
Computer Science 12 Design Automation for Embedded Systems Reconciling Compilers & Timing Analysis...
77
Computer Science 12 Design Automation for Embedded Systems Reconciling Compilers & Timing Reconciling Compilers & Timing Analysis Analysis for Safety-Critical Real-Time for Safety-Critical Real-Time Systems Systems – – WCET-aware program optimizations WCET-aware program optimizations Heiko Falk Embedded Systems/Real-Time Systems Ulm University, Germany Jan C. Kleinsorge Computer Science 12 TU Dortmund, Germany
-
Upload
beverly-hunt -
Category
Documents
-
view
229 -
download
2
Transcript of Computer Science 12 Design Automation for Embedded Systems Reconciling Compilers & Timing Analysis...

Computer Science 12Design Automation for Embedded Systems
Reconciling Compilers & Timing AnalysisReconciling Compilers & Timing Analysis
for Safety-Critical Real-Time Systemsfor Safety-Critical Real-Time Systems
– –
WCET-aware program optimizationsWCET-aware program optimizations
Heiko Falk
Embedded Systems/Real-Time Systems
Ulm University, Germany
Jan C. Kleinsorge
Computer Science 12
TU Dortmund, Germany

Slide 2 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
OutlineOutline
WCET-aware Optimizations and Code Quality
Graph Coloring Register Allocation
Scratchpad Memory Allocation
Cache-aware Memory Content Selection
Cache Partitioning for Multi-task Real-time Systems
Combination of Scratchpad Allocation, Memory Content Selection and Cache Partitioning

Slide 3 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
WCET-aware Optimizations and Code QualityWCET-aware Optimizations and Code Quality
WCET as objective function Actual speed-up but also by enhancing analyzability Side-effects of changes on timing hard to anticipate Issuing just a single instruction can lead to uncertainty regarding:
Location, alignment, access pattern (cache), schedule (pipeline), branch prediction, etc.
Code quality for WCET-aware optimizations Avoid dynamic dispatch, excessive inflation and layout changes
without being clear about its effects In short: maintain predictability first

Slide 4 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
WCET-aware Optimizations and Systems (1)WCET-aware Optimizations and Systems (1)
Semantics:
Computation
Layout
Pipeline
System
Ab
stra
ction
Open parameters:
+ Ideally: just program input
+ Location: accesses to busses, memories
+ Order, registers
+ DependenciesExpressionsExpressions
Insn (virt.)Insn (virt.)
Insn (phys.)Insn (phys.)
““BLOB”BLOB”

Slide 5 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
WCET-aware Optimizations and Systems (2)WCET-aware Optimizations and Systems (2)Practical heuristics to pick the right level of abstraction: Still on WCEP? Will decision change WCEP? Are side-effects possible and (in how far) are they bounded? What's the overall impact on the system? How often do we need to re-evaluate intermediate solutions?
Uncertainty that cannot be tackled at any level: Speculative execution, cache hierarchies (and replacement
policies), timing anomalies in general, general I/O, etc. However: Trend towards (many) simpler cores in fact improves
situation as far as per-task predictability is concerned

Slide 6 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
OutlineOutline
WCET-aware Optimizations and Code Quality
Graph Coloring Register Allocation
Scratchpad Memory Allocation
Cache-aware Memory Content Selection
Cache Partitioning for Multi-task Real-time Systems
Combination of Scratchpad Allocation, Memory Content Selection and Cache Partitioning
Slide 7 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
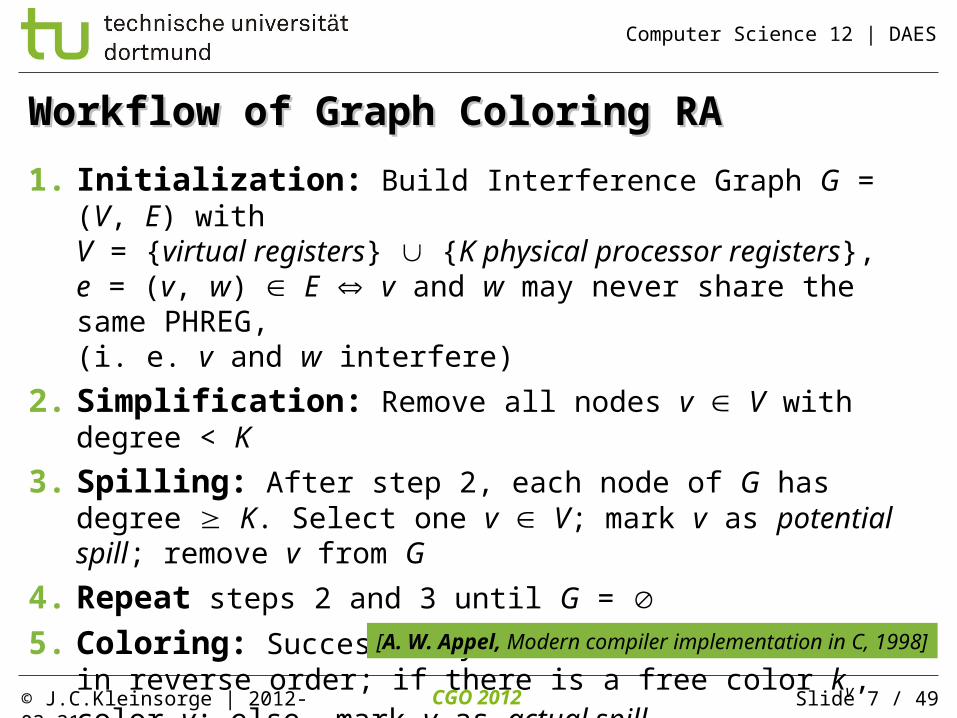
Workflow of Graph Coloring RAWorkflow of Graph Coloring RA
1. Initialization: Build Interference Graph G = (V, E) withV = {virtual registers} {K physical processor registers},e = (v, w) E v and w may never share the same PHREG, (i. e. v and w interfere)
2. Simplification: Remove all nodes v V with degree < K
3. Spilling: After step 2, each node of G has degree K. Select one v V; mark v as potential spill; remove v from G
4. Repeat steps 2 and 3 until G =
5. Coloring: Successively re-insert nodes v into G in reverse order; if there is a free color kv, color v; else, mark v as actual spill
[A. W. Appel, Modern compiler implementation in C, 1998]

Slide 8 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
Problem of Standard Graph ColoringProblem of Standard Graph Coloring
3. Spilling: After step 2, each node of G has degree K. Select one v ∊ V; mark v as potential spill; remove v from G
Which node v should be selected as potential spill?
Common graph coloring implementations select … … the first node v according to the order in which VREGs
were generated during code selection, ... the node with highest degree in the interference graph, ... a node with high degree, with many DEFs/USEs, in
some inner loop – maybe depending on profiling data.
Uncontrolled spill code generation – potentially alongWorst-Case Execution Path (WCEP) defining the WCET!

Slide 9 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
WCET-aware Register Allocation WCET-aware Register Allocation
Derived from classic Chaitin graph coloring Registers allocation as a problem from the „tip“ of the memory
hierarchy Besides runtime overhead, spill-code affects:
Instruction count, schedule, memory layout, cache access and pattern, etc.
WCET-aware optimization must take into account: Where to store data (actual allocation decision)? But also: Where to store (spill) instruction (relative to WCEP)?
The catch: …relies on WCET data provided by WCET analysis using aiT ...can’t obtain WCET data since code contains virtual registers

Slide 10 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
WCET-aware RA: of Chickens and Eggs WCET-aware RA: of Chickens and Eggs
Pessimistic register allocation: Start by marking all VREGs as actual
spill (each VREG is spilled. Now code is fully analyzable)
Perform WCET analysis, get WCEP Allocate VREGs of basic block b with
most worst-case spill code executions to PHREGs using standard GC on original program
Re-evaluate novel WCEP Stop and allocate rest if no more
VREGS on WCEP

Slide 11 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
Results – Worst-Case Execution TimesResults – Worst-Case Execution Times
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
110%
Re
lati
ve
WC
ET
ES
T [
%]
(Op
tim
iza
tio
n L
ev
el -
O3
)
100% = WCETEST using Standard Graph Coloring (highest degree)
93%
24%
69%

Slide 12 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
Results – Average-Case Execution TimesResults – Average-Case Execution Times
0%
10%
20%
30%
40%
50%
60%
70%
80%
90%
100%
110%
120%
Re
lati
ve
AC
ET
[%
](O
pti
miz
ati
on
Le
ve
l -O
3)
100% = ACET using Standard Graph Coloring (highest degree)
-6% – -12%

Slide 13 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
Summary & CaveatsSummary & CaveatsSummary Standard graph coloring unaware of worst-case properties May thus lead to uncontrolled spill code generation along WCEP WCET-aware register allocation: combination of standard graph
coloring with WCET-aware spill heuristic Average WCET reductions over 46 benchmarks: 31.2%
Caveats “Bad” spills not revocable, might unbalance pipeline load Experiments with highly accurate ILP-based WCET-aware register
allocation
[H. Falk, WCET-aware Register Allocation based on Graph Coloring, DAC 2009]

Slide 14 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
OutlineOutline
WCET-aware Optimizations and Code Quality
Graph Coloring Register Allocation
Scratchpad Memory Allocation
Cache-aware Memory Content Selection
Cache Partitioning for Multi-task Real-time Systems
Combination of Scratchpad Allocation, Memory Content Selection and Cache Partitioning

Slide 15 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
Caches vs. Scratchpad Memories Caches vs. Scratchpad Memories (SPM)(SPM)
Caches: Processor
L1-Cache
Main Memory
Scratchpads: Processor
SPM
Main Memory
Hardware-controlled Cache contents difficult to
predict statically Latencies of memory
accesses highly variable WCETEST often imprecise
Caches often deactivated in hard real-time systems
No autonomous hardware SPM seamlessly integrated in
processor’s address space Latencies of memory
accesses constant WCETEST extremely precise
SPM contents to be defined by compiler

Slide 16 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
Scratchpad Allocation: Variants and CaveatsScratchpad Allocation: Variants and Caveats
Characteristics of code and data allocation: Data relocation and mutation „naturally“ supported by architecture Code relocation usually requires modification of instructions
Locality annihilated (Potentially already optimized) Runtime properties destroyed
Static and dynamic scratchpad optimization: Static: Precompute global and static relocation, maintain order
(therefore locations implicit) Dynamic: Precompute dynamic exchange of SPM contents
Perspective of static analysis: self-modifying code Static dispatch (overlaying targets) Memory allocation is hard

Slide 17 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
ILP for WCET-aware SPM Allocation of CodeILP for WCET-aware SPM Allocation of Code
Goal Determine set of basic blocks to be allocated to the SPM ...such that selected basic blocks lead to overall minimization
of WCETEST
...under consideration of switching WCEPs.
Approach Integer-linear programming (ILP) Optimality of results: no need for backtracking techniques
In the following: uppercase = constants, lowercase = variables

Slide 18 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
Costs of basic block bi:
models the WCETEST of bi if it is allocated to main memory or SPM, respectively
Decision Variables & CostsDecision Variables & Costs
Binary decision variables per basic block (BB):

Slide 19 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
Intraprocedural Control FlowIntraprocedural Control Flow
Modeling of a function’s control flow:
A
CB
D
E
Acyclic sub-graphs: (Reducible) Loops:
B
A
C
D
E
Treat body of inner-most loop L like acyclic sub-graph
Fold loop L Costs of L:
Continue with next innermost loop
[V. Suhendra et al., WCET Centric Data Allocation to Scratchpad Memory, RTSS 2005]
= WCET of any path starting at A
Loop LB, C, D

Slide 20 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
Jump scenarios:
Cross-Memory JumpsCross-Memory Jumps
Allocation of consecutive BBs: Allocation of consecutive BBs in the CFG to different memories
requires adaption/insertion of dedicated jumping code Cross-memory jumps are costly Jumping code: variable overhead in terms of WCETEST and
code size, depending on decision variables
bi
bk
bj
bi
bk
bj
bi
bj
a) Implicit b) Unconditional c) Conditional

Slide 21 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
Penalties for jump scenarios ( Boolean XOR): Penalty for Implicit jumps:
Add high penalty if BBs i and j are placed in different memories
Penalty for Unconditional jumps: If bi and bj in different memories:
If bi and bj adjacent in same memory: 0
If bi and bj not adjacent in same memory:
Conditional jumps: Obvious combination of and
Penalties for Cross-Memory JumpsPenalties for Cross-Memory Jumps
bi
bk
bj
bj
bk bj

Slide 22 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
Jump Penalties & Interprocedural Control FlowJump Penalties & Interprocedural Control Flow
Jump penalties for basic block bi:
Modeling of the global control flow: Variable models cost of WCEP starting at bF
entry
If F’ calls F, must be added to WCETEST of F’

Slide 23 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
Call PenaltiesCall Penalties
Call penalties for basic block bi:
If bi calls F, add WCETEST of F to call penalty. Furthermore, add if bi contains cross-memory call, otherwise.
Final control flow constraints per basic block bi:
Add jump and call penalties to variable modeling WCETEST of any path starting at bi

Slide 24 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
Objective FunctionObjective Function
WCETEST of entire program:
Variable models WCETEST of entire program
Size of BB bi depends on actual jumping code for bi:
Size of jumping code for bi:# bytes for jumping code, depending on jump/call scenario
Total size of basic block bi:Size of bi without any jumping code plusSize of bi’s jumping code
Scratchpad CapacityScratchpad Capacity
Slide 25 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
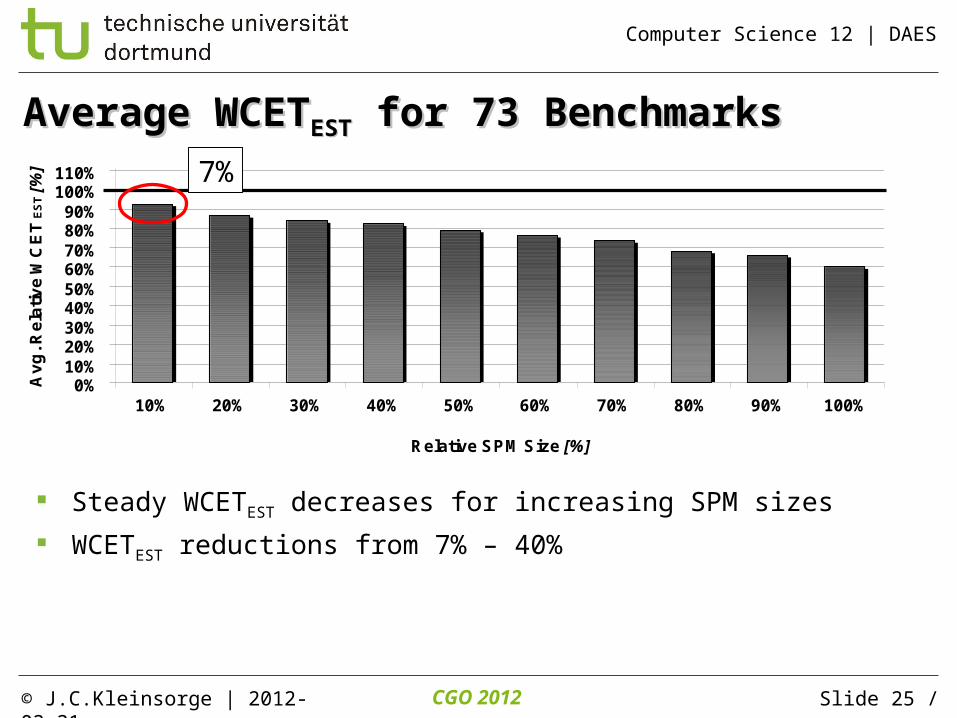
Average WCETAverage WCETESTEST for 73 Benchmarks for 73 Benchmarks
0%10%20%30%40%50%60%70%80%90%
100%110%
10% 20% 30% 40% 50% 60% 70% 80% 90% 100%
Relative SPM Size [%]
Av
g. R
ela
tiv
e W
CE
TE
ST [
%]
Steady WCETEST decreases for increasing SPM sizes
WCETEST reductions from 7% – 40%
7%

Slide 26 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
Summary & CaveatsSummary & Caveats
Summary Current state of the art:
Neglects varying jumping code in basic blocks Select one element of power set of basic blocks
Our approach: Models changing WCEPs Uses jump scenarios to cope with varying jumping code
Caveats Implicit control-flow model requires well-structured code No component-wise compilation
[H. Falk, J. Kleinsorge Optimal Static WCET-aware Scratchpad Allocation of Program Code,DAC 2009]

Slide 27 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
OutlineOutline
WCET-aware Optimizations and Code Quality
Graph Coloring Register Allocation
Scratchpad Memory Allocation
Cache-aware Memory Content Selection
Cache Partitioning for Multi-task Real-time Systems
Combination of Scratchpad Allocation, Memory Content Selection and Cache Partitioning

Slide 28 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
Cache-aware Memory Content SelectionCache-aware Memory Content Selection
Compilers good at dealing with registers (register/stack) WCC good at SPM-allocation (spm/main memory) Aspects of cache-aware optimizations:
Generally unresolved problem due to system-wide influence of local decisions and generally unknown cache parameters
Only generalized attempts on data - like loop transformations - to improve average access pattern on data
For predictability and idle optimization potential in code: Divide program in cached or uncached parts Software-controlled memory content selection to adapt to
actual access pattern

Slide 29 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
012345
C a c h eS et M a in M e m o ry
fo o 2
fo o 3
fo o 1S e t
Example for unprofitable memory layout: Mutual eviction of functions Could lead to a highly increased WCETEST due to thrashing
fo o 1void foo1() { for(i=0; i<100; i++) { foo2(); foo3(); ... }}
Cache-aware Memory Content SelectionCache-aware Memory Content Selection
fo o2fo o2
fo o3
fo o 1

Slide 30 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
Basic idea: Step-wise allocation of functions to cached memory areas Select functions whose WCETEST benefits most from cached
execution
Unprofitable functions w. r. t. a program’s WCETEST must not evict profitable ones from cache
Hill-climbing approach with a “profit”-metric:
Cache-aware Memory Content SelectionCache-aware Memory Content Selection

Slide 31 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
Memory Content Selection Algorithm (1)Memory Content Selection Algorithm (1)LLIR mcs( LLIR P, Cache cache ):
// Precompute profit profit = computeFunctionProfit( P )
// Fill cache exactly once for_each( sort( F in P, profit ) ): allocate( F, cache ) if cache.full:
break // Perform WCET-aware cache-allocation ...

Slide 32 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
Memory Content Selection Algorithm (2)Memory Content Selection Algorithm (2) // “Overcharge” cache memory unless WCETEST degrades wcet = computeWCET( P ) profit = computeFunctionProfit( P )
// As before: most profitable function first for_each( sort( F in P, profit ) ): allocate( F, cache ) tmp = computeWCET( P )
// Only keep improvements if ( wcet < tmp ): deallocate( F, cache ) else wcet = tmp profit = computeFunctionProfit( P )

Slide 33 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
adpcm
g721_encode g723_encodegsm
h264dec
md5
rijndael_decoder rijndael_encoder statem
ate v32.m
odem_benc.
Average
50%
60%
70%
80%
90%
100%
5% Cache 10% Cache 20% Cache
Re
lati
ve
WC
ET
Results compared to unoptimized cache usageE
ST 20%

Slide 34 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
Conclusion Iterative approach ensures optimizing along a possibly switching
WCEP Profitable functions not evicted from cache by unprofitable ones
w.r.t. their WCETEST
Achieves WCETEST reductions of up to 20%
Caveats Greedy approach (upside: direct, simple) Functions as allocation units might be too coarse
Summary & CaveatsSummary & Caveats
[S. Plazar, P. Lokuciejewski and P. Marwedel, WCET-driven Cache-aware Memory Content Selection, ISORC 2010]

Slide 35 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
OutlineOutline
WCET-aware Optimizations and Code Quality
Graph Coloring Register Allocation
Scratchpad Memory Allocation
Cache-aware Memory Content Selection
Cache Partitioning for Multi-task Real-time Systems
Combination of Scratchpad Allocation, Memory Content Selection and Cache Partitioning

Slide 36 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
Software-based Cache PartitioningSoftware-based Cache Partitioning
General thoughts on presented optimization strategies: Until now, greedy relocation successful strategy to get around
intra-task cache conflicts due to tight coupling with static WCET analysis
Fails in multi-task environments: Analysis unaware of potential preemptions
Safety can only be achieved by guaranteeing no collisions Granularity: instructions (possibly splitting basic blocks)
Intuition: Divide the cache into partitions of optimal size Assign one task per partition to prevent mutual eviction

Slide 37 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
Software-based Cache PartitioningSoftware-based Cache Partitioning Exploit the cache addressing logic (index bits) Distribute memory blocks of tasks over address space Ensure mapping to particular cache lines
Effectively inverts the logical mapping direction
0x0
0x80
0x100
0 x 0
0 x 1 8 0
0 x 8 0
0 x 2 0 0
0 x 1 0 0
0 x 2 8 0Ta s k 1 (p a r t3 )
Ta s k 2 (p a r t1 )
Ta s k 1 (p a r t2 )
Ta s k 1 (p a r t1 )
M a in M e m o r y
Ta s k 1
Ta s k 2
C a c h e
Ta s k 2 (p a r t2 )

Slide 38 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
WCET-aware Cache PartitioningWCET-aware Cache Partitioning
Greedy approach Partition size depends on task’s
code size Example: 4 tasks with the same
code size
Better ILP-model to select individual
partition size per task Take number of activations into
account
Cache Line
0
63
Task 1
Task 2
Task 4
Task 3
Cache Line
0
63
Task 1
Task 2
Task 4
Task 3
[F. Müller, Compiler Support for Software-Based Cache Partitioning, 1995]

Slide 39 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
ILP ILP FormulationFormulation

Slide 40 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
ILP FormulationILP Formulation
Each task must have a partition assigned:
Keep track of the cache size:

Slide 41 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
ILP FormulationILP Formulation
Partition-specific WCET per task:
Objective function to minimize:
Slide 42 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
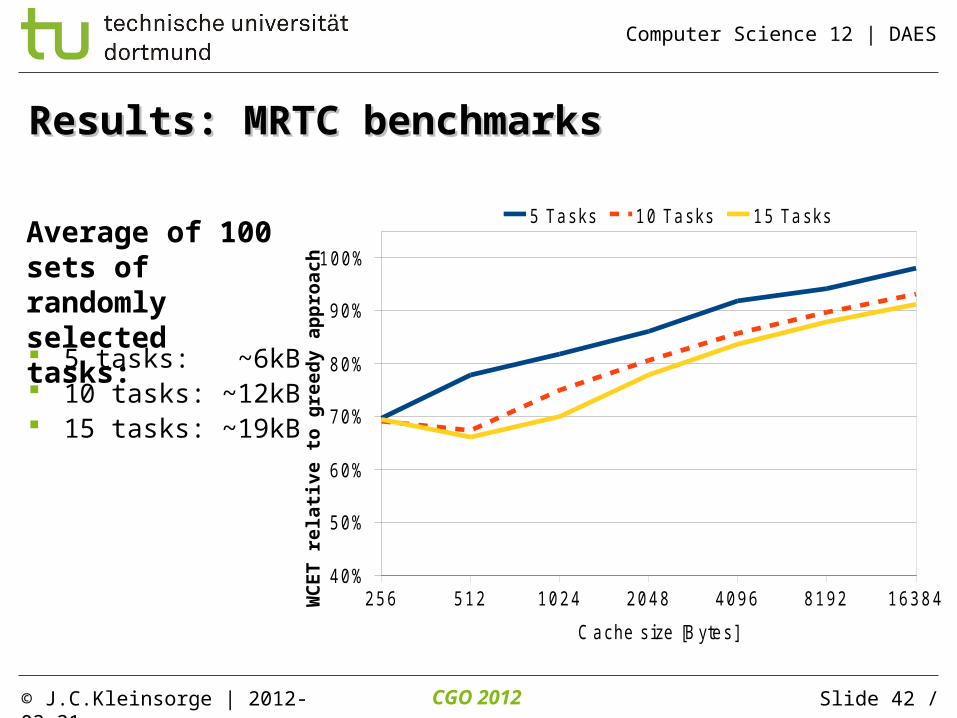
Results: MRTC benchmarksResults: MRTC benchmarks
256 512 1024 2048 4096 8192 1638440%
50%
60%
70%
80%
90%
100%
5 Tasks 10 Tasks 15 Tasks
C ache size [B ytes]
Re
lativ
e W
CE
T
Average of 100 sets of randomly selected tasks:
5 tasks: ~6kB 10 tasks: ~12kB 15 tasks: ~19kB
WC
ET
re
lati
ve t
o g
reed
y ap
pro
ach

Slide 43 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
Conclusion Optimal partition sizes w.r.t. the overall system WCET Partitioning introduces predictability for preemptive schedules Average WCET reduction of 12% (5 tasks) up to 19% (15 tasks)
compared to greedy approach
Caveats “Zero-collision” policy can be too conservative depending on the actual
cache logic and scheduling policy Pre-computation of partitions time consuming Locality in address space (basic block splits, instruction corrections)
Summary & CaveatsSummary & Caveats
[S. Plazar, P. Lokuciejewski and P. Marwedel, WCET-aware Software Based Cache Partitioning for Multi-Task Real-Time Systems, WCET 2009]

Slide 44 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
OutlineOutline
WCET-aware Optimizations and Code Quality
Graph Coloring Register Allocation
Scratchpad Memory Allocation
Cache-aware Memory Content Selection
Cache Partitioning for Multi-task Real-time Systems
Combination of Scratchpad Allocation, Memory Content Selection and Cache Partitioning

Slide 45 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
An Experiment: Combined ApproachAn Experiment: Combined Approach
Can SPM allocation, memory content selection and cache partitioning be combined?
Intention is to fully exploit memory hierarchy All three severely alter the memory layout due to relocation and
partitioning Order of application critical for good results
Example:MCS prior to SPM
Cached Uncached SPM
Taski
Taski,j
Taski,k
Taski,l
Taski,j,0
Taski,j,1
Taski,j,2
Taski,k,0
Taski,k,1

Slide 46 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
Combined Approach (1)Combined Approach (1)
Reasoning about the order of application SPM allocation (SPMA) should be performed prior to Memory
Content Selection (MCS) and Cache Partitioning (CP) CP prior to MCS:
Similar to previous example: cache potentially under-utilized MCS prior to CP:
CP only considers objects designated to be cached by MCS Likely that the greedy MCS decision was inappropriate given the
potential exploited by a fine-grained partitioning Computing MCS solution per partition in precomputation of CP Apply CP ILP to determine optimal combination

Slide 47 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
Application in order: Application in order: Effects of SPM, CP invoking MCS in preprocessing
Remainsuncached (MCS)
Not affected byCP/MCS (SPMA)

Slide 48 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
EvaluationEvaluation
0%
20%
40%
60%
80%
100%
0% 1% 3% 5% 10% 15% 20% 25%
25%
15%
5%
1%
Gai
n c
om
par
ed t
o u
no
pti
miz
ed
co
de
SPM size (%)
Cache size (%)
92%
Gains in WCETEST:
crc, fft1, gsm_decode, trellis
73%

Slide 49 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
Remarks WCET-aware compilation:
Compilers usually are unaware of timing Optimistic optimization strategies: no clearly defined objective “Maybe faster but could be worse” doesn’t quite cut it for hard
real-time applications (profile-guided optimization no match) Fine-grained optimization decisions span from well-directed
exploitation over conflict reduction to full conflict freedom
Challenges Multi-tasking: component-wise compilation, interaction, OS Multi-core: inter-core communication Tailor (fully) predictable but still highly configurable systems
Conclusion Conclusion
Slide 50 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES

Slide 51 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
Backup: RABackup: RA

Slide 52 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
WCET-Aware Graph Coloring (1)WCET-Aware Graph Coloring (1)LLIR WCET_GC_RA( LLIR P ):
// Iterate until current WCEP is fully allocated. while ( true ): // Clone P, spill all VREGs of P’ onto stack. LLIR P’ = P.copy() P’.spillAllVREGs()
// Compute Worst-Case Execution Path for fully spilled LLIR. set<basic_blocks> WCEP = computeWCEP( P’ )
// If there are no more VREGs, the allocation loop is over. if ( getVREGs( WCEP ) == ) break

Slide 53 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
WCET-Aware Graph Coloring (2)WCET-Aware Graph Coloring (2) // Determine that block on the WCEP with highest product of // Worst-Case Execution Count * spilling instructions. basic_block b’ = getMaxSpillCodeBlock( WCEP ) basic_block b = getBlockOfOriginalP( b’ )
// Collect all VREGs of this most critical block. list<virtualRegister> vregs = getVREGs( b )
// Sort VREGs by #occurrences, apply standard graph coloring. vregs.sort( occurrences of VREG in b ) traditionalGraphColoring( P, vregs ) end while
// Allocate all remaining VREGs not lying on the WCEP. traditionalGraphColoring( P, getVREGs( P ) ) return P;}

Slide 54 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
WCET-aware RA: spilling WCET-aware RA: spilling

Slide 55 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
Backup: SPM allocationBackup: SPM allocation

Slide 56 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
Timing Predictability of Caches & SPMs Timing Predictability of Caches & SPMs (G.721)(G.721)
SPMs are – in contrast to caches – highly predictable: WCETEST scale with ACETs
[L. Wehmeyer, P. Marwedel, Influence of Memory Hierarchies on Predictability for TimeConstrained Embedded Software, DATE 2005]

Slide 57 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
Support of the ILP by WCC InfrastructureSupport of the ILP by WCC Infrastructure
WCETEST of BB bi for SPM and main memory: ,
Max. Iteration counts of loop L: Size of BB bi:
SPM Size = 47 kBSPM Access = 1 CycleFlash Access = 6 Cycles
Other parameters hard-coded: , , …
Slide 58 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
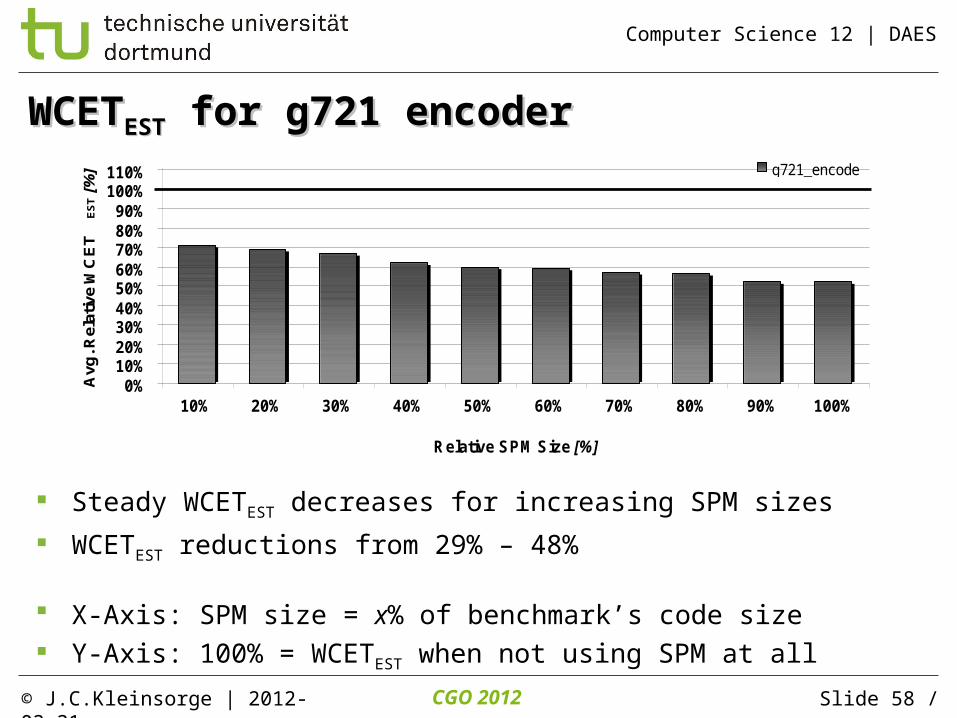
WCETWCETESTEST for for g721 encoderg721 encoder
Steady WCETEST decreases for increasing SPM sizes
WCETEST reductions from 29% – 48%
0%10%20%30%40%50%60%70%80%90%
100%110%
10% 20% 30% 40% 50% 60% 70% 80% 90% 100%
Relative SPM Size [%]
Avg
. Rel
ativ
e W
CE
TE
ST [%
] g721_encode
X-Axis: SPM size = x% of benchmark’s code size Y-Axis: 100% = WCETEST when not using SPM at all

Slide 59 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
0%10%20%30%40%50%60%70%80%90%
100%110%
10% 20% 30% 40% 50% 60% 70% 80% 90% 100%
Relative SPM Size [%]
Av
g. R
ela
tiv
e W
CE
TE
ST [
%] cover
WCETWCETESTEST for for covercover
X-Axis: SPM size = x% of benchmark’s code size Y-Axis: 100% = WCETEST when not using SPM at all
Stepwise WCETEST decreases: Useful content allocated to SPM only at 40%, 70% and 100% relative SPM size
WCETEST reductions of 10%, 35% and 44%

Slide 60 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
0%10%20%30%40%50%60%70%80%90%
100%110%
10% 20% 30% 40% 50% 60% 70% 80% 90% 100%
Relative SPM Size [%]
Av
g. R
ela
tiv
e W
CE
TE
ST [
%] md5
WCETWCETESTEST for for md5md5
X-Axis: SPM size = x% of benchmark’s code size Y-Axis: 100% = WCETEST when not using SPM at all
Almost invariable WCETEST reductions for all SPM sizes: 40% – 44%
ILP clearly finds tiny but time-critical hot-spot of md5 and allocates it to SPM

Slide 61 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
Backup: Content selectionBackup: Content selection

Slide 62 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
Example for unprofitable memory layout: Mutual eviction of functions Could lead to a highly increased WCETEST due to increased
number of possible cache missesM a in M e m o ryC a c h e
fo o 2
S e t
fo o 3
fo o 1012345
S e t
Cache-aware Memory Content SelectionCache-aware Memory Content Selection
WCETEST reduction:(350-195+690-470 = )
375 cycles

Slide 63 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
Evaluation
Infineon TriCore TC1796,16 kB 2-way set associative cache (LRU), 2 MB program flash
Employed the 10 largest benchmarks of our benchmark suites DSP Stone, MediaBench, MiBench, MRTC, Netbench and UTDSP
Code size ranges from 5 kB (v32.modem_bencode) up to 15 kB (the two rijndael benchmarks)
Using optimization level –O3 (incl. procedure positioning)
Artificially limit cache sizes to 5, 10 and 20% of overall code size

Slide 64 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
Optimization Time
Most of the optimization time consumed by repetitive WCET analyses employing aiT
Maximal number of analyses amounts to: Test machine: Intel Xeon X3220 (2.4 GHz)
rinjndael_decoder: 6 WCET analyses consumed almost 2 hours of CPU time
g721/g723_encode: 17 WCET analyses amount to 8 respectively 10 minutes analysis time

Slide 65 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
Backup: Cache partitioningBackup: Cache partitioning

Slide 66 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
Distribution of CodeDistribution of Code
Achieved by exploiting the linker Each portion is assigned to its own section Example linker script for two tasks:
0 x 0
0 x 1 8 0
0 x 8 0
0 x 1 0 0
0 x 2 8 0Ta s k 2 (p a r t3 )
Ta s k 2 (p a r t1 )
Ta s k 1 (p a r t2 )
Ta s k 1 (p a r t1 )
M a in M e m o r y
Ta s k 2 (p a r t1 )
—

Slide 67 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
Memory usageMemory usage
0 x 0
0 x 1 8 0
0 x 8 0
0 x 2 0 0
0 x 1 0 0
0 x 2 8 0Ta s k 1 (p a r t3 )
Ta s k 2 (p a r t1 )
Ta s k 1 (p a r t2 )
Ta s k 1 (p a r t1 )
M a in M e m o r y
Ta s k 1
Ta s k 2
C a c h e
—

Slide 68 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
Optimization TimeOptimization Time
Host machine: Dual Xeon L5420 @ 2.50GHz Using a single core Complete workflow consists of:
Compilation Analysis Optimization
: up to 3 minutes
: up to 1 hour / task
: up to 1 minute

Slide 69 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
Results: UTDSP benchmarksResults: UTDSP benchmarks
256 512 1024 2048 4096 8192 1638440%
50%
60%
70%
80%
90%
100%
5 Tasks 10 Tasks 15 Tasks
C ache size [B ytes]
Re
lativ
e W
CE
T
Average of 100 sets of randomly selected tasks: 5 tasks: ~8kB 10 tasks: ~18kB 15 tasks: ~26kB
WC
ET
re
lati
ve t
o G
reed
y a
pp
roac
h
Slide 70 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
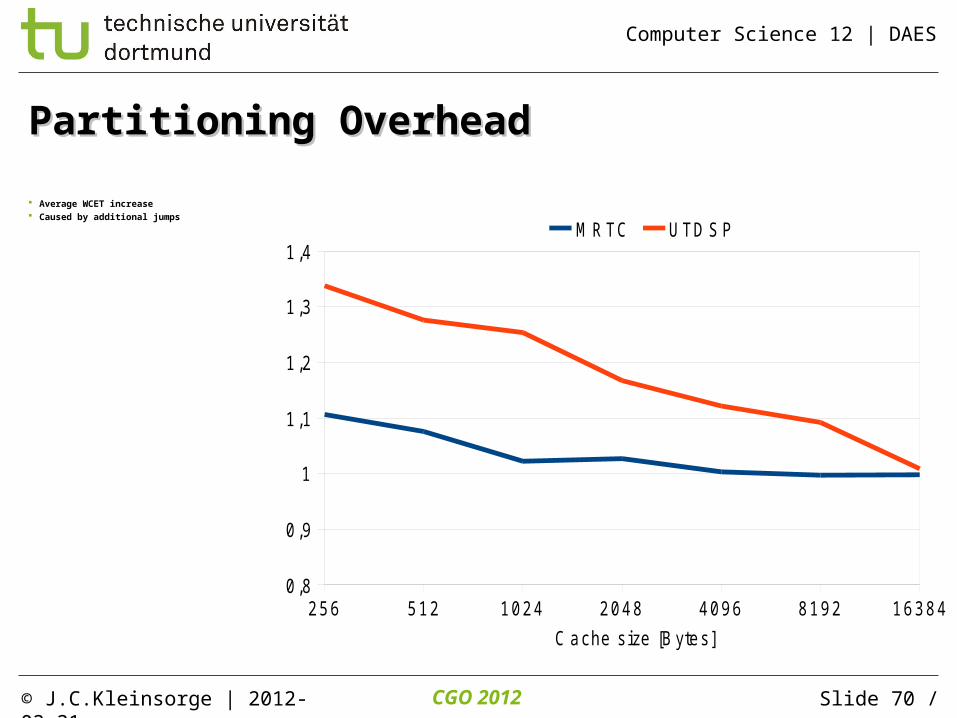
Partitioning OverheadPartitioning Overhead
256 512 1024 2048 4096 8192 163840,8
0,9
1
1,1
1,2
1,3
1,4MRTC UTD S P
C ache size [B ytes]
Average WCET increase Caused by additional jumps

Slide 71 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
Backup: CombinedBackup: Combined

Slide 72 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
Combined Approach (2)Combined Approach (2)
Adaption of algorithms for multi-tasking model SPMA
Requires heuristic to assign memory space per task Three heuristics directly apparent:
WCET: ratio of single task WCET to accumulated task-set WCET CS: ratio of code-size to accumulated code-size WCET&CS = (WCET/CS)/2: based on assumption that larger
portions of assigned space also yields performance improvements
CP and MCS restrict to functions not allocated to SPM already

Slide 73 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
EvaluationEvaluationSample results for multi-task set of: crc, g721 marcuslee decoder, h264dec_ldecode_block
CP
CP&MCS
Gai
n c
om
par
ed t
o u
no
pti
miz
ed
co
de
Allowed relative cache size of full task-set
Algorithm:

Slide 74 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES
Backup: DemoCarBackup: DemoCar

Slide 75 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES

Slide 76 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES

Slide 77 / 49© J.C.Kleinsorge | 2012-03-31 CGO 2012
Computer Science 12 | DAES










![Safety Considerations For WCET Evaluation Methods … · SAFETY CONSIDERATIONS FOR WCET EVALUATION METHODS IN AVIONIC EQUIPMENT Xavier Jean, ... CS-25.1309 [1]. Hardware and …](https://static.fdocuments.us/doc/165x107/5b69663e7f8b9af23e8e1073/safety-considerations-for-wcet-evaluation-methods-safety-considerations-for.jpg)







