
Hadoop MapReduce Types - Fordhamstorm.cis.fordham.edu/zhang/cs5950/slides/MapReduceType.pdfHadoop...
25
Hadoop MapReduce Types Spring 2015, X. Zhang Fordham Univ.
Transcript of Hadoop MapReduce Types - Fordhamstorm.cis.fordham.edu/zhang/cs5950/slides/MapReduceType.pdfHadoop...

Hadoop MapReduce Types
Spring 2015, X. Zhang
Fordham Univ.

Outline
• MapReduce Types • default types • partition class and number of reducer tasks • control: choosing number of reducers • or how to partition keys …
• Default streaming jobs • Input Splits and Records • Serialization/Deserialization in hadoop:
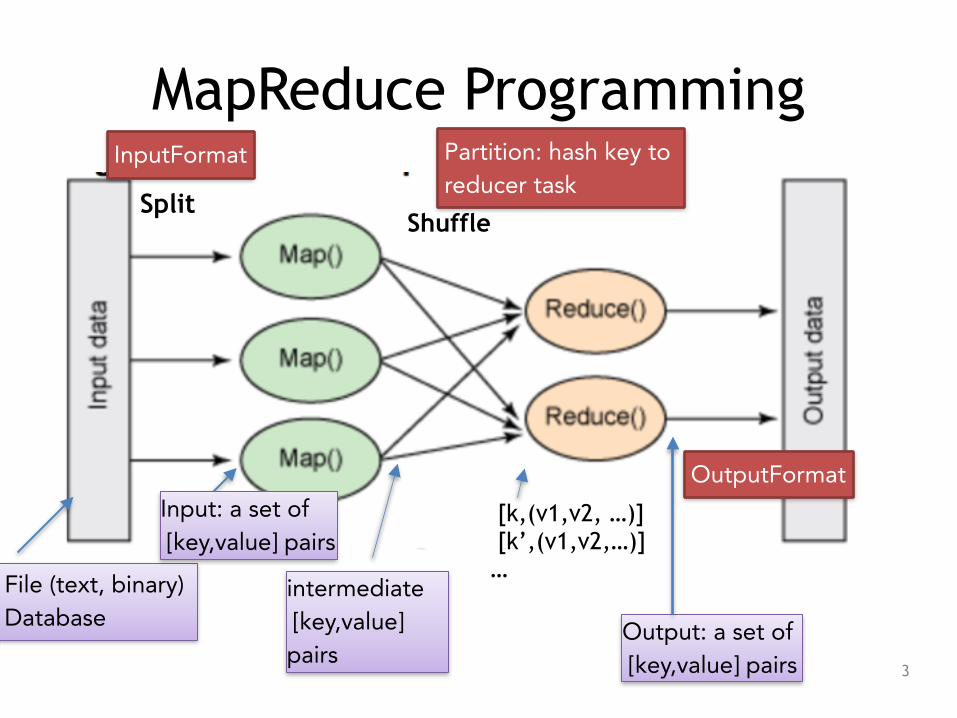
MapReduce Programming
3
Output: a set of [key,value] pairs
Split
intermediate [key,value] pairs
[k,(v1,v2, …)] [k’,(v1,v2,…)] …
Shuffle
File (text, binary) Database
Input: a set of [key,value] pairs
InputFormat
OutputFormat
Partition: hash key to reducer task

What happens? • Maps are the individual tasks which transform input records into a intermediate records. The
transformed intermediate records need not be of the same type as the input records. A given input pair may map to zero or many output pairs.
• Hadoop Map-Reduce framework spawns one map task for each InputSplit generated by the InputFormat for the job. !
• Framework first calls setup(org.apache.hadoop.mapreduce.Mapper.Context), followed by map(Object, Object, Context) for each key/value pair in the InputSplit. Finally cleanup(Context) is called.
• All intermediate values associated with a given output key are subsequently grouped by the framework, and passed to a Reducer to determine final output.
• Users can control sorting and grouping by specifying two key RawComparator classes.
• Mapper outputs are partitioned per Reducer.
• Users can control which keys (and hence records) go to which Reducer by implementing a custom Partitioner.
• Users can optionally specify a combiner, via Job.setCombinerClass(Class), to perform local aggregation of intermediate outputs, which helps to cut down amount of data transferred from the Mapper to the Reducer. 4
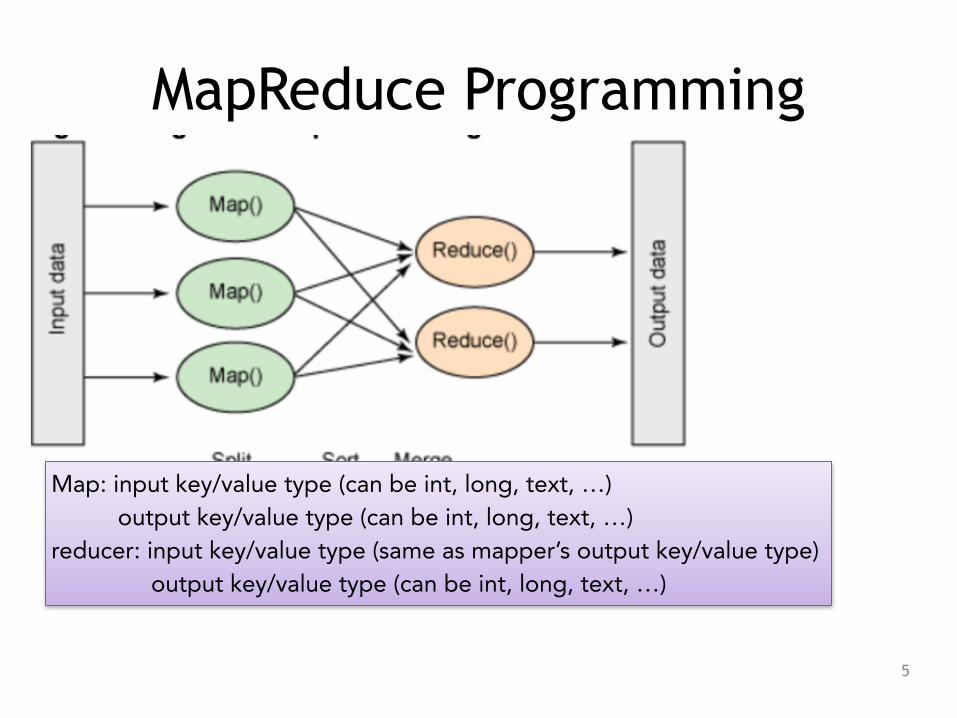
MapReduce Programming
5
Map: input key/value type (can be int, long, text, …) output key/value type (can be int, long, text, …) reducer: input key/value type (same as mapper’s output key/value type) output key/value type (can be int, long, text, …)

Map and Reduce Function
• map task: call mapper class’s map function to map input key/value pair to a set of intermediate key/value pairs. (k1, v1) -> list (k2, v2)
6

Reduce Function
• reduce task: call reducer class’s reduce function to process: (k2, list(v2)) -> list (k3,v3)
7

Partition Function
• partition: (k2, v2) -> integer • work on the intermediate key k2, and
returns the partition index
8

a MapReduce Job
Class Job: org.apache.hadoop.mapreduce.Job All Implemented Interfaces: JobContext, org.apache.hadoop.mapreduce.MRJobConfig !public class Job!extends org.apache.hadoop.mapreduce.task.JobContextImpl!implements JobContext!!The job submitter's view of the Job.
It allows the user to
• configure the job: using set***** methods, only work until the job is submitted, afterwards they will throw an IllegalStateException.
• submit it,
• control its execution,
• and query the state.
Normally the user creates the application, describes various facets of the job via Job and then submits the job and monitor its progress.
9
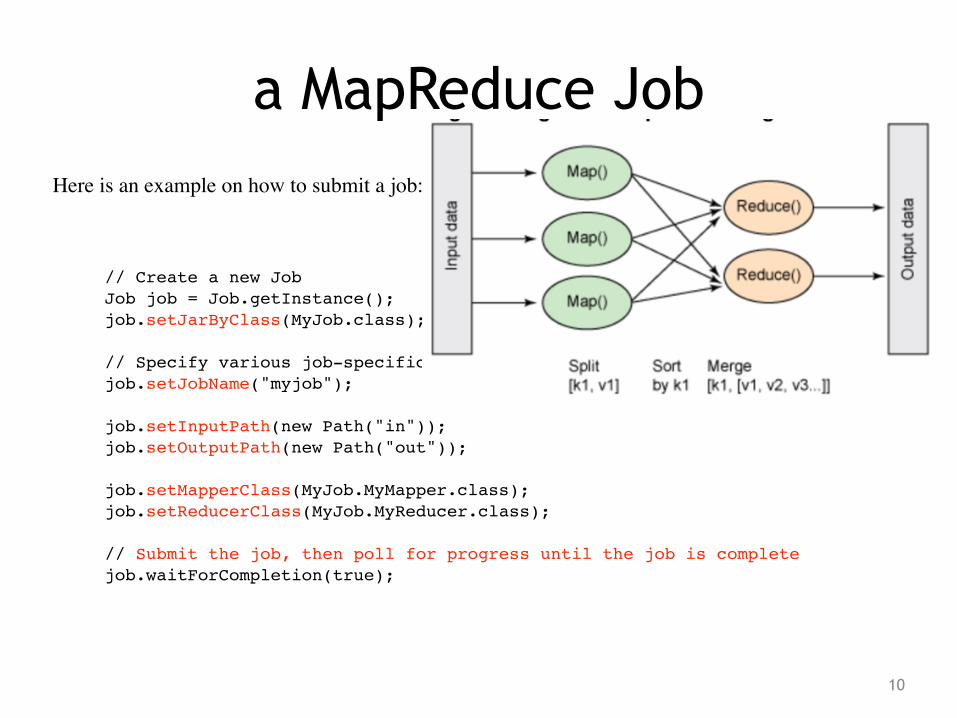
a MapReduce JobHere is an example on how to submit a job:
! // Create a new Job! Job job = Job.getInstance();! job.setJarByClass(MyJob.class);! ! // Specify various job-specific parameters ! job.setJobName("myjob");! ! job.setInputPath(new Path("in"));! job.setOutputPath(new Path("out"));! ! job.setMapperClass(MyJob.MyMapper.class);! job.setReducerClass(MyJob.MyReducer.class);!! // Submit the job, then poll for progress until the job is complete! job.waitForCompletion(true);
10

11
Mapper class’s KEYIN must be consistent with inputformat.class Mapper class’s KEYOUT must be consistent with map.out.key.class…

a minimalMapReduce Job
• Try to run the minimalMapReduce job !
• Compare it with the …WithDefaults j
12
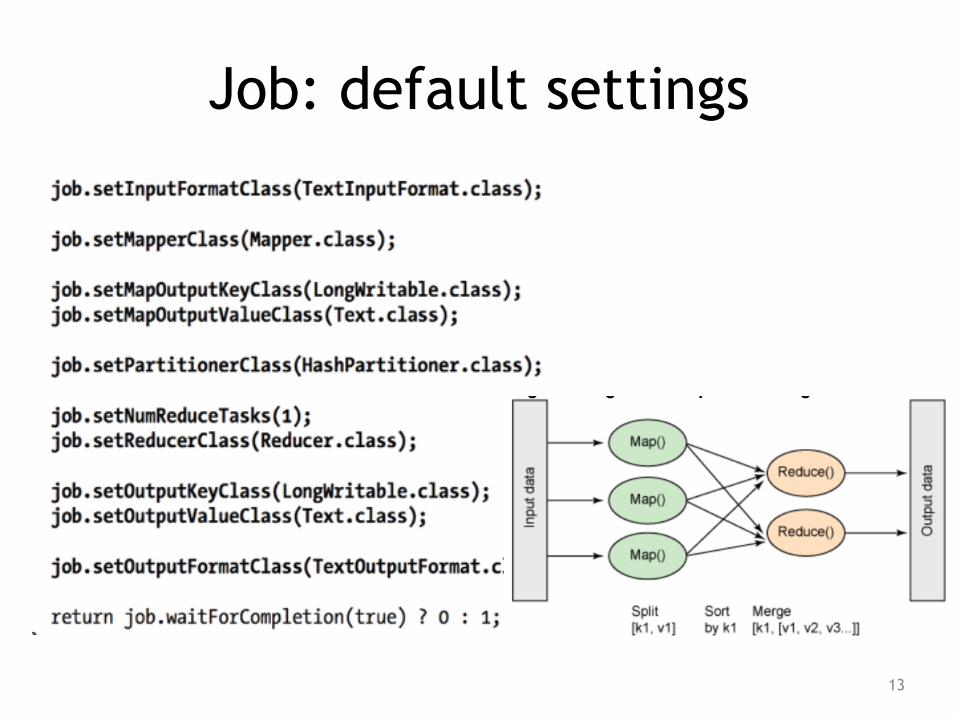
Job: default settings
13

Default InputFormatClass
• Default input format is TextInputFormat, which produces one (key,value) pair for each line in the text file
• keys of type LongWritable, the offset of the beginning of the line in the file
• values of type Text, the line of text.
• Other InputFormatClass ?
14

Default Mapper
Full name: org.apache.hadoop.mapreduce.Mapper<KEYIN,VALUEIN,KEYOUT,VALUEOUT>
!Mapper is a generic type, which allows it to work with any key or value types.
15
an identity function: simply write input key, value pair to output

Mapper: run
• Expert users can override this method for more complete control over the execution of the Mapper (when they write their own mapper class, e.g., maximumTemperaturMapper.java)
16
public void run(Context context) throws IOException, InterruptedException {! setup(context);! try {! while (context.nextKeyValue()) {! map(context.getCurrentKey(), context.getCurrentValue(), context);! }! } finally {! cleanup(context);! }! }!}!

Default PartitionerPartitioner controls the partitioning of the keys of the intermediate map-outputs.
• The key (or a subset of the key) is used to derive the partition, typically by a hash function.
• The total number of partitions is the same as the number of reduce tasks for the job.
• Hence this controls which of the m reduce tasks the intermediate key (and hence the record) is sent for reduction.
Default Partitioner: HashPartitioner, which hashes a record’s key to determine which partition the record belongs in. Each partition is processed by a reduce task, so the number of partitions is equal to the number of reduce tasks for the job: public class HashPartitioner<K, V> extends Partitioner<K, V> {
public int getPartition(K key, V value, int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks; }
}
The key’s hash code is turned into a nonnegative integer by bitwise ANDing it with the largest integer value. It is then reduced modulo the number of partitions to find the index of the partition that the record belongs in.
17

Default Reducer
• Default reducer is Reducer, again a generic type, which simply writes all its input to its output:
18

Default OutputFormat
• Default output format TextOutputFormat writes out records, one per line
• converting keys and values to strings • separating them with a tab character.
19

Exercises
• If we want to see the output of mapper class …
• If we want to input to be parsed differently to generate input <key,value> pair? • for example, if input data is formatted:
1901, 234 1902, 340 …
20

Outline
• MapReduce Types • default types • Serialization/Deserialization in hadoop: • partition class and number of reducer tasks • control: choosing number of reducers • or how to partition keys …
• Reading input: InputFormat • Input Splits and Records
• Writing output: OutputFormat • TextOutputFormat
• Default streaming jobs

Default Streaming Job• More stripped down streaming job: • !!
• Equivalently,
22
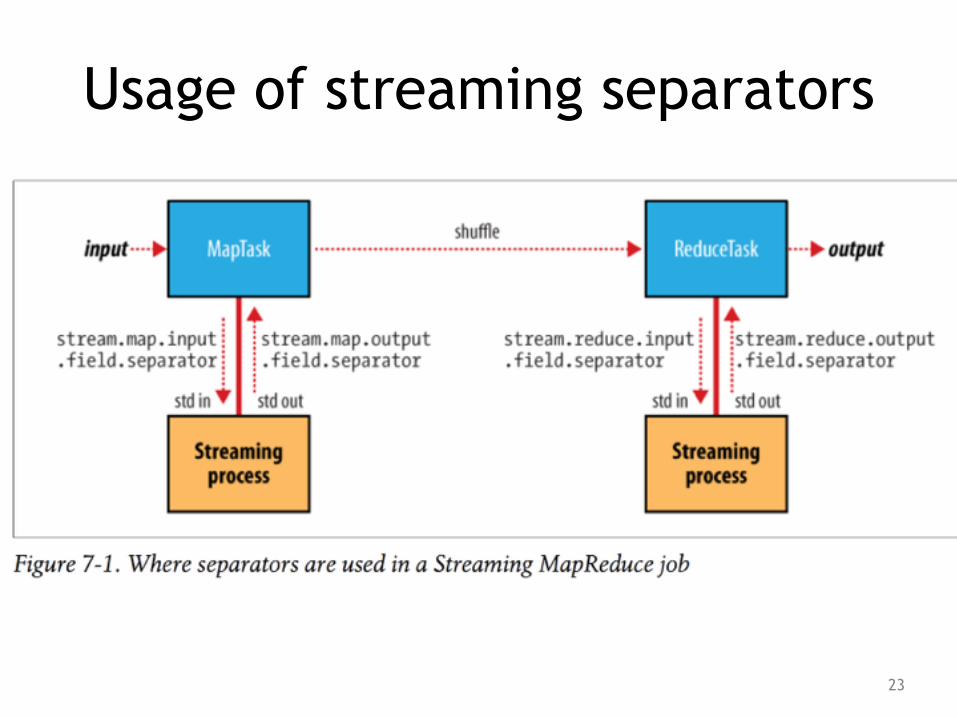
Usage of streaming separators
23
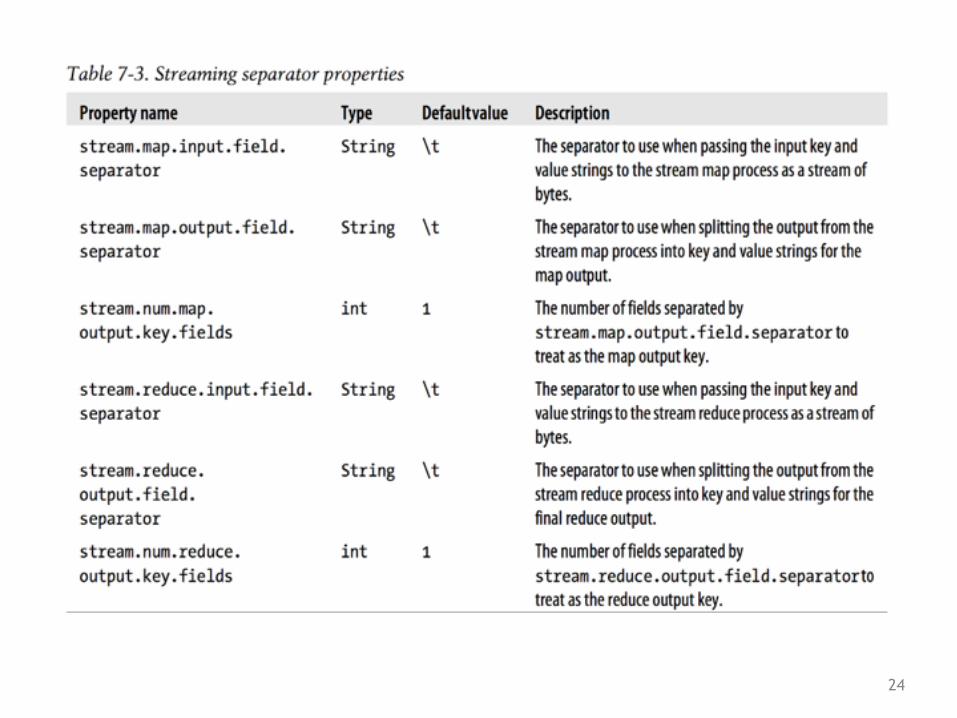
24

Input Splits
• input split: a chunk of input that is processed by a single map • length: largest split processed first … • a set of storage locations (to help schedule
map tasks close to data) • record: each split is divided into records • mapper class is called to process each record,
a key-value pair • mapper does not have global state about
the whole input 25








![A task-level adaptive MapReduce framework for real-time ...lik/publications/Fan-Zhang-FGCS-2015.pdf150 F.Zhangetal./FutureGenerationComputerSystems43–44(2015)149–160 theBodyAreaNetwork[1]thatiswidelyrecognizedasamedium](https://static.fdocuments.us/doc/165x107/5fddb58472fc6f7abe0a2b18/a-task-level-adaptive-mapreduce-framework-for-real-time-likpublicationsfan-zhang-fgcs-2015pdf.jpg)









