
COS 320 Compilers David Walker. Outline Last Week –Introduction to ML Today: –Lexical Analysis...
38
COS 320 Compilers David Walker
-
date post
21-Dec-2015 -
Category
Documents
-
view
213 -
download
0
Transcript of COS 320 Compilers David Walker. Outline Last Week –Introduction to ML Today: –Lexical Analysis...

COS 320Compilers
David Walker

Outline
• Last Week– Introduction to ML
• Today:– Lexical Analysis– Reading: Chapter 2 of Appel
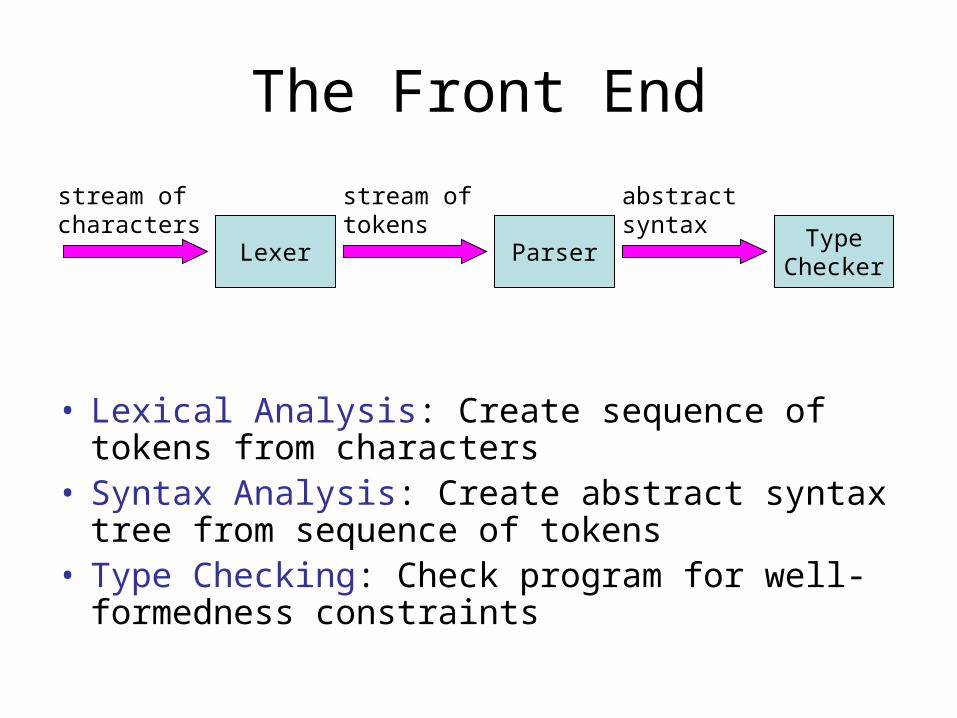
The Front End
• Lexical Analysis: Create sequence of tokens from characters
• Syntax Analysis: Create abstract syntax tree from sequence of tokens
• Type Checking: Check program for well-formedness constraints
Lexer Parser
stream ofcharacters
stream oftokens
abstractsyntax
TypeChecker

Lexical Analysis
• Lexical Analysis: Breaks stream of ASCII characters (source) into tokens
• Token: An atomic unit of program syntax– i.e., a word as opposed to a sentence
• Tokens and their types:Type:IDREALSEMILPARENNUMIF
Characters Recognized:foo, x, listcount10.45, 3.14, -2.1;(50, 100if
Token:ID(foo), ID(x), ...REAL(10.45), REAL(3.14), ...SEMILPARENNUM(50), NUM(100)IF

Lexical Analysis Examplex = ( y + 4.0 ) ;

Lexical Analysis Examplex = ( y + 4.0 ) ;
ID(x)
Lexical Analysis

Lexical Analysis Examplex = ( y + 4.0 ) ;
ID(x) ASSIGN
Lexical Analysis

Lexical Analysis Examplex = ( y + 4.0 ) ;
ID(x) ASSIGN LPAREN ID(y) PLUS REAL(4.0) RPAREN SEMI
Lexical Analysis

Lexer Implementation• Implementation Options:
1. Write a Lexer from scratch– Boring, error-prone and too much work
2. Use a Lexer Generator– Quick and easy. Good for lazy compiler writers.
Lexer Specification

Lexer Implementation• Implementation Options:
1. Write a Lexer from scratch– Boring, error-prone and too much work
2. Use a Lexer Generator– Quick and easy. Good for lazy compiler writers.
Lexer Specification
lexergenerator
Lexer
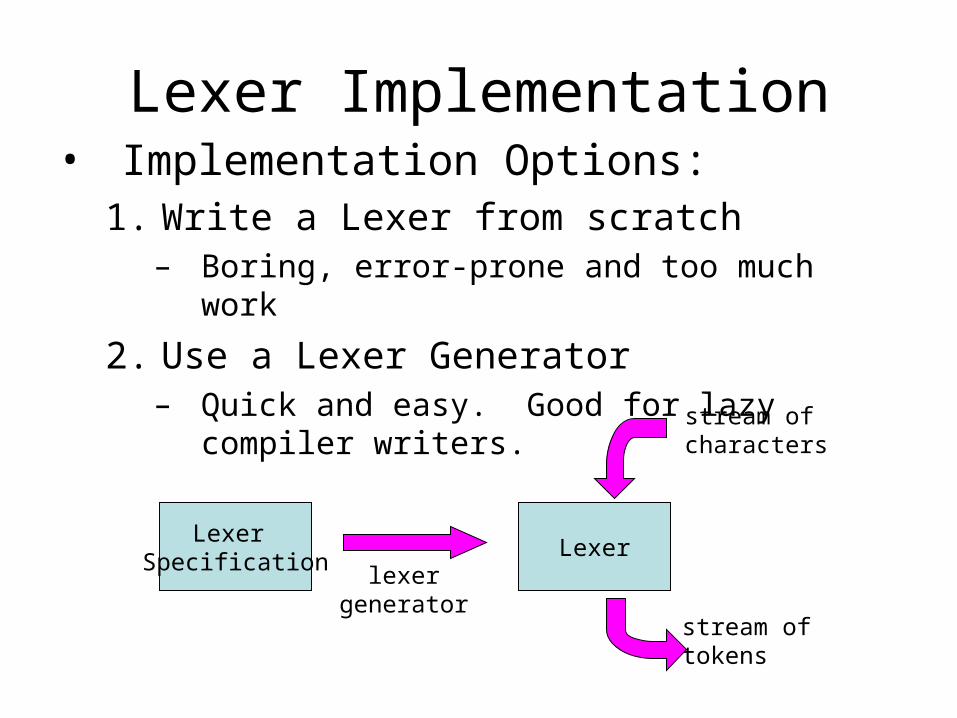
Lexer Implementation• Implementation Options:
1. Write a Lexer from scratch– Boring, error-prone and too much work
2. Use a Lexer Generator– Quick and easy. Good for lazy compiler writers.
Lexer Specification
lexergenerator
Lexer
stream ofcharacters
stream oftokens

• How do we specify the lexer?– Develop another language – We’ll use a language involving regular
expressions to specify tokens
• What is a lexer generator?– Another compiler ....

Some Definitions• We will want to define the language of legal tokens
our lexer can recognize– Alphabet – a collection of symbols (ASCII is an alphabet)– String – a finite sequence of symbols taken from our alphabet
– Language of legal tokens – a set of strings• Language of ML keywords – set of all strings which are ML
keywords (FINITE)• Language of ML tokens – set of all strings which map to ML tokens
(INFINITE)• Some people use the word “language” to mean more general sets:
– eg: ML Language – set of all strings representing correct ML programs (INFINITE).

Regular Expressions: Construction
• Base Cases:– For each symbol a in alphabet, a is a RE denoting the
set {a}– Epsilon (e) denotes { }
• Inductive Cases (M and N are REs)– Alternation (M | N) denotes strings in M or N
• (a | b) == {a, b}– Concatenation (M N) denotes strings in M
concatenated with strings in N• (a | b) (a | c) == { aa, ac, ba, bc }
– Kleene closure (M*) denotes strings formed by any number of repetitions of strings in M
• (a | b )* == {e, a, b, aa, ab, ba, bb, ...}

Regular Expressions
• Integers begin with an optional minus sign, continue with a sequence of digits
• Regular Expression: (- | e) (0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9)*

Regular Expressions
• Integers begin with an optional minus sign, continue with a sequence of digits
• Regular Expression: (- | e) (0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9)*
• So writing (0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9) and even worse (a | b | c | ...) gets tedious...

Regular Expressions
• common abbreviations: – [a-c] == (a | b | c)– . == any character except \n– \n == new line character– a+ == one or more– a? == zero or one
• all abbreviations can be defined in terms of the “standard” regular expressions

Ambiguous Token Rule Sets
• A single expression is a completely unambiguous specification of a token.
• Sometimes, when we put together a set of regular expressions to specify all of the tokens in a language, ambiguities arise:– i.e., two regular expression match the same
string

Ambiguous Token Rule Sets
• Example:– Identifier tokens: a-z* (a-z | 0-9)*– Sample keyword tokens: if, then, ...
• How do we tokenize:– foobar ==> ID(foobar) or ID(foo)
ID(bar)– if ==> ID(if) or IF

Ambiguous Token Rule Sets
• We resolve ambiguities using two rules:– Longest match: The regular expression that
matches the longest string takes precedence.– Rule Priority: The regular expressions
identifying tokens are written down in sequence. If two regular expressions match the same (longest) string, the first regular expression in the sequence takes precedence.

Ambiguous Token Rule Sets
• Example:– Identifier tokens: a-z (a-z | 0-9)*– Sample keyword tokens: if, then, ...
• How do we tokenize:– foobar ==> ID(foobar) or ID(foo)
ID(bar)– if ==> ID(if) or IF

Ambiguous Token Rule Sets
• Example:– Identifier tokens: a-z* (a-z | 0-9)*– Sample keyword tokens: if, then, ...
• How do we tokenize:– foobar ==> ID(foobar) or ID(foo)
ID(bar)– if ==> ID(if) or IF

Lexer Implementation
Implementation Options:1. Write Lexer from scratch
– Boring and error-prone
2. Use Lexical Analyzer Generator– Quick and easy
ml-lex is a lexical analyzer generator for ML.
lex and flex are lexical analyzer generators for C.

ML-Lex Specification
• Lexical specification consists of 3 parts:
User Declarations
%%
ML-LEX Definitions
%%
Rules

User Declarations
• User Declarations:– User can define various values that are
available to the action fragments.– Two values must be defined in this section:
• type lexresult– type of the value returned by each rule action.
• fun eof ()– called by lexer when end of input stream is reached.

ML-LEX Definitions
• ML-LEX Definitions:– User can define regular expression
abbreviations:
– Define multiple lexers to work together. Each is given a unique name.
DIGITS = [0-9] +;LETTER = [a-zA-Z];
%s LEX1 LEX2 LEX3;

Rules
• Rules:
• A rule consists of a pattern and an action:– Pattern in a regular expression.– Action is a fragment of ordinary ML code.
• Rules may be prefixed with the list of lexers that are allowed to use this rule.
<lexer_list> regular_expression => (action.code) ;

Rules
• Rules:
• A rule consists of a pattern and an action:– Pattern in a regular expression.– Action is a fragment of ordinary ML code.– Longest match & rule priority used for disambiguation
• Rules may be prefixed with the list of lexers that are allowed to use this rule.
<lexer_list> regular_expression => (action.code) ;

Rules
• Rule actions can use any value defined in the User Declarations section, including– type lexresult
• type of value returned by each rule action
– val eof : unit -> lexresult• called by lexer when end of input stream reached
• special variables:– yytext: input substring matched by regular expression– yypos: file position of the beginning of matched string– continue (): used to recursively called lexer

A Simple Lexerdatatype token = Num of int | Id of string | IF | THEN | ELSE | EOFtype lexresult = token (* mandatory *)fun eof () = EOF (* mandatory *)
fun itos s = case Int.fromString s of SOME x => x | NONE => raise fail%%
NUM = [1-9][0-9]*ID = [a-zA-Z] ([a-zA-Z] | NUM)*
%%
if => (IF);then => (THEN);else => (ELSE);{NUM} => (Num (itos yytext));{ID} => (Id yytext);

Using Multiple Lexers
• Rules prefixed with a lexer name are matched only when that lexer is executing
• Enter new lexer using command YYBEGIN
• Initial lexer is called INITIAL

Using Multiple Lexers
type lexresult = unit (* mandatory *)fun eof () = () (* mandatory *)
%%
%s COMMENT
%%
<INITIAL> if => ();<INITIAL> [a-z]+ => ();<INITIAL> “(*” => (YYBEGIN COMMENT; continue ());<COMMENT> “*)” => (YYBEGIN INITIAL; continue ());<COMMENT> “\n” | . => (continue ());

A (Marginally) More Exciting Lexertype lexresult = string (* mandatory *)fun eof () = (print “End of file\n”; “EOF”) (* mandatory *)
%%
%s COMMENT
INT = [1-9] [0-9]*;
%%
<INITIAL> if => (“IF”);<INITIAL> then => (“THEN”);<INITIAL> {INT} => ( “INT(“ ^ yytext ^ “)” );<INITIAL> “(*” => (YYBEGIN COMMENT; continue ());<COMMENT> “*)” => (YYBEGIN INITIAL; continue ());<COMMENT> “\n” | . => (continue ());

Implementing Lexers
• By compiling, of course:– convert REs into non-deterministic finite
automata– convert non-deterministic finite automata into
deterministic finite automata– convert deterministic finite automata into a
blazingly fast table-driven algorithm
• you did everything but possibly the last step in your favorite algorithms class
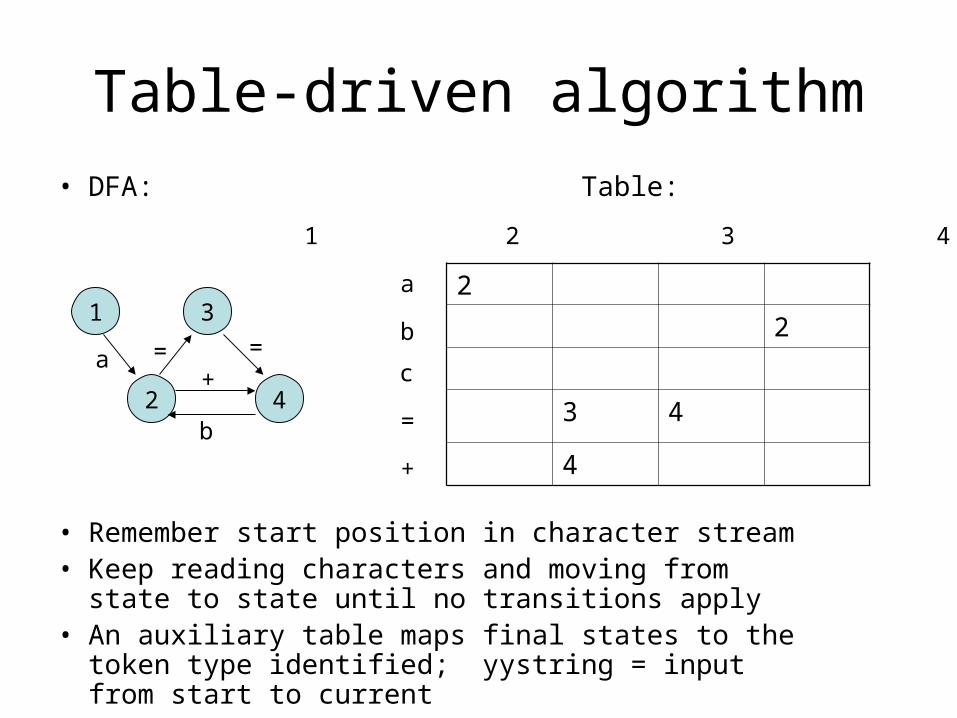
Table-driven algorithm
• DFA: Table:
• Remember start position in character stream• Keep reading characters and moving from state to
state until no transitions apply• An auxiliary table maps final states to the token
type identified; yystring = input from start to current
1 3
2 4
a
b
+= =
2
2
3 4
4
1 2 3 4
a
b
c
=
+

• DFA:
• Detail: how to deal with longest match?– when reading “iffy” should recognize “iffy” as
ID, not “if” as keyword and then “fy” as ID
a-z
Table-driven algorithm
1 2
a-z

• DFA:
• Detail: how to deal with longest match?– save most recent final state seen and
position in character string– when no more transition can be made, revert
to last saved legal final state– see Appel 2.4 for more details
a-z
Table-driven algorithm
1 2
a-z

Summary
• A Lexer:– input: stream of characters– output: stream of tokens
• Writing lexers by hand is boring, so we use a lexer generator: ml-lex– lexer generators work by converting REs
through automata theory to efficient table-driven algorithms.
– theory wins again.


















