
Course Work Project Project title “Data Analysis Methods for Microarray Based Gene Expression...
22
Course Work Project Project title “Data Analysis Methods for Microarray Based Gene Expression Analysis” Sushil Kumar Singh (batch 2002-03) IBAB, Bangalore Done at Siri Technologies Pvt. Ltd. Bangalore
-
Upload
tobias-moore -
Category
Documents
-
view
221 -
download
0
Transcript of Course Work Project Project title “Data Analysis Methods for Microarray Based Gene Expression...

Course Work Project
Project title
“Data Analysis Methods for Microarray Based Gene Expression Analysis”
Sushil Kumar Singh (batch 2002-03)IBAB, Bangalore
Done at Siri Technologies Pvt. Ltd.
Bangalore

Outline
Introduction Overview of Data Analysis Normalization Clustering Algorithms Future work Acknowledgements Questions ???
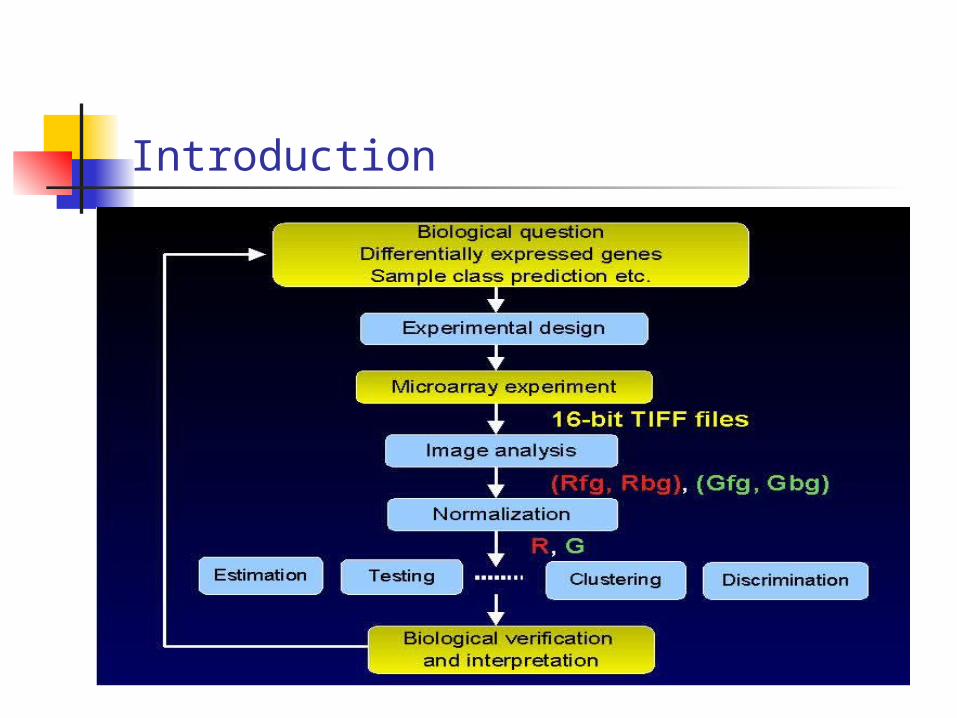
Introduction
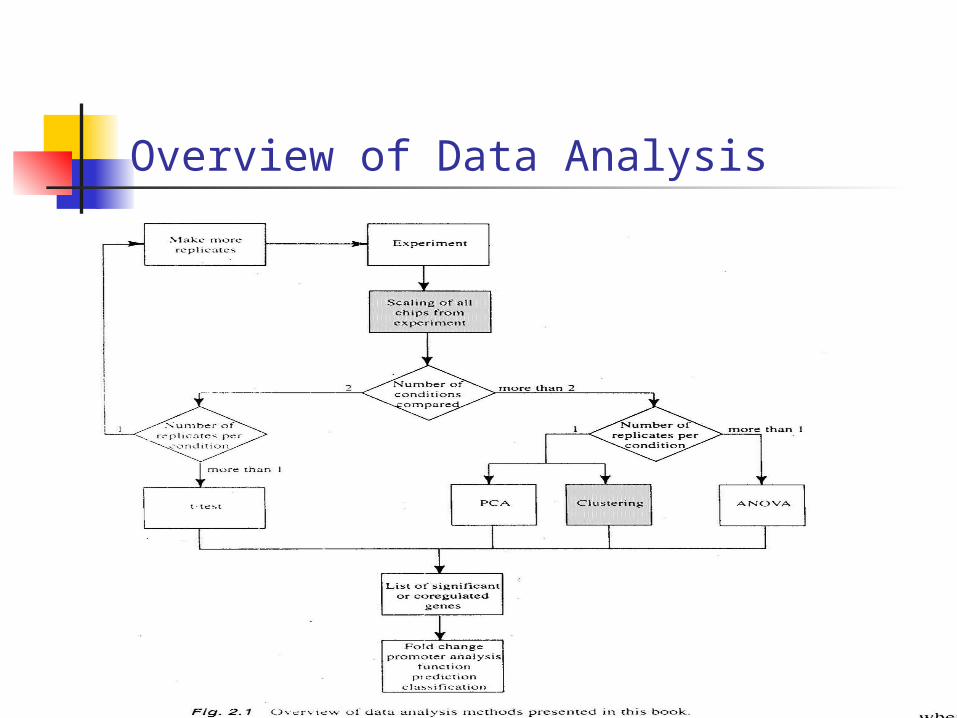
Overview of Data Analysis

Normalization An attempt to remove systematic variation
from data. Sources of systematic variation –
Biological source Influenced by genetic or environmental factors, Age,
sex etc. Technical source
Induced during extraction, labelling, and hybridization of samples
Printing tip problems Measurement source
Different DNA conc. Scanner problem

Why Normalize Data
To recognize the biological information in data.
To compare data from one array to another.
In practice we do not understand the data – inevitably some biology will be removed too.

Normalization methods
Methods of elements selections Housekeeping genes All elements Using Spiked control
Methods to calculate normalization factor Log ratio Lowess Ratio statistics

Clustering
For a sample of size “n” described by a d-dimensional feature space, clustering is a procedure that
Divides the d-dimensional features in K-disjoint groups in such a way that the data points within each group are more similar to each other than to any other data point in other group.

Clustering algorithms
Unsupervised – without a priory biological information Agglomerative – Hierarchical Divisive – K-means, SOM
Supervised – a priory biological knowledge Support vector machine (SVM)

Hierarchical clustering (HC)
Agglomerative technique steps
The pair-wise distance is calculated between all genes. The two genes with shortest distance are grouped
together to form a cluster. Then two closest cluster are merged together, to form
a new cluster. The distances are calculated between this new cluster
and all other clusters Steps 2 to 4 are repeated until all the objects are in
one cluster.
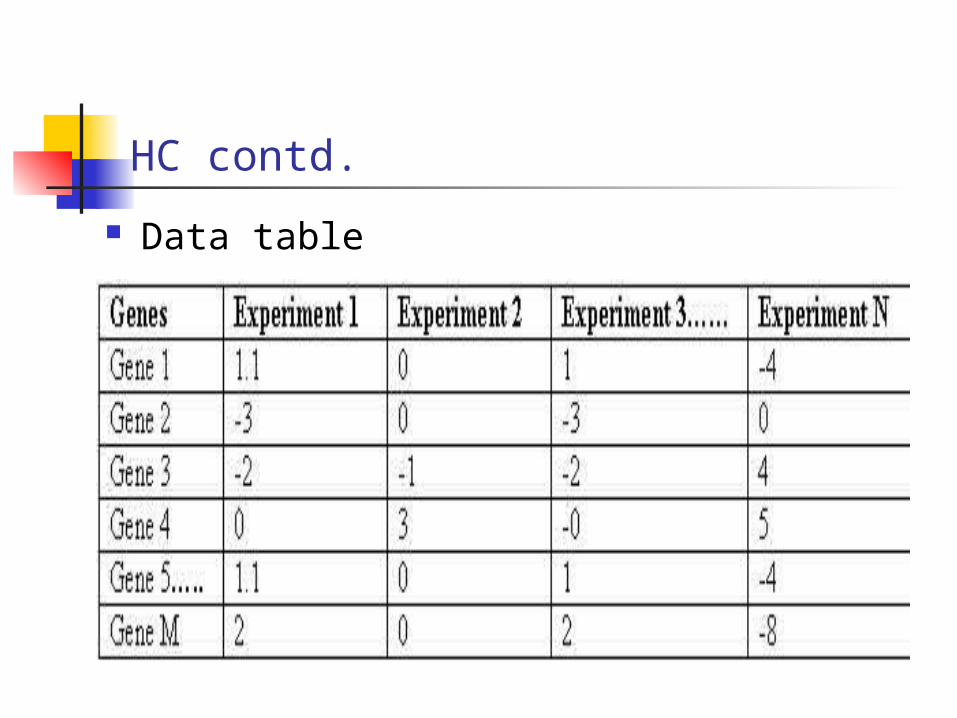
HC contd.
Data table
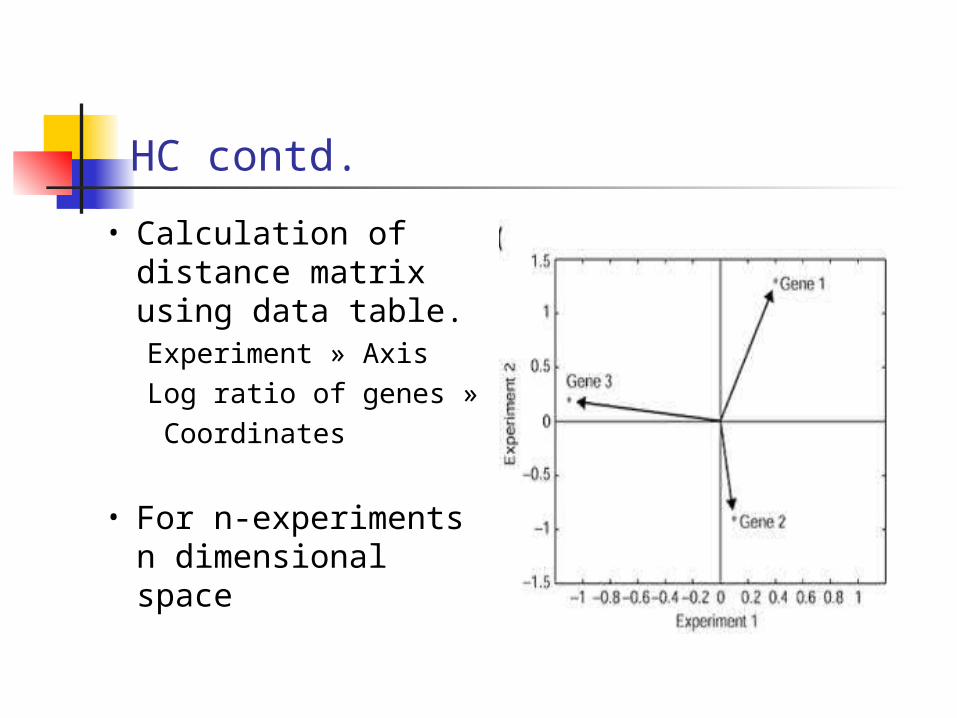
HC contd.
• Calculation of distance matrix using data table.Experiment » AxisLog ratio of genes » Coordinates
• For n-experiments n dimensional space

HC contd.
Distance between genes Euclidean distance
Pearson correlation
Semi-metric distance – Vector angle
Metric distance – Manhattan or City block

HC contd. Distance between clusters
Single linkage clustering
Complete linkage clustering
Average linkage clustering UPGMA Weighted pair-group average Within-groups clustering Ward’s method

HC contd.
The result of HC displayed as branching tree diagram called “Dendrogram”.
Pros and cons of HC Easy to implement, quick visualization of
data set. Ignores negative associations between
genes, falls in category of greedy algorithms.

K-means Clustering
Divisive approach Steps
Specify K-initial clusters and find their centroid.
For each data point the distance to each centroid is calculated.
Each data point is assigned to its nearest centroid.
Centroids are shifted to the center of data points assigned to it.
Steps 2-4 is iterated until centroid are not shifted anymore.
K-means clustering contd.
Pros and Cons No dendrogram It is a powerful method if one has prior idea
about the no. of cluster, so it works well with PCA.
x1
x2

Future Work
It includes similar analysis on Self Organizing Map (SOM) Support Vector Machine (SVM) Relevance Network Gene Shaving Self Organizing Tree Analysis (SOTA) Cluster Affinity Search Technique (CAST)

Acknowledgements
Institute of Bioinformatics and Applied Biotechnology (IBAB), Bangalore
Dr. Ashwini K Heerekar (Siri Technologies Pvt. Ltd, Bangalore)
Dr. Jonnlagada Srinivas (Siri Technologies Pvt. Ltd, Bangalore)
Mr. Kiran Kumar (Siri Technologies Pvt. Ltd, Bangalore)
Mr. Mahantha Swamy MV. (Siri Technologies Pvt. Ltd, Bangalore)

Selected references: A Biologist Guide to Analysis of DNA
Microarray DATA, by Steen Knudsen DNA Microarrays And Gene Expression from
experiment to data analysis and modeling, by P. Baldi and G. Wesely
Papers: Computational Analysis of Microarray Data by John Quackenbush,
Nature Genetics Review, June 2001, vol2. The use and analysis of Microarray Data by Atul Butte, Nature
Review drug discovery, Dec 2002, vol1. Microarray Data Normaliation and Transformation by John
Quackenbush, Nature Genetics.

Questions
???

Thank You


















