

Power your journey to AI with IBM Cloud Pak for Data DataStage

Cloud Pak for Data SystemIBM Performance Server for PostgreSQL
Netezza/PureData for Analytics to PerformanceServer Migration
Olaf Depper ([email protected])Bob Baskett ([email protected])World Wide DTE – Hybrid Data Management
IBM Community Webcast, Jan. 22, 2019

Legal Disclaimer
© IBM Corporation 2020. All Rights Reserved.The information contained in this publication is provided for informational purposes only. While efforts were made to verify the completeness and accuracy of the information contained in this publication, it is provided AS IS without warranty of any kind, express or implied. In addition, this information is based on IBM’s current product plans and strategy, which are subject to change by IBM without notice. IBM shall not be responsible for any damages arising out of the use of, or otherwise related to, this publication or any other materials. Nothing contained in this publication is intended to, nor shall have the effect of, creating any warranties or representations from IBM or its suppliers or licensors, or altering the terms and conditions of the applicable license agreement governing the use of IBM software.
References in this presentation to IBM products, programs, or services do not imply that they will be available in all countries in which IBM operates. Product release dates and/or capabilities referenced in this presentation may change at any time at IBM’s sole discretion based on market opportunities or other factors, and are not intended to be a commitment to future product or feature availability in any way. Nothing contained in these materials is intended to, nor shall have the effect of, stating or implying that any activities undertaken by you will result in any specific sales, revenue growth or other results.
Performance is based on measurements and projections using standard IBM benchmarks in a controlled environment. The actual th roughput or performance that any user will experience will vary depending upon many factors, including considerations such as the amou nt of multiprogramming in the user's job stream, the I/O configuration, the storage configuration, and the workload processed. Therefore, no assurance can be given that an individual user will achieve results similar to those stated here.

Agenda
Performance Server OverviewWhat's new
IBM Cloud Pak for Data
IBM Performance Server for PostgreSQL
Architecture
What stays the same
Migration Path(s)
Migration Demo
Best Practices
Questions

A faster, more secure way to move your core business applications to any cloudthrough enterprise-ready containerized software solutions
Cloud Paks – Middleware anywhere
Complete yet simpleApplication, data and AI services,fully modular and easy to consume
IBM certifiedFull software stack support, and ongoing security, compliance and version compatibility
Run anywhereOn-premises, on private and public clouds,and in pre-integrated systems
IBM containerized softwarePackaged with Open Source components,
pre-integrated with the common operational services,and secure by design
Container platformand operational services
Logging, monitoring, security,identity access management
▪ A Hyper Converged System combines storage, compute, networking and software into a single system to reduce complexity & increase scalability
▪ Red Hat OpenShift Container Management Platform and Kubernetes for highly reliable, rapidly deployed micro-services
▪ The Platform for Data & AI - quickly assembled with pre-tested building blocks
▪ Built-in governance. Simplify & unify how you collect, manage, govern & analyze data
▪ New capabilities available through library of add-on modules.
Introducing Cloud Pak for Data System
+
▪ A Hyper Converged System combines storage, compute, networking and software into a single system to reduce complexity & increase scalability
▪ Red Hat OpenShift Container Management Platform and Kubernetes for highly reliable, rapidly deployed micro-services
▪ The Platform for Data & AI - quickly assembled with pre-tested building blocks
▪ Built-in governance. Simplify & unify how you collect, manage, govern & analyze data
▪ New capabilities available through library of add-on modules.
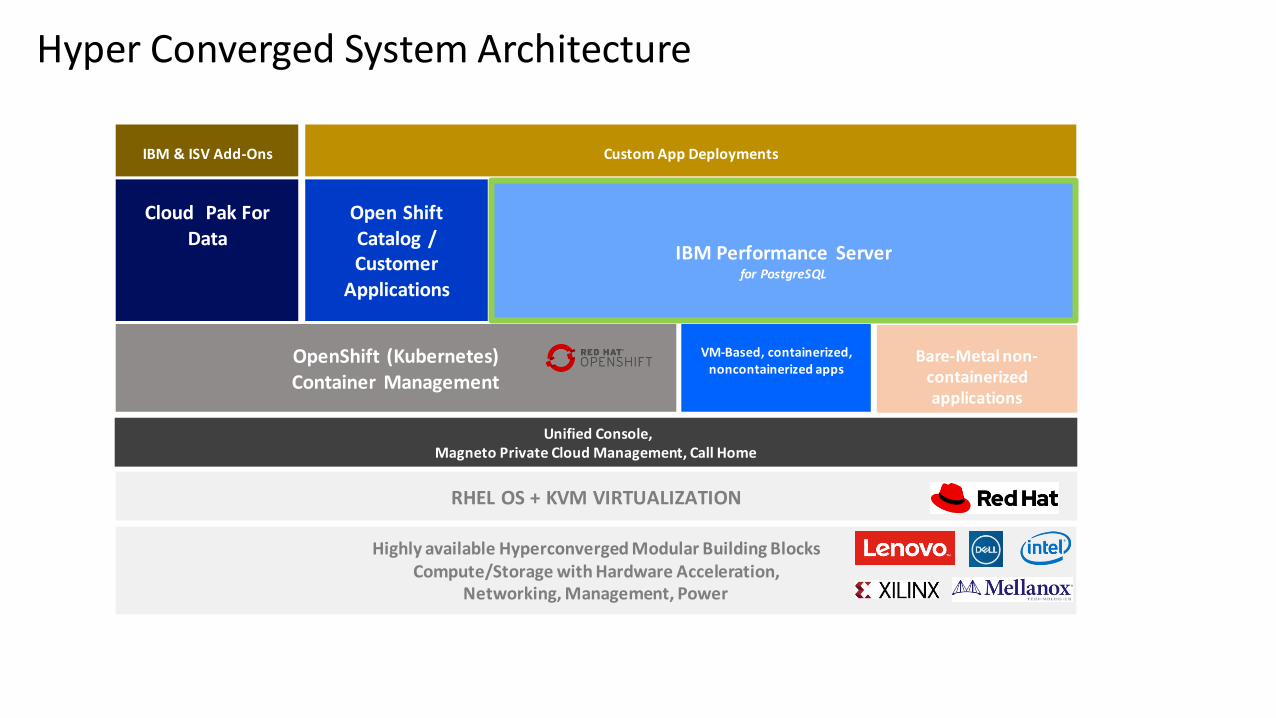
Unified Console,Magneto Private Cloud Management, Call Home
Cloud Pak For Data
Open Shift Catalog /Customer
Applications
IBM Performance Server for PostgreSQL
OpenShift (Kubernetes) Container Management
Highly available Hyperconverged Modular Building BlocksCompute/Storage with Hardware Acceleration,
Networking, Management, Power
RHEL OS + KVM VIRTUALIZATION
Bare-Metal non-containerized applications
IBM & ISV Add-Ons Custom App Deployments
VM-Based, containerized, noncontainerized apps
Hyper Converged System Architecture

IBM Performance Server for PostgreSQL
Cloud in-a-boxavailable in Cloud Pak for Data System to take advantage of hyper converged modularity
Blazing-fastbuilt over open source and optimized for High Performance Analytics with built-in hardware acceleration
Simpleload and go, minimal administration and tuning
Scalable & elasticmulti-tenant, start small, grow as you need on storage and compute
AvailabilityRed Hat Open Shift (Kubernetes)-container managed, highly available
Support & usageproduction ready and fully supported by IBM, unlimited use as with Db2 Warehouse
fully (100%) compatible with Netezza/Pure Data System for Analytics line of appliance offerings, all nz* utilities compatible, Synergy with data integration & BI tools, “fork-lift” existing Netezza systems, ‘nz_migrate’ and go!
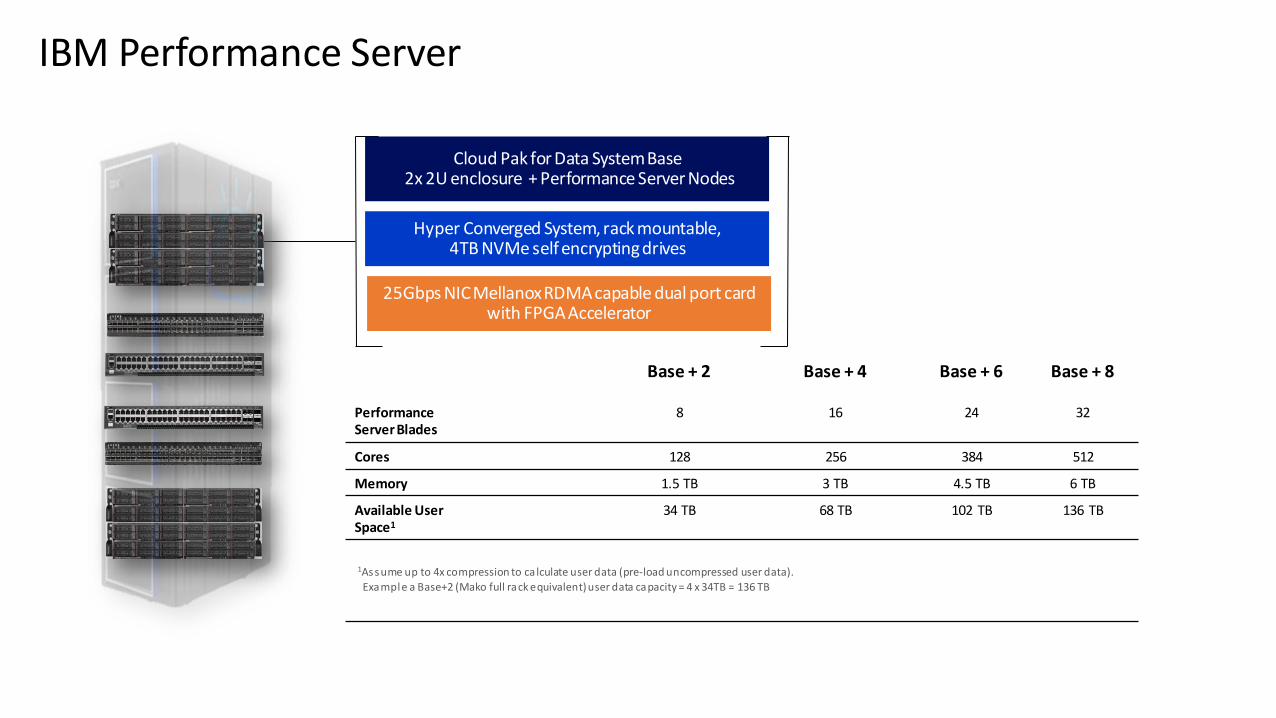
Base + 1 Base + 2 Base + 4 Base + 6 Base + 8
Performance Server Blades
4 8 16 24 32
Cores 64 128 256 384 512
Memory 0.76 TB 1.5 TB 3 TB 4.5 TB 6 TB
Available User Space1
17 TB 34 TB 68 TB 102 TB 136 TB
1Assume up to 4x compression to calculate user data (pre-load uncompressed user data). Example a Base+2 (Mako full rack equivalent) user data capacity = 4 x 34TB = 136 TB
Cloud Pak for Data System Base 2x 2U enclosure + Performance Server Nodes
Hyper Converged System, rack mountable, 4TB NVMe self encrypting drives
25Gbps NIC Mellanox RDMA capable dual port card with FPGA Accelerator
IBM Performance Server
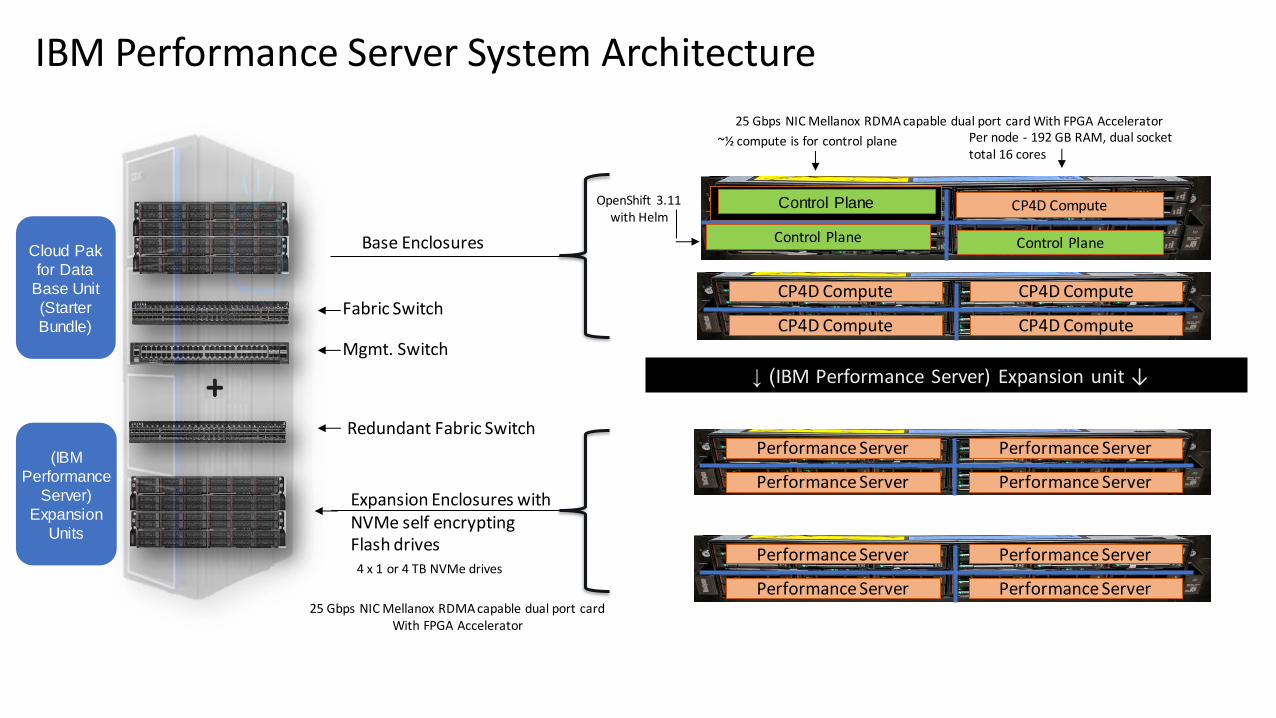
IBM Performance Server System Architecture
Fabric Switch
Mgmt. Switch
Base Enclosures
Redundant Fabric Switch
Expansion Enclosures with NVMe self encrypting Flash drives
Control Plane CP4D Compute
Control Plane
Per node - 192 GB RAM, dual socket total 16 cores
~½ compute is for control plane
OpenShift 3.11 with Helm
CP4D Compute CP4D Compute
CP4D Compute CP4D Compute
25 Gbps NIC Mellanox RDMA capable dual port cardWith FPGA Accelerator
4 x 1 or 4 TB NVMe drives
↓ (IBM Performance Server) Expansion unit ↓
Performance Server Performance Server
Performance Server Performance Server
Performance Server Performance Server
Performance Server Performance Server
25 Gbps NIC Mellanox RDMA capable dual port card With FPGA Accelerator
Cloud Pak
for Data
Base Unit
(Starter
Bundle)
(IBM
Performance
Server)
Expansion
Units
Control Plane

Performance Server Blades
140 cores 128 Cores / VPCs
Memory 896 GB 1.5 TB
Storage - RAW 148 TB (traditional HDD) 128 TB (NVMe)
Available User Space48 TB2 34 TB1
Performance 1X 3X+ (5-8x Twin Fin)
Footprint Full rack ~ 1/5 of a rack >50% reduction
Full
rac
k M
ako
Ap
pli
ance
1TPC-DS 10, 20 and 30 TB tests and App nexus, Catalina show ~3x query performance improvement over a full rack Mako
3x faster2
@ 1/5th foot print
IBM Performance Server Vs Full Rack N3001 Mako Appliance
Fabric Switch
Mgmt. Switch
Base Enclosures
Redundant Fabric Switch
Performance Server Expansion Enclosures with NVMe self encrypting Flash drives
Hyp
er
Co
nve
rge
d S
yste
m
2Multiply by 4 (assumes 4x compression) to calculate user data capacity
Cloud Pak
for Data
Base Unit
Performance
Server
Expansion
Units

CompatibleCompatible
Native Netezza Compatibility❑ Simple
• Load and Go, Minimal administration and Tuning
❑ Compatible
• 100% Netezza compatibility
• ”Fork-lift” existing Netezza/IBM PureData® System for Analytics (PDA) systems
• Simply use familiar ‘nz_migrate’ and go!
• Existing UDFs / UDXs work (requires re-compile)
• Bi-directional D/R Replication, Backup/Restore with older Netezza/PDA
❑ Smart with built-in FPGA Performance Accelerator
• Data Stream processing
• Machine Learning
• In-place Advanced Analytics & Geo Spatial
❑ Familiar interface and tools

Database Engine Enhancements
IBM Performance Server
❑ Modernization• Containerized for microservice architecture and deployment in kubernetes• UI upgraded to REACT based UI with same look and feel as IBM Cloud Pak for Data • Native Go (Lang) Driver implemented for modern day app connectivity• PostgreSQL compatible
❑ Serviceability• Maintenance prediction engine
❑ Hardware• Upgraded to 64-bit engine to take full advantage of memory• Upgraded to full NVMe (Non-Volatile Memory Express) support with NVMeOF
(NVMe over Fabrics) implementation for fast performance• FPGA (Field-programmable gate array) ready
❑ Differentiation• Multiple databases with Cross-database writes• Security Roles• Global temporary tables• Ability to take advantage of NVMe Drives• Hardware acceleration through FPGA
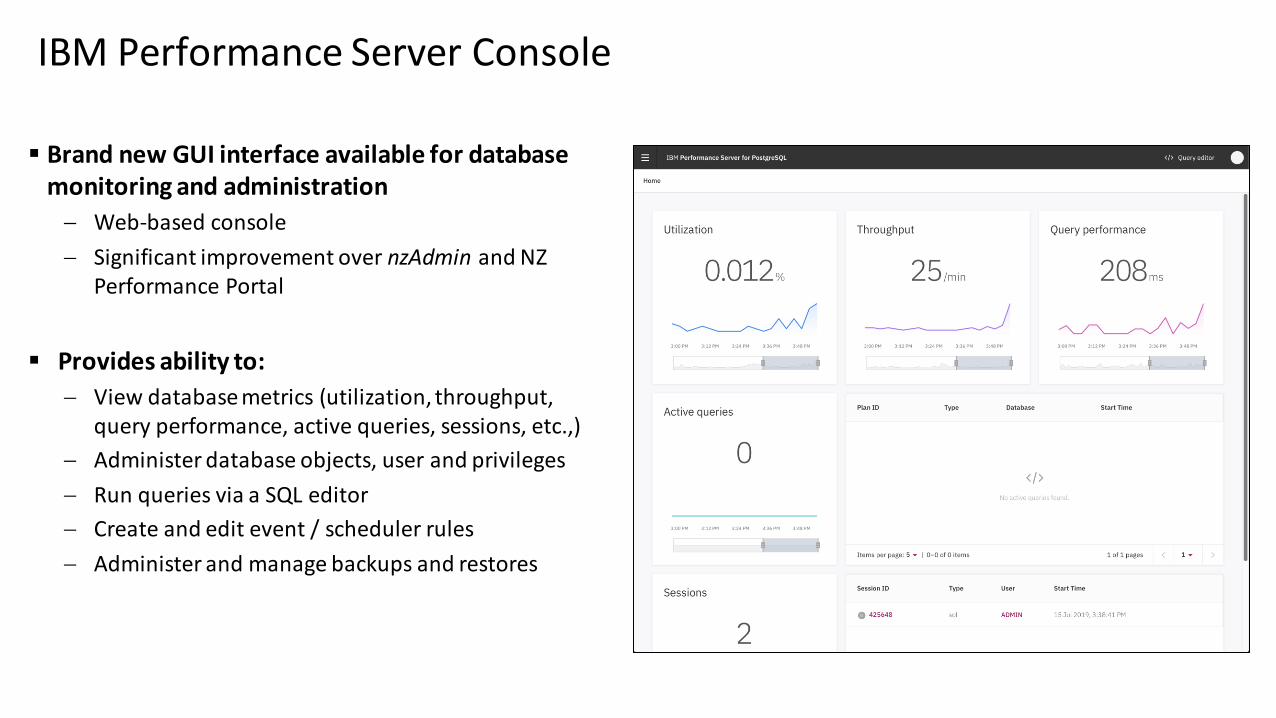
▪ Brand new GUI interface available for database monitoring and administration
− Web-based console
− Significant improvement over nzAdmin and NZ Performance Portal
▪ Provides ability to:
− View database metrics (utilization, throughput, query performance, active queries, sessions, etc.,)
− Administer database objects, user and privileges
− Run queries via a SQL editor
− Create and edit event / scheduler rules
− Administer and manage backups and restores
IBM Performance Server Console
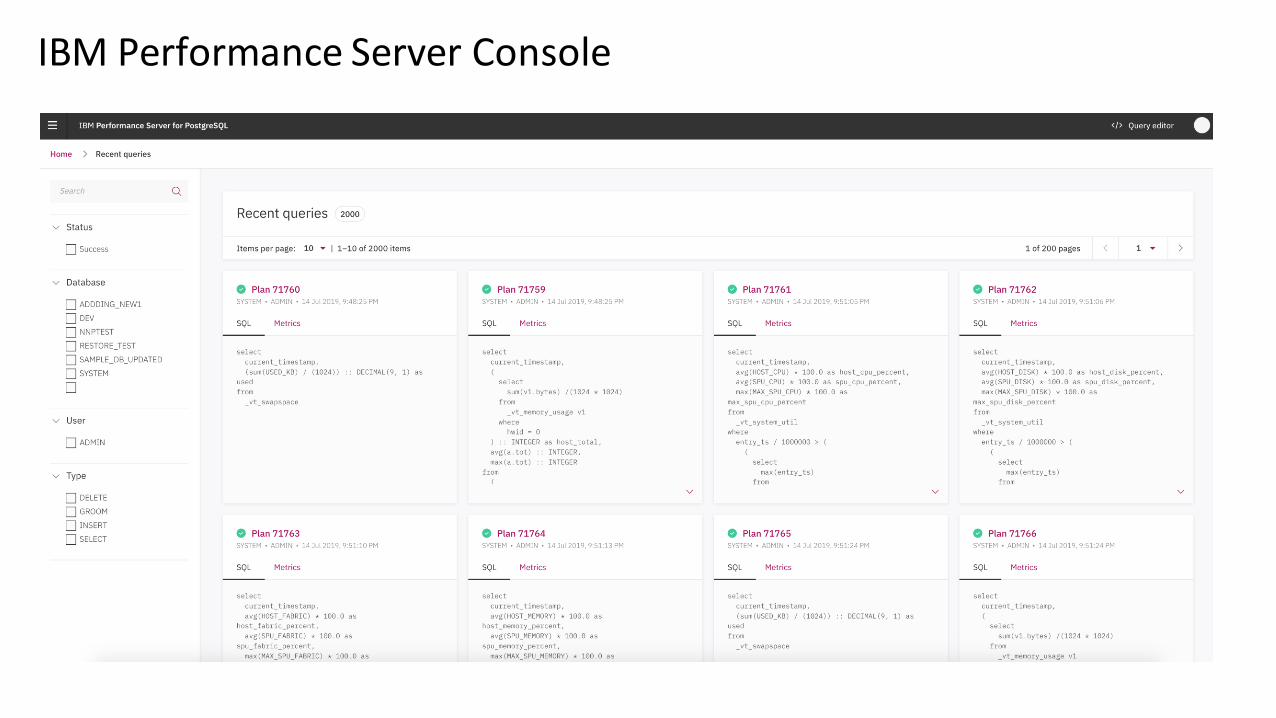
IBM Performance Server Console
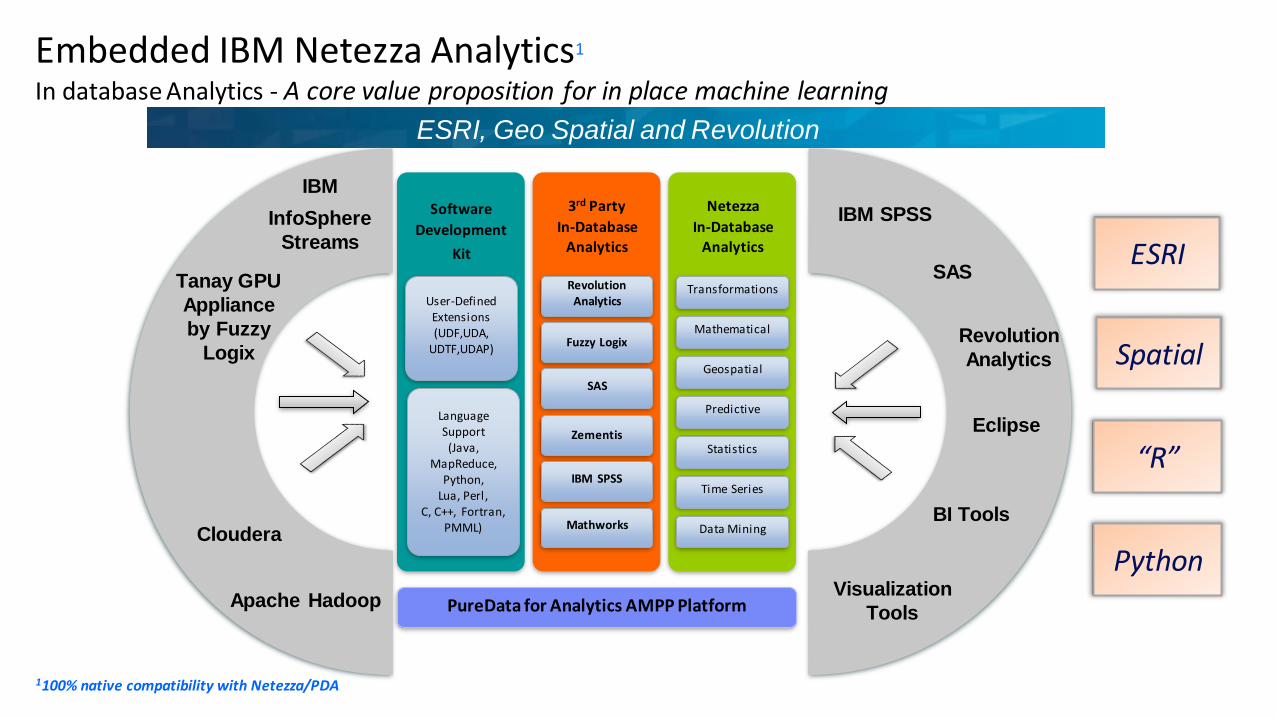
Embedded IBM Netezza Analytics1
In database Analytics - A core value proposition for in place machine learning
ESRI, Geo Spatial and Revolution
ESRI
“R”
Spatial
Python
1100% native compatibility with Netezza/PDA
PureData for Analytics AMPP Platform
Software
Development
Kit
3rd Party
In-Database
Analytics
Netezza
In-Database
Analytics
User-DefinedExtensions(UDF,UDA,
UDTF,UDAP)
Transformations
Mathematical
Geospatial
Predictive
Statistics
Time Series
Data Mining
Fuzzy Logix
SAS
IBM SPSS
Mathworks
Revolution Analytics
BI Tools
Visualization
Tools
Eclipse
Revolution
Analytics
SAS
IBM SPSS
Apache Hadoop
Cloudera
Tanay GPU
Appliance
by Fuzzy
Logix
IBM
InfoSphere
Streams
LanguageSupport
(Java,MapReduce,
Python, Lua, Perl,
C, C++, Fortran, PMML)
Zementis

Synergy with Data Integration and Reporting & Analysis Tools
SQL
O
DB
C
JD
BC
O
LE-D
B
SQL
O
DB
C
JD
BC
O
LE-D
B
Data In Data Out
Data Integration1 Reporting & Analysis1
▪ IBM
▪ Information Server
▪ InfoSphere Streams
▪ Ab Initio
▪ Hadoop
▪ Informatica
▪ Microsoft
▪ Oracle
▪ SAP
▪ SAS▪ Others using standard
ODBC/JDBC/OLE-DB/SQL
▪ IBM
▪ Cognos
▪ SPSS
▪ Campaign
▪ Hadoop
▪ Information Builders
▪ Microsoft
▪ MicroStrategy
▪ Oracle
▪ SAP
▪ SAS
▪ Tableau▪ Others using standard
ODBC/JDBC/OLE-DB/SQL
1100% native compatibility with Netezza/PDA

Data Virtualization
• High performance / Enterprise Ready
• Hybrid data store with extreme functionality
Service
Node
Cluster
Constellation
Caching
Policy
Data SourceNode
AnalyticsApplication
• Single data fabric for self-service
• DV gateway through Fluid Query
IBM
Performance Server

Back up & Restore
100% CompatibleWith existing Netezza/Pure Data System for Analytics
Lightning fast restore from backup if you should need it
▪ Build on External Table framework
▪ Backup and restore user data using nzbackup and nzrestore
▪ Supported backup types
− Full
− Differential
− Cumulative
▪ Connectors Supported
− File System Connector
− Veritas NetBackup Connector
− IBM Tivoli Storage Manager Connector
− EMC NetWorker

Netezza Tool Compatibility – 100% native Netezza compatibility
nz_abort nz_db_views_rowcount nz_dump_ext_table nz_get_ext_table_namesnz_altered_tables nz_ddl nz_find_acl_issues nz_get_ext_table_objidnz_backup nz_ddl_aggregate nz_find_control_chars_in_data nz_get_ext_table_ownernz_backup_size_estimate nz_ddl_all_grants nz_find_non_integer_strings nz_get_function_namenz_best_practices nz_ddl_comment nz_find_object nz_get_function_namesnz_build_html_help_output nz_ddl_database nz_find_object_orphans nz_get_function_signaturesnz_catalog_diff nz_ddl_diff nz_find_object_owners nz_get_group_namenz_catalog_dump nz_ddl_ext_table nz_find_table_orphans nz_get_group_namesnz_catalog_size nz_ddl_function nz_fix_acl nz_get_group_objidnz_change_owner nz_ddl_grant_group nz_format nz_get_group_ownernz_check_disks nz_ddl_grant_user nz_frag nz_get_group_usersnz_check_disk_scan_speeds nz_ddl_group nz_genc nz_get_lastTXidnz_check_spu nz_ddl_history_config nz_genstats nz_get_library_namenz_check_statistics nz_ddl_library nz_get nz_get_library_namesnz_check_views nz_ddl_mview nz_get_acl nz_get_mgmt_table_namenz_cksum nz_ddl_object nz_get_admin nz_get_mgmt_table_namesnz_clone nz_ddl_owner nz_get_aggregate_name nz_get_mgmt_view_namenz_columns nz_ddl_procedure nz_get_aggregate_names nz_get_mgmt_view_namesnz_compiler_check nz_ddl_scheduler_rule nz_get_aggregate_signatures nz_get_modelnz_compiler_stats nz_ddl_schema nz_get_column_attnum nz_get_mview_basenamenz_compressedTableRatio nz_ddl_security nz_get_column_name nz_get_mview_definitionnz_compress_old_files nz_ddl_sequence nz_get_column_names nz_get_mview_matrelidnz_core nz_ddl_synonym nz_get_column_oid nz_get_mview_namenz_coreAnalysis nz_ddl_sysdef nz_get_column_type nz_get_mview_namesnz_csv nz_ddl_table nz_get_database_name nz_get_mview_objidnz_db_group_access_listing nz_ddl_table_redesign nz_get_database_names nz_get_mview_ownernz_db_size nz_ddl_user nz_get_database_objid nz_get_object_namenz_db_tables_rowcount nz_ddl_view nz_get_database_owner nz_get_object_objidnz_db_tables_rowcount_statistic nz_ddl_view+ nz_get_database_table_column_names nz_get_object_ownernz_db_user_access_listing nz_dimension_or_fact nz_get_ext_table_name nz_get_object_type
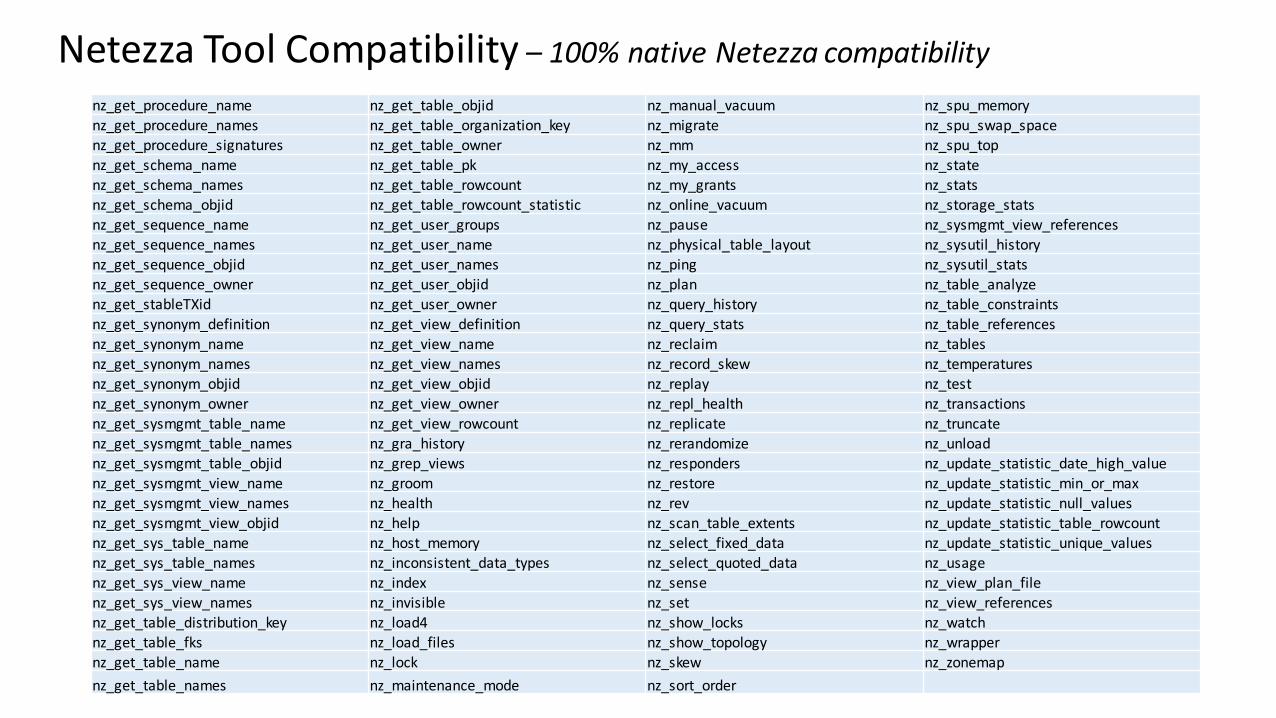
nz_get_procedure_name nz_get_table_objid nz_manual_vacuum nz_spu_memorynz_get_procedure_names nz_get_table_organization_key nz_migrate nz_spu_swap_spacenz_get_procedure_signatures nz_get_table_owner nz_mm nz_spu_topnz_get_schema_name nz_get_table_pk nz_my_access nz_statenz_get_schema_names nz_get_table_rowcount nz_my_grants nz_statsnz_get_schema_objid nz_get_table_rowcount_statistic nz_online_vacuum nz_storage_statsnz_get_sequence_name nz_get_user_groups nz_pause nz_sysmgmt_view_referencesnz_get_sequence_names nz_get_user_name nz_physical_table_layout nz_sysutil_historynz_get_sequence_objid nz_get_user_names nz_ping nz_sysutil_statsnz_get_sequence_owner nz_get_user_objid nz_plan nz_table_analyzenz_get_stableTXid nz_get_user_owner nz_query_history nz_table_constraintsnz_get_synonym_definition nz_get_view_definition nz_query_stats nz_table_referencesnz_get_synonym_name nz_get_view_name nz_reclaim nz_tablesnz_get_synonym_names nz_get_view_names nz_record_skew nz_temperaturesnz_get_synonym_objid nz_get_view_objid nz_replay nz_testnz_get_synonym_owner nz_get_view_owner nz_repl_health nz_transactionsnz_get_sysmgmt_table_name nz_get_view_rowcount nz_replicate nz_truncatenz_get_sysmgmt_table_names nz_gra_history nz_rerandomize nz_unloadnz_get_sysmgmt_table_objid nz_grep_views nz_responders nz_update_statistic_date_high_valuenz_get_sysmgmt_view_name nz_groom nz_restore nz_update_statistic_min_or_maxnz_get_sysmgmt_view_names nz_health nz_rev nz_update_statistic_null_valuesnz_get_sysmgmt_view_objid nz_help nz_scan_table_extents nz_update_statistic_table_rowcountnz_get_sys_table_name nz_host_memory nz_select_fixed_data nz_update_statistic_unique_valuesnz_get_sys_table_names nz_inconsistent_data_types nz_select_quoted_data nz_usagenz_get_sys_view_name nz_index nz_sense nz_view_plan_filenz_get_sys_view_names nz_invisible nz_set nz_view_referencesnz_get_table_distribution_key nz_load4 nz_show_locks nz_watchnz_get_table_fks nz_load_files nz_show_topology nz_wrappernz_get_table_name nz_lock nz_skew nz_zonemap
nz_get_table_names nz_maintenance_mode nz_sort_order
Netezza Tool Compatibility – 100% native Netezza compatibility

nzstate / nzsql / nzstats
[nz@e1n1 ~]$ nzstateSystem state is 'Online’.
[nz@e1n1 ~]$ nzsqlWelcome to nzsql, the IBM Netezza SQL interactive terminal.
Type: \h for help with SQL commands\? for help on internal slash commands\g or terminate with semicolon to execute query\q to quit
SYSTEM.ADMIN(ADMIN)=> \lList of databasesDATABASE | OWNER
--------------------+-------BAR70DS_10240B | PRODBAR70DS_10240B_ODS | PRODBAR70DS_10240B_STG | PRODDB1 | ADMINSYSTEM | ADMINTPCDS100 | PRODTPCH100 | PRODTPCH1000B | PROD
(8 rows)
[nz@e1n1 ~]$ nzstats
Field Name Value-------------------- ------------------------Name e1n1Description <sys description>Contact <contact name>Location <sys location>IP Addr 9.0.0.16Up Time 51263 secsUp Time Text 14 hrs, 14 mins, 23 secsDate 19-Sep-19, 03:03:40 EDTState 8State Text OnlineModel R8_BMSerial Num <serial #>Num SFIs 0Num SPAs 1Num SPUs 8Num Data Slices 224Num Hardware Issues 0Num Dataslice Issues 0

nzhw / nzsw
[nz@e1n1 ~]$ nzhwDescription HW ID Location Role State Security------------- ----- -------------------- ------ ------ --------Rack 1001 rack1 Active Ok N/ASPA 1002 spa1 Active Ok N/AHost 1003 rack1.host1 None None N/AHost 1004 rack1.host2 None None N/ASPU 1005 spa1.spu1 Active Online N/ASPU 1006 spa1.spu2 Active Online N/ASPU 1007 spa1.spu3 Active Online N/ASPU 1008 spa1.spu4 Active Online N/ASPU 1009 spa1.spu5 Active Online N/ASPU 1010 spa1.spu6 Active Online N/ASPU 1011 spa1.spu7 Active Online N/ASPU 1012 spa1.spu8 Active Online N/ADiskEnclosure 1013 spa1.diskEncl1 Active Ok N/ADisk 1014 spa1.diskEncl1.disk1 Active Ok DisabledDisk 1015 spa1.diskEncl1.disk2 Active Ok DisabledDisk 1016 spa1.diskEncl1.disk3 Active Ok DisabledDisk 1017 spa1.diskEncl1.disk4 Active Ok DisabledDiskEnclosure 1018 spa1.diskEncl2 Active Ok N/ADisk 1019 spa1.diskEncl2.disk1 Active Ok DisabledDisk 1020 spa1.diskEncl2.disk2 Active Ok DisabledDisk 1021 spa1.diskEncl2.disk3 Active Ok DisabledDisk 1022 spa1.diskEncl2.disk4 Active Ok DisabledDiskEnclosure 1023 spa1.diskEncl3 Active Ok N/ADisk 1024 spa1.diskEncl3.disk1 Active Ok DisabledDisk 1025 spa1.diskEncl3.disk2 Active Ok DisabledDisk 1026 spa1.diskEncl3.disk3 Active Ok DisabledDisk 1027 spa1.diskEncl3.disk4 Active Ok Disabled...
[nz@e1n1 ~]$ nzswPARAMETER | VALUE
------------------------+------------------------NPS Version | 11.0.1.0 [Build 0]NPS Uptime | 1 hr, 18 mins, 43 secsCatalog Version | 3.1792INZA Version | Not InstalledSQLEXT Toolkit Version | 11.0.0.0FDT Version | Not InstalledHPF Version | 100.0Model | R8_BMNumber of User DBs | 17Number of Data Slices | 224Replication State | Not ConfiguredQuery history DB | Not ConfiguredZone Maps | table orientedGoD | WLM based GoD enabled

Agenda
Performance Server Overview
Migration Methods
Migration Demo
Best Practices
Questions

▪Both IBM Netezza / PureData for Analytics and IBM Performance Server use the same database architecture and are 100% compatible
▪A migration from Netezza to Performance Server therefore does not require 3rd party/ external tools
▪The migration can be done by using nz* tools, available on every system
− Either through backup / restore (nzbackup & nzrestore)
− Or using the nz_migrate tool
Migration Overview

▪Choose the migration tool depending on your requirements (size of database, downtime requirements etc.)
▪nz_migrate with the -CreateTargetDatabase true option
−A migration is generally going to be much faster than an nzbackup / nzrestore
− It requires 0 external storage to be provisioned
− It provides a lot more flexibility and options (but more options means a bit more complexity)
−And this only supports a "full" migration of a table ... there is no support for "-differential”
▪nzbackup / nzrestore
− These tools are very simple and easy to use
− They support a "-differential" option if you are unable to do a data cut-over all at once
Migration Tooling

▪nzbackup --noData nz_migrate
− So, rather than using "nz_migrate -CreateTargetDatabase"
− We are using the "nzbackup -noData" option to move over just the DDL
− This is a slightly different way to accomplish much the same thing (they are very similar in nature)
− Then we would use nz_migrate to move over the actual data (and not involve itself with any of the DDL)
▪We could also use a COMBINATION of
− nz_migrate # to move over a "full copy" of the database
− nzbackup # to then perform any subsequent "-differential" backups to resync the databases after the fact
− For details on this feature, refer to the online help text for the "nz_migrate -backupset <backupsetid>" option
Migration Tooling (Cont’d)

▪Preparing your new appliance
▪Preparing for
− Creating OS users, if any
− OS hardening
▪Copy nzevent from old PDA machine
− Command : nzevent show -syntax
▪System Configuration and Database configuration
− /nz/data/config/system.cfg
− /nz/data/postgresql.conf
Pre-Migration Activity

▪Backing up database users, groups and permissions is very easy
− From source machine : nzbackup –globals –dir <>
− On target machine : nzrestore –globals –dir <>
▪Alternate method
− Utilize support tools: nz_ddl_users and nz_ddl_groups
− It generates create users and create groups commands along with grant permissions that can be applied on target machine
− It will also create your resource groups as defined on source machine
Backup database USERS and GROUPS

▪Once all your data is migrated, you can perform the following optional steps to further improve performance on the new environment:
− Run Groom on all database/tables : nz_groom <database> <table>
− Generate stats on all tables / databases : nz_genstats <database> <table>
Post Migration

Migration nz_migrate – all in one shot
• Utilize nz_migrate to migrate data from source system to Performance Server
• nz_migrate -sdb <> -tdb <> -shost <> -thost localhost –threads <> -status 60
• If you want nz_migrate to take care of database objects creation, use the following options:
• -CreateTargetDatabase YES -CreateTargetTable YES
Example syntax:#> /nz/support-IBM_Netezza-11.0.1-191011-0426/bin/nz_migrate \
-shost 192.168.50.129 \-tuser nz \-tpassword netezza \-thost 192.168.0.24 \-sdb TEST\-tdb TEST\-suser nz \-spassword netezza \-cksum fast \-genStats Full \-TruncateTargetTable YES \-CreateTargetDatabase YES \-CreateTargetTable YES \-format ascii \

▪ Use the following procedure if your downtime requirements are high.These are the same steps you would followed in a Netezza environment
− nz_migrate has option “-backupsetid”
− Use nz_migrate to migrate most chunk of data to target using nz_migrate
− While this is happening, one can continue using PDA with their regular operations
− Keep target up-to-date using incremental nzbackup on source followed by restore on target.
− Repeat for each database.
− Steps…
• Phase 1: migrate your global objects (users/ groups / resource groups)
• Phase 2: Migrate your databases / schemas
• Phase 3: Data reorganization for large tables ( > 10 M rows)
• Phase 4: Keeping target up-to-date with incrementals
• Phase 5: Unlocking the database when ready for cutover
Downtime Minimized Migration
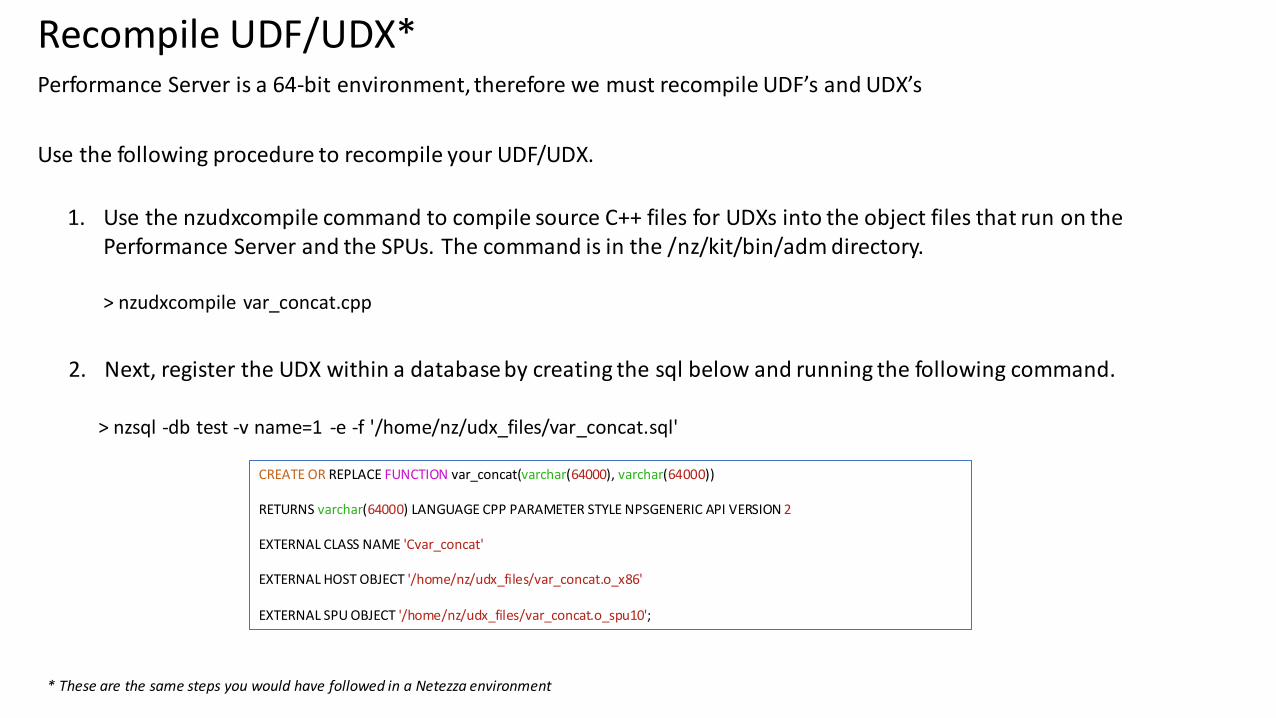
Performance Server is a 64-bit environment, therefore we must recompile UDF’s and UDX’s
Use the following procedure to recompile your UDF/UDX.
1. Use the nzudxcompile command to compile source C++ files for UDXs into the object files that run on the Performance Server and the SPUs. The command is in the /nz/kit/bin/adm directory.
> nzudxcompile var_concat.cpp
2. Next, register the UDX within a database by creating the sql below and running the following command.
> nzsql -db test -v name=1 -e -f '/home/nz/udx_files/var_concat.sql'
Recompile UDF/UDX*
CREATE OR REPLACE FUNCTION var_concat(varchar(64000), varchar(64000))
RETURNS varchar(64000) LANGUAGE CPP PARAMETER STYLE NPSGENERIC API VERSION 2
EXTERNAL CLASS NAME 'Cvar_concat'
EXTERNAL HOST OBJECT '/home/nz/udx_files/var_concat.o_x86'
EXTERNAL SPU OBJECT '/home/nz/udx_files/var_concat.o_spu10';
* These are the same steps you would have followed in a Netezza environment

Agenda
Performance Server Overview
Migration Methods
Migration Demo
Best Practices
Questions

▪ The video shows the following scenario
− Database BDI with 24 tables exists on IBM Netezza
− Database BDI does not exist on Performance Server
− Goal is to migrate BDI to Performance Server, using nz_migrate command
− Steps:
1. Verify that the database does not exist on target
2. Use the following command for the migration:
nz_migrate –sdb bdi –tdb bdi –shost pda –thost ips – CreateTargetDatabase yes
3. Verify that target database BDI was created: nzsql \l
4. Verify that all 24 tables have been created in the target: nzsql –d bdi –c “\d”
5. Verify that all rows have been migrated (using a SELECT COUNT(*) on all tables)
→ Database BDI successfully migrated!
Demo Scenario

Agenda
Performance Server Overview
Migration Methods
Migration Demo
Best Practices
Questions

• Performance Server (nzrev 11.x) and NPS 7.2.x are software compatible (Performance Server is a fork), but there are subtle operational differences
• Host runs inside a docker container on Performance Server unlike bare metal on a host• Different administration layers (platform commands like ap*)
• No nzadmin – use Cloud Pak/Performance Server web console microservice
• Networking• Customer connection is to the CP4D switch not to a host (similar to IBM Integrated Analytics System) • Uses OpenShift internal networking. Requires DNS wildcard. Cannot find web console without this being set up
• Roles vs. Groups• You can create user groups to organize users with similar privileges and tasks• You can also use roles to assign privileges to a number of users at a time
Key Things to keep in mind

Summary: IBM Performance Server for PostgreSQL
Fully compatible Get 100 percent compatibility with the existing IBM PureData® System for Analytics, including single-command frictionless migration for existing users.
Blazing fast With its open source design, IBM Performance Server for PostgreSQL is optimized for high-performance analytics, with built-in hardware acceleration.
Scalable and elastic Multitenancy architecture helps enable you to grow as you need on storage and compute.
Highly available Built on Red Hat OpenShift, IBM Performance Server for PostgreSQL is Kubernetes-container managed and is deployed through microservices.
Built-in machine learning Drive more value from your data with the ability to run in-database machine-learning models, using tools and advanced algorithms already preferred by data scientists and analytics professionals.
Simple Load and go, with minimal administration and tuning. Automatic discovery by IBM Cloud Pak for Data System can greatly reduce the required setup and expansion time.
Fully supported IBM Performance Server for PostgreSQL is production ready and fully supported by IBM — with unlimited use.
Added value Gain access to services that include IBM Data Virtualization, IBM Watson® Knowledge Catalog and others to propel your journey to AI.

• IBM Demos www.ibm.com/demos• Collection Cloud Pak for Data
• Video: IBM Cloud Pak for Data – Introduction to IBM Performance Server for PostgreSQLhttps://youtu.be/w0XvALy-i1A
• Product Tour: Explore IBM Performance Server for PostgreSQLhttps://www.ibm.com/cloud/garage/dte/producttour/explore-ibm-performance-server-postgresql
• Hands-on lab: IBM Performance Server for PostgreSQL: Getting to know the database environmenthttps://www.ibm.com/cloud/garage/dte/tutorial/ibm-performance-server-postgresql-getting-know-netezza-environment
• IBM Community:https://community.ibm.com/community/user/hybriddatamanagement/communities/community-home?CommunityKey=d9f9d5de-e89f-4a6a-84a0-31df8b81f182
• IBM Knowledge Center for Performance Server: https://www.ibm.com/support/knowledgecenter/en/SS5FPD_1.0.0/com.ibm.ips.doc/postgresql/intro.html
• IBM Product Pages• https://www.ibm.com/products/cloud-pak-for-data/system• https://www.ibm.com/analytics/netezza
Additional resources

Agenda
Performance Server Overview
Migration Methods
Migration Demo
Best Practices
Questions



















