
EBI is an Outstation of the European Molecular Biology Laboratory. Bioinformatics Challenges in Data...
22
EBI is an Outstation of the European Molecular Biology Laboratory. Bioinformatics Challenges in Data Handling and Presentation to the Bioinformaticists
-
Upload
godfrey-stanley -
Category
Documents
-
view
217 -
download
1
Transcript of EBI is an Outstation of the European Molecular Biology Laboratory. Bioinformatics Challenges in Data...

EBI is an Outstation of the European Molecular Biology Laboratory.
Bioinformatics Challenges in Data Handling and Presentation to the Bioinformaticists

Metagenomic nucleotide sequence and annotation: Range of environments
Global ocean survey
Human faecal virus communities
Human distal gut microbiome
Phosphorus removal sludge communities
Obesity-associated gut microbiome
Acidophilicbacterial community
Mouse gut flora
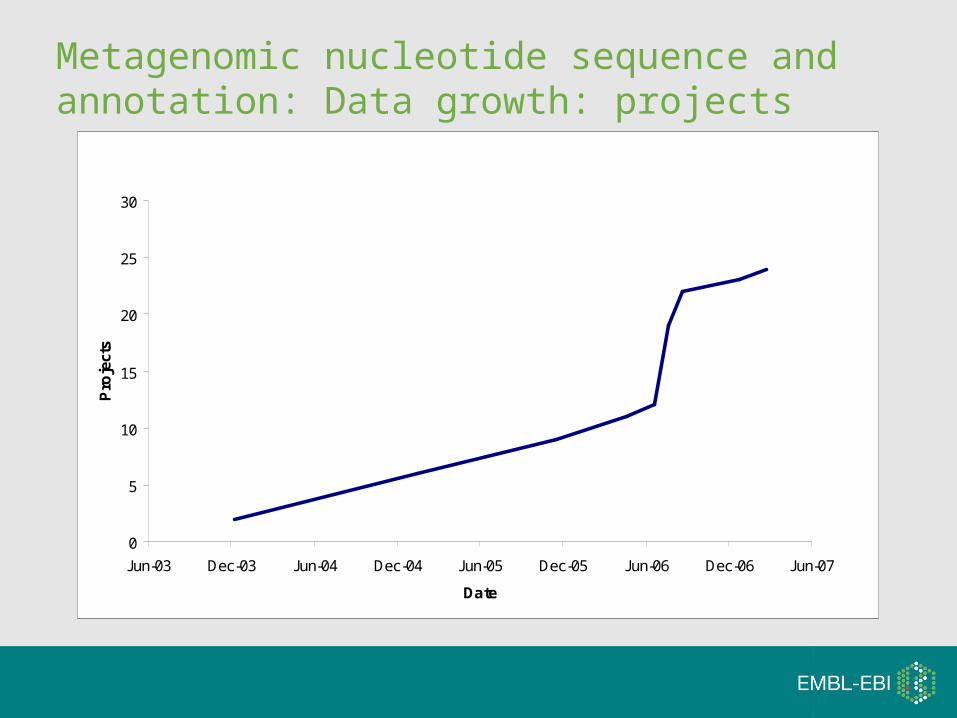
Metagenomic nucleotide sequence and annotation: Data growth: projects
0
5
10
15
20
25
30
Jun-03 Dec-03 Jun-04 Dec-04 Jun-05 Dec-05 Jun-06 Dec-06 Jun-07
Date
Pro
ject
s

Metagenomic nucleotide sequence and annotation: Data growth: volume of dataset
1
10
100
1,000
10,000
Jun-03 Dec-03 Jun-04 Dec-04 Jun-05 Dec-05 Jun-06 Dec-06 Jun-07
Date
Meg
abas
e p
airs
1
10
100
1,000
10,000
100,000
1,000,000
10,000,000
Seq
uen
ces
Bases
Sequences

Metagenomic nucleotide sequence and annotation: Assembly issues
Most metagenome records have not been assembled into scaffolds in INSDC records (only 4 of 24 projects so far) and remain as unassembled WGS records
Those that have been assembled into scaffolds show very limited assembly - of the four assembled projects, one contains almost as many scaffolds as contigs

Metagenomic nucleotide sequence and annotation: Metadata issues
• Metadata, particularly sampling information, are often not shown, or are provided with limited granularity, restricting re-analysis by users
• INSDC offers appropriate structures for such metadata, but they are frequently not used, even when the information is available to the submitters
Current:FT source 1..2866FT /organism="marine metagenome"FT /environmental_sampleFT /mol_type="genomic DNA"FT /isolation_source="isolated as part of a large datasetFT composed predominantly from surface water marine samplesFT collected along a voyage from Eastern North American coastFT to the Eastern Pacific Ocean, including locations in theFT Sargasso Sea, Panama Canal, and the Galapagos Islands"FT /note="metagenomic"FT /db_xref="taxon:408172"
Could be:FT source 1..2866FT /organism="marine metagenome"FT /environmental_sampleFT /mol_type="genomic DNA"FT /country="French Polynesia: Moorea, Cooks Bay"FT /lat_lon="17.476 S 149.81 W"FT /isolation_source="marine surface water; sampleFT depth: 34M; size range: 0.1-0.8 microns; waterFT temperature: 28.900; salinity: 35.100"FT /db_xref="taxon:408172"

Metagenomic nucleotide sequence and annotation: Taxonomy issues
Taxonomic annotation in metagenomic data is simplistic - a very small number of non-specific taxa are necessarily used to describe all of the raw data
Analysis methodology, particularly binning, is inconsistent across the dataset, so taxonomic assertions in assembled sequence are of uncertain provenance
Standards on whether or not single contigs should contribute to scaffolds for more than one taxon are yet to be established

Metagenomes and UniProt (1/2)
• As of this month, ~6 million protein sequences from Global Ocean Survey have been released (vs. 4,534,260 UniProtKB entries)
• Future exponential increase is anticipated:• The growth of public protein sequence data is exponential with a
doubling time of about 20 months• Metagenomics data will have substantially shorter doubling time• GOS data will more than double the existing protein-coding
sequences in UniProtKB

Metagenomes and UniProt (2/2)
• Perspectives• Vast amount of sequence data• Environmental context in metadata• New kind of data requires new storage, processing, and data mining
procedures
• Taxonomically unassigned data will not be included in the UniProt Knowledgebase
• UniMES – UniProt Metagenomics and Environmental sequences (June 2007)

UniMes requirements
• Distinct storage and dissemination: separated from current UniProt databases.
• Distinct production pipeline• Distinct accession number range: MES followed by 11
hexadecimal numbers, e.g. MES00000000001• Distinct data mining pipelines: less restricted rules due to
the lack of basic knowledge about the taxonomic origin of these sequences

UniMes pipeline overview
EMBL
Primary data
Genomic sequence (EMBL)
Other SubmissionsMetagenomics data
(WGS)
UniProt KnowledgebaseUniProt Metagenomics UniProt Archive
Classification
Clustering
Automatic annotationrules
Secondary analysis
Secondary analysis
DNA Metagenomics (to be established)

UniProtKB vs.UniMes Database growth
0
1
2
3
4
5
6
2005 2006 2007
UniProt Knowledgebase (in mln of sequences)UniProt Metagenomics and Environmental Sequences (in mln of sequences)

0
50
100
150
200
250
300
2005 2006 2007
UniProt Metagenomics and Environmental Sequences (storage in GB)
UniMes storage growth

UniMes hardware requirements (1/2)
• 2 HP/Compaq AlphaServers ES45 with 4 1250MHz CPU’s and 12GB Memory
Oracle database designed to store and maintain data
derived from EMBL
Oracle Warehouse for data analysis, integration
and display
• 64-bit linux farm (AMD operon) using 40 nodes for data mining procedures

UniMes hardware requirements (2/2)
• New oracle servers: Sunfire v490 with 4 1500MHz UltraSparc IV CPUS’s and 16 GB memory
• We have enough physical storage and CPU power for 2007

UniMes dissemination
• FASTA and XML files• UniProt Web Site: text and similarity searches

GOS submission
• Submission of nucleic acid sequence data to EMBL/GenBank/DDBJ is mandatory for publication of scientific paper
• Craig Venter Institute submission to EMBL/GenBank/DDBJ in March 2007
• Environmental metadata can only be found in the CAMERA website
• Metadata are of great importance for metagenomic sequence data:• Descriptions of sampling sites and habitats • Analysis of metagenomics sequence data
• URGENT need for the community to agree on what metadata must be included with the submission of any metagenomics sample

UniMes and GOS data
Protein Sequences
0
1,000,000
2,000,000
3,000,000
4,000,000
5,000,000
6,000,000
7,000,000
8,000,000
9,000,000
10,000,000
GOS UniParc
Amino Acids (bln)
0.00
50.00
100.00
150.00
200.00
250.00
300.00
GOS UniParc
Average Sequence Length
050
100150
200
250300
350400
GOS UniProt KB
Median Sequence Length
0
50
100
150
200
250
300
GOS UniProt KB

UniMes and GOS data
Fragm ents (%)
0
5
1015
20
25
3035
40
45
GOS UniP rot KB
Amino Acid Distribution
0
20000000
40000000
60000000
80000000
100000000
120000000
140000000
A R N D C Q E G H I L K M F P S T W Y V B Z X
GOS UniProt KB

UniMes and GOS data
Percentage Coverage by InterPro Methods
79.5
80
80.5
81
81.5
82
82.5
83
83.5
84
UniProt KB UniParc GOS

UniMes and GOS data
Top 10 InterPro entries hitting UniProt: Top 10 InterPro entries hitting GOS
Top 10 InterPro entries hitting UniParc (including GOS):

UniMes and GOS data: Analysis
Calculation time: 763,425 CPU hoursStorage for InterPro hits to GOS: 50 GB


















