
DATA SCIENCE USING SPARK: AN INTRODUCTION
44
DATA SCIENCE USING SPARK: AN INTRODUCTION
Transcript of DATA SCIENCE USING SPARK: AN INTRODUCTION

DATA SCIENCE USING SPARK:
AN INTRODUCTION

TOPICS COVERED
Introduction to Spark
Getting Started with Spark
Programming in Spark
Data Science with Spark
What next?
2

DATA SCIENCE PROCESS
3
Real World
Raw data is
collected
Raw data is
collectedData is
processed
Data is
processedClean
Data
Clean
Data
Exploratory
Data Analysis
Exploratory
Data Analysis
Machine
Learning
Algorithms
Statistical
Models
Machine
Learning
Algorithms
Statistical
Models
Build
Data Product
Build
Data Product
Communicate
----------------
visualizations
----------------Report
Findings
Communicate
----------------
visualizations
----------------Report
Findings
Make Decisions
Source: Doing Data Science by Rachel Schutt & Cathy O’Neil

DATA SCIENCE & DATA MINING
Distinctions are blurred
4
StatisticsMachine
Learning
Database
Management
Management
Science
Natural Language
ProcessingText Mining Web Mining
(Structured)
Data Mining
(Unstructured)
Data Mining
Data MiningVisual Data
Mining
Big Data
Engineering
Business
AnalyticsData Science
Domain
Knowledge
Knowledge Discovery

WHAT DO WE NEED TO SUPPORT DATA SCIENCE WORK?
Data Input /Output
Ability to read data in multiple formats
Ability to read data from multiple sources
Ability to deal with Big Data (Volume, Velocity, Veracity and Variety)
Data Transformations
Easy to describe and perform transformations on rows and columns of data
Requires abstraction of data and a dataflow paradigm
Model Development
Library of Data Science Algorithms
Ability to import / export models from other sources
Data Science pipelines / workflow Development
Analytics Applications Development
Seamless integration with programming languages / IDEs
5

INTRODUCTION TO SPARK
S H A R A N K A L W A N I
6

WHAT IS SPARK?
7
▪ A distributed computing platform designed to be
▪ Fast
▪ General Purpose
▪ A general engine that allows combination of multiple types of computations
▪ Batch
▪ Interactive
▪ Iterative
▪ SQL Queries
▪ Text Processing
▪ Machine learning

8
Fast/Speed
Computations in memory
Faster than MR even for disk computations
Generality
Designed for a wide range of workloads
Single Engine to combine batch, interactive,
iterative, streaming algorithms.
Has rich high-level libraries and simple native
APIs in Java, Scala and Python.
Reduces the management burden of
maintaining separate tools.

9
SPARK UNIFIED STACK

10
CLUSTER MANAGERS
▪ Can run on a variety of cluster managers
▪ Hadoop YARN - Yet Another Resource Negotiator is a cluster management technology and one of the key features in Hadoop 2.
▪ Apache Mesos - abstracts CPU, memory, storage, and other compute resources away from machines, enabling fault-tolerant and elastic distributed systems.
▪ Spark Standalone Scheduler – provides an easy way to get started on an empty set of machines.
▪ Spark can leverage existing Hadoop infrastructure

11
SPARK HISTORY
▪ Started in 2009 as a research project in UC Berkeley RAD lab which became AMP Lab.
▪ Spark researchers found that Hadoop MapReduce was inefficient for iterative and interactive computing.
▪ Spark was designed from the beginning to be fast for interactive, iterative with support for in-memory storage and fault-tolerance.
▪ Apart from UC Berkeley, Databricks, Yahoo! and Intel are major contributors.
▪ Spark was open sourced in March 2010 and transformed into Apache Foundation project in June 2013.

C O N F I D E N T I A L A N D P R O P R I E T A R Y 12
SPARK VS HADOOP
Hadoop MapReduce
Mostly suited for batch jobs
Difficulty to program directly in MR
Batch doesn’t compose well for large apps
Specialized systems needed as a workaround
Spark
Handles batch, interactive, and real-time
within a single framework
Native integration with Java, Python, Scala
Programming at a higher level of abstraction
More general than MapReduce

GETTING STARTED WITH SPARK
13

14
GETTING STARTED WITH SPARK …..NOT COVERED TODAY!
There are multiple ways of using Spark
▪ Certified Spark Distributions
▪ Datastax Enterprise (Cassandra + Spark)
▪ HortonWorks HDP
▪ MAPR
▪ Local/Standalone
▪ Databricks cloud
▪ Amazon AWS EC2

15
LOCAL MODE▪ Install Java JDK 6/7 on MacOSX or Windows
http://www.oracle.com/technetwork/java/javase/downloads/jdk7-downloads-1880260.html
▪ Install Python 2.7 using Anaconda (only on Windows)
https://store.continuum.io/cshop/anaconda/
▪ Download Apache Spark from Databricks, unzip the downloaded file to a convenient location
http://training.databricks.com/workshop/usb.zip
▪ Connect to the newly created spark-training directory
▪ Run the interactive Scala shell (REPL)
./spark/bin/spark-shell
val data = 1 to 1000
val distData = sc.parallelize(data)
val filteredData = distData.filter(s => s<25)
filteredData.collect()

16
DATABRICKS CLOUD
▪ A hosted data platform powered by Apache Spark
▪ Features
▪ Exploration and Visualization
▪ Managed Spark Clusters
▪ Production Pipelines
▪ Support for 3rd party apps (Tableau, Pentaho, Qlik View)
▪ Databricks Cloud Trail
http://databricks.com/registration
▪ Demo

17
DATABRICKS CLOUD
▪ Workspace
▪ Tables
▪ Clusters

18
DATABRICKS CLOUD
▪ Notebooks
▪ Python
▪ Scala
▪ SQL
▪ Visualizations
▪ Markup
▪ Comments
▪ Collaboration

19
DATABRICKS CLOUD
▪ Tables
▪ Hive tables
▪ SQL
▪ Dbfs
▪ S3
▪ CSV
▪ Databases
20
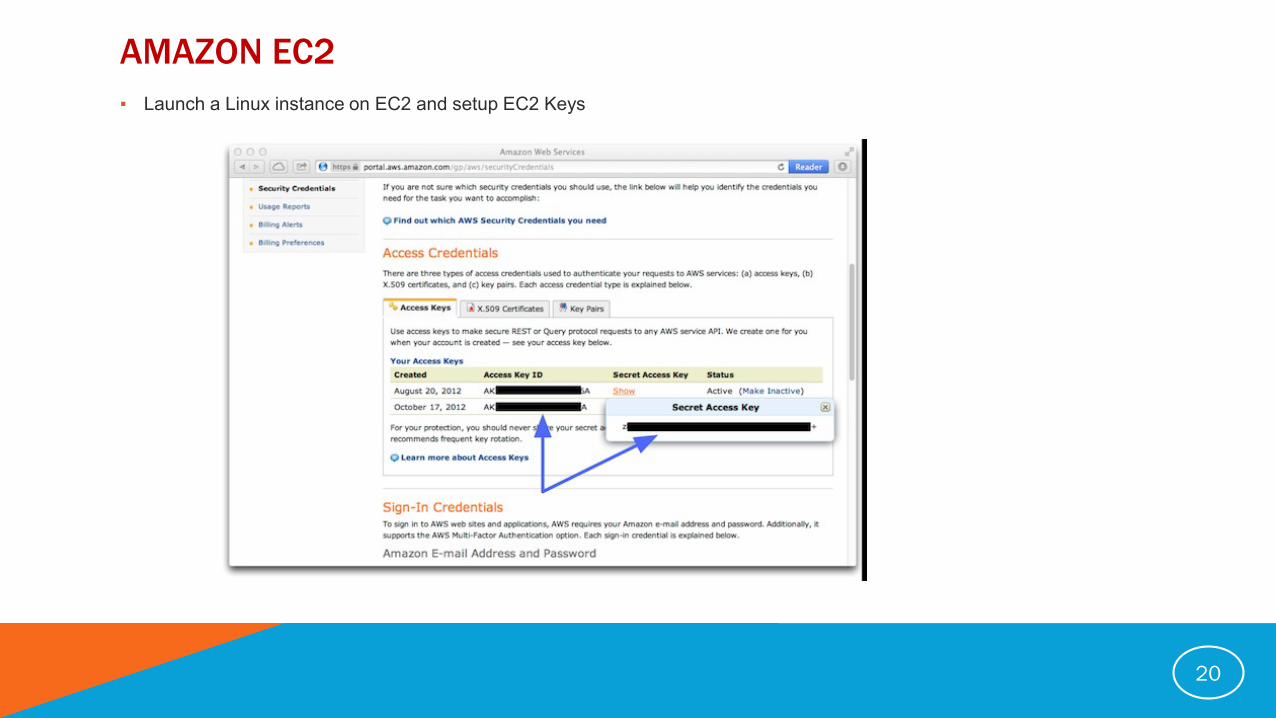
AMAZON EC2
▪ Launch a Linux instance on EC2 and setup EC2 Keys

21
AMAZON EC2
▪ Setup an EC2 pair from the AWS console

22
AMAZON EC2
▪ Spark binary ships with a spark-ec2 script to manage clusters on EC2
▪ Launching Spark cluster on EC2
./spark-ec2 -k <keypair> -i <key-file> -s <num-slaves> launch <cluster-name>
▪ Running Applications
./spark-ec2 -k <keypair> -i <key-file> login <cluster-name>
▪ Terminating a cluster
./spark-ec2 destroy <cluster-name>
▪ Accessing data in S3
s3n://<bucket>/path

PROGRAMMING IN SPARK
S H A R A N K A L W A N I
23

24
Spark Cluster
• Mesos• YARN• Standalone

25
Scala – Scalable Language
▪ Scala is a multi-paradigm programming language with focus on the functional programming paradigm.
▪ In functional programming functions are used and they use variables that are immutable.
▪ Every operator, variable and function is an object.
▪ Scala generates bytecode that runs on the top of any JVM and can also use any of the java libraries.
▪ Spark is completely written in Scala.
▪ Spark SQL, GraphX, Spark Streaming etc. are libraries written in Scala.
▪ Scala Crash Course by Holden Karau @databricks
lintool.github.io/SparkTutorial/slides/day1_Scala_crash_course.pdf

Write programs in terms of transformations on distributed datasets
Resilient Distributed Datasets (RDDs)
Read-only collections of objects that can be stored in memory or disk across a cluster
Partitions are automatically rebuilt on failure
Parallel functional transformations ( map, filter, ..)
Familiar Scala collections API for distributed data and computation
Lazy transformations
26
Spark Model
27
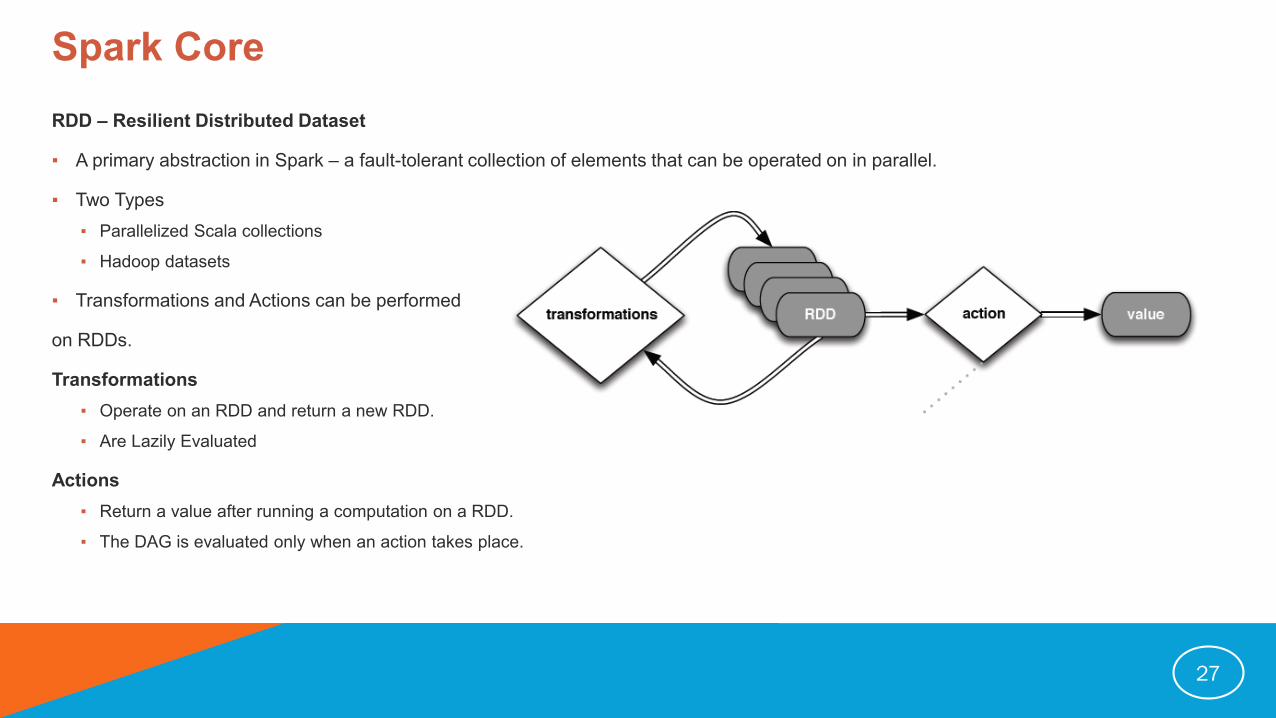
Spark Core
RDD – Resilient Distributed Dataset
▪ A primary abstraction in Spark – a fault-tolerant collection of elements that can be operated on in parallel.
▪ Two Types
▪ Parallelized Scala collections
▪ Hadoop datasets
▪ Transformations and Actions can be performed
on RDDs.
Transformations
▪ Operate on an RDD and return a new RDD.
▪ Are Lazily Evaluated
Actions
▪ Return a value after running a computation on a RDD.
▪ The DAG is evaluated only when an action takes place.

Interactive Queries and prototyping
Local, YARN, Mesos
Static type checking and auto complete
28
Spark Shell

29
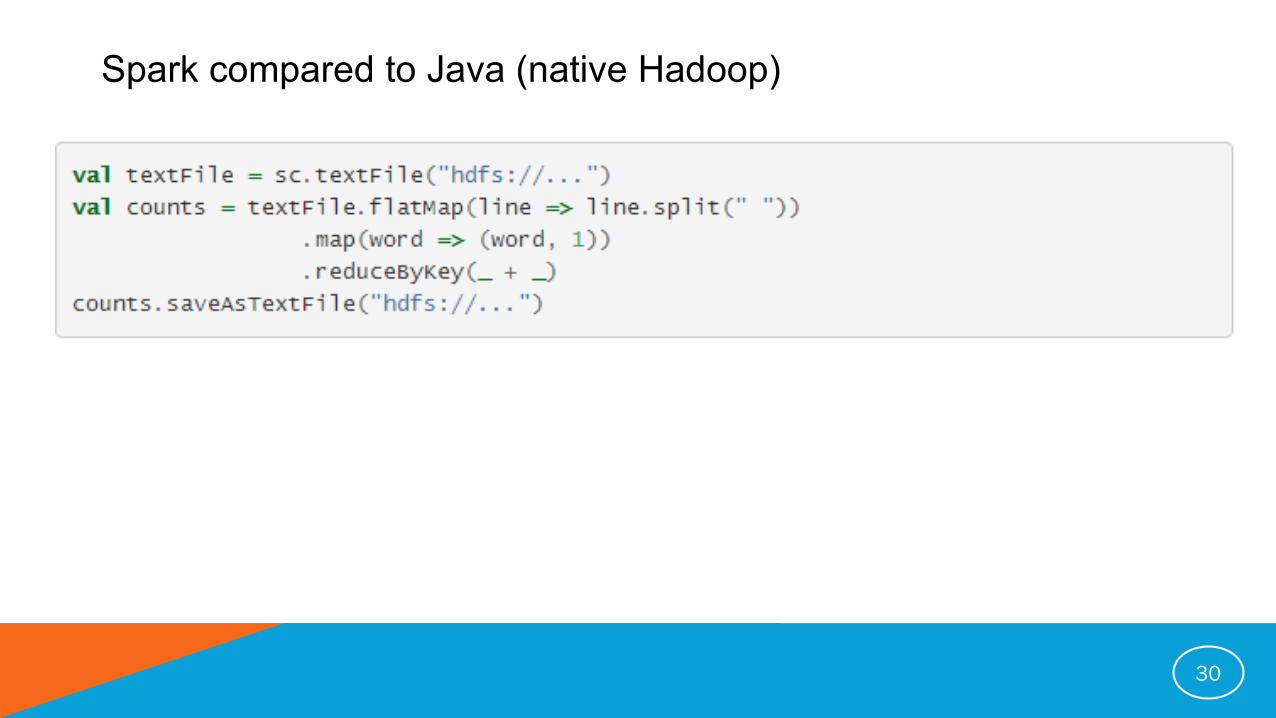
Spark compared to Java (native Hadoop)
30
Spark compared to Java (native Hadoop)

• Real time computation similar to Storm
• Input distributed to memory for fault tolerance
• Streaming input in to sliding windows of RDDs
• Kafka, Flume, Kinesis, HDFS
31
Spark Streaming

32

33
Spark Streaming

DATA SCIENCE USING SPARK
34

WHAT DO WE NEED TO SUPPORT DATA SCIENCE WORK?
Data Input /Output
Ability to read data in multiple formats
Ability to read data from multiple sources
Ability to deal with Big Data (Volume, Velocity, and Variety)
Data Transformations
Easy to describe and perform transformations on rows and columns of data
Requires abstraction of data and a dataflow paradigm
Model Development
Library of Data Science Algorithms
Ability to import / export models from other sources
Data Science pipelines / workflow Development
Analytics Applications Development
Seamless integration with programming languages / IDEs
35

WHY SPARK FOR DATA SCIENCE?
C O N F I D E N T I A L A N D P R O P R I E T A R Y 36
SPARK is HOTSPARK is HOT
FASTDistributed In-memory Platform
Scalable Small to Big Data; Well integrated into the Big Data Ecosystem
Expressive Simple, higher level abstractions for describing computations
Flexible Extendible, Multiple language bindings (Scala, Java, Python, R)

37
Traditional Data Science Tools
Matlab
R
SAS
SPSS
RapidMiner
And many others….
Designed to work on single machines
Proprietary & Expensive

38
What is available in Spark?
Basic RDD (Transformations & Actions) Basic RDD (Transformations & Actions)
Extensions to RDD (SchemaRDD, RRDD, RDPG, DStreams)Extensions to RDD (SchemaRDD, RRDD, RDPG, DStreams)
Library of Algorithms(MLlib, R packages, Mahout?, Graph Algorithms)Library of Algorithms(MLlib, R packages, Mahout?, Graph Algorithms)
Analytics Workflows (ML Pipeline)Analytics Workflows (ML Pipeline)

DATA TYPES FOR DATA SCIENCE (MLLIB)
Single Machine Data Types Distributed Data Types
(supported by RDDs)
Local Vector
Labeled Point
Local Matrix
39
Distributed Matrix
RowMatrix
IndexedRowMatrix
CoordinateMatrix

40
Schema RDDs

41

42
R
Spark
Context
(ref. in R)
Java
Spark
Context
Local
R to Spark Dataflow
Spark
Executor
Spark
Executor
R
R
Worker
Worker
tasks
tasks
broadcast vars
R pacakges
broadcast vars
R pacakges

43
44
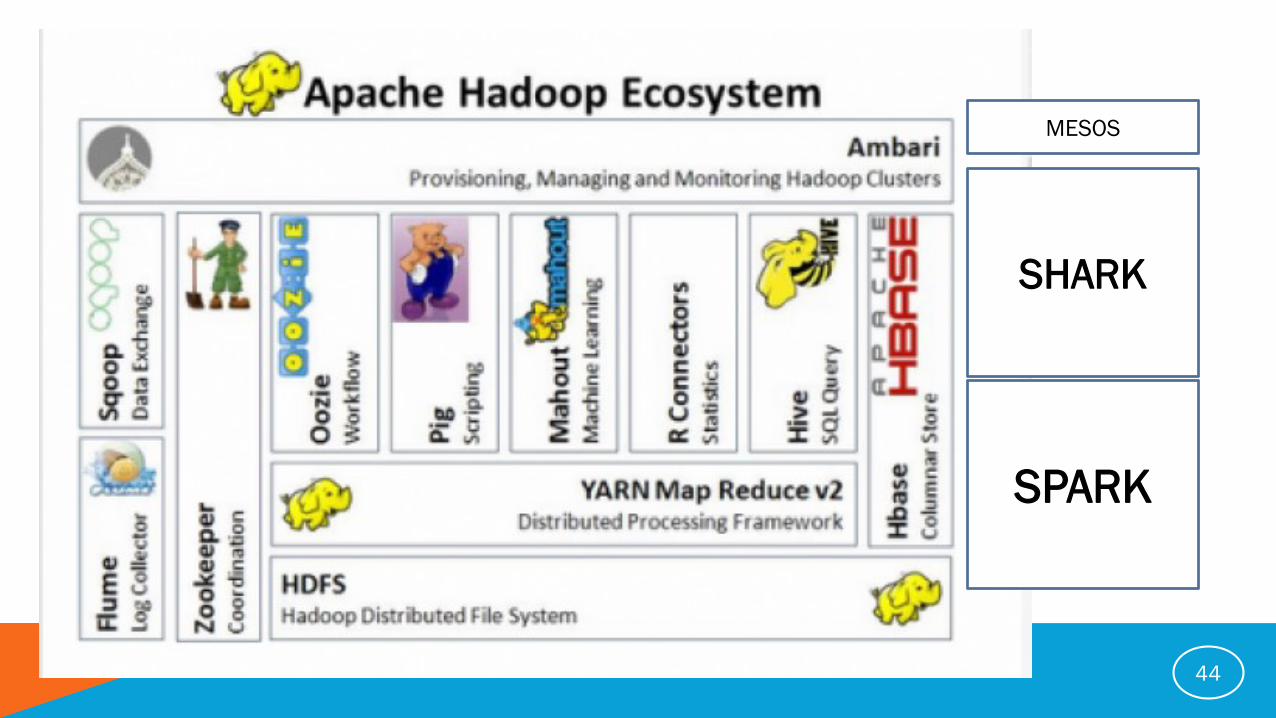
SHARK
SPARK
MESOS


















