
GPU-REMuSiC on Graphics Processing Units
47
Chun-Yuan Lin, Assistant Processor Department of Computer Science and Information Engineering Chang Gung University GPU-REMuSiC on Graphics Processing Units 2011/5/20 1 PPCB
Transcript of GPU-REMuSiC on Graphics Processing Units

Chun-Yuan Lin, Assistant Processor
Department of Computer Science and Information Engineering
Chang Gung University
GPU-REMuSiC on Graphics
Processing Units
2011/5/20 1 PPCB

Outline
Sequence alignment problem
Pair-wise sequence alignment
Multiple sequence alignment
Previous studies
Parallel computing for dynamic programming
Related works on CUDA
Constrain multiple sequence alignment
Developments of a series of tools
RE-MuSiC
GPU-REMuSiC implementation
2011/5/20 2 PPCB

Sequence alignment problem
2011/5/20 3 PPCB

2011/5/20 4 PPCB

2011/5/20 5 PPCB

2011/5/20 6 PPCB

2011/5/20 7 PPCB

2011/5/20 8 PPCB

2011/5/20 9 PPCB

2011/5/20 10 PPCB

PAM100
2011/5/20 11 PPCB

2011/5/20 12 PPCB

2011/5/20 13 PPCB

2011/5/20 14 PPCB

2011/5/20 15 PPCB

2011/5/20 16 PPCB

2011/5/20 17 PPCB

We can not use dynamic programming for k sequences.
2011/5/20 18 PPCB

2011/5/20 19 PPCB

2011/5/20 20 PPCB

Previous studies
2011/5/20 21 PPCB

2011/5/20 22 PPCB

2011/5/20 23 PPCB

Some bioinformatics applications have been successfully
ported to GPGPU in the past.
Liu et al. (IPDPS 2006) implemented the Smith-Waterman algorithm to
run on the nVidia GeForce 6800 GTO and GeForce 7800 GTX, and
reported an approximate 16× speedup by computing the alignment
score of multiple cells simultaneously.
Charalambous et al. (LNCS 2005) ported an expensive loop from
RAxML, an application for phylogenetic tree construction, and achieved a
1.2× speedup on the nVidia GeForce 5700 LE.
2011/5/20 24 PPCB

Liu et al. (IEEE TPDS 2007) presented a GPGPU approach to
high-performance biological sequence alignment based on
commodity PC graphics hardware. (C++ and OpenGL Shading
Language (GLSL))
Pairwise Sequence Alignment (Smith-Waterman algorithm, scan database)
Multiple sequence alignment (MSA)
2011/5/20 25 PPCB

Some bioinformatics applications have been successfully
ported to CUDA now.
Smith-Waterman algorithm (goal: scan database)
Manavski and Valle (BMC Bioinformatics 2008),
Striemer and Akoglu (IPDPS 2009),
Liu et al. (BMC Research Notes 2009)
Khajeh-Saeed et al. (Journal of Computational Physics, 2010)
Liu et al. (BMC Research Notes 2010)
Multiple sequence alignment (ClustalW)
Liu et al. (IPDPS 2009) for Neighbor-Joining Trees construction
Liu et al. (ASAP 2009)
2011/5/20 26 PPCB

Manavski and Valle present the first solution based on commodity hardware that efficiently computes the exact Smith-Waterman alignment. It runs from 2 to 30 times faster than any previous implementation on general-purpose hardware.
Pre-compute a query profile parallel to the query sequence for each possible residue.
The implementation in CUDA was to make each GPU thread compute the whole alignment of the query sequence with one database sequence. (pre-order the sequences of the database in function of their length)
The ordered database is stored in the global memory, while the query-profile is saved into the texture memory.
For each alignment the matrix is computed column by column in order parallel to the query sequence. (store them in the local memory of the thread)
2011/5/20 27 PPCB

Striemer and Akoglu further study the effect of memory organization and
the instruction set architecture on GPU performance.
They pointed out that query profile in Manavski’s method has a major drawback
in utilizing the texture memory of the GPU that leads to unnecessary caches
misses. (larger than 8KB)
Long sequence problem.
They placed the substitution matrix in the constant memory to exploit the
constant cache, and created an efficient cost function to access it. (modulo
operator is extremely inefficient on CUDA, not use hash function)
They mapped query sequence as well as the substitution matrix to the constant
memory.
2011/5/20 28 PPCB

Liu et al. proposed Two versions of CUDASW++ are implemented: a
single-GPU version and a multi-GPU version.
The alignment can be computed in minor-diagonal order from the top-left
corner to the bottom-right corner in the alignment matrix.
Considering the optimal local alignment of a query sequence and a subject
sequence as a task.
Inter-task parallelization: Each task is assigned to exactly one thread and dimBlock
tasks are performed in parallel by different threads in a thread block.
Intra-task parallelization: Each task is assigned to one thread block and all dimBlock
threads in the thread block cooperate to perform the task in parallel.
2011/5/20 29 PPCB
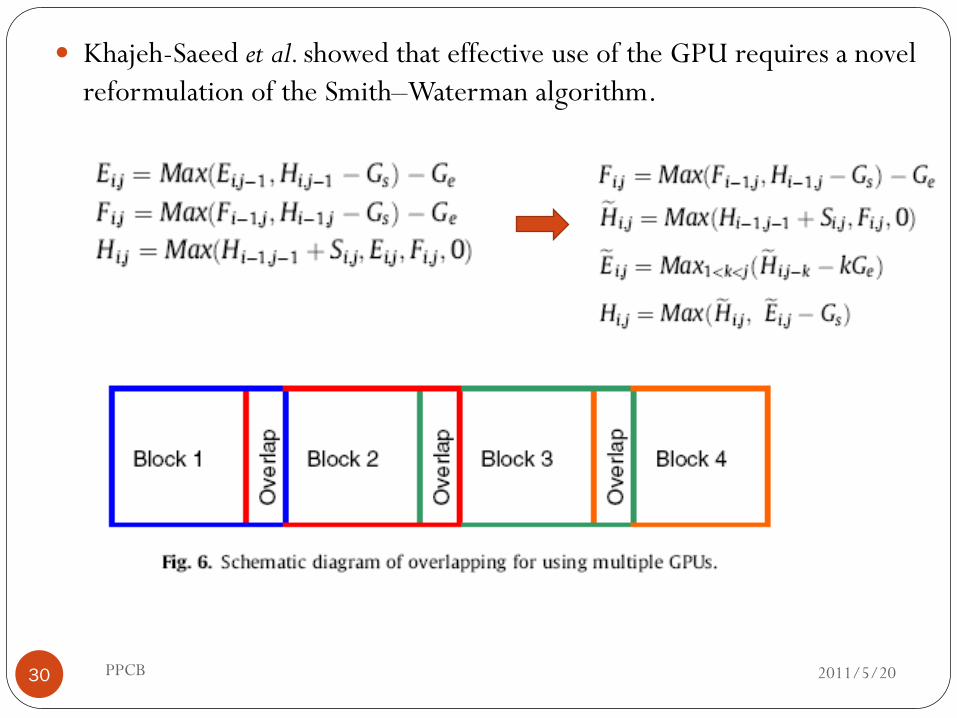
Khajeh-Saeed et al. showed that effective use of the GPU requires a novel
reformulation of the Smith–Waterman algorithm.
2011/5/20 30 PPCB

Liu et al. described the latest release of the CUDASW++ software,
CUDASW++ 2.0, which makes new contributions to Smith-Waterman
protein database searches using compute unified device architecture
(CUDA).
2011/5/20 31 PPCB

Liu et al. presents MSA-CUDA, a parallel MSA program, which
parallelizes all three stages of the ClustalW processing pipeline using
CUDA.
Pairwise distance computation:
As the work in Liu et al. (BMC Research Notes 2009)
Neighbor-Joining Trees: as the work in Liu et al. (IPDPS 2009)
Progressive alignment:
conducted iteratively in a
multi-pass way.
2011/5/20 32 PPCB

Constrain multiple sequence alignment
2011/5/20 33 PPCB

(Tang, CSB 2002) P = HKH
Constrain Multiple Sequence Alignment (CMSA)
2011/5/20 34 PPCB

G. Myers, S. Selznick, Z. Zhang and W. Miller. “Progressive multiple alignment with constraints,” Proceedings of the 1st ACM Conference on Computational Molecular Biology, 1997.
(Position constraint, is jt)
C.Y. Tang, C.L. Lu, M.D.T. Chang, Y.T. Tsai, etc, “Constrained Multiple Sequence Alignment Tool Development and Its Application to RNase Family Alignment,” Journal of Bioinformatics and Computational Biology, vol. 1, 2003. (CSB 2002) (CMSA)
(Character constraint, P: a set of single residue/nucleotide)
Y.T. Tsai, Y.P. Huang, C.T. Yu and C.L. Lu, “MuSiC: a tool for multiple sequence alignment with constraints,” Bioinformatics, vol. 20, 2004. (MuSiC)
(Segment constraint, P: a set of short segment) C.L. Lu and Y.P. Huang, “A memory-efficient algorithm for multiple
sequence alignment with constraints,” Bioinformatics, vol. 21, 2005. (MuSiC-ME)
2011/5/20 35 PPCB

Y.-T. Tsai, “The constrained common sequence problem,” Information Processing Letters, vol. 88, 2003.
F. Y.L. Chin, etc,
“A simple algorithm for the constrained sequence problems,” IPL, vol. 90, 2004.
“ Efficient Constrained Multiple Sequence Alignment with Performance Guarantee,” JBCB, vol. 3, 2005. (CSB, 2003)
A. N. Arslan, etc.
“Algorithms for the constrained common sequence problem,” Proc. Prague Stringology Conference, 2004.
“A fast Algorithm for the Constrained Multiple Sequence Alignment problem,” Acta Cybernetica (accepted)
“A parallel algorithm for the constrained multiple sequence alignment problem,” BIBE 2005.
“A space-efficient algorithm for the constrained pairwise sequence alignment problem,” GIW 2005.
“FastPCMSA: An improved parallel algorithm for the constrained multiple sequence alignment problem,” FCS 2006.
“A* Algorithms for the Constrained Multiple Sequence Alignment Problem,” ICAI 2006.
“Space-efficient Parallel Algorithms for the Constrained Multiple Sequence Alignment Problem,” BIOCOMP 2006.
2011/5/20 36 PPCB

2011/5/20 37 PPCB

RE-MuSiC steps Step1. Compute the score of the global sequence alignment without
any constraint using the Needleman-Wunsch algorithm between all pairs of the K sequences and build the distant matrix.
Step2. Follow the results of Step1 to create a complete graph G of K sequences.
Step3. Use the complete graph G to construct a Kruskal merging order tree .
Step4. Use the created in Step3 as a guide tree. Progressively align the sequences according to the branching order of the Two closest pre-aligned groups of sequences are joined by CPSA algorithm to represented sequences of two groups. (ClustalW)
2011/5/20 38 PPCB

GPU-REMuSiC implementation
2011/5/20 39 PPCB

In the past, we have designed an efficient parallel algorithm for the
constrained multiple sequence alignment based on the memory-efficient
algorithm (MuSiC-ME). (PCMSA, MPI)
3k
0
5
10
15
20
25
30
0 5 10 15 20 25 30 35
total processers
spee
d up
32 sequences 64 sequences 128 sequences
256 sequences 512 sequences
4k
0
5
10
15
20
25
30
0 5 10 15 20 25 30 35
total processers
spee
d up
32 sequences 64 sequences 128 sequences
256 sequences 512 sequences
5k
0
5
10
15
20
25
30
0 5 10 15 20 25 30 35
total processers
spee
d u
p
32 sequences 64 sequences 128 sequences
256 sequences 512 sequences
2011/5/20 40 PPCB

Define eight possible
methods for computing
dynamic programming
by CUDA
(a)SRST (b) SRMT
Figure 3: SRST and SRMT.
(a) ARST (b) ARMT
Figure 4: ARST and ARMT.
(a) SDST (b) SDMT
Figure 5: SDST and SDMT.
(a) ADST (b) ADMT
Figure 6: ADST and ADMT.
2011/5/20 41 PPCB

Figure 7. Distance matrix and the thread blocks allocation.
Figure 8. The load balancing cutting technology by two GPUs
2011/5/20 42 PPCB

(Device) Grid
Constant
Memory
Texture
Memory
Global
Memory
Block (0, 0)
Shared Memory
Local
Memory
Thread (0, 0)
Registers
Local
Memory
Thread (1, 0)
Registers
Block (1, 0)
Shared Memory
Local
Memory
Thread (0, 0)
Registers
Local
Memory
Thread (1, 0)
Registers
Host
Intra-task parallelization
•Sequences (global memory)
•Scoring matrix (constant memory)
•alphabetical order
•ASCII indexing
•Si and Sj stored in shared memory
•Result stored in shared memory
•Memory efficient
•Only score
2011/5/20 43 PPCB
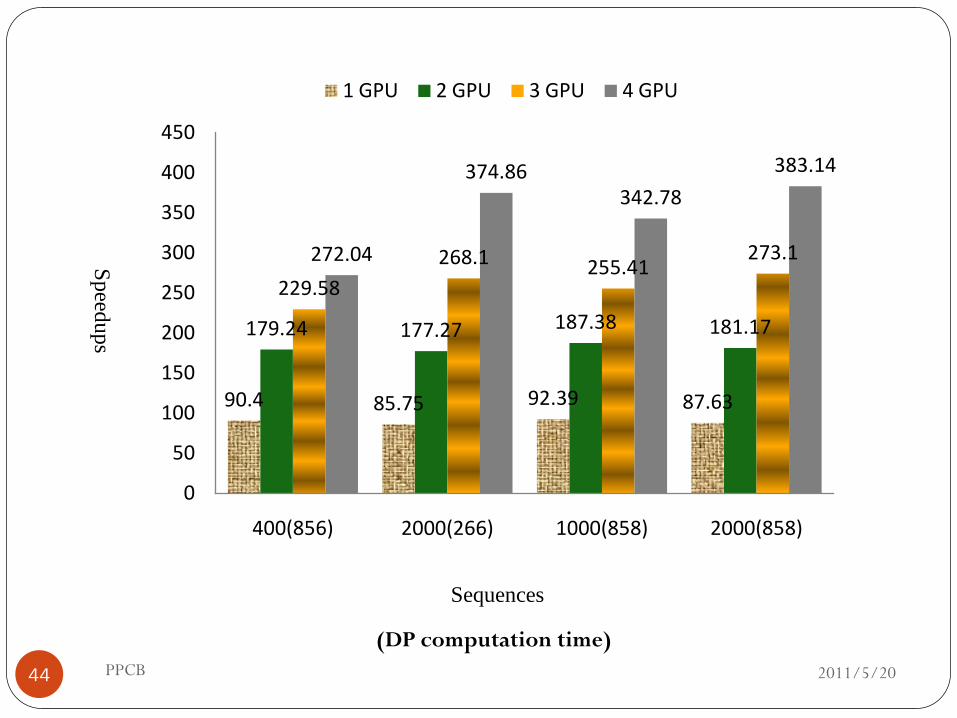
Sp
eedu
ps
Sequences
90.4 85.75 92.39 87.63
179.24 177.27 187.38 181.17
229.58
268.1 255.41273.1272.04
374.86342.78
383.14
0
50
100
150
200
250
300
350
400
450
400(856) 2000(266) 1000(858) 2000(858)
1 GPU 2 GPU 3 GPU 4 GPU
(DP computation time)
2011/5/20 44 PPCB

Sp
eedu
ps
Sequences
Figure 10. The speedup ratios by comparing GPU-REMuSiC and RE-MuSiC.
12.51
22.78
12.59 13.5113.3
26.36
13.5
21.1
13.5
28.05
13.68
21.9
13.52
29.18
13.93
22.36
0
5
10
15
20
25
30
35
400(856) 2000(266) 1000(858) 2000(858)
1 GPU 2 GPU 3 GPU 4 GPU
2011/5/20 45 PPCB

0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
CPU 1 GPU 2 GPU 3 GPU 4 GPU
Other Distant Matrix
2011/5/20 46 PPCB
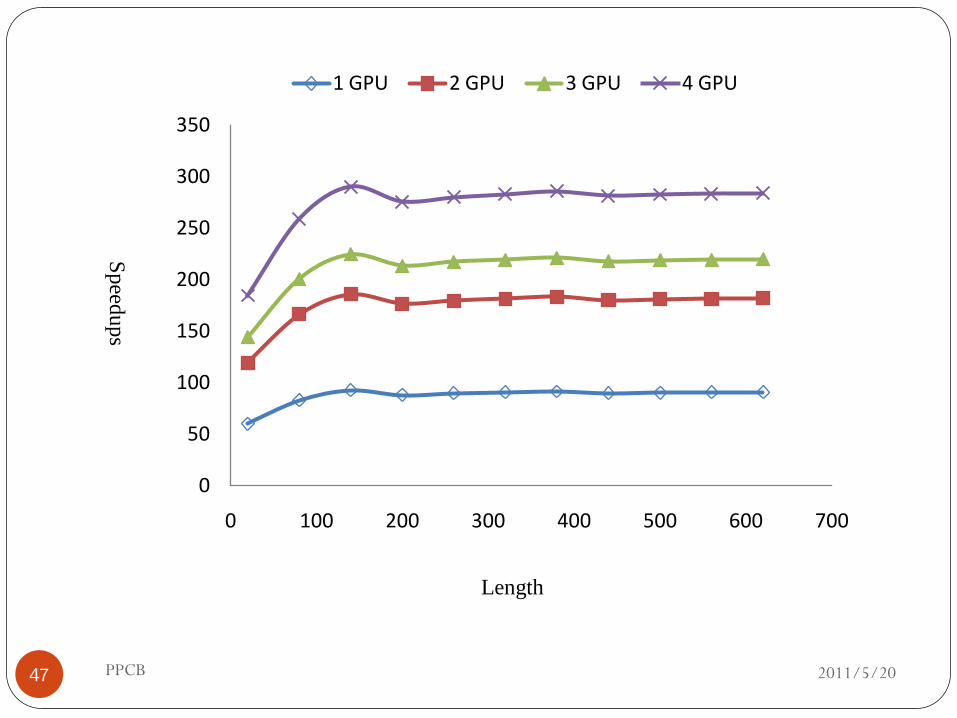
Sp
eedu
ps
Length
0
50
100
150
200
250
300
350
0 100 200 300 400 500 600 700
1 GPU 2 GPU 3 GPU 4 GPU
2011/5/20 47 PPCB









![Real-Time Volume Graphics [02] GPU Programming](https://static.fdocuments.us/doc/165x107/568132af550346895d9961ba/real-time-volume-graphics-02-gpu-programming.jpg)








