How We Used Cassandra/Solr to Build Real-Time Analytics Platform
Upload
edgar-shawCategory
view
233download
5
Cassandra TrainingIntroduction & Data Modeling

2 Introduction to Cassandra
Aims
• By the end of today you should know:
• How Cassandra organises data
• How to configure replicas
• How to choose between consistency and availability
• How to efficiently model data for both reads and writes
• You need to consider Active-Active scenarios
• Who to ask to help you & sign off on your data model
• HINT: Ask Neil directly or email [email protected].

3 Introduction to Cassandra
Agenda – 100ft
• Quick Introduction
• Data Structures
• Efficient Data Modeling
• Data Modeling Examples

6 Introduction to Cassandra
Elevator Pitch
What?
Write path optimised
Eventually consistent (ms)
Distributed Hash Table
Highly durable
Tunable consistency
10 Introduction to Cassandra
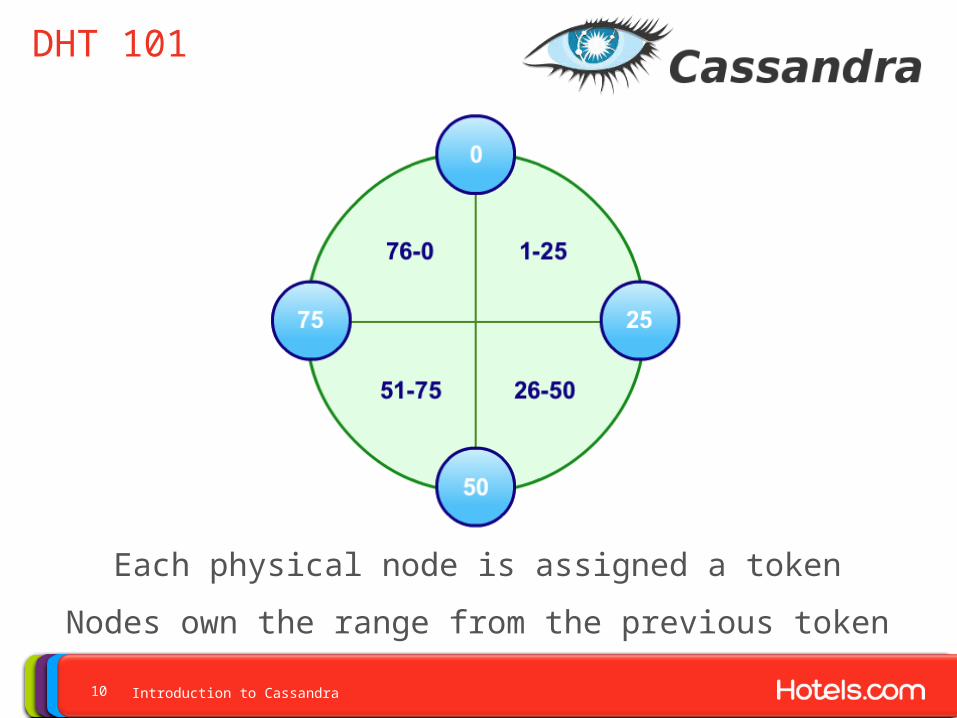
DHT 101
Each physical node is assigned a token
Nodes own the range from the previous token

11 Introduction to Cassandra
Cassandra Write Path
The coordinator will send the update to two nodes, starting at
the owning node and working clockwise
12 Introduction to Cassandra
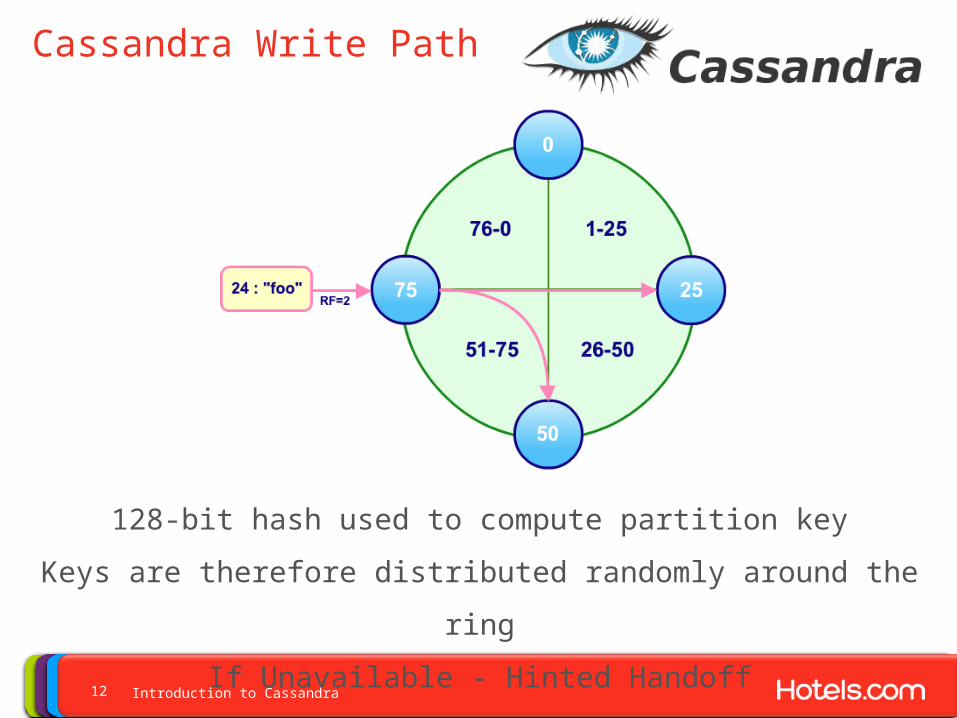
Cassandra Write Path
128-bit hash used to compute partition key
Keys are therefore distributed randomly around the ring
If Unavailable - Hinted Handoff

14 Introduction to Cassandra
Cassandra Write Path
• SSTables are sequential and immutable
• Data may reside across SSTables
• SSTables are periodically compacted together

15 Introduction to Cassandra
Cassandra Read Path
Data read command sent to closest replica - snitch
Digest commands sent to other replicas – CL
Read Repair Chance 10% - digest all replicas

16 Introduction to Cassandra
Start & Interrogate C*
• vagrant box add dse.box http://htraining.s3.amazonaws.com/dse.box
• mkdir ~/vagrant
• curl http://htraining.s3.amazonaws.com/vagrant-dse.tar.gz > ~/vagrant/dse.tar.gz
• cd ~/vagrant && tar xzvf dse.tar.gz
• cd dse && vagrant up
• vagrant ssh node1
• nodetool ring

17 Introduction to Cassandra
Cassandra Read Path
Read Mechanics
Find Candidate SSTables - Bloom Filters
Seek Through SSTables
Memory Mapped Files
Check Memtable
-> minimise sstables for best efficiency

18 Introduction to Cassandra
Deletion & Tombstones
Deleted data marked as removed – tombstone
Stops zombie data – distributed system
Tombstones collected after a few days – configurable

19 Introduction to Cassandra
Brewer’s Theorem
Distributed Data
– only 2 at a time –
Consistency
Availability
Partition Tolerance
20 Introduction to Cassandra
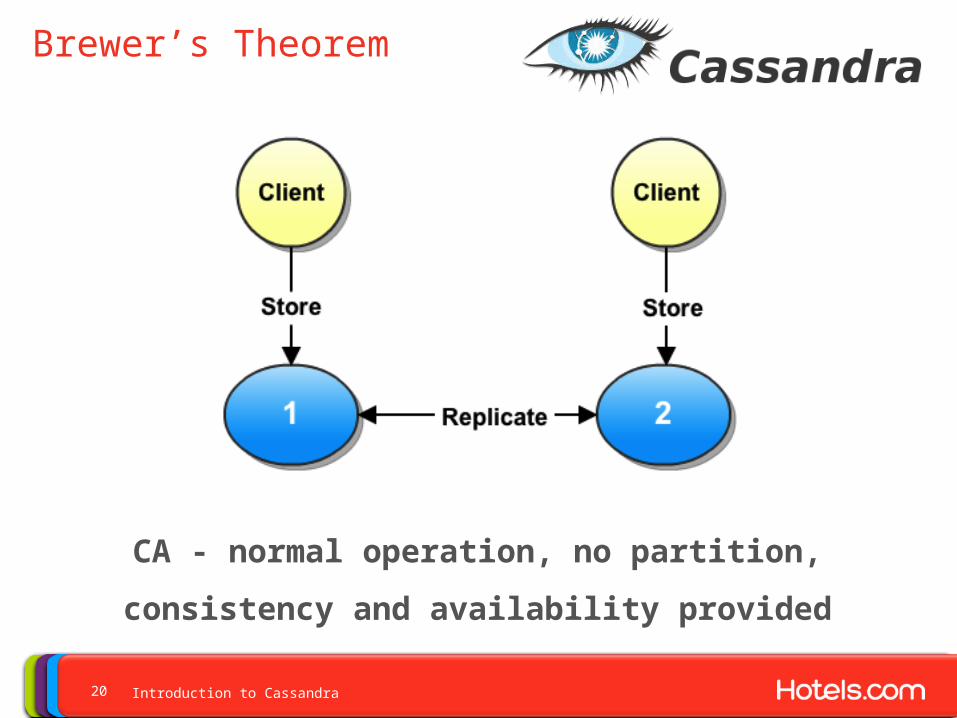
Brewer’s Theorem
CA - normal operation, no partition, consistency and
availability provided
21 Introduction to Cassandra
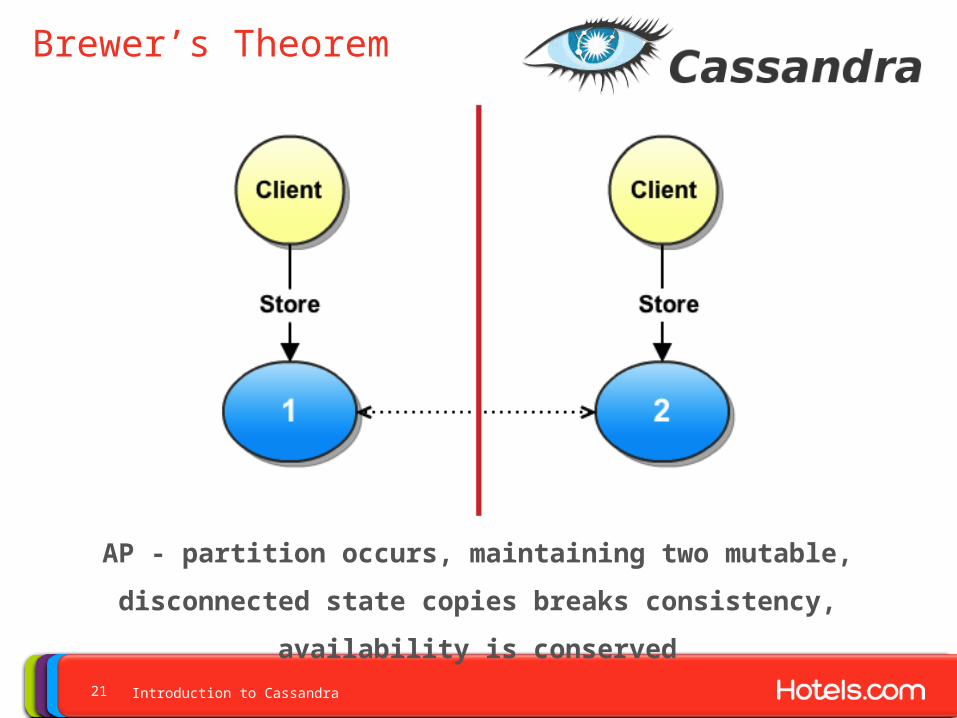
Brewer’s Theorem
AP - partition occurs, maintaining two mutable, disconnected state
copies breaks consistency, availability is conserved

22 Introduction to Cassandra
Brewer’s Theorem
CP - partition occurs, to maintain consistency we need to take one
side offline, sacrificing availability

23 Introduction to Cassandra
Tuneable Consistency
Cassandra Consistency Level
Specify node number to agree on read/write
Choose consistency or availability:
CL.LOCAL_QUORUM, CL.ONE
Eventual consistency will bring both sides into
agreement eventually

25 Introduction to Cassandra
Agenda – 100ft
• Quick Introduction
• Data Structures
• Efficient Data Modeling
• Data Modeling Examples

26 Introduction to Cassandra
Data Model
Keyspace
Analogous to Database/Schema
Segregate Applications
Replication configured at this level

27 Introduction to Cassandra
Data Model
Column Family
Analogous to Table
Contains many rows
Caches configurable at this level

28 Introduction to Cassandra
Data Model
Row
Each one has a partition key - hash
Has many columns – up to 2Bn
Columns don’t have to be defined ahead of time
Rows in the same CF can have different columns
No sorting by rows, model ordering in rows

29 Introduction to Cassandra
Data Model
Columns
Sorted by name before being written to SSTable
Name and Value are typed
Values can be type-validated
Column update is timestamped
Can have TTL

30 Introduction to Cassandra
Data Model
Counter Columns
Distributed counters
Can get false counts

31 Introduction to Cassandra
Data Model
Super Columns – Don’t Use
Blob of columns stored inside a single column
Have to read and write whole blob
Memory intensive
Conflicts resolved for whole blob - bad

32 Introduction to Cassandra
Secondary Indices
Can define an index on a column
Cassandra will maintain an inverted index
Use sparingly
Low Cardinality Columns Only
Often times better to maintain own view

33 Introduction to Cassandra
Thrift vs CQL
Thrift
Original interface, hash style syntax
CQL
SQL-like syntax but highly limited
Sent over Thrift but plans for own protocol

35 Introduction to Cassandra
Scaling Cassandra
Imagine RF=3, Quorum, Nodes=6
Each query impacts 2 nodes sync
Each write will touch all 3 nodes, though async
To scale writes add more nodes
To scale reads, add more replicas

37 Introduction to Cassandra
Agenda – 100ft
• Quick Introduction
• Data Structures
• Efficient Data Modeling
• Data Modeling Examples

39 Introduction to Cassandra
Data Modelling - Concepts
Rows in same CF will live on different nodes
High cost of multi-get
De-normalise your data into rows
Don’t Put Consistent Load on Single Row
Will heat up replica nodes

40 Introduction to Cassandra
Data Modelling - Concepts
Writes to Single Row Atomic & Isolated
Columns are Ordered
Column Range Slicing Efficient
Mutating data often needs compaction tuning

41 Introduction to Cassandra
Wide Rows
Efficient Reads
Store how you want to fetch
Fetch most efficient over few rows
Store what you want to fetch in few rows

42 Introduction to Cassandra
Time Series
Use Timestamp for Column Name – ordered
Range slicing efficient
Can limit row length by using date partition key
e.g. 20121004

43 Introduction to Cassandra
Composite Columns
Composite Column
e.g. time1:log_class, time1:log_message,
time2:log_class, time2:log_message

44 Introduction to Cassandra
Time Series
Writing to a Single Row Hotspots
Use Round Robin Over Rows
e.g. 20121004:1, 20121004:2, etc…

45 Introduction to Cassandra
Compound Keys
Compound Key in CQL3
Partition Key is the row key
Compound Key = Partition Key + Composite Key
e.g. partition key = 20121004, composite key = time1
20121004 => time1:name, time1:msg, time2:name, time2:msg

46 Introduction to Cassandra
Agenda – 100ft
• Quick Introduction
• Data Structures
• Efficient Data Modeling
• Data Modeling Examples

47 Introduction to Cassandra
Working with CQL
• cqlsh -3 192.168.33.21
• CREATE KEYSPACE my_app_data
WITH strategy_class = SimpleStrategy
AND strategy_options:replication_factor = 2;
• DESCRIBE KEYSPACE my_app_data;

48 Introduction to Cassandra
Compound Keys
USE my_app_data;
CREATE COLUMNFAMILY logs (
day text, -- partition key
log_id timeuuid, -- clustering column
log_class text,
log_message text,
primary key (day, log_id)
);
DESCRIBE columnfamilies;

49 Introduction to Cassandra
Compound Keys
INSERT INTO logs
(day,log_id,log_class,log_message)
VALUES (‘20130604’, ‘2013-06-04 10:05:00’, ‘error’, ‘it
broke’)
USING CONSISTENCY ONE;
INSERT INTO logs
(day,log_id,log_class,log_message)
VALUES (‘20130604’, ‘2013-06-04 11:05:00’, ‘error’, ‘it broke again’)
USING CONSISTENCY QUORUM;

50 Introduction to Cassandra
Compound Keys
SELECT * FROM logs USING CONSISTENCY ONE
WHERE
day=‘20130604’;
SELECT * FROM logs USING CONSISTENCY QUORUM
WHERE
day=‘20130604’
AND log_id > ‘2013-06-04
11:00:00’;
TRY WITH CL.TWO: vagrant suspend node2
Setting CL and range querying columns, losing consistency

51 Introduction to Cassandra
Compound Keys
cassandra-cli -h 192.168.33.21
use my_app_data;
list logs;
See the raw Cassandra data

52 Introduction to Cassandra
Code Example - Clients
Hector
Solid Java Client
In Use in Production
Round Robin
Node Discovery

53 Introduction to Cassandra
Code Example - Clients
Astyanax
Netflix Open Source Library
Simpler APIs

54 Introduction to Cassandra
Code Example
Example: Storing Payment Methods
https://github.com/neilbeveridge/example-compoundkeys

55 Introduction to Cassandra
Code Example
Requirements
Store 1-10 payment methods
Use a single row

56 Introduction to Cassandra
Code Example
Non-CQL
Define a composite column class
public static final class Composite {
private @Component(ordinal = 0)
String paymentUuid;
private @Component(ordinal = 1)
String field;

57 Introduction to Cassandra
Code Example
Writing Data
UUID paymentUUID = TimeUUIDUtils.getUniqueTimeUUIDinMillis();
String sPaymentUUID = paymentUUID.toString();
batch.withRow(PAYMENTS_CF, userId)
.putColumn(new Composite(sPaymentUUID, "pvtoken"), paymentInfo.pvToken, null)
.putColumn(new Composite(sPaymentUUID, "name"), paymentInfo.name, null)
.putColumn(new Composite(sPaymentUUID, "number"), paymentInfo.number, null)

58 Introduction to Cassandra
Code Example
Reading Data
Need some logic to handle record boundaries
//handle the payment info boundary
if (lastSeen != null && !column.getName().getPaymentUuid().equals(lastSeen)) {
payments.add(payment);
payment = new PaymentInfo();
payment.paymentUUID = UUID.fromString(column.getName().paymentUuid);
}
lastSeen = column.getName().getPaymentUuid();

59 Introduction to Cassandra
Code Example
A Bit Messy

60 Introduction to Cassandra
Code Example
CQL3
Need to define a Schema
Cassandra needs it to split up the row for us

61 Introduction to Cassandra
Code Example
Schema
create table paymentinfo_cql (
user text,
paymentid timeuuid,
name text,
number text,
pvtoken text,
primary key (user,paymentid)
);

62 Introduction to Cassandra
Code Example
Inserting Data
insert into paymentinfo_cql (
user, paymentid, name, number, pvtoken
) values (
'%1$s','%2$s','%3$s','%4$s','%5$s’
)

63 Introduction to Cassandra
Code Example
Reading Data
select * from paymentinfo_cql where user='%s

64 Introduction to Cassandra
Multi Datacentre Support
Cassandra RF=2 (availability), Solr RF=1 (offline search)
RFs set per Column Family and per logical datacentre

65 Introduction to Cassandra
Multi Datacentre Support
Both DCs participate in same ring
Cassandra walks clockwise as normal to fulfill RFs

66 Introduction to Cassandra
Performance Tuning Levers
Memory Mapped Files
SSTables memory mapped
Visible as high virtual memory consumption
Read fastest when working set fits in free RAM

67 Introduction to Cassandra
Performance Tuning Levers
Row Cache
Saves locating SSTables, seeking, reconciliation
Off-heap – IPC marshaling penalty
Whole row in memory
Good for small numbers of hot rows – Gaussian dist.

68 Introduction to Cassandra
Performance Tuning Levers
Key Cache
Saves seeking through SSTables
Beneficial for large SSTables - tiered compaction
On-heap
69 Introduction to Cassandra
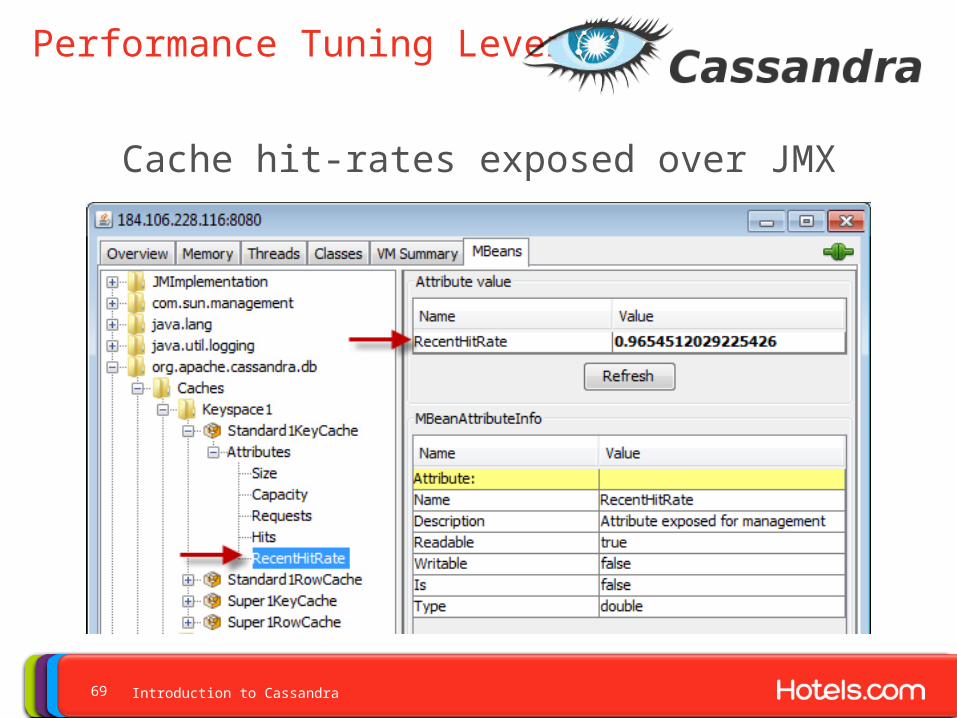
Performance Tuning Levers
Cache hit-rates exposed over JMX

70 Introduction to Cassandra
Performance Tuning Levers
Take care using memory that might be stolen from
the read path (VirtMem)

86 Introduction to Cassandra
Aims
• By the end of today you should know:
• How Cassandra organises data
• How to configure replicas
• How to choose between consistency and availability
• How to efficiently model data for both reads and writes
• You need to consider Active-Active scenarios
• Who to ask to help you & sign off on your data model
• HINT: Ask Neil directly or email [email protected].

87 Introduction to Cassandra
Code Example
Questions
htraining.s3.amazonaws.com/cassandra-training.pptx