
CHAPTER 4 PREPROCESSING FOR ENGLISH...
27
90 CHAPTER 4 PREPROCESSING FOR ENGLISH SENTENCE Current phrase based Statistical Machine Translation system does not use any linguistic information and it only operates on surface word form. It is shown that adding linguistic information helps to improve the translation process. Adding linguistic information can be done through preprocessing steps. On the other hand, machine translation system for language pair with disparate morphological structure needs best pre-processing or modeling before translation. This chapter explains about how preprocessing is applied on the raw source language sentence to make it more appropriate for translation. 4.1 MORPHO-SYNTACTIC INFORMATION OF ENGLISH LANGUAGE Grammar of a language is divided into syntax and morphology. Syntax is how words are combined to form a sentence and morphology deals with the formation of words. Morphology is also defined as the study of how meaningful units can be combined to form words. One of the reasons to process a morphology and syntax together in language processing is that a single word in a language is equivalent to combination of words in another. The term “morpho-syntax” is a hybrid word that comes from morphology and syntax. It plays a major role in processing different types of languages and it is also a related term to machine translation because the fundamental unit of machine translation is words and phrases. Retrieving the syntactic information is a primary step in pre-processing English language sentences. The tool which is used for retrieving syntactic structure from a given sentence is called parsing and which is used to retrieve morphological features from a word is called as morphological analyzer. Syntactic information includes dependency relation, syntactic structure and POS tag morphological information consists of lemma and morphological features. Klein and Manning (2003) [150] from Stanford University proposed a statistical technique for retrieving the syntactical structure of English sentences. Based on this technique a “Stanford Parser tool” was developed. This parser provides dependency relationship as well as phrase structure trees for a given sentence. Stanford parser
Transcript of CHAPTER 4 PREPROCESSING FOR ENGLISH...

90
CHAPTER 4
PREPROCESSING FOR ENGLISH SENTENCE
Current phrase based Statistical Machine Translation system does not use any linguistic
information and it only operates on surface word form. It is shown that adding
linguistic information helps to improve the translation process. Adding linguistic
information can be done through preprocessing steps. On the other hand, machine
translation system for language pair with disparate morphological structure needs best
pre-processing or modeling before translation. This chapter explains about how
preprocessing is applied on the raw source language sentence to make it more
appropriate for translation.
4.1 MORPHO-SYNTACTIC INFORMATION OF ENGLISH
LANGUAGE
Grammar of a language is divided into syntax and morphology. Syntax is how words
are combined to form a sentence and morphology deals with the formation of words.
Morphology is also defined as the study of how meaningful units can be combined to
form words. One of the reasons to process a morphology and syntax together in
language processing is that a single word in a language is equivalent to combination of
words in another. The term “morpho-syntax” is a hybrid word that comes from
morphology and syntax. It plays a major role in processing different types of languages
and it is also a related term to machine translation because the fundamental unit of
machine translation is words and phrases. Retrieving the syntactic information is a
primary step in pre-processing English language sentences. The tool which is used for
retrieving syntactic structure from a given sentence is called parsing and which is used
to retrieve morphological features from a word is called as morphological analyzer.
Syntactic information includes dependency relation, syntactic structure and POS tag
morphological information consists of lemma and morphological features.
Klein and Manning (2003) [150] from Stanford University proposed a statistical
technique for retrieving the syntactical structure of English sentences. Based on this
technique a “Stanford Parser tool” was developed. This parser provides dependency
relationship as well as phrase structure trees for a given sentence. Stanford parser

91
package is a Java implementation of probabilistic natural language parsers, such as
highly optimized PCFG and lexicalized dependency parsers, and a lexicalized PCFG
parser. The parser was also developed for other languages such as Chinese, Italian,
Bulgarian, and Portuguese. This parser uses the knowledge gained from hand-parsed
sentences to produce the most likely analysis of new sentences. In this pre-processing
Stanford parser is used to retrieve the morpho-syntactic information of English
sentences.
4.1.1 POS and Lemma Information
Part-of-Speech (POS) tagging is the task of labeling each word in a sentence with its
appropriate parts-of-speech like noun, verb, adjective, etc. This process takes an
untagged sentence as input then assigns a POS tag to words and produces tagged
sentences as output. The most widely used part of speech tagset for English is PennTree
bank tagset which is given in the Appendix-A. In this thesis, English sentences are
tagged using this tagset. POS and lemma of word forms are shown in Table 4.1. The
example shown bellow represents the POS tagging for English sentences.
English Sentence
The boy is going to the school.
Part-of-Speech Tagging
The/DT boy/NN is/VBZ going/VBG to/TO the/DT school/NN ./.
Table 4.1 POS and Lemma of Words
Word POS LemmaPlaying NN Playing
Playing VBG Play
Walked VBD Walk
Pens NNS Pen
Training VBG Train
Training NN Training
Trains NNS Train
Trains VBZ Train

92
Morphological analyzer or lemmatizer is used to find the lemma of a word.
Lemmas have special importance in highly inflected languages. Lemma is a dictionary
word or a root word. For example the word “play” is available in dictionary but other
word forms like playing, played, and plays aren’t available. So the word “play” is
called a lemma or dictionary word for the above mentioned word forms.
4.1.2 Syntactic Information
Syntactic information of a language is used in NLP tasks like Machine translation,
Question Answering, Information Extraction and Language Generation. Syntactic
information can be extracted from parsing. Parsing extracts the information such as
parts-of-speech tags, phrases and relationships between the words in the sentences. In
addition, from the parse tree of a sentence, noun phrases, verb phrases, and
prepositional phrases are also identified. Figure 4.1 shows an example of English
syntactic tree. The parser output is a tree structure with a sentence label as the root. The
example shown bellow indicates the syntactic information of English sentences.
Figure 4.1 Example of English Syntactic Tree

93
English Sentence
The boy is going to the school.
Parts of speech for each word
(NN = Noun, VBZ = Verb, DT = Determiner, VBG = Verbal Gerund)
S NP DT the NN boy VP VBZ is VP VBG going PP TO to NP DT the NN school
Parsing information
(ROOT (S (NP (DT The) (NN boy)) (VP (VBZ is) (VP (VBG going) (PP (TO to) (NP (DT the) (NN school))))) (. .)))
Phrases
Noun Phrases (NP): “the boy”, “the school”
Verb Phrases (VP): “is”, “going”
Sentences (S): “the boy is going to the school”
4.1.3 Dependency Information
Dependency information represents a relation between individual words. A typed
dependency parser additionally labels dependencies with grammatical relations, such as
subject, direct object, indirect object etc. It is used in several NLP applications and such
applications benefit particularly from having access to dependencies between words
typed with grammatical relations. Since these relations also provide information about
predicate-argument structure which is not readily available from phrase structure parse
trees. The Stanford typed dependency representation was designed to provide a simple
description of the grammatical relationships in a sentence. It can be easily understood
and used even by people without linguistic knowledge. It is also used to extract textual
relations. An example of the typed dependency relation for an English sentence is given
below.

94
English Sentence
The boy is going to the school.
Subject Verb Object
The boy is going to the school
Subject Verb Object
Typed dependencies
det(boy-2, The-1)
nsubj(going-4, boy-2)
aux(going-4, is-3)
root(ROOT-0, going-4)
prep(going-4, to-5)
det(school-7, the-6)
pobj(to-5, school-7)
4.2 DETAILS OF PREPROCESSING ENGLISH SENTENCES
Recently, SMT systems are introduced with linguistic information in order to address
the problem of word order and morphological variance between the language pairs.
This preprocessing of source language is done constantly on the training and testing
corpora. More source side pre-processing steps brings the source language sentence
closer to that of the target language sentence.
This section explains the preprocessing methods for English sentence to
improve the quality of English to Tamil Statistical Machine Translation system. The
preprocessing module for English language sentence includes three stages, which are
reordering, factorization and compounding. Figure 4.2 shows the preprocessing stages
of English language sentence. The first step in preprocessing English sentence is to
retrieve the linguistic features such as lemma, POS tag, and syntactic relations using
Stanford parser. These linguistic features along with the sentence will be subjected to
reordering and factorization stages. Reordering applies the reordering rules to the

95
syntactic trees for rearranging the phrases in the English sentence. Factorization takes
the surface words in the sentence and then factored using syntactic tool. This
information is appended to the words in the sentence. Part-of-Speech tags are
simplified and included as a factor in factorization. This factored sentence is given to
the compounding stage. Compounding is defined as adding additional morphological
information to the morphological factor of source (English) language words. Additional
morphological information includes function word, subject information, dependency
relations, auxiliary verbs, and model verbs. This information is based on the
morphological structure of the target language. After adding this information, few
function words, auxiliary information are removed and reordered information is
incorporated in integration phase.
Figure 4.2 Preprocessing Stages of English Sentence
Integration
English Sentence
Stanford Parser Tool
Compounding
Preprocessed English Sentence
Factorization Reordering

96
4.2.1 Reordering English Sentences
Reordering transforms the source language sentence into a word order that is closer to
that of the target language. Mostly in Machine Translation system the order of the
words in the source language sentence is often different from the words in the target
language sentence. The word-order difference between source and target languages is
one of the most significant errors in a Machine Translation system. Phrase based SMT
systems are limited for handling long distance reordering. A set of syntactic reordering
rules are developed and applied on the English language sentence to better align with
the Tamil sentence. The reordering rules elaborate the structural differences of English
and Tamil sentences. These transformation rules are applied to the parse trees of the
English source language. Parse trees are developed using Stanford parser tool. Quality
of parse trees plays an important role in syntactic reordering. In this thesis, the source
language is English and therefore the parses are more accurate and the reordering based
on the parses are exactly matched with target language. Generally, English parsers are
performing better than other language parsers because, English parsers developed from
longer and advanced statistical parsing techniques are applied.
Reordering is successfully applied for French to English (Xia and Mc-Cord,
2004) [151] and from German to English (Collins et al., 2005) translation system [152].
Xia and McCord (2004) used reordering rules to improve the translation quality, with
these reordering rules being automatically learned from the parse trees for both source
and target sentences [151]. Marta Ruiz Costa-juss`a 2006, proposes a novel reordering
algorithm for SMT [153]. They introduced two new approaches; they are block
reordering and Statistical Machine Reordering (SMR). The author also explains various
reordering methods like syntax based reordering and heuristic reordering in 2009 [154].
Ananthakrishnan R, et.al (2008) developed a syntactic and morphological
preprocessing for English to Hindi SMT system. They reorder the English source
sentence as per Hindi syntax, and segment the suffixes of Hindi for morphological
processing [155]. Recent developments showed an improvement in translation quality
when using the explicit syntax based reordering. One of these developments is the pre-
translation approach which alters the word order of source language sentence to target
language word order before translation. This is done based on predefined linguistic
rules that are either manually created or automatically learned from parallel corpora.

97
4.2.1.1 Syntactic Comparison between English and Tamil
This subdivision gives a closer look and notable differences between the syntax of
English and Tamil language. Syntax is a theory of sentence structure and it guides
reordering when translations between a language pair contain disparate sentence
structure. English and Tamil are from different language families. English is an Indo-
European language and Tamil is a Dravidian language. English has the word order of
Subject–Verb-Object (SVO) and Tamil has the word order of Subject-Object-Verb
(SOV). For example, the main verb of a Tamil sentence always comes at the end but in
English it comes between subject and object. English is a fixed word order language
where Tamil word order is flexible. Flexibility in word order represent that the order
may change freely without affecting the grammatical meaning of the sentence. While
translating from English to Tamil, English verbs have to be moved from after the
subject to end of the sentence.
English prepositions are postpositions in Tamil language. Tamil is a head-final
language also called as verb-final language. The Tamil verb comes at the end of the
clause. Demonstratives and modifiers precede the noun within the noun phrase. The
simplest Tamil sentence can consist of only two noun phrases, with no verb (even
linking verb) are present. For example, when a pronoun (இ ) idu 'this' is followed by
a noun ( த்தகம்) puththakam 'book', the sequence is translated into English 'This is a
book.' Tamil is a null subject language. Not all Tamil sentences have subjects, verbs,
and objects. It is possible to construct grammatically valid and meaningful sentences
using subject and verb only. For example, a sentence may only have a verb—such as
("completed")—or only a subject and object, without a verb such as (அ என் .)
athu envEdu ("That [is] my house").
Tamil language does not have a copula verb (a linking verb equivalent to the
word is). The word is included in the translations only to convey the meaning more
easily. Schiffman (1999) observed that Tamil syntax is the mirror-image of the order in
an English sentence, especially when there are relative clauses, quotations, adjectival
and adverbial clauses, conjoined verbal constructions, and aspectual and modal
auxiliaries, among others [156].

98
4.2.1.2 Reordering Methodology
Reordering is a first step which is applied in preprocessing of source language sentence.
Reordering is an important aspect for languages which differ in their syntactic structure.
Reordering rules are handcrafted using syntactic word order difference between English
and Tamil language. During training, English sentences in a parallel corpus are
reordered and in decoding, English sentence which is given for testing is reordered.
Lexicalized automatic reordering is implemented in Moses toolkit. This automatic
reordering is only better for short range sentences. Therefore external module is needed
for dealing the long range reordering. This reordering stage is also a way of indirectly
integrating syntactic information to the source language. The example given bellow
shows the reordering English sentences. The first sentence is the original English
sentence and the second sentence is pre-translation reordered source sentence and the
third sentence is the translated Tamil sentence.
English Sentence: I bought vegetables to my home.
Reordered English: I my to home vegetables bought
Tamil Sentence : நான் என் ைடய ட் ற்கு காய்கறிகள் வாங்கிேனன் .
( wAn ennudaiya vIddiRkku kAikaRikaL vAmginEn )
Figure 4.3 shows the method of reordering English sentences. English sentence
is given to the Stanford parser for retrieving syntactic information. After retrieving the
information, the English sentence is reordered using pre-defined syntactic rules. In
order to obtain the similar word order of the target language, reordering is applied in
source sentence prior to translation. 180 rules are developed according to the syntactic
difference between English and Tamil languages. Syntax-based rules are used to reorder
the English language sentence to better match the sentence with Tamil language. It is
applied to the English parse tree at the sentence level. The rule for reordering is
restricted to the particular language pair. Reordering will be carried out in phrases as
well as words. All the created rules are compared with the production rule of an English

99
sentence. If match is found then transformation is performed according to the target rule.
Examples of English reordering rules are shown in Table 4.2. All the rules are included
in Appendix B.
Figure 4.3 Process of Reordering
In general, PBSMT reordering performance goes down when encountering
unknown phrases or long sentences. The main advantage of reordering is word order
improvement in translation and better utilization of Phrase based SMT system [157].
Incorporating reordering in the search process implies a high computational cost.
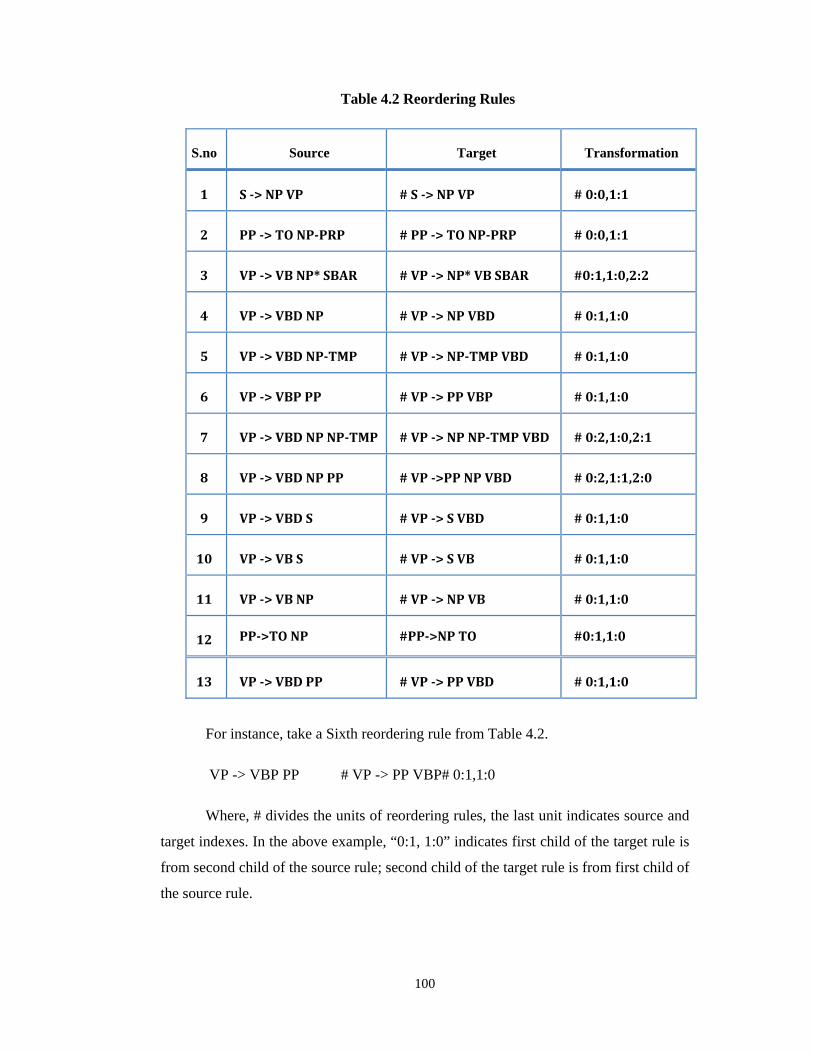
Reordering rules consists of three units (Table 4.2).
i. Production rules of original English sentence (source).
ii. Transformed production rules according to Tamil sentence (target).
iii. Source part numbers and target part numbers. These numbers indicate the
reorder of the source sentence (transformations).
Reordering Syntactic
Rules
Syntactic Information
English Sentence
Stanford Parser Tool
Reordered English Sentence
100
Table 4.2 Reordering Rules
S.no Source Target Transformation
1 S > NP VP # S > NP VP # 0:0,1:1
2 PP > TO NPPRP # PP > TO NPPRP # 0:0,1:1
3 VP > VB NP* SBAR # VP > NP* VB SBAR #0:1,1:0,2:2
4 VP > VBD NP # VP > NP VBD # 0:1,1:0
5 VP > VBD NPTMP # VP > NPTMP VBD # 0:1,1:0
6 VP > VBP PP # VP > PP VBP # 0:1,1:0
7 VP > VBD NP NPTMP # VP > NP NPTMP VBD # 0:2,1:0,2:1
8 VP > VBD NP PP # VP >PP NP VBD # 0:2,1:1,2:0
9 VP > VBD S # VP > S VBD # 0:1,1:0
10 VP > VB S # VP > S VB # 0:1,1:0
11 VP > VB NP # VP > NP VB # 0:1,1:0
12 PP>TO NP #PP>NP TO #0:1,1:0
13 VP > VBD PP # VP > PP VBD # 0:1,1:0
For instance, take a Sixth reordering rule from Table 4.2.
VP -> VBP PP # VP -> PP VBP# 0:1,1:0
Where, # divides the units of reordering rules, the last unit indicates source and
target indexes. In the above example, “0:1, 1:0” indicates first child of the target rule is
from second child of the source rule; second child of the target rule is from first child of
the source rule.

101
Source 0(VBP) 1(PP)
Target 1(PP) 0(VBP)
For example take an English sentence “I bought vegetables to my home” The
Syntactic tree for the sentence is shown in Figure 4.4.
English Sentence: I bought vegetables to my home.
Figure 4.4 English Syntactic Tree Production rules of English Sentence
i. S->NP VP
ii. VP->VBD NP PP
iii. PP->TO NP
iv. NP->PRP$ NN
The first production rule (i) S->NP VP is matched with the first reordering rule
in Table.4.2. The target transformation is same as the source pattern and therefore no
change in first production rule.
The next production rule (ii) VP->VBD NP PP is matched with the eighth
reordering rule in table and the transformation is 0:2 1:1 2:0 , it means that source
word order (0,1,2) is transformed into (2,1,0). (0,1,2) are the index of VBD NP and PP,

102
now the transformed pattern is PP NP VBD. This process is continuously applied to
each of the production rules. Finally the transformed production rule is given below.
Reordered Production rules of English sentence
i. S->NP VP
ii. VP->PP NP VBD
iii. PP->NP TO
iv. NP->NN PRP$
Reordered English Sentence: I my home to vegetables bought.
English parallel corpora which is used for training is reordered and the testing
sentences are also reordered. 80% of English sentences are reordered correctly
according to the rules which are developed. Original and reordered English sentences
are shown in Table 4.3. After reordering the English sentences are given to the
compounding stage.
Table 4.3 Original and Reordered Sentences
Original Sentences Reordered Sentences
I saw a beautiful child I a beautiful child saw
He came last week He last week came
Sharmi gave her book to Arthi Sharmi her book Arthi to gave
She went to shop for buying fruits She fruits buying for shop to went
Cat is sleeping on the table Cat the table on sleeping is.
4.2.2 Factoring English Sentence
The current phrase-based models are limited to the mapping of small text chunks
without the use of any explicit linguistic information like morphological and
syntactical. Such information plays a significant role in morphologically rich
languages. In other hand, for many language pairs, the availability of bilingual corpora
is very less. SMT performance is based on the quality and quantity of corpora. So, SMT
strictly needs a new method which uses linguistic information explicitly with fewer

103
amounts of parallel data. Philip Koehn and Hoang (2007) developed a Factored
translation framework for statistical translation models to tightly integrate linguistic
information [10]. It is an extension of phrase-based Statistical Machine Translation that
allows the integration of additional morphological and lexical information, such as
lemma, word class, gender, number, etc., at the word level on both source and the target
languages. Factoring English language sentence is a basic step in factored translation
system. Factored translation model is one way of representing morphological knowledge
to Statistical machine translation explicitly. Factors which are considered in pre-
processing and their description of English language are shown in Table.4.4. In this
example, word refers surface word, lemma represents the dictionary word or root word,
word class represents word-class category and morphology tag represents compound tag
which contains morphological information and/or function words. In some cases the
“morphology” tag, also contains the dependency relations and/or PNG information. For
instance, the English sentence, “I bought vegetables to my home”, is factored into
linguistic factors which are shown in Table.4.5. Factored representation of English
sentence is shown in Table 4.6.
Table 4.4 Description of Factors in English Word
FACTORS DESCRIPTION EXAMPLE
Word Surface words or word forms Coming,went,beautiful,eyes
Lemma Root word or Dictionary word Play,run,home,pen
Word Class Minimized POS tag N,V,ADJ,ADV
Morphology
POS tag, dependency information, function words, subject information, Auxilary and model verbs
VBD,NNS, nsubj,pobj, to,
has been,will

104
Table 4.5 Example of English Word Factors
Table 4.6 Factored Representation of English Language Sentence
English factorization is considered as one of the important pre-processing step.
Factorization splits the surface word into linguistic factors and integrates as a vector. 1Stanford Parser 1.6.5 Tool is used for Factorization
WORD LEMMA POSTAG W-C DEPLABEL
I I PRP PRP Nsubj
bought buy VBD V Root
vegetables vegetable NNS V Dobj
to to TO PRE Prep
my my PRP$ PRP Poss
home home NN N Pobj
WORD FACTORS 1
I i|PRP|PRP_nsubj
bought buy|V|VBD
vegetables vegetable|N|NNS_dobj
to to|PRE|TO_prep
my my|PRP|PRP$_poss
home home|N|NN_pobj

105
Instead of mapping surface words in translation, factored models maps the linguistic
units (factors) of language pair. Stanford Parser is used for factorizing English language
sentence. From the parser output, linguistic information such as, lemma, part-of-speech
tags, syntactic information and dependency information are retrieved. This linguistic
information is integrated as factors to the surface word.
4.2.3 Compounding English Language Sentence
A baseline Statistical Machine Translation (SMT) system only considers surface word
forms and does not use linguistic information. Translating into target surface word form
is not only dependent on the source word-form and it also depends on additional
morpho-syntactic information. While translating from morphologically simpler
language to morphological rich language, it is very hard to retrieve the required
morphological information from the source language sentence. This morphological
information is an important term for producing a target language word-form. The
preprocessing phase compounding is used to retrieve the required linguistic information
from source language sentence. Morphologically rich languages have a large number of
surface forms in the lexicon to compensate for a free word-order. This large number of
word-forms in Tamil language is very difficult to generate from English language
words. Compounding is defined as adding additional morphological information to
morphological factor of source (English) language words. Additional morphological
information includes subject information, dependency relations, auxiliary verbs, model
verbs and few function words. This information is based on the morphological structure
of Tamil language. In compounding phase, dependency relations are used to identify
the function words from the English factored corpora. During integration, few function
words are deleted from the factored sentence and attached as a morphological factor to
the corresponding content word.
In Tamil language, function words are not directly available but it is fused with
corresponding content word. So instead of making the sentences into similar
representation, function words are removed from an English sentence. This process
reduces the length of the English sentences. Like function words, auxiliary verbs and
model verbs are also identified and attached in morphological factor of head word of
source sentence. Now the morphological factor representation of the English language
106
sentence is similar to that of the Tamil language sentence. This compounding step
indirectly integrates dependency information into the source language factor.
4.2.3.1 Morphological Comparison between English and Tamil
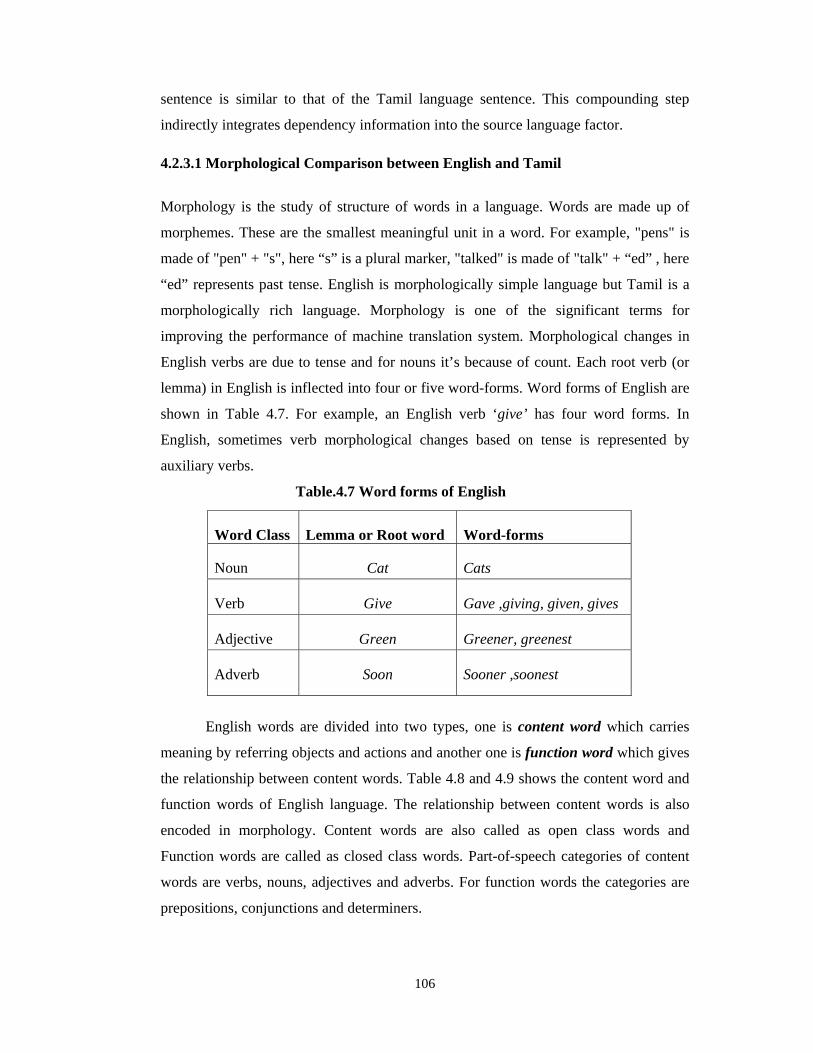
Morphology is the study of structure of words in a language. Words are made up of
morphemes. These are the smallest meaningful unit in a word. For example, "pens" is
made of "pen" + "s", here “s” is a plural marker, "talked" is made of "talk" + “ed” , here
“ed” represents past tense. English is morphologically simple language but Tamil is a
morphologically rich language. Morphology is one of the significant terms for
improving the performance of machine translation system. Morphological changes in
English verbs are due to tense and for nouns it’s because of count. Each root verb (or
lemma) in English is inflected into four or five word-forms. Word forms of English are
shown in Table 4.7. For example, an English verb ‘give’ has four word forms. In
English, sometimes verb morphological changes based on tense is represented by
auxiliary verbs.
Table.4.7 Word forms of English
English words are divided into two types, one is content word which carries
meaning by referring objects and actions and another one is function word which gives
the relationship between content words. Table 4.8 and 4.9 shows the content word and
function words of English language. The relationship between content words is also
encoded in morphology. Content words are also called as open class words and
Function words are called as closed class words. Part-of-speech categories of content
words are verbs, nouns, adjectives and adverbs. For function words the categories are
prepositions, conjunctions and determiners.
Word Class Lemma or Root word Word-forms
Noun Cat Cats
Verb Give Gave ,giving, given, gives
Adjective Green Greener, greenest
Adverb Soon Sooner ,soonest

107
Generally, languages not only differ in the word order but also differ in
encoding the relationship between words. English language is strictly in fixed word
order and involves heavy usage of function words but less usage in morphology. Tamil
language had a rich morphological structure and heavy usage of content word but free
word-order language.
Table 4.8 Content Words of English
Table.4.9 Function Words of English
Function Words Examples
Prepositions of, at, in, without, between
Pronouns he, they, anybody, it, one
Determiners the, a, that, my, more, much, either, neither
Conjunctions and, that, when, while, although, or
Modal verbs can, must, will, should, ought, need, used
Auxiliary verbs be (is, am, are), have, got, do
Particles no, not, nor, as
Content Words Examples
Nouns John, room, answer, Kumar
Adjectives happy, new, large, grey
Full verbs search, grow, hold, play
Adverbs really, completely, very, also, enough
Numerals one, thousand, first
Yes/No answers yes, no (as answers)

108
Because of the function words, the average number of words in English
sentences is more compared to the words in an equivalent Tamil sentence. Some of the
function words in English don’t exist in Tamil language because these words are
coupled with Tamil content words. English language contains more function words
than content words but Tamil language has more content words. Corresponding
translation of English function words are coupled in Tamil content word. While
translating from English to Tamil language, equivalent translation will not available for
English function words and this leads to the alignment problem. Table 4.10 shows the
various word forms based on English tenses
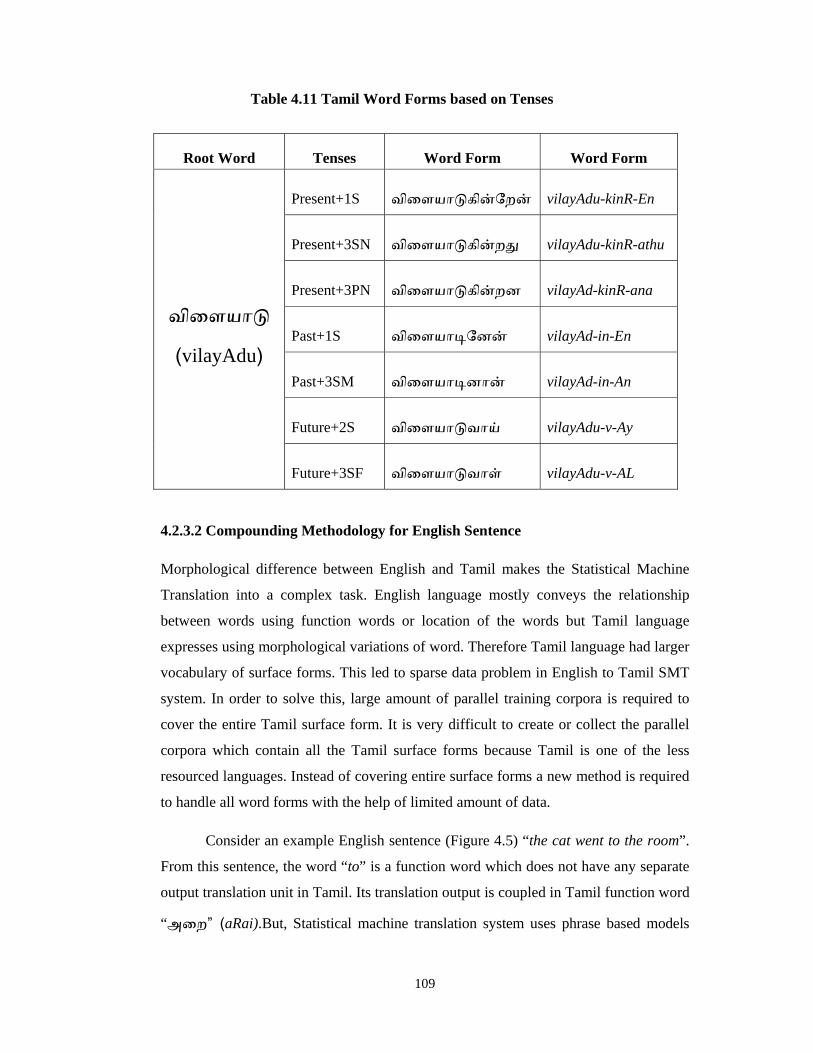
In Tamil, verbs are morphologically inflected due to tense and PNG (Person-
Number-Gender) markers and nouns are inflected due to count and cases. Each Tamil
verb root is inflected into more than ten thousand surface word forms because of
agglutinative nature of Tamil language. This morphological richness of Tamil language
leads to sparse data problem in Statistical Machine Translation system. Examples of
Tamil word forms based on tenses are given in Table 4.11.
Table 4.10 English Word Forms based on Tenses
Root Word Tenses Word Form
Play
Simple Present Play
Present Continuous is playing
Present Perfect have played
Past Played
Past perfect had played
Future will play
Future Perfect will have played
109
Table 4.11 Tamil Word Forms based on Tenses
4.2.3.2 Compounding Methodology for English Sentence
Morphological difference between English and Tamil makes the Statistical Machine
Translation into a complex task. English language mostly conveys the relationship
between words using function words or location of the words but Tamil language
expresses using morphological variations of word. Therefore Tamil language had larger
vocabulary of surface forms. This led to sparse data problem in English to Tamil SMT
system. In order to solve this, large amount of parallel training corpora is required to
cover the entire Tamil surface form. It is very difficult to create or collect the parallel
corpora which contain all the Tamil surface forms because Tamil is one of the less
resourced languages. Instead of covering entire surface forms a new method is required
to handle all word forms with the help of limited amount of data.
Consider an example English sentence (Figure 4.5) “the cat went to the room”.
From this sentence, the word “to” is a function word which does not have any separate
output translation unit in Tamil. Its translation output is coupled in Tamil function word
“அைற” (aRai).But, Statistical machine translation system uses phrase based models
Root Word Tenses Word Form Word Form
விைளயா
(vilayAdu)
Present+1S விைளயா கின்ேறன் vilayAdu-kinR-En
Present+3SN விைளயா கின்ற vilayAdu-kinR-athu
Present+3PN விைளயா கின்றன vilayAd-kinR-ana
Past+1S விைளயா ேனன் vilayAd-in-En
Past+3SM விைளயா னான் vilayAd-in-An
Future+2S விைளயா வாய் vilayAdu-v-Ay
Future+3SF விைளயா வாள் vilayAdu-v-AL

110
and it will consider “to the room” is a single phrase and it is aligned to the Tamil word
“அைறக்கு” (aRaikku) so there is no difficulty in alignment and decoding. Again the
problem is a raised for a new sentence which contains a phrase like “to the X” (eg. to the
school). Here X is considered as any noun. Even if X (or home) is available in bilingual
corpora, system cannot decode a correct translation for “to the X”. Because phrase based
SMT guess “to the X” is an unknown phrase even if X is aligned correctly. So the
function words should be treated separately prior to the SMT system. Here, these words
are taken care of by a preprocessing step called compounding. Compounding identifies
some of the function words and attaches to the morphological factor of related content
word in factored model. It retrieves morphological information of English content word
from dependency relations and function words.
Figure 4.5 English to Tamil Alignment
Compounding also identifies the subject information from English dependency
relations [158]. This subject information is folded into the morphological factor of
English verb and it helps to identify the PNG (Person-Number-Gender) marker for
Tamil language during translation. PNG marker plays an important role in Tamil
morphology due to the subject-verb agreement nature of Tamil language. Most of the
Tamil verbs are generated using this PNG marker. English auxiliary verbs are also
identified from the dependency information and then removed and folded in
morphological factor of the head word/verb. Figure 4.6 shows the block diagram of
compounding English language sentence. English sentence is factorized and then
subjected to the compounding phase. A word in factorized sentence includes part of
speech and morphological information as factors. Compounding takes dependency
relations from Stanford parser and produces the compounded sentences using pre-

111
defined linguistic rules. These rules are developed based on morphological difference
between English and Tamil language. This rule identifies the transformations from
English morphological factors to Tamil morphological factors. Sample compounding
rules are shown in Table 4.12. Based on the dependency information the rules are
developed.
Figure 4.6 Block Diagram for Compounding
Another important advantage of compounding is that it also used for solving the
difficulty of handling copula construction in English sentence. Copula is a special type
English Sentence
Stanford Parser
Update Morph
factor of
Child Word
Update Morph
factor of
Head Word
Deletion of
Function
words
Factorization
Compounded English Sentence
Dependency Information
Dependency Rules

112
of verb in English, while in other languages other parts of speech serve the role of
copula. Copula is used to link the subject of a sentence with a predicate and it is also
referred as a linking verb because it does not describe action. Example for copula
sentences is given bellow.
1. Sharmi is a doctor.
2. Mani and Arthi are lawyers.
1. Table 4.12 Compounding Rules for English Sentence
Alignment is one of the important features for improving the translation
performance. Compounding helps to improve the quality of word alignment and
reduces the length of the English sentences. Table 4.13 shows the average word count
in sentences. It also helps for target word generation indirectly. In this thesis, factored
SMT is used for only mapping the linguistic factors between English and Tamil
language. After compounding, morphological factor of English and Tamil words are
relatively more similar. Therefore now it is easy for SMT system to align and decode
morphological information. Table 4.14 and Table 4.15 shows the factored and
compounded sentences respectively. Reordered sentence is taken as input for
compounding.
Dependency
Information Removed Word
Morphological Features
Head Child
aux, auxpass Child Word +Child Word -
dobj - - +ACC
pobj Head word - +Head word
poss Child Word +poss -
nsubj - +Subject -

113
Table 4.13 Average Words per Sentence
Table 4.14 Factored English Sentence Table 4.15 Compounded English Sentence
4.2.4 Integrating Reordering and Compounding
Integration is the final stage in source side preprocessing. Here the preprocessed
English sentence is obtained from reordering and compounding stages. Reordering
takes the raw sentence and reorders according to the predefined rules. Compounding
takes the factored sentence and alters the morphological factors of the content words
using the compounding rules. Function words are identified in compounding stage.
From these function words few of them are removed during the integration process.
Figure.4.7 shows the integration process of preprocessing stages. Table.4.16 shows the
examples of preprocessed sentences.
Method Sentences Words Average words per Sentence
SMT/FSMT 8300 49632 5.98
C-FSMT 8300 33711 4.06
I | i | PN | prn
bought | buy | V | VBD
vegetables | vegetable | N | NNS
to | to | TO | TO
my | my | PN | PRP$
home | home | N | NN
I | i | PN | prn
bought | buy | V | VBD_i
vegetables | vegetable | N | NNS
to | to | TO | TO
my | my | PN | PRP$
home | home | N | NN_to

114
Original English sentence: I bought vegetables to my home. 0 1 2 3 4 5 Reordered English sentence: I my house to vegetables bought. 0 4 5 3 4 5 Factored English sentence: I | i | PN | prn bought | buy | V | VBD vegetables | vegetable | N | NNS
to | to | TO | TO my | my | PN | PRP$ home | home | N | NN
Compounded English sentence:
I | i | PN | prn bought | buy | V | VBD_i vegetables | vegetable | N | NNS
to | to | TO | TO my | my | PN | PRP$ home | home | N | NN_to
Preprocessed English sentence:
I | i | PN | prn_i my | my | PN | PRP$ home | home | N |NN_to vegetables | vegetable | N | NNS bought | buy | V | VBD_1S.
Figure 4.7 Integration Process
Factored Sentence
Compounded Sentence
Integration
Reordered Sentence
Preprocessed English Sentence
Function word Index

115
Table 4.16 Preprocessed English Sentences
Original Sentences Pre-processed Sentences
She may not come here she|she|PN|prp_she here|here|AD|adv
come|come|V|vb_3SF_may_not
I went to school I|i|PN|prp_i school|school|N|nn_to
went|go|V|vb.past_1S
I gave a book to him I|i|PN|prp_i a|a|AR|det book|book|N|nn_ACC
him|him|PN|prp_to gave|give|V|vb.past_1S
The cat was killing the rat
the|the|AR|det cat|cat|N|nn the|the|AR|det
rat|rat|N|nn_ACC
killing|kill|V|vb.prog_3SN_was
4.3 SUMMARY
This chapter presented linguistic preprocessing for English language sentence for better
matching with Tamil language sentence. Preprocessing stages includes reordering,
factoring and compounding. Finally integration process incorporates the stages. The
chapter has also presented the effect of syntactic and morphological variance between
English and Tamil language. It is showed that reordering and compounding rules
produce significant gain in Factored translation system. However, reordering plays an
important role especially for language pairs with disparate sentence structure. The
difference in word order between two languages is one of the most significant sources
of errors in Machine Translation. While phrase based MT systems do very well at
reordering inside short windows of words, long-distance reordering seems to be a
challenging task. The translation accuracy can be significantly improved if the
reordering is done prior to translation. Reordering rules which are developed here is
only valid for English and Tamil language. It also can be used for other Dravidian
languages with small modifications. In future, automatic rule creation for reordering
using bi-lingual corpora will improve the accuracy and this system is applicable for any
language pair also. Compounding and factoring are used in order to reduce the amount

116
of English-Tamil bilingual data. Preprocessing also reduces the number of words in
English sentence. Accuracy of preprocessing heavily depends on the quality of the
parser. Different researches have proven that preprocessing is the effective method in
order to obtain a word-order and morphological information which match the target
language. Moreover, this preprocessing approach can be generally applicable for other
languages which differ in word order and morphology. This research work has proved
that adding linguistic knowledge in preprocessing of training data can lead to
remarkable improvements in translation performance.


















