
Cognitive Media Processing #12
50
Cognitive Media Processing @ 2015 Cognitive Media Processing #12 Nobuaki Minematsu
Transcript of Cognitive Media Processing #12

Cognitive Media Processing @ 2015
Cognitive Media Processing #12
Nobuaki Minematsu

Menu of the last four lectures
Robust processing of easily changeable stimuli Robust processing of general sensory stimuli
Any difference in the processing between humans and animals?
Human development of spoken language Infants’ vocal imitation of their parents’ utterances
What acoustic aspect of the parents’ voices do they imitate?
Speaker-invariant holistic pattern in an utterance Completely transform-invariant features -- f-divergence --
Implementation of word Gestalt as relative timbre perception
Application of speech structure to robust speech processing
Radical but interesting discussion A hypothesis on the origin and emergence of language
What is the definition of “human-like” robots?

?
Machine strategy (engineers’ strategy): ASR Collecting a huge amount of speaker-balanced data
Statistical training of acoustic models of individual phonemes (allophones)
Adaptation of the models to new environments and speakers Acoustic mismatch bet. training and testing conditions must be reduced.
Human strategy: HSR A major part of the utterances an infant hears are from its parents.
The utterances one can hear are extremely speaker-biased.
Infants don’t care about the mismatch in lang. acquisition. Their vocal imitation is not acoustic, it is not impersonation!!
A difference bet. machines and humans

De facto standard acoustic analysis of speech
Feature separation to find specific info.
speechwaveforms
phasecharacteristics
amplitudecharacteristics
sourcecharacteristics
filtercharacteristics
Insensitivity to phase differences
-25000
-20000
-15000
-10000
-5000
0
5000
10000
15000
20000
0 5 10 15 20 25 30 35
"A_a_512"
0
1
2
3
4
5
6
7
8
9
10
0 2000 4000 6000 8000 10000 12000 14000 16000
"A_a_512_hamming_logspec"
2
3
4
5
6
7
8
9
0 5 10 15 20 25 30 35
"A_a_512_hamming_logspec_idft_env"
Insensitivity to pitch differences
Two acoustic models for speech/speaker recognition Speaker-independent acoustic model for word recognition
Text-independent acoustic model for speaker recognition
Require intensive collection is possible or not?
P (o|w) =�
s P (o, s|w) =�
s P (o|w, s)P (s|w) ��
s P (o|w, s)P (s)
P (o|s) =�
w P (o, w|s) =�
w P (o|w, s)P (w|s) ��
w P (o|w, s)P (w)
o � ow + os
oos
ow

Insensitivity and sensitivity
Infants’ vocal learning is insensitive to age and gender differences. (A)
sensitive to accent differences. (B)
Infants’ vocal learning seems to be insensitive to feature instances and sensitive to feature relations.
(A) = instances and (B) = relations.
Relations, i.e., shape of distribution can be represented geometrically as distance matrix.
10-year-oldchildren
femaleadults
male adults
1st Formant frequency [kHz]
2nd
Form
ant f
requ
ency
[kH
z]
(A)
Uç
AQ
E
I Williamsport, PA Chicago, IL Ann Arbor, MI Rochester, NY
Distribution of normalized formants among AE dialects [Labov et al.’05]
(B)
formant frequencies of adults and children

“Separately brought up identical twins”
The parents get divorced immediately after the birth. The twins were brought up separately by the parents.
What kind of pron. will the twins have acquired 5 years later?
Williamsport, PA
Qç
A
E
I
√
Rochester, NY
QI
E
A ç
√
Diff. of VTL = Diff. of timbre
Diff. of regional accents = Diff. of timbre
Machines that don’t learn what infants don’t learn.

Invariance in variability
Topological invariance [Minematsu’09] Topology focuses on invariant features wrt. any kind of deformation.

Complete transform-invariance
Any general expression for invariance?[Qiao’10] BD is just one example of invariant contrasts.
f-divergence is invariant with any kind of transformation.
Invariant features have to be f-divergence. If is invariant with any transformation,
The following condition has to be satisfied.
g(t) =�
t � � log(fdiv) = BD
fdiv(p1, p2) = fdiv(P1, P2)g(t) = t log(t) � fdiv = KL � div.
�M(p1(x), p2(x))dx
M = p2(x)g�
p1(x)p2(x)
�
x
y
u
vA
B
p1
p2
P1P2
(x,y)
(u,v)fdivfdiv
fdiv(p1, p2) =
∫p2(x)g
(p1(x)
p2(x)
)dx
− log
∫ √P1(u, v)P2(u, v)dudv
g(u, v)|J(u, v)|
1

Utterance to structure conversion using f-div. [Minematsu’06]
An event (distribution) has to be much smaller than a phoneme.
c1
c3c2
c1
c3c2c4cD
c4cD
Bhattacharyya distance
BD-based distance matrix
Invariant speech structure
Sequence of spectrum slices
Sequence of cepstrum vectors
Sequence of distributions
Structuralization by interrelating temporally-distant events
Sequence of spectrum slices
Sequence of cepstrum vectors
Sequence of distributions
Structuralization by interrelating temporally-distant events
Sequence of spectrum slices
Sequence of cepstrum vectors
Sequence of distributions
Structuralization by interrelating temporally-distant events
Sequence of spectrum slices
Sequence of cepstrum vectors
Sequence of distributions
Structuralization by interrelating temporally-distant events
spectrogram (spectrum slice sequence)
cepstrum vector sequence
distribution sequence

Isolated word recognition using warped utterances Word = V1V2V3V4V5 such as /eoaui/, PP = 120 (CL=0.8%)
Word-based HMMs (20 states) vs. word-based structures (20 events) Training = 4M+4F adults, testing = other 4M+4F with various VTLs
4,130-speaker triphone HMMs are also tested with 0.30. The speaker-independent HMMs widely used as baseline model in Japan
Application of structures to ASR
0
20
40
60
80
100
-0.4
0
-0.3
5
-0.3
0
-0.2
5
-0.2
0
-0.1
5
-0.1
0
-0.0
5
0.00
0.05
0.10
0.15
0.20
0.25
0.30
0.35
0.40
4130-speaker triphone HMMs
Wor
d re
cog.
rat
e [%
] #train spk = 8 #test spk = 8
PP=120
Word HMM (20S) 17 matched HMMs
Structure (20S)

An experiment with real vocal imitation
Demonstration with my wife and daughter Constraint conditions are given by my wife.
Initial conditions are given by my daughter.
c 1
c 3 c 2
c 1
c 3 c 2 c 4
c D
c 4
c D
0
20
40
60
80
100
-0.4
0
-0.3
5
-0.3
0
-0.2
5
-0.2
0
-0.1
5
-0.1
0
-0.0
5
0.0
0
0.0
5
0.1
0
0.1
5
0.2
0
0.2
5
0.3
0
0.3
5
0.4
0
4130-speakertriphone HMMs
Wo
rd r
eco
g. r
ate
[%] #train spk = 8
#test spk = 8PP=120
Word HMM (20S)17 matched HMMsStructure (20S)
+-

Proficiency estimation based on structural distance
A big solution for CALL development
USA/F12 Minematsu (Japanized)
USA/M08 Minematsu (Japanized)
(Minematsu@ICSLP 2004)

Clustering of learners
Contrast-based comparison
Substance-based comparison
F1
I1K1A1
C1D1
E1H1
B1G1A3
L1D3
F3H3
E3
I3
B3G3K3
C3
L3K6
C6A6
F6
I6
J6
L6
E6H6
B6D6G6
B5
L5G5
F2
F5
C5
E5D5H5K2K5G2K8A2
E2
I2D2H2
J2
C2
J5A8A5
I5
I8A4
C4
I4
F4H4
J4
J1
J3
L4
E4K4G4
B4D4
B7
L7G7
I7
F7H7A7D7K7
C7
E7
L2
L8G8
B8
B2D8
E8
F8
C8
J7H8
J8
L7
L8
L3
L4
L1
L6
L2
L5
E8
E7
E3
E4
E1
E6
E2
E5
J3
J7
J4
J8
J5
J6
J1
J2K2K5K6K4K8K1K3K7
I1
I4
I3
I7
I8
I5
I2
I6A4A6A1A3A7A8A2A5D7D8D2D5D1D6D3D4
B3
B4
B7
B8
B1
B6
B2
B5G1G7G3G4G2G5G6G8
F2
F5
F1
F7
F6
F8
F3
F4H3H7H1H4H2H5H6H8
C1
C7
C3
C4
C2
C5
C6
C8
1 3 6 5 2 4 7 8
L E J K I AD B G F HC

Application of speaker-pair-open prediction
TED talks browser from your viewpoint If TED talkers provide their SAA readings....
If these readings are transcribed by phoneticians....
Visualization of pronunciation diversity [Kawase et al.,’14]
?
young
old
young
old
young
old
old
young
Y. Kawase, et al., “Visualization of pronunciation diversity of World Englishesfrom a speaker’s self-centered viewpoint”

Cognitive Media Processing @ 2015
A new framework for “human-like” speech machines #4
Nobuaki Minematsu

Cognitive Media Processing @ 2015
Title of each lecture• Theme-1
• Multimedia information and humans • Multimedia information and interaction between humans and machines • Multimedia information used in expressive and emotional processing • A wonder of sensation - synesthesia -
• Theme-2 • Speech communication technology - articulatory & acoustic phonetics - • Speech communication technology - speech analysis - • Speech communication technology - speech recognition - • Speech communication technology - speech synthesis -
• Theme-3 • A new framework for “human-like” speech machines #1 • A new framework for “human-like” speech machines #2 • A new framework for “human-like” speech machines #3 • A new framework for “human-like” speech machines #4
c 1
c 3 c 2
c 4
c D

Menu of the last four lectures
Robust processing of easily changeable stimuli Robust processing of general sensory stimuli
Any difference in the processing between humans and animals?
Human development of spoken language Infants’ vocal imitation of their parents’ utterances
What acoustic aspect of the parents’ voices do they imitate?
Speaker-invariant holistic pattern in an utterance Completely transform-invariant features -- f-divergence --
Implementation of word Gestalt as relative timbre perception
Application of speech structure to robust speech processing
Radical but interesting discussion A hypothesis on the origin and emergence of language
What is the definition of “human-like” robots?

DNN and speech structure
Deep neural network [Hinton+’06, ’12] Deeply stacked artificial neural networks
Results in a huge number of weights
Unsupervised pre-training and supervised fine-tuning
Findings in DNN-based ASR [Mohamed+’12] First several layers seem to work as extractor of invariant features or speaker-normalized features.
Still difficult to interpret structure and weights of DNN physically. Interpretable DNNs are becoming one of the hot topics [Sim’15].
A simple question asked in tutorial talks of DNN “What are really speaker-independent features?”
Asked by N. Morgan at APSIPA2013 and ASRU2013
Some similarities between DNN and speech structure?

DNN as posterior estimator
General framework for training DNN Unsupervised pre-training and supervised training
In the latter training, speaker-adapted HMMs are used to prepare posteriors (=labels) for each frame of the training data.
DNN is trained so that it can extract speaker-invariant features and can predict posteriors in a speaker-independent way.
Output of DNN = posteriors (phoneme state posteriors in ASR)

Posteriors = normalized similarities
Posteriors of { }
Can be interpreted as normalized similarity scores biased by priors.
Output of DNN = normalized similarity scores to a definite set of speaker-adapted acoustic “anchors” of { }.
Similarities can be converted to distances/contrasts to “anchors”. Either of similarity matrix or distance matrix is used for clustering.
123
N...... 12 3
N......
: speaker-dependent : speaker-independent(invariant)

Distances to anchors
Speech structure extracted from an utterance
Structure extraction for speakers and
Sequence of spectrum slices
Sequence of cepstrum vectors
Sequence of distributions
Structuralization by interrelating temporally-distant events
Sequence of spectrum slices
Sequence of cepstrum vectors
Sequence of distributions
Structuralization by interrelating temporally-distant events
Sequence of spectrum slices
Sequence of cepstrum vectors
Sequence of distributions
Structuralization by interrelating temporally-distant events
Sequence of spectrum slices
Sequence of cepstrum vectors
Sequence of distributions
Structuralization by interrelating temporally-distant events
spectrogram (spectrum slice sequence)
cepstrum vector sequence
distribution sequence
: speaker-dependent : speaker-independent(invariant)

Invariant contrasts
DNN as speaker-invariant contrast estimation Use of spk-dependent HMMs to prepare posterior labels
“Anchors” have to be given from researchers.
A huge amount of data to guarantee spk-invariance of DNN
Str. extraction as speaker-invariant contrast detection Use of within-utterance acoustic events only
“Anchors” exist in a given utterance.
Spk-invariance is guaranteed by invariant properties of f-div.
123
N......

A claim found in classical linguistics
Theory of relational invariance [Jakobson+’79] Also known as theory of distinctive features
Proposed by R. Jakobson
We have to put aside the accidental properties of individual sounds and substitute a general expression that is the common denominator of these variables.
Physiologically identical sounds may possess different values in conformity with the whole sound system, i.e. in their relations to the other sounds.
c 1
c 3 c 2
c 4
c D

More classical claims in linguistics
Nikolay Sergeevich Trubetskoy (1890-1938) “The Principles of Phonology” (1939)
The phonemes should not be considered as building blocks out of which individual words are assembled. Each word is a phonic entity, a Gestalt, and is also recognized as such by the hearer.As a Gestalt, each word contains something more than sum of its constituents (phonemes), namely, the principle of unity holds the phoneme sequence together and lends individuality to a word.
c 1
c 3 c 2
c 4
c D
Sequence of spectrum slices
Sequence of cepstrum vectors
Sequence of distributions
Structuralization by interrelating temporally-distant events

More classical claims in linguistics
Ferdinand de Saussure (1857-1913) Father of modern linguistics
“Course in General Linguistics” (1916)
What defines a linguistic element, conceptual or phonic, is the relation in which it stands to the other elements in the linguistic system.The important thing in the word is not the sound alone but the phonic differences that make it possible to distinguish this word from the others.Language is a system of only conceptual differences and phonic differences.
c 1
c 3 c 2
c 4
c D

Poverty of Stimulus
https://www.thoughtco.com/poverty-of-the-stimulus-pos-1691521
It is the argument that the linguistic input received by young children is in itself insufficient to explain their detailed knowledge of their first language, so people must be born with an innate ability to learn a language.

Menu of the last four lectures
Robust processing of easily changeable stimuli Robust processing of general sensory stimuli
Any difference in the processing between humans and animals?
Human development of spoken language Infants’ vocal imitation of their parents’ utterances
What acoustic aspect of the parents’ voices do they imitate?
Speaker-invariant holistic pattern in an utterance Completely transform-invariant features -- f-divergence --
Implementation of word Gestalt as relative timbre perception
Application of speech structure to robust speech processing
Radical but interesting discussion A hypothesis on the origin and emergence of language
What is the definition of “human-like” robots?

Origin and evolution of language
A MODULATION-DEMODULATION MODEL FOR SPEECHCOMMUNICATION AND ITS EMERGENCE
NOBUAKI MINEMATSUGraduate School of Info. Sci. and Tech., The University of Tokyo, Japan,
Perceptual invariance against large acoustic variability in speech has been a long-discussedquestion in speech science and engineering (Perkell & Klatt, 2002), and it is still an openquestion (Newman, 2008; Furui, 2009). Recently, we proposed a candidate answer based onmathematically-guaranteed relational invariance (Minematsu et al., 2010; Qiao & Minematsu,2010). Here, transform-invariant features, f -divergences, are extracted from the speech dynam-ics in an utterance to form an invariant topological shape which characterizes and represents thelinguistic message conveyed in that utterance. In this paper, this representation is interpretedfrom a viewpoint of telecommunications, linguistics, and evolutionary anthropology. Speechproduction is often regarded as a process of modulating the baseline timbre of a speaker’s voiceby manipulating the vocal organs, i.e., spectrum modulation. Then, extraction of the linguis-tic message from an utterance can be viewed as a process of spectrum demodulation. Thismodulation-demodulation model of speech communication has a strong link to known morpho-logical and cognitive differences between humans and apes.
1. Introduction
Many speech sounds can be represented as standing waves in a vocal tube andtheir acoustic properties depend on the shape and length of the tube. The processof producing vowel sounds is very similar to that of producing sounds with a windinstrument. A vocal tube can be regarded as an instrument and, by changing itsshape dynamically, sounds of different timbre such as [ i u ] can be generated.
The length and shape of the vocal tube varies among speakers. This is whyvoice quality differs among them and one can identify a speaker by hearing hisvoice. Figure 1 shows the tallest adult and the shortest adult in the world. Theremust be a very large gap in voice quality between the two, but they were ableto communicate orally with no trouble the first time they saw each other. Humanspeech communication is very robust to acoustic variability caused by speaker dif-ferences. This is a good example of invariance and variability in speech processes.
In telecommunications, a message is transmitted to receivers by changing oneparameter of a carrier wave in relation to that message. A sinusoidal wave is oftenused as carrier. This transmission scheme is called modulation and in (Wikipedia,2011) it is explained by using the performance of a musician as a metaphor.

From Wikipedia
Modulation used in telecommunicationFigure 1. The tallest and shortest adults
=
=
Figure 2. Frequency modulation and demodulation
A musician modulates the tone from a musical instrument by varyingits volume, timing and pitch. The three key parameters of a carriersine wave are its amplitude (“volume”), its phase (“timing”) and itsfrequency (“pitch”), all of which can be modified in accordance witha content signal to obtain the modulated carrier.
We can say that a melody contour is a pitch-modulated (frequency-modulated)version of a carrier wave, where the carrier corresponds to the baseline pitch.
We speak using our instruments, i.e., vocal organs, by varying not only theabove parameters, but also the most important parameter, called the timbre orspectrum envelope. From this viewpoint, it can be said that an utterance is gen-erated by spectrum modulation (Scott, 2007). The default shape and length of avocal tube determines speaker-dependent voice quality and, by changing the shapeor modulating the spectrum envelope, an utterance is produced and transmitted.
In a large number of previous studies in automatic speech recognition (ASR),to bridge a gap between the ASR performance and the performance of humanspeech recognition (HSR), much attention was paid to the dynamic aspects ofutterances, and many dynamic features were proposed (Greenberg & Kingsbury,1997; Hermansky & Morgan, 1994; Furui, 1981; Ostendorf et al., 1996). Al-though these studies proposed new features for ASR, if one views speech pro-duction as spectrum modulation, he may point out that these proposals did notprovide a good answer to a very fundamental question of ASR and HSR: “what isthe algorithm for spectrum demodulation?”
In telecommunications, a transmitted message is received via demodulation.In (Wikipedia, 2011), demodulation is explained as a process of extracting theoriginal message intact from a modulated carrier wave. In any form of modula-tion, AM, PM, or FM, methods exist that can be used to analytically extract themessage component exclusively by removing the carrier component from a modu-lated carrier. Figure 2 illustrates the processes of transmitting and receiving a mes-sage via FM. The process of spectrum demodulation, which in this case refers tospeech recognition, should therefore be realized by a mathematical algorithm thatextracts the linguistic message exclusively by removing the speaker-dependentvoice quality, i.e., removing speaker identity, from an utterance.
=modulated carrier
message
carrier
modulationmessage
demodulation
modulated carriercarrier
messagemessage
=modulationdemodulation

A way of characterizing speech production
Speech production as spectrum modulation Modulation in frequency (FM), amplitude (AM), and phase (PM)
= Modulation in pitch, volume, and timing (from Wikipedia)
= Pitch contour, intensity contour, and rhythm (= prosodic features)
What about a fourth parameter, which is spectrum (timbre)? = Modulation in spectrum (timbre) [Scott’07]
= Another prosodic feature?
tFront Central Back
Low
Mid
High beat
bit
bet
batbut
bought
pot
bird
about
bootput
Front Central Back
Low
Mid
High beat
bit
bet
batbut
bought
pot
bird
about
bootput
Front Central Back
Low
Mid
High beat
bit
bet
batbut
bought
pot
bird
about
bootput
Front Central Back
Low
Mid
High beat
bit
bet
batbut
bought
pot
bird
about
bootput
Front Central Back
Low
Mid
High beat
bit
bet
batbut
bought
pot
bird
about
bootput
Front Central Back
Low
Mid
High beat
bit
bet
batbut
bought
pot
bird
about
bootput
Front Central Back
Low
Mid
High beat
bit
bet
batbut
bought
pot
bird
about
bootput
time
Schwa = most lax = most frequent = home position = spk.-specific baseline timbre
Tongue = modulator

Demodulation in frequency, amplitude, and phase Demodulation = a process of extracting a message intactly by removing the carrier component from the modulated carrier signal.
Not by extensive collection of samples of modulated carriers
(Not by hiding the carrier component by extensive collection)
Demodulation used in telecommunication
=modulated carrier
message
carrier
modulationmessage
demodulation
modulated carriercarrier
messagemessage
=modulationdemodulation

Spectrum demodulation
Speech recognition = spectrum (timbre) demodulation Demodulation = a process of extracting a message intactly by removing the carrier component from the modulated carrier signal.
By removing speaker-specific baseline spectrum characteristics
Not by extensive collection of samples of modulated carriers
(Not by hiding the carrier component by extensive collection)
message message
=
messagemessage
=
modulated carriercarrier
modulation demodulation
modulated carriercarrier
modulationdemodulation

Utterance to structure conversion using f-div. [Minematsu’06]
An event (distribution) has to be much smaller than a phoneme.
c1
c3c2
c1
c3c2c4cD
c4cD
Bhattacharyya distance
BD-based distance matrix
Invariant speech structure
Sequence of spectrum slices
Sequence of cepstrum vectors
Sequence of distributions
Structuralization by interrelating temporally-distant events
Sequence of spectrum slices
Sequence of cepstrum vectors
Sequence of distributions
Structuralization by interrelating temporally-distant events
Sequence of spectrum slices
Sequence of cepstrum vectors
Sequence of distributions
Structuralization by interrelating temporally-distant events
Sequence of spectrum slices
Sequence of cepstrum vectors
Sequence of distributions
Structuralization by interrelating temporally-distant events
spectrogram (spectrum slice sequence)
cepstrum vector sequence
distribution sequence

Two questions
Q1: Does an ape have a good modulator? Does the tongue of an ape work as a good modulator?
Q2: Does an ape have a good demodulator? Does the ear (brain) of an ape extract the message intactly?
message message
=
messagemessage
=
modulated carriercarrier
modulation demodulation
modulated carriercarrier
modulationdemodulation

Structural diff. in the mouth and the nose
pharynx
pharynx
larynx
larynx
stomach
lung
stomachlung

Flexibility of tongue motion
The chimp’s tongue is much stiffer than the human’s. “Morphological analyses and 3D modeling of the tongue musculature of the chimpanzee” (Takemoto’08)
Less capability of manipulating the shape of the tongue.

Old and new “Planet of the Apes”

Q1: Does the ape have a good modulator?
Morphological characteristics of the ape’s tongue Two (almost) independent tracts [Hayama’99]
One is from the nose to the lung for breathing.
The other is from the mouth to the stomach for eating.
Much lower ability of deforming the tongue shape [Takemoto’08] The chimp’s tongue is stiffer than the human’s.
message
carrier
modulationcarrier
messagemodulation
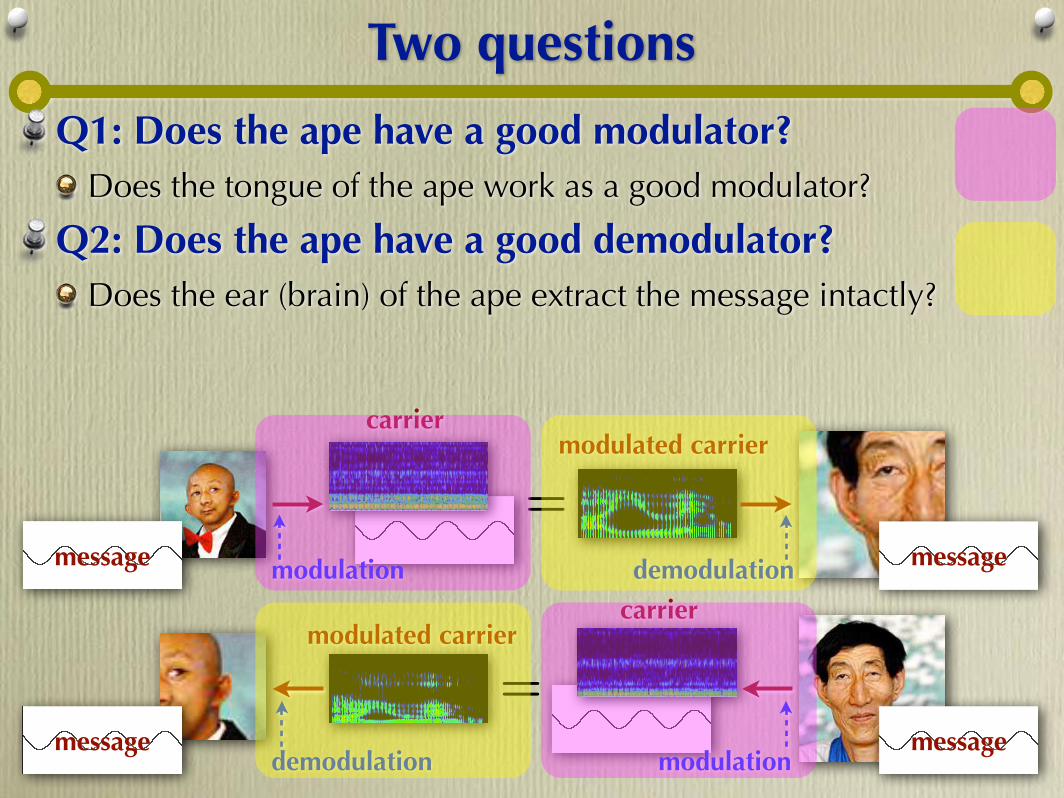
Two questions
Q1: Does the ape have a good modulator? Does the tongue of the ape work as a good modulator?
Q2: Does the ape have a good demodulator? Does the ear (brain) of the ape extract the message intactly?
message message
=
messagemessage
=
modulated carriercarrier
modulation demodulation
modulated carriercarrier
modulationdemodulation

The nature’s solution for static bias?
How old is the invariant perception in evolution? [Hauser’03]
12
1 = 2At least, frequency (pitch) demodulation seems difficult.

VI = children’s active imitation of parents’ utterances Language acquisition is based on vocal imitation [Jusczyk’00].
VI is very rate in animals. No other primate does VI [Gruhn’06].
Only small birds, whales, and dolphins do VI [Okanoya’08].
A’s VI = acoustic imitation but H’s VI = acoustic = ?? Acoustic imitation performed by myna birds [Miyamoto’95]
They imitate the sounds of cars, doors, dogs, cats as well as human voices.
Hearing a very good myna bird say something, one can guess its owner.
Beyond-scale imitation of utterances performed by children No one can guess a parent by hearing the voices of his/her child.
Very weird imitation from a viewpoint of animal science [Okanoya’08].
Language acquisition through vocal imitation
?

Q2: Does the ape have a good demodulator?
Cognitive difference bet. the ape and the human Humans can extract embedded messages in the modulated carrier.
It seems that animals treat the (modulated) carrier as it is.
From the (modulated) carrier, what can they know? The apes can identify individuals by hearing their voices.
Lower/higher formant frequencies = larger/smaller apes
message
carrier
modulation demodulation
=
carrier
messagemodulationdemodulation
=

Function of the voice timbre
What is the original function of the voice timbre? For apes
The voice timbre is an acoustic correlate with the identity of apes.
For speech scientists and engineers They had started research by correlating the voice timbre with messages conveyed by speech stream such as words and phonemes.
Formant frequencies are treated as acoustic correlates with vowels.
“Speech recognition” started first, then, “speaker recognition” followed.
fn =c
2l1n
fn =c
2l2n
f =c
2⇡
A2
A1l1l2
�1/2

Function of the voice timbre
What is the original function of the voice timbre? For apes
The voice timbre is an acoustic correlate with the identity of apes.
For speech scientists and engineers They had started research by correlating the voice timbre with messages conveyed by speech stream such as words and phonemes.
Formant frequencies are treated as acoustic correlates with vowels.
“Speech recognition” started first, then, “speaker recognition” followed.
But the voice timbre can be changed easily. Speaker-independent acoustic model for word recognition
Speaker-adaptive acoustic model for word recognition HMMs are always modified and adapted to users.
These methods don’t remove speaker components in speech.
P (o|w) =�
s P (o, s|w) =�
s P (o|w, s)P (s|w) ��
s P (o|w, s)P (s)

Menu of the last four lectures
Robust processing of easily changeable stimuli Robust processing of general sensory stimuli
Any difference in the processing between humans and animals?
Human development of spoken language Infants’ vocal imitation of their parents’ utterances
What acoustic aspect of the parents’ voices do they imitate?
Speaker-invariant holistic pattern in an utterance Completely transform-invariant features -- f-divergence --
Implementation of word Gestalt as relative timbre perception
Application of speech structure to robust speech processing
Radical but interesting discussion A hypothesis on the origin and emergence of language
What is the definition of “human-like” robots?

What is the goal of speech engineering?

Clever Hans
A horse who can “calculate” https://simple.wikipedia.org/wiki/Clever_Hans
Can he calculate or can he pretend to calculate?

“Pretending to be normal”
A book written by Liane Holliday Willey She is autistic (Asperger’s syndrome).

Definition of “human-likeness”
Necessary conditions Sufficient conditions Necessary and sufficient conditions What can researchers do?
Different researchers may claim different “necessary” conditions.
What a researcher can do is just to satisfy his/her own “necessary” conditions to make his/her own human-like robot.

Cognitive Media Processing @ 2015
Final assignment• 1. Read the following two papers and give your own comments.
• Both papers are available at the lecture’s site. Summaries are not needed. • http://www.gavo.t.u-tokyo.ac.jp/~mine/japanese/media2019/class.html
• A: “Speech structure and its application to robust speech processing” • (A’: “音声に含まれる言語的情報を非言語情報から音響的に分離して抽出する方法の提案 ~人間らしい音声情報処理の実現に向けた一検討~”)
• B: “A modulation and demodulation model for speech communication and its emergence”
• 2. Show your own necessary conditions of “human-likeness”. • 3. Comment on the content of this class. Your comments will be
reflected on future classes. • Submission
• Your file should be named as [student_id]_[name].pdf • Email subject should be "CMP assignment 3". • Your report should be sent to [email protected]
• Deadline = Jan. 28 (Tue) 23:59 (3 weeks to go)


















