
Critically reviewing quantitative papers using a CASP critiquing tool Steve George
40
Critically reviewing quantitative papers using a CASP critiquing tool Steve George Sue and Sam have been asked to critique an empirical paper Sam, this is really difficult. I don’t even know what some of these questions mean, let alone the answers to them!
-
Upload
hyacinth-patton -
Category
Documents
-
view
43 -
download
2
description
Critically reviewing quantitative papers using a CASP critiquing tool Steve George. Sam , this is really difficult. I don’t even know what some of these questions mean, let alone the answers to them!. Sue and Sam have been asked to critique an empirical paper. - PowerPoint PPT Presentation
Transcript of Critically reviewing quantitative papers using a CASP critiquing tool Steve George

Critically reviewingquantitative papers using a CASP critiquing tool
Steve GeorgeSue and Sam have been asked
to critique an empirical paper
Sam, this is really difficult. I don’t even know what some of
these questions mean, let alone the answers to them!

It isn’t that complicated Sue. What the CASP
scheme does is break down what is potentially a complex question into easily answerable bits. Come on, let’s have a
go…

Safety and effectiveness of nurse telephone consultation in out of hours primary care: randomised controlled trial.Val Lattimer, Steve George, Felicity Thompson, Eileen Thomas, Mark Mullee, Joanne Turnbull, helen Smith, Michael Moore, Hugh bond, Alan Glasper (the South Wiltshire Out of Hours Project (SWOOP) Group)
BMJ 1998;317:1054–9

Did the study ask a clearly-focused question?
• If the authors of a paper haven’t asked a clearly focused question they’re not going to get an answer which means anything, and you can stop reading at that point!

Did the study ask a clearly-focused question?
Abstract – p.1054
Objective: To determine the safety and effectiveness of nurse telephone consultation in out of hours primary care by investigating adverse events and the management of calls.

Did the study ask a clearly-focused question?
Introduction – p.1055
The principal objective of this trial, and that used in determining its power, was to establish whether there was equivalence in the number of adverse events generated by a general practice co-operative augmented by nurse consultation compared with standard cooperative service. A secondary objective was to collect data on the management of calls and on emergency hospital admissions and attendances at accident and emergency departments among those who had contacted the out of ours service.

Did the study ask a clearly-focused question?• It’s always worth considering the history of a
paper’s subject area: this was a highly political area in the 1990s.
• The authors undertook a General Practitioner survey a couple of years earlier, in which it became clear that the `safety’ of putting nurses on the telephone to answer patients’ calls was a concern amongst GPs at that time .
• A sensible aim of a large scale study looking at nurse telephone consultation would therefore be to establish its safety, and it made sense to do a study of its effectiveness at the same time.

Did the study ask a clearly-focused question?• The authors had done a pilot study previously,
and a common question is “Why didn’t they do the safety study at that stage?”
• The answer is that `effectiveness’ outcomes are far more common than the `adverse event’ outcomes used to measure safety. To look at safety we have to collect data on a very large number of people – many more than would be included in any pilot study or in many trials.
• Many randomised controlled trials, even drug trials, don’t look at safety – that’s established much later by post-marketing surveillance studies on large numbers.

So there are studies that you do after trials?
…and there are different types of trials which are done at different stages
in the development of an Intervention…

Types of clinical trial
• Phase I – clinical pharmacology and toxicity – generally not
randomised
• Phase II – initial clinical investigation for treatment effect – sometimes randomised
• Phase III – full-scale evaluation of treatment – nearly always randomised, and as well as there being drug trials most non-drug trials also fall into this category – so trials of surgery, therapies, role replacement etc.
• Phase IV – post-marketing surveillance studies – not randomised

OK – next question!

Was this a randomised controlled trial (RCT) and was it appropriately so?
• This is one people often get wrong.
• Subjects in a randomised controlled trial aren’t randomly selected from the population. There wouldn’t be any point in doing that. If you were going to test a new anti-hypertensive drug you’d want all the subjects in your trial to have high blood pressure, and if you randomly selected them from the population they wouldn’t have it.
• Subjects in a randomised controlled trial are often highly selected, and `random’, in this case, refers to the method by which you allocate them to treatment within the trial, not the means by which you select them from the population.

Was this a randomised controlled trial (RCT) and was it appropriately so?
• The standard pattern in trials is that patients are invited to take part in the trial, have their details taken, sign a consent form, and are then given either one treatment or the other.
• In order to do that in this trial the investigators would have had to have set up two services, one using nurses on the telephone, one not, working in parallel, at the same time, and sent each patient to one of them or the other - very costly if not logistically impossible.
• So, instead, they split the trial year up into periods when the nurse service ran and periods when it didn’t.

Was this a randomised controlled trial (RCT) and was it appropriately so?
The trial year was divided into 26 blocks of two weeks. Within each block, one of each pair of matching out of hours periods —for example, Tuesday evenings—was randomly allocated to receive the intervention, the other being allocated to the normal service, by means of a random number generator on a Hewlett Packard 21S pocket calculator. For logistical reasons weekends (Saturdays and Sundays) were treated as single units for randomization. The complete pattern of intervention periods was known in advance only to the lead investigators and the trial coordinator (SG, VL, and FT).
Methods: randomisation – p.1056

Was this a randomised controlled trial (RCT) and was it appropriately so?• A simple random sequence of numbers can result
in quite considerable differences of numbers in different arms of trials, particularly if a trial is small.
• Instead, a method called `block randomisation’ is often used in drug trials in order to iron out differences in numbers of subjects in each arm of a trial.
• A trial is divided into blocks of four or six subjects, commonly, and within each block two (of four) or three (of six) subjects are allocated to each intervention. Allocation within each block is random, and so the whole sequence of all the blocks placed one after another becomes random.

Was this a randomised controlled trial (RCT) and was it appropriately so?• This was a block randomised controlled trial, but
using a method different from that used in drug trials.
• Rather than blocks being composed of individual patients, the investigators divided the trial year over which they were going to run the trial into a series of 26 blocks of two weeks. Within each block they therefore had two Monday evenings, two Tuesday evenings, two weekends, and so on.
• They randomised so that one or other of the two became an allocation unit within the trial, with patients ringing in during that block allocated to one service or the other.

Was this a randomised controlled trial (RCT) and was it appropriately so?
• So the first part of this question is answered, in that this was a randomised controlled trial.
• For the second part we need to consider whether or not a randomised controlled trial was the best type of research study to use.

The randomised controlled trial is the best single study to answer the question
How effective is
[new treatment]
in the management of
[specified ailment]
compared to
[placebo or best existing treatment]

The randomised controlled trial is not the best single study to answer the questions
– What is the cause of this rare disease?– How many of this population of elderly people
need incontinence care?– Why don’t patients like turning up to antenatal
clinics?
• These questions are best answered by approaches other than randomised controlled trials.
• However, in this case, a randomised controlled trial was the best way to answer the question set.

Were participants appropriately allocated to intervention and control groups?
• The best way to tell if randomisation has been effective is to look at the tables of baseline data for a trial – often table 1, but in this paper split between tables 2 and 3.
• As a broad rule, if the two groups randomised are broadly similar randomisation has worked, and if they’re not, it hasn’t.
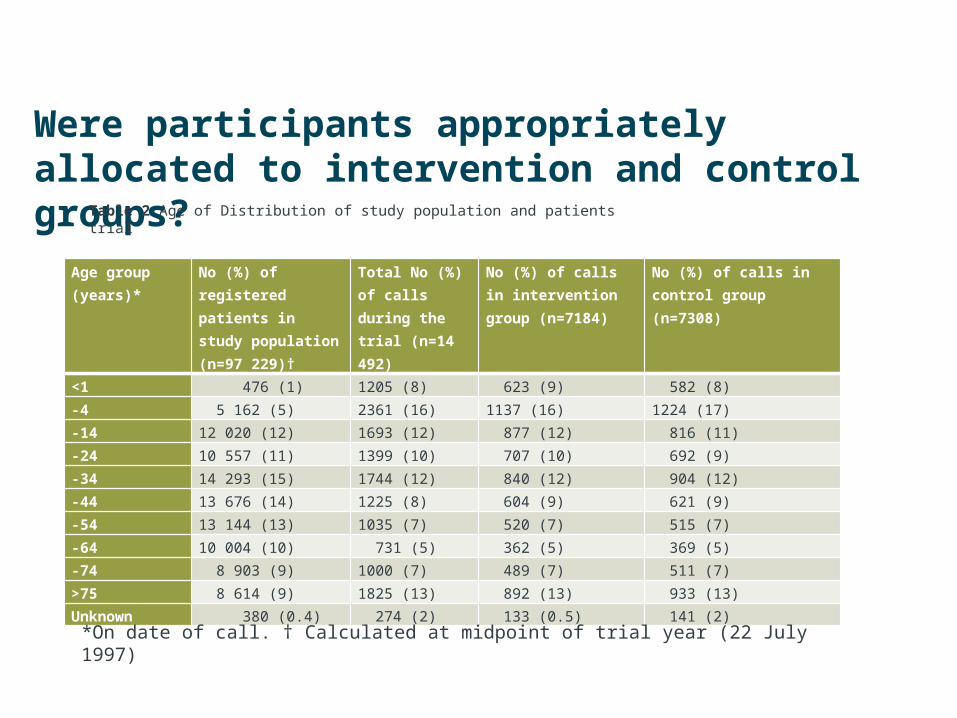
Were participants appropriately allocated to intervention and control groups?
Age group (years)*
No (%) of registered patients in study population (n=97 229)†
Total No (%) of calls during the trial (n=14 492)
No (%) of calls in intervention group (n=7184)
No (%) of calls in control group (n=7308)
<1 476 (1) 1205 (8) 623 (9) 582 (8)-4 5 162 (5) 2361 (16) 1137 (16) 1224 (17)-14 12 020 (12) 1693 (12) 877 (12) 816 (11)-24 10 557 (11) 1399 (10) 707 (10) 692 (9)-34 14 293 (15) 1744 (12) 840 (12) 904 (12)-44 13 676 (14) 1225 (8) 604 (9) 621 (9)-54 13 144 (13) 1035 (7) 520 (7) 515 (7)-64 10 004 (10) 731 (5) 362 (5) 369 (5)-74 8 903 (9) 1000 (7) 489 (7) 511 (7)>75 8 614 (9) 1825 (13) 892 (13) 933 (13)Unknown 380 (0.4) 274 (2) 133 (0.5) 141 (2)
Table 2 Age of Distribution of study population and patients trial
*On date of call. † Calculated at midpoint of trial year (22 July 1997)

Were participants appropriately allocated to intervention and control groups?
Sex Study population (n=97 229)
Total No of calls (n=14
492)
Intervention group
(n=7184)
Control group
(n=7308)Male 46 358 (48) 6039 (42) 2970 (41) 3069 (42)Female 50 270 (52) 5450 (58) 4212 (59) 4238 (58)Unknown 601 (0.6) 3 (0.02) 2 (0.03) 1 (0.01)
Table 3 Sex distribution of study population and patients in trial. Values are numbers (percentages)

Were participants, staff and study personnel ‘blind’ to participants’ study group?• A blinded trial is one in which the design prevents
participants, carers or those assessing outcome from knowing which intervention group a participant was in.
• Blinding is sometimes impossible e.g. trials of surgical operations and trials of therapies involving active patient participation - like `talking therapies’ or physiotherapy.
• The 2010 CONSORT Statement recommended that the use of terms like “single blinded” and “double blinded” was terminated and that reports of trials which were meant to be blinded should discuss, instead `If done, who was blinded after assignment to interventions and how?

Were participants, staff and study personnel ‘blind’ to participants’ study group?
Methods: randomisation – p.1056
The complete patter of intervention periods was known in advance only to the lead investigators and the trial coordinator (SG, VL, and FT). Nurses providing the intervention knew their shifts only after the duty roster for general practitioners providing out of hours care had been fixed. General practitioners were therefore blind to the intervention at the point which they were able to choose or swap duty periods. Most were not aware until the start of a period of duty whether nurses were present. The pattern of intervention and control days was not publicized and would have only become apparent to a member of the public on a particular day on calling the out of hours service and discovering whether nurse consultation was operating.

Were participants, staff and study personnel ‘blind’ to participants’ study group?• The investigators don’t claim to have blinded this
trial. It’s obvious whether or not you spoke to a nurse before speaking to a doctor or only spoke to a nurse.
• However, all outcomes were objective – total deaths, numbers of A&E attendances and hospital admissions, and so can’t be influenced by opinion.
• In terms of allocation concealment the pattern of intervention was known only to the lead investigators. Nurses and doctors working on the ground were blind to the intervention until a point when they would be unable to choose or swap duty periods.

Were all of the participants who entered the trial accounted for at its conclusion?
• Sadly, this isn’t always the case, and it’s always worth checking that all the tables add up...
• “Intention to treat” analysis accounts for every person who is recruited to a trial.
• They are analysed in the group to which they were first assigned, not the one in which they ended up – which in drug trials can be different for various reasons – and they’re not left out because, for instance, they didn’t complete the course of treatment.

Were all of the participants who entered the trial accounted for at its conclusion?
• This means that systems must be set up which can account for missing data (and every trial has missing data).
• Usually a conservative assumption is made e.g. in a trial of an intervention designed to stop people smoking the assumption is made that if they’ve been lost to follow up they’ve continued to smoke.
• In this trial people were entered according to the system in operation at the time they called, so swapping groups isn’t really an option, and all the tables add up, so nobody’s been left out of the analysis.

OK – next question!

Were the participants in all groups followed up and data collected in the same way?• It’s very important that the only thing that differs
between groups in a trial is the intervention being tested, as otherwise a false conclusion may be reached.
• Here the investigators collected data on workload from the data base of calls, data on mortality from the Office For National Statistics, data on admissions from local hospitals, and then data on attendance at A&E from GP cooperative records, all using the total list of names and addresses of people that called, and they then matched the data gathered to the period in which they called, so it would have been difficult to treat the groups differently.

Did the study have enough participants to minimise the play of chance?
• There are two ways to approach this – the first is to learn enough statistics, and to gain access to a statistical software package that will allow you to do it, and recalculate the sample size for the study using the data given.
• If that seems like overkill the first thing to look out for is that the investigators have done a sample size calculation before starting the trial. Then, look to see if they actually achieved that sample size during recruitment.
• If they’ve done that that’s usually enough. In this trial they did both, so that box gets a tick.

How are the results presented and what is the main result?
• This is an equivalence trial i.e. a trial where the aim is not to show differences, but rather to demonstrate equivalence, between two treatments.
• It is impossible, however, to prove equivalence without an infinite series of observations. Practically, we have to define limits within which we will accept equivalence.
• Equivalence limits are entirely arbitrary (but, then again, so is the 5% accepted level for statistical significance).
• Limits commonly used in studies of bio-equivalence are from -20% to +25% of expected figure .

How are the results presented and what is the main result?
• 95% confidence intervals (CI) are calculated around the trial result (e.g. the difference between the groups).
– 1. If the 95% CIs lie entirely between the upper and lower equivalence limits equivalence is assumed.
– 2. If the 95% CIs lie either completely above the upper equivalence limit, or below the lower equivalence limit, equivalence is rejected.
– 3. If the 95% CI’s cross either equivalence limit the result is considered uncertain.
• In general, a much larger number of patients is required for equivalence trials than for difference trials.

How are the results presented and what is the main result?• In this trial the existing death rate for England was
used to calculate an expected number of deaths over the trial year based on the size of the population covered by the GP cooperative used for the trial.
• Limits were then set around it from 80% to 125% of that number, which is a range used in bioequivalence studies.
• They then compared the number of deaths plus the confidence intervals around it to the equivalence limits.
• In that way it was shown that there was equivalence in the number of deaths observed in each arm of the trial.

How precise are these results?
• This question is not really relevant to this trial as the equivalence design means that the precision of the results (shown by the width of the confidence intervals) is an integral part of the results.
• In a difference trial the magnitude of the result might be shown, but not the confidence intervals around it.
• Even if a p-value demonstrates that a result is significant the confidence intervals around it can mean that there is a wide range of possible results.

Were all important outcomes considered so the results can be applied?
• The outcomes considered were:
– deaths within seven days of a contact with the out of hours service
– emergency hospital admissions within 24 hours and within three days of contact
– attendance at accident and emergency within three days of a contact
– how all the calls were managed and by whom

Were all important outcomes considered so the results can be applied?
• The range of outcomes looked at in this trial was wide, but the context in which the trial was done has changed.
• This trial looked at the safety of nurse telephone consultation services, and that safety result still stands…

Were all important outcomes considered so the results can be applied?
• …but the nurses in this trial worked within the context of a primary care cooperative, which haven’t existed for some years, so the result showing that calls needing to be handled by doctors were reduced by 50% can’t now be interpreted, unless a similar system comes into operation again.
• One of the major problems with randomised controlled trials is that their results are too often applied to people who weren’t represented in the trial population, or in circumstances which are different from those pertaining in the trial.

Were all important outcomes considered so the results can be applied?
• The results of this trial were used by the government to inform the setting up of NHS Direct.
• However, NHS Direct wasn’t linked to primary care, and consequently never showed the reduction in workload for out of hours medical care.
• There are similar concerns about the new “111” helpline number for non-urgent care. An implicit assumption is that the use of this helpline by the public will lead to reductions in demand for other services - however this wasn’t what happened with NHS Direct…

That’s an important lesson. Thanks Sam

The CASP scheme and Ockham’s razor
• “Simpler explanations are, other things being equal, generally better than more complex ones” (William of Ockham 1288 – 1348).
• A scheme like CASP allows us to break what is a potentially complex question into a number of simpler chunks…
• …but the scheme you choose isn’t fixed – why not design your own?


















