

Using smartphones to teach digital media in writing courses: Handouts
Upload
suresh-soodCategory
view
131download
1
Big Data Cool Tools for Dark Data and Dark Matter: DeepDive and Apache Spark
linkedin.com/in/sureshsood@soody
slideshare.net/ssood/bigdatacooltools
July 2015

Areas for Conversation
1. Big data, Internet of Things and Hadoop
2. Data science paradigm, innovations and discoveries
3. Apache Spark - high level abstraction
4. DeepDive - overcoming the challenges of dark data
5. Opportunities and next steps

Kelly, Kevin (2013), A Catalog of Possibilitieshttp://kk.org/cooltools/

By 2020, the estimate is that there will be four times more digital data in bytes than grains of sand exist on the entire planet (Judah Phillips 2013) and trillions of sensors by 2022 (Stanford 2013). This data deluge will need to be managed and interrogated by people who have the skills to frame the strategic questions, translate that into ‘data language’, source data relevant to an investigation, mine, analyse, visualise and communicate the outcomes…
Source:
http://www.uts.edu.au/future-students/analytics-and-data-science/master-data-science-and-innovation/about-course#why-mdsi

Internet of Things“trillion sensors”
Source: www.tsensorssummit.org

McKINSEY GLOBAL INSTITUTE: THE INTERNET OF THINGS: MAPPING THE VALUE BEYOND THE HYPE , JUNE 2015

Variety of Data Types & Big Data Challenge 1. Astronomical 2. Documents 3. Earthquake4. Email5. Environmental sensors 6. Fingerprints7. Health (personal) Images8. Graph data (social network)9. Location10.Marine11.Particle accelerator 12.Satellite13.Scanned survey data 14.Sound15.Text16.Transactions17.Video
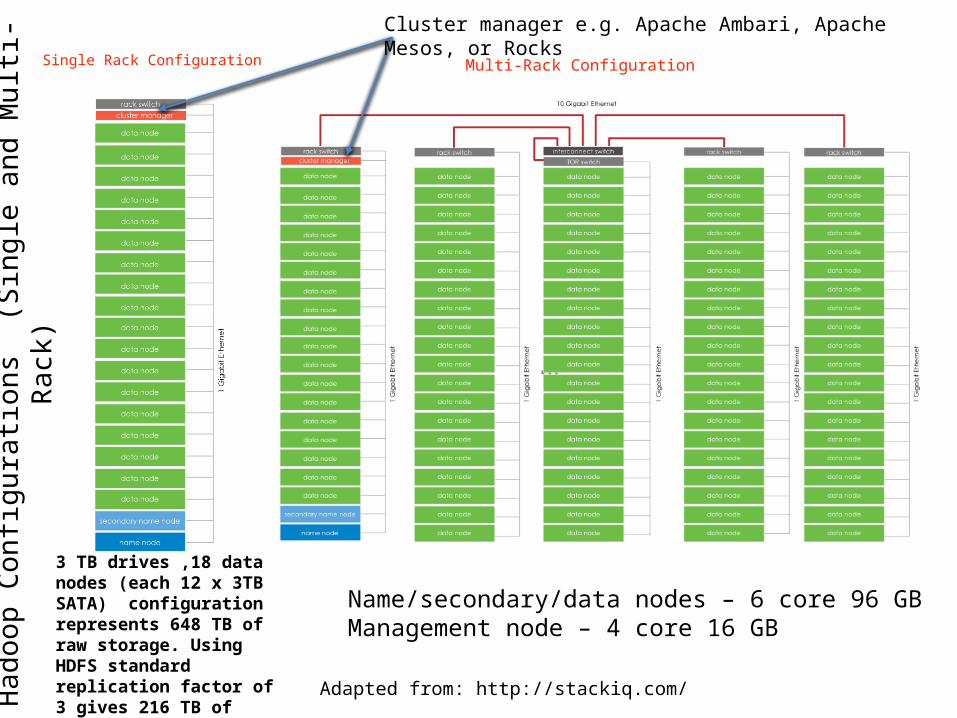
Had
oop
Confi
gura
tions
(Si
ngle
and
Mul
ti-Ra
ck)
Adapted from: http://stackiq.com/
Cluster manager e.g. Apache Ambari, Apache Mesos, or Rocks
3 TB drives ,18 data nodes (each 12 x 3TB SATA) configuration represents 648 TB of raw storage. Using HDFS standard replication factor of 3 gives 216 TB of usable storage
Name/secondary/data nodes – 6 core 96 GBManagement node – 4 core 16 GB
Single Rack Configuration Multi-Rack Configuration

Data Science Paradigm Workflows & Discovery

Data Science Discoveries
1. Outlier / Anomaly / Novelty / Surprise detection
2. Clustering (= New Class discovery, Segmentation)
3. Correlation & Association discovery
4. Classification, Diagnosis, Prediction
Source: Borne, Kirk (2012) LSST All Hands Meeting, 13-17 August

Statistics, Data Mining or Data Science ?
• Statistics– precise deterministic causal analysis over precisely collected data
• Data Mining– deterministic causal analysis over re-purposed data carefully sampled
• Data Science– trending/correlation analysis over existing data using bulk of population i.e.
big data
Adapted from:
NIST Big Data taxonomy draft report (see http://bigdatawg.nist.gov /show_InputDoc.php)

Data Science Innovation
Data science innovation is something an organization or individual has not done before using data. The innovation focuses on discovery using new or nontraditional data sources solving new problems.
Adapted from:
Franks, B. (2012) Taming the Big Data Tidal Wave, p. 255, John Wiley & Son

http://tacocopter.com/
New Sources of Information (Big data) : Social Media + Internet of Things Customer Experience Innovations
7,919 40,204
2,003,254,102 51 Gridded Data Sources
http://smap.jpl.nasa.gov/

The following BigQuery query (note that the wildcard on "TAX_WEAPONS_SUICIDE_" catches suicide vests, suicide bombers, suicide bombings, suicide jackets, and so on):
SELECT DATE, DocumentIdentifier, SourceCommonName, V2Themes, V2Locations, V2Tone, SharingImage, TranslationInfo FROM [gdeltv2.gkg] where (V2Themes like '%TAX_TERROR_GROUP_ISLAMIC_STATE%' or V2Themes like '%TAX_TERROR_GROUP_ISIL%' or V2Themes like '%TAX_TERROR_GROUP_ISIS%' or V2Themes like '%TAX_TERROR_GROUP_DAASH%') and (V2Themes like '%TERROR%TERROR%' or V2Themes like '%SUICIDE_ATTACK%' or V2Themes like '%TAX_WEAPONS_SUICIDE_%')
The GDELT Project pushes the boundaries of “big data,” weighing in at over a quarter-billion rows with 59 fields for each record, spanning the geography of the entire planet, and covering a time horizon of more than 35 years. The GDELT Project is the largest open-access database on human society in existence. Its archives contain nearly 400M latitude/longitude geographic coordinates spanning over 12,900 days, making it one of the largest open-access spatio-temporal datasets as well.
GDELT + BigQuery = Query The Planet

The ANZ Heavy Traffic Index comprises flows of vehicles weighing more than 3.5 tonnes (primarily trucks) on 11 selected roads around NZ. It is contemporaneous with GDP growth.
The ANZ Light Traffic Index is made up of light or total traffic flows (primarily cars and vans) on 10 selected roads around the country. It gives a six month lead on GDP growth in normal circumstances (but cannot predict sudden adverse events such as the Global Financial Crisis).
http://www.anz.co.nz/about-us/economic-markets-research/truckometer/
ANZ TRUCKOMETER

Oil reserves shipment monitoring
Ras Tanura Najmah compound, Saudi Arabia
Source: http://www.skyboximaging.com/blog/monitoring-oil-reserves-from-space

•Big data transforms actuarial insurance from using probability methods to estimate premiums into dynamic risk management using real data generating individually tailored premiums
•Estimate 20 km work or home journey, data point acquired every min and journey captures 12 points per km. Assume 1000 km per month driving or generating 12,000 points per month resulting in 144,000 points per car/annum. Hence, 1,000 cars leads to 144 million points per annum.
•Telematics technology (black box) monitor helps assess the driving behavior and prices policy based on true driver centric premiums by capturing: –Number of journeys –Distances travelled–Types of roads –Speed–Time of travel –Acceleration and braking–Any accidents –Location ?
•Benefits low mileage, smooth and safe drivers
•Privacy vs. Saving monies on insurance (Canada ; http://bit.ly/Black_box)
Black Box Insurance

http://smart-dove.com/

Sparkstream processing
graph analyticsmachine learning
SocialMedia
Hadoop Distributed File System
Java PosDesktop Mobiles Set top box
Beacon technology
Electronic pricing
VideoAnalytics
Customer Profiling, Behaviour, Content & Context
Internetof
Things
OfBiz
SMAnalytics
Sensors
Suresh Sood 2015
CX Innovation Hub - Realisation Architecture


“Beacons have a huge potential to capture a consumer’s attention at the elusive zero moment of truth, which is the exact moment that they make a purchasing decision,” said Matt Witt, executive vice president of digital integration at Tris3ct, Chicago.

Spark - High Level Abstractionversion 1.4.0
Full-text search of Wikipedia in <1 sec (vs 20 sec for on-disk data)
Spark Core
SparkR

GraphX -Spark API for graphs and graph-parallel computation
PageRank —> Google
Friend of a friend —> Facebook

Graph Analytics• 1990’s Ivan Milat killed 7 backpackers making him Australia's most notorious Serial Killer
• Everyone in Australia was a suspect
• Large volumes of data from multiple sources
RTA Vehicle records Gym Memberships Gun Licensing records Internal Police records
• Police applied node link analysis techniques (NetMap) to the data
• Harness power of the human mind
• Analyst can spot indirect links, patterns , structure, relationships and anomalies
• A bottom-up approach with process of discovery to uncover structure
• Reduced the suspect list from 18 million to 230
• Further analysis with the use of additional satellite information reduced this to 32
Data Information Knowledge

The family of projects currently under development within AMPLab. Source: AMPLab

Berkeley Data Analytics Stack Software
Source: https://amplab.cs.berkeley.edu/software/

Powered By Spark


Applications Using Spark
Apache Mahout - Previously on Hadoop MapReduce, Mahout has switched to using Spark as the backend
Apache MRQL - A query processing and optimization system for large-scale, distributed data analysis, built on top of Apache Hadoop, Hama, and Spark
BlinkDB - a massively parallel, approximate query engine built on top of Shark and Spark
Spindle - Spark/Parquet-based web analytics query engine
Thunderain - a framework for combining stream processing with historical data, think Lamba architecture
DF from Ayasdi - a Pandas-like data frame implementation for Spark

Information Architecture
Source: http://carat.cs.berkeley.edu
AWS - Amazon Web Services

What does DeepDive do? (http://deepdive.stanford.edu/)
• System to extract value from dark data **
• Dark data is data buried in text, tables, figures, and images, which lacks structure and so is essentially unprocessable by existing software
• DeepDive helps bring dark data to light by creating structured data (SQL tables) from unstructured information (text documents) and integrate such data with an existing structured database
• Extract sophisticated relationships between entities and make inferences about facts involving those entities
• DeepDive helps one process a wide variety of dark data and put the results into a database.
• Once in a database, one can use standard tools consuming structured data, e.g., visualization tools like Tablaeu or analytics tools like Excel.
** http://www.gartner.com/it-glossary/dark- data)

What Actually is DeepDive? • New type of data management system enabling extraction — integration —
prediction problems in a single system
• Allows users to rapidly construct sophisticated end-to-end data pipelines e.g. dark data BI systems
• Users focus on the portion of their system that most directly improves the quality of their application
• Traditional pipeline-based systems require developers to build extractors, integration code, and other components—without any idea of how changes improve the quality of their data product
• This simple insight is the key to how DeepDive systems produce higher quality data in less time
• DeepDive-based systems are used by users without machine learning expertise in a number of domains from paleobiology to genomics to human trafficking

DeepDive System Advances • Trained system uses machine learning to cope with noise and imprecision
• Computes calibrated probabilities for every assertion
• Simple system training via low-level feedback through MindTagger interface
• Rich, structured domain knowledge via rules
• Joint inference based approach requires necessary signals or features not algorithms
• Systems achieve high quality - PaleoDeepDive has higher quality than human volunteers in extracting complex knowledge in scientific domains
• Variety of sources e.g. millions of documents, web pages, PDFs, tables, and figures.
• Allows developers to use knowledge of a given domain to improve the quality of the results by writing simple rules (doc/basics/inference_rules.html) informing the inference (learning) process. User feedback on the correctness of the predictions improves the predictions.
• Use the data to learn "distantly" (doc/general/distant_supervision.html). Most machine learning systems require tedious training for each prediction

Source: http://deepdive.stanford.edu/

PaleoDeepDive Database• Extract paleobiological facts to build higher coverage fossil records• Statistical inference on billions of variables /terabyte scale• Very useful artefact for scientist• The human created paleodb generated from 329 volunteers, 13 years & 46k docs• 200 papers use macroscopic properties & 17 nature and science publications -
transformative! • Paper in data structure out• Build probabilistic model based on observations to build probabilistic database model • PaleoDeepDive machine created • - 10x documents• 100 x extractions• Per document order of magnitude more than human • Machine systematically puts data into database• Formation precision (location)
• PaleoDB volunteers 0.84• 16% relates to insidious knowledge using background info if better than text

MEMEX
Source : http://www.scientificamerican.com/slideshow/scientific-american-exclusive-darpa-memex-data-maps/
Also see, http://humantraffickingcenter.org/posts-by-htc-associates/memex-helps-find-human-trafficking-cases-online/

MEMEX - Human Trafficking Analytics
• Human traffickers coercive victims into sex work or low cost labour appearing in adverts online
• Adverts contain embedded data on name of worker, contact info, physical characteristics, services offered, location, price/pay rates, and other attributes. Useful data but not accessible via SQL or R.
• DeepDive converts “raw set of advertisements into a single clean structured database table”
• 30 million advertisements obtained for sex work from online
• Trafficking analytic signals
✴ Traffickers move victims from place to place to keep them isolated and easier to control. Detect individuals in the advertisement data who post multiple advertisements from different physical locations
✴ Non-trafficked sex workers exhibit economic rationality charge as much as possible for services, and avoid engaging in risky services. Charging non-market rates or engaging in risky services
✴ Traffickers may have multiple victims simultaneously. If the contact information for multiple workers across multiple advertisements contains consecutive phone numbers, it might suggest one individual purchased several phones at one time.
Source : http://www.scientificamerican.com/slideshow/scientific-american-exclusive-darpa-memex-data-maps/Also see, http://humantraffickingcenter.org/posts-by-htc-associates/memex-helps-find-human-trafficking-cases-online/

DeepDive Data Extraction and Dataset Generation
• URL where the advertisement was found
• Phone number of the person in the advertisement
• Name of the person in the advertisement
• Location where the person offers services
• Rates for services offered

What about Barack Obama?• wife is Michelle Obama• went to Harvard Law School• …
Billions of webpages Billions of tweets
Billions of photosBillions of videos
Billions of events
Billions of blogs
Enhance Wikipedia with the Web

Some Information 50TB Data 500K Machine hours 500M Webpages 400K Videos 20K Books 7Bn Entity Mentions 114M Relationship
Mentions
Tasks we perform:
Web Crawling
Information Extraction
Deep Linguistic Processing
Audio/Video Transcription
Tera-byte Parallel Joins
Statistics on Wikipedia Project

Source: Kumar, A., Niu,F and Re, C. (2013) Hazy: Making it Easier to Build and Maintain Big data Analytics ,‐Databases, January 23, Vol 11, 1
Geo DeepDive Development Pipeline

Probabilistic Predictions in Geo DeepDive
Source: Kumar, A., Niu,F and Re, C. (2013) Hazy: Making it Easier to Build and Maintain Big data Analytics ,‐Databases, January 23, Vol 11, 1

DeepDive inspired main memory & database analytics
MADlib - Big Data Machine Learning in SQL
open-source library for scalable in-database analytics. It provides data-parallel implementations of mathematical, statistical and machine learning methods for structured and unstructured data.
Cloudera ImpalaOpen Source Analytic Database for Apache Hadoop enabling users with ability of issuing low-latency SQL queries to data stored in HDFS and Apache HBase while maintaining data locality.
Google Brain & Microsoft Adamlow-level techniques, such as Hogwild!, have been adopted in Google Brain and Microsoft Adam.

• The data collected in a single day take nearly two million years to playback on an MP3 player• Generates enough raw data to fill 15 million 64GB iPods every day • The central computer has processing power of about one hundred million PCs• Uses enough optical fiber linking up all the radio telescopes to wrap twice around the Earth• The dishes when fully operational will produce 10 times the global internet traffic as of 2013• The supercomputer will perform 1018 operations per second - equivalent to the number of stars in three million
Milky Way galaxies - in order to process all the data produced.• Sensitivity to detect an airport radar on a planet 50 light years away.• Thousands of antennas with a combined collecting area of 1,000,000 square meters - 1 sqkm)• Previous mapping of Centaurus A galaxy took a team 12,000 hours of observations and several years - SKA ETA 5
minutes !
To the scientists involved, however, the SKA is no testbed, it’s a transformative instrument which, according to Luijten, will lead to “fundamental discoveries of how life and planets and matter all came into existence. As a scientist, this is a once in a lifetime opportunity.”
Sources: http://bit.ly/amazin-facts & http://bit.ly/astro-ska
Galileo
Square Kilometer Array Construction (SKA1 - 2018-23; SKA2 - 2023-30)
Centaurus A

Next Steps
• Download …Spark or DeepDive
• Establish a reading circle in the workplace • Invite guest speakers
• Attend meetups e.g. R and Spark
• Visit AAI


















