
Architecture of the Upcoming OrangeFS v3 Distributed Parallel File System
24
A View into the Future of OrangeFS Boyd Wilson (Boydw at Omnibond dot com) 9/12/2014
-
Upload
all-things-open -
Category
Technology
-
view
362 -
download
1
Transcript of Architecture of the Upcoming OrangeFS v3 Distributed Parallel File System

A View into the Future of OrangeFS
Boyd Wilson (Boydw at Omnibond dot com)
9/12/2014

Outline • Overview of types of file systems • Why do We Care • What is Missing • A look at what is coming

File System Types - Block level Local…
Local Examples: XFS, EXT, BTR, ZFS, etc… Topology: JBOD, Internal, SAN Uses: Small Files, Applications, Databases (Small-IO)
Limits: Bandwidth & Storage of a Single Node Resilience: RAID
Server
SAN
Storage
Server
JBOD
Server

File System Types - Block level SAN… Failover Cluster Examples: CFS, OCFS2, DRBD(kinda), etc…
Topology: SAN or Virtual SAN (DRBD) Uses: Small Files, Applications, Databases (Small-IO)
Limits: Network Bandwidth of Single Node Resilience: RAID &/or Storage Host Failure
Server
SAN
Storage
Virtual SAN
Server Server Server

File System Types – Object Store… Hash based Examples: Swift, Ceph, etc…
Topology BE: Distributed Local, JBOD or SAN Topology FE: Network (IP) Uses: Files as Objects, Larger IO, Non-Posix, VM Image Limits: Poor for Small IO, Fixed Hash Location Resilience: Storage Server Failure (built in)
Server Network (IP)
Storage Storage
Server Server
Storage Storage
Server
Storage
Server
Object Based Clients

File System Types – Parallel / Distributed… Hash based Examples: Gluster, Ceph (on top of Object Store)
Topology BE: Distributed Local, JBOD or SAN Topology FE: Network IP Uses: Large File IO, Posix, VM Image Limits: Poor for Small IO, Fixed Hash size, possible hot spots to hashed volume Resilience: Replicated Volumes (if not striped)
Server Network (IP)
Storage Storage
Server Server
Storage Storage
Server
Storage
Server
Posix Based Clients

Distributed Hash Based Concepts
• Gluster uses an algorithm based on filename – Replicate or stripe at the Volume level (not both) – Striping requires MD like lookup
• Ceph uses its crush algorithm – object pool level replication based on rules, – object writes may have to go through a primary OSD to get to Secondary – Ceph file system implementation on top of object store uses metadata.
File or Object
S1 S2 S3 S4
Algorithm
Virt1 Virt2 Virt3 Virt4 Virt5 Virt6 Virt7

File System Types – Parallel / Distributed… Single MD Examples: Lustre, HDFS, MooseFS etc…
Topology BE: Distributed Local, JBOD or SAN Topology FE: Network IP &/or IB Uses: HPC(Lustre), Large File IO, posix, Limits: Poor for Small IO, MD Hot Spots, Append only (HDFS)
Resilience: HA Configuration (Lustre), Replicated Files Only (MooseFS, HDFS)
OSD
Network (IP)
Storage Storage
OSD OSD
Storage Storage
OSD
Storage
MDS
Parallel IO Clients

File System Types – Parallel / Distributed…
Distributed MD Examples: OrangeFSv2, GPFS, FhGFS, etc… Topology BE: Distributed Local, JBOD or SAN Topology FE: Network IP, IB, Portals Uses: HPC, Large File IO, posix, Large file DB Limits: Not great for Small IO, Resilience: HA (OrangeFSv2, add on), (GPFS built in)
O+MD
Network (IP, IB, Portals)
Storage Storage
O+MD O+MD
Storage Storage
O+MD
Storage
O+MD
Parallel IO Clients
Shared Nothing Metadata Architecture

Server Metadata Filedata
Network
Server Metadata Filedata
Server Metadata Filedata
Server Metadata Filedata
Server Metadata Filedata
Server Metadata Filedata
Server Metadata Filedata
Server Metadata Filedata
Server Metadata Filedata
Client Parallel File IO
Server Metadata Filedata
Server Metadata Filedata
Server Metadata Filedata
- Reads/Writes on a file with a Stripe size of 4 - Stripe can be set on System, Directory or File
- Reads/Writes on a file with a Stripe size of 8
- Reads/Writes on a file with a Stripe size of 1, a “Stuffed” file, MD/FD resides on 1 Server
Server Metadata Filedata
Network
Server Metadata Filedata
Server Metadata Filedata
Server Metadata Filedata
Server Metadata Filedata
Server Metadata Filedata
Server Metadata Filedata
Server Metadata Filedata
Server Metadata Filedata
Client Directory IO
Server Metadata Filedata
Server Metadata Filedata
Server Metadata Filedata
- Directory has grown to a large number of Directory Entries and has created a Distributed Hash for Directory entries.
- Directory path building request (v2.9) - Cached once built for performance
Parallel Client Interactions (OrangeFSv2)
Metadata
Filedata
Legend

Types of File Systems Summary… Block
File Systems Local: small files, apps, compiles, etc.. SAN: Storage Area network, same as local.
Network File Handling / System
Protocols
Native: Remote access to file system data HTTP: used more for object level access, sing Parallel: PVFS, pNFS
Distributed Hash Based Systems
Replicated Object Stores: Ceph, Swift, etc… Replicated Volumes: Gluster
Centralized MD: Lustre Centralized MD Replicated FS: HDFS, MooseFS Distributed MD: OrangeFS (v2), GPFS
Metadata Based Distributed Systems
Replicated Metadata & File Object
Replicated Distributed Objects (FD, Stripes & MD), Distributed Directories, Capability Based Security with Parallel file based network protocol.

Why Do We Care about Parallel?
16 Storage Servers with 2 LVM’d 5+1 RAID sets under OrangeFSv2 were tested with up to 32 clients over 10g Ethernet, with read performance reaching nearly 12GB/s (96Gb/s) and write performance reaching nearly 8GB/s (64Gb/s).
0 2 4 6 8
10 12 14
2 4 8 16 32
GB
/s
Number of kmod clients
Aggregate Writes Aggregate Reads

Why Else Do We Care? Unified Name Space All files accessible from a single mount point
Parallel Client Protocol
Distributes load Increases aggregate throughput
MPIIO Enables programs to directly leverage parallel storage, seriously increases performance
Enables the Future New levels of Redundancy / Availability / Stability New levels of Protection New levels of Performance

What’s Missing? Availability Distributed Primary Object Replication
Adjustable Write Confidence Real Time Object Replication Geographic File Replication Customizable Data Placement Rules
Security Capability based Security Client Trust Levels
Data Integrity PBJ (Parallel Background Jobs) Replica Verification and Repair Metadata Verification and Repair Checksum Verification and Repair
Administration & Monitoring
Advanced Web UI and Command options for Admins Monitoring health in Web UI and Web-Service Calls
Maintenance File Redistribution (Load or Space driven) Online Storage Node Addition and Removal

OrangeFS Version Picture Availability • Replicated Metadata • Replicated File Objects
Data Integrity • PBJ • Checksums • WAN Replication • Background Healing
Maintenance • Online Node Addition • Online Node Removal • Online Rebalance • Web Administration
Diverse Clients • Linux • Windows • WebDAV • Hadoop Ecosystem
Performance • Configurable Striping • Distributed Metadata • Parallel Protocol
Security • Capabilities • PKI based infrastructure
Exists in OrangeFS Now (in v2.9)
Slated for Future (in v3.0)

To maintain coherence and minimize hot spots and leverage all hardware for IO, Primary Objects will be distributed across the FS Nodes.
Server Metadata Filedata
Network
Server Metadata Filedata
Server Metadata Filedata
Server Metadata Filedata
Server Metadata Filedata
Server Metadata Filedata
Server Metadata Filedata
Server Metadata Filedata
Server Metadata Filedata
Distributed Primary Object Replication
Server Metadata Filedata
Server Metadata Filedata
Server Metadata Filedata
Metadata
Filedata
Legend
Replication
Server Metadata Filedata
Server Metadata Filedata
Server Metadata Filedata
Server Metadata Filedata
Objects (Strips) are replicated based on Data Placement Rules in Real Time with a Split Flow.
To maintain performance Write Confidence can be configured to allow for continuation after n number of objects have been written to.
Availability
Server Metadata Filedata
Server Metadata Filedata
Server Metadata Filedata
Server Metadata Filedata
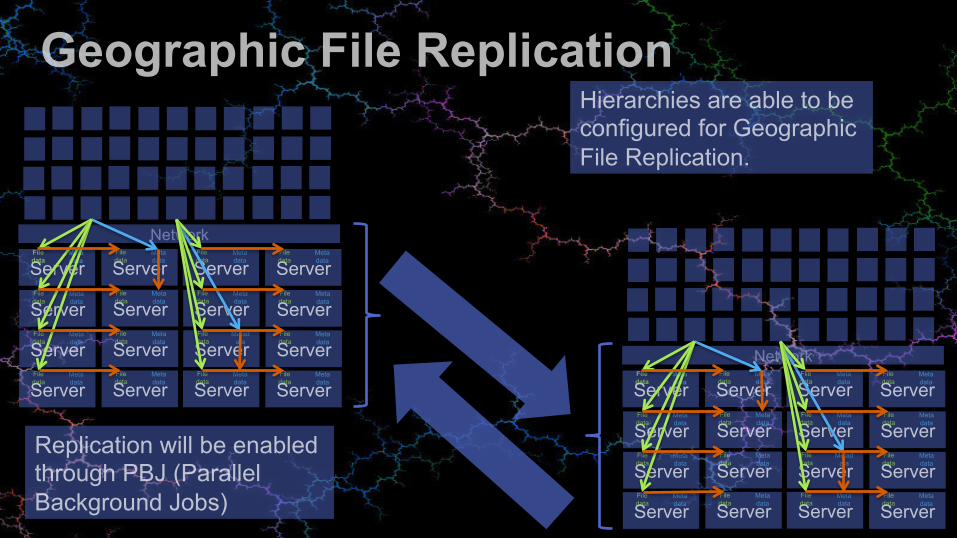
Geographic File Replication
Server Meta data
File data
Network
Server Meta data
File data Server
Meta data
File data
Server Meta data
File data Server
Meta data
File data Server
Meta data
File data
Server Meta data
File data Server
Meta data
File data Server
Metadata
File data
Server Meta data
File data Server
Meta data
File data Server
Meta data
File data
Server Meta data
File data
Server Meta data
File data
Server Meta data
File data
Server Meta data
File data Server
Meta data
File data
Network
Server Meta data
File data Server
Meta data
File data
Server Meta data
File data Server
Meta data
File data Server
Meta data
File data
Server Meta data
File data Server
Meta data
File data Server
Metadata
File data
Server Meta data
File data Server
Meta data
File data Server
Meta data
File data
Server Meta data
File data
Server Meta data
File data
Server Meta data
File data
Server Meta data
File data
Hierarchies are able to be configured for Geographic File Replication.
Replication will be enabled through PBJ (Parallel Background Jobs)

Security
With v2.9 Capabilities are the foundation of security. UIDs and GIDs are supported, other security models can be implemented in the future.
Server
Network
Server
Server
Server
Server
Server
Server
Server
Untrusted Trusted With v2.9 untrusted clients are supported by leveraging file system certificates
Cap
abili
ties
In future trusted clients will be validated by server based certificates

Data Integrity PBJ (Parallel Background Jobs) will leverage the distributed processing of the storage cluster to perform necessary FS actions.
Server PBJ
Network
Parallel Background Jobs
Server PBJ
Server PBJ
Server PBJ
Server PBJ
Server PBJ
Server PBJ
Server PBJ
Server PBJ
Server PBJ
Server PBJ
Server PBJ
Server PBJ
Server PBJ
Server PBJ
Server PBJ
PBJ will be able to verify and repair file and metadata object replicas in parallel while the file system is online.
PBJ will be able to verify and repair the metadata entries in parallel while the file system is online.
PBJ will be able to verify and repair file object checksums in parallel while the file system is online.

Maintenance PBJ will be able to drain objects off of nodes that need to be removed, in parallel, while the file system is online.
Server PBJ
Network
Parallel Background Jobs
Server PBJ
Server PBJ
Server PBJ
Server PBJ
Server PBJ
Server PBJ
Server PBJ
Server PBJ
Server PBJ
Server PBJ
Server PBJ
Server PBJ
Server PBJ
Server PBJ
Server PBJ
PBJ will be able to redistribute objects to new nodes, in parallel, while the file system is online.
PBJ will be able to redistribute objects across existing nodes, to level storage and load in parallel, while the file system is online.

Administration and Monitoring Management Commands and an Adaptive Web UI will be available for Administration and Monitoring.
PBJ will be used to gather statistics and information in parallel and be made available for Administration and Monitoring
Administration and Monitoring information will be available via web services for simplicity and automation.

Scaling and Performance
To improve metadata performance LMDB is being integrated. LMDB leverages memory maps for memory speed access without the need for cache.
To increase scaling 128bit UUIDs are implemented for Object and Server Identifiers.
The (OID, SID) tuple is unique within the file system and used to address all objects.
Server Server Server Server Server Server Server Server Server Server Server Server
Server Server Server Server
Server Server Server Server Server Server Server Server Server Server Server Server
Server Server Server Server
Server Server Server Server Server Server Server Server Server Server Server Server
Server Server Server Server
Server Server Server Server Server Server Server Server Server Server Server Server
Server Server Server Server
v3 will use local SID caches to locate other servers it regularly interacts with. A Server location process will be used to locate others as needed.
… …

Thank You
Thank You…
Community www.orangefs.org Support www.orangefs.com Company www.omnibond.com

Intelligent
Transportation Solutions
Identity Manager Drivers & Sentinel
Connectors
Parallel Scale-‐Out Storage Software
Social Media
Interaction System
Solution Areas


















