
Bouma2
40
Bouma2 Erez Buchnik February-2012
-
Upload
erez-buchnik -
Category
Technology
-
view
621 -
download
0
Transcript of Bouma2

Bouma2Erez Buchnik
February-2012

”If you can raed tihs,
tehn you are prbbolay not a sttae-mhciane.”

Agenda
• Problem
• Existing Solutions
• Bouma2 – Model
• Comparisons
• Algorithm Design in Detail
• Discussion

Agenda
• Problem• Existing Solutions
• Bouma2 – Model
• Comparisons
• Algorithm Design in Detail
• Discussion

The Multiple Exact String-Match Problem
“Given a string-set L ⊆ Σ∗
and an input stream WI ∈
Σ∗, find all occurrences of
any of the strings in L that
appear in WI”Uses: AV, IPS, DPI, DNA Search etc...
References
• Aho-Corasick ’75
• Commentz-Walter ’79
• Rabin-Karp ’87
• Wu-Manber ’94
• Muth-Manber ’96
• Hopcroft-Motwani-Ullman ’00
• Dori-Landau ’06

Agenda
• Problem
• Existing Solutions• Bouma2 – Model
• Comparisons
• Algorithm Design in Detail
• Discussion
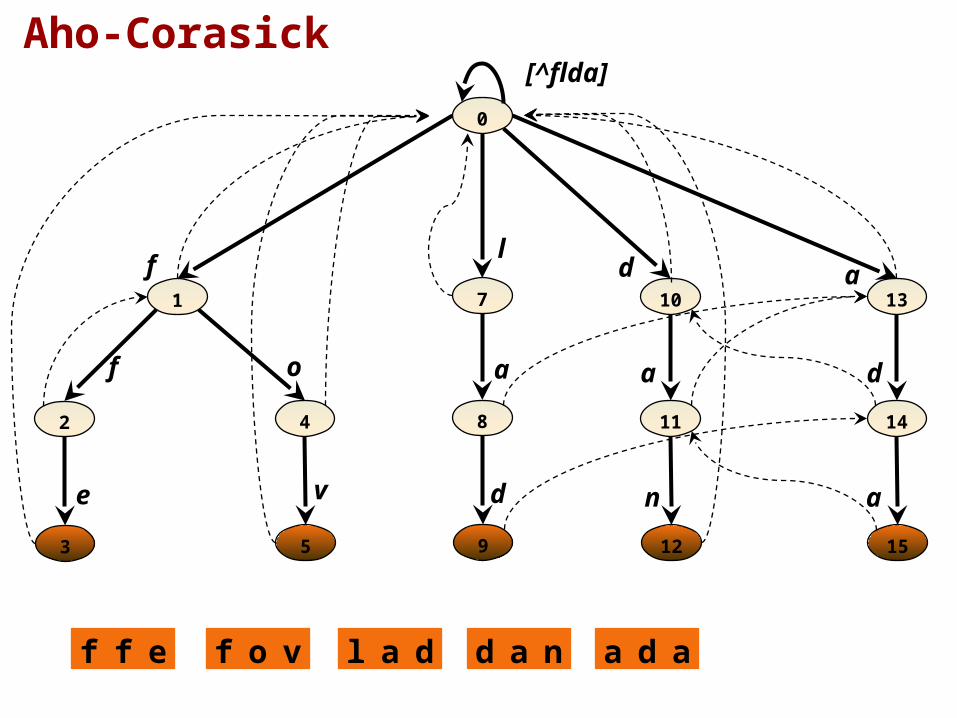
Aho-Corasick
0
7
8
9
a
d
13
14
15
d
a
10
11
12
a
n
ld a
[^flda]
a dl
f1
2
3
f
e
4
5
o
v
f ef o vf a nd d aa
Erez buchnik
Background slideexample desc. slide
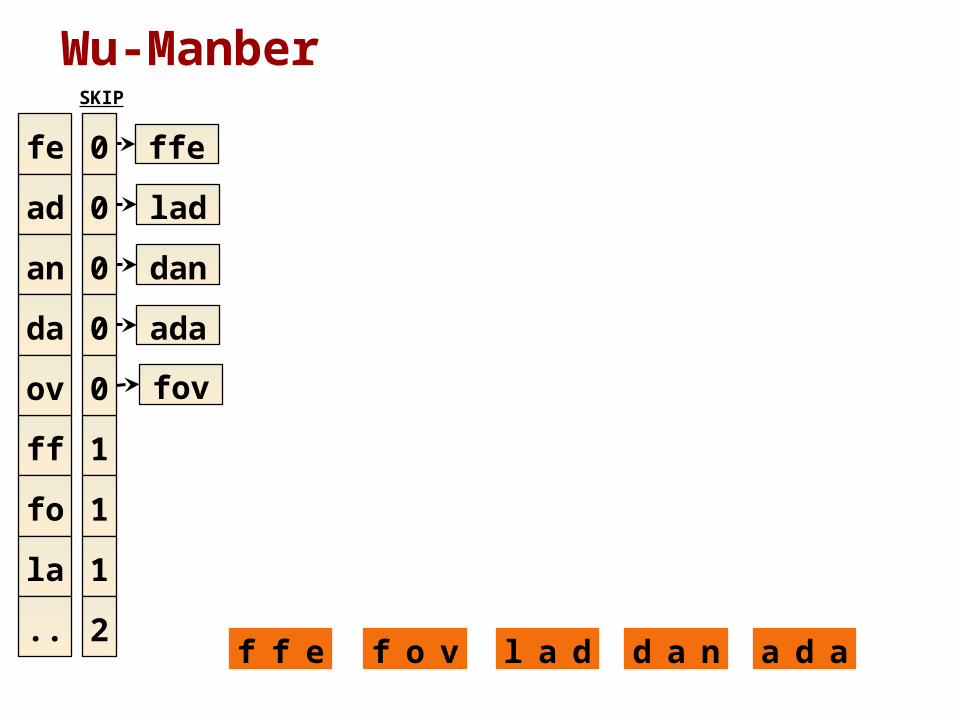
Wu-Manber
0
lad
ffe
fov
fe
0ad
dan0an
ada0da
1ff
1fo
1la
2..
SKIP
0ov
a dlf ef o vf a nd d aa
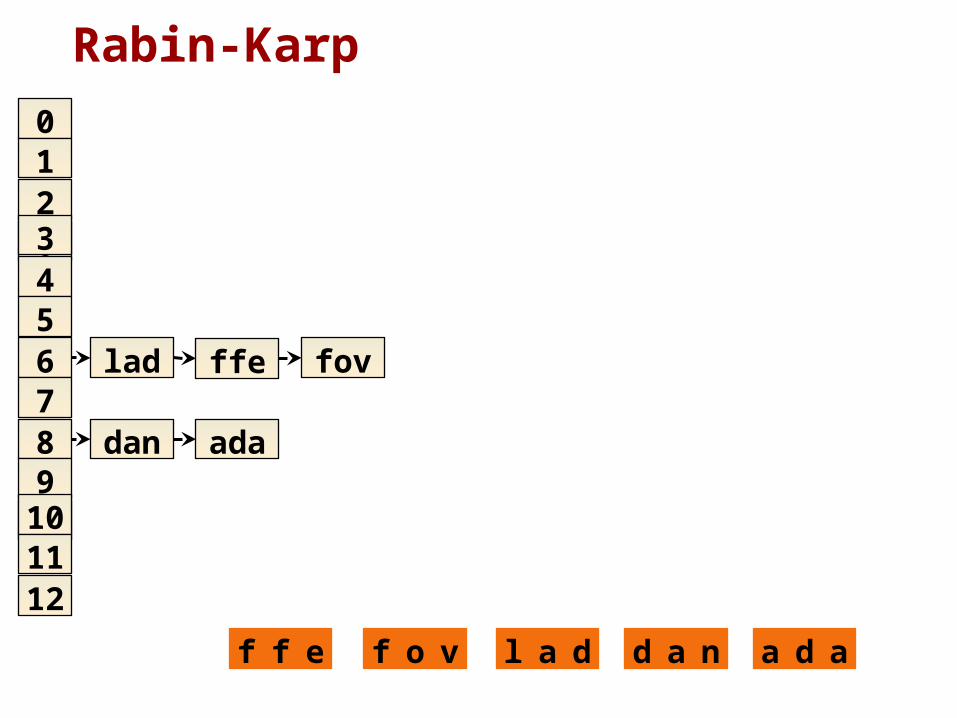
Rabin-Karp
012034567890101112
lad
dan ada
ffe fov
a dlf ef o vf a nd d aa

Agenda
• Problem
• Existing Solutions
• Bouma2 – Model• Comparisons
• Algorithm Design in Detail
• Discussion
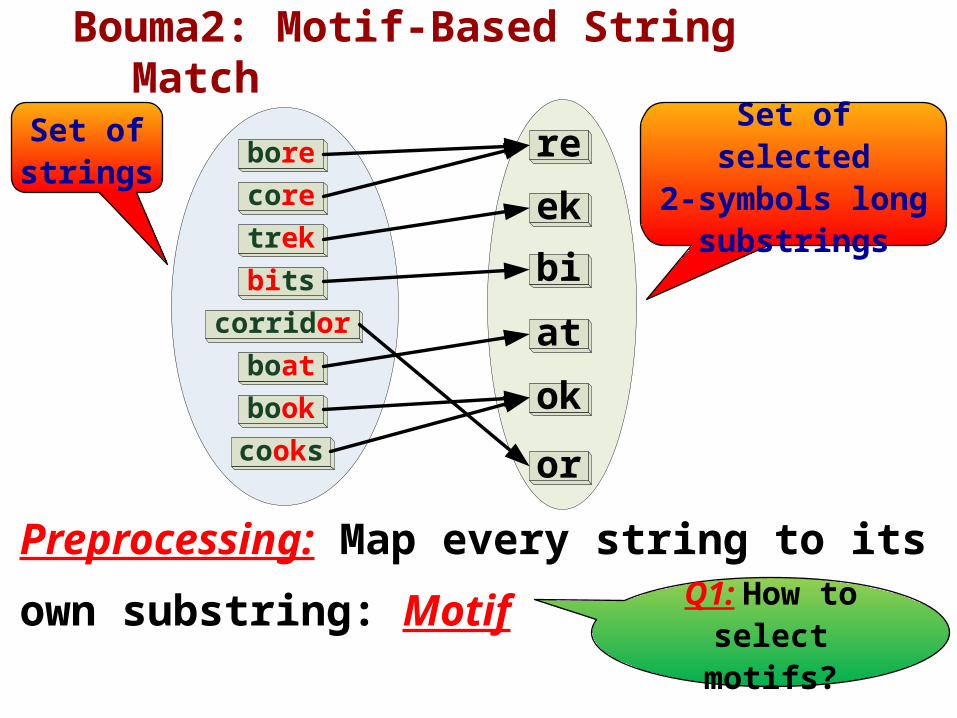
Bouma2: Motif-Based String Match
bi
re
or
at
ok
ek
bore
core
bits
corridor
boat
book
cooks
trek
Preprocessing: Map every string to its
own substring: Motif
Set of strings
Set of selected2-symbols long
substrings
Q1: How to select
motifs?
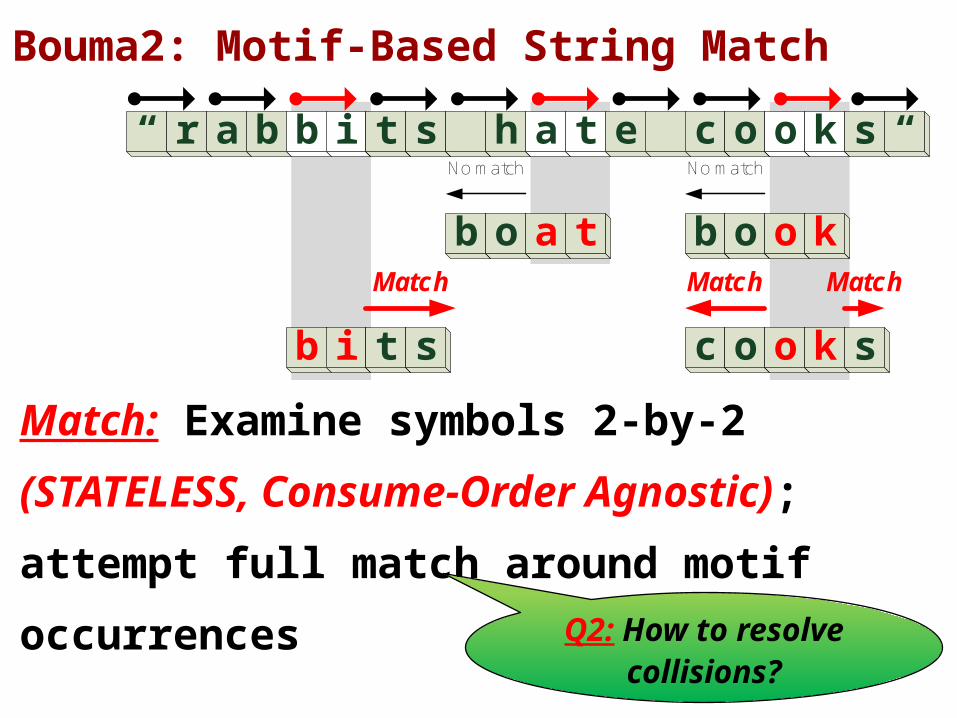
Bouma2: Motif-Based String Match
“ r a b b i t s h a t e
b o o k
c o o k s “
c o o k s
No match
Match Match
b o a t
No match
b i t s
Match
Match: Examine symbols 2-by-2
(STATELESS, Consume-Order
Agnostic); attempt full match around
motif occurrences Q2: How to resolve collisions?
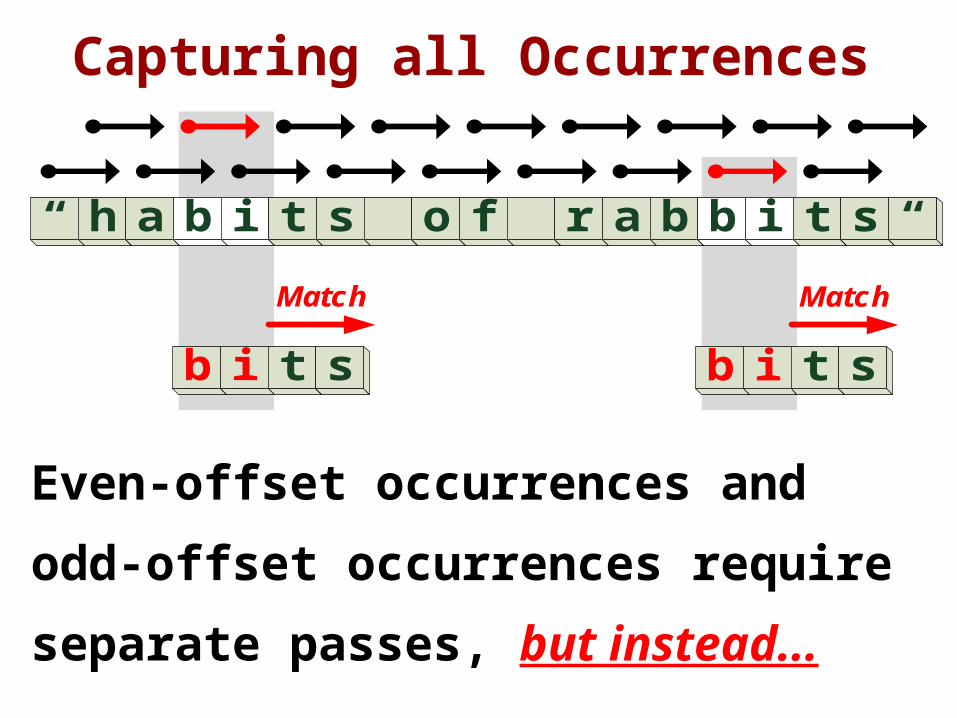
Capturing all Occurrences
“ h a b i t s o f r a b b i t s “
b i t sb i t s
MatchMatch
Even-offset occurrences and
odd-offset occurrences require
separate passes, but instead...
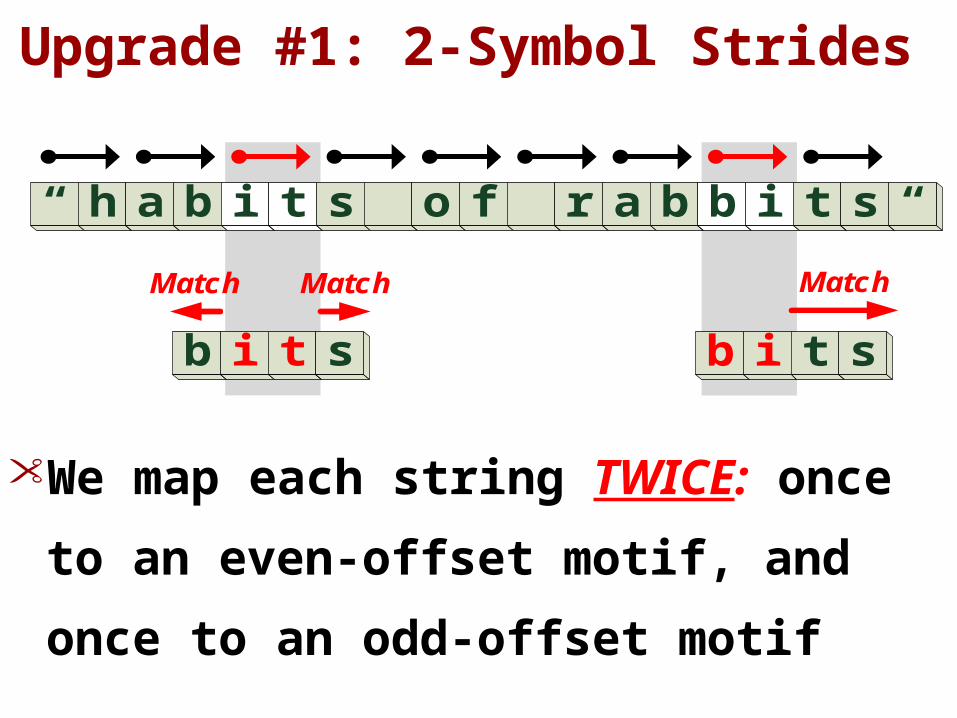
Upgrade #1: 2-Symbol Strides
“ h a b i t s o f r a b b i t s “
b i t s
Match
b i t s
MatchMatch
• We map each string TWICE:
once to an even-offset motif,
and once to an odd-offset motif
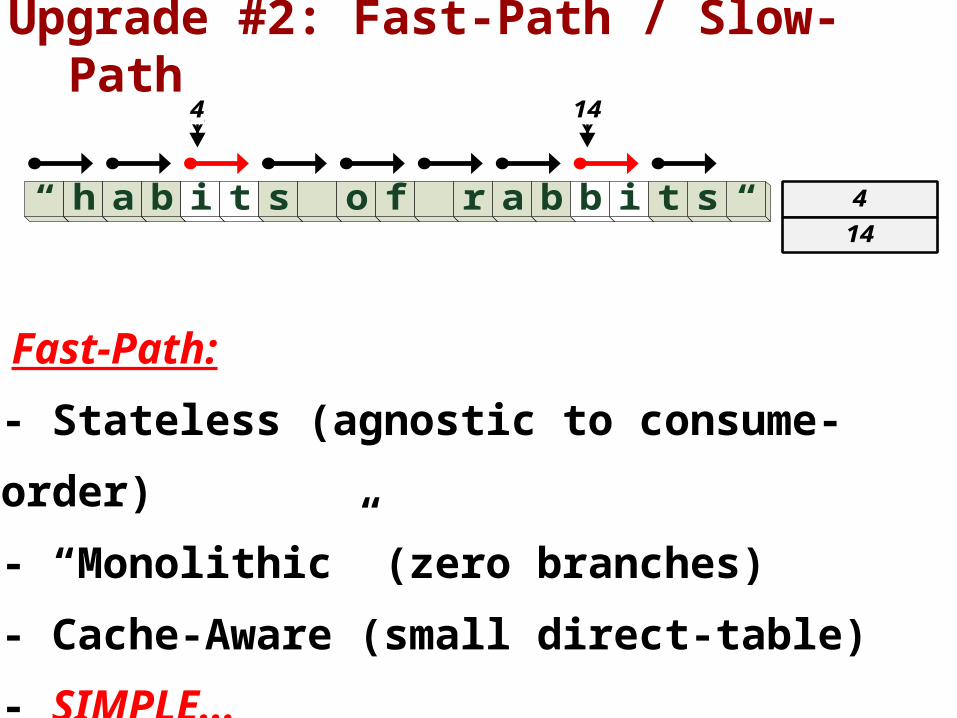
Upgrade #2: Fast-Path / Slow-Path
“ h a b i t s o f r a b b i t s “ 4
14
4 14
Fast-Path:
- Stateless (agnostic to consume-
order)
- “Monolithic” (zero branches)
- Cache-Aware (small direct-table)
- SIMPLE...

Upgrade #2: Fast-Path / Slow-Path
“ h a b i t s o f r a b b i t s “
b i t s
Match
b i t s
MatchMatch
4
14
4 14
Slow-Path:
- Memory-Efficient (pointers to original
strings for comparison)
- “Localized” (separate structure for
every motif)

Agenda
• Problem
• Existing Solutions
• Bouma2 – Model
• Comparisons• Algorithm Design in Detail
• Discussion

• n – length of input• S – no. of string-matches in n• P – Probability of motif-match• l – length of the longest string
Match Complexities:
- Aho-Corasick:
- Bouma2:
Bouma2 vs. Aho-Corasick
)( SnO )))2(5.0(( lPnO

Benchmark- Performed against the Snort implementation of Aho-
Corasick- Tested with 1GB of genuine IP traffic recorded at an ISP
site- Database included 4,841 unique strings extracted from
Snort rules, 3 bytes long or longer- Aggregate size of database strings: 98,546 bytes- Tested using Snort source-code merged with Bouma2 over
Intel Core2 Duo 2.53GHz with 1.95GB RAM running XP SP3- Profiled with Visual Studio 2010 Sampling Profiler- For Bouma2, three different motif-selection methods were
compared:B2-M (Minimum): Minimum motifsB2-RS (Rare in Strings): Prefer motifs that occur less times within the database stringsB2-RI (Rare in Input): Prefer motifs that are expected to occur less times in the input (based on statistics over one third of the input)
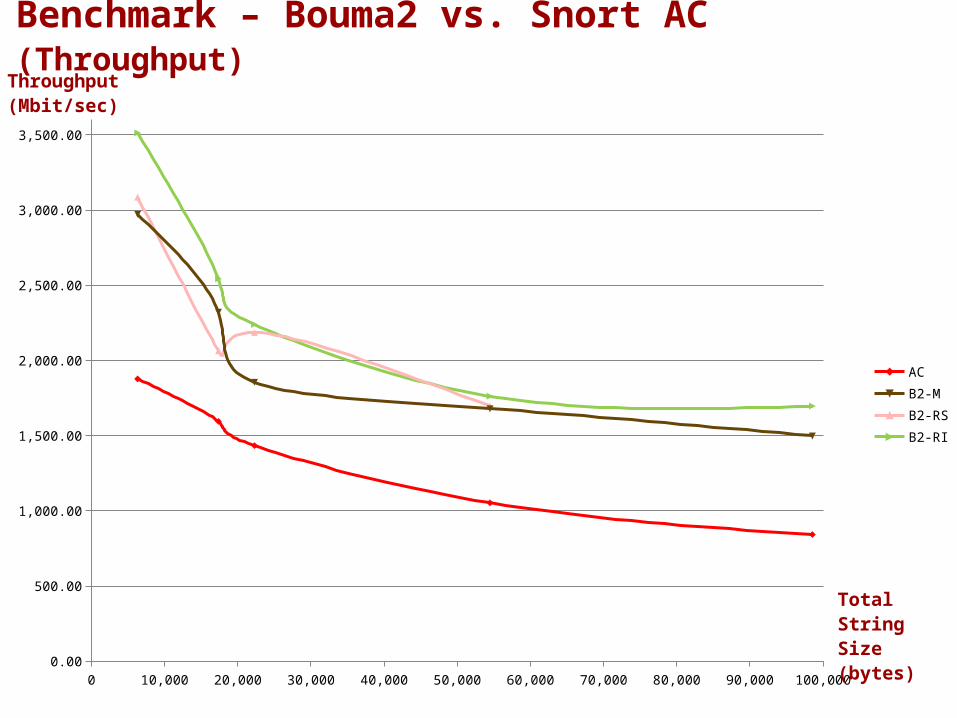
Throughput(Mbit/sec)
Benchmark – Bouma2 vs. Snort AC (Throughput)
0 10,000 20,000 30,000 40,000 50,000 60,000 70,000 80,000 90,000 100,0000.00
500.00
1,000.00
1,500.00
2,000.00
2,500.00
3,000.00
3,500.00
AC
B2-M
B2-RS
B2-RI
Total String Size (bytes)

Total String Size (bytes)
- Snort creates several AC instances, which are pre-filtered by port- The comparison was done against a single Bouma2 instance
0 10,000 20,000 30,000 40,000 50,000 60,000 70,000 80,000 90,000 100,0000
10,000,000
20,000,000
30,000,000
40,000,000
50,000,000
AC
B2-M
B2-RS
B2-RI
Memory Consumption(bytes)
Benchmark – Bouma2 vs. Snort AC (Memory)

Agenda
• Problem
• Existing Solutions
• Bouma2 – Model
• Comparisons
• Algorithm Design in Detail• Discussion

• A1: Out of all 2-symbol substrings,
find a minimum subset that covers
all given strings (even & odd
offsets)
Q1: How to select motifs?
bo co do id or re ri rrbo re • •
co re • •
co rr id or • • • •
b or e •
c or e •
c or ri do r • • •
Even Offset
Odd Offset

• But... maybe the minimum
subset is not the optimal
subset?
Q1: How to select motifs?
bo co do id or re ri rrbo re Χ √
co re Χ √
co rr id or Χ Χ √ Χ
b or e √
c or e √
c or ri do r Χ √ Χ
Even Offset
Odd Offset

Q1: How to select motifs?
Bad selection of motifs for English
text searches: substrings of ‘the’ - the
most common word in English
“The good, the bad and the ugly“ in theaters nearby
thea
No match No match
thea
Matchter thea
Match No match
ter
ter
thea
Match No match
ter
at ea er he te thEven
Offset th ea te r Χ Χ √Odd
Offset t he at er Χ Χ √

• Use input-specific occurrence
statistics to optimize motif-sets• REALISTIC...
Q1: How to select motifs?2-Symbol Sequence Occurrence Probability
bo 0.0002re 0.001861co 0.001028rr 0.000031id 0.001756or 0.000444ri 0.000284do 0.000151
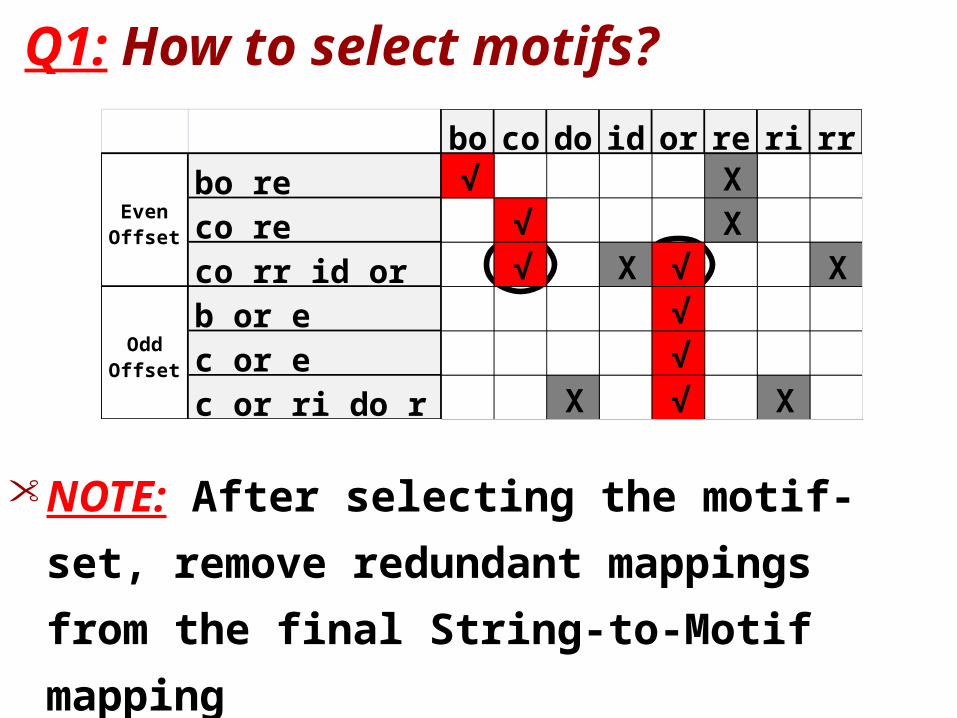
• NOTE: After selecting the motif-set,
remove redundant mappings from
the final String-to-Motif mapping
Q1: How to select motifs?
bo co do id or re ri rrbo re √ Χ
co re √ Χ
co rr id or √ Χ √ Χ
b or e √
c or e √
c or ri do r Χ √ Χ
Even Offset
Odd Offset
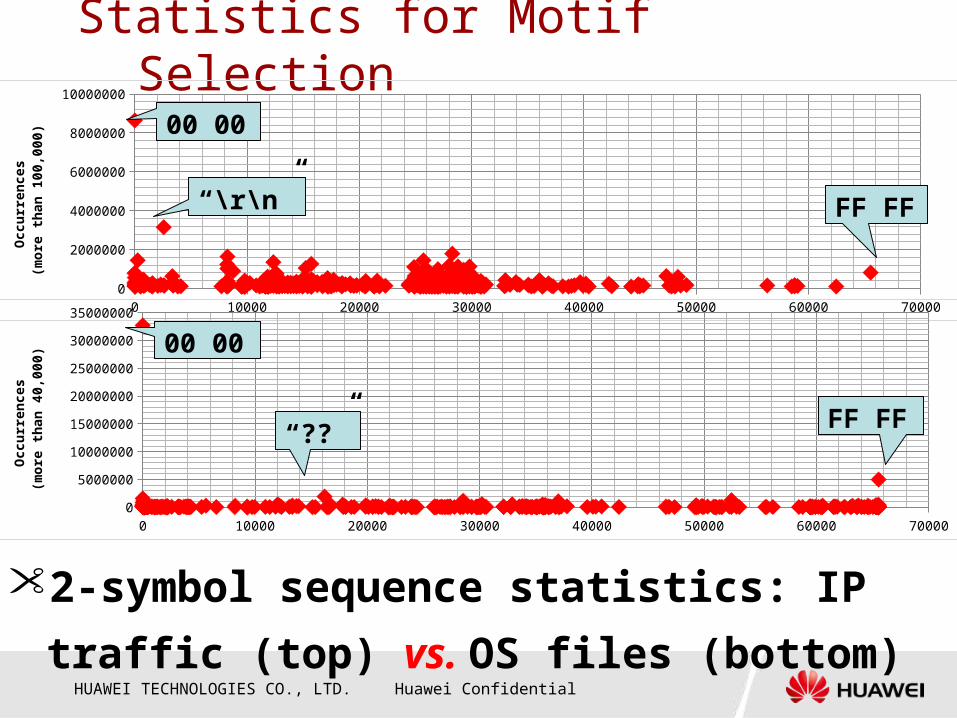
Statistics for Motif Selection
0 10000 20000 30000 40000 50000 60000 700000
2000000
4000000
6000000
8000000
10000000
Occ
urr
ence
s (m
ore
th
an 1
00,0
00)
“\r\n”
00 00
FF FF
0 10000 20000 30000 40000 50000 60000 700000
5000000
10000000
15000000
20000000
25000000
30000000
35000000
Occ
urr
ence
s (m
ore
th
an 4
0,00
0)
00 00
“??”FF FF
• 2-symbol sequence statistics: IP
traffic (top) vs. OS files (bottom)

Motif Selection as an ILP Problem
• L: a given string-set
• TL: all 2-symbol substrings of strings in L
• c(t): cost-function for every t in TL
Minimize ,
whereas for every
LTt
txtc )(
}1,0{tx LTt
Subject To: for every Lw
LTtt twassocx 1),(0 ,
and
LTtt twassocx 1),(1

• A2: - New structure: The Mangled-Trie
- Examine adjacent symbols at relative
offsets to eliminate strings
- The Mangled-Trie itself dictates where to
look next (instead of following a strict
left-to-right sequence)
Q2: How to resolve collisions?
b o r ec o r ec o r r i d o r
c o r r i d o r
-1 0 1 2 3 4 5 6-2-3-4-5-6
I
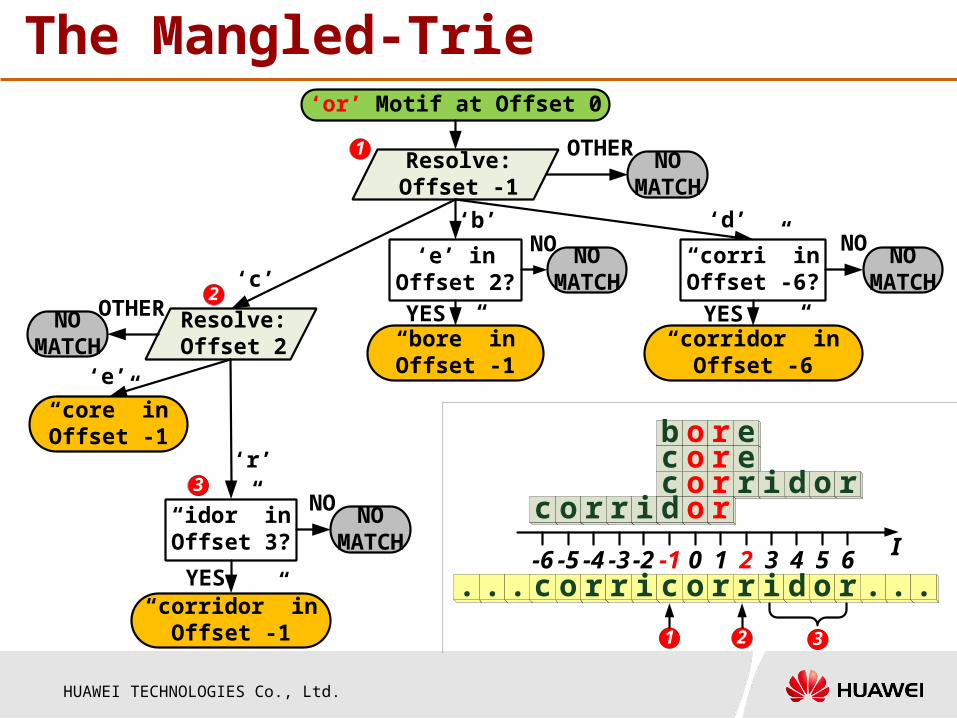
The Mangled-Trie
. . .
b o r ec o r ec o r r i d o r
c o r r i d o r
c o r r i c o r r i d o r . . .
1 2 3
Resolve: Offset -1
‘b’
‘c’
‘d’
OTHER NO MATCH
‘e’ in Offset 2?
“bore” in Offset -1
NO NO MATCH
YES
“corri” in Offset -6?
“corridor” in Offset -6
NO NO MATCH
YESResolve: Offset 2
OTHERNO MATCH
‘e’
‘r’
“core” in Offset -1
“idor” in Offset 3?
“corridor” in Offset -1
NO NO MATCH
YES-1 0 1 2 3 4 5 6-2-3-4-5-6 I
1
2
3
‘or’ Motif at Offset 0

• A3: - Optimize Frequent Scenarios: Apply
statistics to Mangled-Trie
construction
- Improve Motif-Set Quality: Avoid
slow-path altogether when possible
Q3: How to optimize slow-path?

Agenda
• Problem• Existing Solutions• Bouma2 – Model• Comparisons• Algorithm Design in Detail
• Discussion

Bouma2:Hash-Functions Revisited
Erez BuchnikMarch-2012

Hash Functions
What is a Hash-Function?
“A hash function is any algorithm or subroutine that maps
large data sets of variable length, called keys, to smaller data sets of a fixed length. ...The values returned by a hash function are called hash values,
hash codes, hash sums, checksums or simply hashes.”
What is a GOOD (non-cryptographic) Hash-Function?
“A good hash function should map the expected inputs as
evenly as possible over its output range. That is, every hash value in the output range should be generated with roughly
the same probability.”
What input should we expect?

Bouma2 defines a hash-function:
- A tailored, optimized mapping
of strings to their own
substrings.- Collision-resolving is also
optimized, based on relative
offset information

The Multiple Exact String-Match Problem
FACT: The definition of the
problem DOES NOT imply that we
must scan the input from left to
right, or in any other order.
“Given a string-set L ⊆ Σ∗ and an input stream
WI ∈ Σ∗, find all occurrences of any of the
strings in L that appear in WI”

The Multiple Exact String-Match Problem
CLAIM: Algorithms that impose
a consume-order constraint are
in general less efficient than
algorithms that are free of this
constraint.
“Given a string-set L ⊆ Σ∗ and an input stream
WI ∈ Σ∗, find all occurrences of any of the
strings in L that appear in WI”
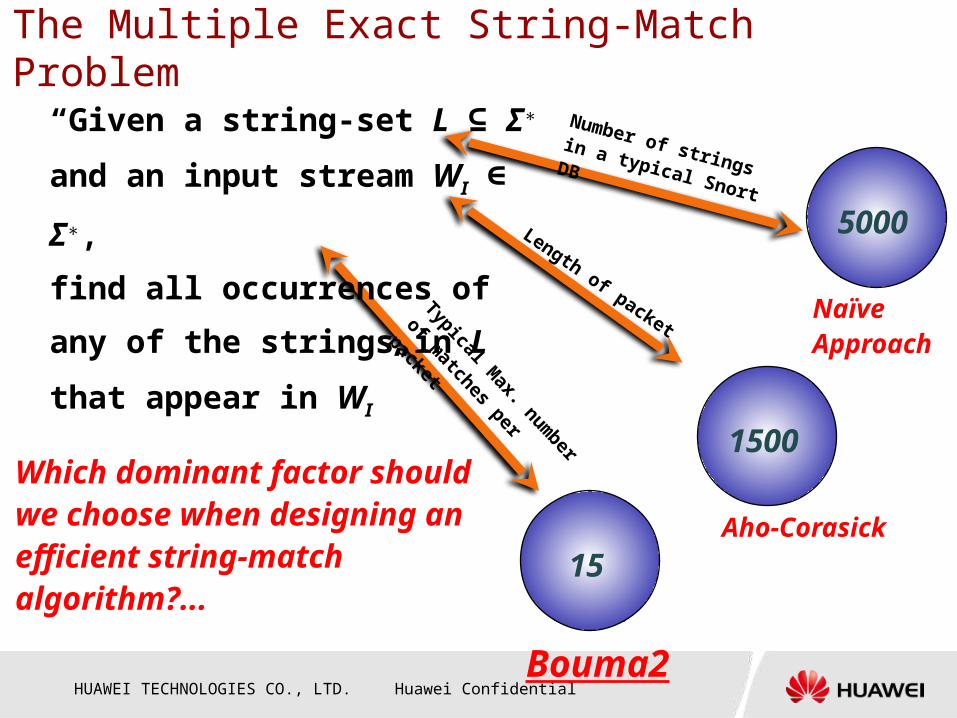
Typical Max. num
ber
of matches per
packet
Length of packet
Number of strings in a typical Snort DB
The Multiple Exact String-Match Problem
“Given a string-set L ⊆ Σ∗
and an input stream WI ∈
Σ∗,
find all occurrences of
any of the strings in L
that appear in WI”
5000
1500
15
Which dominant factor should we choose when designing an efficient string-match algorithm?...
Naïve Approach
Aho-Corasick
Bouma2

















