
Association Rule Mining (Some material adapted from: Mining Sequential Patterns by Karuna Pande...
27
Association Rule Association Rule Mining Mining (Some material adapted from: (Some material adapted from: Mining Sequential Patterns by Karuna Pande Joshi) Mining Sequential Patterns by Karuna Pande Joshi)
-
date post
21-Dec-2015 -
Category
Documents
-
view
216 -
download
0
Transcript of Association Rule Mining (Some material adapted from: Mining Sequential Patterns by Karuna Pande...

Association Rule MiningAssociation Rule Mining
(Some material adapted from:(Some material adapted from:
Mining Sequential Patterns by Karuna Pande Joshi)Mining Sequential Patterns by Karuna Pande Joshi)
22

33
An ExampleAn Example

44
TerminologyTerminology
Item
Itemset
Transaction

55
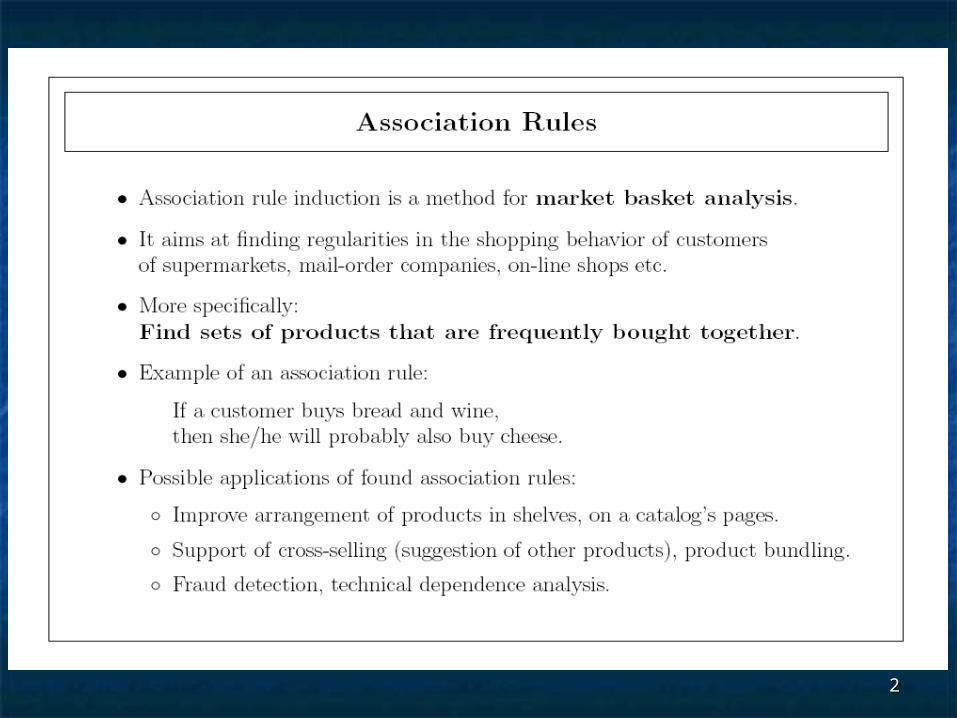
Association RulesAssociation Rules
Let Let UU be a set of items and let be a set of items and let XX, , YY UU, with , with XX YY = =
An association rule is an expression An association rule is an expression of the form of the form XX YY, whose meaning is:, whose meaning is: If the elements of If the elements of XX occur in some occur in some
context, then so do the elements of context, then so do the elements of YY

66
Quality MeasuresQuality Measures
Let T be set of all transactions. The Let T be set of all transactions. The following statistical quantities are relevant following statistical quantities are relevant to association rule mining:to association rule mining: support(X)support(X)
|{t |{t T: X T: X t}| / |T|t}| / |T| support(support(X X YY) )
|{t |{t T: XT: XY Y t}| / |T|t}| / |T| confidence(confidence(XX YY) )
|{t |{t T: XT: XY Y t}| / |{t t}| / |{t T: X T: X t}|t}|
The percentage of all transactions, containing item set x
The percentage of all transactions, containing both item sets x and y
The percentage of transactions containing item set x, that also contain item set y. How good is item set x at predicting item set y.

77
Learning AssociationsLearning Associations
The purpose of association rule learning is to find “interesting” rules, i.e., rules that meet the following two user-defineduser-defined conditions: support(support(XX YY) ) MinSupportMinSupport confidence(confidence(XX YY) ) MinConfidenceMinConfidence

88
ItemsetsItemsets
Frequent itemsetFrequent itemset An itemset whose support is greater An itemset whose support is greater
than MinSupport (denoted Lthan MinSupport (denoted Lkk where where kk is is the size of the itemset)the size of the itemset)
Candidate itemsetCandidate itemset A potentially frequent itemset (denoted A potentially frequent itemset (denoted
CCkk where where kk is the size of the itemset) is the size of the itemset)
High percentage of transactions contain the full item set.

99
Basic IdeaBasic Idea
Generate all frequent itemsets Generate all frequent itemsets satisfying the condition on minimum satisfying the condition on minimum supportsupport
Build all possible rules from these Build all possible rules from these itemsets and check them against the itemsets and check them against the condition on minimum confidencecondition on minimum confidence
All the rules above the minimum All the rules above the minimum confidence threshold are returned for confidence threshold are returned for further evaluationfurther evaluation

1010

1111

1212


1414

1515

1616

1717

1818

1919

2020

2121

2222
AprioriAll (I)AprioriAll (I) LL11 For each item For each item IIjj II
count({count({IIjj}) = | {}) = | {TTi i : : IIjj TTii} |} | If count({If count({IIjj}) }) MinSupportMinSupport x x mm
LL11 LL11 {({ {({IIjj}, count({}, count({IIjj})}})} kk 2 2 While While LLkk-1-1
LLkk For each (For each (ll11, count(, count(ll11)) )) LLkk-1-1
For each (For each (ll22, count(, count(ll22)) )) LLkk-1-1 If (If (ll11 = { = {jj11, …, , …, jjkk-2-2, , xx} } ll22 = { = {jj11, …, , …, jjkk-2-2, , yy} } xx yy))
ll { {jj11, …, , …, jjkk-2-2, , xx, , yy}} count(count(ll) ) | { | {TTi i : : ll TTi i } |} | If count(If count(ll) ) MinSupportMinSupport x x mm
LLkk LLkk {( {(ll, count(, count(ll))}))} kk k k + 1+ 1
Return Return LL11 LL22… … LLk-1k-1
The number of all transactions, containing item I_j
If this count is big enough, we add the item and count to a stack, L_1

Rule GenerationRule Generation
Look at set {a,d,e}Look at set {a,d,e} Has six candidate association rules:Has six candidate association rules:
{a}{a}{d,e} confidence: {a,d,e} / {a} = 0.571{d,e} confidence: {a,d,e} / {a} = 0.571 {d,e}{d,e}{a} confidence: {a,d,e} / {d,e} = 1.000{a} confidence: {a,d,e} / {d,e} = 1.000 {d}{d}{a,e} confidence: {a,d,e} / {d} = 0.667{a,e} confidence: {a,d,e} / {d} = 0.667 {a,e}{a,e}{d} confidence: {a,d,e} / {a,e} = 0.667{d} confidence: {a,d,e} / {a,e} = 0.667 {e}{e}{a,d} confidence: {a,d,e} / {e} = 0.571{a,d} confidence: {a,d,e} / {e} = 0.571 {a,d}{a,d}{e} confidence: {a,d,e} / {a,d} = 0.800{e} confidence: {a,d,e} / {a,d} = 0.800

Confidence-Based Pruning Confidence-Based Pruning

Rule GenerationRule Generation
Look at set {a,d,e}. Let Look at set {a,d,e}. Let MinConfidenceMinConfidence == 0.800 == 0.800 Has six candidate association rules:Has six candidate association rules:
{d,e}{d,e}{a} confidence: {a,d,e} / {d,e} = 1.000{a} confidence: {a,d,e} / {d,e} = 1.000 {a,e}{a,e}{d} confidence: {a,d,e} / {a,e} = 0.667{d} confidence: {a,d,e} / {a,e} = 0.667 {a,d}{a,d}{e} confidence: {a,d,e} / {a,d} = 0.800{e} confidence: {a,d,e} / {a,d} = 0.800 {d}{d}{a,e} confidence: {a,d,e} / {d} = 0.667{a,e} confidence: {a,d,e} / {d} = 0.667
Selected Rules:Selected Rules: {d,e}{d,e}a and {a,d}a and {a,d}ee

2626
SummarySummary
Apriori is a rather simple algorithm Apriori is a rather simple algorithm that discovers useful and interesting that discovers useful and interesting patternspatterns
It is widely usedIt is widely used It has been extended to create It has been extended to create
collaborative filtering algorithms to collaborative filtering algorithms to provide recommendationsprovide recommendations

2727
ReferencesReferences
Fast Algorithms for Mining Association Rules (1994)Fast Algorithms for Mining Association Rules (1994) Rakesh Agrawal, Ramakrishnan Srikant. Proc. 20th Int. Conf. Rakesh Agrawal, Ramakrishnan Srikant. Proc. 20th Int. Conf.
Very Large Data Bases, VLDB (Very Large Data Bases, VLDB (PDFPDF))
Mining Association Rules between Sets of Items in Mining Association Rules between Sets of Items in Large Databases (1993)Large Databases (1993) Rakesh Agrawal, Tomasz Imielinski, Arun Swami. Proceedings Rakesh Agrawal, Tomasz Imielinski, Arun Swami. Proceedings
of the 1993 ACM SIGMOD International Conference on of the 1993 ACM SIGMOD International Conference on Management of DataManagement of Data
Introduction to Data Mining Introduction to Data Mining P-N. Tan, M. Steinbach and V. Kumar, Introduction to Data P-N. Tan, M. Steinbach and V. Kumar, Introduction to Data
Mining, Pearson Education Inc., 2006, Chapter 6 Mining, Pearson Education Inc., 2006, Chapter 6


















