
More Practical Dynamo: Practical Uses for Dynamo Within Revit
Upload
justin-carpenterCategory
view
218download
1
Dynamo: Amazon's Highly Available Key-value Store
Dr. Yingwu Zhu

Background
• Data consistency• Vector clocks and data versions• Update confliction resolution (or version
reconciliation)• Quorum systems• Merkle trees

Data Consistency• Ensure that each user observes a consistent view of
the data, including visible changes made by the user and any other users.
• Weak consistency• Strong consistency• Eventual consistency: when no updates occur for a long period of
time, eventually all updates will propagate through the system and all the replicas will be consistent.
• Strong consistency and High availability– Don’t be greedy: Pick one!– Trade consistency for availability
• Example: data cache + lease in DFS but with network failures;

Vector Clock
• Used to detect update conflicts in distributed systems
• A vector of (user, counter) pairs– E.g. <(A, 3), (B, 1), (C, 2)>– A modifies the associated data, then <(A, 4), (B, 1), (C,
2)>– If the counters on the first object’s clock are less-than-
or-equal to all of the users in the second clock, then the first is subsumed by the second.
– Otherwise, conflicts are detected!

Data Versions
• Data replicas with different vector clocks, we call them different versions
• Some data versions can be merged if their vector clocks are compatible (one is subsumed by the other)
• Otherwise, need to resolve conflicts!

Conflict Resolution
• Syntactic reconciliation: if one time clock subsumes the other
• Semantic reconciliation: how to merge different versions of data in conflict– Application resolver: leave it to the
application/user– “Last write wins”: timestamp-based resolution
• Simple (each data object is associated with a timestamp)

Quorum Systems
• In data replication (N replicas), Divide the quorum sets into reading sets R and writing sets W
• R+W > N (overlaps between R and W)– the latency of a read/write operation is dictated
by the slowest of the R (or W) replicas. For this reason, R and W are usually configured to be less than N, to provide better latency.
– Different R and W for different tradeoffs between read and write performance

Merkle Trees• A tree of hashes
in which the leaves are hashes of data blocks in, for instance, a file or set of files. Nodes further up in the tree are the hashes of their respective children
• used to verify its contents.

Motivation In Modern Data Centers:
Hundreds of services Thousands of commodity machines Millions of customers at peak times Performance + Reliability + Efficiency = $$$10
Outages are bad Customers lose confidence , Business loses
money Accidents happen

Dynamo
• Motivation• Goals• System Design• Evaluation

Motivation Data center services must address
Availability Service must be accessible at all times
Scalability Service must scale well to handle customer
growth & machine growth Failure Tolerance
With thousands of machines, failure is the default case
Manageability Must not cost a fortune to maintain

Goals
• Build a distributed storage system -- Dynamo:– Scale– Simple: key-value interface– Highly available (always writable)– Service Level Agreements (SLA) Guarantee

System Assumptions and Requirements
• Query Model: simple read and write operations to a data item that
is uniquely identified by a key.– RDBMS is overkill, expensive hardware requirements
• ACID Properties: Atomicity, Consistency, Isolation, Durability.– Weak consistency for high availability– No isolation, only single key update
• Efficiency: latency requirements which are in general measured at the 99.9th percentile of the distribution.– Amazon cares all the clients rather than the majority
• Other Assumptions: operation environment is assumed to be non-hostile and there are no security related requirements such as authentication and authorization.

Service Level Agreements (SLA)
• Application can deliver its functionality in bounded time: Every dependency in the platform needs to deliver its functionality with even tighter bounds.
• Example: service guaranteeing that it will provide a response within 300ms for 99.9% of its requests for a peak client load of 500 requests per second.
Service-oriented architecture of Amazon’s platform

Design Consideration
• Sacrifice strong consistency for availability• Conflict resolution is executed during read
instead of write, i.e. “always writeable”.• Other principles:
– Incremental scalability.– Symmetry.– Decentralization.– Heterogeneity.

Simple Interface
Only two operations put (key, context, object)
key: primary key associated with data object context: vector clocks and history (needed for
merging) object: data to store
get (key)

Data Partition
• Incrementally scale • Dynamically partition data
over a set of nodes• Consistent hashing: the output
range of a hash function is treated as a fixed circular space or “ring”.
• ”Virtual Nodes”: Each node can be responsible for more than one virtual node.
• Same to Chord ring in spirit

Advantages of using virtual nodes
• If a node becomes unavailable the load handled by this node is evenly dispersed across the remaining available nodes.
• When a node becomes available again, the newly available node accepts a roughly equivalent amount of load from each of the other available nodes.
• The number of virtual nodes that a node is responsible can decided based on its capacity, accounting for heterogeneity in the physical infrastructure.

Data Replication
• Each data item is replicated at N hosts.
• “preference list”: The list of nodes that is responsible for storing a particular key.– Similar to Chord successor list

Data Versioning
• A put() call may return to its caller before the update has been applied at all the replicas
• A get() call may return many versions of the same object.
• Challenge: an object having distinct version sub-histories, which the system will need to reconcile in the future.
• Solution: uses vector clocks in order to capture causality between different versions of the same object.

Data Versioning Updates generate a new vector clock Eventual consistency
Multiple versions of the same object might co-exist
Syntactic Reconciliation System might be able to resolve conflicts
automatically Semantic Reconciliation
Conflict resolution pushed to applications

Vector Clock
• A vector clock is a list of (node, counter) pairs.• Every version of every object is associated
with one vector clock.• If the counters on the first object’s clock are
less-than-or-equal to all of the nodes in the second clock, then the first is an ancestor of the second and can be forgotten.– The 2nd subsumes the 1st one

Vector clock example

Execution of get() & put()
Coordinator node is among the top N in the preference list
Coordinator runs a R/W quorum system R = read quorum W = write quorum R + W > N

Sloppy Quorum
• R/W is the minimum number of nodes that must participate in a successful read/write operation.
• Setting R + W > N yields a quorum-like system.• In this model, the latency of a get (or put)
operation is dictated by the slowest of the R (or W) replicas. For this reason, R and W are usually configured to be less than N, to provide better latency.

Handling Transit Failures
Temporary failures: Hinted Handoff Offload your dataset to a node that follows the
last of your preference list on the ring Hint that this is temporary Responsibility sent back when node recovers

Hinted handoff
• Assume N = 3. When A is temporarily down or unreachable during a write, send replica to D.
• D is hinted that the replica is belong to A and it will deliver to A when A is recovered.
• Again: “always writeable”

Handling Permanent Failures
Permanent failures: Replica Synchronization Synchronize with another node Use Merkle Trees: leave nodes are hashes for keys
top-down comparison Minimize data transferred for synchronization Reduce disk reads for synchronization

Membership & Failure Detection
Ring Membership Use background gossip to build 1-hop DHT Use external entity to bootstrap the system to
avoid partitioned rings Failure Detection
Use standard gossip, heartbeats, and timeouts to implement failure detection

Implementation
• Java• Local persistence component allows for
different storage engines to be plugged in:– Berkeley Database (BDB) Transactional Data
Store: object of tens of kilobytes
– MySQL: object of > tens of kilobytes
– BDB Java Edition, etc.

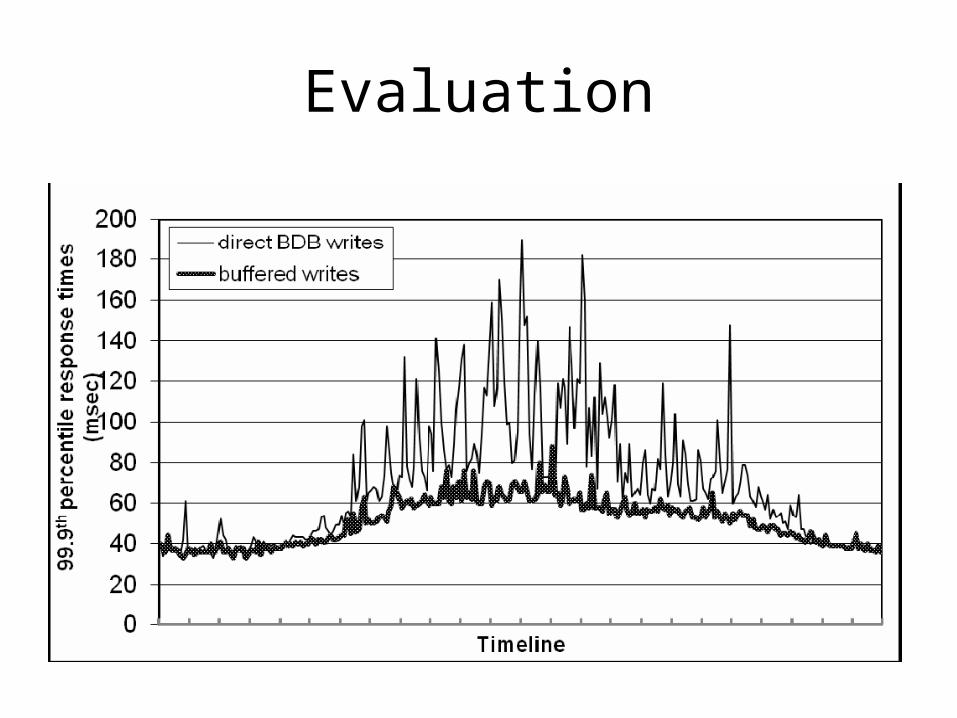
Evaluation
12 hours per xtick
Most within 300ms of SLA
Evaluation

Buffered or No-buffered?
• Write into memory, considered write complete
• Writer thread periodically flush the data into disk
• Pros: further improve performance• Cons: trade durability for performance

Summary of techniques used in Dynamo and their advantages
Problem Technique Advantage
Partitioning Consistent Hashing Incremental Scalability
High Availability for writesVector clocks with reconciliation
during readsVersion size is decoupled from update
rates.
Handling temporary failures Sloppy Quorum and hinted handoff Provides high availability and durability guarantee when some of the
replicas are not available.
Recovering from permanent failures Anti-entropy using Merkle treesSynchronizes divergent replicas in the
background.
Membership and failure detectionGossip-based membership protocol
and failure detection.
Preserves symmetry and avoids having a centralized registry for storing membership and node
liveness information.

Thinking?
• What matters in distributed systems?• How do we make tradeoffs?• What techniques have you learned from this
paper in implementing a distributed system?


















