

Flexible Paxos: Reaching agreement without majorities
53
Flexible Paxos: Reaching agreement without majorities Heidi Howard, Dahlia Malkhi, Alexander Spiegelman University of Cambridge, VMware Research, Technion [email protected] @heidiann360 hh360.user.srcf.net fpaxos.github.io 1
-
Upload
heidi-howard -
Category
Technology
-
view
3.868 -
download
2
Transcript of Flexible Paxos: Reaching agreement without majorities

Flexible Paxos: Reaching agreement
without majoritiesHeidi Howard, Dahlia Malkhi, Alexander Spiegelman University of Cambridge, VMware Research, Technion
[email protected] @heidiann360
hh360.user.srcf.net fpaxos.github.io
1

2

3

TL;DR Majorities are not necessary to safety reach distributed consensus.
4

Aims
1. Understand the widely adopted Paxos algorithm and how Flexible Paxos safely generalizes it
2. Introduce a broad spectrum of possibilities for reaching consensus and
3. Promote the idea that Paxos is not the best point on this spectrum for most practical systems
5

Defining ConsensusReaching agreement in an asynchronous distributed system in the face of crash failures.
More specifically:
• Compromising safety is never an option
• No clock synchronization is assumed
• Participants fail by crashing and messages may be lost but neither can act arbitrarily
6

Consensus is not a solved problem
• Consensus is not scalable - often limited to 3, 5 or 7 participants.
• Consensus is slow - each decision requires at least majority agreement, more when failures occur.
• Consensus is not available - cannot handle majority failures or many network partitions.
You pay a high price even if no failures occur. Consider by many as “best avoided”
7

Back in the good old days …
8

Single server system
Client
Client
Client
Server
9

Single server system
Client
Client
Client
Server
Append
10

Single server system
Client
Client
Client
Server
OK @ 4
11

Single server system
Client
Client
Client
ServerRead 4
12

Single server system
Client
Client
Client
Server
13

Single server system
Client
Client
Client
Server
14

Single server system
Client
Client
Client
Server
15

Distributed systems came to the rescue
16

Replicate for availability
Client
Client
Client
Server
Server
Server
17

Replicate for availability
Client
Client
Client
Leader
Server
Server
Append
18

Replicate for availability
Client
Client
Client
Leader
Server
Server
19

Replicate for availability
Client
Client
Client
Leader
Server
Server
OK
OK
20

Replicate for availability
Client
Client
Client
Leader
Server
Server
OK
21

How many copies is enough?
We refer to any group of nodes which is ‘enough’ as a replication quorum
More copies, More resilient
Fewer copies, Faster replication
22

Now what happens when a server fails?
23

Client
Client
Client
Leader
Server
Server
24

Client
Client
Client
Leader
Server
Server
Append
25
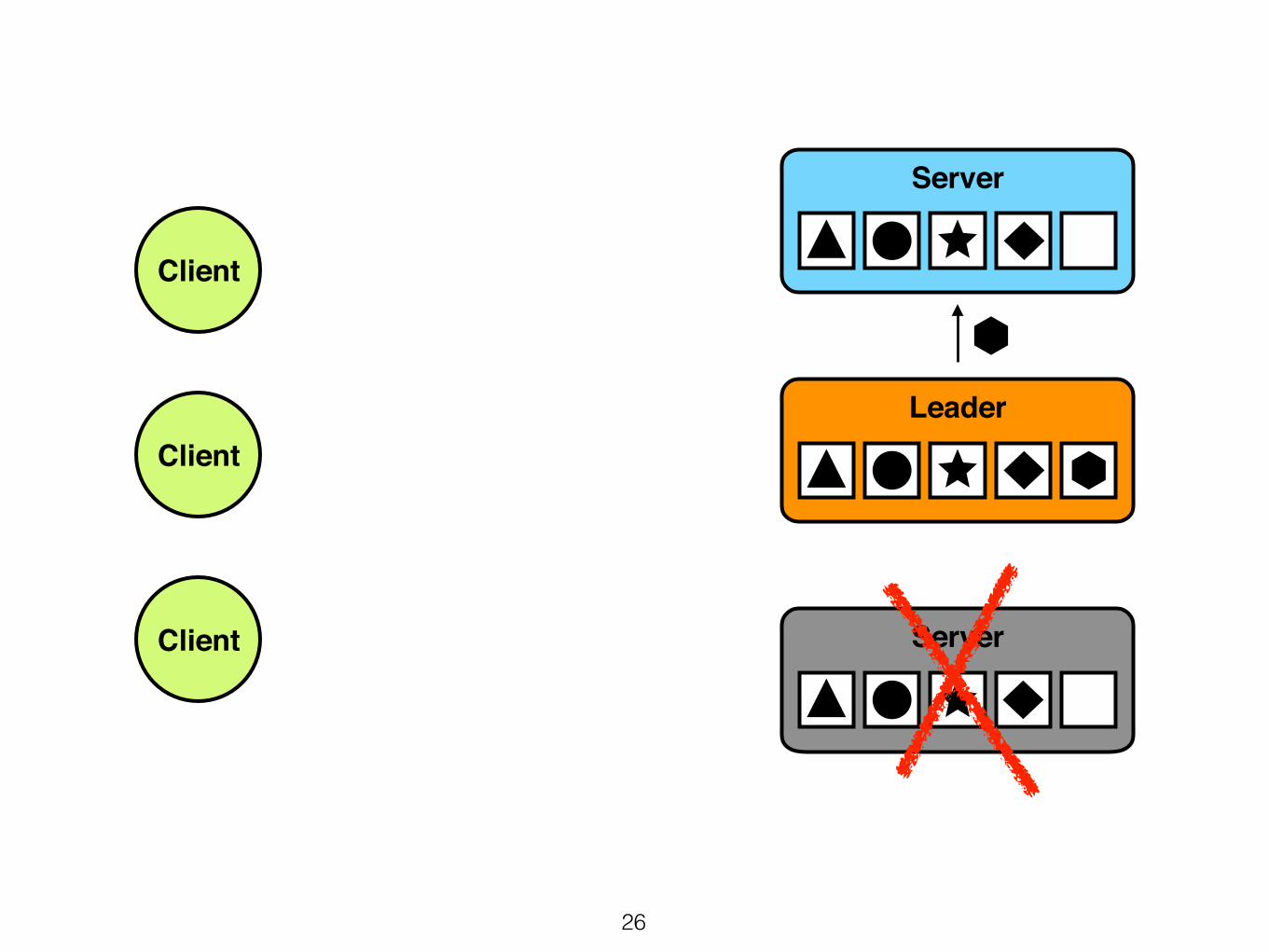
Client
Client
Client
Leader
Server
Server
26

Client
Client
Client
Leader
Server
Server
27
OKOK

What happens when the leader fails?
28

Client
Client
Client
Leader
Server
Server
29

Client
Client
Client
Leader
Server
Leader
30

Recall that we never compromise safety
Thus the new leader has two jobs:
1. To stop the old leader. We cannot say for sure that they have failed.
2. To learn about which log entries have already been agreed and not overwrite them.
The order is important here!
31

How to stop past leaders?
They may come back to haunt us.
• Ask them to stop
• Use leases and wait for them to expire
• Ignore them by having nodes promise to stop replicating for them
32

How many promises are enough?
Leaders cannot wait forever.
We need a minimum of one node from each replication quorum to promise not to replicate new entries.
We refer to this as the leader election quorum.
33

Promises are tricky to safely break
Let’s assume each leadership term has a unique term number.
Problem: We don’t always know who the past leaders are. We need a deterministic scheme for breaking promises.
Solution: Each node stores the promise as “ignore all smaller terms”.
34

Learn all committed entries
The new leader must never overwrite committed entries.
It must learn about the committed entries before it starts adding new entries without leaving holes.
35

Safely handle in-progress commands
Any in-progress entries already replicated on the leader election quorum nodes must be finished by the new leader.
If there are conflicting in-progress entries from different leaders, we choose the log entry with the highest view.
36

Context
This mechanism of views and promises is widely utilised. This core idea is commonly referred to as Paxos.
It’s a recurring foundation in the literature:
Viewstamped Replication [PODC’88], Paxos [TOCS’98], Zab/Zookeeper [ATC’10] and Raft [ATC’14] and many more.
37

What’s changed?
Traditionally, it was thought that all quorums needed to intersect, regardless of whether the quorum was used for replication or leader election.
Majorities are the widely adopted approach to this.
We have just seen that the only requirement is that leader election quorums intersect with replication quorums.
38

ImplicationsIn theory:
• Helps us to understand Paxos
• Generalisation & weakening of the requirements
• Orthogonal to any particular algorithm built upon Paxos
In practice:
• Many new quorum schemes now become feasible
• Introduces a new breed of scalable, resilient consensus algorithms.
39

Quorums Systems
40

Majorities
Replication quorum Leader election quorum41

Majorities - 1
Replication quorum Leader election quorum42

CountingReplication quorum + Leader election quorum = Number of nodes + 1
More copies, More resilient
Fewer copies, Faster replication
43

Replication quorum = 2/6
Replication quorum Leader election quorum44

Replication quorum = 3/8
Replication quorum Leader election quorum45

Not all members were created equal
• Machines and the networks which connect them are heterogeneous
• Failures are not independent: members are more likely to simultaneously fail if they are located in the same host, rack or even datacenter
46
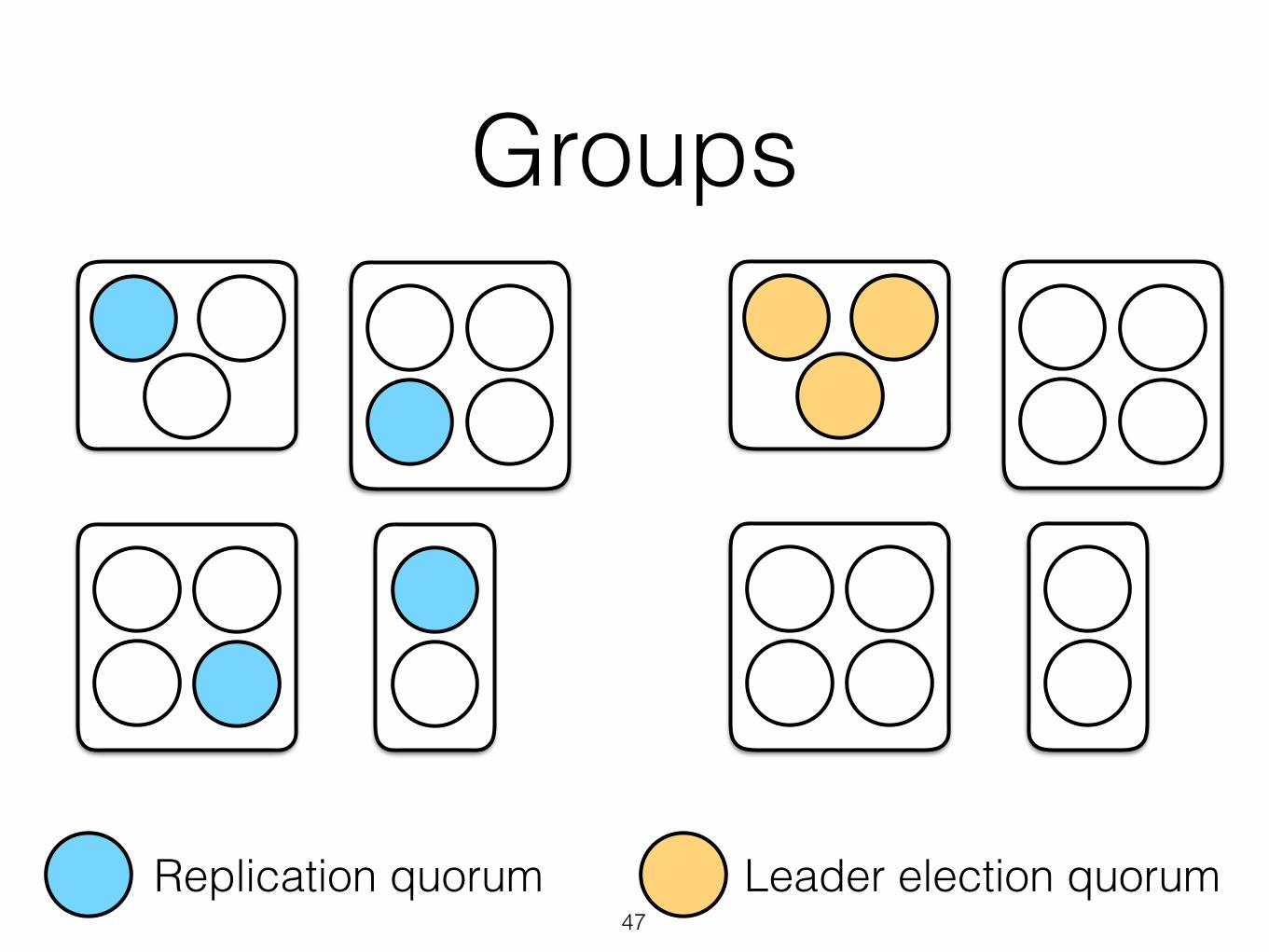
Groups
Replication quorum Leader election quorum47

Grids
Replication quorum Leader election quorum48

Any many more…
Weighed Voting
2
2
33
1
1
Grid Paths
Combined Schemes Hierarchy49

Majorities are no longer ‘one size fits all’
Majorities are unlikely to be optimal for most practical systems
• Requirements of real systems differ. Performance really matters.
• Leader election is rare so often we optimize for the common replication phase.
50

Summary• The only quorum intersection requirement is that
leader election quorums must intersect with the replication quorums.
• Majorities are not the only option for safely reaching consensus and are often not best suited to practical systems.
• Don’t give up on strong consistency guarantees. Distributed consensus can be performant and scalable.
51

Ongoing Work• Adoption into existing production systems
• Building new algorithms offering interesting compromises
• Practical analysis of quorum systems for consensus
• Extending to other algorithms and different failures models e.g. Flexible Fast Paxos and Flexible Byzantine Paxos
52


















