
GPU - Graphical Processing Unit
69
Faculté Polytechnique Graphical Processing Unit
Transcript of GPU - Graphical Processing Unit

8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 1/69

8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 2/69
Université de Mons
Thanks GPU

8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 3/69
Université de Mons
Table of content
1. History & Resume
2. GPU and 3D rendering
3. Architecture of a GPU4. GPU programming
5. CUDA
6. Conclusion

8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 4/69
Université de Mons
What is a GPU ?
The GPU is a processor specialized in 3D tasks
Offload the the CPU (central processor unit) of
several tasks
Highly parallel structuremore effective than
CPU for a range of complexe algorithme
Calculation of floating point

8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 5/69
Université de Mons
Central Processing Unit : CPU
5Prof. Untel | Service Untel (voir pied de page dans le menu Powerpoint)
• an essential component in a computer.
• interpret instructions and process datas of a
program.
• Sequential process (not much data but higher
complexity)
• Need to process more and more datas for
Multimedia applications (games, CAD,…)

8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 6/69
Université de Mons
Evolution of the CPU
6Prof. Untel | Service Untel (voir pied de page dans le menu Powerpoint)
• Multimedia applications used dedicated
algorithms to proceed
• Linear algorithm to apply the same
instructions to a large amount of data : we
speak about « vector calculus »
• Adaptation of the Architectures of CPU to use
Multimedia complexion :
Intel Pentium MMX, AMD Opteron 3D Now !

8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 7/69Université de Mons
Limitation of the CPU
7Prof. Untel | Service Untel (voir pied de page dans le menu Powerpoint)
• New generation of CPU with higher
performances seems more features and
functions for the users
• Users want more and more functions and they
want that technologies follow their desire
• But technologies are limited because internal
clock frequency of CPU are physically limited

8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 8/69Université de Mons
Solution to turn away the problem
8Prof. Untel | Service Untel (voir pied de page dans le menu Powerpoint)
• Multi-core : combine several CPU to one CPU
• Add a specific processor to multimedia
application GPU
BUT need parallel programming

8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 9/69Université de Mons
Multi-core CPU
9Prof. Untel | Service Untel (voir pied de page dans le menu Powerpoint)
• Classic programming is not adapted to multi-
core architecture because sequential
programming use one core and no more
• Classic programming + multi-core doesn’t
seem improvement !
• Need parallel programming : the problem is
divided into elementary task which are
process simultaneously by several CPU to
decrease computation time

8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 10/69Université de Mons
Multi-core CPU
10Prof. Untel | Service Untel (voir pied de page dans le menu Powerpoint)
• Parallel programming seems complex
programming
• Parallel programming is already used by
scientists to use supercalculators
• Multi-core CPU is good but not enough
compare to GPU

8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 11/69Université de Mons
GPU Vs CPU
11Prof. Untel | Service Untel (voir pied de page dans le menu Powerpoint)
• Comparison on FLOPS performance (Floating
point Operation Per Second)

8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 12/69Université de Mons
Origin of GPU
12Prof. Untel | Service Untel (voir pied de page dans le menu Powerpoint)
• Need to display a 2D projection of a 3D model
in real time
CAD : to visualize in 3D a virtual object
Video Games : to represent a virtual world
• 2 techniques : Ray tracing Rasterizing

8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 13/69Université de Mons
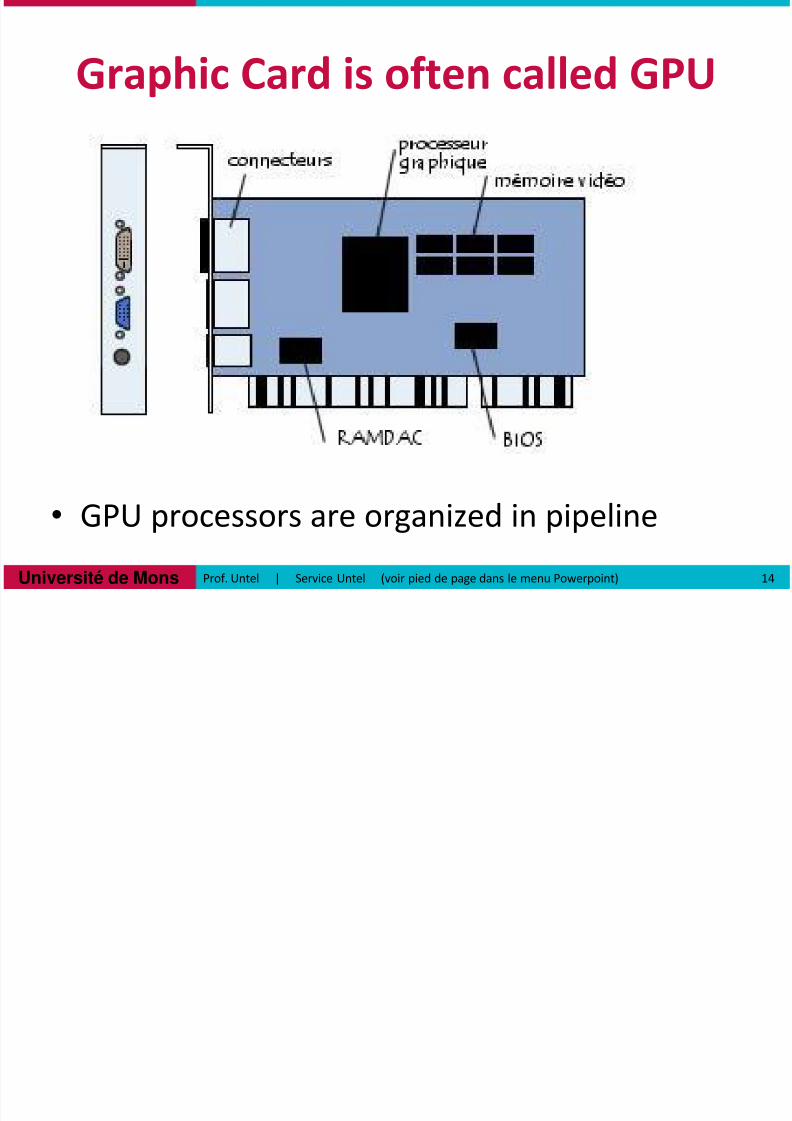
Graphic Card is often called GPU
13Prof. Untel | Service Untel (voir pied de page dans le menu Powerpoint)
• Graphic Card is an important part of the
computer
• Composed by memory area, processors,
registers and communication chipsets
• GPU = graphics processors on this card
•Until 240 parallel processors flow on GPU
@1500MHz
• Single Instruction on Multiple Data [SIMD]
8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 14/69Université de Mons
Graphic Card is often called GPU
14Prof. Untel | Service Untel (voir pied de page dans le menu Powerpoint)
• GPU processors are organized in pipeline

8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 15/69Université de Mons
GPU Programming
15Prof. Untel | Service Untel (voir pied de page dans le menu Powerpoint)
Languages
Shading Language

8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 16/69Université de Mons
Language GPGPU
16Prof. Untel | Service Untel (voir pied de page dans le menu Powerpoint)
CUDA
OpenCLAccelerator
…..

8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 17/69Université de Mons
Programming Model
17Prof. Untel | Service Untel (voir pied de page dans le menu Powerpoint)
Tableau = texture
Kernel =Fragment Shader
Calculus = Graphics renderingFeedback
GPGPU complexity
Memory AccessBandwidth
…..

8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 18/69Université de Mons
Table of content
1. History & Resume
2. GPU and 3D rendering
3. Architecture of a GPU4. GPU programming
5. CUDA
6. Conclusion

8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 19/69Université de Mons
Basic need ?
Show, in real time, a 2D projection (on the screen) of a 3D model
Raytracing
Rasterisation

8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 20/69Université de Mons
There is a specific vocabulary for
the GPU
Vertex
Texture
Pixel & fragmentShader
Pipeline

8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 21/69Université de Mons
A Vertex (plural : Vertices) are
commonly used to define the
corners of surfaces in 3D
models, where each such point
is given as a vector.
A vertex is represented by
coordonates X,Y and Z
Vertex
This cube has 8 vertices

8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 22/69Université de Mons
Texture
A Texture is a 2D image which
is applicated at a 3D object
perceived surface quality of an
artwork

8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 23/69Université de Mons
Pixel Fragment
• A pixel is the smallest item of information in an image seen by the viewer
• A fragment is the data necessary to generate a single pixel of
a drawing primitive. It is constituate by :
Some coordonates X,Y,Z
A color
A visibility depth
NOT seen by the user

8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 24/69
Université de Mons
Shader
A shader is simple programs that describe the traits of either a vertex or apixel (via the fragments).
It allows to control a subset of the GPU processors
Lots of special shading functions defined thanks to major graphics software
libraries (OpenGL and Direct3D)
3 types of shaders :
Vertex Shader
Run for each vertex given at the
processor
transform each vertex's 3D
position to the 2D coordinate of
the screen
Geometry shader
add and remove vertices
New shader (not present oneeach GPU)
Pixel (or fragment) Shader
calculate the color of individual
pixels lighting/shadow effect

8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 25/69
Université de Mons
Pipeline
A pipeline is an ordonate sequence of different
levels.
Each level get the data of the past one, do his
own operation and send the results to the
next one.
A pipeline is « full » when each level is working
simultaneously optimal use

8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 26/69
Université de Mons
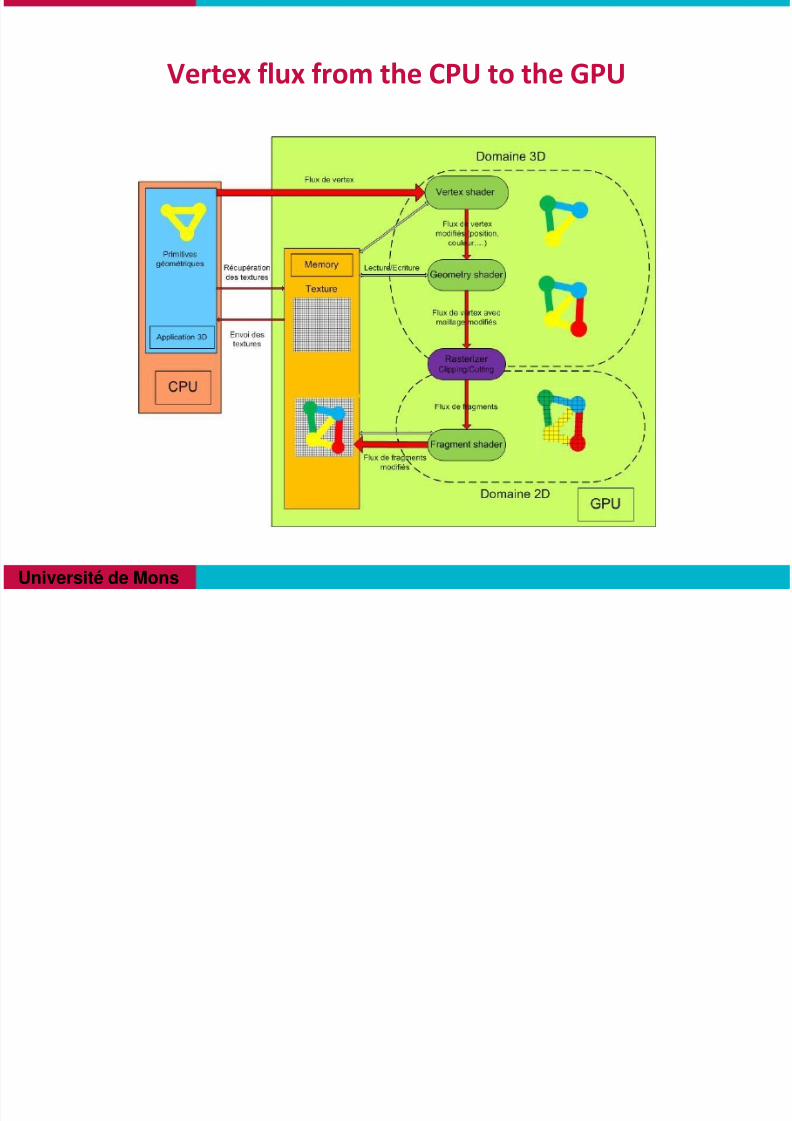
Actual Graphic Pipeline
The graphics pipeline typically accepts some representation of a
three-dimensional scene as an input and results in a 2D raster
image (image made of pixels) as output.
OpenGL and Direct3D are two notable graphics pipeline modelsaccepted as widespread industry standards.
The graphic pipeline contains 4 levels :
3 programmable levels
pilot by the shader
1 non-programmable level
The rasterizer
8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 27/69
Université de Mons
Vertex flux from the CPU to the GPU

8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 28/69
Université de Mons
Pre-stage : Tessellation
8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 29/69
Université de Mons
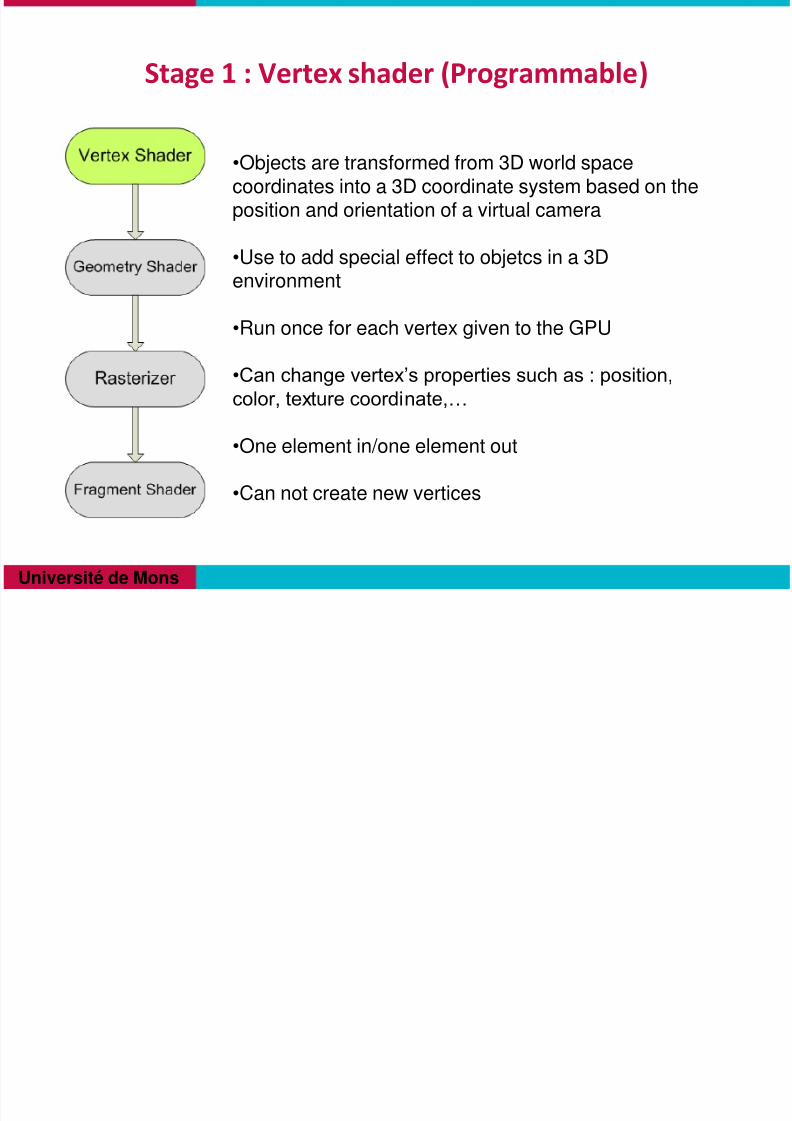
Stage 1 : Vertex shader (Programmable)
•Objects are transformed from 3D world spacecoordinates into a 3D coordinate system based on theposition and orientation of a virtual camera
•Use to add special effect to objetcs in a 3D
environment
•Run once for each vertex given to the GPU
•Can change vertex’s properties such as : position,
color, texture coordinate,…
•One element in/one element out
•Can not create new vertices

8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 30/69
Université de Mons
Stage 2 : Geometry shader (Prgrammable)
•One element in / 0 ~100 elements out
•Can add and remove vertices
•Can be used to add volumetric detail (too costly forCPU) or for the refinement of the mesh size
•Ex : 20 triangles 100 triangles smaller
•Displacement Mapping
•Last type of shader created (not always present in thepipeline)
Mesh size = taille des mailles = maillage
8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 31/69
Université de Mons
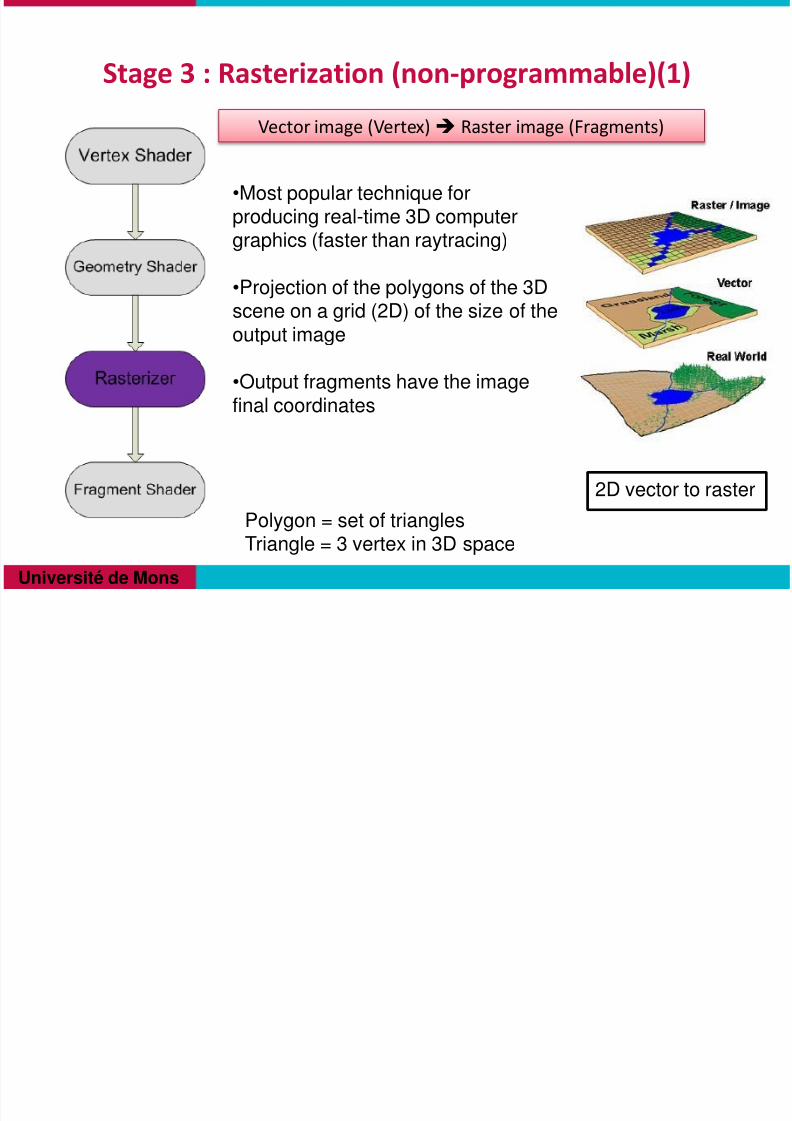
Stage 3 : Rasterization (non-programmable)(1)
•Most popular technique forproducing real-time 3D computergraphics (faster than raytracing)
•Projection of the polygons of the 3Dscene on a grid (2D) of the size of theoutput image
•Output fragments have the imagefinal coordinates
2D vector to raster
Vector image (Vertex) Raster image (Fragments)
Polygon = set of trianglesTriangle = 3 vertex in 3D space

8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 32/69
Université de Mons
Stage 3 : Rasterization (2)
The Rasterization algorithme has minimum 3 steps :
1. Calculation of the 2D coordinates (transformation)
2. Filtering of the vertex (clipping)
3. Rasterization itself (scan conversion)
4. Acceleration technics (optional)
5. Further refinments

8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 33/69
Université de Mons
Stage 3 : Rasterization (3)
The Rasterization algorithme has minimum 3 steps :
1. Calculation of the 2D coordinates (transformation)
Set of mathematics transformation :• Translation, scalling, rotation : to put the 3D figure at the desire
location (Exemple = the origine)• Projection : from 3D to 2D (orthogonal projection (removed the
z-components), perspective projection)
These operations are done thanks to a multiplication of thevertex’s augmented 3D matrix by different matrix
Ex : Translation matrix :
Ex : A man who turn his head

8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 34/69
Université de Mons
Stage 3 : Rasterization (4)
2. Filtering of the vertex (clipping)
• Triangles 2D vertices location are calculated BUT may be outside of the window (area on the screen wherethe pixel will be written)
• Clipping is the process of truncating triangles to fit them inside the viewing area.
3. Rasterization itself (scan conversion)
• To fill in the 2D triangles that are now in the image plane in pixels
• Exemple : treatment of a line (coordonates (1,1) to (5.1), color degraded blue to green) Will fill pixel (1,1), (2,1), (3,1), (4,1), & (5,1) ;
For each pixel, ones has to determinates the caracteristic with a goog balance :
(1,1) being totaly blue, (2,1) less blue, (3,1) blue)green,…
• This is much more complicated for shape like triangle but the principe remains the same
• Difficulty : Pixel Aliasing
use of Z-buffer to see which pixel is closer to the camera

8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 35/69
Université de Mons
Stage 3 : Rasterization (5)
4. Acceleration techniques
I. Backface culling :determines whether a polygon of a graphical object is
visible, if not (it shows its back to the camera) cull
II. Spatial data structures

8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 36/69
Université de Mons
Stage 4 : Fragment shader (Programmable)
•Give his final color to each pixel (fonction of lighting,reflexing or refraction of the light,…)
•Biggest computational resource•Perform complex per-pixel effects and refinmentstechniques such as :
I. Texture filtering : to create clean images at anydistance
II. Environment mapping : a form
of texture mapping in which thetexture coordinates view-dependentto simulate reflection on a shinyobject
III. Shadows : traditionnally not processin the rasterizer modern techniques
Fragment Shader = Pixel Shader
OpenGL Direct3D

8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 37/69
Université de Mons
Exit of the pipeline
• Fragment flux can :
Either be written in a framebufferand then display on the screen
Either, if it need more treatment, bewritten in a texture and then pick backby the the CPU

8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 38/69
Université de Mons
Resume

8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 39/69
Université de Mons
The unified architecture came from the 6th generation
of GPU
Before : 2 types of processor in the GPU
Vertex Units
Fragments Units
Creation of a neck of strangling when one type was over-charged not optimal
Since GeForce 8, processors are not specifics anymore
optimal use of the pipeline : Unified Architecture

8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 40/69
Université de Mons
GPU-s evolution through the different generations
Gén Year Nvidia AMD/ATI Particularities
1 96 TNT2 Rage -DirectX6 = standard
-Rasterziation of traingle and texture
-Limitation : no vertex treatment
-Other provider : 3 dfx (Voodoo)
2 99 Geforce 256 Radeon 7500 -Open GL supported
- vertex treatment supported
3 0102
Geforce 3Geforce 4
Radeon 8500 -Nvidia buy 3 dfx-Vertex treatment programmable
4 02 Geforce FX Radeon 9700 - Fragments treatment programmable
- First GPGPU opérations
5 04
05
Geforce 6
Geforce 7
Radeon X800
Radeon X1800
-Speed of treatment increase
-GPGPU operation developped
6 06
07
08
Geforce 8
Geforce 9
Radeon HD200
Radeon HD300
-Geometry shader appear
-Unified architecture
-Nvidia created CUDA language
7 08 Geforce 200 Radeon HD400 -Not very spread yet
-Technical improvments (frequence, memory,
number of processor, bandwith,…)

8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 41/69
Université de Mons
Table of content
1. History & Resume
2. GPU and 3D rendering
3. Architecture of a GPU
4. GPU programming
5. CUDA
6. Conclusion

8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 42/69
Université de Mons
Architecture of a GPU
42Prof. Untel | Service Untel (voir pied de page dans le menu Powerpoint)

8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 43/69
Université de Mons
Short remember :
Architecture of a CPU
CPU and its evolution
Drawbacks
Architecture of a GPU
Needs
SIMD/MIMD
Short talk about data management
Gathering/scattering and PRAM
Overview
43Prof. Untel | Service Untel (voir pied de page dans le menu Powerpoint)
Time

8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 44/69
Université de Mons
Architecture of a CPU
44Prof. Untel | Service Untel (voir pied de page dans le menu Powerpoint)
Arithmetic Logic Unit orCalcul Unit :
• Manage all operations
Control Unit :
• Manage all instructions
Cache :
• Fast memory access• Expensive
• High volume
DRAM :
• Dynamic random access memory• Cheap but need to be refreshed
Control brain
ALU hands
Memory tools
CONTROLALU ALU
ALU ALU
CACHE
DRAM
h b

8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 45/69
Université de Mons
CPU processing
For a computer :
Program = several sequential instructions
Simple CPU : SISD (single instruction single data)
Short remember :
ARCHITECTURE OF A CPU
CPU AND ITS EVOLUTION
DRAWBACKS
Architecture of a GPU
NEEDS
SIMD/MIMD
Data management
GATHERING/SCATTERING AND PRAM
45Prof. Untel | Service Untel (voir pied de page dans le menu Powerpoint)
Instruction1 Instruction2 Instruction3
Program
code
• Instructions are computed 1 by 1
• On a single data at each time

8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 46/69
Université de Mons
At first : SISD
In-order processors
Out-of-order processors ( performances )
Instructions dispatch to an instruction queue The results are queued
The process is still sequential
High volume of cache memory
Need to have a fast access to instructions and datas
Lots of « go and back » on datas
CPU and its evolution
46Prof. Untel | Service Untel (voir pied de page dans le menu Powerpoint)

8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 47/69
Université de Mons
Evolution ( Pentium 3 )
SIMD (single instruction multiple data)
Vectorial calculus performances
Reasons
Only a few « go and back » on datas The complexity of the algorithm is very
High volume of cache memory and out-of-order execution are
superficials for multimedia applications
Evolution and drawbacks
47Prof. Untel | Service Untel (voir pied de page dans le menu Powerpoint)
CPU is perfect for sequential program but is weak for
multimedia applications

8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 48/69
Université de Mons
A GPU is a SIMD processor
To be able to process a lot of datas
Architecture of a GPU
48Prof. Untel | Service Untel (voir pied de page dans le menu Powerpoint)

8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 49/69
Université de Mons
A high memory bandwidth
10 x CPU bandwidth to process lots of datas in real time
Needs of the GPU
49Prof. Untel | Service Untel (voir pied de page dans le menu Powerpoint)

8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 50/69
Université de Mons
Parler de la nouvelle génération GPU
MIMD (multiple instruction multiple data)
Comparer MIMD et SIMD
Parler de la gestion des données
Gathering
Scattering
Parler du modèle PRAM utilisé dans les GPU
Reste à faire
50Prof. Untel | Service Untel (voir pied de page dans le menu Powerpoint)

8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 51/69
Université de Mons
Table of content
1. History & Resume
2. GPU and 3D rendering
3. Architecture of a GPU
4. GPU programming
5. CUDA
6. Conclusion

8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 52/69
Université de Mons
• CUDA (Computer Unified Device Architecture) is a
development library created by NVIDIA in 2007.
• It allows to use the power of a compatible graphic
card for general purpose computing.• Programmers can use C,C++ or Fortran to develop
applications using CUDA.
• Interfaces (wrappers) enable to use high-level
languages such as Java, .net or Python.
CUDA
52

8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 53/69
Université de Mons
Different components of CUDA
53
• CUDA is constituated of set of software layers to
communicate with the GPU: a Driver, a Runtime and
a few librairies.

8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 54/69
Université de Mons
• Include the code of all the functions to be
executed on the GPU.
• Using those libraries, developpers can only
use a set of predefined functions.
• They do not have access to the actual GPU.
• Examples:• CUBLAS, which has a set of building blocks for linear algebra calculations
on the GPU
• CUFFT, which can handle calculation of Fourier transforms
CUDA Libraries
54

8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 55/69
Université de Mons
• Also called « C for CUDA »
• The high-level API is implemented “above” the low-
level API, each call to a function of the Runtime is
broken down into more basic instructions managedby the Driver API
• The term “high-level API” is relative. Even the
Runtime API is still what a lot of people would
consider very low-level; yet it still offers functionsthat are highly practical for initialization.
High Level API : CUDA Runtime
55

8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 56/69
Université de Mons
• The Driver API is more complex to manage; it
requires more work to launch processing on the
GPU.
• The upside is that it’s more flexible, giving theprogrammer additional control.
• Note that the high-level and Low-level APIs are
mutually exclusive – the programmer must use one
or the other, but it’s not possible to mix function calls
from both.
Low Level API : CUDA Driver
56
CUDA from the Hardware

8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 57/69
Université de Mons
• Nvidia’s Shader Core is made up of several clusters Nvidia calls Texture
Processor Clusters.
• Each cluster is made up of a texture unit and 2 streaming multiprocessors.
CUDA from the Hardware
Point of View
57

8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 58/69
Université de Mons
• These processors consist of a front
end that reads/decodes and launches
instructions and a backend made up
of a group of eight calculating units
and two SFUs (Super Function Units).
where the instructions are executed
in SIMD fashion.
• The same instruction is applied to all
the threads in the warp. Nvidia calls
this mode of execution SIMT (forsingle instruction multiple threads).
• The backend operates at double
the frequency of the front end.
The streaming Multiprocessor
58
Streaming multiprocessors’

8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 59/69
Université de Mons
• At each cycle, a warp ready for execution is
selected by the front end, which launches
execution of an instruction.
• To apply the instruction to all 32 threads in the
warp, the backend will take four cycles, but since it
operates at double the frequency of the front end,from its point of view only two cycles will be
executed.
• to avoid having the front end remain unused for
one cycle, the ideal is to alternate types of
instructions every cycle – a classic instruction forone cycle and an SFU instruction for the other.
Streaming multiprocessors
operating mode
59

8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 60/69
Université de Mons
• Each multoprocessors have a small
memory area called Shared Memory
with a size of 16 KB per multiprocessor.
• This memory area provides a way for
threads in the same block tocommunicate. All the threads in a given
block are executed by the same
multiprocessor.
• The assignment of blocks to the
different multiprocessors is completelyundefined, meaning that two threads
from different blocks can’t
communicate during their execution.
Shared Memory
60

8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 61/69
Université de Mons
• To limit too-frequent access to theshared memory, Nvidia has also
provided its multiprocessors with a
cache (approximately 8 KB per
multiprocessor) for access to constants
and textures.
• The multiprocessors also have 8,192
registers that are shared among all the
threads of all the blocks active on that
multiprocessor. The number of activeblocks per multiprocessor can’t exceed
eight, and the number of active warps
are limited to 24 (768 threads)
Cache Memory - Registers
61

8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 62/69
Université de Mons
• Finding the optimum balance between the number of blocks andtheir size – more threads per block will be useful in masking the
latency of the memory operations, but at the same time the
number of registers available per thread are reduced.
• Blocks of 512 threads would be particularly inefficient, since onlyone block might be active on a multiprocessor, potentially wasting
256 threads. So, Nvidia advises using blocks of 128 to 256 threads,
which offers the best compromise between masking latency and
the number of registers needed for most kernels.
Optimizing a CUDA program
62

8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 63/69
Université de Mons
• Host : CPU
• Device : GPU
• Kernel : Function executed
on the GPU• Thread : basic element of the data
to be processed (very lightweight)
• Warp : group of 32 threads
• Block : set of 64 to 512 threads
• Grid : Array of blocks
Definitions

8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 64/69
Université de Mons
VCheck
Definitions (2)
64Prof. Untel | Service Untel (voir pied de page dans le menu Powerpoint)
CUDA from a Software

8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 65/69
Université de Mons
CUDA = set of extensions to the C language
Type qualifiers for functions :
__global__ void function()
Function called by the CPU, executed on the GPU
__device__ void function()
Function called by and executed on the GPU
__host__ void function() Standard function (executed on the CPU)
CUDA from a Software
Point of View
65Prof. Untel | Service Untel (voir pied de page dans le menu Powerpoint)

8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 66/69
Université de Mons
Restrictions on __device__ and __global__ :
1. Cannot be recursive
2. Must have a fixed number of arguments
Type qualifier for variables :
__shared__ variableThis variable will be stored in the
multiprocessor’s shared memory
Software Point of View (2)
66Prof. Untel | Service Untel (voir pied de page dans le menu Powerpoint)

8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 67/69
Université de Mons
1. CPU code is extracted
and handed to the
standard compiler
2. GPU code is converted
into PTX code(assembly code) and
scanned for
inefficiences
3. PTX is translated isGPU-specific
commands that are
incapsulated in the exe
Compilation
67Prof. Untel | Service Untel (voir pied de page dans le menu Powerpoint)

8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 68/69
Université de Mons
A few applications examples
68

8/7/2019 GPU - Graphical Processing Unit
http://slidepdf.com/reader/full/gpu-graphical-processing-unit 69/69
ATI equivalent to Nvidia’s CUDA


















