Cheap and Fast – But is it Good? Evaluating Non-Expert Annotations for Natural Language Tasks
27
Cheap and Fast – But is it Good? Evaluating Non-Expert Annotations for Natural Language Tasks EMNLP 2008 Rion Snow CS Stanford Brendan O’Connor Dolores Labs Jurafsky Linguistics Stanford Andrew Y. Ng CS Stanford
-
Upload
colorado-lancaster -
Category
Documents
-
view
30 -
download
0
description
Cheap and Fast – But is it Good? Evaluating Non-Expert Annotations for Natural Language Tasks. EMNLP 2008 Rion Snow CS Stanford Brendan O’Connor Dolores Labs Jurafsky Linguistics Stanford Andrew Y. Ng CS Stanford. Agenda. Introduction Task Design: Amazon Mechanical Turk (AMT) - PowerPoint PPT Presentation
Transcript of Cheap and Fast – But is it Good? Evaluating Non-Expert Annotations for Natural Language Tasks

Cheap and Fast – But is it Good?Evaluating Non-Expert Annotations
for Natural Language TasksEMNLP 2008
Rion Snow CS StanfordBrendan O’Connor Dolores Labs
Jurafsky Linguistics StanfordAndrew Y. Ng CS Stanford

Agenda• Introduction• Task Design: Amazon Mechanical Turk (AMT)• Annotation Tasks– Affective Text Analysis– Word Similarity– Recognizing Textual Entailment (RTE)– Event Annotation– Word Sense Disambiguation (WSD)
• Bias Correction• Training with Non-Expert Annotations• Conclusion

Purpose
• Annotation is important for NLP research.• Annotation is expensive.– Time: annotator-hours– Money: financial cost
• Non-Expert Annotations– Quantity– Quality?

Motivation
• Amazon’s Mechanical Turk system– Cheap– Fast– Non-expert labelers over the Web
• Collect datasets from AMT instead of expert annotators.

Goal
• Comparing non-expert annotations with expert annotations on the same data in 5 typical NLP task.
• Providing a method for bias correction for non-expert labelers.
• Comparing machine learning classifiers trained on expert annotations vs. non-expert annotations.

Amazon Mechanical Turk (AMT)
• AMT is an online labor market where workers are paid small amounts of money to complete small tasks.
• Requesters can restrict which workers are allowed to annotate a task by requiring that all workers have a particular set of qualifications.
• Requesters can give a bonus to individual workers.
• Amazon handles all financial transactions.

Task Design
• Analyze the quality of non-expert annotations on five tasks.– Affective Text Analysis– Word Similarity– Recognizing Textual Entailment– Event Annotation– Word Sense Disambiguation
• For every task, authors collect 10 independent annotations for each unique item.

Affective Text Analysis
• Proposed by Strapparava & Mihalcea (2007)• Judging headlines with 6 emotions and a
valence value.• Emotions ranged in [0, 100]– Anger, disgust, fear, joy, sadness, and surprise.
• Valence ranged in [-100, 100]• Outcry at N Korea ‘nuclear test’
Anger Disgust Fear Joy Sadness Surprise Valence
30 30 30 0 20 40 -50

Expert and Non-Expert Correlations
5 Experts (E) and 10 Non-Experts (NE)

Non-Expert Correlation for Affect Recognition
Overall, 4 non-expert annotations per example to achieve the equivalent correlation as a single expert annotator.
3500 non-expert annotations / USD => 875 expert-equivalent annotations / USD

Word Similarity
• Proposed by Rubenstein & Goodenough (1965)
• Numerically Judging the word similarity for 30 word pairs on a scale of [0, 10].
• {boy, lad} => highly similar• {noon, string} => unrelated• 300 annotations completed by 10 labelers
within 11 minutes.
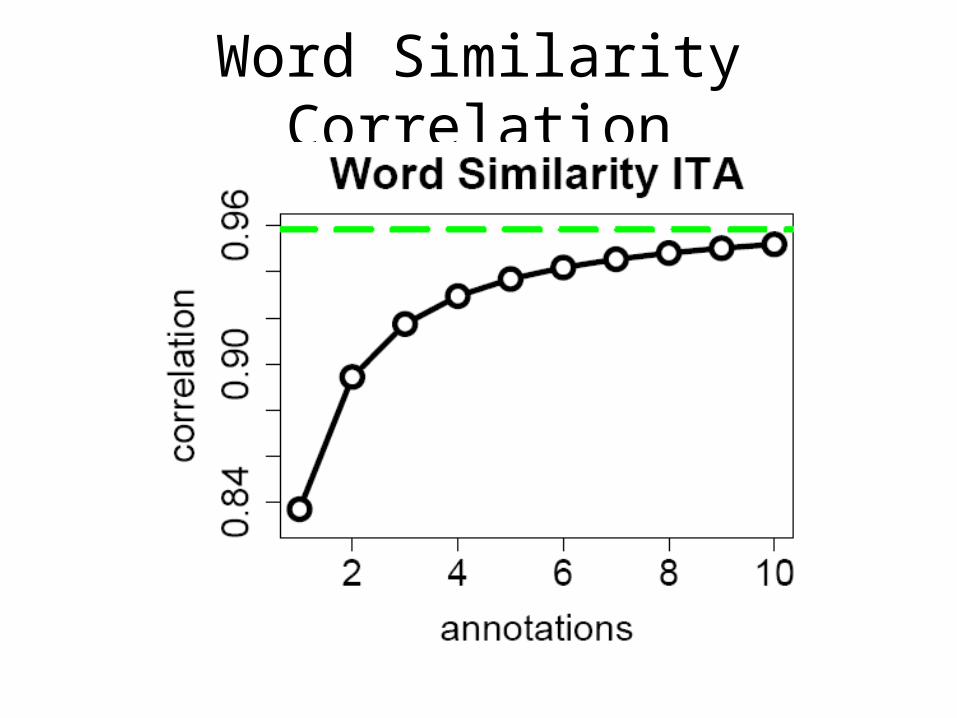
Word Similarity Correlation

Recognizing Textual Entailment
• Proposed in the PASCAL Recognizing Textual Entailment task (Dagan et al., 2006)
• Presented with 2 sentences and given a binary choice of whether the second hypothesis sentence can be inferred from the first.
• Oil Prices drop.– Crude Oil Prices Slump. (True)– The Government announced last week that it plans to
raise oil prices. (False)• 10 annotations each for all 800 sentence pairs.
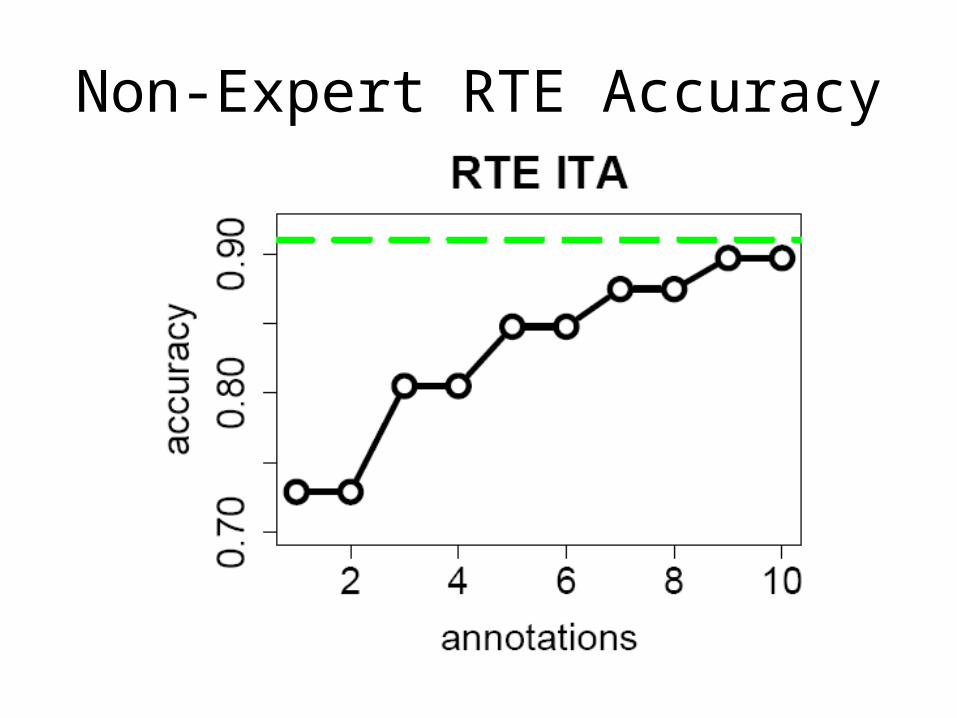
Non-Expert RTE Accuracy

Event Annotation
• Inspired by the TimeBank corpus (Pustejovsky et al., 2003)
• It just blew up in the air, and then we saw two fireballs go down to the water, and there was a big small, ah, smoke, from ah, coming up from that.
• Determine which event occurs first.• 4620 total annotations by 10 labelers.

Temporal Ordering Accuracy

Word Sense Disambiguation• SemEval Word Sense Disambiguation Lexical
Sample task (Pradhan et al., 2007)• Present the labeler with a paragraph of text
containing the word “present” and ask the labeler which one of the following three sense labels is most appropriate.– executive officer of a firm, corporation, or university.– head of a country.– head of the U.S., President of the United States
• 10 annotations for each of 177 examples given in SemEval.
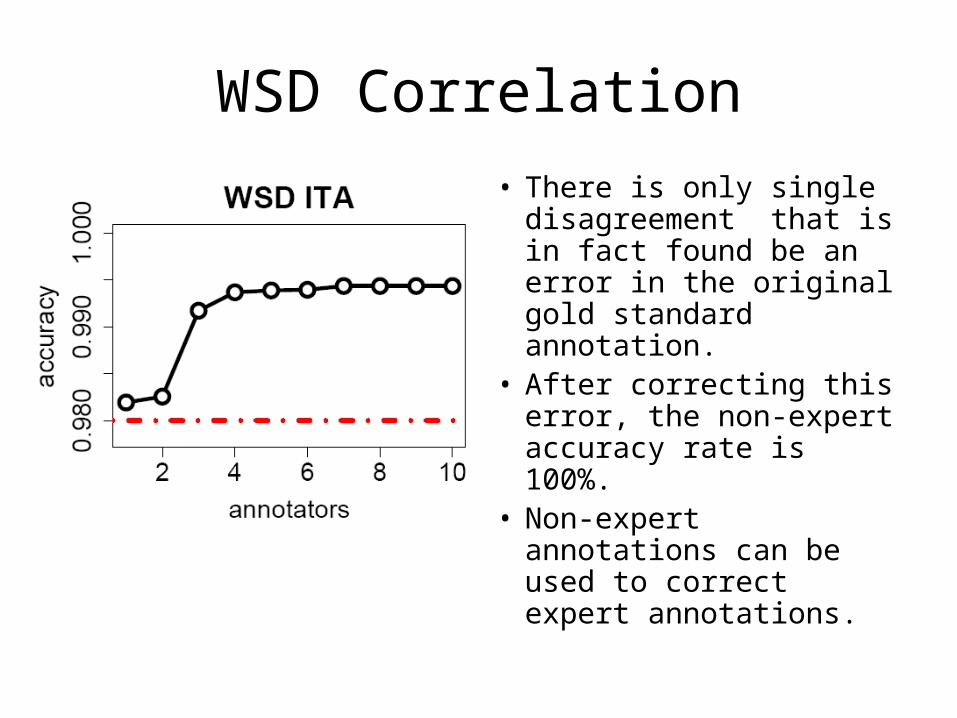
WSD Correlation
• There is only single disagreement that is in fact found be an error in the original gold standard annotation.
• After correcting this error, the non-expert accuracy rate is 100%.
• Non-expert annotations can be used to correct expert annotations.

Costs for Non-Expert Annotations
Time is given as the total amount of time in hours elapsed from submitting the requester to AMT until the last assignment is submitted by the last worker.

Bias Correction for Non-Expert Labelers
• More labelers.• Amazon’s compensation mechanism.• Model the reliability and biases of individual
labelers and correct for them.

Bias Correction Model for Categorical Data
• Using small expert-labeled sample to estimate labeler response likelihood.
• Each labeler’s vote is weighted by her log likelihood ratio for her given response.– Labelers who are more then 50% accurate have
positive votes.– Labelers whose judgments are pure noise have
zero votes.– Anti-correlated labelers have negative votes.

Bias Correction Results: RTE & Event Annotation
Evaluated with 20-fold cross-validation.

Training with Non-Expert Annotations
• Comparing a supervised affect recognition system with expert vs. non-expert annotations.
• bag-of-words unigram model similar to the SWAT system (Katz et al., 2007) on the SemEval Affective Text task.

Performance of Expert-Trained vs. Non-Expert-Trained Classifiers
Why is a single set of non-expert annotations better than a single expert annotation?

Conclusion
• It is effective using AMT for a variety of NLP annotation tasks.
• Only a small number of non-expert annotations per item are necessary to equal the performance of an expert annotator.
• Significant improvement by controlling for labeler bias.

THE END
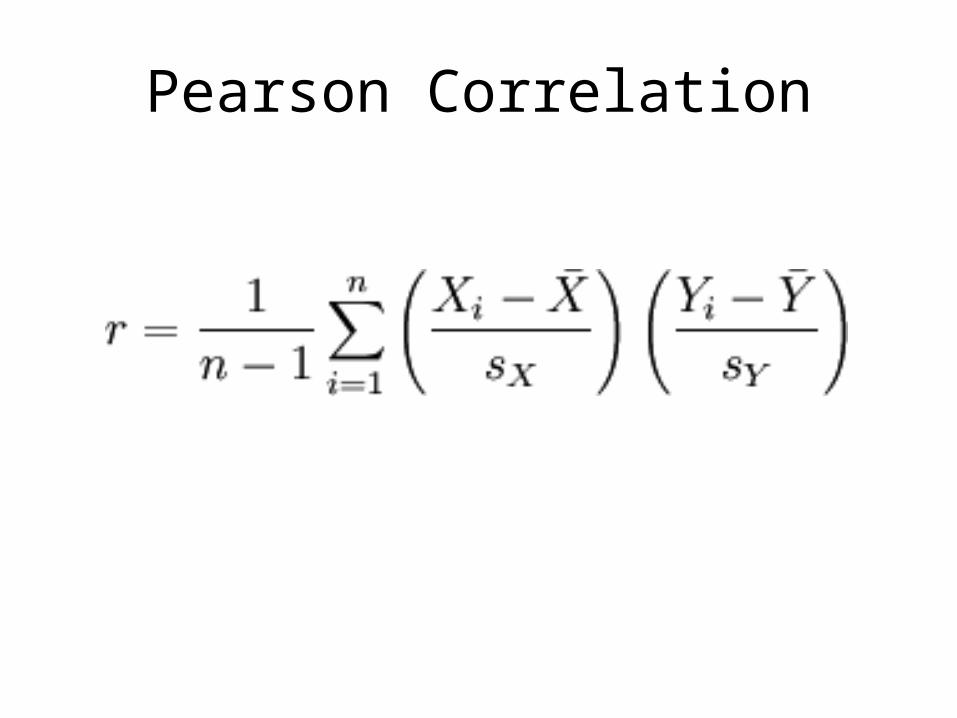
Pearson Correlation


















