
Deep Learning Chapter12
92
16/06/14 DENSO IT LABORATORY, INC. Copyright @ 2015 Denso IT Laboratory All Right Reserved. p. 1 p. 1 Chapter 12 Applications @uchumik
-
Upload
kei-uchiumi -
Category
Technology
-
view
2.577 -
download
2
Transcript of Deep Learning Chapter12

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 1
p. 1
Chapter 12Applications
@uchumik

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 2
12.2 COMPUTER VISIONCHAPTER 12. APPLICATIONS

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 3
コンピュータビジョン
• 最も活発なディープラーニングの適⽤先の1つ– ⼈間には簡単,機械には難しい領域– 標準的なベンチマークタスクがある
• 物体認識,OCR(光学⽂字認識)
• 応⽤範囲– 多岐に渡る
• ⼈間のvisual abilityの再現:e.g. 顔認識• 全く新しいvisual abilityの創造
– e.g. 動画の中の物体の振動から⾳を再現する– 主に前者に注⼒している

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 4
CVにおけるディープラーニングの適⽤
• ほとんどは物体認識や何らかの形状の検出– 物体認識
• 画像の中に何があるのか• バウンディングボックス単位で物体周辺に注釈付け
– 画像からシンボル系列を書き起こす(これちょっとわからない)• マルチラベリング?
– セグメンテーション• 各ピクセルが物体の内側か外側かをラベル付け
• ⽣成モデリングがディープラーニング研究の指針– 画像合成の⼀連の研究もある
• 画像合成や創造ができるモデルは画像の復元にも使える

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 5
前処理
• 画像の規格化– 画素の持つ値が妥当な範囲に収まるようにする
[0,1] or [-1,1], etc.– 値の範囲が異なるデータを混ぜると上⼿くいかない
• ⼊⼒画像のトリミング– 標準的なサイズにトリミング– 任意のサイズに対応するものもある(Waibel et al.,
1989)– Convolutional Model の場合は⼊⼒に応じた出⼒サイ
ズになる• ノイズ除去やピクセルのラベリングなど(Hadsell et al.,
2007)

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 6
Dataset Augmentation
• 訓練データセットに限定した前処理の1つ• ほとんどのモデルで汎化誤差を⼩さくできる• テスト時にも適⽤可能なもの– ⼊⼒画像に少しだけ変更を加えたものを複数作成
• 位置を少しずらしてトリミングするなど– 複数の予測結果で投票
• アンサンブル学習のアプローチと解釈可能

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 7
正規化処理
• 学習データとテストセット両⽅に適⽤• データのばらつきを減らすことで汎化– コンパクトなモデルで訓練データが表現できる– 無駄に複雑なモデルにしなくて良い

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 8
あまりこの章はディープに関係していない
• 前処理は別にディープに限らない話• ⼤きなモデルを⼤規模データで学習する場合は前
処理不要な場合もある– AlexNet は訓練事例から平均画像を引く処理のみ
(Krizhevsky et al., 2012)

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 9
前処理について概要を紹介

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 10
Contrast Normalization
• コントラストのばらつきを抑える処理• 画像を で表す
• 画像全体のコントラスト
• 輝度平均
⾚,緑,⻘の輝度

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 11
Gloval contrast normalization
• 輝度平均を引いてばらつきを抑える• 標準偏差が s になるようスケーリング– s は通常 1– ゼロ割が発⽣しないように ε,λ を導⼊
• L2ノルムのリスケーリングになっている

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 12
GCN の解釈
• 球⾯上に画像をマッピングしている• Raw input
– 輝度の⼤きさがバラバラでベクトルの向きは同じものがある– ばらつきを隠れ層で吸収しようとすると,バイアス項だけ異なるような隠れ
ユニットが必要になる• GCN
– 輝度のばらつきがなくなるのでベクトルの向きだけに問題が簡略化される

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 13
GCN の問題
• 画像の中に⼤きな影や明るい領域がある場合– 半分がビルの陰になっている広場の画像など– 影の部分のエッジが⽬⽴たなくなってしまう
Local contrast normalization

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 14
Local contrast normalization
• 画像全体ではなく,⼩領域に対して規格化
⾒えにくいけど,エッジが際⽴っている

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 15
LCN の定義
• 近傍ピクセルを使って平均0,標準偏差sに規格化• いくつかのバリエーション– 対象ピクセルを中⼼とした矩形ウィンドウを⽤いる
(Pinto et al., 2008)– ガウシアンで重み付けて平均や標準偏差を計算する– カラー画像を処理する場合
• チャンネルごとに分けて処理する• 複数チャンネルの情報を組み合わせる(Sermanet et al.,
2012)
• ゼロ割対策は GCN 同様で必要– ⼩領域だと標準偏差がよりゼロになりやすい

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 16
Dataset Augmentation
• 訓練データに修正を加えた事例を追加する– 簡単に汎化性能を上げられる
• 物体認識は分類タスクで DA の影響が⼤きい– ⾓度の違いなどで⾒え⽅が変わる– 幾何的な演算で簡単に変形が可能– 無作為な変形や回転,反転などでデータを増やして汎
化性能を上げられる• もっと⾼度な DA が使われることもある– 画像の⾊をランダムに微動(Krizhevsky et al., 2012)– ⼊⼒に⾮線形な歪みを加える(LeCun et al., 1998b)

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 17
12.3 SPEECH RECOGNITIONCHAPTER 12. APPLICATIONS
ほとんど読み物の章で⾳声認識の知識がないとよく分からない…

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 18
⾳声認識
• The automatic speech recognition(ASR)
– ⾳響信号の系列が与えられた時に最尤な単語or⽂字列を求める関数を学習
• ⼊⼒⾳響ベクトル列– よくやられるのは20msフレームで分割
• 出⼒系列– 通常は単語列あるいは⽂字列

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 19
GMM-HMM
• 80年代から2012年くらいまでのstate-of-the art
• GMMs: Gaussian mixture models– ⾳響的な特徴と⾳素間の関係のモデル
• HMM: Hidden Markov Models– ⾳素系列のモデル

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 20
GMM-HMM model family
• ⾳響波形が以下の過程で⽣成されたとする– HMMで⾳素の状態列と⾳素系列が⽣成される
• ⾳素の状態列(beginning, middle , end of each phoneme, etc.)
– GMMで⾳素の状態から⾳響波形のセグメントが⽣成される

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 21
NN を⽤いた ASR
• 1980年代後半から90年代初期に提案された• GMM-HMMに匹敵する性能– TIMIT ⾳素認識コーパスでの評価結果
• 産業界がついてこなかった– それまでに作られた GMM-HMM の資産– ASR の実装の難易度から,新しく作るためのコスト
• 2000年代後半まで– NNはGMM-HMMのための特徴量の研究に⽤いられた
16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 22
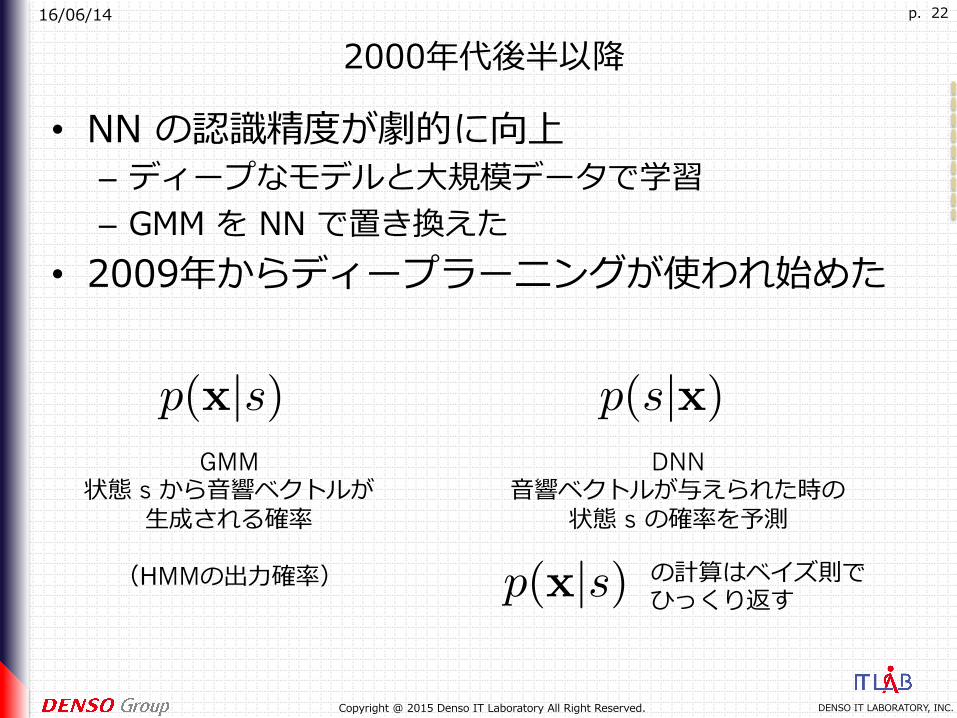
2000年代後半以降
• NN の認識精度が劇的に向上– ディープなモデルと⼤規模データで学習– GMM を NN で置き換えた
• 2009年からディープラーニングが使われ始めた
GMM 状態 s から⾳響ベクトルが
⽣成される確率
(HMMの出⼒確率)
DNN ⾳響ベクトルが与えられた時の
状態 s の確率を予測
の計算はベイズ則で ひっくり返す

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 23
事前学習
• Deep feedforward networks の初期値として RBM を⽤いる– 各層の構造とRBMの構造を合わせておく– ⼀番下の層からRBMを学習して,NNの初期値に使う

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 24
DNN 以降の⾳声認識
• TIMIT コーパスの認識率が有意に向上– ⾳素エラー率は26%から20.7%まで改善
• Phone Recognition– 話者適⽤の特徴量を追加することでエラー率低下– ⾳素ではなく単⾳の認識?
• 正直この辺は知識がないのでよく分からないです.• Phone recognition using restricted Boltzmann machines
という論⽂が⾔及されている⽂献っぽい.
• ⾳素認識から⼤語彙⾳声認識へ– ⼿法を⼤きく変えなくてもより複雑な問題に適⽤でき
た

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 25
企業の動向
• 主だった企業も⼤学と共同でディープラーニングの調査を開始– Hinton et al. (2012a) で近年のブレイクスルーを説明
• 携帯電話などで実⽤化– 同じグループから後に,⼤規模なラベル付きデータを
⽤いて様々な条件のもとで評価を実施• 事前学習は必要ないことがわかった

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 26
ブレイクスルー
• 過去10年で前例の無い単語誤り率の低下– ⼀気に30%程度下がった– 急速にコミュニティがディープラーニングにシフト– たった2年で⾳声認識ソフトのほとんどがDNNを組み
込むようになった• 過去10年の間– 学習データは⼤きくなっていたが,認識率はGMM-
HMMから⼤きな変化はなし

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 27
Convolutional Networks
• Time Delay Neural Network の発展
t
TDNN
t
f
CNN
⾳響ベクトルの系列に対して 時間⽅向のみのフィルタを適⽤
⾳響ベクトル列を時間と周波数の画像 と考えてフィルタを適⽤ 周波数領域の相関も⾒れる
f

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 28
end-to-end deep learning speech recognition systems
• deep LSTM で frame-to-phoneme alignmentGraves et al., 2013– LSTM をスタック– BPTT をするため時間⽅向での展開
• TIMIT オーパスで phone error rate 17.7• ⾳響レベルの情報と⾳素の間の対応付けをどう
学習するかというのが課題– ???

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 29
12.4 NATURAL LANGUAGE PROCESSING
CHAPTER 12. APPLICATIONS

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 30
⾃然⾔語処理
• ⼈間の使う⾔語(⾃然⾔語)を扱う– 形式的ではないために曖昧なことが多い
• 機械翻訳のような問題も含む• ここではNLPに適⽤可能なNNについて紹介

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 31
n-grams
• ⾃然⾔語のトークン列の確率分布の定義• 扱う対象に応じてトークン列が変わる– 単語,⽂字,バイト列,etc.
• n-1個のトークンが与えられた時に,n番⽬のトークンが現れる条件付き確率で定義される
• 系列の確率は n-gram 確率の積で表す

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 32
n-gram model の訓練
• 最尤推定は訓練データ中の頻度カウントで求められる
• 通常はn-gramとn-1 gramを同時に訓練– 条件付き確率は以下で計算
普通はこういうことはしない
p(wi|wi�1) =c(wi�1wi)Pwi
c(wi�1wi)頻度カウントだけ持つ

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 33
n-gram を使った⽂の確率
• “THE DOG RAN AWAY” の例– eq. 12.7 はかなり怪しい– 参照している Chen and Goodman, 1999 はたぶん
1998だと思われる.– BOS/EOSを⼊れて n-gram の計算ができるようパ
ディングする• 先頭になりやすい単語,⽂末になりやすい単語もわかる
p(JOHN READ A BOOK)
= p(JOHN | < BOS >)p(READ|JOHN)p(A|READ)p(BOOK|A)p(< EOS > |BOOK)

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 34
ゼロ頻度問題
• 最尤推定を⾏うと確率が0になる n-gram が出る• ⽂の確率を計算する際に,n-gram 確率が 0 にな
ると⽂の確率は 0 になってしまう
p(READ|CHER) =c(CHER READ)P
w c(CHER w)=
0
1
p(CHER READ A BOOK) = 0
p(A|READ)p(BOOK|A)p(EOS|BOOK)の値が⾼くても0

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 35
スムージング
• 訓練データで観測されない n-gram にも0でない確率を与える– n-gram 確率に事前分布を置く
• ⼀様分布やディリクレ分布など– ⾼次モデルと低次モデルを混合する
• ⾼次の n-gram の確率が 0 でも低次でバックオフして対処

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 36
次元の呪い
• 語彙のサイズ
• 可能な n-gram の数
• ⼤量の訓練事例が必要となる– 実際には⼗分な訓練データがある時に,さらに n を控
えめな値にしてもほとんどの n-gram は訓練データには現れない
⼤きくなる

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 37
n-gram の可視化
• nearest-neighbor lookup– k-nearest neighbor と類似した non-parametric
prediction としてみることができる– one-hot vector 空間だと任意の単語間の距離が同じ
• 意味のある情報にはならない
• 意味的に類似する単語間で知識を共有したい

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 38
class-based language model
• 単語カテゴリの概念を導⼊• 同じカテゴリの単語間で統計的強度を共有• 単語間の共起頻度に基づいて単語集合をクラスタ
リング or クラス分類• 単語の代わりにクラスIDを利⽤できる– P(X|Context) -> P(X|Class ID)
• ⽂の中にある幾つかの単語が同じクラスの別の単語に置き換わる場合については汎化と⾔っても良い– ⽂脈が消えているので細かい情報は劣化している

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 39
Composite model
• 単語ベースとクラスベースの混合 or バックオフ

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 40
Neural Language Models
• 単語の分散表現を⽤いたクラスベース⾔語モデルBengio et al., 2001– 2単語が互いに異なるという情報を失わずに単語間の類
似を認識できる– ある単語と類似する別の単語の間の統計的関連度を
シェアするモデル

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 41
分散表現
• 類似する単語は特徴を共有する– dog と cat の分散表現が多くの特徴を共有するならお
互いを含む⽂はもう⼀⽅の語も含みやすい• 次元の呪いをクリア– 各訓練事例が特徴を通じて類似⽂と関連する
• word embedding と呼ぶこともある– 単語を低次元の特徴空間に埋め込む– 元々の空間(語彙次元)では one-hot-vector
• すべての単語ペアのユークリッド距離は√2– 特徴空間では周辺⽂脈が類似する単語は近くに配置

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 42
• 国や数字などの類似する単語がまとまっている

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 43
High Dimensional Outputs
• 出⼒ラベル=単語としたい– 語彙サイズは数⼗万次元なので計算コストが⼤きい– 分散表現から出⼒空間へアフィン変換してからソフト
マックス関数を適⽤• アフィン変換の重み⾏列が⼤きくなってしまう• 語彙サイズが だと出⼒次元も
• 計算量もメモリ使⽤量も⼤きい– 学習時だけではなくテスト時も同様
• 最適化の⽬的関数– クロスエントロピーを使うと問題が出る– ソフトマックス関数の計算が⼊る

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 44
計算量
• 出⼒分布 の予測に使う最上位の階層を とする• affine-softmax 出⼒層の計算
• アフィン変換の重み⾏列• バイアス• 計算量は は通常数千

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 45
Use of short list
• 語彙のサイズを減らすことで計算コストを下げる– 語彙を10K or 20K に制限 (Bengio et al.,
2001,2003)– を少数の⾼頻度語 と残りの低頻度語
へ分割し,コンテキストCに続く単語がどちらに属するか予測
– 低頻度語の確率はn-gram ⾔語モデルを⽤いる• ショートリストの問題– NLMの汎化性能の利点が⾼頻度語だけに制限される

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 46
Hierarchical Softmax
• を階層的な確率に分解– 計算オーダーが線形から log オーダーになる
• 単語の階層的なカテゴリを構築している– 階層構造は単語をリーフとする⽊構造– 平衡⽊なら⽊の深さは

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 47
階層ソフトマックスの計算
• 根から葉まで⽊の各ノード毎に計算
• 単語確率はブランチの確率の積– 条件付き確率が欲しい場合
ロジスティック回帰で可能

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 48
階層ソフトマックスの利点
• 計算コストが• l 層の全結合層を考える– 隠れそうの計算量
– ユニットの幅• 出⼒層の計算量
– :単語を表すのに必要な平均ビット数

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 49
階層ソフトマックスの⽋点
• テストの結果がサンプリングベースの⼿法と⽐べると悪い
• だとn_bを⼩さくした⽅が効率的
• が10^3 以上のため,計算効率が上がらない
• 正確な対数尤度の最適化が難しい

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 50
ツリーはどうするのか
• 実在する階層を⽤いる(Morin and Bengio 2009)– NLMと同時に学習することもできる

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 51
Importance Sampling
• 勾配の計算で正解でない単語の確率計算をサボる
全部の単語を使わずにサンプルしたサブセットで近似

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 52
モンテカルロサンプリング
• モデルから単語をサンプルする場合,結局ソフトマックスの計算が必要になってしまう
• 別の提案分布 q からサンプルする– 別の分布を⽤いたことによるバイアスは後で補正する– 提案分布には n-gram ⾔語モデル(unigram, bigram)
を⽤いる

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 53
Importance sampling の適⽤先
• ⼤規模で疎な出⼒層を持つ⼿法• 出⼒が 1-of-n よりもむしろ疎なベクトルの場合– e.g. Bag of words
• 正解が疎でも学習中の勾配は密になる– 結局⾮ゼロの要素全てについて計算するため,出⼒次
元が⼤きい場合は importance sampling が有効Dauphin et al., 2011

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 54
Noise-Contrastive Estimation and Ranking Loss
• ランキング学習として捉える• 正解の単語 が他の単語 より上位になるよ
うスコアリング関数を作る• 損失関数
• 問題– 条件付き確率の推定はできない(回帰問題ではない)
マージン1で正解のa_yが他のa_iよりもスコアが⾼ければ勾配は0

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 55
Combining Neural Language Models with n-grams
• n-gram model の利点– ⾼いモデルのキャパシティ
• 計算コストを掛けずにたくさんの語彙の頻度を持てる• ルックアップはコンテキストにマッチする部分のみ
– ハッシュやツリー構造を使う場合• 計算量はほとんど語彙のサイズと独⽴になる
• NLM– パラメータを2倍にすると計算時間も2倍– Embedding layers は one-hot-vec を連続次元に射影するイン
デックスになっているので,語彙を増やしても計算量は変わらない
• NLMとn-gramでアンサンブル– (Bengio et al., 2001,2003)– Mikolov et al., 2011a
• NNとMEMMを組み合わせて同時に学習する• MEMMで,コンテキストに対する特定の n-gram に対応する• MEMMの出⼒が 1-of-n とスパースなので計算量の増加を押さえられる

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 56
Neural Machine Translation
• 読み込んだ⽂を同じ意味の別⾔語で出⼒する• 翻訳の候補を提⽰した後,⾔語モデルで評価• ⾔語モデルを n-gram から置き換える形でNNが
使われ始めた– Devlin et al., 2014– MLP で⽬的⾔語のフレーズの確率を計算– MLP だと前処理で⼊⼒系列を固定⻑にする必要がある
• ⼊⼒系列と出⼒系列を可変⻑にしたい– RNN の出番
16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 57
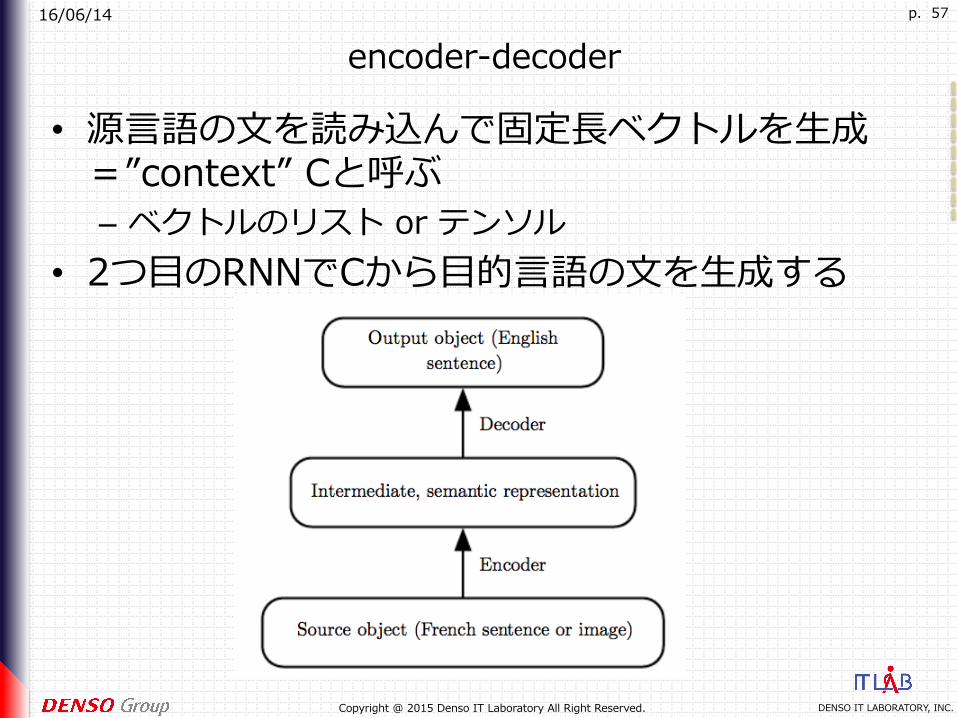
encoder-decoder
• 源⾔語の⽂を読み込んで固定⻑ベクトルを⽣成=”context” Cと呼ぶ– ベクトルのリスト or テンソル
• 2つ⽬のRNNでCから⽬的⾔語の⽂を⽣成する

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 58
Using an Attention Mechanism and Aligning Pieces of Data
• RNNのようにたたみ込むのではなく,各時刻の を で重み付けて加重平均を取ることで各時刻の C をつくっている

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 59
12.5 OTHER APPLICATIONSCHAPTER 12. APPLICATIONS

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 60
Recommender system
• ユーザにアイテムを推薦する• 2種類のアプリケーション– online advertising– item recommendations
• ユーザとアイテム間の関係を予測– 幾つかのアクションの確率を予測– 広告表⽰や推薦のゲインの期待値を予測
• 推薦アイテムは製品に限らない– SNSのニュースフィード,映画,ゲームの対戦相⼿,
出会い系のマッチング,etc.

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 61
教師あり学習として扱う
• ユーザとアイテムについての情報が与えられた時,interest の代わりになるものを予測– 回帰や確率的分類問題に帰着
• interest– 広告のユーザクリック– レーティング– ”like”ボタンのクリック– 製品の購⼊– 課⾦額– ページの滞在時間– etc.

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 62
協調フィルタリング(Collaborative Filtering)
• ユーザorアイテム間の類似度に基づく⼿法– 1さんと2さんが同じアイテムA,Bを好き
→ 好みが似ている– 1さんがアイテムDを好きなら2さんも好きだろう
• ノンパラメトリックなCF(⤴︎)– e.g. nearest-neighbor
• パラメトリックなCF– 分散表現の学習に基づく
• ユーザとアイテムを embedding vector にする• e.g. Matrix Factorization

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 63
パラメトリックCF
• ⽬的変数(e.g. レーティング)の Bilinear Prediction– user embedding と item embedding の内積で⽬的
変数を予測
:予測⾏列
:user embedding
:item embedding
:user bias
:item bias
ユーザによって評価の傾向が異なる (★1ばかり付けるとか★5ばかりとか)
アイテムの⼈気度

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 64
embedding vector
• 低次元に落とすことで可視化可能• ユーザ間,アイテム間の⽐較可能• SVDによる獲得
• SVDの問題– 値の無いエントリを値が0だったとして恣意的に扱う
• 値のないエントリの予測にかける計算コストをなくしたい

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 65
学習⽅法
• レーティングの⼆乗誤差を最⼩化する• 勾配法で簡単に最適化できる– u/i embedding について偏微分してそれぞれを更新

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 66
Netflix prize コンペ
• 匿名化されたユーザのレーティングデータを⽤いて映画のレーティングを予測する
• Bilinear Prediction も SVD も好成績– 優勝した ensemble models のコンポーネントとして
も使われている

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 67
RBMによるレコメンデーション
• 協調フィルタリングに最初にNNを利⽤(Salakhutdinov et al., 2007)
• Netflix コンペの優勝⼿法のコンポーネントの1つ• レーティング⾏列分解の様々な先進的⼿法– NNコミュニティで蓄積された
(Salakhutdinov and Mnih, 2008)

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 68
協調フィルタリングの基本的な制約
• コールドスタート問題– 新しいアイテムやユーザに対するデータが無い
• ⼀般的な対処⽅法– ユーザやアイテムについて独⾃の追加情報を⼊れる
• e.g. ユーザプロフィールやアイテムの特徴,etc. → content-based recommender systems

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 69
content-based recommender systems
• U/Iの特徴量を⽤いて embedding にマッピング– Deep Learning で学習する
(Huang et al., 2013; Elkahly et al., 2015)• 特徴量抽出– CNNのような特殊なアーキテクチャも利⽤される
(van den Oord et al., 2013)• ⼊⼒として⾳響特徴を受け取り,歌についての embedding
を計算• song embedding とユーザ embedding の内積でユーザへ推
薦する歌を予測

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 70
EXPLORATION V.S. EXPLOITATION
12.5.1.1

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 71
レコメンデーションの問題
• レコメンデーションは強化学習の領域である– contextual bandits として理論的に説明される
(Langford and Zhang, 2008; Lu et al., 2010)• レコメンデーションシステムを⽤いたデータ収集– 獲得されるユーザの好みがバイアスされる
• 全てのアイテムをレコメンドできないため,レコメンドしたものについてのみのユーザのレスポンスのみ⾒ることになる
• 他のアイテムをレコメンドした場合の結果から得られるはずの情報は⼊⼿できない
– 各訓練事例に対してクラスをサンプルして分類器を学習しているようなもの• クラスを選んでから,フィードバックとして合否が与えられる
– 教師あり学習と⽐較して少ない情報しか使えない• 教師あり学習の場合は正解クラスは最初から分かっている

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 72
ひどいケース
• システム運⽤開始時には,正しい decision が選ばれる確率は⾮常に低い
• システムが正しい decision を選ぶまで,正しい decision についての学習は⾏われない→ ⼤量にデータを集めても間違った decision を 選び続けるかもしれない
強化学習と似ている選んだアクションについての報酬だけが観測できる

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 73
バンディット問題
• 強化学習の特殊なケース– 1アクション1報酬を受け取る場合を想定(遅延なし)– 普通の強化学習ではアクション系列と報酬列を扱う
• どの報酬とアクションが対応しているかも不明
• contextual bandits– decision に影響を与える幾つかの⼊⼒変数
(context)が与えられている状況を扱う– policy: コンテキストをアクションにマッピングする– 学習器と(アクションに依存した)データ分布の間の
フィードバックループが研究課題

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 74
強化学習
• exploration と exploitation のトレードオフ• exploitation– 現在の学習済みポリシーから最適なアクションを選ぶ– ⾼い報酬が得られると知っているアクション
• exploration– 知識の無いアクション aʼ を⾏う探索– 既知のベストなアクションの報酬を超えて欲しいが,
報酬が0になる場合もある• どちらに転んでも何らかの知識は得られる

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 75
exploration の実装⽅法
• ランダムにアクションを選択– 可能な全てのアクション空間をカバーするように時々
ランダムでアクションを選択• モデルベース– 報酬の期待値と報酬についてのモデルの不確実性の度
合いに基づいてアクションを選択する

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 76
exploration or exploitation
• どちらをどの程度選ぶかは様々な要素から決まる• 重要な要素の1つはタイムスケール– 報酬を増やすのに短い時間しか使えない
• exploitation を選びやすい– 報酬を増やすのに多くの時間が使える
• 将来のアクションがより効率的かつ知識に基づくようにするために exploration から始めやすくなる
• 時間が進んでポリシーが改善されたら exploitation を増やす
• 教師あり学習だとこのトレードオフは存在しない

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 77
評価の難しさ
• ポリシー⾃⾝がどの⼊⼒を⾒るかを決める– 学習器と環境の間にインタラクションがある– ⼊⼒を固定したテストセットによる性能評価をするの
は簡単ではない• Contextual bandits の評価⼿法を提案
(Dudik et al., 2011)– 内容はこの本には書かれていないので聞かれると困
る…

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 78
KNOWLEDGE REPRESENTATIONREASONING AND QUESTION ANSWERING
12.5.2

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 79
Representations
• NLPでの成功は embedding を⽤いたこと• embeddings が表現するもの– 単語やコンセプトの意味的な知識
• embedding 研究の最前線– フレーズの embeddings– 単語とファクトの関係の embeddings– 課題はまだまだ多い
• 先進的な representation の改善のために⾏うべきことがまだそのままになっている

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 80
indexRelations
• 2つのエンティティの関係を獲得する分散表現の学習⽅法を⾒つけ出す– オブジェクトについてのファクトと,どのようにオブ
ジェクト間で相互作⽤が起こるかを形式化できる

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 81
2項関係(binary relation)
• 順序対の集合– 集合に含まれるペアは関係も持ち,含まれないペアは
関係を持たない– e.g. 集合{1,2,3}における “is less than” の関係
• 関係が定義できれば動詞のように使える
• 数字以外にも適⽤できる– e.g. is_a_type_of の関係を定義
→ 1 is less than 2
→ dog is a type of mammal

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 82
AIにおける relation
• relation:簡潔かつ⾼度に構造化された⾔語の⽂
– 3つ組の形式• 関係は動詞の役割をする• 2つの引数は主語と⽬的語の役割
• attribute:属性の定義– relationと似てるけど引数が1つ

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 83
正直納得のいかない例
• has_fur attribute
• has relation じゃない??

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 84
NNで relation representation を学習
• ⾃然⾔語の⾮構造データからエンティティ間の関係を推定する!
• 関係を同定する構造化データベースはある– ⼀般的な構造は関係データベース
• 同じ種類の情報を格納• 3つ組の⽂の形式にはなっていない
– 知識ベース:以下のような知識を伝えるのが⽬的• ⽣活に関する常識• ⼈⼯知能システムの応⽤領域に関する専⾨知識
と⾔ったが…

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 85
知識ベースの例
• ⼀般的な知識を扱う– e.g. Freebase, OpenCyc, WordNet, Wikibase, etc.
• 専⾨知識を扱う– e.g. GeneOntology

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 86
Representation の学習
• 知識ベースから学習– 三つ組データを訓練事例にして,各エンティティの同
時分布を獲得するよう⽬的関数を最⼤化(Bordes et al., 2013a)
• モデルの定義– Neural Language Models を拡張してエンティティや
関係をモデル化– NLM
• 各単語の分散表現のベクトルを学習• 単語間の相互作⽤も学習する
– e.g. 単語列が与えられた時にどの単語が次に来やすいのか
16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 87
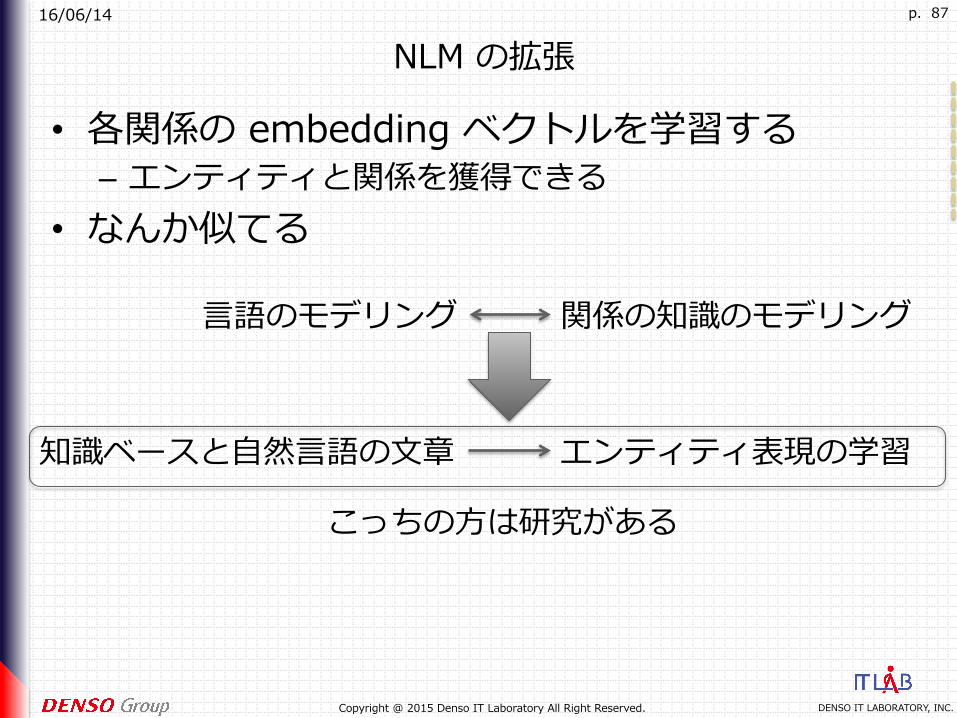
NLM の拡張
• 各関係の embedding ベクトルを学習する– エンティティと関係を獲得できる
• なんか似てる
⾔語のモデリング 関係の知識のモデリング
エンティティ表現の学習知識ベースと⾃然⾔語の⽂章
こっちの⽅は研究がある

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 88
先⾏研究
• 関係とエンティティで異なる表現形式(Paccanaro and Hinton, 2000; Bordes et al., 2011)– エンティティはベクトル– 関係は⾏列
• 関係はエンティティに対するオペレータのように振る舞うという考え⽅
• 関係も別のエンティティと⾒なす⼿法(Bordes et al., 2012)– 関係についてのステートメントを作れる– が,同時分布のモデルを⽴てるためにエンティティを
組み合わせる機構を置く⽅がより柔軟になる• Bengio 先⽣的にはこのやり⽅はお勧めではなさそう

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 89
link prediction
• 関係学習の短期的な適⽤先– ナレッジグラフの⽋損リンクを予測する
• 既存の知識ベース– ⼈⼿で作られるので⼀度作るとそのままになりやすい– 多数の関連リンクが⽋損している傾向がある
• 実際のアプリケーション– Wang et al. (2014)– Lin et al. (2015)– Garcia-Duran et al. (2015)
• 評価– 正例しか持っていないため難しい– ヘルドアウトデータを使って評価する– よくあるのは precision@10%
• モデルが出したランキングの上位10%以内に正解が含まれる回数で評価

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 90
その他の応⽤
• 語義曖昧性解消– ⽂脈に対する単語の適切な語義の意味を求めるタスク
(Navigli and Velardi, 2005; Bordes et al., 2012)• 質問応答– 関係の知識と⾔語理解,理由付けの処理を組み合わせ
る– ⼊⼒情報を処理して重要な事柄を記憶し,検索可能な
ように組織化する必要がある• 後でその理由付けを⾏う
限定された環境(“toy”環境)でのみ解ける 難しい未解決問題のまま

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 91
現状把握
• 特定の事柄の記憶/検索のベストアプローチ– 10.12で紹介した Memory Networks
• 明⽰的な記憶メカニズムを使⽤• toy question answering task を解くために提案
(Weston et al., 2014)– GRU recurrent nets を使った拡張
(Kuman et al., 2015)• メモリへの⼊⼒を読み込んでメモリの内容に対する応答を⽣成

16/06/14
DENSO IT LABORATORY, INC.Copyright @ 2015 Denso IT Laboratory All Right Reserved.
p. 92
おわり
• 深層学習の応⽤は紹介した以外にもたくさんある• 今後も確実に増え続けるから全部はとても説明で
きないぜ!– ここで紹介したことはあくまで執筆時に可能なことの
代表的な応⽤例だよ


















