
![[Spark meetup] Spark Streaming Overview](https://static.fdocuments.us/doc/165x107/55a457161a28ab057e8b45fd/spark-meetup-spark-streaming-overview.jpg)
Using apache spark to fight world hunger - Israel spark meetup at taboola
24
-
Upload
tsliwowicz -
Category
Software
-
view
193 -
download
1
Transcript of Using apache spark to fight world hunger - Israel spark meetup at taboola

Spark Meetup, December 2015Noam [email protected]

Overview
● Food shortage: new problems, new solutions
● Intermezzo: how DNA works
● Tach’les: what we do with Apache Spark

The planet has gotten very populous
And it’s the only one we got

World Population
Annual Growth Rate:Peak - 2.1% (1962)Current - 1.1% (2009)
https://en.wikipedia.org/wiki/World_population#/media/File:World-Population-1800-2100.svg
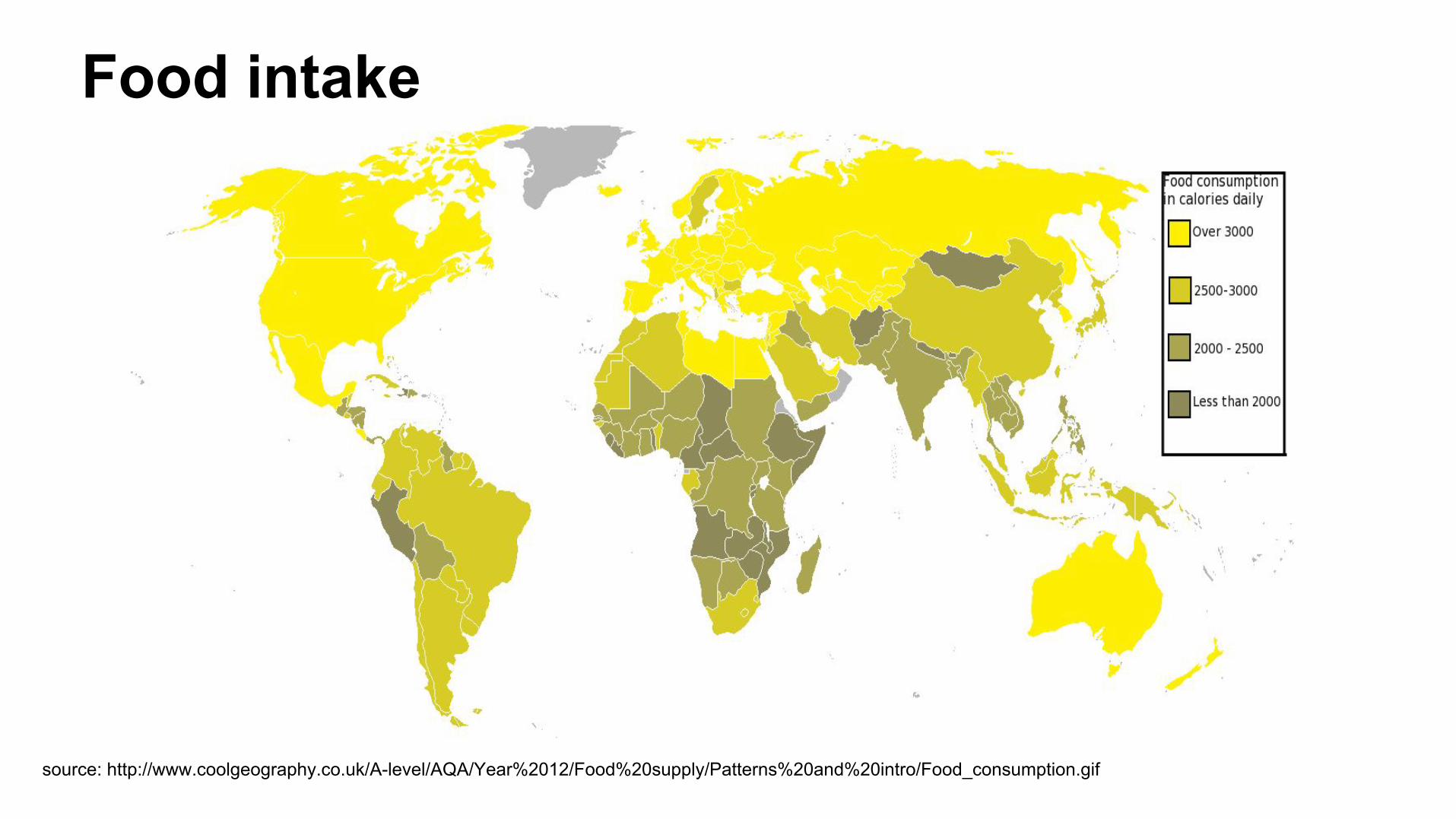
Food intake
source: http://www.coolgeography.co.uk/A-level/AQA/Year%2012/Food%20supply/Patterns%20and%20intro/Food_consumption.gif

Upscale: Same area, more crops

Plant breeding
● An ancient art
● Incremental changes
● Slow but considerable
source: https://en.wikipedia.org/wiki/Zea_%28genus%29#/media/File:Maize-teosinte.jpg
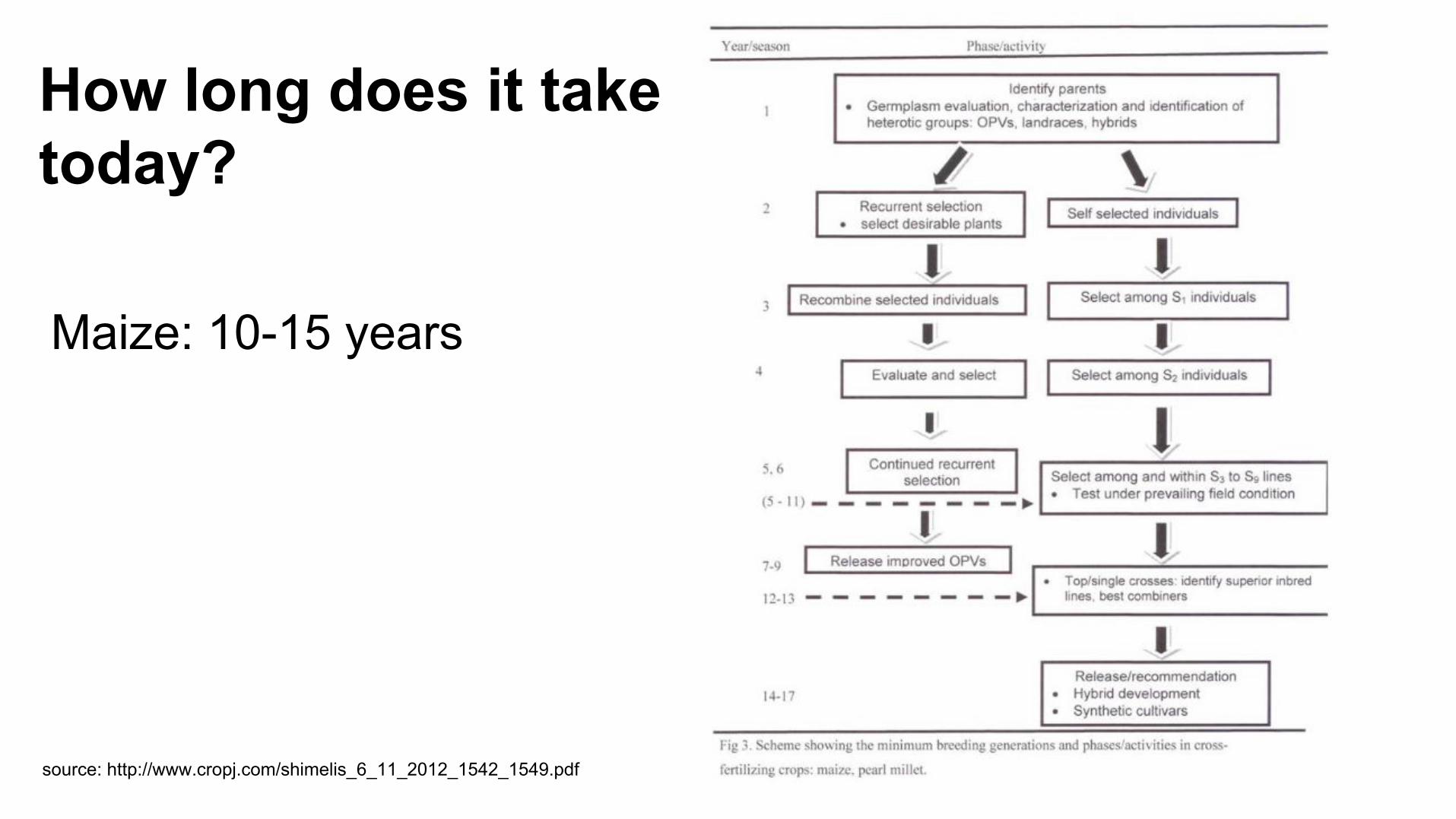
How long does it take today?
Maize: 10-15 years
source: http://www.cropj.com/shimelis_6_11_2012_1542_1549.pdf

How breeding works12345
12345
12345
12345
12345
12345
12345
12345
12345

Computational genomics
⬇ Prices of DNA sequencing⬆ Number of samples per crop sequenced and analyzed⬆ Amount and quality of genomic data⬇ Prices of computation⬇ Prices of storageWe’re entering a new era
BIG DATA Genomics

Food security - a computational problem?
● The plant’s potential lies in its DNA.
● We analyze and compare sequences from many plants.
● Resulting in better predictions for breeding.
● Faster rate of crop improvement.

Intermezzo: DNA - how does it work?
● Four “letters”:
cytosine(C), guanine(G),
adenine(A), thymine(T)
● Encode 20 amino acids
● Combine to make:
+100K proteins

Conceptually we can think of this as a “pipeline”:“The Central Dogma”

DNA as storage● Durable
● Supports random access
● Efficient sequential reads
● Easily replicated
● Contains error correction mechanisms
● Maximally “data local”

Part 2: What we do with
● Analyze lots of genome sequences.
● Apply similarity algorithms, find where they match.
● Finally, assist the breeding program.

Input data is “noisy”
● Contains errors and gaps.
● Is fragmented.
● All due to sequencing technology.

Our setup● Hadoop clusters on both private cloud and AWS
● Textual files, using Parquet.
● MapR 5 Hadoop distro
● Spark 1.4.1
● SparkSQL and Hive (JDBC)
● Instances: ~150GB RAM, 40 cores.
● Provisioning: Ansible

Our data● A dozen or so different crops, going for hundreds.
● Each crop: potentially ~1K fully sequenced samples
● ~100K “markers”.
● Each sequence: 1Gbp - 10Gbp (giga base-pairs =
characters) long
● Current: several terabytes, aiming at petabytes

Working with Spark and Scala
● Scala’s type system is your friend
● Thinking functional takes time - and can be “overdone”
● Remember to add @tailrec when needed
● Scala case classes - great
● Nested structure: keeps you DRY, but sluggish.
● Scala has its pitfalls - profile.
● Spark as the “ultimate scala collection” - Martin Odersky.

● Complex unmanaged framework - the usual 20/80 rule:
20% fun algorithmic stuff,
80% integration/devops/tuning/black-voodoo
● Integration with Hive - doable but cumbersome
● DataFrames API - very clean
● Parquet in Spark 1.4 - seamless, Parquet with SparkSQL
< 1.3 - rather sucks.
Integrations with Spark

● If RDD objects need high RAM → memory gets tricky.
● Spark UI in 1.4.1 - very nice
● PairRDD - need to be your own “query optimizer”
● repartition / coalesce - very useful, but gets tricky if data
variability is high (a dynamic real-time optimizer would be
great).
Performance tuning with Spark

● Testing: “local” is great, but means no unit-test :-(
● sbt-pack - good alternative to sbt-assembly.
● Spark packages: spark-csv, spark-notebook and more.
● Speaking of open-source packages...
Testing, packaging and extending Spark

ADAM Project - Genomics using Spark
● Fully open sourced from
● Similarity algorithms
● Population clustering
● Predictive analysis using Deep Learning
● And more


















