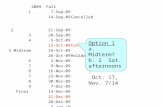
Before MidTermAfter MidTerm Midterm is Oct 27 th : Covers everything up to Oct 22 th. Bring 100...
99
Before MidTerm After MidTerm rm is Oct 27 th : Covers everything up to Oct 22 th . 100 question scantron.
-
Upload
oliver-hutchinson -
Category
Documents
-
view
217 -
download
0
description
Path Planning Search: Our Role We have to define the problem space – State Representation – Initial State – Operators – Goal State (a test to see if a node is the goal) – (If possible) A heuristic We have to pick the right algorithm – We do not need to invent an algorithm
Transcript of Before MidTermAfter MidTerm Midterm is Oct 27 th : Covers everything up to Oct 22 th. Bring 100...

Before MidTerm After MidTerm
Midterm is Oct 27th: Covers everything up to Oct 22th.Bring 100 question scantron.

Search Review
Starting with path planning search

Path Planning Search: Our Role• We have to define the problem space
– State Representation– Initial State– Operators– Goal State (a test to see if a node is the goal)– (If possible) A heuristic
• We have to pick the right algorithm– We do not need to invent an algorithm

Which Algorithm to Use• Can you create an admissible heuristic? Then use A* (Rubik's Cube,
15-puzzle, GPS routing finding, maze searching…) Otherwise• Do you know the exact depth of the solution? Then use depth limited
search (frogs and toads)• Is the search tree finite, and you just want a solution (does not have
to be optimal)? Then use depth-first search.• Do you want the optimal solution, but don’t know how deep the
solution could be? Try Iterative deepening.• Do you want the optimal solution, the goal state is explicit, you have a
plan to detect repeated states, and you want the fastest possible results? Try bidirectional search (probably using Iterative deepening from both directions) (GPS route finding)

Possible Outcomes of Search• The algorithm finds the goal node, and reports success.• The algorithm keeps searching until there is nothing left in the
queue, and then reports failure. (This failure can be seen as successfully proving that there is no solution)
• The algorithm keeps searching until you run out of memory, or you run out of time and kill the program.

Diameter of a Search Problem I• The diameter of a search problem is the cost of the cheapest
solution to the hardest problem in the search space. • If all operators have the same cost, it the just tree depth at
which the cheapest goal state lies, for the worst instantiation of the problem.
• Assume both of the below are the worse cases of two problems
255
1 7
2 5
operators have the same cost operators have the varying costs
Diameter = 2
Diameter = 9

Diameter of a Search Problem II• Sometimes we know the diameter of a search problem, because
someone worked it out.• For example, for Rubik’s cube it is 20, for the 15-puzzle it is 80, for
the N Frogs and Toads problem, it is N2 + 2N etc• Let us practice stating some English sentences that capture this:
– No matter how long John spends randomly scrambling a Rubik’s cube, an optimal algorithm can always solve it in 20 moves or less.
– Susan created a new GPU-based algorithm to solve the Rubik’s cube. It was able to solve a scrambled cube in just 0.0000000001 seconds, using 23 moves. The algorithm is fast, but clearly not optimal.

Diameter of a Search Problem III• Sometimes we don’t know the diameter of a search problem, the
best we can do is provide a guess, or upper and/or lower bounds.• For example:
– For the 24-puzzle the diameter is unknown. But it is known to be at least 152 and at most 208.
– For the GPS route finding problem in Ireland, the diameter is a little more than 300 miles.

Exercise: The 2Cube Problem• Your friend takes two solved Rubik's cubes.• She scrambles each one for as long as she likes.• You task is to transform one to the other, in as
few moves possible.• What can we say about the diameter of 2Cube? ___ ≤ Diameter(2Cube) ≤ ___
Your Task

Diameter of a Search Problem IIII• Why do we care about the Diameter? Part 1• Assuming we also know the branching factor (even approximately), then
knowing the diameter give us a worst case for the problem space. For example:– A problem with a BF of 10 and a diameter of 9 means we might have to search a billion nodes
(109). If we can check 10,000 nodes a second, that would take about a day.– A problem with a BF of 5 and a diameter of 20 means we might have to search about 95 trillion
nodes (520). If we can check 10,000 nodes a second, that would take about a 300 years.
• This reasoning only applies to the worst case. It may be that most cases are much simpler. For example:– For the 15 puzzle, of the 10,461,394,944,000 solvable states, only 17 are at depth 80. Most
puzzles take under 65 moves (see distribution).– For GPS directions, most journeys are 20 miles or less.
http://kociemba.org/fifteen/fifteensolver.html

Diameter of a Search Problem V• Why do we care about the Diameter? Part 2• Knowing the diameter immediately suggests two algorithms we might want to
use.– Depth-limited search, with the depth set to the Diameter. (will be complete, but not optimal)– Iterative Deepening

A* I• A* is optimal and complete.• For any given heuristic, A* is optimally fast.• There is no point trying to beat A*, but you may be able to find a
better heuristic on a given problem.
• Suppose there are two heuristics, hA(n) and hB(n).• It could be that one is always best, then you should only use the
best one (how would you know this?)• If sometimes hA(n) is best, and other times hB(n) best, then there is
a simple trick you can do. Use hC(n), where: hC(n) = max[ hA(n) , hB(n) ]

A* IIA heuristic is a function that, when applied to a state, returns a number tells us approximately how far the state is from the goal state*.
– How many miles to drive– How many twists of the Rubik’s Cube– How many tiles we have to slide.– How many …
Note we said “approximately”. Heuristics might underestimate or overestimate the merit of a state. But for reasons which we will see, heuristics that only underestimate are very desirable, and are called admissible.

The true driving distance from BCOE to Sub Station is 0.6 miles. The straight line heuristic says it is 0.269.This is an admissible heuristic

Why Greedy Search Fails
0 22
We have developed a good visual sense of when/how greedy search fails when searching functions. Let us develop an informal sense of when greedy search fails searching trees.

Why Greedy Search FailsFind Route from Dublin to Arklow
Let us say that because the roads are pretty straight, the h(n) costs are basically the same as the true costs.
This just makes my example easier to explain, even if the h(n) estimates are lower than the true costs, my point is true.
Dublin
Arklow
Wexford
Wicklow300
100
120
60

Why Greedy Search Fails
Dublin
Arklow
Wexford
WicklowWexford
Dublin
Wicklow
Find Route from Dublin to Arklow
We expand the children of Dublin {Wexford, Wicklow }Greedy search asks “Which one of you thinks you are closest to Arklow?”Wexford thinks it is only 60 miles, but Wicklow thinks it is 120 miles, so greedy search say “Lets expand Wexford”
300
100
120
60

Why Greedy Search Fails
100
Wexford
Dublin
300
Wicklow
Arklow
60
Find Route from Dublin to Arklow
Dublin
Arklow
Wexford
Wicklow300
100
120
60
Greedy search found the goal, it was 300 + 60 = 360 miles.
Greedy search only looked at the h(n) costs, it only looked forward.

Greedy Search Vs A-Star
100
Wexford
Dublin
300
Wicklow
Find Route from Dublin to Arklow
Dublin
Arklow
Wexford
Wicklow300
100
120
60
We expand the children of Dublin {Wexford, Wicklow }A*search asks “Which one of you thinks you are closest to Arklow, after you add in the miles you have already traveled, your g(n) costs?”Wexford says, I have gone 300, and have 60 miles to go.Wicklow says, I have gone 100, and have 120 miles to go.So A* search say “Lets expand Wicklow”

Greedy Search Vs A*
100
Wexford
Dublin
300
Wicklow
Arklow
120
Find Route from Dublin to Arklow
Dublin
Arklow
Wexford
Wicklow300
100
120
60
Greedy search only looked at the h(n) costs, it only looked forward.
But A-Star look backwards and forward to make its decision. f(n) = g(n) + h(n)

Romania

Romania

Romania


Romania Problem
Initial state: AradGoal state: Bucharest
Operators: From any node, you can visit any connected node.
Operator cost, the driving distnace.
What is the BF for this problem?

These are the h(n)values.
We can use the straight line heuristic

These are the h(n)values.
These are the g(n)values.

Greedy best-first search exampleIn other words, we are searching using only the h(n)

We expand all possible operators (there are three), and then expand the cheapest node on the fringe…
374329253

Now the cheapest node on the fringe is Fagaras, so we expand it

Is this optimal?
So, Arad to Sibiu to Fagaras to Bucharest140 + 99 + 211 = 450
We are done!

Properties of greedy best-first search• Complete? No – can get stuck in loops, e.g., • Iasi Neamt Iasi Neamt…• But, complete in finite space with repeated state
checking! (may take a lot of memory)
• Time? O(bm), but a good heuristic can give dramatic improvement Similar to depth-first search
Space? O(bm) -- keeps all nodes in memory•• Optimal? No!

A* Search
• Idea: avoid expanding paths that are already relatively expensive• Evaluation function f(n) = g(n) + h(n)•– g(n) = cost so far to reach n – h(n) = estimated cost from n to goal– f(n) = estimated total cost of path through n to goal
Intuition: Greedy best-first search expands the node that appears to have shortest path to goal (looks only forward). But what about cost of getting to that node? Take it into account (also look backwards)!
Aside: do we still have “looping problem”?Iasi to Fagaras:Iasi Neamt Iasi Neamt…
No! We’ll eventually get out of it, because g(n) keeps going up.

A* search exampleIn other words, we are searching using the sum of h(n) and g(n)
f(n) = h(n) and g(n)




Bucharest appears on the fringe but not selected for expansion
since its cost (450)is higher than that of Pitesti (417).

A* found the optimal path!
A* found: Arad to Sibiu to Rimnicu to Pitesti to Bucharest = 418 milesGreedy Search found: Arad to Sibiu to Fagaras to Bucharest = 450 miles

Blind Search
The search techniques we have seen so far...
• Breadth first search• Uniform cost search• Depth first search• Depth limited search • Iterative Deepening• Bi-directional Search
Would also find the optimal solution, but would have expanded more nodes (memory problems)
Will not find optimal solution (in general)
Will not find optimal solution (in general)
Would also find the optimal solution, but would have expanded more nodes (no memory problems, but time problems) Would also find the optimal solution, assuming both algorithms used would have found the optimal solution

Optimizing Search: Our Role• We have to define the problem space
– State Representation: An array of real numbers, a linked list, a tree, a bitstring, a matrix..
– Operators: We want to make sure we can reach any state, from any state.
– An evaluation function. Takes in a state, gives us a single number score
• We have to pick the right algorithm– We do not need to invent an algorithm– We have to be resigned to the fact that we generally will never know if we
have the optimal solution.
An array of real numbers a tree
C A E F BD A
a linked list

Optimizing Search: Algorithms• Greedy Search: Create a random state, apply all operators, pick the best child as
the new current state, repeat until all children are worse than current state. • Greedy Search with Random Restarts: Do Greedy Search as many times as you
can afford, keep the best answer. Easy to parallelise.• Simulated Annealing: Do greedy search, but in the early iterations, pick among
the children randomly. Very very slowly, begin to pick less randomly, favoring the better children, until you are always picking the best child (i.e. greedy search). – If you smoothly fade from random to greedy slowly enough, this will be optimal. In practice
“slowly enough” is too slow to be practical. However, Simulated Annealing still tends to work very well in practice.
• Genetic Algorithm: Within your time budget: Create a population of random states. Evaluate them. “Kill of” most of the bad state. Replace them with children of the better state, by using crossover (sex) or mutation. – There are lots of parameters to set.

Optimizing Search: Discussion• The quality of the solution we will find depends a lot on the solution space.
– Is it smooth?– Are there many good solutions, or just one?
• We can answer that question in one or two dimensions, but not for higher dimensional problems (in general).
Is it smooth? Are there many good solutions, or just one?

Sample Optimization ProblemHere we have a state which is divided into 50 precincts.
We have the task of assigning 5 districts of equal sizes.
The overall election is decided by who wins the most districts.
If, instead, the party that captured the most precincts won, this state would go to the blue party.Popular vote

Sample Optimization ProblemFor a sensible assignments of five districts, the blue party does win.
All precincts in a districts must be connected.

Sample Optimization ProblemHowever, we can search for assignments of the five districts, such that red wins!
This is called Gerrymandering
One basic idea of Gerrymandering, try to have just one or two districts that concentrate almost all of your rival.

Sample Optimization ProblemHere is a real world example.
We could frame Gerrymandering as an optimization problem.
• What would be the initial state?• What are the operators?• What is the evaluation function?
Gerrymandered 4th Congressional District in Illinois

Sample Optimization Problem
Parts Layout for Waterjet cutting

Sample Optimization Problem
We need to make 50,000 of this part. How many blank sheets of metal do we need?

34% of the metal is wasted
19% of the metal is wasted
Xie et al. Nesting of two-dimensional irregular parts: an integrated approach. International Journal of Computer Integrated Manufacturing, Vol. 20, No. 8, December 2007, 741 – 756
Sample Optimization Problem

This is an example of super human AI. No human could do as well as an algorithm on a complex parts layout job.

Adversarial Search

Specific Setting Two-player, turn-taking, deterministic, fully observable, zero-sum, time-constrained game. The generalizations beyond this are fairly
simple
State space (like the problem space) Initial state Operators: (Successor function): Which
actions can be executed in each state MAX’s and MIN’s actions alternate, with MAX
playing first in the initial state Terminal test: it tells if a state is terminal
and, if yes, if it’s a win or a loss for MAX, or a draw
All states are fully observable

Here, uncertainty is caused by the actions of another agent (MIN), who competes with our agent (MAX)

MIN wants MAX to lose (and vice versa)
At each turn, the choice of which action to perform must be made within a specified time limit
The state space is enormous: only a tiny fraction of this space can be explored within the time limit

Game Tree (for a single game, not the full search tree)
MAX’s play
MIN’s play
Terminal state(win for MAX) Here, symmetries have been used to reduce
the branching factor
MIN nodes
MAX nodes
MIN nodes
MAX nodes
MAX nodes

Game Tree
MAX’s play
MIN’s play
Terminal state(win for MAX)
In general, the branching factor and the depth of terminal states are largeChess:• Number of states: ~1040
• Branching factor: ~35• Number of total moves in a game: ~100

Choosing an Action: Basic Idea
1) Using the current state as the initial state, build the game tree uniformly to the maximal depth h (called horizon) feasible within the time limit
2) Evaluate the states of the nodes on the horizon
3) Back up the results from the leaves to the root and pick the best action assuming the worst from MIN
Minimax algorithm

Evaluation Function Function e: state s number e(s) e(s) is a heuristic that estimates how
favorable s is for MAX e(s) > 0 means that s is favorable to
MAX (the larger the better)
e(s) < 0 means that s is favorable to MIN
e(s) = 0 means that s is neutral

Example: Tic-tac-Toee(s) = number of rows, columns, and diagonals open for MAX - number of rows, columns,
and diagonals open for MIN
8-8 = 0 6-4 = 2 3-3 = 0

Construction of an Evaluation Function
Usually a weighted sum of “features”:
Features may include Number of pieces of each type Number of possible moves Number of squares controlled
n
i ii=1
e(s)= wf(s)

Backing up Values
6-5=1 5-6=-15-5=05-5=0 6-5=1 5-5=1 4-5=-1 5-6=-1 6-4=25-4=16-6=0 4-6=-2
-1 -2 1
1Tic-Tac-Toe treeat horizon = 2 Best move
We are pretending that because of time requirements, we can only look ahead two moves.Of course, for Tic-Tac-Toe we could go all the way to the terminal states. But for most real games, we could never evaluate the full tree.

Continuation
0
1
1
1 32 11 2
1
0
1 1 0
0 2 01 1 1
2 22 3 1 2

Why using backed-up values?
At each non-leaf node N, the backed-up value is the value of the best state that MAX can reach at depth h if MIN plays well (by the same criterion as MAX applies to itself)
If e is to be trusted in the first place, then the backed-up value is a better estimate of how favorable STATE(N) is than e(STATE(N))

Minimax Algorithm1. Expand the game tree uniformly from the
current state (where it is MAX’s turn to play) to depth h
2. Compute the evaluation function at every leaf of the tree
3. Back-up the values from the leaves to the root of the tree as follows:a. A MAX node gets the maximum of the evaluation of
its successorsb. A MIN node gets the minimum of the evaluation of
its successors4. Select the move toward a MIN node that has
the largest backed-up value

Minimax Algorithm1. Expand the game tree uniformly from the
current state (where it is MAX’s turn to play) to depth h
2. Compute the evaluation function at every leaf of the tree
3. Back-up the values from the leaves to the root of the tree as follows:a. A MAX node gets the maximum of the evaluation of
its successorsb. A MIN node gets the minimum of the evaluation of
its successors4. Select the move toward a MIN node that has
the largest backed-up value
Horizon: Needed to return a decision within allowed time

Game Playing (for MAX)Repeat until a terminal state is
reached1. Select move using Minimax2. Execute move3. Observe MIN’s move
Note that at each cycle the large game tree built to horizon h is used to select only one moveAll is repeated again at the next cycle (a sub-tree of depth h-2 can be re-used)
1 2 3

Can we do better?Yes ! Much better !
3
-1
Pruning
-1
3
This part of the tree can’t have any effect on the value that will be backed up to the root

Alpha-Beta Pruning
Explore the game tree to depth h in depth-first manner
Back up alpha and beta values whenever possible
Prune branches that can’t lead to changing the final decision
alpha and beta, represent the maximum score that the maximizing player is assured of and the minimum score that the minimizing player is assured of respectively

Alpha-Beta Algorithm Update the alpha/beta value of the parent
of a node N when the search below N has been completed or discontinued
Discontinue the search below a MAX node N if its alpha value is the beta value of a MIN ancestor of N
Discontinue the search below a MIN node N if its beta value is the alpha value of a MAX ancestor of N

Example
0 5 -3 25-2 32-3 033 -501 -350 1-55 3 2-35

Example
0 5 -3 25-2 32-3 033 -501 -350 1-55 3 2-35
0

Example
0 5 -3 25-2 32-3 033 -501 -350 1-55 3 2-35
0
0

Example
0 5 -3 25-2 32-3 033 -501 -350 1-55 3 2-35
0
0 -3

Example
0 5 -3 25-2 32-3 033 -501 -350 1-55 3 2-35
0
0 -3

Example
0 5 -3 25-2 32-3 033 -501 -350 1-55 3 2-35
0
0
0 -3

Example
0 5 -3 25-2 32-3 033 -501 -350 1-55 3 2-35
0
0
0 -3 3
3

Example
0 5 -3 25-2 32-3 033 -501 -350 1-55 3 2-35
0
0
0 -3 3
3

Example
0 5 -3 25-2 32-3 033 -501 -350 1-55 3 2-35
0
0
0
0 -3 3
3
0

Example
0 5 -3 25-2 32-3 033 -501 -350 1-55 3 2-35
0
0
0
0 -3 3
3
0
5

Example
0 5 -3 25-2 32-3 033 -501 -350 1-55 3 2-35
0
0
0
0 -3 3
3
0
2
2

Example
0 5 -3 25-2 32-3 033 -501 -350 1-55 3 2-35
0
0
0
0 -3 3
3
0
2
2

Example
0 5 -3 25-2 32-3 033 -501 -350 1-55 3 2-35
0
0
0
0 -3 3
3
0
2
2
2
2

Example
0 5 -3 25-2 32-3 033 -501 -350 1-55 3 2-35
0
0
0
0 -3 3
3
0
2
2
2
2

Example
0 5 -3 25-2 32-3 033 -501 -350 1-55 3 2-35
0
0
0
0 -3 3
3
0
2
2
2
2
0

Example
0 5 -3 25-2 32-3 033 -501 -350 1-55 3 2-35
0
0
0
0 -3 3
3
0
2
2
2
2
5
0

Example
0 5 -3 25-2 32-3 033 -501 -350 1-55 3 2-35
0
0
0
0 -3 3
3
0
2
2
2
2
1
1
0

Example
0 5 -3 25-2 32-3 033 -501 -350 1-55 3 2-35
0
0
0
0 -3 3
3
0
2
2
2
2
1
1
-3
0

Example
0 5 -3 25-2 32-3 033 -501 -350 1-55 3 2-35
0
0
0
0 -3 3
3
0
2
2
2
2
1
1
-3
0

Example
0 5 -3 25-2 32-3 033 -501 -350 1-55 3 2-35
0
0
0
0 -3 3
3
0
2
2
2
2
1
1
-3
1
1
0

Example
0 5 -3 25-2 32-3 033 -501 -350 1-55 3 2-35
0
0
0
0 -3 3
3
0
2
2
2
2
1
1
-3
1
1
-5
0

Example
0 5 -3 25-2 32-3 033 -501 -350 1-55 3 2-35
0
0
0
0 -3 3
3
0
2
2
2
2
1
1
-3
1
1
-5
0

Example
0 5 -3 25-2 32-3 033 -501 -350 1-55 3 2-35
0
0
0
0 -3 3
3
0
2
2
2
2
1
1
-3
1
1
-5
-5
-5
0

Example
0 5 -3 25-2 32-3 033 -501 -350 1-55 3 2-35
0
0
0
0 -3 3
3
0
2
2
2
2
1
1
-3
1
1
-5
-5
-5
0

Example
0 5 -3 25-2 32-3 033 -501 -350 1-55 3 2-35
0
0
0
0 -3 3
3
0
2
2
2
2
1
1
-3
1
1
-5
-5
-5
0
1

Example
0 5 -3 25-2 32-3 033 -501 -350 1-55 3 2-35
0
0
0
0 -3 3
3
0
2
2
2
2
1
1
-3
1
1
-5
-5
-5
2
2
2
2
1
1

Example
0 5 -3 25-2 32-3 033 -501 -350 1-55 3 2-35
0
0
0
0 -3 3
3
0
2
2
2
2
1
1
-3
1
1
-5
-5
-5
1
2
2
2
2
1

How much do we gain?Consider these two cases:
3
a = 3
-1
b=-1
(4)
3
a = 3
4
b=4
-1

How much do we gain? Assume a game tree of uniform branching factor
b Minimax examines O(bh) nodes, so does alpha-
beta in the worst-case The gain for alpha-beta is maximum when:
• The MIN children of a MAX node are ordered in decreasing backed up values
• The MAX children of a MIN node are ordered in increasing backed up values
Then alpha-beta examines O(bh/2) nodes [Knuth and Moore, 1975]
But this requires an oracle (if we knew how to order nodes perfectly, we would not need to search the game tree)
If nodes are ordered at random, then the average number of nodes examined by alpha-beta is ~O(b3h/4)