
Copyright 2003 limsoon wong Recognition of Protein Features Limsoon Wong Institute for Infocomm...
82
Copyright 2003 limsoon wong Recognition of Protein Features Limsoon Wong Institute for Infocomm Research BI6103 guest lecture on ?? March 2004
-
Upload
warren-pitts -
Category
Documents
-
view
218 -
download
1
Transcript of Copyright 2003 limsoon wong Recognition of Protein Features Limsoon Wong Institute for Infocomm...

Copyright 2003 limsoon wong
Recognition of Protein Features
Limsoon Wong
Institute for Infocomm ResearchBI6103 guest lecture on ?? March 2004

Copyright 2003 limsoon wong
Lecture Plan
• Membrane proteins
• Subcellular localization

Copyright 2003 limsoon wong
Recognition of Transmembrane Helices

Copyright 2003 limsoon wong
Eukaryotic Cells
• Eukaryotic cells have membrane-bound compartments with specialized functions

Copyright 2003 limsoon wong
Lipids & Membrane
• Membrane is a double layer of lipids and associated proteins which define subcellular compartments or enclose the cell
• Lipids consist of a “polar head group” and long-chain fatty acids• This dual nature promotes formation of lipid bilayers
• “Hydrophobic tails” are shielded from aqueous environment
• Water-soluble (i.e., charged or polar) molecules cant pass through this impermeable barrier
• Permeability across the bilayer is regulated by membrane proteins that span the bilayer and function like channels or pores

Copyright 2003 limsoon wong
all- -barrel
Membrane Proteins
• Two types of membrane proteins: Integral vs peripheral
• Two types of integral membrane proteins: all- vs -barrel

Copyright 2003 limsoon wong
Topography & Topology
• topography: predict location of transmembrane segment
• topology: predict location of N- and C-termini wrt lipid bilayer
• We focus on topography prediction for all- membrane proteins
Lipid molecules

Copyright 2003 limsoon wong
Datasets
• Jayasinghe et al. Protein Sci, 10:455-458, 2001– 59 high resolution membrane proteins– www.biocomp.unibo.it/gigi/ENSEMBLE
• Moller et al. Bioinformatics, 16:1159--1160, 2000– 151 low resolution membrane proteins
• Jones et al., Biochem., 33(10):3038--3049, 1994– 38 multi-spanning and 45 single-spanning membrane proteins– topologies experimentally determined
• Sonnhammer et al., ISMB, 6:175-182, 1998– 108 multi-spanning and 52 single-spanning membrane proteins
– most of experimentally determined topologies, but less reliably determined than Jones et al.

Copyright 2003 limsoon wong
Monne et al., JMB, 288:141--145, 1999:
Turn Propensity Scale for TM Helices
• E. coli Lep protein contains two TM domains (H1, H2) and C-terminal doman P2
• Translocation of P2 to lumenal side is easy to test by glycoslation
• Replace H2 by 40 residue poly-L segment LIK4L21XL7VL10Q3P
• The poly-L segment can form either one long TM or 2 closely-spaced TM helices, depending on what is substituted for X
ER

Copyright 2003 limsoon wong
Monne et al., JMB, 288:141--145, 1999:
Turn Propensity Scale for TM Helices
• Using the poly-L segment, measure “turn” propensity of the 20 amino acids by substituting them for the X in the poly-L segment
• Hydrophobic residues (I, V, L, F, C, M, A) do not induce turn
• Charged and polar residues (except S & T) induce turn
• Exercise:– What are the charged/polar
residues?
– What could be reason of S & T not inducing turn?
glycoslated
non-glycoslated

Copyright 2003 limsoon wong
Monne et al., JMB, 288:141--145, 1999
• In all- membrane proteins, – hydrophobic residues
prefer membrane env and have low turn propensity
– charged & polar residues induce turn formation to avoid membrane interior
prediction of TM helix distinction of 1 long TM
helix vs 2 closely spaced TM helices
Monne et al., JMB, 288:141--145, 1999:
Turn Propensity Scale for TM Helices

Copyright 2003 limsoon wong
Monne et al., JMB, 288:141--145, 1999
• Inside of cellular membrane is hydrophobic
• Segment of protein that spans membrane is expected to contain many hydrophobic amino acids
Locate segments that have high average “hydrophobicity” score
Wiess et al, ISMB, 1:420--421, 1993 Hydrophobicity Approach

Copyright 2003 limsoon wong
Wiess et al, ISMB, 1:420--421, 1993 Hydrophobicity Approach
• find a segment of 10 to 70aa with hp > 0.71
• expand to longer segment with hp > 0.35
• mark this segment as TM
• repeat above starting from position after previous segment
• Caveats:– may be unable to
distinguish hydrophobic core of nonmembrane proteins vs. transmembrane regions
– what are the right thresholds?
Adjustable thresholds

Copyright 2003 limsoon wong
An Example: Bacteriorhodopsin
http://www.ncbi.nlm.nih.gov/entrez/query.fcgi?cmd=Retrieve&db=protein&list_uids=461610&dopt=GenPept&term=bacteriorhodopsin&qty=1
1 gigtllmlig tfyfiargwg vtdkkareyy aitilvpgia saaylsmffg iglttvevag 61 maepleiyya ryadwlfttp lllldlalla nadrttigtl igvdalmivt gligalshtp
121 larytwwlfs tiaflfvlyy lltvlrsaaa elsedvqttf ntltalvavl wtaypilwii
181 gtegagvvgl gvetlafmvl dvta
7 transmembrane helices

Copyright 2003 limsoon wong
An Example: Bacteriorhodopsin
1 gigtllmlig tfyfiargwg vtdkkareyy aitilvpgia saaylsmffg iglttvevag 61 maepleiyya ryadwlfttp lllldlalla nadrttigtl igvdalmivt gligalshtp
121 larytwwlfs tiaflfvlyy lltvlrsaaa elsedvqttf ntltalvavl wtaypilwii
181 gtegagvvgl gvetlafmvl dvta
• After applying hydrophobicity scale...

Copyright 2003 limsoon wong
An Example: Bacteriorhodopsin
• Compute hydrophobicity score, hp > 7
1 gigtllmlig tfyfiargwg vtdkkareyy aitilvpgia saaylsmffg iglttvevag 61 maepleiyya ryadwlfttp lllldlalla nadrttigtl igvdalmivt gligalshtp
121 larytwwlfs tiaflfvlyy lltvlrsaaa elsedvqttf ntltalvavl wtaypilwii
181 gtegagvvgl gvetlafmvl dvta
TM identified: 6/7, TM FP: 0TM residue identified: 62/117, TM residue FP: 4

Copyright 2003 limsoon wong
An Example: Bacteriorhodopsin
• Expand segment, maintain hp > 5, avoid low hydrophobicity
1 gigtllmlig tfyfiargwg vtdkkareyy aitilvpgia saaylsmffg iglttvevag 61 maepleiyya ryadwlfttp lllldlalla nadrttigtl igvdalmivt gligalshtp
121 larytwwlfs tiaflfvlyy lltvlrsaaa elsedvqttf ntltalvavl wtaypilwii
181 gtegagvvgl gvetlafmvl dvta
TM identified: 6/7, TM FP: 0TM residue identified: 100/117, TM residue FP:15

Copyright 2003 limsoon wong
Sonnhammer et al., ISMB, 6:175-182, 1998:
TMHMM, A HMM Approach
• There are 3 main locations of a residue:– TM helix core (viz., in hydrophobic tail of membrane– TM helix cap (viz., in head of membrane)
• cytoplasmic vs • non-cytoplasmic side of the helix core
– loops• cytoplasimc vs • non-cytoplasmic (short) vs • non-cytoplasmic (long)
So needs HMM with 7 states• Exercise: What is the 7th state for?
cyto
non-cyto
Copyright 2003 limsoon wong
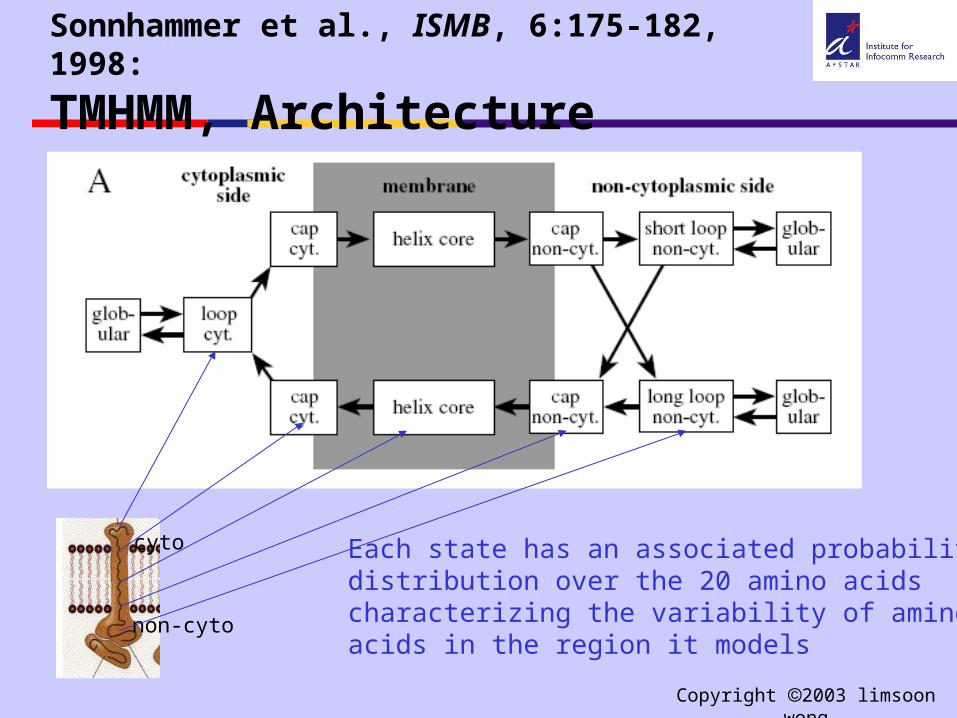
Sonnhammer et al., ISMB, 6:175-182, 1998:
TMHMM, Architecture
cyto
non-cyto
Each state has an associated probabilitydistribution over the 20 amino acids characterizing the variability of amino acids in the region it models

Copyright 2003 limsoon wong
Sonnhammer et al., ISMB, 6:175-182, 1998:
TMHMM, Architecture
• The first 3 and last 2 core states have to be traversed. But all other core states can be bypassed.
• This models core regions of 5--25 residues

Copyright 2003 limsoon wong
Sonnhammer et al., ISMB, 6:175-182, 1998:
TMHMM, Architecture
• The states of globular, loop, & cap regions. • The caps are 5 residues each. Since core is 5--25
residues, this allows for helices 15--35 residues long
To model bias in amino acid usage near cap
To model neutral aminoacid distribution

Copyright 2003 limsoon wong
Sonnhammer et al., ISMB, 6:175-182, 1998:
TMHMM, Training the HMM• Stage 1: Baum-Welch is used for maximum likelihood estimation from
“diluted” labeled training data. As precise end of TM is only approximately known, we “dilute” by unlabeling 3 residues on each side of a helix boundary to accommodate this
• Stage 2: Baum-Welch is used for maximum likelihood estimation from
“relabeled” training data. The original training data are diluted as by unlabeling 5 residues on each side of a helix boundary. Model from Stage 1 is used to produce “relabeled training data” by relabeling this part under constraints of remaining labels
• Stage 3: Model from Stage 2 is further tuned by a method for “discriminative” training, to maximize probability of correct prediction (Krogh, ISMB, 5:179--186, 1997)

Copyright 2003 limsoon wong
Krogh, ISMB, 5:179--186, 1997:
Discriminative HMM Training

Copyright 2003 limsoon wong
Sonnhammer et al., ISMB, 6:175-182, 1998:
TMHMM, Example
Non-cytoplasmic Cytoplasmic TM segment
Datasets• Jones et al., Biochem., 33(10):3038--3049, 1994• Sonnhammer et al., ISMB, 6:175-182, 1998
Copyright 2003 limsoon wong
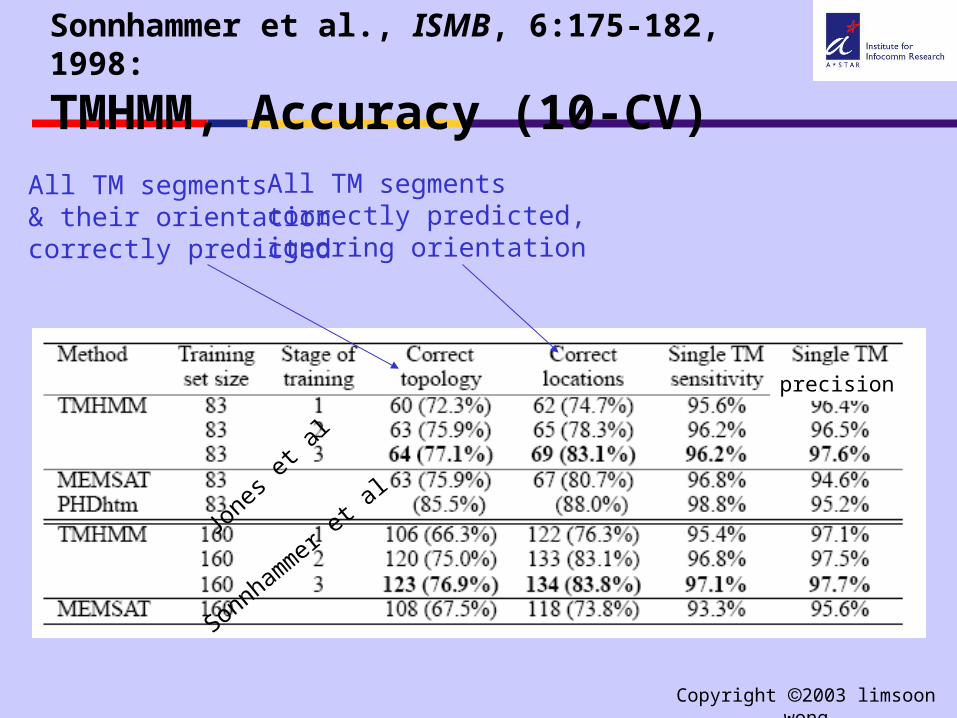
Sonnhammer et al., ISMB, 6:175-182, 1998:
TMHMM, Accuracy (10-CV)
All TM segments& their orientationcorrectly predicted
All TM segmentscorrectly predicted,ignoring orientation
precision
Jone
s et a
l
Sonnhammer
et al

Copyright 2003 limsoon wong
NN HMM1 HMM2
ENSEMBLE
Martelli et al. Bioinformatics, 19:i205--i211, 2003
ENSEMBLE

Copyright 2003 limsoon wong
ENSEMBLE:
The Neural Network Part
• The NN part is a cascade shown above, a la Rost et al., Protein Science, 1995
h1
h2
h5
HMM
LOOP
Inputlayer17*2inputs
1
17
15 hiddenunits
17 * 20input units
Feed-forwardback-propagationneural network

Copyright 2003 limsoon wong
ENSEMBLE:
The HMM1 Part
• HMM1 models the hydrophobic nature of most TM helices, a la Krogh et al. JMB 2001 & Sonnhammer et al., ISMB 1998

Copyright 2003 limsoon wong
ENSEMBLE:
The HMM2 Part
• HMM2 models TM helices that are mix of hydrophobic and hydrophilic residues, ala Martelli et al., Bioinformatics 2002.

Copyright 2003 limsoon wong
NN HMM1 HMM2
ENSEMBLE
ENSEMBLE:
Predicting if a residue is in TM
NN(p,i) = NN(H,p,i) NN(L,p,i) HMM1(p,i) = AP1(H,p,i) AP1(I,p,i) AP1(O,p,i)
HMM2(p,i) = AP2(H,p,i) AP2(I,p,i) AP2(O,p,i)
• E(p,i) = (NN(p,i) + HMM1(p,i) + HMM2(p,i)) / 3
position
helix
loop (inner I, outer O)
E(p,i) > 0 means residue i of protein p is in TM helix

Copyright 2003 limsoon wong
Ensemble: Topography PredictionFariselli et al., Bioinformatics, 2003
NN HMM1 HMM2
ENSEMBLE MaxSubSeq
TM helix found by MaxSubSeq butwould be missed w/o it
This path istaken means positions m to j form a helix
Copyright 2003 limsoon wong
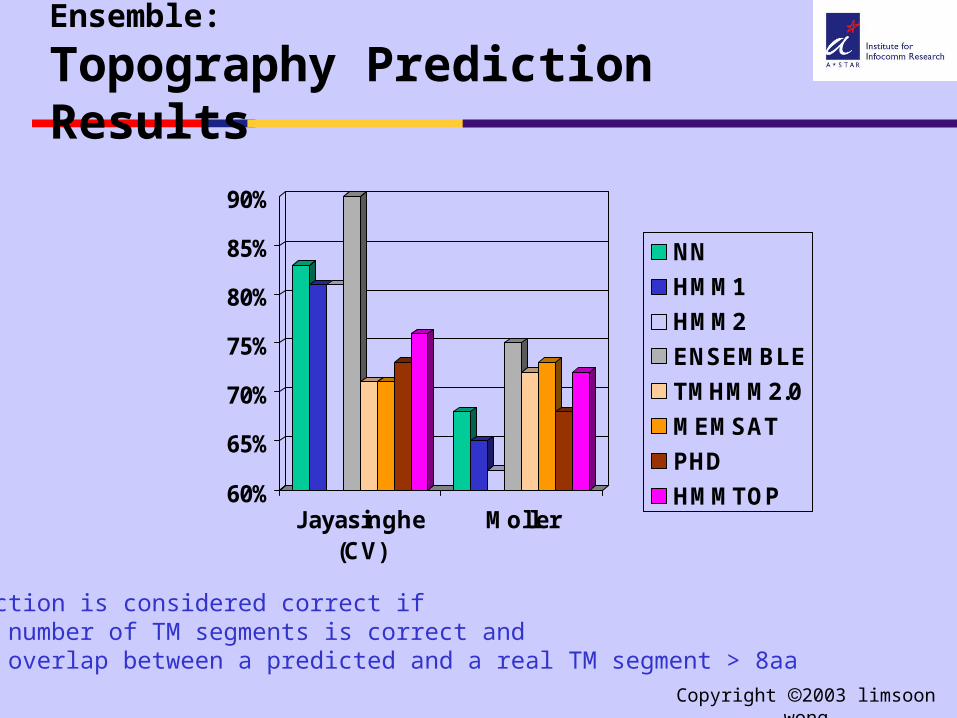
Ensemble:
Topography Prediction Results
60%
65%
70%
75%
80%
85%
90%
Jayasinghe(CV)
Moller
NN
HMM1
HMM2
ENSEMBLE
TMHMM2.0
MEMSAT
PHD
HMMTOP
A prediction is considered correct if (a) the number of TM segments is correct and(b) the overlap between a predicted and a real TM segment > 8aa

Copyright 2003 limsoon wong
Topology Prediction: Postive-Inside RuleGavel et al., FEBS, 282:41--46, 1991
• Positively-charged residues (Lys and Arg) are enriched more than 2 fold in stromal vs luminal loops

Copyright 2003 limsoon wong
Topology Prediction:
Ensemble
“positive-inside” rule

Copyright 2003 limsoon wong
Ensemble:
Topology Prediction Results
40%
45%
50%
55%
60%
65%
70%
75%
80%
Jayasinghe(CV)
Moller
ENSEMBLE(rule 4)
TMHMM2.0
MEMSAT
PHD
HMMTOP
ENSEMBLE(rule 1)

Copyright 2003 limsoon wong
Short Break

Copyright 2003 limsoon wong
Subcellular Localization

Copyright 2003 limsoon wong
Compartments and Sorting
• Eukaryotic cells requires proteins be targeted to their subcellular destinations
• Protein sorting is determined by specific amino acid sequences, or “signals”, within the protein
• Secretory pathway targets proteins to plasma membrane, some membrane-bound organelles such as lysosomes, or to export proteins from the cell

Copyright 2003 limsoon wong
Secretory Pathway
• The secretory pathway consists of the endoplasmic reticulum (ER), Golgi apparatus and transport vesicles
• The transport vesicles carry proteins from one compartment to the other
• Exocytosis is mediated by fusion of secretory vesicles with the plasma membrane.
• Endocytosis is the opposite of exocytosis and involves the uptake of extracellular material by pinching off vesicles from the plasma membrane
• The contents of the endocytic vesicles are delivered to the lysosomes by membrane fusion
• Lysosomes contain hydrolytic enzymes that breakdown macromolecules into the smaller subunits which can be utilized by the cell for its own biosynthesis

Copyright 2003 limsoon wong
Datasets
• Reinhartdt & Hubbard, NAR, 26:2230--2236, 1998– 2427 eukaryotic proteins for 4 locations (cytoplasmic, extracellular, nuclear,&
mitochondrial)
– 997 prokaryotic proteins for 3 locations (cytoplasmic, extracellular, & periplasmic)
• Park & Kanehisa, Bioinformatics, 19:1656--1663, 2003– 7589 eukaryotic proteins from 709 organisms for 12 locations
(chloroplast, cytoplasmic, cytoskeleton, ER, extracellular, golgi, lysosomal, mitochondrial, nuclear, peroxisomal, plasma membrane, vacuolar)
• Chou & Cai, JBC., 277:45765--45769, 2002– 2191 proteins for 12 locations
• Emanuelsson et al., JMB, 300:1005--1016, 2000
• Gardy et al., NAR, 31:3613--3617, 2003

Copyright 2003 limsoon wong
Common Eukaryotic Protein Sorting Signals
For a comprehensive list of cellular localization sites, see
http://mendel.imp.univie.ac.at/CELL_LOC/index.html

Copyright 2003 limsoon wong
Schematic View of SortingSignals
cleavage site
~25aa

Copyright 2003 limsoon wong
Sequence Logos ofSP, mTP, & cTP
SPsignal peptide
mTPmitochondrial
transfer peptide
cTPchloroplast
transit peptide

Copyright 2003 limsoon wong
Neural Network Approach: TargetPEmanuelsson et al., JMB, 300:1005--1016, 2000
• cTP, mTP, SP– 4 hidden units– feedforward NNs– input windows:
• 55aa (cTP), 35aa (mTP), 27aa (SP)
• sparsely encoded
• Integrating Network– 0 hidden unit– feedforward NN– input is taken from the
outputs of cTP, mTP, SP networks over 100aa at N-terminal
cTP: chloroplast transit peptide, mTP: mitochondria transfer peptide, SP: signal peptide

Copyright 2003 limsoon wong
TargetP:
Performance
Dataset: Emanuelsson et al., JMB, 2000

Copyright 2003 limsoon wong
Expert System Approach: PSORT Horton & Nakai, ISMB, 1997
A simplified version of the decision tree thatPSORT uses tocheck and reasonover various sorting signals

Copyright 2003 limsoon wong
A Refinement: PSORT-BGardy et al., NAR, 31:3613--3617, 2003
SCL-BLAST
Motifs HMMTOPOuter
MembraneProtein
SubLocCSignal
Peptides
BayesianNetwork
Localization sitesor “unknown”
• Sites considered– cytoplasm– inner membrane– periplasm– outer membrane– extracellular space

Copyright 2003 limsoon wong
PSORT-B:
SCL-BLAST
• Homology to a protein of known localization is good indicator of a protein’s actual localization site
BLAST target protein against a database of proteins whose localization sites are known
Return localization sites of hits at E-value of 10e-10
over 80% of length

Copyright 2003 limsoon wong
PSORT-B:
Motifs
• Some motifs in PROSITE may be able to identify subcellular localization with 100% precision
Scan target protein against a database of such motifs (28 such 100%-precision motifs are known)
Return localization sites corresponding to the motif hits

Copyright 2003 limsoon wong
PSORT-B:
HMMTOP
-helical transmembrane region is reliable indicator of localization to inner membrane
Scan target protein for transmembrane helices using HMMTOP
Return localization site as “inner membrane” if >2 helices found

Copyright 2003 limsoon wong
PSORT-B:
Outer Membrane Proteins
• Outer-membrane proteins have characteristics -barrel structure
Identify freq seq occurring only in -barrel proteins (279 such freq seq known)
Scan target protein for these freq seq
Return localization site as “outer membrane” if >2 such freq seq found

Copyright 2003 limsoon wong
PSORT-B:
SubLocC
• Overall amino acid composition is useful for recognizing cytoplasmic proteins
Trained SVM on overall amino acid composition to predict cytoplasmic vs non-cytoplasmic, as in SubLoc
Analyze target protein’s amino acid composition using this SVM

Copyright 2003 limsoon wong
PSORT-B:
Signal Peptides• Presence of signal peptide at N-
terminal means protein not cytoplasmic
Train HMM and SVM to recognize signal peptides and their cleavage sites
If high-confidence cleavage site found by HMM in first 70aa of target protein, then “non-cytoplasmic”
If low-confidence cleavage site found, pass candidate signal peptide to SVM to confirm
If confirmed, then “non-cytoplasmic” Otherwise, “unknown”
Copyright 2003 limsoon wong
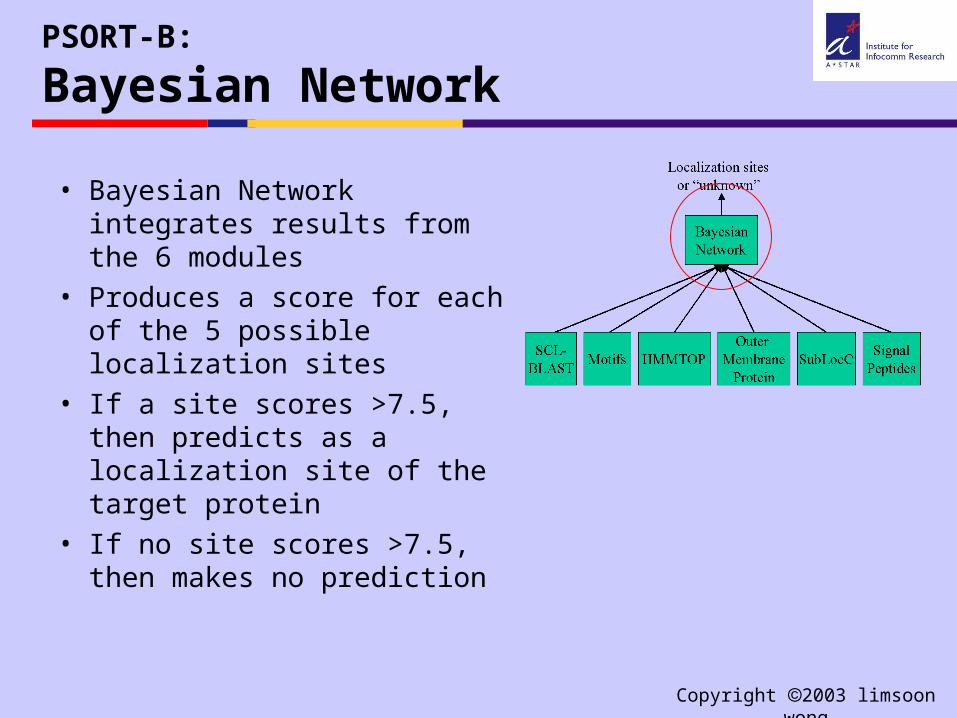
PSORT-B:
Bayesian Network
• Bayesian Network integrates results from the 6 modules
• Produces a score for each of the 5 possible localization sites
• If a site scores >7.5, then predicts as a localization site of the target protein
• If no site scores >7.5, then makes no prediction

Copyright 2003 limsoon wong
PSORT-B:
Performance of Individual Modules
Dataset: Gardy et al., NAR, 2003

Copyright 2003 limsoon wong
PSORT-B:
Performance wrt Localization Sites
PSORT-B is a considerable improvement over original PSORT
Dataset: Gardy et al., NAR, 2003

Copyright 2003 limsoon wong
PSORT vs PSORT-B:
Some Remarks
• PSORT considers various signal/features in a top-down way driven by its reasoning tree
• PSORT-B generates all signal/features in a bottom-up way, then integrate them for decision making using Bayesian Network
• Machine learning “beats” human expert? Probably the number of features/rules needed is too much/complicated

Copyright 2003 limsoon wong
Amino acid composition of proteins residing in different sites are different

Copyright 2003 limsoon wong
Amino Acid Composition Differences
• each cellular location has own characteristic physio-chemical environment
• proteins in each location have adapted thru evolution to that environment
• thus reflected in the protein structure and amino acid composition
• If the above is true, the amino acid composition differences wrt cellular location sites should be more pronounced on protein surfaces than protein interior
• Exercise: Why?

Copyright 2003 limsoon wong
Adaptation of Protein SurfacesAndrade et al., JMB, 1998
Proportion ofjth amino acid type in ith protein
• To test the theory of adaptation of protein surfaces to subcellular localization, we do a plot of 3 types of composition vectors along their first two principal components

Copyright 2003 limsoon wong
Adaptation of Protein Surfaces Andrade et al., JMB, 1998
Total amino acidcomposition vector
Surface amino acidcomposition vector
Interior amino acidcomposition vector
• Clearly total & surface composition vectors show better separation than interior composition vectors

Copyright 2003 limsoon wong
Amino Acid Composition
• This means can use amino acid composition vectors, especially those from protein surfaces, to predict subcellular localization!
• Let’s see how this turn out….

Copyright 2003 limsoon wong
Neural Networks: NNPSLReinhardt & Hubbard, NAR, 26:2230--2236, 1998
Input1
Input20
cytoplasmic
extracellular
mitochodrial
nuclear
fraction of each aminoacid in the input protein

Copyright 2003 limsoon wong
NNPSL:
Performance
• Outputs NNPSL have values 0 to 1. The difference () between the highest and the next highest nodes can be used as a reliability index
0 < < 0.2
0.2 < < 0.4
0.4 < < 0.6
0.6 < < 0.8
0.8 < < 1
Dataset: Reinhardt & Hubbard,NAR, 1998

Copyright 2003 limsoon wong
Performance Emanuelsson, BIB, 3:361--376, 2002
(940 proteins)
(2738 proteins)
Dataset: Emanuelsson et al., JMB, 2000

Copyright 2003 limsoon wong
Markov ChainYuan, FEBS Letters, 451:23--26, 1999
Why?

Copyright 2003 limsoon wong
Markov Chain:
Performance
NNPSL 4th Order Markov(Eukaryotic)
Dataset: Reinhardt & Hubbard,NAR, 1998

Copyright 2003 limsoon wong
Support Vector Machines: SubLocHua & Sun, Bioinformatics, 17:721--728, 2001
extracellularvs rest
nuclearvs rest
cytoplasmicvs rest
mitochondrialvs rest
ArgmaxX X-vs-rest
SVM
SVM
SVM
SVMThe SVMs use • polynomial kernel with d = 9 (prokaryotic),
K(Xi,Xj) = (Xi ·Xj + 1)d
• RBF kernel with =16 (eukaryotic),K(Xi, Xj) = exp(- |Xi - Xj|2
20-dimensional vector giving amino
acid composition of the input protein

Copyright 2003 limsoon wong
SubLoc:
Performance
NNPSL SubLoc
(Eukaryotic)
Dataset: Reinhardt & Hubbard, NAR, 1998
Copyright 2003 limsoon wong
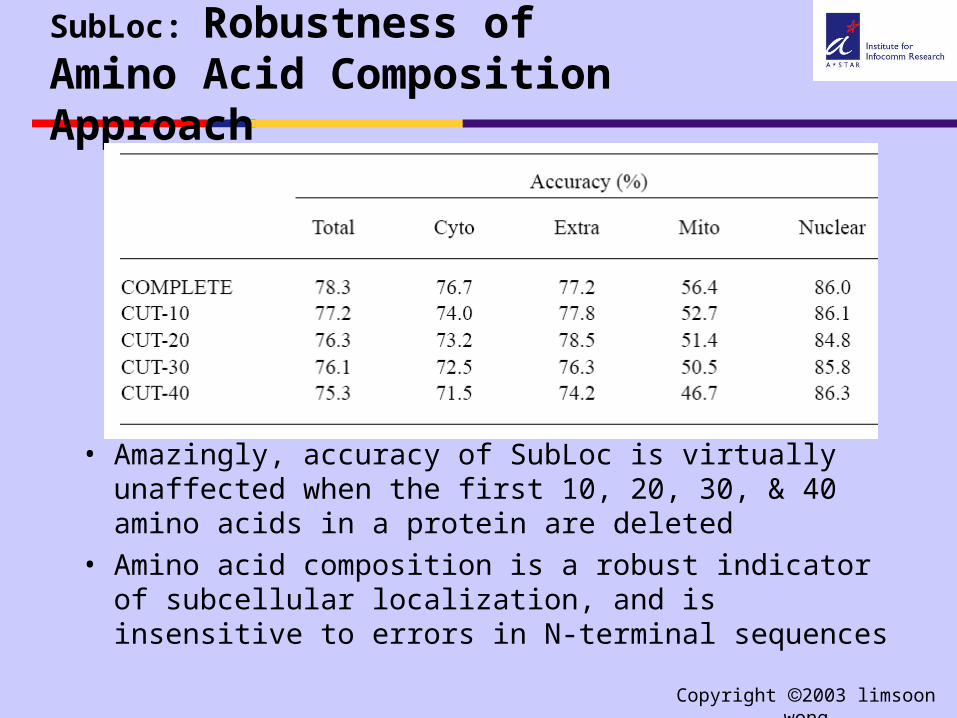
SubLoc: Robustness of Amino Acid Composition Approach
• Amazingly, accuracy of SubLoc is virtually unaffected when the first 10, 20, 30, & 40 amino acids in a protein are deleted
• Amino acid composition is a robust indicator of subcellular localization, and is insensitive to errors in N-terminal sequences

Copyright 2003 limsoon wong
Amino Acid Composition:Taking it Further
• How about pairs of consecutive amino acids? (a.k.a 2-grams) How about 3-grams, …, k-grams?
• How about pseudo amino acid composition?
• How about presence of entire functional domains? (I.e. think of the presence/absence of a functional domain as a summary of amino acid sequence info...)

Copyright 2003 limsoon wong
Functional Domain CompositionChou & Cai, JBC, 277:45765--45769, 2002
Training seqs of various localizationsites
BLAST againstdb of known functional domains(SBASE-A)
aminoacid
composition+
Train SVM using these vectors
xi = 1 means ith domain is present

Copyright 2003 limsoon wong
Functional Domain Composition:
Performance
• Not so good• Why? Number of known domains in SBASE-A too small Need to handle situation where a protein has no
hit in known domains
Dataset: Reinhardt & Hubbard, NAR, 1998

Copyright 2003 limsoon wong
Functional Domain CompositionCai & Chou, BBRC, 305:407--411, 2003
Training seqs of various localizationsites
BLAST againstdb of known functional domains(Interpro)
NN-5875D:Train k-NN (k=1) using these vectors
or, if nohit found
Pseudo aminoacid composition
Aminoacidcomposition
NN-40D:Train k-NN (k=1) using these vectors
If a protein got a hit in Interpro,use NN-5875D; else use NN-40D

Copyright 2003 limsoon wong
Functional Domain Composition:
Performance
Dataset: Reinhardt & Hubbard, NAR, 1998
Copyright 2003 limsoon wong
Notes

Copyright 2003 limsoon wong
References (Transmembrane)
• Wiess et al. “Transmembrane segment prediction from protein sequence data”, ISMB, 420--421, 1993
• Gavel et al. “The positive-inside rule applies to thylakoid membrane proteins”, FEBS 282:41--46, 1991
• Monne et al. “A turn propensity scale for transmembrane helices”, JMB, 288:141--145, 1999
• Sonnhammer et al. “A hidden Markov model for predicting transmembrane helices in protein sequences”, ISMB, 6:175--182, 1998
• Martelli et al. “An ENSEMBLE machine learning approach for the prediction of all-alpha membrane proteins”, Bioinformatics, 19(suppl):i205--i211, 2003

Copyright 2003 limsoon wong
References (Transmembrane)
• Von Heijne. “Membrane protein structure prediction”, JMB, 225: 487--494, 1992
• Jacoboni et al. “Prediction of the transmembrane regions of beta-barrel membrane proteins with a neural network-based predictor”, Protein Sci., 10:779--787, 2001
• Martelli et al. “a sequence-profile-based HMM for predicting and discriminating beta barrel membrane proteins”, Bioinformatics, 18:S46--S53, 2002
• Moller et al. “Evaluation of methods for the prediction of membrane spanning regions”, Bioinformatics, 17:646--653, 2001
• Fariselli et al. “MaxSubSeq: an algorithm for segment-length optimization. The case study of the transmembrane spanning segments”, Bioinformatics, 19:500--505, 2003

Copyright 2003 limsoon wong
References (Transmembrane)
• Rost et al. “Transmembrane helices predicted at 95% accuracy”, Protein Sci., 4:521--533, 1995
• Krogh et al. “Predicting transmembrane protein topology with a hidden Markov model: Application to complete genomes”, JMB, 305:567--580, 2001
• Andersson et al. “Different positively charged amino acids have similar effectson the topology of a polytopic transmembrane protein in E. coli”, JBC, 267:1491--1495, 1992

Copyright 2003 limsoon wong
References (Subcellular Localization)
• Horton & Nakai, “Better prediction of protein cellular localization sites with the k-nearest neighbours classifier”, ISMB, 5:147--152, 1997
• Gardy et al., “PSORT-B: Improving protein subcellular localization for Gram-negative bacteria”, NAR, 31:3613--3617, 2003
• Emanuelsson, “Predicting protein subcellular localization from amino acid sequence information”, BIB, 3:361--376, 2002
• Andrade et al., “Adaptation of protein surfaces to subcellular location”, JMB, 276:517--525, 1998
• Yuan, “Prediction of protein subcellular locations using Markov chain models”, FEBS Letters, 451:23--26, 1999

Copyright 2003 limsoon wong
References (Subcellular Localization)
• Emanuelsson et al., “ChloroP, a neural network-based method for predicting chloroplast transit peptides and their cleavage sites”, Protein Sci., 8:978--984, 1999
• Emanuelsson et al., "Predicting subcellular localization of proteins based on their N-terminal amino acid sequence", JMB, 300:1005-1016, 2000
• Hua & Sun, “Support vector machine approach for protein subcellular localization prediction”, Bioinformatics, 17:721--728, 2001
• Reinhardt & Hubbard, “Using neural networks for prediction of the subcellular location of proteins”, NAR, 26:2230--2236, 1998

Copyright 2003 limsoon wong
References (Subcellular Localization)
• Cai & Chou, “Nearest neighbour algorithm for predicting protein subcellular location by combining functional domain composition and pseudo-amino acid composition”, BBRC, 305:407--411, 2003
• Chou & Cai, “Using functional domain composition and support vector machines for prediction of protein subcellular location”, JBC, 277:45765--45769, 2002
• Park & Kanehisa, “Prediction of protein subcellular locations by support vector machines using compositions of amino acids and amino acid pairs”, Bioinformatics, 19:1656--1663, 2003


















