cvpr2017 tutorial kaiminghe - CVPR'17 Tutorial on...
45
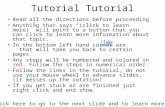
Learning Deep Features for Visual Recognition CVPR 2017 Tutorial Kaiming He Facebook AI Research (FAIR) covering joint work with: Xiangyu Zhang, Shaoqing Ren, Jian Sun, Saining Xie, Zhuowen Tu, Ross Girshick, Piotr Dollar 1x1 conv, 64 3x3 conv, 64 1x1 conv, 256 1x1 conv, 64 3x3 conv, 64 1x1 conv, 256 1x1 conv, 64 3x3 conv, 64 1x1 conv, 256 1x1 conv, 128, /2 3x3 conv, 128 1x1 conv, 512 1x1 conv, 128 3x3 conv, 128 1x1 conv, 512 1x1 conv, 128 3x3 conv, 128 1x1 conv, 512 1x1 conv, 128 3x3 conv, 128 1x1 conv, 512 1x1 conv, 128 3x3 conv, 128 1x1 conv, 512 1x1 conv, 128 3x3 conv, 128 1x1 conv, 512 1x1 conv, 128 3x3 conv, 128 1x1 conv, 512 1x1 conv, 128 3x3 conv, 128 1x1 conv, 512 1x1 conv, 256, /2 3x3 conv, 256 1x1 conv, 1024 1x1 conv, 256 3x3 conv, 256 1x1 conv, 1024 1x1 conv, 256 3x3 conv, 256 1x1 conv, 1024 1x1 conv, 256 3x3 conv, 256 1x1 conv, 1024 1x1 conv, 256 3x3 conv, 256 1x1 conv, 1024 1x1 conv, 256 3x3 conv, 256 1x1 conv, 1024 1x1 conv, 256 3x3 conv, 256 1x1 conv, 1024 1x1 conv, 256 3x3 conv, 256 1x1 conv, 1024 1x1 conv, 256 3x3 conv, 256 1x1 conv, 1024 1x1 conv, 256 3x3 conv, 256 1x1 conv, 1024 1x1 conv, 256 3x3 conv, 256 1x1 conv, 1024 1x1 conv, 256 3x3 conv, 256 1x1 conv, 1024 1x1 conv, 256 3x3 conv, 256 1x1 conv, 1024 1x1 conv, 256 3x3 conv, 256 1x1 conv, 1024 1x1 conv, 256 3x3 conv, 256 1x1 conv, 1024 1x1 conv, 256 3x3 conv, 256 1x1 conv, 1024 1x1 conv, 256 3x3 conv, 256 1x1 conv, 1024 1x1 conv, 256 3x3 conv, 256 1x1 conv, 1024 1x1 conv, 256 3x3 conv, 256 1x1 conv, 1024 1x1 conv, 256 3x3 conv, 256 1x1 conv, 1024 1x1 conv, 256 3x3 conv, 256 1x1 conv, 1024 1x1 conv, 256 3x3 conv, 256 1x1 conv, 1024 1x1 conv, 256 3x3 conv, 256 1x1 conv, 1024 1x1 conv, 256 3x3 conv, 256 1x1 conv, 1024 1x1 conv, 256 3x3 conv, 256 1x1 conv, 1024 1x1 conv, 256 3x3 conv, 256 1x1 conv, 1024 1x1 conv, 256 3x3 conv, 256 1x1 conv, 1024 1x1 conv, 256 3x3 conv, 256 1x1 conv, 1024 1x1 conv, 256 3x3 conv, 256 1x1 conv, 1024 1x1 conv, 256 3x3 conv, 256 1x1 conv, 1024 1x1 conv, 256 3x3 conv, 256 1x1 conv, 1024 1x1 conv, 256 3x3 conv, 256 1x1 conv, 1024 1x1 conv, 256 3x3 conv, 256 1x1 conv, 1024 1x1 conv, 256 3x3 conv, 256 1x1 conv, 1024 1x1 conv, 256 3x3 conv, 256 1x1 conv, 1024 1x1 conv, 256 3x3 conv, 256 1x1 conv, 1024 1x1 conv, 512, /2 3x3 conv, 512 1x1 conv, 2048 1x1 conv, 512 3x3 conv, 512 1x1 conv, 2048 1x1 conv, 512 3x3 conv, 512 1x1 conv, 2048 ave pool, fc 1000 7x7 conv, 64, /2, pool/2
Transcript of cvpr2017 tutorial kaiminghe - CVPR'17 Tutorial on...

LearningDeepFeaturesforVisualRecognition
CVPR2017Tutorial
KaimingHeFacebookAIResearch(FAIR)
coveringjointworkwith:
Xiangyu Zhang,Shaoqing Ren,JianSun,Saining Xie,Zhuowen Tu, RossGirshick,PiotrDollar
1x1conv,64
3x3conv,64
1x1conv,256
1x1conv,64
3x3conv,64
1x1conv,256
1x1conv,64
3x3conv,64
1x1conv,256
1x1conv,128
,/2
3x3conv,128
1x1conv,512
1x1conv,128
3x3conv,128
1x1conv,512
1x1conv,128
3x3conv,128
1x1conv,512
1x1conv,128
3x3conv,128
1x1conv,512
1x1conv,128
3x3conv,128
1x1conv,512
1x1conv,128
3x3conv,128
1x1conv,512
1x1conv,128
3x3conv,128
1x1conv,512
1x1conv,128
3x3conv,128
1x1conv,512
1x1conv,256
,/2
3x3conv,256
1x1conv,1024
1x1conv,256
3x3conv,256
1x1conv,1024
1x1conv,256
3x3conv,256
1x1conv,1024
1x1conv,256
3x3conv,256
1x1conv,1024
1x1conv,256
3x3conv,256
1x1conv,1024
1x1conv,256
3x3conv,256
1x1conv,1024
1x1conv,256
3x3conv,256
1x1conv,1024
1x1conv,256
3x3conv,256
1x1conv,1024
1x1conv,256
3x3conv,256
1x1conv,1024
1x1conv,256
3x3conv,256
1x1conv,1024
1x1conv,256
3x3conv,256
1x1conv,1024
1x1conv,256
3x3conv,256
1x1conv,1024
1x1conv,256
3x3conv,256
1x1conv,1024
1x1conv,256
3x3conv,256
1x1conv,1024
1x1conv,256
3x3conv,256
1x1conv,1024
1x1conv,256
3x3conv,256
1x1conv,1024
1x1conv,256
3x3conv,256
1x1conv,1024
1x1conv,256
3x3conv,256
1x1conv,1024
1x1conv,256
3x3conv,256
1x1conv,1024
1x1conv,256
3x3conv,256
1x1conv,1024
1x1conv,256
3x3conv,256
1x1conv,1024
1x1conv,256
3x3conv,256
1x1conv,1024
1x1conv,256
3x3conv,256
1x1conv,1024
1x1conv,256
3x3conv,256
1x1conv,1024
1x1conv,256
3x3conv,256
1x1conv,1024
1x1conv,256
3x3conv,256
1x1conv,1024
1x1conv,256
3x3conv,256
1x1conv,1024
1x1conv,256
3x3conv,256
1x1conv,1024
1x1conv,256
3x3conv,256
1x1conv,1024
1x1conv,256
3x3conv,256
1x1conv,1024
1x1conv,256
3x3conv,256
1x1conv,1024
1x1conv,256
3x3conv,256
1x1conv,1024
1x1conv,256
3x3conv,256
1x1conv,1024
1x1conv,256
3x3conv,256
1x1conv,1024
1x1conv,256
3x3conv,256
1x1conv,1024
1x1conv,256
3x3conv,256
1x1conv,1024
1x1conv,512
,/2
3x3conv,512
1x1conv,2048
1x1conv,512
3x3conv,512
1x1conv,2048
1x1conv,512
3x3conv,512
1x1conv,2048
avepool,fc1
000
7x7conv
,64,/2,pool/2

Outline
• Introduction• ConvolutionalNeuralNetworks:Recap• LeNet,AlexNet,VGG,GoogleNet;BatchNorm
• ResNet• ResNeXt
slideswillbeavailableonline

RevolutionofDepth
3.57
6.7 7.3
11.7
16.4
25.828.2
ILSVRC'15ResNet
ILSVRC'14GoogleNet
ILSVRC'14VGG
ILSVRC'13 ILSVRC'12AlexNet
ILSVRC'11 ILSVRC'10
ImageNetClassificationtop-5error(%)
shallow8layers
19layers22layers
152layers
8layers
KaimingHe,Xiangyu Zhang,Shaoqing Ren,&JianSun.“DeepResidualLearningforImageRecognition”.CVPR2016.

EngineofVisualRecognition
34
5866
86
HOG,DPM AlexNet(RCNN)
VGG(RCNN)
ResNet(FasterRCNN)*
PASCALVOC2007ObjectDetectionmAP (%)
shallow8layers
16layers
101layers
*w/otherimprovements&moredata
KaimingHe,XiangyuZhang,ShaoqingRen,&JianSun.“DeepResidualLearningforImageRecognition”.CVPR2016.

EngineofVisualRecognition
ResNets/extensionsareleadingmodelsonpopularbenchmarks• Detection:COCO/VOC• Segmentation:COCO/VOC/ADE/Cityscape• VisualReasoning:VQA/CLEVR• Video:UCF101/HMDB• …
Search“ResNet”onILSVRC2016resultpagereturns226entries
Source:RossGirshick

Howdidcomputerrecognizeanimage?
edges classifier “bus”?
pixelsclassifier “bus”?
histogram classifier “bus”?edges
SIFT/HOG
histogram classifier “bus”?edgesK-means
sparsecodeFV/VLAD
shallower
deeper
Butwhat’snext?
[Lowe1999,2004],[Sivic &Zisserman2003],[Dalal &Triggs 2005],[Grauman &Darrell2005][Lazebnik etal2006],[Perronnin &Dance2007],[Yangetal2009],[Jégou etal2010],……

LearningDeepFeatures
histogram classifier “bus”?edgesK-means
sparsecodeFV/VLAD
Specializedcomponents,domainknowledgerequired
“bus”?
Genericcomponents/“layers”,lessdomainknowledge
“bus”?
Repeatelementary layers:goingdeeper
• Richersolutionspace• End-to-endlearning byBackProp

ConvolutionalNeuralNetworks:Recap
LeNet,AlexNet,VGG,GoogleNet;BatchNorm,…

LeNet
• Convolution:• locally-connected• spatiallyweight-sharing
• weight-sharingisakeyinDL(e.g.,RNNsharesweightstemporally)
• Subsampling• Fully-connectedoutputs• TrainbyBackProp
• AllarestillthebasiccomponentsofmodernConvNets!
“Gradient-basedlearningappliedtodocumentrecognition”,LeCun etal.1998“Backpropagationappliedtohandwrittenzipcoderecognition”, LeCun etal.1989

AlexNet
LeNet-stylebackbone,plus:• ReLU [Nair&Hinton2010]
• “RevoLUtion ofdeeplearning”*• Acceleratetraining;bettergradprop(vs.tanh)
• Dropout[Hinton etal2012]• In-networkensembling• Reduceoverfitting (mightbeinsteaddonebyBN)
• Dataaugmentation• Label-preservingtransformation• Reduceoverfitting
11x11conv,96,/4,pool/2
5x5conv,256,pool/2
3x3conv,384
3x3conv,384
3x3conv,256,pool/2
fc,4096
fc,4096
fc,1000
“ImageNetClassificationwithDeepConvolutionalNeuralNetworks”, Krizhevsky,Sutskever,Hinton.NIPS2012
*QuoteChristianSzegedy

VGG-16/19
Simply“VeryDeep”!• Modularizeddesign• 3x3Convasthemodule• Stackthesamemodule• Samecomputationforeachmodule(1/2spatialsize=>2xfilters)
• Stage-wisetraining• VGG-11=>VGG-13=>VGG-16• Weneedabetterinitialization…
“16layersarebeyondmyimagination!”-- afterILSVRC2014resultwasannounced.
“VeryDeepConvolutionalNetworksforLarge-ScaleImageRecognition”,Simonyan & Zisserman.arXiv 2014(ICLR2015)
3x3conv,64
3x3conv,64,pool/2
3x3conv,128
3x3conv,128,pool/2
3x3conv,256
3x3conv,256
3x3conv,256
3x3conv,256,pool/2
3x3conv,512
3x3conv,512
3x3conv,512
3x3conv,512,pool/2
3x3conv,512
3x3conv,512
3x3conv,512
3x3conv,512,pool/2
fc,4096
fc,4096
fc,1000

Initialization
input𝑋
output𝑌 = 𝑊𝑋
weight𝑊
1-layer:𝑉𝑎𝑟 𝑦 = (𝑛+,𝑉𝑎𝑟 𝑤 )𝑉𝑎𝑟[𝑥]
Multi-layer:
𝑉𝑎𝑟 𝑦 = (2𝑛3+,𝑉𝑎𝑟 𝑤3
�
3
)𝑉𝑎𝑟[𝑥]
If:• Linearactivation• 𝑥, 𝑦, 𝑤:independentThen:
𝑛+, 𝑛678
LeCun etal1998“EfficientBackprop”Glorot &Bengio 2010“Understandingthedifficultyoftrainingdeepfeedforwardneuralnetworks”

Initialization
1 3 5 7 9 11 13 15depth
exploding
vanishing
ideal
Forward:
𝑉𝑎𝑟 𝑦 = (2𝑛3+,𝑉𝑎𝑟 𝑤3
�
3
)𝑉𝑎𝑟[𝑥]
Backward:
𝑉𝑎𝑟𝜕𝜕𝑥 = (2𝑛3678𝑉𝑎𝑟 𝑤3
�
3
)𝑉𝑎𝑟[𝜕𝜕𝑦]
Bothforward(response)andbackward(gradient)signalcanvanish/explode
LeCun etal1998“EfficientBackprop”Glorot &Bengio 2010“Understandingthedifficultyoftrainingdeepfeedforwardneuralnetworks”

Initialization:“Xavier”
• Initializationunderlinear assumption
∏ 𝑛3+,𝑉𝑎𝑟 𝑤3�3 = 𝑐𝑜𝑛𝑠𝑡?@ (healthyforward)
and∏ 𝑛3678𝑉𝑎𝑟 𝑤3�3 = 𝑐𝑜𝑛𝑠𝑡A@(healthybackward)
𝑛3+,𝑉𝑎𝑟 𝑤3 = 1or
𝑛3678𝑉𝑎𝑟 𝑤3 = 1
LeCun etal1998“EfficientBackprop”Glorot &Bengio 2010“Understandingthedifficultyoftrainingdeepfeedforwardneuralnetworks”

Initialization:“MSRA”
• InitializationunderReLU
∏ 𝟏𝟐𝑛3+,𝑉𝑎𝑟 𝑤3�
3 = 𝑐𝑜𝑛𝑠𝑡?@ (healthyforward)and
∏ 𝟏𝟐𝑛3678𝑉𝑎𝑟 𝑤3�
3 = 𝑐𝑜𝑛𝑠𝑡A@(healthybackward)
𝟏𝟐𝑛3
+,𝑉𝑎𝑟 𝑤3 = 1or
𝟏𝟐𝑛3
678𝑉𝑎𝑟 𝑤3 = 1
KaimingHe,XiangyuZhang,ShaoqingRen,&JianSun.“DelvingDeepintoRectifiers:SurpassingHuman-LevelPerformanceonImageNetClassification”.ICCV2015.
With𝐷 layers,afactorof2 perlayerhasexponentialimpactof2G

Initialization
Xavier/MSRAinit• RequiredfortrainingVGG-16/19fromscratch• Deeper(>20)VGG-stylenetscanbetrainedw/MSRAinit
• butdeeperplainnetsarenotbetter(seeResNets)• Recommendedfornewlyinitializedlayersinfine-tuning
• e.g.,Fast/er RCNN,FCN,etc.
• H,
�or I
,�
doesn’tdirectlyapplytomulti-branchnets(e.g.,GoogleNet)• butthesamederivationmethodologyisapplicable• doesnotmatter,ifBNisapplicable…
KaimingHe,XiangyuZhang,ShaoqingRen,&JianSun.“DelvingDeepintoRectifiers:SurpassingHuman-LevelPerformanceonImageNetClassification”.ICCV2015.
*Figuresshowthebeginningoftraining
ours
Xavier
22-layerVGG-style
𝑋𝑎𝑣𝑖𝑒𝑟oursXavier
30-layerVGG-style
𝑀𝑆𝑅𝐴
𝑋𝑎𝑣𝑖𝑒𝑟
𝑀𝑆𝑅𝐴

GoogleNet/Inception
Accuratewithsmallfootprint.MytakeonGoogleNets:• Multiplebranches
• e.g.,1x1,3x3,5x5,pool
• Shortcuts• stand-alone1x1,mergedbyconcat.
• Bottleneck• Reducedimby1x1beforeexpensive3x3/5x5conv
input
Conv7x7+ 2(S)
MaxPool 3x3+ 2(S)
LocalRespNorm
Conv1x1+ 1(V)
Conv3x3+ 1(S)
LocalRespNorm
MaxPool 3x3+ 2(S)
Conv Conv Conv Conv1x1+ 1(S) 3x3+ 1(S) 5x5+ 1(S) 1x1+ 1(S)
Conv Conv MaxPool 1x1+ 1(S) 1x1+ 1(S) 3x3+ 1(S)
Dept hConcat
Conv Conv Conv Conv1x1+ 1(S) 3x3+ 1(S) 5x5+ 1(S) 1x1+ 1(S)
Conv Conv MaxPool 1x1+ 1(S) 1x1+ 1(S) 3x3+ 1(S)
Dept hConcat
MaxPool 3x3+ 2(S)
Conv Conv Conv Conv1x1+ 1(S) 3x3+ 1(S) 5x5+ 1(S) 1x1+ 1(S)
Conv Conv MaxPool 1x1+ 1(S) 1x1+ 1(S) 3x3+ 1(S)
Dept hConcat
Conv Conv Conv Conv1x1+ 1(S) 3x3+ 1(S) 5x5+ 1(S) 1x1+ 1(S)
Conv Conv MaxPool 1x1+ 1(S) 1x1+ 1(S) 3x3+ 1(S)
AveragePool 5x5+ 3(V)
Dept hConcat
Conv Conv Conv Conv1x1+ 1(S) 3x3+ 1(S) 5x5+ 1(S) 1x1+ 1(S)
Conv Conv MaxPool 1x1+ 1(S) 1x1+ 1(S) 3x3+ 1(S)
Dept hConcat
Conv Conv Conv Conv1x1+ 1(S) 3x3+ 1(S) 5x5+ 1(S) 1x1+ 1(S)
Conv Conv MaxPool 1x1+ 1(S) 1x1+ 1(S) 3x3+ 1(S)
Dept hConcat
Conv Conv Conv Conv1x1+ 1(S) 3x3+ 1(S) 5x5+ 1(S) 1x1+ 1(S)
Conv Conv MaxPool 1x1+ 1(S) 1x1+ 1(S) 3x3+ 1(S)
AveragePool 5x5+ 3(V)
Dept hConcat
MaxPool 3x3+ 2(S)
Conv Conv Conv Conv1x1+ 1(S) 3x3+ 1(S) 5x5+ 1(S) 1x1+ 1(S)
Conv Conv MaxPool 1x1+ 1(S) 1x1+ 1(S) 3x3+ 1(S)
Dept hConcat
Conv Conv Conv Conv1x1+ 1(S) 3x3+ 1(S) 5x5+ 1(S) 1x1+ 1(S)
Conv Conv MaxPool 1x1+ 1(S) 1x1+ 1(S) 3x3+ 1(S)
Dept hConcat
AveragePool 7x7+ 1(V)
FC
Conv1x1+ 1(S)
FC
FC
Soft maxAct ivat ion
soft max0
Conv1x1+ 1(S)
FC
FC
Soft maxAct ivat ion
soft max1
Soft maxAct ivat ion
soft max2
Szegedy etal.“Goingdeeperwithconvolutions”.arXiv 2014(CVPR2015).

GoogleNet/Inceptionv1-v3
Moretemplates,butthesame3mainpropertiesarekept:• Multiplebranches• Shortcuts(1x1,concate.)• Bottleneck
Szegedy etal.“RethinkingtheInceptionArchitectureforComputerVision”.arXiv 2015(CVPR2016).

BatchNormalization(BN)
• Recap:Xavier/MSRAinit arenotdirectlyapplicableformulti-branchnets
• Optimizingmulti-branchConvNets largelybenefitsfromBN• includingallInceptionsandResNets
Ioffe &Szegedy.“BatchNormalization:AcceleratingDeepNetworkTrainingbyReducingInternalCovariateShift”.ICML2015.

BatchNormalization(BN)
• Recap:Normalizingimageinput(LeCun etal1998“EfficientBackprop”)
• Xavier/MSRAinit:Analyticnormalizingeachlayer
• BN:data-drivennormalizingeachlayer,foreachmini-batch• Greatlyacceleratetraining• Lesssensitivetoinitialization• Improveregularization
Ioffe &Szegedy.“BatchNormalization:AcceleratingDeepNetworkTrainingbyReducingInternalCovariateShift”.ICML2015.

BatchNormalization(BN)
layer 𝑥 𝑥Q =𝑥 − 𝜇𝜎
𝑦 = 𝛾𝑥Q + 𝛽
• 𝜇:meanof𝑥 inmini-batch• 𝜎:std of𝑥 inmini-batch• 𝛾:scale• 𝛽:shift
• 𝜇,𝜎:functionsof𝑥,analogoustoresponses
• 𝛾, 𝛽:parameterstobelearned,analogoustoweights
Ioffe &Szegedy.“BatchNormalization:AcceleratingDeepNetworkTrainingbyReducingInternalCovariateShift”.ICML2015.

BatchNormalization(BN)
layer 𝑥 𝑥Q =𝑥 − 𝜇𝜎
𝑦 = 𝛾𝑥Q + 𝛽
2modesofBN:• Trainmode:• 𝜇,𝜎 arefunctionsofabatchof𝑥
• Testmode:• 𝜇,𝜎 arepre-computed*ontrainingset
*:byrunningaverage,orpost-processingaftertraining
Caution:makesureyourBNusageiscorrect!(thiscausesmanyofmybugsinmyresearchexperience!)
Ioffe &Szegedy.“BatchNormalization:AcceleratingDeepNetworkTrainingbyReducingInternalCovariateShift”.ICML2015.

BatchNormalization(BN)
Figurecredit:Ioffe &Szegedy
w/oBNw/BNaccuracy
iter.
Ioffe &Szegedy.“BatchNormalization:AcceleratingDeepNetworkTrainingbyReducingInternalCovariateShift”.ICML2015.

ResNets
Credit:???

Simplystackinglayers?
0 1 2 3 4 5 60
10
20
iter. (1e4)
trainerror(%)
0 1 2 3 4 5 60
10
20
iter. (1e4)
testerror(%)CIFAR-10
56-layer
20-layer
56-layer
20-layer
• Plain nets:stacking3x3convlayers…• 56-layernethashighertrainingerror andtesterrorthan20-layernet
KaimingHe,XiangyuZhang,ShaoqingRen,&JianSun.“DeepResidualLearningforImageRecognition”.CVPR2016.

Simplystackinglayers?
0 1 2 3 4 5 60
5
10
20
iter. (1e4)
erro
r (%
)
plain-20plain-32plain-44plain-56
CIFAR-10
20-layer32-layer44-layer56-layer
0 10 20 30 40 5020
30
40
50
60
iter. (1e4)
erro
r (%
)
plain-18plain-34
ImageNet-1000
34-layer
18-layer
• “Overlydeep”plainnetshavehighertrainingerror• Ageneralphenomenon,observedinmanydatasets
solid:test/valdashed:train
KaimingHe,XiangyuZhang,ShaoqingRen,&JianSun.“DeepResidualLearningforImageRecognition”.CVPR2016.

7x7conv,64,/2
3x3conv,64
3x3conv,64
3x3conv,64
3x3conv,64
3x3conv,128,/2
3x3conv,128
3x3conv,128
3x3conv,128
3x3conv,256,/2
3x3conv,256
3x3conv,256
3x3conv,256
3x3conv,512,/2
3x3conv,512
3x3conv,512
3x3conv,512
fc1000
ashallowermodel
(18layers)
adeepercounterpart(34layers)
7x7conv,64,/2
3x3conv,64
3x3conv,64
3x3conv,64
3x3conv,64
3x3conv,64
3x3conv,64
3x3conv,128,/2
3x3conv,128
3x3conv,128
3x3conv,128
3x3conv,128
3x3conv,128
3x3conv,128
3x3conv,128
3x3conv,256,/2
3x3conv,256
3x3conv,256
3x3conv,256
3x3conv,256
3x3conv,256
3x3conv,256
3x3conv,256
3x3conv,256
3x3conv,256
3x3conv,256
3x3conv,256
3x3conv,512,/2
3x3conv,512
3x3conv,512
3x3conv,512
3x3conv,512
3x3conv,512
fc1000
“extra”layers
• Richersolutionspace
• Adeepermodelshouldnothavehighertrainingerror
• Asolutionbyconstruction:• originallayers:copiedfroma
learnedshallowermodel• extralayers:setasidentity• atleastthesametrainingerror
• Optimizationdifficulties:solverscannotfindthesolutionwhengoingdeeper…
KaimingHe,XiangyuZhang,ShaoqingRen,&JianSun.“DeepResidualLearningforImageRecognition”.CVPR2016.

DeepResidualLearning
• Plainnet
KaimingHe,XiangyuZhang,ShaoqingRen,&JianSun.“DeepResidualLearningforImageRecognition”.CVPR2016.
anysmallsubnet
𝑥
𝐻(𝑥)
weightlayer
weightlayer
relu
relu
𝐻 𝑥 isanydesiredmapping,
hopethesmallsubnetfit𝐻(𝑥)

DeepResidualLearning
• Residual net
KaimingHe,XiangyuZhang,ShaoqingRen,&JianSun.“DeepResidualLearningforImageRecognition”.CVPR2016.
𝐻 𝑥 isanydesiredmapping,
hopethesmallsubnetfit𝐻(𝑥)
hope thesmallsubnetfit𝐹(𝑥)
let𝐻 𝑥 = 𝐹 𝑥 + 𝑥weightlayer
weightlayer
relu
relu
𝑥
𝐻 𝑥 = 𝐹 𝑥 + 𝑥
identity𝑥
𝐹(𝑥)

DeepResidualLearning
• 𝐹 𝑥 isaresidual mappingw.r.t.identity
KaimingHe,XiangyuZhang,ShaoqingRen,&JianSun.“DeepResidualLearningforImageRecognition”.CVPR2016.
• Ifidentitywereoptimal,easytosetweightsas0
• Ifoptimalmappingisclosertoidentity,easiertofindsmallfluctuations
weightlayer
weightlayer
relu
relu
𝑥
𝐻 𝑥 = 𝐹 𝑥 + 𝑥
identity𝑥
𝐹(𝑥)

CIFAR-10experiments
0 1 2 3 4 5 60
5
10
20
iter. (1e4)
erro
r (%
)
plain-20plain-32plain-44plain-56
20-layer32-layer44-layer56-layer
CIFAR-10plainnets
0 1 2 3 4 5 60
5
10
20
iter. (1e4)
erro
r (%
)
ResNet-20ResNet-32ResNet-44ResNet-56ResNet-110
CIFAR-10ResNets
56-layer44-layer32-layer20-layer
110-layer
• DeepResNetscanbetrainedwithoutdifficulties• DeeperResNetshavelowertrainingerror,andalsolowertesterror
solid:testdashed:train
KaimingHe,XiangyuZhang,ShaoqingRen,&JianSun.“DeepResidualLearningforImageRecognition”.CVPR2016.

ImageNetexperiments
0 10 20 30 40 5020
30
40
50
60
iter. (1e4)
erro
r (%
)
ResNet-18ResNet-34
0 10 20 30 40 5020
30
40
50
60
iter. (1e4)
erro
r (%
)
plain-18plain-34
ImageNetplainnets ImageNetResNets
solid:testdashed:train
34-layer
18-layer
18-layer
34-layer
• DeepResNetscanbetrainedwithoutdifficulties• DeeperResNetshavelowertrainingerror,andalsolowertesterror
KaimingHe,XiangyuZhang,ShaoqingRen,&JianSun.“DeepResidualLearningforImageRecognition”.CVPR2016.

ImageNetexperiments
• Apracticaldesignofgoingdeeper
3x3,64
3x3,64
relu
relu
64-d
3x3,64
1x1,64relu
1x1,256relu
relu
256-d
all-3x3
KaimingHe,XiangyuZhang,ShaoqingRen,&JianSun.“DeepResidualLearningforImageRecognition”.CVPR2016.
bottleneck(forResNet-50/101/152)
similarcomplexity

ImageNetexperiments7.4
6.7
6.15.7
4
5
6
7
8
ResNet-34ResNet-50ResNet-101ResNet-15210-crop testing,top-5val error(%)
thismodelhaslowertimecomplexity
thanVGG-16/19
• Deeper ResNetshavelower error
KaimingHe,XiangyuZhang,ShaoqingRen,&JianSun.“DeepResidualLearningforImageRecognition”.CVPR2016.

ResNets beyondcomputervision
• NeuralMachineTranslation (NMT):8-layerLSTM!
Wuetal.“Google'sNeuralMachineTranslationSystem:BridgingtheGapbetweenHumanandMachineTranslation”.arXiv 2016.
residualconnections
residualconnections

ResNets beyondcomputervision
• SpeechSynthesis (WaveNet):ResidualCNNson1-dsequence
vandenOordetal.“WaveNet:AGenerativeModelforRawAudio”.arXiv 2016.
residualconnections

ResNets beyondcomputervision
• SpeechRecognition – ResidualCNNson1-dsequence
Xiong etal.“TheMicrosoft2016ConversationalSpeechRecognitionSystem”.arXiv 2016.
residualconnections

ResNeXt
tobepresentedinCVPR2017“AggregatedResidualTransformationsforDeepNeuralNetworks”Saining Xie,RossGirshick,PiotrDollár,Zhuowen Tu,andKaimingHe.

Multi-branch
• (Recap):shortcut,bottleneck,andmulti-branch
Saining Xie,RossGirshick,PiotrDollár,Zhuowen Tu,andKaimingHe.“AggregatedResidualTransformationsforDeepNeuralNetworks”.arXiv 2016(CVPR2017).
Inception:heterogeneousmulti-branch
ResNeXt:uniformmulti-branch
input
pool 1x1 1x11x1
1x1 3x3 5x5
concat

ResNeXt• Concatenation andAddition areinterchangeable
• GeneralpropertyforDNNs;notonlylimitedtoResNeXt
• Uniformmulti-branchingcanbedonebygroup-conv
Saining Xie,RossGirshick,PiotrDollár,Zhuowen Tu,andKaimingHe.“AggregatedResidualTransformationsforDeepNeuralNetworks”.arXiv 2016(CVPR2017).

ResNeXt
Saining Xie,RossGirshick,PiotrDollár,Zhuowen Tu,andKaimingHe.“AggregatedResidualTransformationsforDeepNeuralNetworks”.arXiv 2016(CVPR2017).
• Betteraccuracy• whenhavingthesameFLOPs/#paramsasResNet
• Bettertrade-offoflargermodels

ResNeXt forMaskR-CNN
KaimingHe,GeorgiaGkioxari,PiotrDollár,andRossGirshick.“MaskR-CNN”.ICCV2017.Saining Xie,RossGirshick,PiotrDollár,Zhuowen Tu,andKaimingHe.“AggregatedResidualTransformationsforDeepNeuralNetworks”.arXiv 2016(CVPR2017).
ResNeXt improves1.6bbox AP(and1.4maskAP)onCOCOFeaturestillmatters!

Morearchitectures(notcoveredinthistutorial)
• Inception-ResNet [Szegedy etal2017]• Inceptionastransformation+residualconnection
• DenseNet [HuangetalCVPR2017]• Denselyconnectedshortcutsw/concat.
• Xception [Chollet CVPR2017],MobileNets [Howardetal2017]• DepthwiseConv (i.e.,GroupConv with#group=#channel)
• ShuffleNet [Zhangetal2017]• MoreGroup/DepthwiseConv +shuffle
• ……
XceptionInception-ResNet
ShuffleNet
DenseNet

TrainingImageNetin1Hour
Priya Goyal,PiotrDollár,RossGirshick,PieterNoordhuis,LukaszWesolowski,Aapo Kyrola,AndrewTulloch,Yangqing Jia,KaimingHe.“Accurate,LargeMinibatch SGD:TrainingImageNetin1Hour”.arXiv 2017.
• 256GPUs• 8,192mini-batchsize• ResNet-50• Nolossofaccuracy
Keyfactors• Linearscalinglearningrateinminibatch size• Warmup• ImplementthingscorrectlyinmultipleGPUs/machines!

Conclusion:FeaturesMatter!
Deepfeatures empoweramazingvisualrecognitionresults(MaskR-CNNw/ResNet101;moreinnexttalk)
KaimingHe,GeorgiaGkioxari,PiotrDollár,andRossGirshick.“MaskR-CNN”.ICCV2017.