CALIBRATION-FREE GAZE TRACKING USING...
6
CALIBRATION-FREE GAZE TRACKING USING PARTICLE FILTER PhiBang Nguyen, Julien Fleureau, Christel Chamaret, Philippe Guillotel Technicolor, 975 Ave. des Champs Blancs, 35576 Cesson-Sevigne, France [email protected] ABSTRACT This paper presents a novel approach for gaze estimation us- ing only a low-cost camera and requiring no calibration. The main idea is based on the center-bias property of human gaze distribution to get a coarse estimate of the current gaze posi- tion as well as benefit from temporal information to enhance this rough gaze estimate. Firstly, we propose a method for de- tecting the eye center location and a mapping model based on the center-bias effect to convert it to gaze position. This initial gaze estimate then serves to construct the likelihood model of the eye-appearance. The final gaze position is estimated by fusing the likelihood model with the prior information ob- tained from previous observations on the basis of the particle filtering framework. Extensive experiments demonstrate the good performance of the proposed system with an average estimation error of 3.43 ◦ which outperforms state-of-the-art methods. Furthermore, the low complexity of the proposed system makes it suitable for real-time applications. Index Terms— HCI, gaze estimation, eye center detec- tion, calibration-free, particle filter 1. INTRODUCTION Gaze estimation plays an important role in different domains, especially in human-computer-interaction since it gives a more efficient and interactive way for dealing with computer. However, existing gaze sensing systems are still far from be- ing widely used in everyday applications because of two main reasons: i) the cost of such systems is still high, essentially due to the embedded devices, ii) most systems require a cali- bration procedure to infer certain person-specific eye parame- ters (i.e., model-based methods) or to regress the correspond- ing mapping function between the eye appearances and the gaze positions on the screen (i.e., appearance-based methods). Such a process is quite cumbersome, uncomfortable and dif- ficult to be done. Moreover, in some situations such as con- sumer home applications (e.g., interactive gaming interfaces, adaptive content selection interfaces) active calibration is al- most impossible because the gaze estimation is required to be imperceptible to users. In the literature, some efforts to avoid calibration have been recently proposed. In [1], Sugano et al. exploit the user mouse’s cursor as an additional information for an implicit calibration. Each time the user clicks, the cursor position (considered as the gaze point) together with the corresponding eye image fea- tures are collected as a labeled sample. The system predicts a new gaze point by linearly interpolating from its nearest neighbors obtained from the labeled samples. The method achieves an accuracy of about 5 ◦ but requires a large num- ber of clicked points (i.e., ≈ 1500 points) and is restricted to specific contexts where there is a physical interaction be- tween the user and the computer. More recently, researchers have focused their attention on using visual saliency to avoid calibration since the computational model of saliency may be interpreted as the gaze probability distribution and hence, may be exploited for gaze estimation. One of the early at- tempts in this new direction was coined by Sugano et al. [2]. The idea behind the scene is relatively simple: i) mapping between eye appearances and gaze points is done by using the Gaussian process regression (GPR), ii) the gaze samples required for training the GPR are created by repeatedly ran- dom sampling on the saliency maps. In order to reduce the computational cost, eye images that are similar to each other (as well as the corresponding saliency maps) are averaged as they are supposed to belong to the same fixation. The method achieves a mean estimation error of 6.3 ◦ . Although it is considered as the first attempt to use the computational model of saliency for a passive calibration, this approach has some limits. Firstly, the method is completely based on vi- sual saliency (which is not always reliable) to acquire train- ing samples, the method might not be able to handle situa- tions where the prediction accuracy of saliency maps is very low (e.g., in scenes containing many instantaneous salient re- gions, during top-down tasks such as object-specific search or text reading). Secondly, in order to go into operating mode, the system needs an off-line and time-consuming training be- forehand (i.e., users have to do 10 minutes of training be- fore each 10-minute test). Thirdly, the number of sampled gaze points (required for the GPR) has to be large enough to successfully approximate the gaze probability distribution. This significantly increases the computational cost. In [3], Chen et al. also integrate visual saliency into their existing model-based gaze estimation system in order to avoid ”per- sonal calibration”. Their main idea is based on inferences in a Bayesian network model relating the stimulus, the gaze and
Transcript of CALIBRATION-FREE GAZE TRACKING USING...

CALIBRATION-FREE GAZE TRACKING USING PARTICLE FILTER
PhiBang Nguyen, Julien Fleureau, Christel Chamaret, Philippe Guillotel
Technicolor, 975 Ave. des Champs Blancs, 35576 Cesson-Sevigne, [email protected]
ABSTRACT
This paper presents a novel approach for gaze estimation us-ing only a low-cost camera and requiring no calibration. Themain idea is based on the center-bias property of human gazedistribution to get a coarse estimate of the current gaze posi-tion as well as benefit from temporal information to enhancethis rough gaze estimate. Firstly, we propose a method for de-tecting the eye center location and a mapping model based onthe center-bias effect to convert it to gaze position. This initialgaze estimate then serves to construct the likelihood modelof the eye-appearance. The final gaze position is estimatedby fusing the likelihood model with the prior information ob-tained from previous observations on the basis of the particlefiltering framework. Extensive experiments demonstrate thegood performance of the proposed system with an averageestimation error of 3.43◦ which outperforms state-of-the-artmethods. Furthermore, the low complexity of the proposedsystem makes it suitable for real-time applications.
Index Terms— HCI, gaze estimation, eye center detec-tion, calibration-free, particle filter
1. INTRODUCTION
Gaze estimation plays an important role in different domains,especially in human-computer-interaction since it gives amore efficient and interactive way for dealing with computer.However, existing gaze sensing systems are still far from be-ing widely used in everyday applications because of two mainreasons: i) the cost of such systems is still high, essentiallydue to the embedded devices, ii) most systems require a cali-bration procedure to infer certain person-specific eye parame-ters (i.e., model-based methods) or to regress the correspond-ing mapping function between the eye appearances and thegaze positions on the screen (i.e., appearance-based methods).Such a process is quite cumbersome, uncomfortable and dif-ficult to be done. Moreover, in some situations such as con-sumer home applications (e.g., interactive gaming interfaces,adaptive content selection interfaces) active calibration is al-most impossible because the gaze estimation is required to beimperceptible to users. In the literature, some efforts to avoidcalibration have been recently proposed.
In [1], Sugano et al. exploit the user mouse’s cursor as
an additional information for an implicit calibration. Eachtime the user clicks, the cursor position (considered as thegaze point) together with the corresponding eye image fea-tures are collected as a labeled sample. The system predictsa new gaze point by linearly interpolating from its nearestneighbors obtained from the labeled samples. The methodachieves an accuracy of about 5◦ but requires a large num-ber of clicked points (i.e., ≈ 1500 points) and is restrictedto specific contexts where there is a physical interaction be-tween the user and the computer. More recently, researchershave focused their attention on using visual saliency to avoidcalibration since the computational model of saliency maybe interpreted as the gaze probability distribution and hence,may be exploited for gaze estimation. One of the early at-tempts in this new direction was coined by Sugano et al. [2].The idea behind the scene is relatively simple: i) mappingbetween eye appearances and gaze points is done by usingthe Gaussian process regression (GPR), ii) the gaze samplesrequired for training the GPR are created by repeatedly ran-dom sampling on the saliency maps. In order to reduce thecomputational cost, eye images that are similar to each other(as well as the corresponding saliency maps) are averagedas they are supposed to belong to the same fixation. Themethod achieves a mean estimation error of 6.3◦. Althoughit is considered as the first attempt to use the computationalmodel of saliency for a passive calibration, this approach hassome limits. Firstly, the method is completely based on vi-sual saliency (which is not always reliable) to acquire train-ing samples, the method might not be able to handle situa-tions where the prediction accuracy of saliency maps is verylow (e.g., in scenes containing many instantaneous salient re-gions, during top-down tasks such as object-specific search ortext reading). Secondly, in order to go into operating mode,the system needs an off-line and time-consuming training be-forehand (i.e., users have to do 10 minutes of training be-fore each 10-minute test). Thirdly, the number of sampledgaze points (required for the GPR) has to be large enoughto successfully approximate the gaze probability distribution.This significantly increases the computational cost. In [3],Chen et al. also integrate visual saliency into their existingmodel-based gaze estimation system in order to avoid ”per-sonal calibration”. Their main idea is based on inferences ina Bayesian network model relating the stimulus, the gaze and

the eye parameters and modeling (i.e., approximating) someprobabilistic densities by Gaussian distributions to estimatethe subject’s visual axis. The gaze point is then derived as theintersection between the estimated visual axis and the screen.The algorithm has a better performance than the Sugano etal.’s with a mean error of about 2◦ and allows head move-ments ( which are not supported by Sugano et al’s method).However, these good results come with an expense which re-quires multiple IR cameras and light sources within a com-plex configuration [4]. Furthermore, their method is specificfor static images and requires a longer learning time to im-prove the accuracy, i.e., users need to look at an image for3− 4 seconds to reach an accuracy of about 2◦.
In this paper, we develop a novel approach for calibration-free gaze estimation that requires only one low-cost camerawith the assumption that user’s head is fixed for the sake ofsimplicity. Differently from methods in [2] and [3] which aretotally based on saliency to avoid calibration, we exploit in-stead, the center-bias effect to achieve calibration-free. Thebasic idea is to obtain a rough estimation of the gaze positionfrom the eye center location with the help of the center-biaseffect. This gaze position is served to build the likelihoodof the eye appearance. The final gaze position is refined byfusing the eye likelihood together with the temporal informa-tion obtained from past observations on the basis of a particlefiltering framework.
2. PROPOSED APPROACH
We formulate the gaze estimation as a probabilistic problemof estimating the posterior probability p(gt|e1:t) (where gtand et are the current gaze position and eye appearance, re-spectively). By applying the Bayes’ rule, we obtain:
p(gt|e1:t) ∝ p(et|gt)p(gt|e1:t−1). (1)
In this equation, the posterior density p(gt|e1:t) can beestimated via the prior probability p(gt|e1:t−1) (the predictionof the current state gt given the previous measurements) andthe likelihood p(et|gt).
Equation 1 characterizes a dynamic system with one statevariable g and the observation e. The gaze position distribu-tion is assumed to follow a first-order Markov process, i.e.,the current state only depends on the previous state. This as-sumption is strongly valid for fixation and smooth-pursuit eyemovements. In a saccadic eye movement, the current gazeposition can also be considered as dependent on the previousgaze position if it is modeled by a distribution having a suffi-ciently large scale as described in Section 2.1.
The particle filtering framework [5] can be adopted tosolve this problem. Theoretically, particle filter based meth-ods approximate the posterior density p(gt|e1:t) via two steps:
1. Prediction: the current state is predicted from the pre-
vious observations e1:t−1
p(gt|e1:t−1) =
∫p(gt|gt−1)p(gt−1|e1:t−1)det−1. (2)
2. Update: the estimation of the current state is updatedwith the incoming observation et using the Bayes’ rule
p(gt|e1:t) ∝ p(et|gt)p(gt|e1:t−1). (3)
The posterior distribution p(gt|e1:t) is approximated bya set of N particles {git}i=1,...,N associated to their weightwi
t. N is empirically set to 5000 which seems to offer a goodtrade-off between the computational cost and the desired ac-curacy (i.e., as the eye gaze may spread over large distanceswhile object movements are often restricted to a smaller areaaround its previous state). In our experiments, this parame-ter does not have a critical impact on the system performance(i.e., a greater number of particles does not improve the fi-nal results). Usually, we cannot draw samples from p(gt|e1:t)directly, but rather from the so-called ”proposal distribution”q(gt|g1:t−1, e1:t) for which q(.) can be chosen under someconstraints. The weights are updated by:
wit = wi
t−1
p(et|git)p(git|git−1)
q(git|gi1:t−1, e1:t). (4)
We choose p(gt|gt−1) as the proposal distribution result-ing in a bootstrap filter with an easy implementation. Thisway, weight updating is simply reduced to the computationof the likelihood. In order to avoid degeneracy problem, re-sampling is also adopted to replace the old set of particles bythe new set of equally weighted particles according to theirimportant weights.
2.1. State Transition Model
Intuitively, fixation and smooth-pursuit eye movements canbe successfully modeled by a distribution whose peak is cen-tered at the previous gaze position state gt−1 (e.g., Gaussiandistribution). Otherwise, for a saccadic eye movement, an-other Gaussian distribution centered at the previous gaze po-sition can also be used but with a much larger scale to describethe uncertainty property of the saccade. Hence, the state tran-sition should be modeled by a Gaussian mixture of two den-sities. However, for the sake of simplicity, we adopt a uniquedistribution for both types of eye movement:
p(gt|gt−1) = ℵ(gt−1; diag(σ2)). (5)
where diag(σ2) is the diagonal covariance matrix which cor-responds to the variance of each independent variable xt andyt (the gaze point being denoted as a two dimensional vectorgt = (xt, yt)).
σ2 needs to be large enough to cover all possible rangesof the gaze on the display in order to model the saccadic eyemovement. We set σ = 1/3 the screen dimensions.

2.2. Likelihood Model
In the context of object tracking, the likelihood p(gt|et) is of-ten computed by a similarity measure between the current ob-servation and the existing object model. For gaze estimation,we model p(gt|et) as follows:
p(gt|et) ∝ exp(−λd(et)). (6)
where λ is the parameter which determines the ”peaky shape”of the distribution and d(et) = ‖et − et‖2 denotes a distancemeasure between the current observation et and the estimatedeye image et (corresponding to the particle position gt).
Since the system is calibration-free, we do not have accessto training images to estimate et. Hence, we propose a simplemethod to estimate p(gt|et) via the detection of the eye cen-ter position and the center-bias effect. This estimation goesthrough two steps described as below.
2.2.1. Eye Center Localization
The most common approach to locate eye center is based onthe natural circular shape of the eye [6], [7], [8]. In gen-eral, shape-based methods require edge detection (or gradientcomputation) as a preprocessing step that is very sensitive tonoise or shape deformations. Moreover, a few of them couldbe used for real time applications due to their high compu-tational cost. We propose here a fast and simple eye centerlocalization and tracking scheme using color cues. Since theuser head is fixed, the subjects face is supposed to be roughlybounded in a predefined rectangle (in the real system, we usea face detection algorithm) and the rough eye regions are de-termined based on anthropometric relations. The algorithmconsists of the following major steps:
1. Converting the eye image into the Y CbCr space2. Based on statistical observations of color eye images
that pixels in pupil region usually have high values in Cb com-ponent and low values in Y and Cr components, an eye centerheat map (HM ) can be determined as follows:
HM(x, y) = Cb(x, y)(1− Cr(x, y))(1− Y (x, y)). (7)
3. All sub-regions that may be the pupil region are thenextracted using the region growing method. To do so, localmaxima larger than a predefined threshold T1 are chosen asseed points. 4-connected regions around each seed point arethen built by growing all pixels whose values are higher than apredefined threshold T2. The selected points are then dynam-ically added to the set of ”candidate points” and the processis continued until we go to the end of the eye region. Empir-ically, we set T1 = 0.98 and T2 = 0.85 to obtain the bestperformance.
4. The heat map is then smoothed by convolving with aGaussian kernel. The use of a Gaussian filter here is importantto stabilize the detection result (i.e., avoiding wrong detectiondue to eyelid, eye glass, reflextion).
2 4 6 8 10 12 14 16 18 20
2
4
6
8
10
12
14
16
18
20
2 4 6 8 10 12 14 16 18 20
2
4
6
8
10
12
14
16
18
20
2 4 6 8 10 12 14 16 18 20
2
4
6
8
10
12
14
16
18
20
Fig. 1. Average spatial histograms of gaze positions recordedby the SMI gaze tracker for Movie viewing (left), Televisionviewing (middle) and Web browsing (right).
5. Finally, the eye center location (xc, yc) is estimated bya weighted voting of all candidate points:
(xc, yc) =
∑(x,y)∈PR HM(x, y).(x, y)∑
(x,y)∈PR HM(x, y). (8)
where PR is the set of candidate points.
2.2.2. Conversion from eye center position to gaze position
The gaze distribution is known to be biased toward the centerof the screen in free viewing mode [9] [10]. Such an effectcould be observed in Fig. 1. In this experiment, we recordgaze position by a commercial eye tracker when users are inthree screen viewing activities: movie watching, televisionwatching and web browsing. 4 observers are asked to watch8 video sequences (i.e., 4 movie clips and 4 television clips,each of 10 minutes). For the web browsing activity, the sub-jects are free to choose 5 favorite web sites to browse dur-ing 10 minutes. The results are then averages on all stim-uli and all subjects. A strong center-bias effect may be ob-served for the movie and television viewing activities whenthe gaze positions are distributed in a very narrow region lo-cated at the middle of the screen. For the web browsing activ-ity, the center-bias is also noticeable despite a large dispersionof gaze distribution around the center.
Based on this statistic property, the ”observed gaze” posi-tion gt = (xgt , ygt) (normalized into [0 1]) can be determinedfrom the current eye center coordinates (xc, yc) (in the eyeimage) by the following simple projection model:
xg = 0.5 + 0.5xc − xc
Axσxc
,
yg = 0.5 + 0.5yc − ycAyσyc
. (9)
where xg and yg are the convert gaze positions;- xc and yc are the current eye center positions in absolute
image coordinates.- xc, yc, σxc and σyc are respectively the mean values and
the standard deviation values of xc and yc. These parametersare continuously computed and updated during the process;
- Ax and Ay are tuning factors which describe the ”scales”of the gaze distribution. They are empirically set to 4 that islarge enough to quantify the center-bias level.

Fig. 2. Examples of successful eye center detection. All thehuman faces are blurred due to privacy protection.
The resulting likelihood can be now computed by Equa-tion 6. Or, more precisely, the likelihood value p(gt|et) giventhe observation et is exponentially proportional to the dis-tance between gt and the ”observed gaze position” get whichis derived from the eye center location via Equation 9:
p(gt|et) ∝ exp(−λ‖gt − get‖2). (10)
The parameter λ in this equation is determined such thatp(gt|et) ≈ ε (where ε is a very small positive number) when‖gi − gt‖2 = D where D is the possibly largest error, gener-ally set to the diagonal of the screen.
3. EXPERIMENTAL RESULTS
Firstly, the proposed eye center detection method is indepen-dently evaluated and then, the performances of the whole sys-tem is given and discussed. Due to the low complexity of theeye center detection and the particle filter methods, the systemruns 10 times faster than real-time with our multi-threadingimplementation.
3.1. Eye Center Detection Evaluation
Although some databases exist for evaluating eye center de-tection algorithms, most of them contains only gray-scale im-ages. As our method is color-based, we therefore, proposehere a data set consisting of 401 color images of 401 peoplewith different resolutions, illuminations, poses, eye colors andspecificities (i.e., wearing glasses). A manual annotation ofboth eye centers was performed to build the ground truth. Fig.2 shows qualitative results obtained on a sample of the testeddatabase. We observe that the method successfully handlessome changes in poses, scales, illuminations, resolutions, eyecolors and the presence of glasses. For quantitative results,the normalized error [11] is adopted as the accuracy measure.This measure may be interpreted as follows: i) e ≤ 0.25 cor-responds to an error equivalent to the distance between theeye center and the eye corners, ii) e ≤ 0.1 corresponds toto the diameter of the iris, and iii) e ≤ 0.05 corresponds tothe diameter of the pupil. Regarding the accuracy required
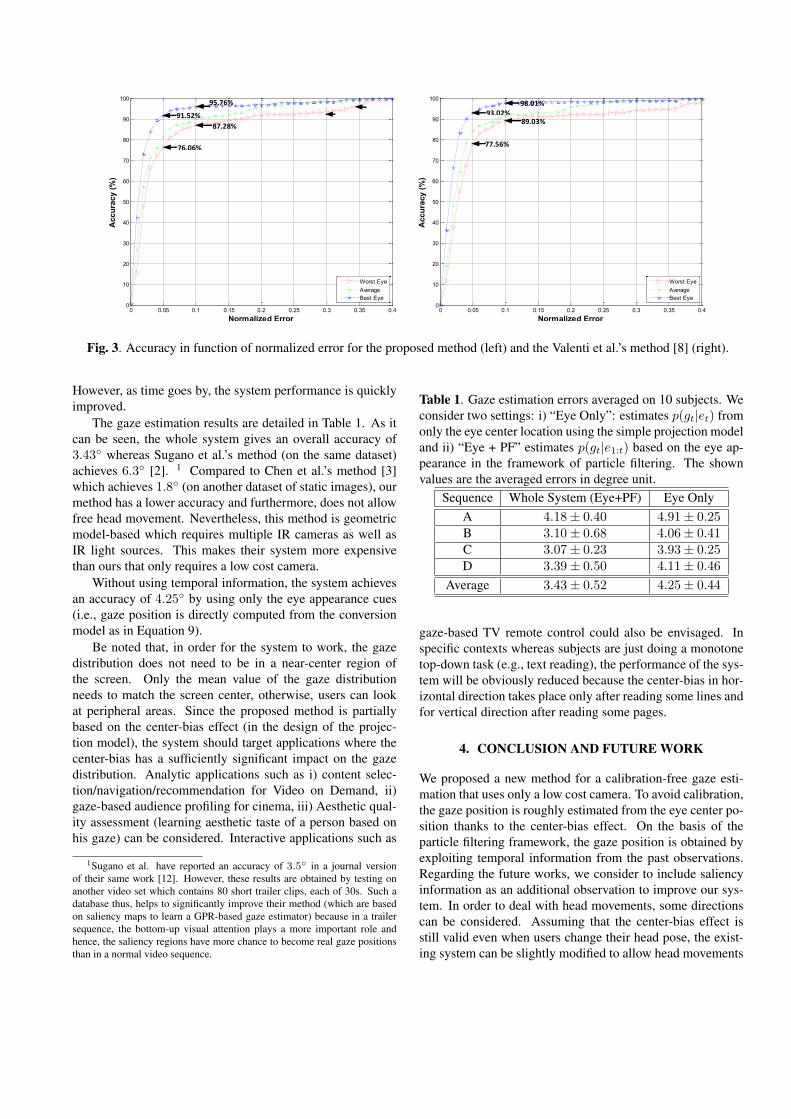
for our application (i.e., pupil center detection), we focus onthe performance obtained for e ≤ 0.05. We also compareour method to a recent state-of-the-art algorithm proposed byValenti et al. [8] which is based on the isophote curvature.Two methods are then tested on the same database and evalu-ated by the same accuracy measure as described above.
Fig. 3 shows the obtained accuracy as a function of thenormalized error for the proposed method (Fig. 3a) andValenti et al.’s method (Fig. 3b). In order to give more in-formation about the accuracy, the minimum normalized error(computed on the better eye only) as well as the average er-ror of the better and worse estimation are also computed. Asone can observe, our method achieves an accuracy compa-rable with the results obtained by Valenti et al. Despite thesimplicity of this approach, the method also works well inother test scenarios (i.e., indoor environment with luminancechange, people wearing glass, different eye color). Further-more, since the proposed system is based on a probabilisticframework, such an accuracy is sufficient for a rough estima-tion of the gaze probability map from the eye image. The finalgaze position is then refined by fusing this map with the priorinformation obtained from the past observations.
3.2. Gaze Tracking Evaluation
Four movies (which have been used in [2]) are selected: A)”Dreams” B) ”Forrest Gump” C) ”Nuovo Cinema Paradiso”and D) ”2001: A Space Odyssey” for evaluation. From these,we extract 4 sequences, each of 10-minute length, by con-catenating many 2 second-sequences from the beginning tothe end of the entire feature length movie with equal timeintervals. The reason for choosing such sequences is to con-sistently compare our method with the one in [2]. The screenresolution is 1280x1024 (376mm×301mm). Ten subjects (8males and 2 females) were involved in our tests. A chin restwas used to fix the head position and maintain a constant dis-tance of 610 mm (about twice the screen height) between thetest subjects and the display. Ground truth data were recordedby a SMI RED gaze tracker with a sampling frequency of 50Hz. The accuracy of the SMI RED gaze tracker is 0.4◦ asreported in its technical specification. The user video werecaptured in parallel with the gaze tracker by a consumer webcamera with a frequency of 16Hz.
Fig. 4 shows the demo interface of the proposed gazetracker. The user video and the video stimulus are displayedat the same time. The mean errors of the proposed system areshown in both digit numbers and curves as functions of time.The performances of each eye are independently measured tohave an idea about the ”ocular dominance” effect. From thegraph of curves, we can see that the mean errors of the systemare rather high in the beginning due to the inaccuracy of theprojection model (the number of samples used for computingthe mean and the standard deviation is not large enough tobe able to represent the statistics of the eye center position).
0 0.05 0.1 0.15 0.2 0.25 0.3 0.35 0.4
0
10
20
30
40
50
60
70
80
90
100
Normalized Error
Accu
racy (
%)
Worst Eye
Average
Best Eye
0 0.05 0.1 0.15 0.2 0.25 0.3 0.35 0.40
10
20
30
40
50
60
70
80
90
100
Normalized Error
Accu
racy (
%)
Worst Eye
Average
Best Eye
77.56%
89.03%
93.02%
98.01%
76.06%
87.28%
91.52%
95.76%
Fig. 3. Accuracy in function of normalized error for the proposed method (left) and the Valenti et al.’s method [8] (right).
However, as time goes by, the system performance is quicklyimproved.
The gaze estimation results are detailed in Table 1. As itcan be seen, the whole system gives an overall accuracy of3.43◦ whereas Sugano et al.’s method (on the same dataset)achieves 6.3◦ [2]. 1 Compared to Chen et al.’s method [3]which achieves 1.8◦ (on another dataset of static images), ourmethod has a lower accuracy and furthermore, does not allowfree head movement. Nevertheless, this method is geometricmodel-based which requires multiple IR cameras as well asIR light sources. This makes their system more expensivethan ours that only requires a low cost camera.
Without using temporal information, the system achievesan accuracy of 4.25◦ by using only the eye appearance cues(i.e., gaze position is directly computed from the conversionmodel as in Equation 9).
Be noted that, in order for the system to work, the gazedistribution does not need to be in a near-center region ofthe screen. Only the mean value of the gaze distributionneeds to match the screen center, otherwise, users can lookat peripheral areas. Since the proposed method is partiallybased on the center-bias effect (in the design of the projec-tion model), the system should target applications where thecenter-bias has a sufficiently significant impact on the gazedistribution. Analytic applications such as i) content selec-tion/navigation/recommendation for Video on Demand, ii)gaze-based audience profiling for cinema, iii) Aesthetic qual-ity assessment (learning aesthetic taste of a person based onhis gaze) can be considered. Interactive applications such as
1Sugano et al. have reported an accuracy of 3.5◦ in a journal versionof their same work [12]. However, these results are obtained by testing onanother video set which contains 80 short trailer clips, each of 30s. Such adatabase thus, helps to significantly improve their method (which are basedon saliency maps to learn a GPR-based gaze estimator) because in a trailersequence, the bottom-up visual attention plays a more important role andhence, the saliency regions have more chance to become real gaze positionsthan in a normal video sequence.
Table 1. Gaze estimation errors averaged on 10 subjects. Weconsider two settings: i) “Eye Only”: estimates p(gt|et) fromonly the eye center location using the simple projection modeland ii) “Eye + PF” estimates p(gt|e1:t) based on the eye ap-pearance in the framework of particle filtering. The shownvalues are the averaged errors in degree unit.
Sequence Whole System (Eye+PF) Eye OnlyA 4.18± 0.40 4.91± 0.25B 3.10± 0.68 4.06± 0.41C 3.07± 0.23 3.93± 0.25D 3.39± 0.50 4.11± 0.46
Average 3.43± 0.52 4.25± 0.44
gaze-based TV remote control could also be envisaged. Inspecific contexts whereas subjects are just doing a monotonetop-down task (e.g., text reading), the performance of the sys-tem will be obviously reduced because the center-bias in hor-izontal direction takes place only after reading some lines andfor vertical direction after reading some pages.
4. CONCLUSION AND FUTURE WORK
We proposed a new method for a calibration-free gaze esti-mation that uses only a low cost camera. To avoid calibration,the gaze position is roughly estimated from the eye center po-sition thanks to the center-bias effect. On the basis of theparticle filtering framework, the gaze position is obtained byexploiting temporal information from the past observations.Regarding the future works, we consider to include saliencyinformation as an additional observation to improve our sys-tem. In order to deal with head movements, some directionscan be considered. Assuming that the center-bias effect isstill valid even when users change their head pose, the exist-ing system can be slightly modified to allow head movements

Fig. 4. Demo interface of the proposed gaze tracker. On the video stimulus window, the green dot is the ground truth gaze pointand the red dot is the gaze point estimated by the system. The curves display the mean estimation errors over time.
just by re-initializing the statistic values (i.e., the mean andthe standard deviation) of the eye center position whenever asufficiently large head movement is detected. Another direc-tion is to integrate a head pose tracker into the existing systemas an additional cues and would be fused with other cues in aprincipled manner thanks to the particle filtering framework.
5. REFERENCES
[1] Y. Sugano, Y. Matsushita, Y. Sato, and H. Koike, “Anincremental learning method for unconstrained gaze es-timation,” in Proc. of the 10th ECCV, 2008, pp. 656–667.
[2] Y. Sugano, Y. Matsushita, and Y. Sato, “Calibration-freegaze sensing using saliency maps,” in Proc. of the 23rdIEEE CVPR, June 2010.
[3] J. Chen and Q. Ji, “Probabilistic gaze estimation withoutactive personal calibration,” in Proc. of IEEE CVPR’11,2011, pp. 609–616.
[4] E. D. Guestrin and M. Eizenman, “General theory of re-mote gaze estimation using the pupil center and cornealreflections,” .
[5] M. Isard and A. Blake, “Condensation - conditional den-sity propagation for visual tracking,” IJCV, vol. 29, no.1, pp. 5–28, 1998.
[6] R. S. Stephens, “Probabilistic approach to the houghtransform,” Journal of Image and Vision Computing,vol. 9, no. 1, pp. 66–71, 1991.
[7] L. Pan, W.S. Chu, J.M. Saragih, and F. De la Torre, “Fastand robust circular object detection with probabilisticpairwise voting,” IEEE Sig. Proc. Letter, vol. 18, no.11, pp. 639–642, 2011.
[8] R. Valenti and T. Gevers, “Accurate eye center locationand tracking using isophote curvature,” in Proc. of theIEEE CVPR’08, June 2008.
[9] P. H. Tseng, R. Carmi, I. G. M. Cameron, D. P. Munoz,and L. Itti, “Quantifying center bias of observers in freeviewing of dynamic natural scenes,” Journal of Vision,vol. 9, no. 7, pp. 1–16, July 2009.
[10] T. Judd, K. Ehinger, F. Durand, and A. Torralba, “Learn-ing to predict where humans look,” in IEEE ICCV’09,2009.
[11] Jesorsky, K. J. Kirchberg, and R. Frischholz, “Robustface detection using the hausdorff distance,” in Proc.Audio Video Biometric Pers. Authentication, 1992, pp.90–95.
[12] Y. Sugano, Y. Matsushita, and Y. Sato, “Appearance-based gaze estimation using visual saliency,” IEEETrans. on PAMI, vol. PP, no. 99, 2012.
