelle AG within legal limits. All copyrights, especially distribution, reproduction and translation, are reserved. No part of this presentation may be reproduced, processed, reproduced or transmitted by electronic means without explicit approval of Libelle. Under no circumstances, including, but not limited to, negligence, shall Libelle, its agents or assignees, including but not limited to its parent, subsidiary, or affiliate companies, be liable for any direct, indirect, incidental, special or consequential damages that result from the use of the information provided herein. Libelle, the Libelle Logo, BusinessShadow®, DBShadow® and FSShadow® are trademarks of Libelle AG in Germany and other countries. SnapMirror, and Snapshot are trademarks or registered trademarks of NetApp, Inc. Windows, Microsoft and SQL Server are registered trademarks of Microsoft Corporation. Oracle is a registered trademark of Oracle Corporation. DB2 is a trademark or registered trademark of IBM Corp. MaxDB is a trademark of MySQL AB, Sweden. UNIX is a registered trademark of The Open Group. SAP and other SAP products and services mentioned herein as well as their respective logos are trademarks or registered trademarks of SAP SE (or an SAP affiliate company) in Germany and other countries. All other product and service names mentioned are the trademarks of their respective companies. V4


















