
Fast Communication and User Level Parallelism
27
Fast Communication and User Level Parallelism Howard Marron
-
Upload
ingrid-franks -
Category
Documents
-
view
22 -
download
1
description
Fast Communication and User Level Parallelism. Howard Marron. Introduction. We have studied systems that have attempted to build transparent layers below the application that created properties like replication and group communication. - PowerPoint PPT Presentation
Transcript of Fast Communication and User Level Parallelism

Fast Communication and User Level Parallelism
Howard Marron

Introduction
We have studied systems that have attempted to build transparent layers below the application that created properties like replication and group communication. We will look at some areas where more control has been given to the user on parallelism

Threads
Allows smaller granularity to programs for better parallelism and performance.Will have lower overhead than processesSame program will run on one machine as a multiprocessor with little or no modificationThreads in same process can easily communicate since they share the same address space

Implementation
Do we want threads and if so where should we implement them?
Operation FastThreads(ULT) Topaz threads (KLT) Ultrix processesNull - Fork 34 948 11300Signal- Wait 37 441 1840
Latency in μsec on a Firefly system

Advantages and problems of ULT
Advantages Thread switching
does not involve the kernel:
Scheduling can be application specific: choose the best algorithm.
ULTs can run on any OS. Only needs a thread library
Disadvantages Most system calls are
blocking and the kernel blocks processes. So all threads within the process will be blocked
The kernel can only assign processes to processors. Two threads within the same process cannot run simultaneously on two processors

Advantages and inconveniences of KLT
Advantages The kernel knows
what the processing environment is and will assign threads accordingly.
Blocking is done on a thread level
Kernel routines can be multithreaded
Disadvantages Thread switching
within the same process involves the kernel. We have 2 mode switches per thread switch.
This results in a significant slow down in thread switches within same process

ULT with Scheduler Activations
Implement user level threads with the help of the kernel.Gain the flexibility and performance of ULTHave functionality of KLT without the overhead

ULT over KLT
Kernel operates without knowledge of user programmingUser threads are never notified of what the kernel schedules since it is transparent to userKernel schedules threads without respect to user thread priorities and memory locations.
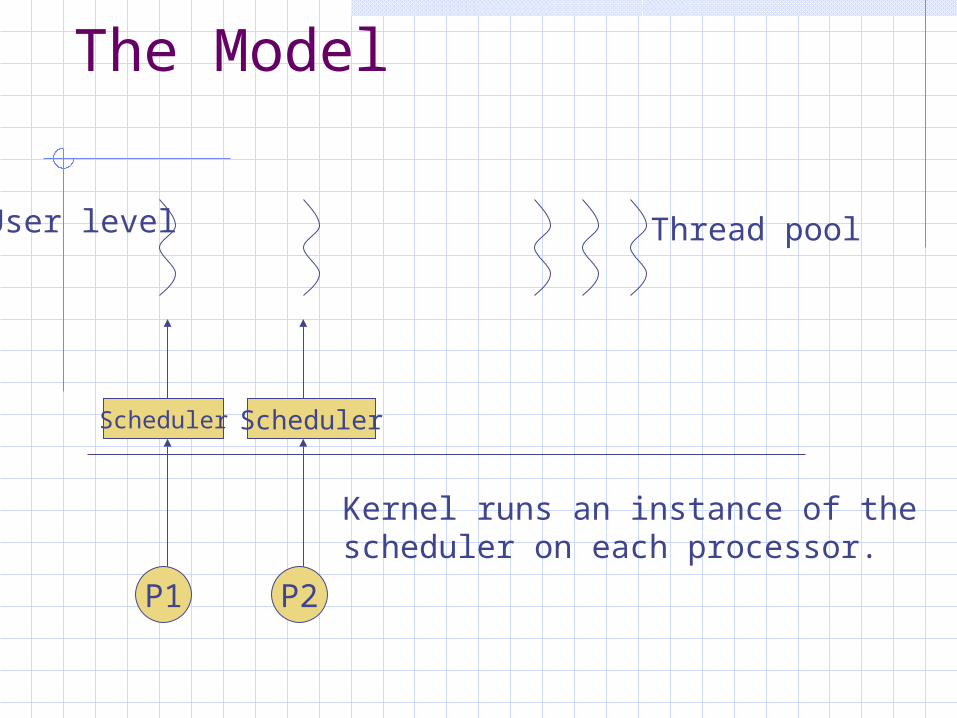
The Model
P1 P2
Scheduler Scheduler
User level Thread pool
Kernel runs an instance of thescheduler on each processor.

Kernel Support of ULT
Kernel has control of processor allocationULT has control of what threads to run on allocated processorsKernel notifies ULT scheduler of any changes to environmentULT scheduler can notify Kernel of current processor needs

Scheduler Activations
Add processor – run a thread hereProcessor preempted – returns state of preempted processor, can run another threadScheduler has blocked – can run thread hereScheduler has unblocked – return thread to ready list

How the kernel and scheduler work together

Hints to Kernel
Add more processors
This processor is idle

Critical Sections
Idea 1 On a CS conflict give control back to
thread holding lock Thread will give control back after
done with CS. Found that was too slow to find if
thread was in CS Hard to make thread give up control
after CS is done

Critical Sections (Cont.)
Idea 2 Make copies of critical sections
available to scheduler. Compare PC of thread with CS to
check if holding a lock Can run the copy of CS and will return
sooner than before since the release of the lock is known to the scheduler.

Results
Operation Fast ThreadsFastThreads w/
schedulers activations Topaz Threads Ultrix ProcessesNull-fork 34 37 948 11300Signal Wait 37 42 441 1840

Results 2

Threads Summary
Best solution to threads problem will lay somewhere between ULT and KLTBoth must cooperate for best performanceWant to have most of control in user level to manage threads since kernel is far away from threads

Remote Procedure Calls
A technique for constructing distributed systemsAllows user to have no knowledge of transport systemCalled procedure can be located anywhereStrong client/server model of computing

Problems with RPC
Adds huge amount of overhead More protection in every call All calls trap to OS Have to wait for response from other
system All calls treated the same – worst case

Ways to improve
95%< all RPCs are to local domainOptimize most taken pathReduce number of system boundaries that RPC crosses

Anatomy of a remote RPC
callRPC()
Run service
CLIENT SERVERKernelUser User
Protection checks
Message transfer
Interpret andDispatch
Schedule
Wake up thread reschedule
Protection checks
Message transfer
Reply

Lightweight RPC (LRPC)
Create new routines for cross domain callsUse RPC similar calls for cross system callsBlur the line of client/server in new callsReduce number of variable copies to messages and stacks by maintaining stacks that are dedicated to individual callsEliminates needs to schedule threads on RPC receipt at server, because processor can be instructed to just switch the calling and called threads

Anatomy of a local LRPC
callRPC()
Run service
CLIENT KernelUserProtection checks
Copy to Stack
Reply
Resume
There is no need to scheduleThreads here, the scheduler Can be told to just switch The two threads
Copy to Stack

Multiprocessors
Can cache whole processor contexts on idle processorsInstead of context switching local processor for cross domain calls, run procedure on cached processorSaves on TLB misses and other exchanges like virtual memory
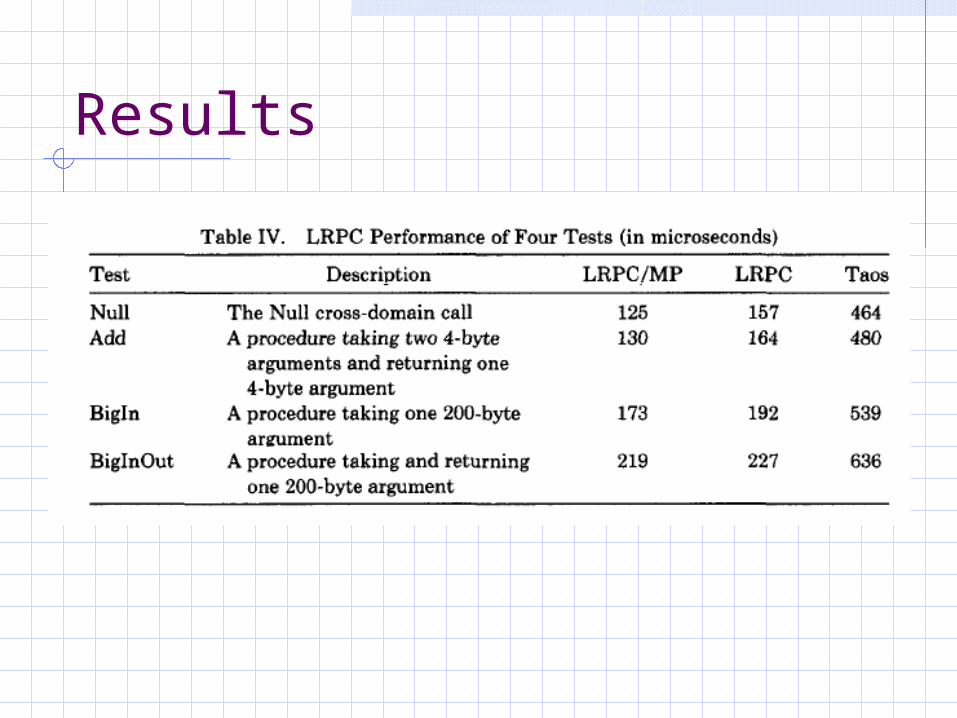
Results

LRPC Conclusions
RPCs can be improved for general caseCommon case should be emphasized not the most general caseCan reduce many unnecessary tasks when optimizing for cross domain tasks.


















