
Apprentissage Supervisé Relationnel par Algorithmes d ...
251
HAL Id: tel-00947322 https://tel.archives-ouvertes.fr/tel-00947322 Submitted on 15 Feb 2014 HAL is a multi-disciplinary open access archive for the deposit and dissemination of sci- entific research documents, whether they are pub- lished or not. The documents may come from teaching and research institutions in France or abroad, or from public or private research centers. L’archive ouverte pluridisciplinaire HAL, est destinée au dépôt et à la diffusion de documents scientifiques de niveau recherche, publiés ou non, émanant des établissements d’enseignement et de recherche français ou étrangers, des laboratoires publics ou privés. Apprentissage Supervisé Relationnel par Algorithmes d’Évolution Sébastien Augier To cite this version: Sébastien Augier. Apprentissage Supervisé Relationnel par Algorithmes d’Évolution. Apprentissage [cs.LG]. Université Paris Sud - Paris XI, 2000. Français. tel-00947322
Transcript of Apprentissage Supervisé Relationnel par Algorithmes d ...

HAL Id: tel-00947322https://tel.archives-ouvertes.fr/tel-00947322
Submitted on 15 Feb 2014
HAL is a multi-disciplinary open accessarchive for the deposit and dissemination of sci-entific research documents, whether they are pub-lished or not. The documents may come fromteaching and research institutions in France orabroad, or from public or private research centers.
L’archive ouverte pluridisciplinaire HAL, estdestinée au dépôt et à la diffusion de documentsscientifiques de niveau recherche, publiés ou non,émanant des établissements d’enseignement et derecherche français ou étrangers, des laboratoirespublics ou privés.
Apprentissage Supervisé Relationnel par Algorithmesd’ÉvolutionSébastien Augier
To cite this version:Sébastien Augier. Apprentissage Supervisé Relationnel par Algorithmes d’Évolution. Apprentissage[cs.LG]. Université Paris Sud - Paris XI, 2000. Français. �tel-00947322�

ORSAYNo d'ordre : 6420UNIVERSIT de PARIS-SUDU.F.R. SCIENTIFIQUE D'ORSAY
THSEprsente pour obtenirLe TITRE de DOCTEUR EN SCIENCESSp�ecialit�e : InformatiquePARM. S�ebastien AUGIERSUJET : Apprentissage Supervis�e Relationnel parAlgorithmes d'�EvolutionSoutenue le 19 d�ecembre 2000 devant la Commission d'examenM. Didier Fayard (pr�esident)M. Yves Kodrato�M. Jacques NicolasM. Marc Schoenauer (rapporteur)M. Gilles Venturini (rapporteur)


Abstract :This thesis investigates the application of evolutionary-based algorithms to the problem of inducingrelational rules from positive and negative examples.We �rst study a language bias that allows enough expressivity to cover at the same time relationallearning from interpretations, and classical propositional languages. Even though the induction cost forthese languages is characterized by NP-completeness on the subsumption test, a practical solution suitablefor real complex problems is proposed.The SIAO1 system, which uses this language bias to learn relational rules, is then presented. It is basedon an evolutionary search strategy characterized by :{ mutation and crossover operators driven by background knowledge and learning examples ;{ a bottom-up search direction that respects the ordering relation de�ned over the language.SIAO1 is then compared to other systems on various classical machine learning bases, proving its polyva-lency. These tests also show that this system compares well to the other approaches and that few learningand evaluation biases are demanded from the user.The third part of this work concerns two generic parallel architectures derived from asynchronous master-slave and pipeline models. These architectures are studied from the point of view of their scalability (ie.dependance on the dataset size) and expected speed-up. A simple but accurate prediction model toforecast the performance of these architectures is also proposed.R�esum�e :Cette thse concerne l'apprentissage de rgles relationnelles partir d'exemples et de contre-exemples, l'aided'algorithmes volutionnaires.Nous tudions tout d'abord un biais de langage o�rant une expressivit su�samment riche pour permettre decouvrir la fois le cadre de l'apprentissage relationnel par interprtations et les formalismes propositionnelsclassiques. Bien que le cot de l'induction soit caractris par la complexit NP-di�cile du test de subsomptionpour cette classe de langages, une solution capable de traiter en pratique les problmes rels complexes estpropose.Le systme SIAO1, qui utilise ce biais de langage pour l'apprentissage de rgles relationnelles est ensuiteprsent. Il est fond sur une stratgie de recherche volutionnaire qui se distingue principalement des approchesclassiques par :{ des oprateurs de mutation et de croisement dirigs par la thorie du domaine et par les exemplesd'apprentissage ;{ le respect de la relation d'ordre d�nie sur le langage.L'valuation du systme sur plusieurs bases faisant rfrence en apprentissage automatique montre queSIAO1 est polyvalent, se compare favorablement aux autres approches et sollicite peu l'utilisateur en cequi concerne la spci�cation de biais de recherche ou d'valuation.La troisime partie de ce travail propose deux architectures parallles gnriques derives des modles matre-esclave asynchrone et du pipeline. Elles sont tudies dans le cadre de l'extraction de connaissances partirde donnes l'aide de SIAO1 du point de vue de l'acclration qu'elles procurent d'une part et de leur capacitchanger d'chelle d'autre part. Un modle de prdiction simple mais prcis des performances de chacune desarchitectures parallles est galement propos.


Apprentissage Supervis�e Relationnel parAlgorithmes d'�EvolutionS�ebastien Augier12 d�ecembre 2000


iLe Ma�tre dit : Zigong, crois-tu que je sois quelqu'un qui�etudie une masse de choses et qui les retient par c�ur ?L'autre r�epondit : En e�et. N'en est-il pas ainsi ?Nullement. J'ai un seul �l pour en�ler le tout.(Entretiens de Confucius, XV. 3) �A ma famille.RemerciementsJe remercie Yves Kodrato� qui a supervis�e ce travail. Sa perception �a la fois largeet actualis�ee du domaine, sa disponibilit�e, son dynamisme et son humour ont �et�e d'ungrand soutien. Merci �a Gilles Venturini, qui a su susciter en DEA mon interet pour lesalgorithmes g�en�etiques et dont une partie des travaux ont servi de point de d�epart �a cetteth�ese. Ses remarques et ses encouragements ont �et�e pr�ecieux. Merci �egalement �a MarcSchoenauer pour ses commentaires avis�es, tant au niveau m�ethodologique que th�eorique,qui m'ont permis de prendre du recul par rapport �a ce travail. Je remercie �egalement Di-dier Fayard d'avoir accept�e de pr�esider le jury de cette th�ese. Je me souviens avec plaisirde son interet pour les nombreuses applications des algorithmes g�en�etiques ainsi que desdiscussions informelles et enrichissantes partag�ees. Merci �a Jacques Nicolas qui a bienvoulu faire partie de ce jury et dont l'expertise en apprentissage et en programmationlogique apporte un point de vision compl�ementaire sur ce travail.Que soient particuli�erement remerci�es C�eline Rouveirol, Mich�ele Sebag et AntoineCornu�ejols, pour leur grande disponibilit�e et leurs remarques au cours de la r�edaction decette th�ese.Pens�ees amicales aux coll�egues du LRI, de l'�equipe I&A et d'EPCAD, en par-ticulier Jacques Al�es-Bianchetti, Erick Alphonse, Alain Brunie-Taton, Lola Canamero,David Faure, Nicolas Graner, Guillaume Leblanc, J�erome Maloberti, Herv�e Mignot, Car-oline Ravis�e et Fabien Torre, pour les nombreux bons moments partag�es et les discussionsanim�ees.Que soient �nalement remerci�es Tobias Sche�er qui a eu la gentillesse de fournir lecode de son algorithme et les �equipes techniques du LRI et du CRI.

ii

Chapitre 1Apprentissage AutomatiqueSymbolique Supervis�eCe chapitre introduit les principaux concepts et algorithmes relatifs �a l'apprentissageautomatique supervis�e. �A cause de la multitude des approches et des travaux r�ealis�es, il nevise pas �a l'exhaustivit�e mais s'attache tout d'abord �a situer le domaine �a la fois dans uneperspective historique qui le lie �a l'intelligence arti�cielle ainsi que dans le contexte actuelqui est caract�eris�e par un d�eveloppement tr�es important des applications industrielles(syst�emes d'aide �a la d�ecision, data mining, etc.). Le corps du chapitre alterne d'unepart la pr�esentation des principales probl�ematiques et r�esultats th�eoriques (Qu'est-ce quel'induction ? Comment formuler le probl�eme dans le cadre de l'informatique ? Quellessont les propri�et�es des objets manipul�es ?), et d'autre part les principaux algorithmesd'apprentissage ainsi que leurs caract�eristiques. Une derni�ere partie est plus sp�eci�quementconsacr�ee �a la programmation logique inductive car ce domaine fournit un cadre plus pr�eciset de nombreux r�esultats tant th�eoriques que pratiques, permettant de mieux situer notretravail.1.1 HistoriqueL'apprentissage automatique (AA) est initialement apparu comme une composantede l'intelligence arti�cielle compl�etant et enrichissant les approches bas�ees sur le mod�eleintelligence = connaissances + raisonnement. Par exemple, dans le cadre des syst�emesexperts, le goulot d'�etranglement provoqu�e par la synth�ese puis le codage des masses deconnaissances n�ecessaires �a une expertise �able et d�etaill�ee d'un domaine est �a l'originedans un premier temps du d�eveloppement d'outils d'aide �a l'acquisition des connaissances,ces derniers ayant �nalement �et�e compl�et�es par des syst�emes capables de g�en�erer directe-ment des r�egles de d�ecision �a partir de donn�ees brutes. Le tableau 1.1 met en �evidence legain apport�e par l'utilisation d'outils d'apprentissage pour la conception et pour la main-tenance des syst�emes experts. Les couts en ann�ees-hommes de ces deux postes pour lessyst�emes GASOIL et BMT, qui utilisent des techniques d'apprentissage automatique sonten e�et inf�erieurs de plus d'un ordre de grandeur �a ceux des syst�emes-t�emoins MYCIN etXCON. Le d�eveloppement de l'apprentissage, dont les applications pratiques concernent1

2 CHAPITRE 1. APPRENTISSAGE AUTOMATIQUE SYMBOLIQUE SUPERVIS�ENom Domaine d'application R�egles Cout Cout Outils d'AAd�eva. maina.MYCIN Diagnostic m�edical 400 100 ND NDXCON Con�guration de syst�emes VAX 8.000 180 30 NDGASOIL Con�guration de syst�emes de 2.800 1 0,1 ExpertEase,s�eparation d'hydrocarbures Extran7BMT Con�guration de syst�emes 30.000 9 2 1st Class,pare-feux RuleMasteraLes couts de d�eveloppement et de maintenance sont exprim�es en ann�ees-hommes.Tab. 1.1: Cout de d�eveloppement et de maintenance de di��erents syst�emes experts, suiv-ant qu'ils mettent en �uvre ou non des techniques d'apprentissage automatique (source :[Muggleton92]).un nombre croissant de domaines, est donc all�e de pair avec l'�evolution de la repr�esentationde la notion d'intelligence, qui ne se limite plus �a l'accumulation et au traitement d'unsavoir encyclop�edique immuable. Peu de chercheurs doutent en e�et aujourd'hui qu'unsyst�eme puisse etre quali��e d'intelligent s'il n'est pas capable d'apprendre a�n de se per-fectionner et de s'adapter.Une seconde motivation pour d�evelopper des algorithmes d'apprentissage, relative auxnombreuses applications directes de ce domaine en entreprise, s'est d�egag�ee puis a pr�e-domin�e depuis les ann�ees 90 [Kodrato�00]. L'apprentissage automatique s'est entre autresimpos�e comme l'une des techniques-cl�e du processus d'extraction des connaissances �apartir des donn�ees (ECD, cf. �gure 1.1), dont le d�eveloppement peut s'expliquer parl'e�et cumulatif d'un certain nombre de facteurs :{ Depuis les ann�ees 80, de nombreuses entreprises ont cr�ee puis archiv�e des basesde donn�ees contenant de nombreuses informations relatives �a leurs clients, leursproduits et leurs concurrents. De nombreuses institutions ont connu un mouvementsemblable.{ Plus r�ecemment, le d�eveloppement des r�eseaux reliant les entreprises a accentu�e lerole central des bases de donn�ees tout en d�ecuplant les possibilit�es d'analyse (aug-mentation de la �abilit�e des donn�ees �a l'aide du recoupement et de l'enrichissementdes bases d'une part, �echanges de donn�ees structur�ees grace, par exemple, au langageXML d'autre part).{ Dans ce contexte, certaines entreprises ou institutions ont construit une structured�edi�ee, appel�ee entrepot de donn�ees (data warehouse). Ces structures sont des basesde donn�ees ayant pour fonction d'int�egrer les informations orient�ees-sujet (utiles �ala prise de d�ecision), provenant de tous les secteurs de l'entreprise, de mani�ere nonvolatile : les mises-�a-jour ne d�etruisent pas les anciennes donn�ees a�n de conserverun historique.

1.2. Poser le probl�eme 3Visualisation
Systèmes de gestion Statistiques
Apprentissage
de bases de données
ECD
Fig. 1.1: Pluridisciplinarit�e de l'ECD.et spécification des besoinsIdentification du problème
Sélection des données à utiliser
Préparation et explorationExtraction desconnaissances
Validation des modèles
Déploiement de l’application
Fig. 1.2: Le processus d'ECD.L'ECD [Kodrato�95] (appel�e KDD en anglais pour knowledge discovery in databases[Frawley et al.91]) a la particularit�e de s'etre construit de mani�ere pragmatique en tantque processus s'int�egrant au m�etier de l'entreprise et couvrant toutes les �etapes allant del'identi�cation du probl�eme jusqu'�a l'exploitation de la solution (�gure 1.2). L'�etape d'ex-traction des connaissances, qui met en jeu des techniques d'apprentissage automatique,est plus connue dans le monde industriel sous le nom de data mining.1.2 Poser le probl�eme1.2.1 Probl�ematique g�en�eraleL'apprentissage au sens large d�enote la capacit�e d'un agent �a am�eliorer ses perfor-mances par l'exp�erience. Plus pr�ecis�ement, cette th�ese se situe dans le cadre de l'appren-tissageAutomatique : l'agent est une machine ex�ecutant un programme. En cons�equence,l'apprentissage peut etre mod�elis�e par un algorithme.Supervis�e : l'exp�erience est constitu�ee de descriptions de situations (instances) class�eespar un professeur. L'ensemble de ces instances class�ees forme la base d'apprentissage,et l'agent est �evalu�e sur sa capacit�e �a classer correctement de nouvelles instancesformant la base de test.Par opposition, on parle d'apprentissage non supervis�e lorsque l'agent doit regrouperles instances en des classes qu'il aura lui-meme �elabor�ees. Une telle tache est typique-ment r�ealis�ee �a l'aide d'une mesure de distance entre les instances, appel�ee mesurede similarit�e. L'un des objectifs de l'agent est alors de trouver une partition min-imisant la distance entre les instances d'une meme classe et maximisant la distanceentre les instances de classes di��erentes.Ainsi, dans le domaine du marketing, l'op�eration consistant �a caract�eriser les ciblesles plus r�eceptives �a une campagne de publipostage �a l'aide de donn�ees d�ecrivant lecomportement de prospects soumis �a une pr�e-�etude rel�eve de la probl�ematique del'apprentissage supervis�e, alors que l'utilisation d'un outil de classi�cation a�n desegmenter cette meme population de prospects rel�eve de l'apprentissage non super-vis�e.

4 CHAPITRE 1. APPRENTISSAGE AUTOMATIQUE SYMBOLIQUE SUPERVIS�ESymbolique : l'agent doit produire des connaissances intelligibles pour l'utilisateur, parexemple sous forme de r�egles. Contrairement aux r�eseaux neuromim�etiques ou auraisonnement �a partir de cas, qui repr�esentent la connaissance respectivement parun ensemble de poids associ�es �a une architecture d'une part, et par une base de cascontenant de nombreux exemples d'autre part, l'adjectif symbolique fait r�ef�erence�a des connaissances concises ayant du sens pour un expert du domaine d'application,que ces connaissances mettent en jeu des objets purement symboliques ou �egalementdes donn�ees num�eriques.1.2.2 Structure du processus de r�esolutionL'apprentissage automatique symbolique supervis�e sera not�e AS par la suite, l'abr�eviationAA faisant r�ef�erence au contexte g�en�eral de l'apprentissage automatique. La �gure 1.3paramètres de contrôlethéorie du domaine
Algorithme d’A.S.description intelligible validation
Test de
des classes
base de test
base d’apprentissage
Utilisateur
performance en prédiction
Fig. 1.3: Utilisation d'un algorithme d'AS.sch�ematise le contexte d'utilisation d'un algorithme d'AS. Les donn�ees fournies en entr�eesont :La base d'apprentissage, not�ee B, qui contient la description des exemples (les instancesclass�ees) dans un langage Le. Lorsque Le est un langage d'ordre 0, les variables ouattributs d�ecrivant les instances sont dits endog�enes, et ceux caract�erisant la classe(ou concept-cible) sont dits exog�enes.La th�eorie du domaine, fournie par l'utilisateur, qui compl�ete la description des exemplespar des connaissances sp�eci�ques au domaine d'application. Par exemple, certainsalgorithmes permettent la sp�eci�cation de hi�erarchies de concepts correspondantaux valeurs d'attributs symboliques ; ainsi dans le domaine �nancier, l'attribut sym-bolique secteur d activit�e pourrait etre enrichi par une hi�erarchie du type :

1.2. Poser le probl�eme 5Energie
Matières_premières
. . .
Industrie_Métallurgique
Industrie_Chimique
Industrie_Pétrolière. . .
Secteur_quelconqueIndustrie_Agro_alimentaireFig. 1.4: Un exemple de hi�erarchie sur des constantes.Les param�etres de controle, �egalement fournis par l'utilisateur, permettent �a ce dernier,lorsqu'il en modi�e la valeur par d�efaut, d'adapter l'algorithme �a ses besoins ou defournir des connaissances sur la nature du concept qui seront exploit�ees lors de larecherche de la description optimale des classes. Sp�eci�er une dur�ee d'apprentissagemaximale, favoriser l'obtention de r�egles courtes et g�en�erales ou au contraire pluslongues mais plus pr�ecises, donner une estimation du bruit des donn�ees, �xer uneperformance en terme de capacit�e pr�edictive �a atteindre, ou encore interdire la pro-duction de r�egles faisant intervenir plus de 10 attributs sont autant d'exemples deparam�etres de controle.En sortie, l'algorithme d'AS retourne une description intelligible des classes. Cette de-scription, appel�ee �egalement hypoth�ese, est exprim�ee dans un langage Lh (habituellementLe � Lh), et est la plupart du temps accompagn�ee par une mesure de sa pr�ecision surl'ensemble d'apprentissage.Un test de validation de l'hypoth�ese est alors r�ealis�e �a l'aide d'une base de test com-portant des instances distinctes de celles qui apparaissent dans la base d'apprentissagea�n d'obtenir une estimation de la capacit�e pr�edictive des connaissances apprises. Lesm�ethodes de validation les plus courantes sont [Kohavi95] :La validation simple (holdout), faite en partitionnant l'ensemble des n instances en unensemble d'apprentissage et un ensemble de test. Il est conseill�e d'utiliser environ2:n3 instances pour l'apprentissage et les n3 instances restantes pour le test.La validation it�er�ee (random subsampling) proc�ede �a un nombre k > 1 arbitraire de vali-dations simples et rend comme estimation la moyenne des taux d'erreur observ�es. Lavariance des taux d'erreur peut etre utilis�ee pour estimer la stabilit�e de l'algorithmed'apprentissage.La validation par extraction (leave-k-out) consiste �a choisir la taille k > 0 de l'ensemblede test, puis �a g�en�erer la totalit�e des Ckn ensembles de test possibles ainsi que lesensembles d'apprentissage associ�es. En pratique seule la m�ethode leave-one-out quin�ecessite n apprentissages est utilis�ee : l'explosion combinatoire rend la validationpar extraction inutilisable sur des ensembles d'apprentissage de taille normale d�esk = 2.La validation crois�ee (cross-validation) reprend le principe de la validation par extraction,tout en diminuant drastiquement sa complexit�e. L'ensemble des instances est divis�een k > 1 partitions de tailles �equivalentes, puis k apprentissages sont r�ealis�es sur lesk unions di��erentes possibles de (k� 1) des partitions, la partition restante servantd'ensemble de test. La valeur k = 10 est tr�es couramment utilis�ee.

6 CHAPITRE 1. APPRENTISSAGE AUTOMATIQUE SYMBOLIQUE SUPERVIS�ELa validation crois�ee strati��ee (strati�ed cross-validation) est une variation de la vali-dation crois�ee qui s'attache �a conserver dans chaque partition une r�epartition desclasses �equivalente �a celle qui est observ�ee sur l'ensemble des instances.En supposant �x�es une fois pour toutes le test de validation ainsi que les bases d'appren-tissage et de test, le role de l'utilisateur consiste �a :{ �Evaluer la description fournie par l'algorithme d'AS du point de vue de sa valeurintrins�eque en tant que connaissance d'une part, et de son pouvoir pr�edictif vial'estimation de sa pr�ecision par le test de validation d'autre part.{ Ajuster, lorsque cela est n�ecessaire, la th�eorie du domaine et �eventuellement lesparam�etres de controle. Bien que cet aspect soit le plus souvent pass�e sous silence,le fait que les algorithmes d'AS fassent en pratique partie d'un processus d'inter-action avec l'utilisateur implique la n�ecessit�e de pouvoir adapter l'algorithme auxprobl�ematiques rencontr�ees : des caract�eristiques telles que la tol�erance �a l'erreur oula notion d'intelligibilit�e ne peuvent etre d�etermin�ees dans l'absolu.1.2.3 Apprentissage supervis�e et optimisationReformulation du probl�emeLa description de l'AS faite ci-dessus peut s'�enoncer comme un probl�eme d'optimisation.D�e�nition 1.1 Probl�eme d'AS (sous forme de probl�eme d'optimisation)�Etant donn�es :{ Un ensemble B = B+ [ B�, appel�e base d'apprentissage, comportant des exemples(B+) et contre-exemples (B�) du concept-cible C repr�esent�es dans le langage Le ;{ Un espace de recherche correspondant �a l'ensemble des formules d�e�nies sur Lh ;{ Une fonction d'�evaluation fB : Lh �! <, qui, �a toute hypoth�ese h de l'espace derecherche, associe un r�eel fB(h) repr�esentant le score de cette hypoth�ese sur la based'apprentissage B.Trouver l'hypoth�ese H telle que fB(H) soit maximale.Bien que l'analyse de la probl�ematique de l'AS permette la mise en �evidence d'un grandnombre de caract�eristiques sp�eci�ques �a ce domaine, la reformulation sous forme d'unprobl�eme d'optimisation est b�en�e�que pour au moins deux raisons :1. Sur le plan pratique, certaines techniques d�evelopp�ees dans ce domaine, qui b�en�e�ciede nombreuses ann�ees de recherche, peuvent etre adapt�ees �a l'AS.2. Sur le plan th�eorique, des avanc�ees r�ecentes concernant les algorithmes de rechercheet d'optimisation ont des r�epercussions tr�es importantes quant �a la perception memede la tache �a accomplir et des r�esultats que l'on peut esp�erer atteindre.

1.2. Poser le probl�eme 7Le th�eor�eme de conservationUn exemple r�ecent de r�esultat th�eorique fondamental est fourni par les th�eor�emes deconservation (no free lunch theorems) relatifs aux m�ethodes de recherche et d'optimisation[Wolpert et al.96b, Wolpert et al.96a] dont le r�esultat central est r�esum�e ci-dessous :Th�eor�eme 1.1 Th�eor�eme de conservationSoit un probl�eme d'optimisation d�e�ni �a l'aide d'une fonction f : X ! Y dont on cherche�a d�eterminer x� 2 X tel que y� = f(x�) 2 Y ait une propri�et�e donn�ee (typiquement quecette valeur soit maximale ou minimale). Supposons de plus :1. Que X et Y sont �nis (c'est toujours le cas pour les probl�emes trait�es par des ma-chines digitales), de cardinalit�es respectives jX j et jYj. F = YX , de cardinal jYjjX j,qui repr�esente l'ensemble des fonctions f possibles, est alors �egalement �ni.2. Que l'algorithme d'optimisation examine, �a chaque �etape, une (ou plusieurs) nou-velle(s) solution(s) dans l'espace X uniquement en fonction des solutions pr�ec�edemmentrencontr�ees et de leurs couts. On note alors dm = f(dxm(1); dym(1)); :::; (dxm(m);dym(m))g l'ensemble ordonn�e des m solutions distinctes examin�ees et dxm (resp. dym)la restriction de dm aux instances (resp. aux couts)1.3. Que la mesure de la performance d'un algorithme a apr�es un nombre m quelconqued'it�erations (au sens de dm) est une fonction de dym, not�ee �(dym). Par exemple,dans le cas o�u l'on cherche x� 2 X tel que f(x�) soit maximal, on choisira �(dym) =max(fdym(i)=i 2 [1::m]g).Alors, en notant P (dymjf;m; a) la probabilit�e conditionnelle d'obtenir l'ensemble ordonn�edym pour le probl�eme d'optimisation f soumis �a l'algorithme a durant m it�erations (�evaluationsdistinctes), on a, quels que soient les algorithmes d'optimisation a1 et a2 :Xf2F P (dymjf;m; a1) = Xf2F P (dymjf;m; a2)et donc, pour toute mesure de performance �(dym), la valeur moyenne de P (�(dym)jf;m; a)pour toutes les fonctions f 2 F est ind�ependante de a.Ce r�esultat a �et�e �etendu aux cas plus g�en�eraux des fonctions qui varient dans le temps etdes algorithmes d'optimisation stochastiques. Il concerne donc l'ensemble des algorithmesd'optimisation fonctionnant en bo�te noire , c'est-�a-dire pour lesquels seule la phased'exploration apporte de l'information (les f 2 F sont �equiprobables : 8f 2 F ; P (f) =1Cette hypoth�ese am�ene deux remarques :(a) Le th�eor�eme s'applique �egalement aux algorithmes pouvant �evaluer plusieurs fois une instance x 2 Xdonn�ee (comme par exemple les algorithmes de mont�ee (hill-climbing), les algorithmes g�en�etiques,le recuit simul�e, etc.) ; cependant il ne comptabilise que les solutions distinctes, dans l'ordre danslequel elles sont examin�ees.(b) La liste dm comptabilise le nombre d'�evaluations d'instances : par exemple, dans le cas d'un al-gorithme de mont�ee (hill-climbing), elle comprend non seulement les points de la suite ascendanteparcourue, mais �egalement tous leurs voisins qui ont aussi du etre �evalu�es.

8 CHAPITRE 1. APPRENTISSAGE AUTOMATIQUE SYMBOLIQUE SUPERVIS�E1jYjjXj ) ; en particulier aucune information relative �a la structure de l'espace de recherche oude la solution n'est disponible. La conservation de la performance moyenne implique quece qu'un algorithme a1 gagne en performance � sur une classe de probl�emes par rapport�a un algorithme a2 est obligatoirement perdu sur une autre classe de probl�emes.En particulier, les algorithmes g�en�etiques, le recuit simul�e, les algorithmes de mont�ee (hill-climbing), de descente (hill-descending) et la recherche al�eatoire ont, sur l'ensemble de tousles probl�emes, une performance moyenne identique. Sur le plan pratique, le fait qu'aucunalgorithme d'optimisation ne soit meilleur qu'un autre dans l'absolu a pour cons�equence :{ qu'il est n�ecessaire d'identi�er les classes de probl�emes sur lesquelles un algorithmedonn�e obtient de meilleures performances ;{ que toute connaissance relative �a la structure de l'espace de recherche devra etreexploit�ee autant que possible.1.3 Strat�egies de r�esolutionLes sections pr�ec�edentes ont �et�e l'occasion de pr�esenter le contexte du travail, deposer le probl�eme �a r�esoudre et de souligner le lien pouvant etre �etabli avec le domainetr�es vaste de l'optimisation. Cette section est consacr�ee aux algorithmes d'AS et a pourdouble objectif :{ de montrer la sp�eci�cit�e de la probl�ematique de l'apprentissage, et d'�enoncer unth�eor�eme de conservation relatif �a ce cadre ;{ de pr�esenter quelques algorithmes repr�esentatifs des principales approches du do-maine.1.3.1 Sp�eci�cit�e du probl�emeUne probl�ematique li�ee �a l'inductionLa principale sp�eci�cit�e d'un probl�eme d'AS par rapport �a un probl�eme de recherche oud'optimisation classique provient du principe mis en �uvre pour le r�esoudre : l'induction.D'un point de vue logique, l'induction est une r�egle de transformation permettant d'inf�erer�a partir d'une observation une loi plus g�en�erale :9x A(x)) B(x)8x A(x)) B(x) � inf�erenceinductive � 8x A(x)) B(x) ; A(c)B(c) � inf�erenced�eductive �Parce qu'elle ne conserve pas la correction (c'est-�a-dire qu'il est possible de g�en�eraliser uneobservation correcte en une th�eorie fausse), l'induction n'est pas autant �etudi�ee en logiqueque la d�eduction, qui consiste, �etant donn�ees une th�eorie et une observation, �a inf�erer lesfaits qui en d�ecoulent. Cependant, si la d�eduction est �a la base des syst�emes de preuve (par

1.3. Strat�egies de r�esolution 9exemple dans le m�ecanisme du cha�nage avant mis en �uvre dans les syst�emes experts),elle ne permet que l'exploitation des th�eories, et non leur cr�eation. La non-correction dela r�egle d'induction met en �evidence le risque li�e �a la g�en�eralisation d'observations lorsde la construction d'un mod�ele. Ce risque est inh�erent �a la d�emarche : apprendre, c'estg�en�erer un mod�ele expliquant non seulement les observations, mais pouvant etre �egalementappliqu�e �a des instances inconnues.En cons�equence, le saut inductif est une caract�eristique de l'apprentissage supervis�e etne peut etre �evit�e. En particulier :{ Lorsque B contient l'ensemble de toutes les instances possibles class�ees, on parle decompression des donn�ees et non d'apprentissage supervis�e. En pratique, ce cas n'estjamais rencontr�e �a cause de la combinatoire mise en jeu dans Le (par exemple, dans lecas attribut-valeur, la connaissance exhaustive d'un probl�eme d'apprentissage d�e�nisur a attributs de modalit�es m1; :::; ma n�ecessite Qai=1mi observations).{ Un algorithme se contentant de m�emoriser B et ne classant que les instances d�ej�aconnues est un syst�eme de requetes sur une base de donn�ees et non un algorithmed'apprentissage supervis�e. Ce cas ne doit pas etre confondu avec celui des algo-rithmes m�emorisant B et classant de nouvelles instances �a l'aide d'une mesure desimilarit�e puisque la mesure de similarit�e correspond �a une composante d'appren-tissage r�ealisant une op�eration de g�en�eralisation.Validation du saut inductifLa conservation de la correction lors du saut inductif est v�eri��ee lors de l'apprentissage�a l'aide de la fonction fB qui �evalue la couverture des hypoth�eses candidates sur les in-stances d'apprentissage2. La �gure 1.5 montre la vision ensembliste associ�ee �a l'�evaluationRègle : CH
B
CH
Fig. 1.5: Diagramme pour H ! C.C �CH nC^H n �C^H nH�H nC^ �H n �C^ �H n �HnC n �C nBFig. 1.6: Tableau de contingence (H; C).d'une hypoth�ese H caract�erisant des instances d'un concept C dans l'ensemble des ex-emples d'apprentissage B. Les e�ectifs peuvent etre repr�esent�es �a l'aide d'un tableau decontingence (�gure 1.6). En particulier, les deux notions suivantes sont centrales pourtoute validation d'une hypoth�ese obtenue par induction :2L'hypoth�ese H couvre l'instance I de la base d'apprentissage B si I 2 H

10 CHAPITRE 1. APPRENTISSAGE AUTOMATIQUE SYMBOLIQUE SUPERVIS�ED�e�nition 1.2 Coh�erence logiqueL'hypoth�ese H est coh�erente par rapport �a la base d'apprentissage B ssi H ne couvre aucuncontre-exemple de B. On dit �egalement que H est correcte par rapport �a B.D�e�nition 1.3 Compl�etude logiqueL'hypoth�ese H est compl�ete par rapport �a la base d'apprentissage B ssi H couvre tous lesexemples de B.Il est parfois pr�ef�erable de substituer aux d�e�nitions bool�eennes ci-dessus (qui proviennentd'un cadre purement logique) des d�e�nitions plus gradu�ees :D�e�nition 1.4 Taux de coh�erenceLe taux de coh�erence de l'hypoth�ese H par rapport �a la base d'apprentissage B est d�e�nipar rapport �a la couverture de H et vaut nC^HnH . Le taux de coh�erence absolu vaut : 1� n �C^Hn �C .D�e�nition 1.5 Taux de compl�etudeLe taux de compl�etude de l'hypoth�ese H par rapport �a la base d'apprentissage B est d�e�nipar : nC^HnC .Les taux de compl�etude et de coh�erence d'une hypoth�ese sont toujours dans l'intervalle[0; 1]. Ils peuvent etre utilis�es dans des heuristiques par les algorithmes d'AS.La validation du saut inductif par �evaluation de la couverture de H sur B n'est pas uned�emarche triviale. En e�et, elle repose sur l'hypoth�ese (implicite dans les syst�emes d'AS)que la base d'apprentissage B est repr�esentative du concept-cible recherch�e (la loi deconservation de la pr�ecision en g�en�eralisation, d�ecrite plus bas, sera l'occasion d'explicitercette notion). Plus pr�ecis�ement, l'hypoth�ese justi�ant un raisonnement inductif peut etreformul�ee de la mani�ere suivante :Toute hypoth�ese H dont la couverture dans l'ensemble B est su�samment voisine duconcept-cible C, approximera C assez pr�ecis�ement sur les instances inconnues.De ce point de vue, il est possible de consid�erer l'�evaluation du mod�ele fourni par l'algo-rithme d'AS sur la base de test comme une validation a posteriori de l'hypoth�ese d'induc-tion pour un couple (algorithme, base d'apprentissage) donn�e.1.3.2 Application du th�eor�eme de conservationLe th�eor�eme de conservation �enonc�e dans le cadre g�en�eral des algorithmes d'optimisa-tion ne peut s'appliquer tel quel au domaine de l'apprentissage supervis�e puisque la baseB fournit des informations sur le probl�eme �a optimiser. Comme le montre le paragrapheci-dessous, le p�erim�etre de la notion de conservation doit etre red�e�ni a�n de ne prendreen compte que les sous-ensembles de B : on parle alors de conservation en g�en�eralisation.Une loi de conservation dans le cadre de l'apprentissage supervis�e

1.3. Strat�egies de r�esolution 11Cullen Scha�er [Scha�er94] a propos�e un r�esultat tr�es similaire au th�eor�eme de conserva-tion dans le cadre de l'apprentissage. Ce r�esultat concerne l'apprentissage supervis�e �a par-tir d'exemples positifs et n�egatifs d�ecrits dans un langage attribut-valeur. Les hypoth�esessont tr�es similaires �a celles �enonc�ees dans le cadre plus g�en�eral des probl�emes d'optimi-sation (prise en compte de l'ensemble de tous les probl�emes possibles, �equiprobabilit�e etd�enombrabilit�e de ces derniers, d�eterminisme de l'algorithme par rapport �a ses entr�ees).Les mesures choisies sont d'une part la pr�ecision en g�en�eralisation, c'est-�a-dire le ratio dunombre d'instances de la base de test correctement class�ees par l'algorithme d'apprentis-sage sur le nombre total d'instances de la base de test, et d'autre part la performance eng�en�eralisation qui est d�e�nie comme la pr�ecision en g�en�eralisation moins 12 .Th�eor�eme 1.2 Loi de conservation de la pr�ecision en g�en�eralisationLa performance en g�en�eralisation moyenne d'un algorithme d'AS sur l'ensemble des probl�emesd'apprentissage est nulle, et sa pr�ecision en g�en�eralisation est �egale �a 12 .Ce r�esultat est illustr�e intuitivement de la mani�ere suivante : consid�erons un probl�emed'apprentissage d�e�ni par le couple (B; T ), avec (par d�e�nition) B \ T = ;. Supposonsalors B �x�ee : l'algorithme d'AS, dont les entr�ees sont constantes, fournit toujours lameme hypoth�ese H. Par cons�equent, pour une base d'apprentissage B donn�ee, la classi-�cation des instances de la base de test T est �x�ee. Soient t1; :::; tm les m instances deT , C(t1); :::; C(tm) leurs classes respectives et H(t1); :::;H(tm) les classes pr�edites par H.Parmi les 2m �etiquetages possibles des m instances de test, la moiti�e exactement est telleque C(ti) = H(ti), et l'autre moiti�e telle que C(ti) 6= H(ti). De plus, comme par hypoth�esetous les �etiquetages des instances de T sont �equiprobables, la pr�ecision en g�en�eralisationmoyenne de H est �egale �a 12 (d'o�u l'on d�eduit �egalement que la performance moyenne eng�en�eralisation est nulle).De la repr�esentativit�e des donn�eesLa loi de conservation de la pr�ecision en g�en�eralisation doit-elle faire perdre tout espoirde pouvoir apprendre des concepts �a partir d'exemples ? Bien entendu, la r�eponse, commedans le cas des probl�emes d'optimisation o�u de nombreux succ�es ont �et�e obtenus sur desprobl�emes r�eels en d�epit du th�eor�eme de conservation, est n�egative. En e�et, certaineshypoth�eses sont �eloign�ees des probl�emes r�eels puisqu'elles postulent :{ l'�equiprobabilit�e des univers possibles ;{ l'absence de connaissances sp�eci�ques au probl�eme �a r�esoudre.A�n d'illustrer cette di��erence, consid�erons par exemple le probl�eme d'apprentissage bi-naire suivant d�e�ni sur m attributs �egalement binaires A1; :::; Am (on suppose m > 0

12 CHAPITRE 1. APPRENTISSAGE AUTOMATIQUE SYMBOLIQUE SUPERVIS�Eassez grand ) : A1 A2 ::: Am�1 Am C0 0 ::: 0 0 0... ... ...B 0 1 ::: 1 1 01 0 ::: 0 0 1... ... ...1 1 ::: 1 0 1T 1 1 ::: 1 1 CT ?Du point de vue th�eorique, le th�eor�eme de conservation dit qu'en l'absence de connais-sances sur le probl�eme et l'univers, il n'est pas possible de d�ecider la valeur de CT puisqueles �ev�enements (CT = 0) et (CT = 1) sont �equiprobables. La probabilit�e d'erreur, quel quesoit le choix fait pour CT , est donc de 12 .D'un point de vue empirique, les tables de contingence relatives aux di��erents attributssont les suivantes :Table pour A1 : Table pour Ai, i 6= 1 :C �CA1 2m�1 � 1 0 2m�1 � 1�A1 0 2m�1 2m�12m�1 � 1 2m�1 2m � 1 C �CAi 2m�2 � 1 2m�2 2m�1 � 1�Ai 2m�2 2m�2 2m�12m�1 � 1 2m�1 2m � 1Il ressort donc qu'une d�ependance entre C et A1 est a priori tr�es hautement probable, etque toutes les d�ependances entre C et Ai; (i 6= 1) sont a priori tr�es hautement improbables.Par cons�equent, on choisit (avec d'autant plus de certitude que m est grand) le mod�eleC = A1, d'o�u l'on d�eduit que CT = 1.Cet exemple illustre le fait que le th�eor�eme de conservation de la g�en�eralisation pr�edictive,qui pose que tous les univers sont possibles et �equiprobables va �a l'encontre de l'hypoth�esede base de l'induction qui pose que tout mod�ele satisfaisant sur B sera satisfaisant sur T, ou encore que :B est repr�esentative de l'univers par rapport �a l'ensemble des mod�eles consid�er�es .Pour d�ecider de la valeur de CT , l'approche empirique simple pr�esent�ee ci-dessus proc�edepar un certain nombre d'�etapes dont on va d�ecider qu'elles sont raisonnables dans le cadrede la classe des probl�emes r�eels :{ la premi�ere �etape consiste �a poser implicitement l'hypoth�ese qu'�a performance iden-tique sur B, les mod�eles les plus simples doivent etre pr�ef�er�es ;

1.3. Strat�egies de r�esolution 13{ la seconde �etape concerne l'�etablissement d'un ordre d'�evaluation des di��erentsmod�eles, d'o�u l'observation, dans un premier temps, des tables de contingence quicorrespondent aux d�ependances C = Ai et C = :Ai ;{ La troisi�eme �etape consiste �a choisir un crit�ere d'�evaluation de la qualit�e des mod�eles(par exemple le test du �2 entre les tables des Ai et les tables correspondant auxmod�eles C = Ai et C = :Ai) ;{ la derni�ere �etape consiste �a inf�erer �a l'aide du mod�ele obtenu la valeur de CT .Chacune de ces �etapes, qui pr�ecise un peu plus la classe des mod�eles contenant la d�e�nitionrecherch�ee du concept-cible, contredit l'hypoth�ese d'�equiprobabilit�e des univers possiblespos�ee par le th�eor�eme de conservation. En e�et, elles introduisent implicitement des con-naissances permettant de guider le choix d'un mod�ele, en pr�ef�erant telle solution �a telleautre. Ces pr�ef�erences, appel�ees biais, sont �etudi�ees plus en d�etail �a la section 1.4.1.3.3 Structure de l'espace de rechercheLa notion de couverture des �el�ements de Le permet de d�e�nir une relation de g�en�eralit�eentre les hypoth�eses :D�e�nition 1.6 Relation de g�en�eralit�eSoient h1 et h2 deux hypoth�eses. Soit H1 (resp. H2) l'ensemble des �el�ements de Le couvertspar h1 (resp. h2). L'hypoth�ese h1 est plus g�en�erale que l'hypoth�ese h2 (not�e h1 �g h2) siet seulement si tout �el�ement de H2 est �egalement �el�ement de H1.La relation de g�en�eralit�e est une relation d'ordre large (elle est r�e exive, antisym�etrique ettransitive). De plus, puisqu'il est possible d'avoir H1nH2 6= ; et H2nH1 6= ; (ie h1 6�g h2et h2 6�g h1), la relation d'ordre est partielle. On note h1 >g h2 ( h1 est strictement plusg�en�erale que h2 ) le fait que h1 �g h2 avec h2 6�g h1. De meme, il est possible de d�e�nirles notions duales plus sp�eci�que que et strictement plus sp�eci�que que .Le role central de la relation de g�en�eralit�e vient du fait qu'elle structure l'espace derecherche Lh ind�ependamment des exemples d'apprentissage. Habituellement, �g poss�edeun unique plus grand �el�ement (l'hypoth�ese qui couvre tous les exemples) et plusieurs pluspetits �el�ements (appartenant �a Le) : l'espace a donc une structure de sup-demi treillis (lad�e�nition math�ematique peut etre trouv�ee en annexe A). �A titre d'exemple, la �gure 1.7d�ecrit le sup-demi treillis relatif aux langages Le (d�e�ni �a l'aide de deux attributs A etB �a valeur dans fa1; a2g et fb1; b2g, respectivement) et Lh (qui introduit le symbole �couvrant toutes les valeurs de l'attribut auquel il s'applique). Lorsqu'un plus petit �el�ementest choisi comme base de la structure (par exemple (a1; b1)), la restriction obtenue est untreillis (repr�esent�e en gras).Cette structure peut etre mise �a pro�t pour guider les algorithmes de recherche etleur permettre d'�elaguer des r�egions non pertinentes de Lh. Il est cependant n�ecessaire deprendre garde, lors de l'implantation de tout algorithme, �a la complexit�e du test �g (qui

14 CHAPITRE 1. APPRENTISSAGE AUTOMATIQUE SYMBOLIQUE SUPERVIS�E(a1,*) (*,b1)
(a1,b1) (a2,b2)(a1,b2) (a2,b1)
(*,b2) (a2,*)
(*,*)
Fig. 1.7: Structure de Lh dans le cas d'un langage attribut-valeur simple.d�epend de l'expressivit�e de Lh). Ce sujet, auquel le chapitre 3 est consacr�e, ne sera pasplus d�etaill�e ici ; bornons-nous pour l'instant �a remarquer les faits suivants :{ du point de vue de son implantation sur une machine, la relation de g�en�eralit�e peutse ramener �a la notion de preuve puisque h1 est plus g�en�eral que h2 si et seulementsi h2 est une cons�equence logique (via le syst�eme de preuve implant�e en machine)de h1 : h2 �g h1 , h2 ` h1 ;{ il a �et�e d�emontr�e que le test ` n'est pas d�ecidable lorsque Lh est le langage de lalogique du premier ordre. Il n'existe donc pas d'algorithme permettant de d�ecideren un temps �ni si, pour deux hypoth�eses quelconques h1 et h2 de la logique dupremier ordre, h2 �g h1.Les deux sous-sections ci-apr�es sont consacr�ees respectivement aux techniques dites as-cendantes et descendantes , selon la direction choisie pour explorer Lh. L'usage consistant�a placer les exemples en bas du graphe de g�en�eralisation, les m�ethodes ascendantes corre-spondent �a des strat�egies de recherche d�eveloppant une ou plusieurs hypoth�eses (initiale-ment sur-sp�eci�ques) par g�en�eralisations successives, alors que les m�ethodes descendantessp�ecialisent des hypoth�eses initialement sur-g�en�erales. Chaque direction de recherche estillustr�ee par une m�ethode faisant r�ef�erence : l'apprentissage bas�e sur la m�ethodologie del'�etoile dans le cas de l'apprentissage par g�en�eralisation et l'approche diviser pour r�egnerdans le cas de l'apprentissage par sp�ecialisation.1.3.4 Apprendre c'est oublierLa m�ethodologie de l'�etoileUne premi�ere technique de parcours de l'espace de recherche consiste �a oublier les d�etailsnon discriminants des exemples a�n d'obtenir des r�egles de classi�cation g�en�erales. Pluspr�ecis�ement, les m�ethodes ascendantes g�en�eralisent des mod�eles sur-sp�eci�ques de mani�ere�a augmenter leur taux de couverture tout en relaxant aussi peu que possible la contraintede coh�erence. La m�ethodologie de l'�etoile, d�etaill�ee dans [Michalski84], et dont l'algorithmeg�en�erique �gure ci-dessous, est un exemple de m�ethode ascendante.

1.3. Strat�egies de r�esolution 15/* Algorithme g�en�erique de l'�etoile. */H = ;Tant que (B+ 6= ;) faire- S�electionner al�eatoirement un exemple positif Ex (le noyau)dans B.- Construire l'�etoile G(ExjB�; m), et choisir la description Dqui maximise le crit�ere de pr�ef�erence.- H H [D.- B B n fEx 2 B+=D �g Exg.- B+ B+ n fEx 2 B+=D �g Exg.Cette m�ethode r�ealise une couverture it�erative des exemples positifs de l'ensemble d'ap-prentissage en ajoutant s�equentiellement, tant que cela est n�ecessaire, une r�egle provenantde la g�en�eralisation d'un exemple positif non encore couvert (le noyau). B+ (resp. B�)d�enote l'ensemble des exemples (resp. contre-exemples) de B. G(EjE ; m) d�enote l'�etoile dunoyau E, de bornem, relativement �a l'ensemble d'instances E , c'est-�a-dire lesm meilleuresdescriptions (suivant un crit�ere de pr�ef�erence donn�e) g�en�eralisant l'exemple E qui ne cou-vrent aucun �el�ement de E .Croissance d'une �etoileLa m�ethode de l'�etoile �evoque un parcours ascendant du graphe de g�en�eralisation, puisquechaque noyau est g�en�eralis�e en un ensemble de m hypoth�eses. Un exemple en est donn�epar le syst�eme SIA (d�ecrit chapitre 2 section 2.2.3), dont le processus de g�en�eralisationest bas�e sur un algorithme �evolutionnaire. La g�en�eralisation du noyau peut �egalement etreobtenue �a l'aide d'une m�ethode localement descendante, comme dans le cas de la familledes syst�emes AQ [Kaufman et al.99].Ces syst�emes g�en�erent en e�et chaque �etoile en d�eveloppant les sp�ecialisations d'un mod�eleinitialement vide par ajout des caract�eristiques du noyau : il s'agit donc d'une sp�ecialisationdirig�ee par les donn�ees (ici, un exemple positif). De plus, contrairement �a la plupart dessyst�emes existants qui implantent un crit�ere de pr�ef�erence pr�e-determin�e, AQ permet �al'utilisateur de le d�e�nir (a�n qu'il soit adapt�e au probl�eme) �a l'aide d'un langage codantune s�equence (d�enot�ee LEF ) de couples (crit�ere, tol�erance), comme par exemple :LEF = < (couverture; 10%); (coh�erence; 100%) >De la couverture it�erative en g�en�eralLa caract�eristique permettant de classer la m�ethodologie de l'�etoile parmi les m�ethodesascendantes est la g�en�eralisation d'un noyau en un ensemble d'hypoth�eses le couvrant.

16 CHAPITRE 1. APPRENTISSAGE AUTOMATIQUE SYMBOLIQUE SUPERVIS�ELe fait qu'il puisse etre n�ecessaire de r�ep�eter plusieurs fois le processus n'a, par contre,aucune implication quand �a la direction de la recherche. Un exemple en est donn�e parle syst�eme CN2 [Clark et al.89], qui ne di��ere d'AQ { du point de vue de la strat�egie derecherche { que par l'absence de noyau : l'algorithme g�en�ere l'une apr�es l'autre des r�eglesen ajoutant �a chaque �etape le test jug�e le plus discriminant, et en maintenant une listedes m meilleurs candidats. Ce m�ecanisme, tr�es voisin de celui mis en �uvre par C4.5 pourconstruire un arbre de d�ecision (cf. section 1.3.5), classe bien �evidemment CN2 parmi lesm�ethodes descendantes.

1.3. Strat�egies de r�esolution 171.3.5 Apprendre c'est discriminerDiviser pour r�egnerL'apprentissage par sp�ecialisation consiste �a choisir un mod�ele initial g�en�eral, puis �a lepr�eciser en discriminant de plus en plus �nement entre les di��erentes classes. La m�ethodediviser pour r�egner , qui est utilis�ee entre autres dans de nombreux algorithmes d'induc-tion d'arbres de d�ecision, est l'approche la plus r�epandue de ce type de technique ; elleconsiste �a construire incr�ementalement le mod�ele de d�ecision en partitionnant l'ensembled'apprentissage en composantes que l'on esp�ere plus homog�enes (�gure 1.8).
PartitionClient Dom. d’activité Client Dom. d’activité
Id1 Pr. libérale NonId2Id3
SalariéSans profession
OuiOui Id4 Salarié Non
PropriétairePropriétaire
OuiOui
Crédit? Crédit?
NonNon
classedescripteurs
EnsembleInitial
Test
Client Dom. d’activité
Id1Id2Id3Id4
Pr. libéraleSalariéSans professionSalarié
NonOuiOuiNon
Propriétaire
NonOuiOuiNon
Crédit?
Résultat
Propriétaire
Oui Non
Crédit? = Oui Crédit? = Non
Fig. 1.8: L'approche diviser pour r�egner.Ce principe se combine �el�egamment �a la structure r�ecursive des arbres de d�ecision pourformer l'algorithme g�en�erique de construction ci-dessous./* Algorithme r�ecursif de construction d'un arbre de d�ecision. */Initialement l'arbre est r�eduit �a sa racine R qui contient tous lesexemples, classes confondues.Tant qu'il reste une feuille F dans l'arbre dont les exemplesappartiennent �a plusieurs classes distinctesa :- Choisir un test T non encore utilis�e dans les n�uds-p�eres del'arbre.- Ajouter �a F autant de branches que T a de valeurs possibles.F devient un n�ud de l'arbre comportant le test T.- Propager les exemples dans les feuilles correspondantes issuesde T.aDans l'exemple d�etaill�e ci-apr�es, le crit�ere d'arret est plus pr�ecis�ement : Tant qu'il existe un testdont le gain d'information est strictement positif .

18 CHAPITRE 1. APPRENTISSAGE AUTOMATIQUE SYMBOLIQUE SUPERVIS�EUn arbre de d�ecision est une structure arborescente permettant de d�eterminer la valeurde la classe d'un exemple en fonction de tests portant sur la valeur des attributs qui lecomposent. Par exemple, la structure de la �gure 1.8, compos�ee d'un test portant sur lavaleur de l'attributPropri�etaire, de deux arcs correspondant aux valuationsOui etNonde cet attribut auxquels sont attach�ees des feuilles �etiquet�ees respectivement Cr�edit ? =Oui et Cr�edit ? = Non, correspond �a un arbre de d�ecision de profondeur 1 pour la classeCr�edit ?.La mesure du gain d'informationLe choix du test T �a utiliser a�n de partitionner �a chaque �etape de la cr�eation de l'arbrel'ensemble d'apprentissage est crucial. Dans le cas des syst�emes d'ordre 0, les �etapes desp�ecialisation correspondent �a l'ajout de contraintes portant sur les valeurs des attributs.Typiquement, les discriminations sur les attributs symboliques sont faites en d�eveloppantautant de sous-arbres qu'il existe de valeurs possibles, alors que les discriminations sur lesattributs num�eriques consistent �a choisir une valeur r�eelle utilis�ee comme seuil (le pointde coupure ) pour g�en�erer une partition binaire. Le crit�ere propos�e par Quinlan, qu'il meten �uvre dans le syst�eme ID3 [Quinlan86], puis ses successeurs C4.5 [Quinlan93] et C5.0est appel�e gain d'information et est d�e�ni par :Gain(E; T ) = Entropie(E)� jT jXi=1 jEijjEj :Entropie(Ei)o�u E (de cardinal jEj) correspond �a l'ensemble d'exemples du n�ud courant et T est letest utilis�e pour partitionner E en jT j sous-ensembles Ei. Cette heuristique, qui �evaluela capacit�e du test �a discriminer au mieux les exemples du point de vue de l'entropiedes partitions candidates, est compatible avec le principe du rasoir d'Occam puisqu'onpeut esp�erer favoriser la cr�eation d'arbres courts. L'entropie d'un ensemble E compos�ed'exemples de classes ci(i 2 [1::jCj]) est une mesure du d�esordre observ�e au sein de cetensemble : Entropie(E) = jCjXi=1�pi:log2(pi)o�u pi correspond �a la proportion des exemples de classe ci dans E. Dans le cas o�u pi = 0,on pose : 0:log2(0) = limx!0 x:log2(x) = 0. Par exemple, dans le cas bool�een (jCj = 2),l'entropie est minimale (nulle) lorsque l'ensemble consid�er�e est compos�e d'exemples d'unememe classe, et au contraire maximale (�egale �a l'unit�e) lorsque les classes sont �equi-r�eparties (p1 = p2 = 12).Post-traitement et extensionsL'obtention d'un ensemble de r�egles �a partir d'un arbre de d�ecision est particuli�erementais�ee puisqu'il su�t de parcourir l'arbre, chaque chemin menant de la racine �a une feuilleconstituant une r�egle dont la partie conditionnelle est compos�ee de la conjonction descouples (Test; R�esultat) des n�uds et arcs du chemin, la conclusion portant sur la classe

1.3. Strat�egies de r�esolution 19de la feuille [Quinlan87]. Bien qu'a priori n�egligeable, l'�etape de g�en�eration des r�egles �apartir de l'arbre de d�ecision est compos�ee en pratique d'un certain nombre d'op�erationsde simpli�cation suppl�ementaires (post-�elagage, regroupement, etc.) qui constituent enfait la partie la plus couteuse et complexe de l'algorithme d'induction C4.5. Le lecteurint�eress�e pourra consulter [Rakotomalala97, Zighed et al.00] qui pr�esentent et comparentde nombreuses approches en se pla�cant dans le cadre g�en�eral des graphes d'induction.1.3.6 De l'importance de la direction de la rechercheDoit-on pr�ef�erer les m�ethodes ascendantes ou descendantes ? Bien que le th�eor�eme deconservation porte �a croire qu'il n'y a pas de r�eponse dans l'absolu �a cette question, il esttentant d'analyser le choix guidant la recherche conduite par les m�ethodes pr�esent�ees a�nd'imaginer les cas favorables et d�efavorables. En ce qui concerne les m�ethodes bas�ees sur lacouverture it�erative des exemples (section 1.3.4), et celles qui op�erent par partitionnementdes donn�ees (section 1.3.5), il est possible de dresser le tableau suivant :M�ethode Op�erateur Crit�ere d'�evaluationDe type AQ Construction d'une �etoile Fonction de la couverture des donn�eesDe type ID3 Ajout d'un test portant sur Fonction de la partition des donn�eesun attributConsid�erons alors les deux probl�emes d'apprentissage supervis�e C1 et C2 d�etaill�es �gure1.9.0%
50 %
100 %
y
Classe 2
Classe 1
y
0 0XX/2
Y
Y/2
Y
X/2 X
x x
x
X/2 X
(C1) (C2)Fig. 1.9: Adaptation de la direction de la recherche aux probl�emes d'apprentissage.Dans les deux cas les exemples peuvent etre d�ecrits �a l'aide de deux attributs num�eriquesx 2 [0; X] et y 2 [0; Y ] ; et il est facile, en appliquant les r�egles d�etaill�ees ci-dessous, deg�en�erer un nombre quelconque d'exemples distincts formant un ensemble d'apprentissage�equilibr�e.

20 CHAPITRE 1. APPRENTISSAGE AUTOMATIQUE SYMBOLIQUE SUPERVIS�E{ Probl�eme C1(RC11) : (x 2 [0; X=2]) ^ (y 2 [0; Y=2]) ! Classe 2(RC12) : (x 2 [X=2; X]) ^ (y 2 [0; Y=2]) ! Classe 1(RC13) : (x 2 [0; X=2]) ^ (y 2 [Y=2; Y ]) ! Classe 1(RC14) : (x 2 [X=2; X]) ^ (y 2 [Y=2; Y ]) ! Classe 2{ Probl�eme C2(RC21) : (x 2 [0; X=2]) ! Classe 1 (pr 0; 4) sinon Classe 2(RC22) : (x 2 [X=2; X]) ! Classe 1 (pr 0; 6) sinon Classe 2Cependant, malgr�e l'apparente trivialit�e de ces deux probl�emes, les deux types d'algo-rithmes �evoqu�es ci-dessus auront des comportements tr�es di��erents.{ Dans le cas du probl�eme C1, une recherche bas�ee sur la g�en�eralisation sera typ-iquement amen�ee �a d�evelopper un noyau dans chacun des quatre sous-espaces, cequi conduira ais�ement aux quatre r�egles fRC11 ; :::;RC14g. Par contre, une recherchebas�ee sur une m�ethode de sp�ecialisation utilisera un crit�ere (comme l'entropie) des-tin�e �a d�eterminer un point de coupure sur l'un des descripteurs num�eriques x ou y,de telle sorte que ce dernier s�epare au mieux l'espace entre les di��erentes classes.Or, quelque soit le point de coupure envisag�e en x ou en y, la partition de l'espaceobtenue conserve une proportion identique d'exemples de classe 0 ou 1 ; une tellem�ethode est alors incapable de d�ecider comment orienter sa recherche.{ Pour ce qui est du probl�eme C2, les roles sont invers�es : une m�ethode de partition-nement (sp�ecialisation), basant son fonctionnement sur l'analyse de la r�epartitionrelative des classes peut d�eterminer un point de coupure optimum en x = X=2. Parcontre, dans le cas de la recherche par g�en�eralisation, il sera di�cile de d�evelopperun noyau puisque l'environnement imm�ediat comporte dans le meilleur des cas 40%de contre-exemples.1.3.7 Autres m�ethodesBien que la plupart des m�ethodes d'AS soient monotones (ascendantes ou descen-dantes), certains travaux se sont attach�es �a explorer le graphe form�e par (Lh;�g) �a la fois�a partir des mod�eles les plus sp�eci�ques, et �a partir du mod�ele le plus g�en�eral : on parlealors de m�ethode mixte. �A titre d'exemple, cette section pr�esente l'espace des versions,ainsi que la m�ethode ascendante r�esultant de sa combinaison avec la m�ethodologie del'�etoile : l'espace des versions disjonctif.L'espace des versionsL'espace des versions, propos�e par T.M. Mitchell [Mitchell77, Mitchell82] est un exemplede m�ethode d'apprentissage mixte (ascendante et descendante) qui traite incr�ementalementun ot d'exemples positifs et n�egatifs repr�esent�es par un nombre �xe d'attributs, sous l'hy-poth�ese que ces derniers ne sont pas bruit�es, et que la d�e�nition recherch�ee ne s'exprimepas sous forme disjonctive. L'algorithme travaille explicitement sur le treillis associ�e �a

1.3. Strat�egies de r�esolution 21la relation de g�en�eralit�e qui structure l'espace de recherche en d�eveloppant deux arbrescompl�ementaires, l'un compos�e des mod�eles sur-sp�eci�ques, et le second compos�e desmod�eles sur g�en�eraux. En pratique, ce processus peut se r�eduire au maintien des en-sembles S et G m�emorisant respectivement les mod�eles maximalement sp�eci�ques et lesmod�eles maximalement g�en�eraux par rapport aux exemples observ�es. L'espace des ver-sions fonctionne sch�ematiquement de la mani�ere suivante [Mitchell97, Winston92] :/* Algorithme de l'espace des versions */1. Chaque arbre est initialement r�eduit �a un n�ud.S Le modèle le plus spécifique ne couvre qu’un exemple.
G Le modèle le plus général s’apparie avec tout.
2. Si l'exemple fourni est positif, g�en�eraliser tous les mod�eles sp�ecifiquesafin qu'ils recouvrent ce nouvel exemple. R�eciproquement, si l'exemplefourni est n�egatif, sp�ecialiser tous les mod�eles g�en�eraux afin d'empecherleur appariement avec cet exemple.Les exemples positifs permettent degénéraliser les modèles spécifiques.
Les exemples négatifs permettent despécialiser les modèles généraux.
Les modifications op�er�ees pour g�en�erer les nouveaux mod�eles sp�ecifiques(resp. g�en�eraux) doivent etre minimales.3. Les exemples positifs �elaguent les mod�eles g�en�eraux. R�eciproquement,les exemples n�egatifs �elaguent les mod�eles sp�ecifiques.Les modèles généraux ne pouvant qu’être spécialisés, toutexemple positif non couvert par un modèle général ne serajamais couvert par aucun successeur de ce modèle.
Les modèles spécifiques ne pouvant qu’être généralisés, toutexemple négatif couvert par un modèle spécifique s’apparieraavec tous les successeurs de ce modèle.4. Lors du d�eveloppement d'un n�ud, il faut �egalement v�erifier :4.a. Que toute sp�ecialisation est la g�en�eralisation d'un mod�ele sp�ecifique(�). R�eciproquement, toute g�en�eralisation doit etre la sp�ecialisationd'un mod�ele g�en�eral (�).

22 CHAPITRE 1. APPRENTISSAGE AUTOMATIQUE SYMBOLIQUE SUPERVIS�E(β)
On développeet vérifie cenoeud
On développeet vérifie cenoeud
(α)
4.b. Qu'aucune sp�ecialisation n'est la sp�ecialisation d'un autre mod�eleg�en�eral (�). R�eciproquement, aucune g�en�eralisation ne peut etre lag�en�eralisation d'un autre mod�ele sp�ecifique (�).(α) (β)On développeet vérifie cenoeud
On développeet vérifie cenoeud5. L'algorithme termine lorsque les deux arbres ont converg�e.
Solution (unique par hypothèse)
L'algorithme de l'espace des versions est caract�eris�e par :{ Un aspect dynamique provenant du traitement incr�emental du ot des exemples. Ilest ainsi possible de classer certaines instances avant que les structures aient converg�evers le mod�ele solution.{ Un traitement �el�egant et sym�etrique des exemples positifs et n�egatifs.

1.3. Strat�egies de r�esolution 23{ Une complexit�e dans le pire des cas pour la taille de G exponentielle en le nombred'exemples d'apprentissage et le nombre d'attributs (cf. [Haussler88] p. 185).{ La recherche bidirectionnelle dans le treillis des mod�eles candidats permet la vi-sualisation du concept de nuance critique (near-miss). Un contre-exemple est unnear-miss s'il est maximalement sp�eci�que (c'est-�a-dire situ�e sur la fronti�ere dutreillis s�eparant G de S).{ Un autre concept fondamental mis en jeu dans cet algorithme est celui de moindreg�en�eralis�e. Le moindre g�en�eralis�e de deux exemples Ex1 et Ex2 est le plus petit�el�ement du treillis de g�en�eralisation couvrant ces deux exemples. Dans de nombreuxlangages, deux exemples quelconques ont plusieurs moindres g�en�eralis�es.{ Une mise en �uvre di�cile en pratique puisque le bruit ou l'absence de mod�ele nondisjonctif dans le langage-cible empechent la convergence de G et S.L'espace des versions disjonctifM. Sebag a �etendu la m�ethode de l'espace des versions au cas de l'apprentissage de con-cepts disjonctifs �a partir de donn�ees �eventuellement bruit�ees [Sebag94, Sebag96]. L'ap-proche propos�ee, appel�ee espace des versions disjonctif, consiste �a construire la th�eorie Hcorrespondant �a la disjonction des �etoiles G(Ex) obtenues pour chaque exemple Ex de laclasse-cible par rapport �a tous les contre-exemples Ce :H = _Ex2BG(Ex)G(Ex) = ^Ce2BC(Ex;Ce)Le terme C(Ex;Ce), qui permet de discriminer l'exemple Ex du contre-exemple Ce,correspond �a la contrainte r�esultant de la disjonction des tests discriminants les plusg�en�eraux relatifs �a chaque attribut :C(Ex;Ce) = _a2ATa(Ex;Ce)Par exemple, les instances : Forme Taille Couleur ClasseEx Cercle 3 rouge ACe Triangle 12 rouge Bsont discrimin�ees par la contrainte :C(Ex;Ce) = [Forme = Cercle] _ [Taille < 12]dans le cas d'un langage o�u les s�electeurs pour les attributs nominaux et num�eriquessont respectivement = et <,>. Le s�electeur 6=, dont l'utilisation conduirait �a discriminer

24 CHAPITRE 1. APPRENTISSAGE AUTOMATIQUE SYMBOLIQUE SUPERVIS�Euniquement sur les valeurs prises par les contre-exemples, est de peu d'interet. Le coutde construction de H est de p:n2, p correspondant au nombre d'attributs et n au nombred'exemples.L'algorithme de l'espace des versions disjonctif est caract�eris�e par :{ La possibilit�e de caract�eriser des concepts disjonctifs. La combinaison de la m�ethodede l'�etoile et de la construction des ensembles G rappelle une m�ethode des plusproches voisins.{ La possibilit�e de traiter des bases bruit�ees puisque l'utilisateur peut relaxer le mod�eleH en r�eglant un param�etre � qui est un entier positif d�enotant le nombre de contre-exemples contraignant l'�etoile qu'une instance est autoris�ee �a couvrir.{ Le controle du risque de sur-g�en�eralisation via un param�etre M � 1 qui sp�eci�ele nombre minimum de tests qu'une instance doit v�eri�er pour ne pas couvrir uncontre-exemple. Ce param�etre, tout comme �, peut etre ajust�e a posteriori sansn�ecessiter de nouvel apprentissage.{ Une complexit�e dans le pire des cas pour la construction de H (ou la classi�cationde nouvelles instances) polynomiale en le nombre d'exemples d'apprentissage etle nombre d'attributs : la perte de l'incr�ementalit�e est compens�ee par le fait quel'algorithme se r�ev�ele en pratique extremement rapide.{ Un mod�ele H qui, bien que symbolique, est peu intelligible puisqu'il s'agit d'unedisjonction de conjonctions de disjonctions d'un grand nombre de tests.1.4 Biais et ApprentissageLes paragraphes pr�ec�edents ont adopt�e une approche descriptive destin�ee �a pr�esenterdi��erentes m�ethodes d'apprentissage. Une autre mani�ere de les di��erencier consiste �a seplacer du point de vue du th�eor�eme de conservation et �a examiner les di��erents param�etres(implicites ou explicites) orientant les choix faits par l'algorithme : on introduit alors lanotion de biais.1.4.1 D�e�nition et caract�erisation des biaisUne d�e�nition couramment admise du concept de biais est donn�ee dans [Utgo�86] :D�e�nition 1.7 Biais�A l'exception des exemples et contre-exemples du concept-cible, tous les facteurs in uen�cantla s�election d'une hypoth�ese sont des biais.En e�et, la d�e�nition ant�erieure, propos�ee dans [Mitchell80] ( Tout crit�ere permettant dechoisir parmi deux g�en�eralisations autre que la coh�erence observ�ee sur l'ensemble d'ap-prentissage est un biais. ) a le d�efaut de poser que le crit�ere d'�evaluation des hypoth�eses

1.4. Biais et Apprentissage 25(ici la coh�erence sur la base d'apprentissage) n'est pas un biais. Or ce crit�ere ne peut etred�e�ni dans l'absolu pour n'importe quel contexte : en consid�erant, par exemple, le casd'une base bruit�ee, le crit�ere de coh�erence aura tendance �a guider l'algorithme d'appren-tissage vers des hypoth�eses sur-sp�eci�ques.Il est possible de classer les biais en trois grandes cat�egories [Nedellec et al.96] :Les biais de langage sont constitu�es par :{ la d�e�nition syntaxique du langage Lh de repr�esentation des hypoth�eses ;{ toutes les contraintes pos�ees avant l'exploration, comme par exemple la taillemaximale des r�egles ;{ la th�eorie du domaine, dont la raison d'etre est de modi�er le comportement del'algorithme d'apprentissage en fournissant des informations qui am�eliorerontses performances.Les biais de recherche comprennent :{ les crit�eres de pr�ef�erence, comme l'ordre d'examen des solutions candidates(qui d�epend, entre autres, de la relation de g�en�eralit�e consid�er�ee) ou encorele crit�ere de validation interm�ediaire (qui attribue un score aux d�e�nitions etd�epend de la fonction de couverture, et donc de la relation de g�en�eralit�e) ;{ les crit�eres restrictifs, qui �elaguent dynamiquement au cours de la recherchedes portions de l'espace des hypoth�eses en fonction des r�esultats ant�erieurs ;{ la th�eorie du domaine, qui permet parfois �a l'utilisateur de sp�eci�er ses pro-pres crit�eres de pr�ef�erence qui peuvent etre pris en compte au niveau de lag�en�eration des hypoth�eses candidates ou etre int�egr�es dans le crit�ere de valida-tion interm�ediaire.Les biais de validation recouvrent :{ le crit�ere de validation proc�edant, dans le cas de l'apprentissage de conceptsdisjonctifs, �a l'acceptation d'une r�egle au sein de l'ensemble solution ;{ le crit�ere d'arret de l'algorithme.1.4.2 Un apprentissage non biais�eUne premi�ere probl�ematique suivant naturellement la pr�esentation de la notion de biaisconcerne la cr�eation et l'�etude d'un syst�eme d'apprentissage id�eal , au sens ou il n'auraitaucun a priori sur le monde et ne reposerait par cons�equent sur aucun biais. Tom M.Mitchell [Mitchell80, Mitchell97] s'est propos�e d'�etudier la construction et les propri�et�esd'un tel syst�eme, et a fourni un argument bas�e sur un raisonnement proc�edant en deuxtemps :

26 CHAPITRE 1. APPRENTISSAGE AUTOMATIQUE SYMBOLIQUE SUPERVIS�E1. Une proc�edure d'apprentissage non biais�ee implique tout d'abord l'absence de toutbiais de langage : en particulier, Lh doit etre su�samment expressif pour permettrela caract�erisation de n'importe quel sous-ensemble d'exemples E � Le. De plus,puisqu'il n'y a aucun moyen pour choisir entre deux formules de Lh qui auraient descouvertures identiques sur Le, nous supposerons que Lh n'est pas trop expressif, etdonc que toute formule de Lh peut etre identi��ee de mani�ere unique par le sous-ensemble de Le qu'elle couvre, d'o�u la relation :jLhj = 2jLej2. En ce qui concerne l'algorithme de recherche, l'absence de biais implique une m�ethodesimilaire �a l'espace des versions, c'est-�a-dire une m�ethode maintenant l'ensemble S detous les mod�eles maximalement sp�eci�ques et l'ensemble G de tous les mod�eles max-imalement g�en�eraux (puisqu'il n'existe aucun moyen de choisir entre deux �el�ementsde S ou deux �el�ements de G). Il su�t alors de remarquer que la borne S ne con-tient qu'un unique �el�ement correspondant obligatoirement �a la disjonction de tousles exemples d'apprentissage du concept-cible, alors que la borne G correspond �a lan�egation de la disjonction de tous les contre-exemples du concept-cible :S = _Ex2B+Ex ; G = :( _Ce2B�Ce)Ainsi, un syst�eme d'apprentissage non biais�e est incapable de faire le moindre sautinductif, puisque les seules instances qu'il pourra classer sont les exemples et lescontre-exemples de la base d'apprentissage3.En cons�equence, toute tache d'apprentissage pr�esuppose la mise en �uvre implicite ouexplicite de biais. Dans le cas contraire, la m�ethode obtenue n'est capable que d'apprendrepar c�ur les exemples d'apprentissage : on obtient un simple algorithme de m�emorisation,dont le seul apport { dans le meilleur des cas { est une compression d'information sansg�en�eralisation.1.4.3 Les biais en pratiqueQuelques exemples de biais utilesPuisque les syst�emes d'apprentissage non biais�es sont incapables de faire le saut inductifn�ecessaire au classement d'instances inconnues, les biais sont une composante indispens-able de toute tache d'apprentissage. De plus, la caract�erisation des biais mis en �uvre parun algorithme d'apprentissage donn�e permet de pr�eciser le type de g�en�eralisation que ce3Une autre mani�ere de s'en convaincre consiste �a consid�erer la loi de conservation de la pr�ecision eng�en�eralisation : pour tout exemple E n'appartenant pas �a la base d'apprentissage, il existe exactementautant d'hypoth�eses H correctes et compl�etes sur B contenant E que d'hypoth�eses correctes et compl�etessur B ne contenant pas E. Il est donc impossible d'attribuer une classe �a E en l'absence de biais.

1.4. Biais et Apprentissage 27dernier va pouvoir op�erer. En pratique, certains biais peuvent etre justi��es par le contexted'utilisation de l'outil d'apprentissage :Les biais relatifs au domaine d'application concernent toutes les connaissances provenantdes parties amont et aval de la cha�ne du processus d�ecisionnel. Par exemple, l'esti-mation du bruit, ainsi que toutes les connaissances relatives au processus de r�ecolteet de repr�esentation des donn�ees proviennent de la partie amont de la cha�ne duprocessus d�ecisionnel. �A l'opppos�e, la prise en compte du cout des d�ecisions est unbiais li�e �a la partie aval de cette meme cha�ne. Typiquement, si le cout d'une erreurdans le cas d'une instance positive du concept-cible est plus (resp. moins) importantque le cout d'une erreur dans le cas d'une instance n�egative, alors il convient depr�ef�erer les d�e�nitions g�en�erales (resp. sp�eci�ques).Les connaissances du domaine peuvent jouer un role tr�es utile en tant que biais per-mettant �a l'utilisateur de contraindre l'espace de recherche ou de sp�eci�er certainespropri�et�es ou structures sur les donn�ees. Par exemple, dans le cas d'une applicationdans le domaine de la chimie mol�eculaire (la base Mutagenesis d�ecrite en annexeB, section B.4), il est possible de repr�esenter les mol�ecules comme un assemblage�el�ementaire d'atomes et de liaisons. Cependant, la sp�eci�cation de structures (commecertains cycles aromatiques) am�eliore le plus souvent la pr�ecision des r�egles apprises.En e�et, bien qu'aucune nouvelle connaissance n'ait �et�e ajout�ee { la structure d'uncycle aromatique peut se retrouver �a partir des descriptions des atomes et des li-aisons {, la r�eduction du cout de repr�esentation de ces concepts facilite leur prise encompte lors de l'apprentissage.Les biais directement li�es �a l'utilisateur sont centr�es autour de l'intelligibilit�e des hy-poth�eses : puisqu'une des caract�eristiques d'un syst�eme d'AS est de fournir unr�esultat compr�ehensible par un etre humain (ce dernier peut alors b�en�e�cier aumieux des connaissances apprises et en controler la validit�e), il est l�egitime dechercher �a maximiser ce crit�ere. Bien que cette notion soit tr�es di�cile �a sp�eci�er entermes informatiques, et par cons�equent encore plus di�cile �a mesurer, [Kodrato�94]remarque que de tr�es nombreux travaux en AS y font r�ef�erence (sans pour autantl'expliciter). Un exemple d'�etude de cette notion est fourni par [Sommer95]. Ce tra-vail s'appuie sur des constats en linguistique et en psychologie pour proposer denombreux crit�eres s�emantiques et syntaxiques entrant en compte dans la qualit�ed'une th�eorie.Les biais li�es au syst�eme sont ax�es autour des contraintes temporelles et mat�eriellesrelatives �a la tache �a accomplir, qu'il s'agisse de limiter la dur�ee d'un apprentissageou de restreindre l'espace de recherche �a cause de consid�erations li�ees �a la m�emoiredisponible ou �a la complexit�e { pour un probl�eme donn�e { de l'exploration de cetespace.Une cat�egorie particuli�ere de biais, relative au domaine d'application du syst�eme d'ap-prentissage mais �a notre connaissance jamais mentionn�ee en d�epit de son importancecroissante, regroupe toutes les contraintes d'ordre juridique, �ethique ou d�eontologique.

28 CHAPITRE 1. APPRENTISSAGE AUTOMATIQUE SYMBOLIQUE SUPERVIS�EPar exemple, en France, la loi du 6 janvier 1978 relative �a l'informatique, aux �chierset aux libert�es, dont l'une des cons�equences est la mise en place de la commissionnationale de l'informatique et des libert�es (CNIL), pr�evoit des dispositions visant �aimposer une r�e exion humaine lorsqu'une d�ecision est prise �a la suite d'un traite-ment informatique et �a informer les int�eress�es des crit�eres retenus dans le cadred'actes administratifs [Encyclop�dia Universalis].

1.5. Apprentissage en logique du premier ordre 29Le principe du rasoir d'OccamD'autres biais peuvent �egalement relever de principes g�en�eraux. Ainsi, le principe deparcimonie, �egalement connu sous le nom de rasoir d'Occam (attribu�e �a William d'Occam,vers 1330 ap. J.-C. Pluritas non est ponenda sine necessitate ) est tr�es utilis�e dans lessciences exp�erimentales telles que la physique et, bien sur, l'AS. Il stipule que les causesne doivent pas etre multipli�ees si elles ne sont pas utiles , ce qui correspond au biaissuivant :Lorsqu'il est n�ecessaire de choisir parmi des hypoth�eses expliquant des observations, etlorsqu'aucun crit�ere (correction, compl�etude, ...) ne permet de d�epartager ceshypoth�eses, alors il est pr�ef�erable de choisir la plus simple.[Blumer et al.87] montre que, sous certaines hypoth�eses tr�es g�en�erales, le rasoir d'Occampermet de s�electionner des mod�eles ayant une probabilit�e importante de bien se comporteren g�en�eralisation. Ce principe se retrouve �egalement dans des r�esultats r�ecents issus desstatistiques th�eoriques. Par exemple, le principe de controle de la capacit�e mis en �uvrepar les machines �a vecteurs de support (SVMs, [Vapnik98]) peut etre r�esum�e de la mani�eresuivante :{ Informellement, la capacit�e d'une machine correspond �a son aptitude �a caract�eriserun ensemble d'apprentissage quelconque sans erreur. Soient f1(�); f2(�); ::: des classesde machines de capacit�e croissante.{ Alors, pour une tache d'apprentissage donn�ee, la meilleure performance en g�en�erali-sation est obtenue au point d'�equilibre entre la pr�ecision sur l'ensemble d'apprentis-sage (�a maximiser) d'une part, et la capacit�e de la classe de la machine (�a minimiser)d'autre part.1.5 Apprentissage en logique du premier ordreLa plupart des outils de data mining commercialis�es �a l'heure actuelle qui mettenten �uvre des techniques d'AS travaillent sur des donn�ees mises sous forme tabulaireet produisent des r�egles de type Si Condition Alors Conclusion o�u Conditionest une conjonction de tests portant sur la valeur des descripteurs et Conclusion laclasse reconnue. On dit alors que Lh est un langage de la logique propositionnelle (oulogique d'ordre 0). Cette section est consacr�ee �a la programmation logique inductive (PLI,[Muggleton90, Muggleton92, Muggleton et al.94, Lavrac et al.99]) qui regroupe l'ensem-ble des techniques d'inf�erence produisant des programmes logiques �a partir d'exemples.Une premi�ere partie rappelle les sp�eci�cit�es du langage et analyse le gain d'expressivit�eau regard de l'accroissement de la complexit�e li�ee �a la manipulation des formules. La sec-onde partie pr�esente quelques techniques classiques de PLI et souligne les points communspartag�es avec les techniques attribut-valeur.

30 CHAPITRE 1. APPRENTISSAGE AUTOMATIQUE SYMBOLIQUE SUPERVIS�E1.5.1 Le langage de la logique relationnelleExpressivit�e du langageLe langage de la logique relationnelle (dont la d�e�nition formelle �gure en annexe A,section A.2.2), est caract�eris�e par un vocabulaire bien plus riche que la logique proposi-tionnelle puisqu'il permet :{ de distinguer les objets (les constantes) des propri�et�es (les pr�edicats) qui les car-act�erisent, comme dans l'expression :parent(s�ebastien; guy){ de d�e�nir des relations g�en�erales portant sur un nombre quelconque d'objets �a l'aidede symboles de variables (associ�es aux quanti�cateurs 8 et 9) :8X 8Y (parent(X; Y )! enfant(Y;X))Cette formule, qui est une clause de Horn, est �egalement not�ee :enfant(Y;X) parent(X; Y ):{ de combiner les relations a�n de former des concepts de complexit�e croissante,comme par exemple :grand parent(X; Y ) parent(X;Z) ^ parent(Z; Y ):ou encore : " ancetre(X; Y ) parent(X; Y ):ancetre(X; Y ) parent(X;Z) ^ ancetre(Z; Y ):qui d�e�nit un concept (ancetre) mettant en jeu une cha�ne relationnelle dont la taillene peut etre born�ee ;{ de repr�esenter, �a l'aide des symboles de fonction, des ensembles in�nis (d�enombrables)de symboles. Il est par exemple possible de d�e�nir l'ensemble @ des entiers naturelsen repr�esentant l'axiomatique de Peano �a l'aide de la constante z�ero et de la fonctionsuccesseur, d'arit�e 1, not�ee s() :" entier naturel(z�ero) :entier naturel(s(X)) entier naturel(X):D'autres notions �el�ementaires d'arithm�etique sur les entiers, telles que la relationd'ordre � et le concept d'addition peuvent etre d�e�nis au moyen de la logique rela-tionnelle : " sup eg(X; z�ero) :sup eg(s(X); s(Y )) sup eg(X; Y ):" somme(X; z�ero;X) :somme(X; s(Y ); s(Z)) somme(X; Y; Z):

1.5. Apprentissage en logique du premier ordre 31Traitement automatiqueEn contrepartie de sa grande expressivit�e, la logique relationnelle a le d�efaut d'etre bienplus couteuse sur le plan calculatoire que la logique attribut-valeur. Par exemple, con-sid�erons le probl�eme de la validation logique d'une hypoth�ese [Muggleton et al.94] :�Etant donn�es les ensembles de clauses B+, B�, T h et H correspondant respectivement �ala base d'apprentissage (exemples et contre-exemples), �a la th�eorie du domaine et �a unmod�ele, d�eterminer si : 8Ex 2 B+; H ^ T h j= Ex8Ce 2 B�; H ^ T h 6j= CeCe probl�eme, qui revient �a r�esoudre plusieurs fois le probl�eme de la satis�abilit�e d'unensemble de clauses, est d�ecidable dans le cas de la logique d'ordre 0 mais ind�ecidable enlogique d'ordre 1 [SS88]. En pratique, les syst�emes d'apprentissage relationnel r�esolventcette di�cult�e en travaillant sur des sous-ensembles du langage de la logique d'ordre 1.Les restrictions les plus courantes comprennent :{ des hypoth�eses sous forme de clauses de Horn ;{ la suppression des symboles de fonctions ;{ l'interdiction de g�en�erer des d�e�nitions r�ecursives.Malgr�e ces restrictions, le test d'implication (not�e `) qui se substitue �a l'implicationlogique ind�ecidable (not�ee j=) est NP -complet. Ce ph�enom�ene4 est illustr�e intuitivementen consid�erant l'hypoth�ese et l'exemple suivants :H : C(I) P (I;X; Y ) ^ P (I; Y; Z) ^ P (I; Z; T ):E : C(e1) P (e1; a; b) ^ P (e1; c; a) ^ P (e1; d; c):Ces deux clauses ne comportent pas de symbole de fonction et ne mettent en jeu aucunm�ecanisme d'auto-r�ef�erence. De plus, seule l'hypoth�ese comporte des variables. Ces for-mules sont donc l'expression la plus simple possible de la notion de concept relationnel :des variables et des constantes lient entre eux des pr�edicats.Cependant, le test E ` H, qui revient �a d�eterminer quels symboles de E associer �aquelles variables de H, peut n�ecessiter de multiples essais. Raisonnons sur l'exemple ci-dessus. Puisque les deux tetes de clause doivent s'apparier, il vient imm�ediatement que lasubstitution �1 = fI=e1g est contenue dans la solution. Cependant, il n'est pas possiblede d�eterminer a priori les instanciations des variables X, Y , Z et T . Choisir par exemple�2 = fI=e1; X=a; Y=bg conduit �a une impasse car l'hypoth�ese devient alors :H�2 = C(e1) P (e1; a; b) ^ P (e1; b; Z) ^ P (e1; Z; T ):4La d�e�nition de ` dans le cadre de SIAO1, l'�etude de sa complexit�e et la construction d'une proc�edurede calcul e�cace sont l'objet du chapitre 3.

32 CHAPITRE 1. APPRENTISSAGE AUTOMATIQUE SYMBOLIQUE SUPERVIS�Eet il n'existe pas dans E d'atome couvert par P (e1; b; Z). Les variables X, Y , Z et T sontdites existentielles car elles apparaissent uniquement dans le corps de la clause ; elles sont�a l'origine de la NP -compl�etude du test `.La complexit�e exponentielle du test de couverture (en fonction du nombre de litt�erauxde l'hypoth�ese, voir chapitre 3) �etant intrins�eque �a la nature relationnelle des donn�ees, iln'est pas surprenant que tous les syst�emes de PLI fassent appel en pratique �a di��erentsbiais qui sont autant de restrictions destin�ees �a g�erer le dilemme cout de l'induction /richesse du langage .1.5.2 La programmation logique inductiveCette section pr�esente tr�es succintement quelques syst�emes de PLI repr�esentatifs du do-maine a�n de situer SIAO1 (ainsi que les approches fond�ees sur les m�ethodes �evolutionnairesd�etaill�ees dans le chapitre 2) parmi les autres travaux qui, bien que mettant en �uvredes m�ethodes di��erentes, ont pour objectif de r�esoudre des probl�emes similaires. A�n derester concis, les biais dont le but est de restreindre la complexit�e et donc l'expressivit�edu langage (comme par exemple le langage des modes de PROGOL ou l'ij-d�eterminationde GOLEM) ne sont pas d�etaill�es. Le lecteur int�eress�e consultera les r�ef�erences.GOLEM [Muggleton et al.90] est un syst�eme adoptant une strat�egie de recherche as-cendante fond�ee sur une adaptation du moindre g�en�eralis�e en pr�esence d'une th�eoriedu domaine. �Etant donn�ee une th�eorie du domaine T h compos�ee de clauses d�e�nies,GOLEM consid�ere l'ensemble Mh (appel�e mod�ele de Herbrand h-facile) de tous lesatomes clos d�eductibles de T h en au plus h �etapes de r�esolution. Cette reformula-tion de la th�eorie a l'avantage de transformer un mod�ele potentiellement in�ni enun mod�ele de taille born�ee qui est toujours calculable.La strat�egie de recherche est fond�ee sur la m�ethode de couverture it�erative. L'hy-poth�ese ajout�ee �a chaque �etape est construite comme moindre g�en�eralis�ee du plusgrand nombre possible d'exemples positifs non couverts. Une di�cult�e relative aucalcul du moindre g�en�eralis�e de deux clauses C1 et C2 de la logique d'ordre 1 vientdu fait que la taille de ce dernier est born�ee par jC1j:jC2j. La taille du moindreg�en�eralis�e cro�t donc exponentiellement ; dans le cas de n exemples, elle peut attein-dre jMhjn + 1. A�n de r�esoudre cette di�cult�e, GOLEM restreint Lh aux clausesij-d�etermin�ees : la taille du plus grand moindre g�en�eralis�e ij-d�etermin�e est en e�etborn�ee par une fonction polynomiale.Une autre cat�egorie de syst�emes de PLI ascendants, dont CIGOL [Muggleton et al.88]et ITOU [Rouveirol91] font partie, est fond�ee sur des op�erateurs dits d'inversion dela r�esolution [Muggleton et al.92]. Plus r�ecemment, le syst�eme CILGG propos�e parJ.-U. Kietz, permet l'induction de concepts relationnels avec une complexit�e polyno-miale. Ce r�esultat est obtenu �a l'aide d'un op�erateur de presque moindre g�en�eralis�egarantissant une borne �a la complexit�e des clauses g�en�er�ees.FOIL [Quinlan et al.93, Quinlan et al.95] est un syst�eme descendant. Les entr�ees sontconstitu�ees des exemples et contre-exemples du pr�edicat-cible, et d'une th�eorie du

1.5. Apprentissage en logique du premier ordre 33domaine d�e�nie en extension. La description en extension d'une th�eorie consiste �a�enum�erer pour chaque symbole de pr�edicat introduit les ensembles de constantes quiv�eri�ent la relation. La th�eorie du domaine prise en compte par FOIL est, commedans le cas de GOLEM, de taille �nie.La strat�egie de recherche est tr�es proche de celle du syst�eme d'ordre 0 CN2 (cf.section 1.3.4). En e�et, FOIL apprend les clauses l'une apr�es l'autre, chaque clause�etant construite par ajout successif de litt�eraux. Le crit�ere de choix du litt�eral �aajouter est le gain d'information, �egalement choisi par Quinlan pour son syst�emeID3 (d�ecrit section 1.3.5). L'op�erateur de ra�nement est construit de mani�ere �aexclure les litt�eraux qui occasionnent des appels r�ecursifs sans �n ou qui ne satisfontpas des contraintes li�ees aux types des arguments ou aux liens entre variables.PROGOL [Muggleton95] est, comme FOIL, un syst�eme descendant apprenant les clausesles unes apr�es les autres. Il introduit le langage des modes, qui permet �a l'utilisateurde d�eclarer des biais tr�es pr�ecis concernant les formes possibles des litt�eraux ins�er�es.Pour chaque exemple, PROGOL d�eveloppe la clause la plus sp�eci�que respectantles contraintes des modes, not�ee ?i. Une recherche de type A� parmi les clauses cou-vrant ?i est alors r�ealis�ee, ce qui donne �a cet algorithme une certaine ressemblanceavec AQ (cf. section 1.3.4).TILDE [Blockeel et al.98, Blockeel et al.99] est un syst�eme construit sur le mod�ele deC4.5 qui g�en�ere des arbres de d�ecision logiques dont les n�uds sont des conjonctionsde litt�eraux et dont les feuilles sont �etiquet�ees par une classe. L'expressivit�e dulangage de repr�esentation correspond �a un programme PROLOG (pouvant contenirdes cuts) dont les tetes de clauses sont des pr�edicats d'arit�e 0. Ce contexte, connusous le nom d' apprentissage �a partir d'interpr�etations et fond�e sur l'hypoth�esede localit�e de l'information, permet l'induction e�cace de concepts relationnels nonr�ecursifs.REMO [Zucker et al.96] et son successeur REPART [Zucker et al.98] ont introduit unetechnique, appel�ee propositionalisation, qui consiste �a reformuler des descriptions enordre 1 en une repr�esentation en ordre 0. La composante relationnelle de la logiqued'ordre 1 provoque un �eclatement de chaque exemple sur plusieurs lignes (ie. exem-ples) de la repr�esentation d'ordre 0 puisqu'�a chaque ligne correspond un appariementpossible de la structure relationnelle. Ainsi, la projection sur une repr�esentation enordre 0 d'une repr�esentation en ordre 1 sp�eci�e un probl�eme d'apprentissage parti-culier, quali��e de multi-instances : la solution recherch�ee doit couvrir au moins uneligne parmi celles associ�ees �a chaque exemple, et aucune des lignes associ�ees auxcontre-exemples. [Alphonse et al.99] a r�esolu l'inconv�enient majeur de ces m�ethodes,li�e �a la taille de la reformulation en ordre 0. En e�et, le nombre d'appariements�etant exponentiel en fonction du nombre de litt�eraux des hypoth�eses, la taille duprobl�eme reformul�e est le principal facteur limitant. La solution propos�ee, appel�eepropositionalisation s�elective, consiste �a alterner les phases de reformulation avecles �etapes d'apprentissage. Par exemple, dans le cas des m�ethodes descendantes,seules les lignes correspondant aux hypoth�eses maximalement g�en�erales discrim-inant les contre-exemples doivent etre m�emoris�ees. L'utilisation incr�ementale des

34 CHAPITRE 1. APPRENTISSAGE AUTOMATIQUE SYMBOLIQUE SUPERVIS�Econtre-exemples permet donc de maintenir une structure bien plus petite, ce qui setraduit exp�erimentalement par un �elagage consid�erable de l'espace des appariementscandidats et un gain en temps �egalement tr�es important.STILL [Sebag et al.97a] est fond�e sur la notion d'appariement stochastique a�n de per-mettre l'induction d'hypoth�eses relationnelles de taille quelconque avec un cout poly-nomial. L'appariement stochastique consiste, apr�es une propositionalisation fond�eesur un patron, �a �echantillonner l'espace des appariements en fonction des ressourcesdisponibles plutot que de proc�eder �a une recherche exhaustive (dont le cout estexponentiel en fonction de la taille des hypoth�eses). Le d�esavantage de la m�ethodevient du fait que le test d'appariement est incorrect et incomplet puisqu'un �echec dutest peut venir soit du fait qu'aucun appariement n'est possible entre l'hypoth�ese etl'exemple, soit du fait que l'�echantillonnage n'a pas permis de trouver l'appariementsolution. L'utilisateur peut controler le dilemme cout de l'induction / qualit�e des hy-poth�eses en param�etrant le nombre d'�echantillons. Plus l'�echantillon est important,plus l'incertitude du test diminue.1.6 R�ecapitulatifCe chapitre a permi d'e�ectuer un tour d'horizon de l'apprentissage automatique sym-bolique supervis�e (AS), qui est le cadre dans lequel se situe notre travail. De nombreuxarguments ont �et�e d�evelopp�es :{ L'AS est une discipline r�ecente, motiv�ee par de nombreux besoins, par exemple ening�eni�erie des connaissances (IC) ou encore en extraction des connaissances �a partirdes donn�ees (ECD).{ L'AS peut etre formul�e comme un probl�eme d'optimisation particulier, portant surdes d�e�nitions. L'espace de recherche est structur�e par une relation d'ordre par-tiel, appel�ee relation de g�en�eralit�e. Les strat�egies de recherche les plus courantesexploitent cette relation.{ Une autre particularit�e de l'AS est l'application du principe d'induction, qui con-siste �a g�en�eraliser des observations �a des cas inconnus. Une condition indispensable�a la g�en�eralisation est la mise en �uvre de biais permettant de choisir une d�e�nitionparmi plusieurs hypoth�eses candidates de qualit�e �equivalente sur la base d'appren-tissage.{ Certains domaines d'application mettent en jeu des donn�ees fortement structur�ees.La programmation logique inductive (PLI) �etudie l'induction de concepts exprim�esdans le langage de la logique du premier ordre. Si l'expressivit�e du langage est unatout de ces m�ethodes, l'accroissement de la complexit�e n�ecessite la mise en �uvrede biais parfois tr�es restrictifs.

Chapitre 2Algorithmes d'�Evolution pour l'ASCe chapitre a pour ambition de pr�esenter bri�evement les algorithmes d'�evolution ainsique les principaux travaux concernant leur application dans le cadre de l'apprentissageautomatique symbolique supervis�e. En cons�equence, une premi�ere partie est consacr�ee �ala description des grandes classes de m�ethodes �evolutionnaires que sont les algorithmesg�en�etiques, les strat�egies d'�evolution, la programmation �evolutionnaire et la program-mation g�en�etique. Toutes ces classes sont pr�esent�ees comme des variations d'un memealgorithme g�en�erique de simulation de l'�evolution de populations d'individus. La sec-onde partie, d�edi�ee �a l'application de ces algorithmes aux probl�emes d'apprentissage au-tomatique symbolique supervis�e, d�ecrit les principales approches qui proviennent des al-gorithmes g�en�etiques ainsi que de la programmation g�en�etique. Elle est compl�et�ee parune pr�esentation plus approfondie de travaux sp�eci�ques, particuli�erement importants ourepr�esentatifs, auxquels il est fait r�ef�erence au cours de cette th�ese.2.1 Les algorithmes d'�evolution2.1.1 IntroductionNaissance du domaineDans les ann�ees 60, plusieurs chercheurs travaillant ind�ependamment en Allemagne, surla cote Est et sur la cote Ouest des US ont propos�e et �etudi�e des m�ethodes d'optimisationbas�ees sur les m�ecanismes de l'�evolution biologique darwinienne. Des trois �ecoles originellesont r�esult�e les trois familles d'algorithmes [Spears et al.93, Schoenauer et al.97] :1. Les algorithmes g�en�etiques d�evelopp�es par J.H. Holland �a Ann Arbor dans le Michi-gan sont issus de travaux consacr�es �a l'�etude de l'�evolution du patrimoine g�en�etiqued'une population. Le mod�ele canonique �etudi�e se fonde sur une repr�esentation desindividus par des chromosomes cod�es sous la forme de cha�nes binaires de taille �xe.2. Les strat�egies d'�evolution, d�evelopp�ees par I. Rechenberg et H.-P. Schwefel �a la TUB(Technische Universit�at Berlin), proviennent de travaux d'optimisation appliqu�esdans divers domaines d'ing�eni�erie. Contrairement aux algorithmes g�en�etiques, les35

36 CHAPITRE 2. ALGORITHMES D'�EVOLUTION POUR L'ASstrat�egies d'�evolution sont principalement utilis�ees dans le but d'optimiser des para-m�etres r�eels.3. La programmation �evolutionnaire, d�evelopp�ee par L.J. Fogel �a San Diego en Cali-fornie est issue de travaux li�es �a l'intelligence arti�cielle : cette m�ethode op�erait ene�et initialement sur des populations d'automates d'�etats �nis, dont l'adaptation�etait mesur�ee par leur capacit�e �a pr�edire leur environnement.Une description des aspects biologiques de l'�evolution et de la reproduction des etresvivants qui ont conduit au Darwinisme mol�eculaire inspirant ces travaux peut etretrouv�ee dans [Back96].Un algorithme d'�evolution g�en�eriqueCes m�ethodes ont de nombreux points en commun. Elles op�erent toutes sur des ensemblesd'objets (des vecteurs binaires ou r�eels, des automates, etc.) qui seront appel�es par analogieavec la source d'inspiration biologique population d'individus . Chaque individu, mod�elis�epar son patrimoine g�en�etique, peut etre consid�er�e d'au moins deux points de vue :{ le point de vue g�enotypique, qui d�ecrit l'individu d'apr�es sa repr�esentation interne(son code g�en�etique brut) ;{ le point de vue ph�enotypique, qui correspond �a l'expression du code g�en�etique dansl'environnement biologique (l'organisme obtenu).
"codage"P(t+1)
phénotypiqueEspace
génotypiqueEspace
sélection
reproductionéval
uatio
n ("
déco
dage
")
population initiale P(t)Fig. 2.1: Interaction g�enotype/ph�enotype au cours du processus d'�evolution.La �gure 2.1, qui reprend un sch�ema propos�e initialement par R.C. Lewontin [Atmar92],montre que l'�evolution, tout comme les m�ethodes qui s'en sont inspir�ees, est un proces-sus qui se d�eroule en alternance sur les plans g�enotypique et ph�enotypique. Contraire-

2.1. Les algorithmes d'�evolution 37ment �a des th�eories de l'�evolution comme le Lamarckisme, le Darwinisme implique que leph�enotype ne modi�e pas le g�enotype (c'est-�a-dire que l'etre vivant ne peut modi�er soncode g�en�etique au cours de son existence) : le ux de l'information g�en�etique ne comporteaucun retour-arri�ere et seuls le principe de survie des plus adapt�es et les modi�cationsmol�eculaires op�erant sur les chromosomes lors de la reproduction des parents d�eterminent(en premi�ere approximation) l'�evolution du patrimoine g�en�etique de la population.Le squelette commun �a tous les algorithmes d'�evolution est compos�e d'une boucle g�en�eriquequi correspond au d�eroulement des g�en�erations biologiques (cf. �gure 2.2).Initialisation de
des individusla populationEvaluation
terminaisonCritère de
non
Opérateur(s)
Finoui
Sélection desindividusd’évolutionFig. 2.2: Algorithme d'�evolution g�en�erique.Bien que le d�etail du fonctionnement de l'�evolution varie d'une m�ethode �a l'autre, lesprincipaux op�erateurs appliqu�es dans la boucle g�en�erique (qui sont la plupart du tempsprobabilistes) peuvent etre class�es en trois cat�egories :{ L'op�erateur d'�evaluation (appel�e �egalement fonction de qualit�e), qui attribue unscore aux individus. Ce score mesure leur adaptation �a l'environnement. Dans le casg�en�eral de l'optimisation (maximisation) d'une fonction f , le score de l'individu Iest simplement f(I).{ L'op�erateur de s�election, qui applique le principe darwiniste selon lequel plus unindividu est adapt�e �a son environnement, plus sa probabilit�e de survivre et de sereproduire est �elev�ee.{ Les op�erateurs de reproduction, qui travaillent sur le code g�en�etique. En modi�antles chromosomes, ils permettent la g�en�eration de nouveaux individus. De nombreuxalgorithmes d'�evolution se placent dans le cadre des algorithmes g�en�etiques en util-isant un op�erateur de mutation et un op�erateur de recombinaison. Cependant, lenombre et la fonction des op�erateurs peuvent varier suivant les m�ethodes et lesobjectifs poursuivis.Deux autres op�erations sont n�ecessaires �a l'implantation du processus de simulation :{ l'initialisation de la population au tout d�ebut du processus ;{ le test de terminaison qui a lieu �a chaque it�eration de la boucle d'�evolution.

38 CHAPITRE 2. ALGORITHMES D'�EVOLUTION POUR L'ASAlgorithmes d'�evolution et optimisationIl existe une tr�es forte similitude entre le processus d'�evolution tel qu'il a �et�e d�ecrit demani�ere g�en�erique ci-dessus et un processus d'optimisation. En e�et, la pression exerc�eepar l'op�erateur de s�election �a travers l'op�erateur d'�evaluation peut etre consid�er�ee commeun proc�ed�e de maximisation de la fonction de qualit�e ; l'algorithme �evolutionnaire corre-spond alors �a un processus d'optimisation de cette fonction. Cependant, les algorithmes�evolutionnaires se di��erencient des m�ethodes d'optimisation classiques puisque :1. la gestion d'une population d'individus permet l'exploration simultan�ee de plusieurspoints de l'espace de recherche ;2. la fonction de qualit�e est utilis�ee uniquement lors de l'�etape d'�evaluation des indi-vidus a�n d'obtenir leur score.Actuellement, la tr�es grande majorit�e des travaux concernant les algorithmes d'�evolutiontraite de leur �etude ou de leur application en tant que proc�edures d'optimisation. Enpratique, ces derniers sont particuli�erement recommand�es lorsque le probl�eme �a r�esoudrepr�esente une ou plusieurs des caract�eristiques suivantes :1. la fonction �a optimiser ne dispose pas des qualit�es de r�egularit�e (telles que la conti-nuit�e, la d�erivabilit�e, ...) requises par les approches math�ematiques classiques ;2. le probl�eme est bruit�e, dynamique, multimodal (cf. les techniques de niches �ecologiquesou les fonctions de partage de la qualit�e (sharing) [Goldberg et al.87]), multi-crit�eres[Zitzler99] ou encore d�e�ni sur des espaces de dimension �elev�ee ;3. la fonction �a optimiser pr�esente certaines qualit�es math�ematiques, cependant lesheuristiques de recherche classiques ne donnent pas de r�esultats satisfaisants. Parexemple, bien que les probl�emes de type longpath [Horn et al.94] puissent etre r�esoluspar un algorithme de mont�ee (hill climbing), le fait que le nombre de pas n�ecessairesoit exponentiel en fonction de la dimension de l'espace de recherche rend ce dernierinutilisable en pratique.Comme le remarque [Back96], meme dans les cas o�u le probl�eme d'optimisation est glob-alement intraitable, la d�ecouverte par les algorithmes d'�evolution de solutions de meilleurequalit�e que celles obtenues par les m�ethodes traditionnelles dans de nombreuses applica-tions pratiques est �egalement une raison majeure de leur succ�es.Les restrictions concernant l'utilisation des algorithmes d'�evolution sont les suivantes :{ Du fait de leur nature stochastique d'une part et de l'utilisation d'une populationd'autre part, ces m�ethodes n�ecessitent une puissance de calcul importante. En par-ticulier, il est pr�ef�erable que la fonction de qualit�e, qui est utilis�ee un tr�es grandnombre de fois, soit rapidement calculable1.1Cette condition n'est pas imp�erative : par exemple [Periaux et al.95] applique des techniques�evolutionnaires �a des probl�emes d'optimisation de formes en a�erodynamique qui n�ecessitent pour chaquestructure des calculs extremement complexes (g�en�eration d'un r�eseau maill�e mod�elisant la structure �apartir de la repr�esentation initiale sous forme de points de controle de courbes splines puis �evaluation dela structure ainsi discr�etis�ee par r�esolution des �equations d'Euler associ�ees).

2.1. Les algorithmes d'�evolution 39{ Bien que certaines classes d'algorithmes �evolutionnaires comme la programmationg�en�etique soient tr�es souples quand �a la structure syntaxique de l'espace de recherche,la plupart des m�ethodes travaillent sur des vecteurs de bool�eens ou de r�eels. Cettecontrainte, commune �a la totalit�e des m�ethodes d'optimisation classiques, est un in-conv�enient lorsque le domaine d'application n�ecessite la manipulation de structurescomplexes, comme par exemple en Apprentissage Symbolique.De plus ces techniques ont, comme beaucoup d'autres, l'inconv�enient de ne pouvoir garan-tir en pratique la d�ecouverte de l'optimum (ou des optima), ni de pouvoir les reconna�tredans le cas o�u ces derniers auraient �et�e d�ecouverts. En e�et les r�esultats th�eoriques,lorsqu'ils existent (convergence �a l'in�ni, taille ad�equate de la population) ont souvent uncout trop important pour pouvoir etre utilis�es dans des conditions r�eelles.Les sous-sections qui suivent sont consacr�ees �a la pr�esentation des principales m�ethodes�evolutionnaires.2.1.2 Les algorithmes g�en�etiquesHistoriqueLes algorithmes g�en�etiques sont probablement les plus connus des algorithmes d'�evolution.Leur forme initiale (dite canonique ) est due aux travaux de Holland, r�esum�es en 1975 dansle livre Adaptation in natural and arti�cial systems [Holland75], qui a servi de r�ef�erence �al'ensemble des travaux du domaine. Bien qu'un des buts initiaux de son travail ait �et�e lasimulation et l'�etude des syst�emes biologiques, Holland a poursuivi un objectif bien plusg�en�eral en d�eveloppant une th�eorie des syst�emes adaptatifs, capables d'apprentissage,interagissant avec leur environnement �a l'aide de d�etecteurs et d'e�ecteurs (la section2.2.1 est consacr�ee aux syst�emes de classeurs issus de ces travaux). De plus, Holland s'est�egalement int�eress�e �a l'application des algorithmes g�en�etiques �a la r�esolution de probl�emesr�eels.Description de l'algorithme g�en�etique canoniqueL'algorithme g�en�etique canonique (AGC) op�ere sur une population P de n individus.Chaque individu Ik (1 � k � n) est compos�e d'un chromosome qui est une cha�ne binairede longueur �xe l : Ik = fik1; :::; ikl g. La population initiale P0 est g�en�er�ee al�eatoirement.Le d�eroulement d'une g�en�eration, qui permet d'obtenir la population Pg+1 �a partir de lapopulation Pg est le suivant :�Evaluation et s�electionSoit f : I �! <+� la fonction d'�evaluation et Pg la population courante ; le premierop�erateur appliqu�e est l'op�erateur de s�election. Ce dernier g�en�ere une population P 0gen choisissant al�eatoirement n individus de Pg, o�u la probabilit�e de s�electionner un

40 CHAPITRE 2. ALGORITHMES D'�EVOLUTION POUR L'ASindividu Ik de Pg est : ps(Ik) = f(Ik)Pnj=1 f(Ij)Cet op�erateur, non d�eterministe et conforme au principe darwiniste de la s�electionnaturelle des individus les plus adapt�es est appel�e s�election proportionnelle �a laqualit�e .ReproductionPar analogie avec le monde biologique, les individus s�electionn�es sont appel�es par-ents. Les op�erateurs mod�elisant la reproduction sexu�ee (la mutation, not�ee � : I ! Iet le croisement, not�e � : I2 ! I2, voir �gure 2.3) permettent d'obtenir le mat�erielg�en�etique des individus de la population suivante (les enfants). Le croisement �a unCroisement
à un point
0 1 1 0
1 1 0 0
0
1
Point de coupure
0 0 1 1 0
1 1 1 0 0
1 1 1
100
0 0 1
111
Mutation0 0 1 0 0 0 11 0 0 1 1 0 0 11Fig. 2.3: Op�erateurs de reproduction de l'AGC.point tire un point de coupure uniform�ement dans [1; l � 1] puis �echange les sous-cha�nes correspondantes. Il est appliqu�e avec une probabilit�e pc �a l'ensemble desindividus de P 0g qui ont �et�e pr�ealablement group�es par paires. La population ainsiobtenue est not�ee P 00g . La mutation consiste �a changer chacun des bits des individusde P 00g avec une probabilit�e pm (suppos�ee peu importante), ce qui fournit Pg+1.La �gure 2.4 d�etaille l'�evolution sur une g�en�eration d'une population de n = 4 individuscomportant l = 5 bits. La fonction de qualit�e utilis�ee ici est f(Ik) = (Plj=1 ikj :2l�j)2. Enpratique, les populations contiennent plusieurs dizaines �a plusieurs milliers d'individus.Une explication intuitive du fonctionnement g�en�eral de l'AGC a �et�e propos�ee par Hollandet Goldberg [Goldberg89]. La s�election duplique les meilleurs individus avec d'autant plusde force que la pression s�elective, d�e�nie par le rapport fmaxf , o�u fmax d�enote la qualit�edu meilleur individu de P et f la qualit�e moyenne, est importante. Le croisement proc�ede�a un �echange d'informations entre deux chromosomes et permet, avec la s�election, lapropagation des blocs de bits garantissant une qualit�e �elev�ee des individus. Il est donctypiquement appliqu�e avec une probabilit�e assez importante (pc = 12 par exemple). Parcontre la mutation, qui ne sert qu'�a maintenir une certaine diversit�e g�en�etique et garantir lapossibilit�e d'explorer tout point de l'espace de recherche, est appliqu�ee avec une probabilit�e

2.1. Les algorithmes d'�evolution 41Pgz }| {I1 = 0 0 0 1 1I2 = 0 1 0 1 1I3 = 1 0 1 1 0I4 = 1 1 1 1 0Calcul des probabilit�es de s�electionf(I1) = 32 ) ps(I1) = 91514 � 0; 0059f(I2) = 112 ) ps(I2) = 1211514 � 0; 0799f(I3) = 222 ) ps(I3) = 4841514 � 0; 3197f(I4) = 302 ) ps(I4) = 9001514 � 0; 5945
s�election�! P 0gz }| {I 01 = I3 = 1 0 1 1 0I 02 = I1 = 0 0 0 1 1I 03 = I4 = 1 1 1 1 0I 04 = I3 = 1 0 1 1 0D�etermination des couples et des points de coupureCouple Croisement ?(I 01; I 03) non(I 02; I 04) oui (e = 3)
Croisement�! P 00gz }| {I 001 = 1 0 1 1 0I 002 = 0 0 1 1 0I 003 = 1 1 1 1 0I 004 = 1 0 0 1 1 Mutation�! Pg+1z }| {I1 = 1 0 1 1 0I2 = 0 0 1 0 0I3 = 1 1 1 1 0I4 = 1 0 1 1 1 f(I1) = 222f(I2) = 42f(I3) = 302f(I4) = 232Fig. 2.4: D�eroulement d'un cycle de l'algorithme g�en�etique canonique.tr�es faible (pm = 11000 par exemple) a�n d'�eviter que l'algorithme ne puisse plus conserveret exploiter les individus prometteurs et �nisse par se comporter comme une marcheal�eatoire.Cette explication, qui valorise l'e�et de l'op�erateur de croisement (principal apport initialde Holland par rapport aux autres m�ethodes �evolutionnaires), est l'objet de discussions eta �et�e souvent remise en question. Par exemple [Jones95] critique la m�ethode de validationconsistant �a comparer un AGC classique avec un AGC sans croisement. Une nouvellem�ethode, bas�ee sur le remplacement du croisement classique par un croisement al�eatoire,montre que dans de nombreux cas le croisement classique, apparemment utile, peut etreremplac�e avantageusement par un op�erateur de macromutation. Cet argument remet encause l'analyse justi�ant l'int�eret du croisement par leur capacit�e �a permettre un �echanged'informations entre individus de la population. D'autre part, elle l�egitimise les m�ethodes�evolutionnaires telles que les strat�egies d'�evolution, d�ecrites section 2.1.3.

42 CHAPITRE 2. ALGORITHMES D'�EVOLUTION POUR L'ASAnalyse de l'algorithme g�en�etique canoniqueL'analyse faite par Holland de l'AGC �a l'aide des sch�emas est le premier r�esultat th�eoriquefaisant r�ef�erence dans le domaine et ayant donn�e lieu �a de tr�es nombreuses investigations.Un sch�ema est un vecteur (not�e H) de f0; 1; �gl, que l'on utilise a�n de caract�eriser lasimilarit�e d'ensembles d'individus ; le symbole � correspondant indi��eremment �a 0 ou �a 1.Par exemple le sch�ema H = 1 � � � 0�, qui comporte deux bits d�e�nis (soulign�es), couvreentre autres les individus 101000 et 111001. Il est ais�e de d�emontrer d'une part qu'ilexiste 3l sch�emas distincts d�e�nis sur l'espace des cha�nes binaires de taille l, et d'autrepart qu'un individu donn�e appartient �a 2l � 1 sch�emas.D�e�nition 2.1 Ordre d'un sch�emaL'ordre d'un sch�ema H, not�e o(H), est le nombre de bits d�e�nis que comporte ce sch�ema.D�e�nition 2.2 Longueur d'un sch�emaLa longueur d'un sch�ema H, not�ee �(H), correspond �a la distance entre la premi�ere et laderni�ere position d�e�nie de ce sch�ema.Par exemple, avec H = 1 � � � 0�, on a : o(H) = 2 et �(H) = 4.Soit m(H; g) le nombre d'exemplaires du sch�ema H pr�esents �a la g�en�eration g dans lapopulation et f(H; g) (resp. f(g)) la moyenne des qualit�es des individus couverts par H(resp. la moyenne des qualit�es des individus de la population) �a la g�en�eration g. L'esp�erencedu nombre d'exemplaires du sch�ema H pr�esents �a la g�en�eration g + 1 dans la populationest donc : E(m(H; g+1)) = m(H; g):f(H;g)f(g) si l'on ne consid�ere que l'action de l'op�erateurde s�election, qui multiplie les instances des sch�emas proportionnellement �a leur forcerelative. Comme d'autre part la probabilit�e de survie d'un sch�ema H �a un croisement�a un point appliqu�e avec la probabilit�e pc est ps�1pt = 1 � pc: �(H)l�1 et que la probabilit�ede survie de H �a la mutation modi�ant chaque bit avec la probabilit�e pm est de ps� =(1 � pm)o(H) � 1 � o(H):pm (pour pm � 1) ; il est possible de minorer E(m(H; g + 1))en ne comptabilisant que les sch�emas dupliqu�es sous r�eserve qu'ils n'ont pas �et�e d�etruitspar l'application des op�erateurs g�en�etiques et en ignorant ceux qui sont �eventuellementcr�e�es lors de la g�en�eration de nouveaux individus. En approximant ps�1pt:ps� qui est de laforme (1� x):(1� y) par (1� x� y), on obtient le r�esultat du th�eor�eme 2.1.Th�eor�eme 2.1 (th�eor�eme des sch�emas)Soit H un sch�ema pr�esent en m(H; g) exemplaires dans Pg. L'esp�erance du nombre derepr�esentants de H dans la population �a la g�en�eration suivante de l'AGC v�eri�e :E(m(H; g + 1)) � m(H; g):f(H; g)f(g) :(1� pc:�(H)l � 1 � o(H):pm)

2.1. Les algorithmes d'�evolution 43Le th�eor�eme des sch�emas a suscit�e de nombreux travaux :L'hypoth�ese des blocs de constructiond�e�nit ces derniers comme les sch�emas de qualit�e sup�erieure �a la moyenne (f(H;g)f(g) >1), courts (�(H) petit) et comprenant peu de bits d�e�nis (o(H) petit). Puisque leth�eor�eme des sch�emas pr�evoit une croissance exponentielle des blocs de constructionau sein de la population, cette hypoth�ese postule (avec de nombreuses con�rmationsempiriques) qu'une performance quasi-optimale peut etre e�ectivement obtenue parcombinaison de sch�emas tr�es performants, courts, et d'ordre faible.Le parall�elisme implicitefait r�ef�erence �a un r�esultat d�emontr�e par Holland estimant (sous certaines hypoth�esesrelatives, entre autres, �a la taille de la population) que le nombre de sch�emas pris encompte utilement �a chaque g�en�eration par un algorithme g�en�etique travaillant surune population de n individus est de l'ordre de �(n3). Ce r�esultat conduit Holland�a conseiller l'utilisation d'un alphabet minimal (c'est-�a-dire binaire), argumentantque le nombre de sch�emas diminue lorsque la taille de l'alphabet d�e�nissant lesvaleurs potentielles des g�enes augmente. Cette argumentation est toutefois fortementcombattue : [Antonisse89] pr�ecise la notion de sch�ema sur les alphabets non binaireset montre que leur nombre ne diminue pas avec la taille de l'alphabet.La caract�erisation des probl�emes trompeurs(du point de vue du th�eor�eme des sch�emas) d�ecoule de la notion de comp�etitionentre sch�emas. Informellement, une fonction est dite trompeuse lorsque les blocs deconstruction courts et d'ordre faible se combinent en des blocs plus longs et d'ordre�elev�e sub-optimaux [Goldberg87].En�n, la strat�egie d'allocation exponentielle des ressources aux meilleurs sch�emas estjusti��ee par Holland sur l'�etude du probl�eme du bandit manchot �a deux (puis k) braspuisqu'il d�emontre que la strat�egie d'allocation optimale consiste �a donner un nombred'essais l�eg�erement plus qu'exponentiel au meilleur bras observ�e. De ce point de vue,l'AGC r�esoud le dilemme exploration versus exploitation puisqu'il maintient un �equilibrequasi-optimal du point de vue de la maximisation des qualit�es cumul�ees des individusg�en�er�es entre l'e�ort consenti �a l'exploration de nouvelles r�egions de l'espace de rechercheet l'exploitation des r�egions connues les plus prometteuses2. Cet argument est repris dans[De jong92] pour souligner la di��erence entre l'objectif d'une proc�edure d'optimisationclassique et ce qu'optimise r�eellement l'AGC.2Contrairement �a ce que l'on pourrait croire, le r�esultat concernant l'optimalit�e de la strat�egie de l'AGCpour la maximisation des qualit�es cumul�ees des individus (quelle que soit la fonction de qualit�e consid�er�ee)n'est pas en opposition avec le th�eor�eme de conservation (cf. section 1.2.3). En e�et, le maximum de laqualit�e cumul�ee des individus ne peut s'exprimer comme une fonction � de l'ensemble ordonn�e dm desm solutions distinctes examin�ees par l'AGC puisque dm ne permet pas de comptabiliser les �evaluationsmultiples.

44 CHAPITRE 2. ALGORITHMES D'�EVOLUTION POUR L'ASQuelques extensionsCompte tenu du nombre et de la vari�et�e des travaux concernant les algorithmes g�en�etiques,toute tentative de r�esumer ces derniers dans un espace raisonnable est vou�ee �a l'�echec.Les quelques lignes suivantes son destin�ees �a donner un avant-gout de certains travauxa�n de permettre un premier �elargissement du champ de vision du lecteur int�eress�e.Premi�eres variations sur l'algorithme g�en�etique canoniqueDe tr�es nombreuses d�eclinaisons des op�erateurs g�en�etiques ont �et�e propos�ees.La classique s�election proportionnelle �a la qualit�e mise en �uvre dans l'AGC peutetre compl�et�ee par des techniques de changement d'�echelle, c'est-�a-dire l'application detransformations du type f(I)! �:f(I)+� a�n de garantir une pression s�elective donn�ee.Les autres op�erateurs de s�election sont la s�election par tournoi de k individus, qui con-siste �a choisir pour chaque ajout le meilleur individu parmi k d�etermin�es al�eatoirementdans la population, et la s�election par le rang o�u la probabilit�e de s�electionner un indi-vidu ne d�epend plus de sa qualit�e mais d'une fonction (typiquement lin�eaire) de son rangdans la population. Chacun des op�erateurs de s�election d�ecrit ci-dessus peut etre utilis�ede mani�ere incr�ementale (steady state) ou g�en�erationnelle : contrairement �a la s�electiong�en�erationnelle, une s�election incr�ementale ne remplace qu'une partie (typiquement un in-dividu) de la population �a chaque g�en�eration. D'un point de vue plus th�eorique, [Baker87]analyse les op�erateurs les plus connus et propose deux op�erateurs de complexit�e �(n)minimisant les erreurs d'�echantillonnage a�n d'augmenter l'ad�equation entre le mod�eledu comportement de l'AG d�eriv�e du th�eor�eme des sch�emas et la r�ealit�e exp�erimentale.D'un point de vue pratique, les variations les plus populaires comprennent la s�election�elitiste, qui garantit la pr�esence des k meilleurs individus d'une g�en�eration sur l'autre(habituellement k = 1), et la s�election par �elevage (breeding), qui utilise un sch�ema clas-sique (roulette, tournoi, ...) n'op�erant que sur les k meilleurs individus (typiquement 10%de la population).En ce qui concerne les croisements, l'op�erateur utilisant un point de coupure a �et�eg�en�eralis�e tout d'abord au croisement �a n points de coupure (d�etermin�es al�eatoirement),puis au croisement uniforme [Syswerda89]. Ce dernier a l'avantage de supprimer toutenotion de localit�e dans les blocs de construction puisqu'il �echange les g�enes des parentsavec une probabilit�e �xe pe. La capacit�e du croisement uniforme de d�etruire les sch�emasne d�epend plus alors que de l'ordre des sch�emas, et non des positions des bits d�e�nis.Quelques autres travaux th�eoriquesLes vertus explicatives et pr�edictives du th�eor�eme des sch�emas ont montr�e de nombreuseslimites qui ont motiv�e d'autres travaux :{ il a pu etre constat�e que des fonctions comme royalroad [Mitchell et al.92], constru-ites pour etre facilement optimisables par les algorithmes g�en�etiques sont en r�ealit�eplus di�ciles que pr�evu ;{ r�eciproquement, certaines fonctions trompeuses se sont r�ev�el�ees en pratique faciles�a optimiser pour les algorithmes g�en�etiques ;

2.1. Les algorithmes d'�evolution 45Parent 2
Parent 1
Enfant 1
Enfant 2
croisement croisement àn (=2) pointsà un point
croisementuniforme
Fig. 2.5: Principaux croisements sur les chromosomes binaires de taille �xe.{ le th�eor�eme donne une borne inf�erieure au nombre de sch�emas dupliqu�es en n�egligeantles e�ets positifs de la mutation et du croisement (l'e�et disruptif est major�e et lapossibilit�e que le sch�ema soit g�en�er�e �a nouveau ignor�ee) ;{ puisque la qualit�e moyenne des individus de la population augmente lorsque l'algo-rithme g�en�etique progresse, l'hypoth�ese d'un ratio f(H;g)f(g) constant qui garantirait laduplication exponentielle des bons sch�emas est peu r�ealiste ;{ les erreurs d'�echantillonnage li�ees �a l'utilisation de populations de petite taille (parrapport �a la taille de l'espace de recherche) ainsi que la variance parfois importantede la qualit�e des individus couvrant un sch�ema donn�e peuvent causer des divergencesentre les comportements attendu et r�eel [Scha�er et al.91].Une premi�ere direction de recherche concerne la poursuite de l'analyse bas�ee sur leth�eor�eme des sch�emas : ainsi N.J. Radcli�e en a propos�e une version tr�es g�en�erale dans lecas d'un alphabet et d'op�erateurs quelconques en �etendant la notion de sch�ema �a la notionde classe d'�equivalence (appel�ee forma) induite par une relation d'�equivalence d�e�nie surles individus. Cette analyse est compl�et�ee par l'�enonc�e de principes caract�erisant d'unepart ce qu'est une bonne repr�esentation du point de vue des formae, et d'autre partl'ad�equation du couple (repr�esentation, op�erateurs) �a l'algorithme d'�evolution [Radcli�e91].Ces travaux ont �egalement permis en pratique la proposition et l'analyse d'op�erateurs tra-vaillant sur des objets tels que les multi-ensembles [Radcli�e92].Une seconde direction de recherche concerne l'�etude de la complexit�e g�en�etique d�eriv�eede la notion de probl�eme trompeur. Parmi les nombreux r�esultats, on notera [Wilson91]qui montre qu'il existe des fonctions AG-faciles qui ne sont pas faciles pour les m�ethodesde gradient, [Venturini95] qui montre que la r�eciproque est �egalement vraie, et [Whitley91]qui montre que les fonctions AG-di�ciles sont �egalement di�ciles pour les m�ethodes demont�ee (hill-climbing).Une derni�ere direction s'a�ranchit du cadre th�eorique de Holland. En e�et, de tr�esnombreuses m�ethodes ont �et�e appliqu�ees �a la mod�elisation des algorithmes g�en�etiques,qu'il s'agisse de simples droites de r�egression (cf. [Grefenstette95] o�u les droites Fe =� + �:Fp et �e(Fp) = �� + ��:Fp mod�elisent la qualit�e des enfants (Fe) �a partir de celledes parents (Fp), ce qui permet une simulation rapide du comportement de l'algorithmebas�ee sur une population virtuelle d'individus repr�esent�es uniquement par leur qualit�e),de mod�eles emprunt�es �a la physique statistique (a�n d'�etudier sur le plan macroscopique

46 CHAPITRE 2. ALGORITHMES D'�EVOLUTION POUR L'ASl'�evolution de grandeurs telles que la qualit�e moyenne des individus), ou encore de mod�elesexacts comme les cha�nes de Markov [Vose92] (il est possible de remarquer dans ce derniercas que chaque population �etant un �etat du syst�eme, le mod�ele associ�e �a l'�evolutiond'une population de taille �nie comporte Cn+2l�12l�1 � (2ln e)n �etats, ce qui rend ce type demod�elisation particuli�erement complexe).2.1.3 Les strat�egies d'�evolutionHistoriqueLes strat�egies d'�evolution [Rechenberg73] ont �et�e con�cues conjointement par Bienert,Rechenberg et Schwefel, ce dernier ayant proc�ed�e aux premi�eres implantations destin�eesaux applications �a des probl�emes d'optimisation num�erique. Contrairement aux algo-rithmes g�en�etiques, cette classe de m�ethodes ne pr�etend pas mod�eliser un quelconqueprocessus biologique : elle met en �uvre des processus it�eratifs simples, d�e�nis et analys�esrigoureusement, et destin�es d�es leur origine �a la r�esolution de probl�emes d'optimisationd�e�nis dans <n. Les paragraphes suivants d�ecrivent par ordre d'apparition chronologiqueles trois classes de strat�egies qui fondent ce domaine.La strat�egie (1 + 1)� ESLa premi�ere strat�egie, not�ee (1 + 1) � ES, travaillait sur un unique vecteur de n r�eelsauquel �etait appliqu�e une mutation, c'est-�a-dire une perturbation de chaque coe�cientd'�ecart-type �xe et de moyenne nulle. Le r�esultat obtenu �etait compar�e au parent, et lemeilleur des deux individus �etait conserv�e. Les premiers travaux th�eoriques de Rechenbergconcernant la convergence de la strat�egie (1 + 1) � ES sur deux types de fonctions luipermirent de proposer la r�egle dite du seuil des 1=5, qui estime �a 1=5 le ratio �s optimal demutations r�eussies. En cons�equence, lorsque �s > 1=5, il faut augmenter l'�ecart-type � del'op�erateur de mutation alors que lorsque �s < 1=5, il faut diminuer �. De plus Schwefelobtint, dans le cas o�u le mod�ele �a optimiser est une sph�ere, une valeur th�eorique pour lecoe�cient de modi�cation de � : c = 0; 8173.La strat�egie (�+ 1)� ESUn second sch�ema de s�election, introduisant la notion de population et l'op�erateur derecombinaison fut ensuite �etudi�e : la strat�egie (� + 1) � ES; � > 1, qui correspond �a las�election incr�ementale (steady-state) des algorithmes g�en�etiques, consiste �a recombiner �achaque �etape les � parents pour obtenir un individu qui, apr�es mutation, remplace le pire3Plus pr�ecis�ement, la r�egle exacte donn�ee par Schwefel est la suivante : Toutes les n mutations, comptercombien de succ�es ont �et�e observ�es au cours des 10:n derni�eres mutations. Si ce nombre est inf�erieur �a2:n, alors � 0; 85� �. Si ce nombre est sup�erieur �a 2:n, alors � �=0; 85. La constante c a en e�et�et�e corrig�ee de 0,817 �a 0,85 a�n de s'a�ranchir de la sp�eci�cit�e du mod�ele sph�erique, qui a tendance �an�ecessiter un pas d'adaptation assez important.

2.1. Les algorithmes d'�evolution 47parent de la population s'il lui est sup�erieur. La mutation et l'ajustement des �ecarts-typesproviennent de la (1+1)-ES strat�egie, alors que la recombinaison (not�ee rec, qui est vuecomme la composition d'un op�erateur de s�election des parents not�e co et d'un op�erateurde combinaison des parents not�e re : rec = re�co) peut appartenir �a l'un des quatre types! suivants :! = 0 Aucune recombinaisonOn a : co : I� ! I (s�election par tirage al�eatoire) et re : I ! I = Id.! = 1 Recombinaison globale interm�ediaireOn a : co : I� ! I� = Id (aucune s�election) et re : I� ! I o�u chaque coe�cient duvecteur r�esultat correspond �a la valeur moyenne des coe�cients des parents.! = 2 Recombinaison locale interm�ediaireOn a : co : I� ! I2 (s�election al�eatoire sexu�ee) et re : I2 ! I o�u chaque coe�cientci du vecteur r�esultat est obtenu �a partir des coe�cients c1i et c2i de ses parents par :ci = u:c1i + (1� u):c2i avec u 2]0; 1[ (en g�en�eral u = 12).! = 3 Recombinaison discr�eteOn a : co : I� ! I� = Id (aucune s�election) et re : I� ! I o�u chaque coe�-cient du vecteur r�esultat est d�etermin�e par tirage al�eatoire parmi les � coe�cientscorrespondant des parents.Les strat�egies (�+ �)� ES et (�; �)� ESFinalement, les strat�egies (� + �) � ES et (�; �) � ES, introduites par Schwefel, corre-spondent respectivement soit �a la survie des � meilleurs individus provenant de l'uniondes � parents et � enfants obtenus par recombinaison puis mutation, soit �a la s�electiondes � < � meilleurs enfants en remplacement de tous les parents. Hormis le sch�ema des�election, une di��erence fondamentale avec les strat�egies pr�ec�edentes provient du fait quel'individu manipul�e comporte non seulement les n coe�cients �a optimiser, mais �egalementles param�etres de l'op�erateur de mutation : les �ecarts-types s'auto-adaptent au cours dud�eroulement de l'algorithme. Plus formellement, un individu ~a est d�e�ni par :~a = (~x; ~�; ~�) 2 I = <n �<n�+ � [��; �]n�avec : n� 2 [1::n] et n� = (n�n�=2):(n��1). ~x = (x1; :::; xn) est le vecteur des coe�cients�a optimiser, ~� = (�1; :::; �n�) est le vecteur des variances associ�ees �a chaque coe�cient, et~� = (�1; :::; �n�) correspond au vecteur des covariances entre chaque couple de coe�cients(il s'agit donc d'une demi-matrice). A�n de limiter la taille du codage d'un individu ainsique le cout des calculs, le coe�cient n� peut etre inf�erieur �a n ; par exemple, choisir pourn quelconque :{ n� = 1 et n� = 0 permet de sp�eci�er une strat�egie simple mettant en �uvre ununique �ecart-type pour tous les coe�cients de ~x ;{ n� = n et n� = 0 sp�eci�e une strat�egie controlant un �ecart-type sp�eci�que �a chaquecoe�cient ;

48 CHAPITRE 2. ALGORITHMES D'�EVOLUTION POUR L'AS{ n� = 2 et n� = n � 1 correspond �a une strat�egie dont le premier coe�cient estassoci�e �a un �ecart-type sp�eci�que �1, �2 �etant l'�ecart-type associ�e �a tous les autrescoe�cients.∆ X2
X1∆
σσ
X1
x=(x1,x2)Lignes d’équi-probabilité de la
O
mutation.
α21
1
perturbation liée à l’opérateur de
X2
Fig. 2.6: Mutation auto-adaptative des strat�egie (�; �)�ES et (�+�)�ES pour n = 2.La �gure 2.6 illustre les di��erentes composantes de ~a dans un espace �a n = 2 dimensionsavec n� = 2.En notant N(�; �2) un tirage donn�e suivant la distribution normale de moyenne � et devariance �2, chaque nouvel indice Ni(�; �2) d�enotant un nouveau tirage, et �etant donn�esles param�etres � , � 0 et �, il est possible de d�e�nir la mutation de l'individu ~a (not�eemut(~a)) comme la compos�ee de trois op�erateurs modi�ant chacun une composante de ~a :mut(~a) = mux(~x;mu�(~�); mu�(~�)), avec :{ mu�(~�) = (�1:exp(� 0:N(0; 1) + �:N1(0; 1)); :::; �n� :exp(� 0:N(0; 1) + �:Nn�(0; 1))) ;{ mu�(~�) = (�1 + �:N1(0; 1) [��; �]4; :::; �n� + �:Nn�(0; 1) [��; �]) ;{ mux(~x) = (x1 + cor1(~�; ~�); :::; xn + corn(~�; ~�)).cori(~�; ~�) d�enote une composante al�eatoire obtenue par tirage suivant une distributionnormale comportant �eventuellement une partie corr�el�ee (cf. �gure 2.6, le lecteur trouverade plus amples d�etails dans [Back96]). Schwefel conseille d'utiliser : � � (q2pn)�1, � 0 �(p2:n)�1 et � � 0; 0873 (� 5o).La recombinaison r�eutilise les versions d�e�nies par ! 2 [0::3] pour la (� + 1) � ES surchacun des vecteurs ~x, ~� et ~� : on note (!1; n1; !2; n2; !3; n3) la recombinaison r�esultant de4Tous les angles �etant �a valeur dans [��; �], en cas de d�epassement une r�eduction modulo � este�ectu�ee.

2.1. Les algorithmes d'�evolution 49l'application de !1 �a ~x, !2 �a ~� et !3 �a ~�, chacune des composantes op�erant respectivementsur n1, n2 et n3 individus.

50 CHAPITRE 2. ALGORITHMES D'�EVOLUTION POUR L'ASSuite �a de nombreuses exp�erimentations, B�ack et Schwefel conseillent :{ l'utilisation de la (�; �)� ES ;{ un choix de � > 15 et d'un ratio �=� � 7 ;{ l'utilisation de la (3; �; 2; �; 0; 1)-recombinaison.2.1.4 La programmation �evolutionnaireLa programmation �evolutionnaire, introduite d�es 1962 par Fogel, se place dans lalign�ee des nombreux travaux de l'�epoque consacr�es �a la programmation automatique.Prenant acte des di�cult�es rencontr�ees par Friedberg qui essaie en 1958 de g�en�erer desprogrammes tr�es simples en langage machine (ce dernier introduit les notions cl�e de mu-tation et d'�evaluation sous les formes respectives d'un op�erateur permutant deux instruc-tions du programme ou modi�ant al�eatoirement l'une des instructions d'une part, et unsuccess number mesurant l'ad�equation des instructions a�n de controler le taux de mu-tation d'autre part), Fogel a pr�ef�er�e orienter sa recherche vers la pr�ediction s�equentiellede symboles �a l'aide d'automates d'�etats �nis repr�esent�es par des tables de transitions.Comme pour ce qui concerne les travaux de Friedberg, la mutation op�ere une modi�-cation al�eatoire de l'individu (la table des transitions), et la s�election correspond �a lavariante mise en �uvre dans la strat�egie d'�evolution (1+ 1)�ES. Un individu est �evalu�epar le pourcentage de lettres correctes de la s�equence qu'il r�eussit �a pr�edire. De memeque les premi�eres strat�egies d'�evolution, et contrairement aux algorithmes g�en�etiques, laprogrammation �evolutionnaire ne met pas en �uvre de m�ecanisme de recombinaison.L'ampleur des di�cult�es rencontr�ees ainsi que les raisons de l'abandon dans les ann�ees 70de la programmation �evolutionnaire ont �et�e diversement appr�eci�ees et analys�ees : selonD.E. Goldberg, l'ampleur de ce qu'il pr�esente comme un �echec fut tel qu'il desservit�egalement le d�eveloppement des algorithmes g�en�etiques �a leurs d�ebuts : The rejectionof this work by the arti�cial intelligence community, more than any other single factor,was responsible for the widespread skepticism faced by more schema-friendly genetic algo-rithms of the late 1960s and mid-1970s. ([Goldberg89], p.105), et la raison des di�cult�esrencontr�ees par Fogel provient, toujours d'apr�es lui, de l'absence de croisement : The evo-lutionary programming of Fogel (.../...) was insu�ciently powerful to search other thansmall problem spaces quickly. We turn away from these and similar studies that ignore thefundamental importance of structure recombination (.../...) ([Goldberg89], p.106). L'-analyse de T. B�ack est beaucoup plus nuanc�ee : les di�cult�es rencontr�ees par Friedberg au-raient caus�e en partie l'ignorance des travaux de Fogel, et d'autre part ces derniers seraientvenus trop tot compte tenu des puissances de calcul extremement modestes disponibles �al'�epoque ([Back96], p. 59). Vers la �n des ann�ees 80, D.B. Fogel reprit les travaux de sonp�ere dans le but de les appliquer aux probl�emes d'optimisation de param�etres continus :les m�ethodes propos�ees sont tr�es similaires aux strat�egies d'�evolution puisqu'elles mettenten place des m�ecanismes d'auto-adaptation bas�es sur l'ajustement des variances et des

2.1. Les algorithmes d'�evolution 51covariances des param�etres.2.1.5 La programmation g�en�etiqueHistoriqueLa programmation g�en�etique (PG) a �et�e propos�ee par J.R. Koza [Koza89, Koza92] dansle but de travailler sur des structures directement utilisables par la machine et (si possibleapr�es simpli�cation) compr�ehensibles par l'homme. En particulier, ces travaux permettentla lev�ee des contraintes de repr�esentation (codage des individus sous forme de cha�nesbinaires de taille �xe) rencontr�ees dans le cadre de la version canonique des algorithmesg�en�etiques. Bien qu'il soit possible de trouver les racines de la programmation g�en�etiqued'une part dans la programmation �evolutionnaire quand �a sa probl�ematique, et d'autrepart dans le langage TB [Cramer85] quand �a la repr�esentation utilis�ee, Koza est reconnucomme le fondateur de ce domaine car il en a pos�e le cadre (en insistant �a la fois sur lessimilitudes et les di��erences entre PG et AG) et a contribu�e �a son d�eveloppement par des�etudes syst�ematiques sur un tr�es grand nombre de probl�emes. Plutot que d'apprendre desautomates d'�etats �nis, les travaux de Koza se sont initialement port�es vers le langageLISP pour les raisons suivantes :{ tous les objets LISP (programmes et donn�ees) sont des S-expressions, c'est-�a-diredes listes syntaxiquement correctes qui peuvent �egalement etre repr�esent�ees sousforme d'arbres ;{ LISP n'est pas un langage typ�e et par cons�equent impose peu de contraintes surles op�erateurs manipulant les programmes, du moment que des contraintes de basetelles que le respect de l'arit�e des fonctions sont v�eri��ees ;{ la manipulation des listes est extremement ais�ee ; de plus les programmes obtenuspeuvent etre imm�ediatement �evalu�es (aucun m�ecanisme de compilation n'est n�ecessaire).Espace de rechercheEn pratique, l'utilisateur doit sp�eci�er :{ l'ensemble T des terminaux (c'est-�a-dire les symboles de constantes et de variablesdu langage) ;{ l'ensemble F des fonctions primitives : F = Sni=1 fi est l'ensemble des symboles defonction ; on notera jfij l'arit�e de la fonction fi ;{ la profondeur maximale des arbres (il s'agit de l'un des param�etres de l'algorithme,cf. par exemple [Koza92] p. 114).

52 CHAPITRE 2. ALGORITHMES D'�EVOLUTION POUR L'ASA�n de permettre les g�en�erations stochastiques d'expressions et les recombinaisons, cesensembles doivent v�eri�er l'hypoth�ese de cloture, sp�eci�ant que toute combinaison syn-taxiquement correcte d'�el�ements de F et T est correcte et �evaluable. Par exemple, dansle cas d'un probl�eme relatif �a la d�ecouverte d'une loi num�erique liant trois variables a,b et c, l'utilisateur pourrait choisir F = f+;�; �; =; sin; cos;pg et T = fa; b; c;<g o�u <d�enote l'ensemble des r�eels pouvant etre repr�esent�es sur la machine. A�n de respecter lapropri�et�e de cloture, certaines des fonctions devront etre �etendues : x ! px sera ainsiremplac�ee par x ! qjxj et (x; y)! x=y sera d�e�nie en y = 0 en posant x=0 = 1.Op�erateursLe croisement et la mutation, qui proviennent des algorithmes g�en�etiques, ont �et�e adapt�esaux structures arborescentes. Comme le montre la �gure 2.7, le croisement consiste �a�echanger deux sous-arbres appartenant chacun �a un parent : si la propri�et�e de cloture estrespect�ee, les deux arbres r�esultant seront bien des S-expressions s�emantiquement valides.Les points de coupure (repr�esent�es par des traits gras) sont d�etermin�es suivant une loifavorisant les liens de profondeur faible. La mutation (qui est volontairement omise parcos
b
cos
b
*
/
cc
2
+
*
/2
cos
b
cc
+sin
-
sin*
cos a
b
0
sin
-
sin*
a0
Fig. 2.7: Exemple de croisement en programmation g�en�etique.Koza dans un grand nombre d'exp�erimentations) modi�e localement un individu en rem-pla�cant un n�ud choisi au hasard par un sous-arbre g�en�er�e al�eatoirement, en changeantun symbole de fonction par un autre de meme arit�e ou en modi�ant un symbole terminal.De nombreuses exp�erimentations sont �a l'origine de certains choix concernant les autresop�erateurs d'�evolution :{ Koza pr�econise l'utilisation d'un sch�ema de s�election ad-hoc copiant sans modi�ca-tion 10% des individus choisis suivant une probabilit�e proportionnelle �a leur qualit�e.Exp�erimentalement, les s�elections peu sensibles �a la performance absolue commepar exemple la s�election par tournoi, bas�ee uniquement sur l'ordre des individus,

2.1. Les algorithmes d'�evolution 53donnent �egalement de bons r�esultats.{ La variance de la qualit�e des individus g�en�er�es al�eatoirement lors de la cr�eation de lapopulation initiale pouvant etre tr�es importante, un m�ecanisme appel�e d�ecimationempeche dans un premier temps la duplication des meilleurs individus a�n d'�eviterque ces derniers ne provoquent la convergence pr�ematur�ee de l'algorithme.Comportement exp�erimentalLa quasi-totalit�e des travaux concernant la programmation g�en�etique �etant de natureapplicative et exp�erimentale, peu de r�esultats th�eoriques sont disponibles (la pluparts'attachent �a reprendre le th�eor�eme des sch�emas). Cependant, il est possible de d�egagerexp�erimentalement trois grandes caract�eristiques de cette approche.La premi�ere a trait �a la sensibilit�e de l'algorithme au choix des fonctions primitives ainsiqu'�a d'autres param�etres li�es �a la taille de l'espace de recherche, comme par exemple laprofondeur maximale autoris�ee des arbres. Par exemple [BT et al.96], qui proc�ede �a une�etude syst�ematique pour �evaluer et comprendre le role des param�etres-cl�e en programma-tion g�en�etique dans le domaine de la classi�cation par induction d'hypersurfaces, remarqueque l'algorithme est tr�es sensible �a l'ajout de nouvelles primitives, et encore plus au choixde la fonction de qualit�e (les tests ont port�e sur un crit�ere entropique et une fonction decout quadratique). Par contre, l'ajout de variables non pertinentes, la complexit�e de laformule-cible ou encore l'introduction de constantes ont peu d'incidence sur la qualit�e desr�esultats.La seconde caract�eristique concerne l'augmentation de la taille des individus au fur et �amesure du d�eroulement de l'�evolution, par opposition aux autres m�ethodes qui travaillentsur des structures de taille �xe. Cet accroissement de la complexit�e des individus est lasource de nombreux inconv�enients que ce soit du point de vue de la quantit�e de m�emoirerequise, du temps d'�evaluation des individus ou de la compr�ehensibilit�e pour l'utilisateur ;il a conduit au d�eveloppement de plusieurs techniques allant de la manipulation directedu langage machine �a la compression des arbres �a l'aide de graphes acycliques orient�es.Cette derni�ere m�ethode, combin�ee �a la m�emorisation au niveau des n�uds du graphedes r�esultats des �evaluations, s'est r�ev�el�ee extremement e�cace en espace et en temps[Ehrenburg96].La derni�ere caract�eristique de la programmation g�en�etique, fortement li�ee �a l'augmenta-tion de la taille des arbres, est la cr�eation dynamique d'introns. Par analogie avec sonhomologue biologique, l'intron arti�ciel correspond �a un segment non codant du chro-mosome et permettrait d'att�enuer l'aspect destructeur du croisement (la �gure 2.7 endonne un exemple d�elimit�e en pointill�es). De ce point de vue, l'accroissement de la tailledes arbres (qui correspond exp�erimentalement �a l'apparition d'introns), correspondrait�a un ajustement dynamique des structures destin�e �a favoriser la conservation des par-ties performantes. Cette hypoth�ese a �et�e valid�ee exp�erimentalement : [Haynes96] montre

54 CHAPITRE 2. ALGORITHMES D'�EVOLUTION POUR L'ASque la destruction des introns par l'utilisation d'une proc�edure de simpli�cation des ar-bres provoque une d�egradation tr�es importante des performances due �a la convergencepr�ematur�ee de l'algorithme, alors que la diminution du taux des individus simpli��es per-met de revenir �a la performance optimale (lorsque ce taux est nul). En cons�equence, laproc�edure de simpli�cation d'arbres �a l'aide de r�egles de r�e�ecriture de type (* 0 X) )0 d�ecrite par Koza [Koza92] ne doit etre appliqu�ee que pour des raisons d'intelligibilit�eune fois le r�esultat �nal obtenu, et non au cours de l'�evolution.Quelques variationsDeux extensions fort utiles de la m�ethode de base doivent etre mentionn�ees. La premi�ereconcerne la suppression de l'hypoth�ese de cloture �a l'aide d'un typage fort permettant�egalement la prise en compte des types g�en�eriques [Montana95]. Cette extension a �et�ecompl�et�ee dans [Haynes et al.96] par la gestion des hi�erarchies de types et des typespolymorphes. La seconde extension concerne la d�ecouverte automatique de proc�edures(ADFs, [Koza92, Koza94]) qui sont autant de blocs de construction interm�ediaires fa-cilitant la compr�ehension. Les proc�edures sont particuli�erement importantes lorsque lasolution du probl�eme a une forte structure hi�erarchique : il n'est pas envisageable d'aug-menter la taille maximale des arbres dans une proportion qui permettrait la d�ecouvertede la fonction d�evelopp�ee car la taille de l'espace de recherche serait alors beaucoup tropimportante.2.2 Algorithmes d'�evolution et apprentissage automa-tiqueComme l'a montr�e le chapitre 1, l'apprentissage automatique supervis�e peut etre for-mul�e comme un probl�eme d'optimisation dans l'espace des r�egles. Puisque d'autre partles algorithmes d'�evolution se sont av�er�es utiles et performants dans le domaine de l'op-timisation, il n'est pas �etonnant que de nombreux syst�emes d'apprentissage bas�es surces algorithmes aient vu le jour. La grande majorit�e des travaux du domaine sont ini-tialement apparus dans la communaut�e des algorithmes g�en�etiques dont le champ d'in-vestigation �etait particuli�erement large ; le d�eveloppement peu important de la program-mation �evolutionnaire, la sp�eci�cation du cadre d'application des strat�egies d'�evolutionaux probl�emes d'optimisation de param�etres r�eels, et �nalement la relative adaptation ducodage binaire �a la repr�esentation de r�egles symboliques ont �egalement contribu�e �a cet�etat de fait. L'apparition (bien plus tard) de la programmation g�en�etique, dont le biais derepr�esentation est encore plus adapt�e �a l'expression de formules complexes, a �et�e la sourcede nombreux autres travaux dans le domaine de l'apprentissage.Historiquement, deux courants correspondant �a deux mani�eres d'envisager l'apprentissage�a l'aide des algorithmes g�en�etiques ont vu le jour �a la meme p�eriode, et d�e�nissent de faitune dichotomie encore utilis�ee pour caract�eriser les syst�emes [Venturini96] :

2.2. Algorithmes d'�evolution et apprentissage automatique 55{ L'approche de Michigan a �et�e propos�ee par Holland [Holland86] et consid�ere quel'ensemble de la population repr�esente une base de connaissances, chaque individucorrespondant �a une r�egle particuli�ere. Le r�esultat de l'apprentissage est alors unsous-ensemble d'individus de la population. Cette approche a donn�e naissance auxsyst�emes de classeurs.{ L'approche de Pittsburgh [Smith83] utilise au contraire l'algorithme g�en�etique en seconformant au cadre des nombreux travaux appliqu�es �a l'optimisation : le meilleurindividu issu de l'�evolution doit fournir la connaissance recherch�ee. En cons�equence,dans le cas o�u le concept-cible peut etre disjonctif, chaque individu code un ensemblede r�egles.Les deux sections ci-dessous sont respectivement consacr�ees �a la description des syst�emesde classeurs (approche de Michigan), puis du syst�eme GABIL qui est l'un des repr�esentantsles plus connus de l'approche de Pittsburgh. La troisi�eme section traite des travaux con-cernant la programmation g�en�etique, et les deux derni�eres d�ecrivent SIA ainsi que REGALet G-Net.2.2.1 Approche de Michigan - Les syst�emes de classeursLa probl�ematique de l'animatLes syst�emes de classeurs (SC), [Holland86] sont des syst�emes d'apprentissage automa-tique incr�ementaux qui apprennent dynamiquement des r�egles de comportement sousforme de cha�nes binaires. Ils ont �et�e d�evelopp�es a�n de r�epondre au probl�eme de l'appren-tissage adaptatif en environnement dynamique : le syst�eme est capable de s'auto-modi�erau cours du temps a�n de mieux s'adapter �a son environnement. Les SC se di��erencientdonc du cadre classique de l'apprentissage supervis�e par plusieurs points :{ aucun oracle (ou professeur) n'est disponible pour fournir le comportement souhait�e :l'apprentissage est non supervis�e ;{ l'environnement sur lequel agit le syst�eme (et dont il re�coit des stimuli) peut varier :l'apprentissage, qui se fait par renforcement, doit etre �egalement adaptatif.On parle alors de la probl�ematique de l'animat [Wilson85, Wilson87], qui d�esigne un robotautonome dont la raison d'exister est la survie dans son environnement [Venturini94b,Wilson99].StructureComme le montre la �gure 2.8, un syst�eme de classeurs est constitu�e :{ D'une liste de messages (cha�nes binaires de taille �xe) d'entr�ee et de sortie.

56 CHAPITRE 2. ALGORITHMES D'�EVOLUTION POUR L'ASEnvironnement
Actions
Messagesde sortie
Effecteurs
Liste des messages
Récompenses Détecteurs
Informations
Messagesd’entrée
Système de classeurs
des règlesd’évaluationAlgorithme
Algorithmegénétique
010110100110111011
101011001001110110
Population de règles
( #10##1 , 101101 , 50 )
( 0####0 , 010111 , 70 )( ##10#1 , 001101 , 30 )
Fig. 2.8: Contexte d'application et structure interne d'un syst�eme de classeurs.{ D'une population de r�egles, appel�ees classeurs, de la forme \( condition, action,force )" o�u condition est une cha�ne de taille �xe d�e�nie sur l'alphabet f0,1,#g,action est une cha�ne binaire de taille �xe, et force est un nombre r�eel. Le caract�ere#, qui peut appara�tre dans la partie condition du classeur, joue le meme role que* pour les sch�emas.{ D'un algorithme d'�evaluation de la qualit�e des r�egles r�epartissant les r�ecompenses(ou les p�enalit�es) associ�ees aux actions entreprises.{ D'un algorithme g�en�etique optimisant la population de r�egles a�n d'am�eliorer etd'adapter constamment les comportements.Fonctionnement g�en�eralLe cycle de fonctionnement d'un SC d�ebute par la r�eception puis l'ajout dans la listecorrespondante des messages provenant des d�etecteurs. Ces messages peuvent d�eclencherdes classeurs dont la partie action, ajout�ee dans la liste des messages, peut elle-memed�eclencher d'autres classeurs : contrairement �a des m�ethodes telles que les syst�emes ex-perts, l'activation des r�egles a lieu en parall�ele. Une fois que le syst�eme de gestion desmessages a converg�e vers un �etat stable (c'est-�a-dire lorsque plus aucun classeur ne peutetre d�eclench�e), les messages restants sont envoy�es aux e�ecteurs, et la r�ecompense (ou la

2.2. Algorithmes d'�evolution et apprentissage automatique 57p�enalit�e) provenant de l'environnement est partag�ee par les classeurs concern�es. L'appren-tissage, destin�e �a introduire de nouveaux classeurs (potentiellement plus performants), estr�ealis�e par un algorithme g�en�etique soit �a intervalles r�eguliers, soit lorsque les performancesdu syst�eme d�eclinent. A�n de ne pas modi�er radicalement la base de r�egles au risque ded�egrader les performances du SC, l'algorithme ne remplace qu'une partie de la population.L'�evaluation des classeurs est fond�ee sur leur force.

58 CHAPITRE 2. ALGORITHMES D'�EVOLUTION POUR L'ASAlgorithme d'allocation des cr�editsLa m�ethode initiale, connue sous le nom de bucket brigade, a �et�e propos�ee par Holland. LeSC est vu comme un syst�eme �economique dans lequel les classeurs ach�etent et vendent del'information : �a chaque �etape un classeur paie, en c�edant une partie de sa force �a l'objetl'ayant d�eclench�e, le droit de placer un message dans la liste suivant la loi :Si(t+ 1) = Si(t) +Ri(t)� Pi(t)� Ti(t)o�u Si d�enote la force du classeur i consid�er�e, Ri les r�ecompenses re�cues des classeursd�eclench�es par i ou re�cues de l'environnement, Pi = �:Si(t) la force c�ed�ee par i dans lecas o�u il a �et�e d�eclench�e et a �emis un message. Ti(t) = �:Si(t) correspond �a un termefacultatif (une taxe) destin�e �a p�enaliser les r�egles improductives. La �gure 2.9 d�etailleClasseurs Listedes Messages Gachettes Ench�eres Forces Listedes Messages Gachettes Ench�eres Forces Listedes Messages Gachettes Ench�eres Forces Listedes Messages �nale Forcesapr�es renforcement(11#; 001; 50) 111 � 5 45 001 55 000 55 55(0#1; 000; 50) 50 � 5 45 101 50 50(00#; 101; 50) 50 � 5 45 � 5 40 101 65Environnement 5Fig. 2.9: D�eroulement d'un cycle de l'algorithme bucket brigade.le fonctionnement de l'algorithmes bucket brigade sur une population de trois classeurs,avec un coe�cient d'ench�eres � = 0; 1 et un taux d'imposition � = 0. Supposons queles d�etecteurs aient re�cu de l'environnement un stimulus qui se traduise par le d�epot dumessage 111 dans la liste des messages. Puisque 111 ne v�eri�e que la premi�ere des troisconditions 11#, 0#1, et 00#, seul le premier classeur est activ�e (ce qui est repr�esent�epar une croix en face de ce dernier dans la colonne Gachettes ). Le premier classeur paiedonc 50 � 0; 1 = 5 unit�es de force �a l'environnement a�n de placer son message (001)dans la liste des messages du tour suivant. Au second tour, l'unique message 001 activedeux classeurs qui r�emun�erent chacun de 5 unit�es le classeur �emetteur. La propagation-consommation des messages se poursuit jusqu'�a ce qu'il ne reste plus aucun classeur�a activer. Le message restant (101) est alors envoy�e aux e�ecteurs. En supposant quel'action sur l'environnement se traduise par une r�ecompense de 25 unit�es, cette derni�eresera attribu�ee au classeur qui avait post�e ce message : le troisi�eme classeur voit donc saforce augmenter de 40 �a 65.

2.2. Algorithmes d'�evolution et apprentissage automatique 592.2.2 Approche de Pittsburgh - GABILGABIL [De jong et al.93, De jong et al.91] est un exemple r�ecent de syst�eme suivantl'approche de Pittsburgh. Ce dernier apprend un concept bool�een repr�esent�e sous la formed'un ensemble disjonctif de r�egles propositionnelles. L'algorithme de recherche est en toutpoint similaire �a un algorithme g�en�etique, sauf en ce qui concerne le codage des individus :si celui-ci est bien binaire, la n�ecessit�e de pouvoir repr�esenter des concepts disjonctifs(c'est-�a-dire une disjonction d'un nombre quelconque de r�egles) a conduit �a l'utilisationde cha�nes binaires de taille variable.Repr�esentation des formulesLa �gure 2.10 d�etaille le g�enotype et le ph�enotype d'un individu compos�e de r = 2 r�eglesdans le cas d'un domaine comprenant n = 2 attributs Taille et Couleur �a valeur dansfpetit; grandg et frouge; bleu; vertg.Taille Couleur Taille Couleur Classe
0 1 1 0 10 1 1 1 11Si [(Taille = petit) ^ (Couleur = bleu _ vert)] _ [(Taille = grand)] Alors Classe = 1Fig. 2.10: Repr�esentation d'un individu dans GABIL.�A chaque attribut Ai est associ�ee une sous-cha�ne ai = [b1; :::; bjAij] dont chaque bit cor-respond �a l'une des jAij valeurs possibles. Un bit �a 0 d�enote l'absence de la valeur corre-spondante dans la disjonction, et 1 sa pr�esence. Lorsque tous les bits sont �a 0 ou �a 1, letest portant sur l'attribut correspondant est abandonn�e. Toutes les r�egles Rj partagentle meme patron PR, r�esultant de la concat�enation dans un ordre �x�e des sous-cha�nes detous les attributs : PR = [a1; :::; an]. Pour �nir, l'individu est obtenu en concat�enant auxr�egles qui le composent un bit codant sa classe.Op�erateurs g�en�etiquesLa mutation correspondait initialement �a l'op�erateur canonique proc�edant par modi�ca-tion d'un bit avec la probabilit�e pm. Elle a �et�e ensuite d�eclin�ee sous deux formes im-plantant deux r�egles provenant de [Michalski84]. La mutation �a tendance g�en�eralisatriceop�ere, lorsqu'elle est d�eclench�ee, un changement de bit de 0 �a 1 avec une probabilit�e de0; 75, et le changement inverse avec une probabilit�e de 0; 25 seulement. Elle correspond �aune version probabiliste des r�egles d'ajout et de suppression d'alternative. La mutationpar abandon choisit un attribut dont la majorit�e des bits sont �a 1 et remplace tous lesbits restant par des 1 : il s'agit donc de l'op�erateur de g�en�eralisation abandonnant unecondition.Contrairement au croisement �a un point standard, l'op�erateur de recombinaison de GABIL

60 CHAPITRE 2. ALGORITHMES D'�EVOLUTION POUR L'ASpermet l'ajout ou la suppression de r�egles : un point de coupure est d�etermin�e sur chacundes parents de telle sorte que les deux points soient s�emantiquement compatibles (c'est-�a-dire situ�es entre les memes attributs), puis les deux sous-cha�nes sont �echang�ees (�gure2.11). Bien que ce m�ecanisme garantisse localement (ie. lors de l'application de l'op�erateur)la conservation de l'espace m�emoire, la possibilit�e de dupliquer lors de la s�election lesindividus les plus longs peut occasionner, tout comme dans le cas de la programmationg�en�etique, une augmentation de l'espace m�emoire n�ecessaire au d�eroulement du processusd'apprentissage.Point de coupure 1
Point de coupure 2
1 0 1 1
0 0 1 0 0 1 0 11 1 0 1 1 1 1 1
0 11 0 00 1 0
00
001 1 1 0 1 1 11 1
0 1 1
Fig. 2.11: Op�erateur de recombinaison de GABIL.Fonction de qualit�eSoit p le pourcentage d'exemples correctement class�es par l'individu I ; la fonction dequalit�e est d�e�nie par : f(I) = p2Ce choix minimaliste provient de la volont�e de combiner de mani�ere tr�es simple les aspectsde coh�erence et de compl�etude sans introduire de biais li�es �a la longueur des individus ou�a leur complexit�e.2.2.3 SIASIA (Symbolic Inductive Algorithm) [Venturini93, Venturini94a, Venturini94b] con-stitue le point de r�ef�erence initial �a partir duquel SIAO1 a �et�e d�evelopp�e. Ce syst�eme,dont la premi�ere application concerne l'analyse de donn�ees judiciaires, a �et�e construit avecles objectifs suivants :{ analyser des donn�ees r�eelles : l'expert veut obtenir des connaissances intelligibles �apartir de donn�ees pouvant etre bruit�ees ;{ certains descripteurs sont symboliques et d'autres num�eriques ;

2.2. Algorithmes d'�evolution et apprentissage automatique 61{ les exemples peuvent etre de taille variable (ils contiennent de nombreuses valeursinconnues).Ce syst�eme se distingue par son codage non binaire, puisqu'�a chaque attribut est as-soci�e un g�ene repr�esentant le domaine de g�en�eralisation. Cette repr�esentation �a l'avantagede permettre des traitements de haut niveau provenant non du cadre de l'optimisa-tion dans un espace binaire mais du domaine plus sp�eci�que de l'apprentissage supervis�esymbolique et num�erique. Ainsi, l'op�erateur de mutation, qui est ici un op�erateur deg�en�eralisation, peut utiliser des connaissances du domaine sous la forme de hi�erarchiessur les constantes symboliques.D'autre part, SIA met �a la disposition de l'utilisateur (qui est suppos�e etre un expertdu domaine et non un expert en analyse de donn�ees) un petit nombre de param�etressimples lui permettant d'adapter l'algorithme �a ses besoins : outre les hi�erarchies re �etantles connaissances du domaine, il est possible de pond�erer les exemples et de sp�eci�er desbiais intelligibles tels que la pr�ef�erence de r�egles plutot g�en�erales ou plutot e�caces ainsiqu'une estimation du taux de bruit de la base.Repr�esentation des formulesLe codage des r�egles est r�ealis�e en associant �a chaque attribut Ai, i 2 [1; n], un g�enepouvant repr�esenter ses di��erentes g�en�eralisations dans le langage-cible. Ces derni�erescomprennent l'ensemble des intervalles convexes couvrant le noyau dans le cas des attributsnum�eriques et les successeurs dans la hi�erarchie des constantes (* compris) dans le casdes attributs symboliques. �A chaque attribut num�erique est ainsi associ�ee une paire der�eels (le plus petit intervalle le contenant), et �a chaque attribut symbolique une cha�nede caract�eres. SIA apprend des r�egles de la forme r = (a; C; f) o�u a = fa1; :::; ang est unvecteur codant les domaines des attributs, C est la classe sur laquelle conclut la r�egle, etf sa force : Si NBPERS 2 [1.5,2.5]r = et NATIO = fran�caisealors MOTCLASS = sans suite (f = 207)Chaque exemple est de la forme ex = (e; CL; p) o�u e est un vecteur codant les valeurs desattributs, CL est la liste des classes auxquelles ex appartient et p est le poids de l'exemple.Traitement des valeurs inconnuesDans la perspective d'ad�equation de l'algorithme aux probl�emes du monde r�eel, SIA o�reun m�ecanisme sophistiqu�e de traitement des valeurs inconnues en les subdivisant en troistypes :{ Une valeur est dite manquante (et d�enot�ee par ?) lorsque la valeur de l'attributconsid�er�e est d�e�nie mais n'a pas �et�e report�ee dans la base. Par exemple, dans lecas d'une application m�edicale, il est possible que l'�etat du patient ou la dur�ee de

62 CHAPITRE 2. ALGORITHMES D'�EVOLUTION POUR L'AScertains examens rendent impossible l'obtention d'une partie des donn�ees au momento�u le syst�eme d'aide �a la d�ecision doit fournir sa r�eponse.{ Une valeur indi��erente (not�ee *) est une valeur manquante dont l'omission est volon-taire de la part de l'analyste qui postule que la valeur de l'attribut n'a aucune im-portance dans le cas de l'instance d�ecrite. Par exemple, il est possible de supposerque la nationalit�e d'une personne ayant commis de nombreux crimes n'aura au-cune importance sur la d�ecision du tribunal, ce qui �evite �a l'expert de rechercherl'information dans le dossier.{ Les valeurs non d�e�nies (not�ees #) correspondent aux cas o�u la valeur de l'attributn'a aucune signi�cation pour l'instance consid�er�ee. Par exemple, l'attribut codant lanationalit�e des dossiers sans auteur n'a aucune signi�cation et n'est donc pas d�e�nipour de telles instances.L'importance de la distinction faite au niveau s�emantique entre les di��erents types devaleurs inconnues provient du constat que les algorithmes qui prennent en compte de tellesvaleurs transforment la base d'apprentissage5 �a l'aide de strat�egies qui induisent toutesun certain nombre d'inconv�enients (voir tableau 2.1).Par opposition, la m�ethode mise en �uvre dans SIA consiste �a :{ conserver, sans aucune modi�cation, les valeurs non d�e�nies dans la base ;{ inclure la s�emantique des valeurs non d�e�nies dans la fonction d'appariement ;{ s'aider de cette meme s�emantique lorsqu'une r�egle est g�en�er�ee �a partir d'un noyaucontenant des valeurs non d�e�nies.En cons�equence, l'appariement est restreint aux attributs connus ainsi qu'au symbole *(qui couvre tout symbole et n'est couvert que par lui-meme).? et # ne �gurent pas dansles r�egles et ne peuvent etre couverts que par *. La cr�eation des noyaux est d�etaill�ee auparagraphe d�ecrivant les op�erateurs g�en�etiques.Traitement des valeurs num�eriquesLes valeurs num�eriques sont conserv�ees telles quelles dans les exemples. De plus, aucunpr�e-traitement (discr�etisation, analyse statistique) n'est utilis�e pour restreindre l'espacede recherche : il existe autant de seuils d�e�nissant les domaines qu'il y a de valeursnum�eriques, et le processus d'apprentissage se charge de d�ecouvrir quelles sont les valeurssigni�catives. Si fv1; :::; vmg sont les valeurs rencontr�ees pour un attribut num�erique, alors5Ils peuvent le faire de mani�ere indirecte par un traitement qui est �equivalent �a une r�e�ecriture. Parexemple C4.5 adopte une strat�egie dynamique qui est une variante du pr�e-traitement remplacer? parla valeur la plus probable dans l'�echantillon d'apprentissage compl�et�ee par une diminution du poids del'exemple consid�er�e a�n de minorer son in uence lors du calcul de l'entropie.

2.2. Algorithmes d'�evolution et apprentissage automatique 63Strat�egie Cons�equenceSupprimer les instances Perte d'informations. De plus certaines bases peuventcontenant des valeurs comporter au moins une valeur non d�e�nie parnon d�e�nies. instance.La r�egle \Si NBPERS = ? et NATIO = fran�caise ..."Remplacer ? par la peut etre transform�ee en \Si NBPERS = 0 etvaleur la plus probable. NATIO = fran�caise ...", d'o�u un probl�eme des�emantique.La signi�cation d'une r�egle telle que \Si NBPERS = ?Traiter ? comme un alors ..." (si elle existe) d�epend du domaine et de lanouveau symbole de technique de r�ecolte des donn�ees. De plus, cetteconstante d�e�nie. strat�egie ne peut etre appliqu�ee au cas des attributsnum�eriques.Le cout en espace du �a la duplication des instancesRemplacer * par toutes ainsi que leur poids peuvent rendre l'apprentissageles valeurs possibles. impossible (n valeurs indi��erentes de modalit�e micausent un facteur de duplication de Qni=1mi ).Un arbre d'h�eritage d'attributs doit pouvoir etreR�epartir les exemples d�e�ni sur le domaine. La segmentation peut conduiresuivant # [Brunet93]. �a des r�esultats contradictoires sur les sous-ensemblesainsi qu'�a une perte de con�ance statistique.Tab. 2.1: Inconv�enients des strat�egies classiques de traitement des valeurs non d�e�nies.les bornes potentielles associ�ees sont : f�1; v1+v22 ; :::; vm�1+vm2 ;+1g.Fonction de qualit�eLa qualit�e d'une r�egle R est d�e�nie par :Q(R) = max(BC(R)� �:MC(R) + �:g(R) + :e(R)BCmax ; 0)Elle cro�t (resp. d�ecro�t) proportionnellement �a la somme des poids, not�ee BC (resp.MC),des exemples bien class�es (resp. mal class�es) par R. BCmax correspond �a la somme despoids des exemples de la classe sur laquelle conclut R. g(R) est une mesure de la g�en�eralit�edeR �a valeur dans [0; 1] de la forme g(R) = 1nPni=1 gi, o�u gi d�enote la g�en�eralit�e du domaineai de R relatif �a l'attribut Ai. e(R) mesure l'explicabilit�e de R pour l'utilisateur qui peutd�e�nir pour ce faire des poids p1; :::; pn caract�erisant la pr�ef�erence accord�ee aux attributs.Les propri�et�es de la fonction de qualit�e sont reli�ees aux trois param�etres �, � et ajusta-bles par l'utilisateur :{ Si � et sont n�egligeables devant 1, on peut montrer [Venturini94b] que la coh�erencede R est n�ecessairement sup�erieure �a ��+1 . L'expert du domaine peut ainsi param�etrer

64 CHAPITRE 2. ALGORITHMES D'�EVOLUTION POUR L'AS� a�n d'obtenir des r�egles parfaitement coh�erentes (en choisissant � > jBj) ouadapter cette contrainte a�n de prendre en compte le bruit (par exemple � = 9force SIA �a n'accepter que des d�e�nitions dont la coh�erence est sup�erieure �a 90%).{ �, qui est un param�etre �a valeur dans f�10�3; 0; 10�3g permet de sp�eci�er un biaisde g�en�eralit�e (� = 10�3), de sp�eci�cit�e (� = �10�3), ou de neutralit�e en ce quiconcerne la g�en�eralit�e syntaxique des r�egles.{ (0 � << 1), permet de pond�erer l'importance de la mesure d'explicabilit�e.Tant que � et sont n�egligeables devant 1, le crit�ere principal d'�evaluation des r�eglesest leur coh�erence (sous la forme BC � �:MC). Il est �egalement important de noter quele param�etre � ne fait que �xer un seuil de coh�erence minimal, mais que le syst�eme peutfournir des r�egles dont la coh�erence est sup�erieure �a ce seuil.Op�erateurs g�en�etiquesHormis le sch�ema de s�election, les op�erateurs g�en�etiques sont au nombre de trois : lacr�eation, la mutation et le croisement.L'op�erateur de cr�eation g�en�ere une r�egle Rinit aussi sp�eci�que que possible couvrant unexemple ex (le noyau). Pour ce faire, les attributs de ex sont transform�es comme suit :Attributs symboliquesLa valeur d'un attribut symbolique est recopi�ee si elle est d�e�nie. Dans le cas o�u ellevaut #, * ou encore ?, elle est abandonn�ee.Attributs num�eriquesDans le cas o�u la valeur de l'attribut num�erique est d�e�nie, on g�en�ere le plus petitintervalle la contenant. Le traitement concernant les valeurs non d�e�nies reste lememe.L'op�erateur de mutation, qui s'applique sur une r�egle R, g�en�eralise un g�ene d�etermin�eal�eatoirement. Dans le cas o�u le g�ene s�electionn�e code un attribut symbolique, l'op�erateurpeut utiliser la hi�erarchie d�e�nie sur le domaine. En ce qui concerne les attributs num�eriques,les bornes des intervalles peuvent etre �etendues. De plus, dans les deux cas, il est �egalementpossible d'abandonner la condition portant sur l'attribut.L'op�erateur de croisement correspond au croisement uniforme d�e�ni dans [Syswerda89],avec une probabilit�e d'�echanger deux g�enes �egale �a 12 . Bien que les r�egles g�en�er�ees parcet op�erateur puissent etre incomparables, plus g�en�erales ou plus sp�eci�ques que leursparents, la propri�et�e de conservation de la couverture du noyau ex �a partir duquel Rinitest g�en�er�ee est toujours v�eri��ee. En e�et, les domaines ai de tous les individus couvrent(par construction) la valeur ei correspondante de ex.�Evolution des r�egles

2.2. Algorithmes d'�evolution et apprentissage automatique 65Les r�egles sont apprises successivement suivant le principe de couverture it�erative d�ecritchapitre 1, section 1.3.4. L'algorithme de d�eveloppement du noyau proc�ede par �evolutiond'une population P de 50 r�egles. La population initiale est g�en�er�ee en ins�erant des r�eglesobtenues par mutation de Rinit de telle sorte que seules les r�egles dont la qualit�e estsup�erieure �a celle de Q(Rinit) sont ins�er�ees dans P . Lorsque la taille maximale est atteinteSIA fait �evoluer la population de r�egles de la mani�ere suivante :1. Appliquer l'un des op�erateurs ci-dessous. La s�election (si n�ecessaire) des r�eglesfournies en argument de l'op�erateur se fait par tirage uniforme dans la population.{ Cr�eation (prob. par d�efaut de 10%) : g�en�eraliser Rinit pour obtenir une r�egleR0.{ Mutation (prob. par d�efaut de 80%) : s�electionner une r�egle et appliquer lamutation pour obtenir R0.{ Croisement (prob. par d�efaut de 10%) : s�electionner deux r�egles et appliquerle croisement pour obtenir R0 et R00.2. Ins�erer R0 (resp. R00) dans la population seulement si elle n'y �gure pas d�ej�a et :{ si R0 a �et�e engendr�ee par mutation �a partir d'une r�egle R, alors R0 remplace Rdans la population seulement si Q(R0) > Q(R) ;{ sinon R0 (resp. R00) n'est ins�er�ee que si sa qualit�e est sup�erieure �a celle de laplus mauvaise r�egle Rpire de la population. Dans ce cas R0 (resp. R00) remplaceRpire.3. Si la meilleure r�egle de la population est rest�ee inchang�ee depuis Nbmax it�erations,alors rendre la (les) meilleure(s) r�egles de P [ Rinit, sinon aller en 1.Plusieurs algorithmes de �ltrage sont propos�es dans [Venturini94b] a�n de supprimer lesr�egles redondantes ou bruit�ees, ce qui permet d'obtenir l'ensemble de r�egles R �nal.Classi�cationLa classi�cation d'une nouvelle instance ex �a partir de la base de r�eglesR se fait au moyend'une mesure de distance d(ex; R). Plus pr�ecis�ement, si R� est l'ensemble des r�egles deR dont la distance �a ex = ([e1; :::; en]; CL; p) est minimale, alors ex est de la classe de lar�egle R� = ([a1; :::; an]; C; f) 2 R� dont la qualit�e est la plus �elev�ee. La distance est de laforme : d(ex; R) = 1n(r) :qPni=1 d2i o�u n(R) est le nombre de conditions non abandonn�eesde R� et di est d�e�nie par :{ si condi a �et�e abandonn�ee dans R�, alors di = 0 ;{ si Ai est symbolique et si ei 2 ai alors di = 0 sinon di = 1 ;{ si Ai est num�erique et [B;B0] sont les bornes de ai, alors si ei 2 [B;B0] alors di = 0,si ei > B0 alors di = ei�B0maxi�mini et si ei < B0 alors di = B�eimaxi�mini .

66 CHAPITRE 2. ALGORITHMES D'�EVOLUTION POUR L'AS2.2.4 REGAL et G-NetLe syst�eme REGAL [Angelano et al.97, Neri97] pr�esent�e en d�etail ci-dessous, est une�evolution du syst�eme GA-SMART [Giordana et al.92]. L'objectif de ces syst�emes, qui fontr�ef�erence en apprentissage supervis�e bas�e sur les algorithmes g�en�etiques, est d'apprendredes formules de la logique relationnelle �etendue aux disjonctions internes. Pour ce faire,les auteurs ont d�evelopp�e :{ un codage des formules adapt�e aux cha�nes de bits de taille �xe ;{ des op�erateurs sp�eci�ques aux probl�emes d'apprentissage supervis�e de concepts dis-jonctifs (les croisements dirig�es g�en�eralisant et sp�ecialisant, ainsi que l'op�erateur des�election bas�e sur le su�rage universel).De plus, l'algorithme peut etre r�eparti sur plusieurs machines, et une version d�edi�ee auxgrappes de stations de travail a �et�e �elabor�ee (il s'agit du syst�eme G-Net [Angelano et al.98,Lo bello98]).Repr�esentation des formulesContrairement aux langages d'ordre 0 d�e�nis sur des attributs �a valeurs discr�etes et dont lecodage des formules correspond naturellement aux cha�nes binaires de taille �xe utilis�eespar l'AGC, la repr�esentation des formules de la logique relationnelle est plus di�cile �amettre en �uvre :{ les formules de la logique relationnelle peuvent etre de taille quelconque ;{ le langage de la logique relationnelle introduit des quanti�cateurs et des symbolesde variable ;{ les domaines d'application mettant en jeu de nombreuses valeurs num�eriques fontcro�tre la taille des chromosomes.La solution adopt�ee par G-NET consiste �a limiter l'espace de recherche �a l'aide d'une for-mule g�en�erique �, fournie par l'utilisateur. Cette formule g�en�erique est alors d�ecompos�eeen :{ une partie fonctionnelle typ�ee (�eventuellement fonctionnelle typ�ee et relationnelle)not�ee �LP (learnable predicates) ;{ une partie purement relationnelle �CP (constraint predicates), �eventuellement vide.Par exemple, la formule g�en�erique � = Color(X; col)^Distance(X;Y; dist)^Follow(X;Y )(dont la partie fonctionnelle typ�ee est marqu�ee en caract�eres d'imprimerie) peut etred�ecompos�ee en �LP = Color(X; col) ^Distance(X;Y; dist) et �CP = Follow(X;Y ). Il estalors possible, connaissant les domaines des di��erents types du langage, de coder la par-tie fonctionnelle sur une cha�ne de bits de taille �xe en utilisant un m�ecanisme similaire�a GABIL. Chaque bit du chromosome code ainsi la pr�esence (1) ou l'absence (0) d'un

2.2. Algorithmes d'�evolution et apprentissage automatique 67symbole de constante donn�e dans une disjonction interne. La partie contrainte, qui n'estpas modi��ee par l'algorithme, ne �gure pas dans le codage du chromosome.� = �LPz }| {Color(X; [red; yellow;white; blue;:]) ^Distance(X;Y; [1; 2; 3; 4; 5; 6; 7; 8])^ �CPz }| {Follow(X;Y )� =Fig. 2.12: Codage de la formule g�en�erique � = �LP ^ �CP dans une cha�ne binaire detaille �xe � [Giordana et al.97].L'ensemble des constantes d'un type donn�e pouvant etre tr�es important, l'utilisateur ala possibilit�e de d�e�nir des disjonctions internes incompl�etes : ces derni�eres ne compor-tent que certaines constantes choisies, ce qui diminue d'autant la taille des chromosomes.Les pr�edicats contenant de telles disjonctions sont �egalement dits incomplets (incompletepredicates, cf. [Neri97] page 71).De plus, un marqueur not�e : code la n�egation interne, ce qui permet d'�etendre l'ex-pressivit�e des disjonctions incompl�etes puisqu'il est alors possible de faire r�ef�erence parcompl�ement �a des ensembles de symboles non cod�es dans la disjonction. Lorsque tous lesbits d'une disjonction compl�ete (y compris l'�etoile) sont �a 1, le pr�edicat correspondant estabandonn�e. Ainsi, la formule g�en�erique � dont le codage � est d�etaill�e �gure 2.12 permetde g�en�erer (entre autres) les formules 'i correspondant aux cha�nes s('i) suivantes :� = red yellow white blue : 1 2 3 4 5 6 7 8s('1) = 0 1 1 0 0 0 0 1 0 0 0 0 0s('2) = 1 1 0 0 1 0 0 0 0 1 1 1 0s('3) = 1 1 1 1 1 0 1 0 0 0 0 0 0'1 = Color(X; [yellow _ white]) ^Distance(X; Y; [3]) ^ Follow(X; Y )'2 = Color(X; [:(white _ blue)]) ^Distance(X; Y; [5 _ 6 _ 7]) ^ Follow(X; Y )'3 = Distance(X; Y; [2]) ^ Follow(X; Y )Fonction de qualit�eLa qualit�e f d'une formule ' est d�e�nie empiriquement par :f(') = (1 + A:z(')):e�w(') + "o�u A est un param�etre (qui vaut 0; 1 par d�efaut) fourni par l'utilisateur ;z(') = nombre de bits �a 1longueur du chromosomeest une mesure de la simplicit�e de l'hypoth�ese ; w(') correspond au nombre d'instancesn�egatives couvertes par ' et " est une constante positive tr�es petite.

68 CHAPITRE 2. ALGORITHMES D'�EVOLUTION POUR L'ASOp�erateurs g�en�etiquesLes op�erateurs de G-Net sont multiples : alors que certains (la mutation et les croisementsclassiques) proviennent du cadre des algorithmes g�en�etiques binaires classiques, d'autres(les croisements dirig�es, la cr�eation de noyaux et la s�election au su�rage universel) ont �et�ed�evelopp�es sp�eci�quement pour la tache d'apprentissage.Les croisements sont au nombre de quatre : le croisement �a deux points [Holland75], lecroisement uniforme [Syswerda89], le croisement sp�ecialisant et le croisement g�en�eralisant.Si les deux premiers sont bien connus, les deux croisements dirig�es ainsi que la proc�edure dechoix du croisement �a appliquer ont �et�e propos�es pour le syst�eme GA-SMART [Giordana et al.92]dans le cadre de la repr�esentation des disjonctions internes sous forme de cha�nes de bits.Puisque le changement d'un bit de 0 �a 1 (resp. de 1 �a 0) ajoute (resp. supprime) uneconstante dans une disjonction, l'application d'un ou-logique (resp. et-logique) sur les bitscodant une disjonction aura pour e�et de g�en�eraliser (resp. sp�ecialiser) cette derni�ere. Lecroisement g�en�eralisant (resp. sp�ecialisant) consiste donc �a appliquer un ou-logique (resp.et-logique) aux bits des deux parents qui correspondent �a un ensemble � de litt�erauxd�etermin�es al�eatoirement. Chaque individu est s�electionn�e pour un croisement avec uneprobabilit�e pc = 0; 6.Lorsque deux individus '1 et '2 ont �et�e d�etermin�es, le choix d'un des quatre croisementsse fait suivant la r�egle ci-dessous o�u pu, p2pt, ps et pg repr�esentent repectivement la prob-abilit�e d'e�ectuer un croisement uniforme, un croisement �a deux points, un croisementsp�ecialisant et un croisement g�en�eralisant :pu = (1� a:fn):bp2pt = (1� a:fn):(1� b)ps = a:fn:rpg = a:fn:(1� r)a et b sont des param�etres �a valeur dans [0; 1] ajustables par l'utilisateur et valant pard�efaut 0; 7 et 0; 4. a correspond �a la pr�ef�erence d'appliquer un croisement dirig�e plutotqu'un croisement classique et b la pr�ef�erence au croisement uniforme plutot qu'au croise-ment �a deux points. fn et r valent respectivement f('1)+f('2)2:fmax et n+('1)+n�('1)+n+('2)+n�('2)(E+C)2 ,o�u f d�enote la fonction de qualit�e, fmax sa valeur maximale, n+(') (resp. n�(')) le nombred'exemples (resp. contre-exemples) couverts par l'hypoth�ese ' et E = jEj (resp. C = jCj)le nombre d'exemples (resp. de contre-exemples) du concept-cible. Moins f('1) et f('2)sont importantes, plus fn est petite et plus la probabilit�e de pr�ef�erer un croisement clas-sique �a un croisement dirig�e est grande. D'autre part, le ratio r est construit de telle sorteque la probabilit�e d'appliquer le croisement sp�ecialisant soit proportionnelle �a la sommedes couvertures des deux hypoth�eses.La mutation, qui correspond �a la version classique de l'AGC, est appliqu�ee avec un tauxpm = 10�4. Elle est compl�et�ee par un op�erateur de g�en�eration (le seeding operator), quiest �egalement utilis�e lors de la cr�eation de la population initiale. Cet op�erateur cr�ee une

2.2. Algorithmes d'�evolution et apprentissage automatique 69formule ', �a partir d'un exemple positif � et �a l'aide d'une cha�ne de bits s (g�en�er�eeal�eatoirement) en d�eterminant tout d'abord al�eatoirement un appariement satisfaisantles contraintes de �CP entre les litt�eraux de � et ceux du mod�ele g�en�erique � puis eng�en�eralisant s aussi peu que possible (c'est-�a-dire en minimisant le nombre de bits de squ'il faut mettre �a 1) a�n d'assurer qu'elle couvre �. L'op�erateur de g�en�eration permetainsi d'augmenter d'une part la couverture de l'espace de recherche en enrichissant ladiversit�e g�en�etique de la population et d'autre part la couverture des exemples �a l'aided'un m�ecanisme similaire �a la cr�eation du noyau �a partir d'une r�egle Rinit qui est utilis�epar SIA.La s�election au su�rage universelLe sch�ema de s�election, qui est l'un des apports majeurs de l'algorithme, est �a la fois tr�esoriginal et tr�es bien adapt�e �a la probl�ematique de l'optimisation multimodale dans le cadrede l'application des algorithmes g�en�etiques �a l'apprentissage supervis�e de concepts. Il a�et�e baptis�e s�election au su�rage universel car �a chaque g�en�eration ce sont des exemplesdu concept-cible qui votent pour les r�egles qui les couvrent ; de plus les exemples ont uneprobabilit�e identique d'etre choisis et chacun dispose d'une voix. Ainsi, si M est la taillede la population A, et 0 < g � 1 son taux de renouvellement, la s�election extrait avecreplacement g:M exemples �i du concept-cible. Chaque exemple �i choisit alors une r�egleau moyen d'un tirage de la roulette ri constitu�ee de toutes les r�egles de A couvrant �i(la probabilit�e de tirer une r�egle 'j de la roulette est proportionnelle �a sa qualit�e f('j)).Dans le cas o�u aucune r�egle de la population ne couvre �i, une nouvelle formule est cr�e�ee�a l'aide de l'op�erateur de g�en�eration. Contrairement aux techniques classiques de cr�eationde niches �ecologiques et de formation d'esp�eces, la s�election au su�rage universel pr�esenteles propri�et�es suivantes :1. �a tout moment de l'�evolution, la couverture (stochastique) de l'ensemble d'appren-tissage par les formules est garantie ;2. il n'est pas n�ecessaire de d�e�nir une distance entre deux individus ;3. la fonction de qualit�e est utilis�ee localement pour comparer des individus couvrantle meme exemple.Ces propri�et�es sont particuli�erement adapt�ees au contexte de l'apprentissage supervis�e deconcepts disjonctifs. D'une part, la premi�ere leur est sp�eci�que et ne peut etre obtenuepar une technique propos�ee dans le cadre plus g�en�eral de l'optimisation. D'autre part,la seconde propri�et�e est souhaitable lorsque le langage-cible est constitu�e de formules dela logique relationnelle puisque la d�e�nition d'une distance dans un tel langage est tr�esdi�cile �a �elaborer. En�n, la derni�ere propri�et�e permet une �evaluation des r�egles dirig�eepar la couverture locale.�Evolution des r�eglesL'architecture distribu�ee de REGAL comprend un ensemble de sous-populations (oud�emes) fPopng distribu�ees sur les processeurs ainsi qu'un processus central appel�e su-

70 CHAPITRE 2. ALGORITHMES D'�EVOLUTION POUR L'ASperviseur. �A chaque g�en�eration t, le d�eme Popn re�coit des autres d�emes un ensembled'individus Anet(t) tel que jAnet(t)j = �:jAn(t)j o�u � est le taux de migration et An(t)l'ensemble d'individus de la population courante. Chaque d�eme Popn applique alors lo-calement la s�election par su�rage universel �a l'aide d'un sous-ensemble sp�eci�que En desexemples d'apprentissage sur An(t) et Anet(t). De plus, �:jAnet(t)j individus (o�u � corre-spond au taux de reproduction extra-d�eme) sont s�electionn�es al�eatoirement parmi Anet(t)a�n de participer �egalement �a la reproduction. En�n, une partie des enfants est ins�er�eeavec remplacement dans An(t+1) alors qu'une autre partie est envoy�ee aux autres d�emessur le r�eseau. Le meilleur individu (au sens d'une mesure �(bestn; En) = Posn:f(bestn)o�u Posn correspond �a la couverture de bestn sur les exemples du concept-cible) est alorsenvoy�e au superviseur et la g�en�eration suivante peut d�ebuter.Le role du superviseur consiste �a maintenir la liste des meilleures d�e�nitions courantes et �aassigner �a chaque d�eme un ensemble En adapt�e, c'est-�a-dire permettant la caract�erisationd'un sous-concept.2.3 R�ecapitulatif - Motivation de SIAO1Ce chapitre a �et�e l'occasion de pr�esenter les algorithmes d'�evolution, dont le fonction-nement g�en�eral s'inspire de la simulation du d�eveloppement de populations d'individus.En pratique, ces algorithmes ont connu un grand succ�es en tant que m�ethodes d'optimisa-tion g�en�erales, car elles sont applicables �a un tr�es vaste ensemble de probl�emes sans pourautant n�ecessiter d'investissement tr�es important que ce soit sur le plan du d�eveloppementdu logiciel, ou sur le plan du cout d'adaptation de la m�ethode au probl�eme �a r�esoudre.En particulier, les algorithmes d'�evolution ont fait l'objet d'�etudes et ont �et�e appliqu�es avecsucc�es dans le domaine de l'apprentissage automatique. Cependant, de par leur g�en�eralit�ememe, une comparaison avec les approches d�edi�ees �a l'apprentissage automatique su-pervis�e symbolique montre qu'un travail d'adaptation aux sp�eci�cit�es du probl�eme estn�ecessaire. En e�et :{ Du point de vue de l'expressivit�e de Lh, il semble di�cile de trouver un juste milieuentre les chromosomes binaires (resp. r�eels) de taille �xe mis en �uvre dans l'AGC(resp. les strat�egies d'�evolution) d'une part, et les arbres tr�es peu contraints utilis�esen programmation g�en�etique d'autre part. Ce probl�eme est particuli�erement �epineuxdans le domaine de la logique du premier ordre, o�u il est n�ecessaire de trouver uncompromis au dilemme provenant de la relation liant l'expressivit�e de Lh �a la taille del'espace de recherche d'une part et �a la complexit�e calculatoire du test de couvertured'autre part.{ Du point de vue de la strat�egie de recherche, les m�ethodes �evolutionnaires sont pourla plupart caract�eris�ees par un d�eplacement non dirig�e, redondant et peu inform�eau sein de l'espace de recherche, alors que le th�eor�eme de conservation donne surle plan th�eorique de bons arguments pour que l'algorithme de recherche exploiteautant que possible toutes les connaissances sp�eci�ques au domaine.

2.3. R�ecapitulatif - Motivation de SIAO1 71{ En�n, la probl�ematique des bases de donn�ees de taille importante (qui se retrouvedans de nombreuses applications pratiques en fouille de donn�ees) doit �egalementetre prise en compte.Le syst�eme SIAO1, d�etaill�e dans les chapitres suivants, propose { entre autres { uner�eponse originale �a chacun des points �evoqu�es ci-dessus :{ L'espace de recherche Lh r�esulte d'un compromis entre les formes �xes (commeles patrons pr�ed�e�nis par l'utilisateur) et les formes quelconques (provenant de laprogrammation g�en�etique). Les hypoth�eses initiales sont en e�et g�en�er�ees �a l'aided'un exemple (ou noyau), ce qui �xe une forme initiale. Celle-ci est alors modi��ee aucours de la recherche, non seulement �a l'aide d'op�erateurs de g�en�eralisation classiquestels que l'abandon de pr�edicat, mais �egalement �a l'aide d'un op�erateur de croisementg�en�erant un presque moindre g�en�eralis�e de la d�e�nition courante et d'un exempledu concept-cible non couvert par cette d�e�nition. L'algorithme peut ainsi cr�eer desformes �a la fois pertinentes et totalement nouvelles, c'est-�a-dire di��erentes des formesdes exemples.{ En ce qui concerne la strat�egie d'exploration, l'ordre partiel d�e�ni sur Lh est mis�a pro�t puisque la recherche est dirig�ee (ascendante). De plus, la redondance estinterdite par le sch�ema de s�election, ce qui permet �egalement de diminuer le risquede convergence pr�ematur�ee. En�n, la recherche est inform�ee puisque les op�erateurssont, autant que faire se peut, dirig�es par les donn�ees : on esp�ere ainsi am�eliorerl'e�cacit�e de l'exploration par rapport aux syst�emes reproduisant exactement lecadre �evolutionnaire qui cherchent en aveugle .{ Les algorithmes d'�evolution �etant gourmands en puissance de calcul, de nombreuxtravaux concernent leur parall�elisation. Cependant, alors que la totalit�e des travauxrelatifs aux algorithmes d'�evolution parall�eles proposent de r�epartir si possible dy-namiquement la charge de calcul (la plupart du temps en �eparpillant la popula-tion sur di��erents processeurs), SIAO1 r�epond �egalement �a la probl�ematique dela r�epartition de la charge m�emoire, lorsque cette derni�ere devient insu�sante pourpermettre �a chaque processeur de contenir en m�emoire vive (RAM) l'ensemble dela base d'apprentissage.

72 CHAPITRE 2. ALGORITHMES D'�EVOLUTION POUR L'AS

Chapitre 3Le biais de langageCe chapitre est d�edi�e �a l'�etude du biais de langage de SIAO1, en particulier dupoint de vue de la complexit�e du test de couverture1. En e�et, comme l'a montr�e lechapitre 1 (section 1.5.1), la prise en compte du dilemme cout de l'induction / richessedu langage est fondamentale dans le contexte de l'apprentissage relationnel. La structurede l'argumentation est donc divis�ee en deux grandes parties interd�ependantes.La premi�ere partie est centr�ee autour du langage de repr�esentation de SIAO1. Elle d�ebutepar une pr�esentation de la probl�ematique et des r�esultats th�eoriques relatifs �a la logiquedu premier ordre en g�en�eral et au test de �-subsomption utilis�e par certaines m�ethodesde PLI en particulier. Une seconde section pr�esente le langage de SIAO1 ainsi que larelation de subsomption choisie pour structurer l'espace. L'expressivit�e du langage ainsique la complexit�e du test de subsomption sont �egalement analys�ees au regard des r�esultatsobtenus dans le cadre de la logique du premier ordre.La seconde partie concerne l'�etude et l'implantation d'un test de subsomption optimis�e.Apr�es avoir montr�e l'int�eret d'un tel test pour SIAO1 dans le cas de probl�emes fortementrelationnels, l'architecture g�en�erale de l'algorithme de subsomption est esquiss�ee, chacunedes trois �etapes (le pr�e-traitement, la r�eduction des domaines et la r�esolution avec prop-agation) �etant d�etaill�ee dans une section sp�eci�que. Finalement, les performances du testde subsomption sont valid�ees sur un probl�eme fortement relationnel.�A l'issue de ce chapitre, le lecteur aura pris connaissance des structures et algorithmesde base sur lesquels le syst�eme SIAO1 est construit. En particulier, les choix qui ont �et�efaits au niveau des biais de langage (repr�esentation des connaissances, th�eorie du domaine,typage, complexit�e du test de subsomption) auront �et�e explicit�es.1Nous nous conformons par la suite �a l'usage du vocabulaire de la logique qui utilise le terme sub-somption pour rendre compte des notions de couverture ou d'appariement de formules.73

74 CHAPITRE 3. LE BIAIS DE LANGAGE3.1 Le langage de repr�esentation de SIAO13.1.1 Contexte th�eoriqueLa donn�ee d'une relation d'ordre partiel large (cf. chapitre 1, section 1.3.3 et annexeA, section A.2) entre deux formules quelconques d'un langage est cruciale dans le cadrede l'apprentissage symbolique puisqu'elle permet :{ le test de couverture d'un exemple ou d'un contre-exemple du concept �a apprendrepar une d�e�nition candidate ;{ l'organisation de l'espace de recherche, ce qui ouvre de nombreuses possibilit�es d'ex-ploitation algorithmique (apprentissage par g�en�eralisation, par sp�ecialisation, espacedes versions, �elagage de l'espace ainsi structur�e, ... ) ;{ la d�e�nition d'une relation d'�equivalence (puisqu'on peut poser [x = y] , [(x �y) ^ (y � x)] ), ce qui rend possible la d�e�nition de classes d'�equivalences entrehypoth�eses : on peut alors par exemple choisir parmi di��erentes formules �equivalentescelle qui sera la plus intelligible �a l'utilisateur.La �-subsomption, d�e�nie par Robinson [Robinson65] et introduite dans le cadre de l'ap-prentissage par Plotkin [Plotkin70] est une relation v�eri�ant les propri�et�es ci-dessus. Lesr�esultats �enonc�es dans cette section sont relatifs au cadre de la PLI : Lh est le langagede la logique du premier ordre (ou l'un de ses sous-ensembles), et les formules manipul�eessont des clauses de Horn.D�e�nition 3.1 Relation de �-subsomptionOn dit qu'une clause D �-subsume une clause E si et seulement si il existe une substitution� telle que D� � E. On notera D `� E.Exemple : Soient les clauses :D : C P (X; Y ) ^ P (Y;X):E1 : C P (a; b) ^ P (b; a):E2 : C P (a; b) ^ P (b; c):E3 : C P (a; a):On a :D `� E1 (avec � = fX=a; Y=bg)D 6`� E2D `� E3 (avec � = fX=a; Y=ag)Les raisons pour lesquelles cette relation (qui formalise l'intuition de la notion d'ap-pariement d�ecrite dans le paragraphe pr�ec�edant) est tellement utilis�ee en PLI sont li�ees �ases nombreuses propri�et�es :Propri�et�e 3.1La �-subsomption est une relation correcte pour l'implication logique, i.e. (D `� E) )(D j= E).

3.1. Le langage de repr�esentation de SIAO1 75La preuve de cette propri�et�e est imm�ediate de par la d�e�nition de la �-subsomptionpuisque : [9� = (D� � E)]) (D j= E). Bien qu'en toute g�en�eralit�e l'implication logiquepuisse etre consid�er�ee comme le test d'appariement id�eal (ce qui revient �a dire que Ds'apparie (ou subsume) E ssi D j= E), cette derni�ere a l'inconv�enient majeur du point devue pratique d'etre ind�ecidable.Le principal int�eret de la �-subsomption vient du fait que, contrairement �a l'implicationlogique, cette relation est d�ecidable.Propri�et�e 3.2La �-subsomption est une relation d�ecidable sur l'ensemble des clauses.L�a encore, la preuve est imm�ediate puisqu'il su�t de tester la compatibilit�e d'un nombre�ni de compositions de substitutions partielles. Dans le pire des cas (chaque litt�eral de Dest compatible avec tous les litt�eraux de E), il existe jEjjDj mani�eres d'associer �a chaquelitt�eral de D un litt�eral de E.Puisque d'une part l'implication logique est ind�ecidable sur l'ensemble des clauses etque d'autre part la �-subsomption est d�ecidable et correcte, il est impossible que la �-subsomption soit compl�ete pour l'implication logique : (D `� E) 6( (D j= E), ce qu'illus-tre le contre-exemple suivant :Contre-exemple :Soient les deux clausesD : pair(s(s(X)) pair(X) et E : pair(s(s(s(s(X)))) pair(X).On a bien : D j= E, mais pas D `� E.[Gottlob87] a caract�eris�e les deux cas d'incompl�etude de la �-subsomption, ce qui permetde formuler la propri�et�e suivante :Propri�et�e 3.3Soient D et E deux clauses. Si D n'est pas auto-r�ef�erente et si E n'est pas une tautologie,alors la �-subsomption est une relation correcte, i.e. (D `� E)( (D j= E).Ainsi, dans le cadre de l'apprentissage de d�e�nitions D non r�ecursives grace �a une based'apprentissage dont les exemples E ne sont pas des tautologies, la �-subsomption peutetre identi��ee �a l'implication logique.Du point de vue op�eratoire, le premier r�esultat montrant que le calcul de `� est NP-di�cileremonte �a [Baxter77]. Plus r�ecemment, [Kietz et al.94] ont �etendu ce r�esultat au cas o�uE est de taille �xe :Propri�et�e 3.4Soient D et E deux clauses. Alors, le calcul de D `� E est NP-di�cile, meme lorsque Eest de taille �xe.

76 CHAPITRE 3. LE BIAIS DE LANGAGE3.1.2 Repr�esentation des hypoth�eses et des instances dans SIAO1Le langage de repr�esentation des hypoth�eses de SIAO1 (not�e Lh par la suite) est unlangage relationnel typ�e sans symboles de fonction qui int�egre certaines caract�eristiques ducalcul des pr�edicats annot�es (APC, [Michalski84]), du langage d'ordre 0 de SIA [Venturini94b],et du contexte de l'apprentissage �a partir d'interpr�etations [De raedt97, Blockeel et al.99].D�e�nition de LhSoient :{ Un ensemble �ni C de symboles de classes (chaque symbole correspond �a un pr�edicatd'arit�e nulle).{ Un ensemble �ni Tn de types de constantes num�eriques.{ Un ensemble �ni Ts de types de constantes symboliques (Tn \ Ts = ;).{ �A chaque type de constante num�erique (resp. symbolique) correspond un ensemble�ni de constantes num�eriques (resp. symboliques). Chacun de ces ensembles com-porte toujours les symboles ? (valeur manquante typ�ee) et * (valeur indi��erentetyp�ee).{ Un ensemble �ni de variables typ�ees.{ Un ensemble �ni P de pr�edicats typ�es (C \ P = ;). �A chaque symbole de pr�edicatest associ�e sa signature constitu�ee :{ d'un entier positif a appel�e arit�e, repr�esentant le nombre d'arguments ;{ de la liste des k types des arguments du pr�edicat.Alors, toutes les formules de Lh sont de la forme :cl a1 ^ a2 ^ ::: ^ ano�u cl est un symbole de classe, et les ai, appel�es atomes, sont de la forme :p(t1; :::; tk)p 2 P est un symbole de pr�edicat d'arit�e k, dont les arguments tj (qui doivent respecterles contraintes de type relatives aux signatures des pr�edicats) peuvent etre :{ une constante c ;{ une disjonction de constantes, appel�ee disjonction interne et not�ee fc1 _ ::: _ cjg ;{ dans le cas des constantes num�eriques, un intervalle not�e [c1; c2] (avec c1 � c2) ;{ une variable.

3.1. Le langage de repr�esentation de SIAO1 77D�e�nition de LeLe est un sous-ensemble strict de Lh destin�e �a repr�esenter les exemples et contre-exemplesdu concept-cible qui sont par hypoth�ese des objets sp�eci�ques (c'est-�a-dire totalementinstanci�es). Pour cette raison, une formule de Le ne comporte :{ aucune variable ;{ aucune disjonction interne ;{ aucun intervalle num�erique.Caract�eristiques de LhLe langage de repr�esentation des hypoth�eses de SIAO1 a, au regard des autres syst�emesde PLI, les caract�eristiques suivantes :{ Lh est un langage relationnel clausal :� dont toutes les variables sont existentielles ;� sans symboles de fonction ;� non r�ecursif.Ces restrictions, qui garantissent la d�ecidabilit�e du test d'implication ainsi que lalocalit�e des instances2, d�e�nissent un cadre tr�es proche de l'apprentissage par in-terpr�etations [De raedt97, Blockeel et al.99]. Ce cadre est particuli�erement appro-pri�e �a l'apprentissage de concepts �a partir d'une base de donn�ees relationnelle. Dansce cas, une relation de la base de donn�ees est typiquement associ�ee �a un pr�edicat,chaque n-uplet correspondant �a un atome instanci�e. Cependant, alors que la basede donn�ees est organis�ee en tables (par relation), la base d'apprentissage est orga-nis�ee par projection des relations sur les instances (on parle alors de saturation).La �gure 3.1 montre la repr�esentation de mol�ecules �a l'aide d'une base de donn�eesrelationnelle, ainsi que la repr�esentation dans le langage Lh correspondante.{ Lh permet d'�etendre les domaines des arguments des pr�edicats d'une mani�ere simi-laire �a ce que propose Michalski dans le cadre du calcul des pr�edicats annot�es (APC,[Michalski84]). Les extensions de domaine correspondent :� Pour les constantes symboliques, �a une compression d'information puisque laclause concept P (X; fc1 _ ::: _ cng) est �equivalente �a l'ensemble de clausesfconcept P (X; c1); :::; concept P (X; cn)g. La pr�esence de d disjonctionsinternes comportant chacune n constantes correspond donc �a nd clauses.2Chaque instance contient toute l'information descriptive la concernant. Les instances sont doncind�ependantes les unes des autres.

78 CHAPITRE 3. LE BIAIS DE LANGAGEMol�eculesId m Classem1 classe1m2 classe2... AtomesId m Id a �El�ementm1 a1 om1 a2 sm1 a3 om2 a4 cLiaisonsId m Id a Id a Liaisonm1 a1 a2 dative 2em1 a2 a3 covalente 4e...classe1 atome(a1; o) ^ atome(a2; s) ^ atome(a3; o) ^liaison(a1; a2; dative 2e) ^ liaison(a2; a3; covalente 4e):classe2 atome(a4; c) ^ :::Fig. 3.1: Repr�esentations de donn�ees relationnelles.� Pour les constantes num�eriques, outre la compression relative aux disjonctionsinternes, les intervalles impliquent la connaissance implicite de la relation d'or-dre � d�e�nie sur <.Ces extensions permettent de faire b�en�e�cier SIAO1 des capacit�es de g�en�eralisationet de l'intelligibilit�e des syst�emes op�erant sur les repr�esentations attribut-valeur.SIAO1 peut donc etre utilis�e �a la fois dans le cadre de probl�emes relationnelsrelevant de la PLI et dans le cadre de probl�emes plus classiques relevant de syst�emesd'ordre 0.{ Il est possible de sp�eci�er une th�eorie du domaine sous la forme de hi�erarchiesimplantant la relation est-un sur des constantes de meme type ou des pr�edicats dememe signature. Par d�e�nition, le symbole (typ�e) * est au sommet de la hi�erarchiede chaque type. Pour ce qui est des pr�edicats, le sommet de chaque hi�erarchie est lepr�edicat vide (not�e ;), qui repr�esente d'un point de vue logique l'abandon de l'atomecorrespondant. Un exemple de hi�erarchie sur des constantes est donn�e par la �gure1.4 du chapitre 1.{ Pour �nir, Lh b�en�e�cie des symboles repr�esentant les valeurs manquantes ( ?) ouindi��erentes (*) dont l'utilit�e a �et�e d�emontr�ee dans le cadre du syst�eme attribut-valeur SIA ([Venturini94b], voir �egalement chapitre 2, section 2.2.3). Cependant,contrairement aux repr�esentations attribut-valeur, les repr�esentations relationnellesexpriment la caract�eristique non d�e�nie d'une valeur par l'abandon du pr�edicatassoci�e, ce qui rend super u l'existence d'un symbole sp�eci�que (not�e # dans le casde SIA). Par exemple, consid�erons la repr�esentation attribut-valeur suivante :classe identifiant nb roues couleur contenance remorque marquevoiture 283LZZ75 4 � # ?L'expert a observ�e une voiture immatricul�ee 283LZZ75. Il sait que la couleur n'estpas une caract�eristique discriminante pour la tache de classi�cation en cours :plutot que de rechercher cette information, il la d�eclare donc indi��erente (sym-bole *). D'autre part, puisqu'aucune remorque n'est attach�ee au v�ehicule, l'attributcontenance remorque n'a aucune signi�cation dans ce contexte, ce que d�enote lesymbole # associ�e aux valeurs non d�e�nies. Finalement, l'expert n'ayant pas con-

3.1. Le langage de repr�esentation de SIAO1 79naissance de la marque de la voiture, l'attribut correspondant est not�e manquant(symbole ?). Le codage relationnel associ�e de l'objet d�ecrit par cette table est donc :voiture objet(283LZZ75) ^ nb roues(283LZZ75; 4) ^ couleur(283LZZ75; �)^ marque(283LZZ75; ?):Typage et g�en�eralisation { types fonctionnels et relationnelsLe typage est souvent per�cu comme une technique dont l'utilit�e se r�esume au controle dela coh�erence d'expressions d'un langage. Cependant, dans le cas de SIAO1, ce dernier estd'autant plus utile qu'il correspond �a un biais de langage naturel (la notion de type est tr�esintuitive) et souple (l'utilisateur segmente autant qu'il le d�esire les ensembles d'attributs).Dans ce cas, le typage ne sert pas uniquement au controle des donn�ees fournies au syst�emed'apprentissage, puisqu'il permet de r�eduire la taille de l'espace de recherche. En e�et,d�e�nir le type d'un objet consiste (entre autres) �a lui associer un ensemble de valeurspotentielles. Par exemple, en supposant l'existence :{ d'un type forme �a valeur dans fcercle; rectangle; triangleg ;{ d'un type couleur �a valeur dans fblanc; bleu; noir; rouge; vertg ;{ d'un pr�edicat Objet d'arit�e 3 et dont les arguments sont de type obj id, forme etcouleur ;il est possible de restreindre les g�en�eralisations de l'atome Objet(X; rectangle; rouge)aux formules v�eri�ant les r�egles de typage, ce qui permet d'�elaguer des atomes tels queObjet(X; frectangle _ noirg; rouge).De plus, SIAO1 enrichit le typage en sp�eci�ant deux modalit�es (relationnelle et fonction-nelle) sur les types :{ Un type est dit relationnel si toutes les g�en�eralisations utiles des symboles de cetype peuvent etre obtenues par variabilisation.{ Un type est dit fonctionnel si toutes les g�en�eralisations utiles des symboles de cetype peuvent etre obtenues par extension de domaine.En pratique, les donn�ees n'ayant qu'un aspect soit structurel, soit ensembliste, il esttoujours possible de d�eterminer avec certitude le biais de langage correspondant. En par-ticulier, lorsque les exemples proviennent d'une base de donn�ees relationnelle, les attributsstructurants correspondent aux cl�es des tables (ce sont des constantes relationnelles), lesautres valeurs �etant des constantes fonctionnelles. Par exemple, dans le cas de la �gure3.1, les types Id m et Id a sont relationnels alors que les types �El�ement et Liaison sontfonctionnels.

80 CHAPITRE 3. LE BIAIS DE LANGAGE3.1.3 La relation de subsomption sur LhLe test de subsomption de SIAO1, not�e `, est similaire au test de �-subsomptionpuisqu'il est fond�e sur la mise en correspondance de chaque litt�eral de l'hypoth�ese avecun litt�eral de l'exemple, sous r�eserve du respect des contraintes d'�egalit�e impos�ees parles variables. Cependant, les particularit�es de Le et Lh induisent certaines di��erences quisont �enum�er�ees ci-apr�es et examin�ees du point de vue de leur impact sur la complexit�e dutest `.Une premi�ere di��erence provient de l'existence d'une th�eorie du domaine sous la forme dehi�erarchies d�e�nies sur les constantes de meme type et les pr�edicats de meme signature.Par bonheur, la complexit�e du test de subsomption reste identique �a celle du test de �-subsomption puisque d'une part les r�egles d'instanciation des variables restent inchang�ees,et que d'autre part chaque appariement entre un litt�eral de l'hypoth�ese et un litt�eral del'exemple g�en�ere au plus une substitution candidate. Plus formellement, en faisant leshypoth�eses tr�es raisonnables :{ d'un cout born�e par une constante k1 pour la complexit�e du test de subsomption dedeux symboles de constante ou de pr�edicat ;{ d'une borne k2 �a l'arit�e des pr�edicats ;alors la complexit�e du test de subsomption entre l'hypoth�ese D et l'exemple E augmente(grossi�erement3) dans le pire des cas de k1:k2:jEj:jDj, ce qui ne modi�e pas la grandeurasymptotique de la complexit�e du test de subsomption, puisque (de par son caract�ereNP-di�cile) cette derni�ere domine asymptotiquement toute fonction polynomiale de jDjet de jEj.La seconde di��erence a trait aux extensions de domaine (disjonctions internes et intervallesnum�eriques). L�a encore, la complexit�e globale du test de subsomption n'est pas modi��ee.En e�et, en remarquant que toute extension de domaine provient d'un type fonctionnelet ne s'apparie par cons�equent qu'avec une constante ou une autre extension de domainedu meme type, il d�ecoule :{ que chaque appariement entre un litt�eral de l'hypoth�ese et un litt�eral de l'exempleg�en�ere au plus une substitution candidate (aucun symbole de variable n'est mis encorrespondance avec une extension de domaine) ;{ qu'en supposant born�ee la taille des extensions de domaine, le test de compatibilit�e(qui revient �a v�eri�er l'inclusion d'un ensemble dans un autre) est de complexit�eborn�ee par une constante k.3C'est par exemple le cas pour l'algorithme propos�e sections 3.2.2 et suivantes, puisqu'alors seule lacomplexit�e du pr�e-traitement correpondant au cout de cr�eation du tableau des contraintes est alt�er�ee.La complexit�e de la recherche n'est par contre pas a�ect�ee, le nombre de contraintes du tableau �etanttoujours born�e par jEj:jDj.

3.1. Le langage de repr�esentation de SIAO1 81En suivant le meme raisonnement que pr�ec�edemment, il d�ecoule donc que la grandeurasymptotique de la complexit�e du test de subsomption n'est pas modi��ee.La derni�ere di��erence entre ` et `� provient de la s�emantique particuli�ere associ�ee auxsymboles * et ?, qui n�ecessite la sp�eci�cation de r�egles d'appariement adapt�ees. En e�et :� Par d�e�nition, une valeur manquante est d�e�nie mais inconnue. Le symbole ? doitdonc etre consid�er�e comme une constante. Cependant, chaque occurrence de ? cor-respond �a une valeur inconnue potentiellement di��erente d'une autre occurrence dumeme symbole. La r�egle d'appariement de ? se ram�ene ainsi �a un simple m�ecanismede r�e�ecriture :Chaque occurrence de ? dans une formule de Lh est �equivalente pour la relationde subsomption �a l'introduction d'un nouveau symbole de constante.Exemples : D D r�e�ecrite E E r�e�ecrite D ? EP (�; �) P (�; �) P (?; ?) P (c1; c2) ouiP (a;A) P (a;A) P (a; ?) P (a; c1) ouiP (A;A) P (A;A) P (?; ?) P (c1; c2) nonR(a) R(a) R(?) R(c1) nonR(?) R(c1) R(?) R(c2) nonUn cas particulier �a cette r�egle survient lorsque le test de subsomption est utilis�ea�n de simpli�er une formule (comme dans le cas de l'algorithme FASTCONDENSEd�ecrit section 3.2.1). Il est alors n�ecessaire de proc�eder �a la r�e�ecriture de la formuleavant duplication. Dans ce cas, la derni�ere ligne du tableau devient :D D r�e�ecrite E � D E r�e�ecrite D ? ER(?) R(c1) R(?) R(c1) ouiCe m�ecanisme permet �egalement de garantir la r�e exivit�e de la relation de sub-somption.� Une valeur est dite indi��erente lorsque la constante �a laquelle elle se rapporte doitetre d�e�nie, sa valeur n'ayant par contre aucune importance pour l'exemple et latache de classi�cation consid�er�es. Soient par exemple les formules suivantes :{ (D1) : oiseau animal(X) ^ ailes(X; 2) ^ plumes(X; �) dont la signi�cationest un animal ayant deux ailes et des plumes (dont la couleur est indi��erente)est un oiseau .(E1) : oiseau animal(titi) ^ ailes(titi; 2)^ plumes(titi; jaunes), qui signi�el'oiseau titi est un animal ayant deux ailes et des plumes jaunes .Il vient naturellement : D1 ` E1.

82 CHAPITRE 3. LE BIAIS DE LANGAGE{ (D2) : oiseau animal(X) ^ ailes(X; 2) ^ plumes(X; jaunes) signi�e unanimal ayant deux ailes et des plumes jaunes est un oiseau .(E2) : oiseau animal(titi) ^ ailes(titi; 2) ^ plumes(titi; �) signi�e l'oiseautiti est un animal ayant deux ailes et des plumes. L'expert n'a pas pris la peinede mentionner la couleur des plumes car il sait que cette donn�ee est, dans lecas de titi, inutile �a la tache de classi�cation.Il vient �egalement : D2 ` E2.La r�egle d'appariement pour * s'�enonce alors :Toute occurrence du symbole * dans une formule de Lh couvre etest couverte par tout symbole de meme type.Exemples : D E D ? EP (a; �) P (a; b) ouiP (�; �) P (a; b) ouiP (a;A) P (a; �) ouiP (A;A) P (�; �) ouiR(a) R(�) ouiEn contrepartie de son int�eret pratique �evident (possibilit�e de sp�eci�er des con-naissances portant sur la tache de classi�cation, facilitation de l'acquisition desdonn�ees, etc. ), la s�emantique choisie pour le symbole * a des r�epercussions surle cadre th�eorique du couple (`;Lh). Ces derni�eres obligent un raisonnement �a deuxniveaux a�n de conserver la richesse et le bien fond�e s�emantique du langage d'unepart, et une structure adapt�ee �a la m�ethode de recherche d'autre part.{ Au niveau de la s�emantique de Lh, o�u op�ere le test de subsomption, les pro-pri�et�es du symbole * sont bien fond�ees. La validation des hypoth�eses par calculde leur couverture et de leur coh�erence se fait donc au moyen du test `.{ Au niveau de la structure de Lh, o�u op�ere la m�ethode de recherche, les propri�et�esdu symbole * ne sont pas bien fond�ees car la relation ` n'est plus une relationd'ordre. Par exemple, les formules F1 : P (X; a) et F2 : P (�; �) v�eri�ent F1 ` F2et F2 ` F1. La relation ` n'est donc plus antisym�etrique, et un algorithmede recherche fond�e uniquement sur cette relation peut etre confront�e �a desprobl�emes de cycles dans le graphe d'exploration.Une solution consiste alors �a consid�erer une relation `2 plus stricte que ` (c'est-�a-dire telle que 8F1; F2 2 Lh; (F1 `2 F2) ) (F1 ` F2)), qui ait la propri�et�ed'etre une relation d'ordre. Cette relation est trivialement obtenue en posantla r�egle de r�e�ecriture suivante pour * :Toute occurrence de * dans une formule de Lh est �equivalente pour larelation de subsomption `2 �a l'introduction d'une nouvelle variable.

3.2. Implantation du test de subsomption 83En d�eveloppant des op�erateurs unidirectionnels respectant la relation `2, l'al-gorithme de recherche est bien fond�e (voir �gure 3.2).P(*,*)
P(a,b)
P(X,b) P(a,Y)
Treillis défini par2
P(*,*)
P(a,b)
P(X,b) P(a,Y)
Graphe de la relation
initiale (noyau)formule génératriceFig. 3.2: La relation `2 g�en�ere un treillis sur le graphe d�e�nipar la relation `, permettant ainsi une exploration e�cace.R�ecapitulatifLa premi�ere partie de ce chapitre a �et�e l'occasion de d�ecrire le langage de repr�esentationdes hypoth�eses et des instances de SIAO1, que ce soit du point de vue de son expres-sivit�e ou de la complexit�e de la relation de subsomption. Puisque Lh ne permet pas deg�en�erer de d�e�nition auto-r�ef�erente et que, par hypoth�ese, aucun exemple de la base d'ap-prentissage n'est une tautologie, le test de subsomption propos�e est �a la fois correct, com-plet, et d�ecidable pour l'implication logique. Son principal inconv�enient, malheureusementinh�erent �a la nature relationnelle du langage, est sa NP-compl�etude. La seconde partie dece chapitre est donc consacr�ee �a l'implantation d'un test optimis�e pouvant op�erer en untemps raisonnable sur des donn�ees complexes.3.2 Implantation du test de subsomption3.2.1 Raisons motivant l'optimisationImportance et complexit�e du test de subsomptionLe test de subsomption est une composante cruciale de SIAO1 puisqu'il est entre autresutilis�e lors de toute �evaluation d'un nouvel individu. Cependant, ce test est �egalement unpoint critique de l'algorithme pour au moins deux raisons.En premier lieu, le test de subsomption doit etre fait tr�es souvent : pour chaque �evaluationd'un individu, le calcul de la couverture de ce dernier n�ecessite autant de tests qu'il ya d'exemples dans la base d'apprentissage. Ce facteur limitant, qui est commun aux al-gorithmes de type g�en�erer et �evaluer proc�edant par �evaluation de la couverture (parmilesquels la plupart des algorithmes bas�es sur la m�ethodologie de l'�etoile), peut etre att�enu�e

84 CHAPITRE 3. LE BIAIS DE LANGAGEpar l'utilisation de strat�egies sp�eci�ques (comme par exemple l'�echantillonnage de la based'apprentissage [Cochran77, Brezellec99], di��erentes techniques de court-circuit ([Augier et al.96]et chapitre 4 section 4.2.3)), ou bien encore trait�e par des m�ethodes de parall�elisation(chapitre 5). Bien que ce chapitre ne soit pas consacr�e �a ce premier facteur limitant, il estcependant important de remarquer qu'il n'est pas rare qu'en pratique plusieurs millionsde tests de subsomption soient n�ecessaires pour un apprentissage.D'autre part, le test de subsomption peut etre extremement complexe, ce facteur d�ependantdu langage utilis�e. Dans le cas de la logique d'ordre 0, une d�e�nition et un exemplecomportent le meme nombre �xe p d'attributs Ai, et le test de subsomption consiste alorsen une succession d'au plus p tests d'appartenance entre chaque valeur vi de l'exemple etle domaine di correspondant de la d�e�nition (voir �gure 3.3).

3.2. Implantation du test de subsomption 85Exemple :D�e�nition : A1 A2 ... Ak ... Apv1 v2 ... vk ... vp2 2 2 2d1 d2 ... dk ... dp p tests d'appartenancede type vi 2 di sontn�ecessaires dans le piredes cas.Fig. 3.3: Complexit�e du test de subsomption en logique d'ordre 0.La complexit�e du test de subsomption en logique d'ordre 0 est donc dans le pire descas lin�eaire en fonction du nombre d'attributs de la d�e�nition (ou de l'exemple). Parcontre, dans le cas du syst�eme SIAO1, o�u l'on travaille dans un langage qui est un sous-ensemble des formules de la logique d'ordre un, la complexit�e du test de subsomption estexponentielle en fonction du nombre de litt�eraux de la d�e�nition. En e�et, comme l'ontmontr�e le chapitre 1 (section 1.5.1) et la section pr�esentant le contexte th�eorique du testde �-subsomption, en supposant que la d�e�nition D (resp. l'exemple E) soit sous la formed'une conjonction D1 ^ ::: ^D� (resp. E1 ^ ::: ^ E") de � (resp. ") atomes ne comportantaucun symbole de fonction, le test de subsomption consiste �a trouver pour chaque atomede D un atome de E compatible. De plus, comme les relations entre atomes occasionn�eespar les variables rendent ces choix interd�ependants (les substitutions �(Di; Ej) doivent etrecompatibles entre elles), "� essais sont n�ecessaires dans le cas d'un test de subsomption�enum�erant les di��erentes combinaisons possibles4 (voir �gure 3.4).(D1,E1)θ
θ θ(D2,E1) θ(D2,Ek) (D2,E
(D1,Ek)θ θ (D1,E
(D2,E1)θ (D2,Ek)θ (D2,Eθ θ(D2,Ek)θ(D2,E1)θ
θ (D ,E1) θ θ (D ,Eδ(D ,Ek) δδ ε)
ε)(D2,Eε)ε)
ε)
"� tests de composition de substitutions sont n�ecessaires dans le pire des cas.Fig. 3.4: Complexit�e du test de subsomption dans le cas de SIAO1.Cette section pr�esente le test de �-subsomption tel qu'il est mis en �uvre dans de nombreuxsyst�emes de PLI et motive le d�eveloppement d'un test de subsomption optimis�e adapt�eau langage de SIAO1.4L'implantation habituelle de ce test, d�etaill�ee ci-apr�es, est fond�ee sur une d�e�nition r�ecursive avecpossibilit�e de retour-arri�ere pr�ecoce. Bien que cette d�e�nition permette de r�eduire le nombre de tests decompatibilit�e dans le cas de certaines instances, la complexit�e dans le pire des cas est toujours "�.

86 CHAPITRE 3. LE BIAIS DE LANGAGELe test de �-subsomption canoniqueLe test de �-subsomption canonique de deux clauses D : Dtete D1 ^ ::: ^ Dn etE : Etete E1 ^ ::: ^ Ep (dont on peut trouver une d�e�nition simple en PROLOG dans[Kietz et al.94]) construit r�ecursivement une substitution solution �a l'aide d'une fonctionbool�eenne apparie atomes(a1,a2,�) rendant vrai si les atomes a1 et a2 s'apparient suiv-ant une substitution �./* Test de �-subsomption canonique */Fonction �-subsomption(D,E)Si apparie atomes(Dtete,Etete,�)Alors ! apparie corps(fD1 ^ ::: ^Dng, fE1 ^ ::: ^ Epg, fE1 ^ ::: ^ Epg, �)Sinon ! �echecFonction apparie corps(Drestant, Erestant, Ecorps, �)Si Drestant = ; Alors ! succ�esSi Erestant = ; Alors ! �echecSi (apparie atomes(D1,E1,�0)) ^ (�; �0 sont compatibles)Alors Si apparie corps(fVni=2Dig, Ecorps, Ecorps, � [ �0) ! succ�esSinon ! apparie corps(Drestant, fVpj=2Ejg, Ecorps, �)Bien qu'il soit possible d'implanter le test ` �a l'aide d'une architecture similaire �a celle dutest `� canonique, de nombreuses observations { r�ealis�ees dans un contexte exp�erimental{ concernant le comportement de cette proc�edure motivent l'implantation d'un test opti-mis�e.Changement de complexit�e lors de l'aplatissementUne premi�ere interrogation provient du fait que le test de �-subsomption canonique aun comportement tr�es di��erent suivant la syntaxe de la formule sur laquelle il s'ap-plique, et ce meme �a s�emantique identique. En consid�erant par exemple le domaine dela chimie mol�eculaire, dans lequel on dispose des pr�edicats atome(identi�ant,symbole)et liaison(identi�ant,identi�ant,type de la liaison), on pourra repr�esenter la mol�ecule dedioxyde de soufre (de structure jO S = On= ) par la formule suivante :atome(X1; o) ^ atome(X2; s) ^ atome(X3; o) ^ liaison(X1; X2; dative 2e) ^liaison(X2; X3; covalente 4e)Fig. 3.5: Description relationnelle classique de la mol�ecule de dioxyde de soufre.Cependant la formule aplatie correspondante (qui est strictement �equivalente) aura un

3.2. Implantation du test de subsomption 87cout d'appariement (en nombre de retours-arri�ere) plus important puisque le test de �-subsomption canonique, qui est totalement guid�e par la syntaxe, fera des retours-arri�ereinutiles sur tous les pr�edicats ajout�es qui correspondent aux constantes aplaties.atome(X1; X2) ^ o(X2) ^ atome(X3; X4) ^ s(X4) ^ atome(X5; X6) ^ o(X6) ^liaison(X1; X3; X7) ^ dative 2e(X7) ^ liaison(X3; X5; X8) ^ covalente 4e(X8))(Les atomes encadr�es correspondent aux constantes aplaties.)Fig. 3.6: Description aplatie de la mol�ecule de dioxyde de soufre.Id�ealement, un test de �-subsomption optimis�e devrait, en ne capturant que la complexit�eintrins�eque associ�ee �a l'aspect relationnel de la formule, utiliser une repr�esentation rendantla recherche aussi ind�ependante que possible de la formulation syntaxique. En particulier,il serait int�eressant que dans le cas de formules isomorphes sur le plan relationnel cetterepr�esentation rende la recherche ind�ependante de l'ordre des atomes ou de leur nombre.Un probl�eme provenant du domaine de la chimie mol�eculaireUn second motif pour remettre en question le test de �-subsomption canonique vient del'observation de son comportement sur des formules fortement relationnelles. Par exem-ple la base Mutagenesis (voir [Debnath et al.91, Srinivasan et al.94], ainsi que l'annexeB, section B.4) d�ecrit des mol�ecules comportant typiquement entre 20 et 40 atomes : siles algorithmes d'apprentissage travaillant par sp�ecialisation sont alors fortement ralentis,puisqu'en testant des hypoth�eses comportant 1, 2, 3, ... atomes sur une mol�ecule com-portant 40 atomes le cout de l'appariement sera dans le pire des cas de 401, 402, 403, ... ;il en va tout autrement d'un algorithme ascendant qui sera confront�e, d�es les premi�eresvariabilisations �a un espace de recherche d'une taille dans le pire des cas de 4040. Dansce dernier cas, et contrairement aux observations concernant la variation de la complexit�elors d'un changement de repr�esentation, le probl�eme est crucial car il ne s'agit pas demesurer l'acc�el�eration ou le ralentissement de l'algorithme mais de constater le fait qu'ilfonctionne correctement ou bien qu'au contraire il est inutilisable car il ne termine pas.Simpli�cation des clausesUne derni�ere raison pour optimiser le test de �-subsomption vient de la n�ecessit�e dedisposer d'un algorithme de simpli�cation des clauses e�cace. Bien que la simpli�cationd'une clause puisse etre envisag�ee de bien des mani�eres di��erentes5, nous nous int�eressonsici �a un probl�eme d�ecidable dont l'algorithme de simpli�cation associ�e est NP-complet.D�e�nition 3.2 Relation d'�equivalence fond�ee sur la �-subsomptionDeux clauses C et D sont dites �-�equivalentes (not�e C �� D) si C `� D et D `� C.5Par exemple, une clause est dite redondante lorsqu'elle est simpli�able �etant donn�e un ensembled'autres clauses (les connaissances du domaine). La redondance est cependant un probl�eme ind�ecidabledans le cas g�en�eral [NC et al.97].

88 CHAPITRE 3. LE BIAIS DE LANGAGED�e�nition 3.3 Clause r�eduiteUne clause C est dite r�eduite si il n'existe aucun sous-ensemble D � C tel que C �� D.Une clause r�eduite D telle que C �� D et D � C est appel�ee r�eduction de C.Exemple : La clause C = p(x; y) ^ p(y; x) ^ p(y; y) peut etre simpli��ee en D =p(y; y) qui est une r�eduction de C.Une propri�et�e remarquable des clauses r�eduites est leur unicit�e : si D1 et D2 sont deuxclauses r�eduites d'une meme clause C, alors D1 et D2 sont identiques �a une substitutionde renommage pr�es. Comme le montrent les lignes suivantes, cette propri�et�e est plusg�en�eralement valable pour toutes les clauses r�eduites �-�equivalentes.Propri�et�e 3.5 Unicit�e des clauses r�eduitesSoient C et D deux clauses r�eduites. Si C �� D, alors C et D sont identiques �a unesubstitution de renommage pr�es.En e�et, si C �� D, il existe des substitutions � et � telles que C� � D et D� � C. Deplus, puisque C et D sont r�eduites, on a : C�� = C et D�� = D : � et � sont donc dessubstitutions de renommage.[Gottlob et al.93] proposent un algorithme e�ectuant au plus jCj tests de �-subsomptionainsi que des arguments concernant son optimalit�e. Cet algorithme prend en entr�ee uneclause C et retourne sa r�eduction. Le pseudo-code est le suivant :/* Algorithme FASTCONDENSE */D CE CTant que (E 6= ;)Choisir L 2 ESi 9L0 2 D n fLg : L `� L0Alors Si D n fLg `� CAlors D D n fLgE E n fLg! DL'int�eret en PLI d'une proc�edure e�cace de simpli�cation des clauses est double :{ En ce qui concerne l'utilisateur, un algorithme de simpli�cation des clauses peutcontribuer �a une meilleure intelligibilit�e du r�esultat.{ En ce qui concerne le syst�eme d'apprentissage, l'algorithme de simpli�cation permetde retirer de l'espace de recherche les doublons. D'autre part, le fait de travailleravec des formules de taille minimale peut r�eduire le cout de certains calculs.

3.2. Implantation du test de subsomption 893.2.2 Architecture g�en�eraleL'algorithme est organis�e en trois parties. La premi�ere traite tout d'abord le cas triv-ial de l'appariement de deux atomes quelconques de D et E, ce qui permet d'une partde traiter imm�ediatement les cas de succ�es ou d'�echec d�eg�en�er�es et d'autre part de con-struire une repr�esentation adapt�ee de l'espace de recherche. L'approche suivie consiste�a travailler directement sur les substitutions partielles (entre litt�eraux), ce qui permetune reformulation non r�ecursive du probl�eme d�ecrivant explicitement dans un tableau lesjEj:jDj contraintes associ�ees. La composante complexe du probl�eme (d�etermination de �)ayant �et�e isol�ee, la seconde partie de l'algorithme met �a pro�t des propri�et�es relatives �al'ind�ependance, la combinaison ou l'incompatibilit�e des contraintes a�n de r�eduire l'espacede recherche. La derni�ere partie de l'algorithme est d�edi�ee �a la recherche de la solutiondans l'espace simpli��e �a l'aide d'une technique classique propageant les contraintes aucours de la construction de la solution.3.2.3 Traitement de la partie �xeSoit jDj (resp. jEj) le nombre d'atomes de D (resp. E). L'ensemble V ars(D) =fX1; :::; Xng des variables typ�ees apparaissant dans la d�e�nition est connu. Il est �egalementfait r�ef�erence �a un algorithme d'appariement de deux atomes � 2 D et " 2 E, not�eapparie atomes(�; "), qui rend vrai ou faux ainsi que la substitution ��;" n�ecessaire �a lar�ealisation de l'appariement dans le cas o�u ce dernier est possible.Exemple :{ Types num�eriques : tn1 ; tn2 .{ Types symboliques : ts1 = fa; b; cg; ts2 = fg; h; ig.{ Hi�erarchie sur ts1 : a ! b.{ Symboles de pr�edicat : P (tn1 ; tn2 ; ts1; ts2); Q(tn1 ; tn2 ; ts1; ts2).{ Th�eorie : P ! Q.On a : apparie atomes(Q(1; [2; 4]; fb _ cg; X2); P (�; 3; a; g)) = vrai et � = fX2=ggRemarques :{ Le symbole � s'apparie avec tout autre symbole du meme type et ne pose doncaucune contrainte sur �.{ On pourra noter par abus � = fX2=gg = fX1=�; X2=g; g = [�; g] a�n de repr�esenterles contraintes de mani�ere plus concise.Outre le traitement des cas triviaux (succ�es final et �echec final), cette partie del'algorithme g�en�ere les ensembles V als(Xi) des valeurs envisageables pour Xi ainsi que

90 CHAPITRE 3. LE BIAIS DE LANGAGEL, un tableau de listes de substitutions partielles qui permet de m�emoriser pour chaqueatome non ferm�e de D la liste des contraintes �el�ementaires associ�ees./* Test de subsomption optimis�e pour SIAO1, partie 1/5 *//* Traitement de la partie fixe. */parcourir D ; pour chaque atome � 2 D :Si � est ferm�e :Si 9" 2 E = apparie atomes(�; ")Alors ! sortir et passer �a un autre atome �Sinon ! �echec finalSinon : parcourir tous les " 2 E :Si apparie atomes(�; ") Alors ajouter la substitution �(�;") �a L(�) etmettre �a jour V als(Xj) pour les variables Xj instanci�ees dans ��;"Si 6 9" 2 E = apparie atomes(�; "), Alors ! �echec finalSi (L a au plus une ligne) _ (8Xi; jV als(Xi)j = 1) Alors ! succ�es finalExemple :{ Types num�eriques : aucun, Types symboliques : ts1 = fa; b; c; d; eg.{ Symboles de pr�edicat : objet(ts1); lien(ts1; ts1){ Hi�erarchie sur ts1 : aucune, Th�eorie : aucune.{ D : objet(X) ^ objet(Y ) ^ objet(Z) ^ lien(X; Y ) ^ lien(Y; Z) ^ lien(Z;X).{ E : objet(a) ^ objet(b) ^ objet(c) ^ objet(d) ^ objet(e) ^ lien(a; b) ^ lien(b; c) ^lien(c; d) ^ lien(d; b).On a : L = 2666666664 objet1 : [a; �; �] [b; �; �] [c; �; �] [d; �; �] [e; �; �]objet2 : [�; a; �] [�; b; �] [�; c; �] [�; d; �] [�; e; �]objet3 : [�; �; a] [�; �; b] [�; �; c] [�; �; d] [�; �; e]lien1 : [a; b; �] [b; c; �] [c; d; �] [d; b; �]lien2 : [�; a; b] [�; b; c] [�; c; d] [�; d; b]lien3 : [b; �; a] [c; �; b] [d; �; c] [b; �; d]3.2.4 Simpli�cation de la partie contrainteOutre la r�esolution des succ�es et �echecs triviaux, la premi�ere partie de l'algorithme apermis le passage d'une formulation classique du probl�eme �a une repr�esentation adapt�ee(un tableau de contraintes sur les substitutions), puisque :

3.2. Implantation du test de subsomption 91{ On obtient une vue g�en�erale du probl�eme rendant possible d'une part un travailglobal sur les contraintes en vue d'�elaguer autant que possible l'espace de rechercheet d'autre part un traitement optimis�e du probl�eme puisqu'il n'est plus d�e�ni demani�ere r�ecursive.{ Tous les tests de r�esultat constant, c'est-�a-dire li�es �a la composante syntaxique �xedu probl�eme (recherche des atomes, tests de couverture des pr�edicats, tests sur lestypes de arguments, tests de couverture des arguments constants, ...) ne �gurentplus dans l'�enonc�e : ils ont d�ej�a �et�e r�ealis�es lors du traitement de la partie �xe duprobl�eme.Le tableau obtenu L comporte un nombre n de lignes �egal au nombre d'atomes �i nonferm�es contenus dans D. Chaque ligne i de L est constitu�ee d'une ou plusieurs contraintes�i;j correspondant aux conditions n�ecessaires �a l'appariement de �i avec un atome de E.L = 26664 �1 : �1;1 �1;2 ::: �1;p1�2 : �2;1 �2;2 ::: �2;p2:::�n : �n;1 �n;2 ::: �n;pnFig. 3.7: Repr�esentation tabulaire du test de subsomption.Comme on l'a vu dans le paragraphe pr�ec�edant d�etaillant le fonctionnement de la m�ethodeapparie atomes, une fois l'ensemble V ars(D) ordonn�e, toute contrainte d'uni�cation �i;jpeut etre repr�esent�ee par une liste de taille �xe �egale �a jV ars(D)j dont chaque �el�ement,not�e �i;j(k), est soit un symbole de constante c, soit une �etoile �. Soit E l'ensemble detoutes les contraintes � ; il est possible de d�e�nir formellement les propri�et�es suivantes :D�e�nition 3.4 Compatibilit�eOn dit que deux contraintes �1 et �2 sont compatibles, et on notera �1 �c �2, lorsque :8k 2 [1::jV ars(D)j], soit �1(k) = � ou encore �2(k) = �, soit �1(k) = �2(k). Dans le cascontraire on dira que �1 et �2 ne sont pas compatibles, ce qui sera not�e �1 :c �2.D�e�nition 3.5 G�en�eralit�eOn dit que la contrainte �1 est plus g�en�erale ou �equivalente �a la contrainte �2, et on notera�1 �c �2 si et seulement si 8k 2 [1::jV ars(D)j], soit �1(k) = �, soit �1(k) = �2(k).Propri�et�e 3.6 �cLa relation �c est une relation d'ordre partiel large bien fond�ee sur E.En e�et d'une part �c est r�e exive, antisym�etrique et transitive, et d'autre part il nepeut exister de suite in�nie strictement d�ecroissante d'�el�ements de E .Propri�et�e 3.7 tDeux contraintes �1 et �2 ont toujours une borne sup�erieure � not�ee �1 t �2 d�e�nie par :

92 CHAPITRE 3. LE BIAIS DE LANGAGE{ si �1(k) = �2(k), alors �(k) = �1(k){ sinon �(k) = �.Propri�et�e 3.8 Structure de EL'espace E des contraintes est un sup-demi treillis. Le plus grand �el�ement de E est [�; �; :::; �].E est un sup-demi treillis puisque toute paire d'�el�ements de E admet une borne sup�erieure.Par contre, E n'est pas un treillis car deux contraintes quelconques ne poss�edent pasobligatoirement de borne inf�erieure.D�e�nition 3.6 CombinaisonOn dit que la contrainte �3 est la combinaison des deux contraintes �1 et �2, et on notera�1 +c �2 = �3, si et seulement si :{ �1 et �2 sont compatibles ;{ 8k 2 [1::jV ars(D)j], si �1(k) = � alors �3(k) = �2(k), sinon �3(k) = �1(k).Exemples : Soient �1 = [a; b; �; �]; �2 = [a; �; c; �]; �3 = [a; b; c; �] et �4 = [d; �; �; �]On a (entre autres) : �1 �c �2 ; �1 +c �2 = �3 et �1 :c �4 ;Dans ce contexte, la recherche d'une substitution � telle que D� � E revient �a trouverun ensemble de contraintes compatibles E = f�1;i1 ; �2;i2 ; :::; �n;ing puisque par constructionla substitution � r�esultant de leur combinaison permet l'appariement de tout atome �i deD avec un atome "j de E. R�eciproquement, s'il n'existe aucun ensemble E de contraintescompatibles, alors il n'existe pas de substitution � telle que D� � E.L = 266664 �1 : �1;1 ::: �1;i1 ::: �1;p1�2 : �2;1 ::: �2;i2 ::: �2;p2:::�n : �n;1 ::: �n;in ::: �n;pnL � (�1;1 _ �1;2 _ ::: _ �1;p1)| {z }appariement de �1 ^ (�2;1 _ �2;2 _ ::: _ �2;p2)| {z }appariement de �2 ^::: ^ (�n;1 _ �n;2 _ ::: _ �n;pn)| {z }appariement de �nSubstitution solution : � = �1;i1 +c �2;i2 +c :::+c �n;inFig. 3.8: R�esolution du test de subsomption.La partie de l'algorithme d'appariement consacr�ee �a la r�eduction de la taille de l'espaceavant de proc�eder �a la recherche proprement dite est bas�ee sur le principe que tout �elagagede cout raisonnable (donc au plus polynomial en temps et en m�emoire) doit etre e�ectu�e,puisque le gain apport�e est exponentiel. Parmi toutes les m�ethodes de simpli�cation,la seule pouvant conduire �a une augmentation de taille m�emoire (la combinaison des

3.2. Implantation du test de subsomption 93contraintes ) est control�ee par l'utilisateur grace �a un param�etre �x�e lors de l'initialisationde SIAO1. Cette partie se d�eroule en quatre �etapes :1. D�etection des composantes ind�ependantes du probl�eme.2. Suppression des contraintes redondantes ou globalement insatis�ables.3. Combinaison control�ee des contraintes et r�eorganisation de la table.

94 CHAPITRE 3. LE BIAIS DE LANGAGED�etection des composantes ind�ependantes du probl�emeUne premi�ere technique de r�eduction de l'espace de recherche consiste �a isoler d'�eventuellescomposantes ind�ependantes. La d�etection de telles composantes permet un gain con-sid�erable puisque n composantes ind�ependantes C1 , ..., Cn comportant respectivementjC1j, ..., jCnj choix possibles peuvent alors etre r�esolues avec un cout dans le pire des casde Pni=1 jCij au lieu de Qni=1 jCij. Dans le cas pr�esent, des sous-ensembles de lignes peuventetre r�esolus ind�ependamment si leurs contraintes portent sur des ensembles de variablesdisjoints. Comme l'illustre l'algorithme ci-dessous, de telles composantes peuvent etreais�ement obtenues grace �a l'utilisation de masques bool�eens m�emorisant la pr�esence oul'absence de contraintes portant sur une variable dans une ligne donn�ee. On notera par lasuite � de tels masques (qui sont compos�es d'une liste de jV ars(D)j bool�eens) et �(k) lekieme �el�ement de �.D�e�nition 3.7 Masque �i d'une ligne de contraintes �iOn dit que �i est le masque associ�e �a la ligne �i si et seulement si :8j 2 [1::jV ars(D)j]; �(j) = ( 1 si 9k = �i;k(j) 6= � ;0 sinon:D�e�nition 3.8 Intersection et union de deux masquesL'intersection (resp. union) de deux masques �1 et �2, not�ee �1 \ �2 (resp. �1 [ �2) estle masque � = 8k; �(k) = �1(k) ^ �2(k) (resp. �1(k) _ �2(k)).L'algorithme suivant d�etermine l'ensemble C des composantes ind�ependantes de L./* Test de subsomption optimis�e pour SIAO1, partie 2/5 *//* D�etection des composantes ind�ependantes du probl�eme. */C �composante courante �couverts �8k 2 [1::n]; �k masque(�k)Tant que 9�i = �i 62 couvertscomposante courante composante courante [ f�igcouverts couverts [ f�igTant que 9�j = �j \ �i 6= (0; :::; 0)�i �i [ �jcomposante courante composante courante [ f�jgcouverts couverts [ f�jgC C [ fcomposante courantegcomposante courante �Ordonner L en groupant ensemble les lignes appartenant �a la meme composante.

3.2. Implantation du test de subsomption 95Exemple :Soit : L = 26666664 Masque Contraintes�1 = [1; 0; 0; 0] [a; �; �; �] [b; �; �; �] [e; �; �; �]�2 = [0; 0; 0; 1] [�; �; �; a] [�; �; �; d]�3 = [0; 1; 1; 0] [�; c; e; �] [�; �; d; �] [�; e; �; �] [�; a; b; �]�4 = [1; 0; 1; 0] [a; �; d; �] [e; �; e; �] [b; �; b; �]Le d�eroulement de l'algorithme est le suivant :Initialisation : C f�g, composante courante f�g, couverts f�g.�Etape 1 : composante courante = f�1gL'it�eration permet d'ajouter �a composante courante �4 puis �3.On obtient : C = ff�1; �4; �3gg.�Etape 2 : composante courante = f�2gOn ne peut plus rien ajouter �a composante courante.On obtient : C = ff�1; �4; �3g; f�2gg.Le r�esultat �nal est :L = 26666664 Masque Contraintes�1 = [1; 0; 0; 0] [a; �; �; �] [b; �; �; �] [e; �; �; �]�3 = [0; 1; 1; 0] [�; c; e; �] [�; �; d; �] [�; e; �; �] [�; a; b; �]�4 = [1; 0; 1; 0] [a; �; d; �] [e; �; e; �] [b; �; b; �]�2 = [0; 0; 0; 1] [�; �; �; a] [�; �; �; d]Remarque :La double ligne d�enote les composantes ind�ependantes et agit comme une coupure lorsde la recherche : apr�es avoir trouv�e un ensemble de contraintes compatibles pour les troispremi�eres lignes, la recherche peut se poursuivre en ignorant ces derni�eres. De mani�ereg�en�erale, lors de la recherche, tout �echec au niveau d'une coupure produira un �echecg�en�eral sans avoir �a remettre en question les choix op�er�es avant celle-ci.Suppression des contraintes redondantes ou globalement insatis�ablesUne fois les composantes ind�ependantes d�etermin�ees, les autres m�ethodes de r�eductionde l'espace de recherche ne travailleront plus que sur chaque composante. Ce paragraphepr�esente trois m�ethodes de pr�e-�elagage permettant de r�eduire l'espace de recherche, quece soit en largeur (diminution du facteur de branchement) ou en profondeur (suppressiondes lignes redondantes). Ces m�ethodes proviennent de la g�en�eralisation d'observationsexp�erimentales concernant la structure de L qui peuvent etre formul�ees plus intuitivementcomme suit :

96 CHAPITRE 3. LE BIAIS DE LANGAGERedondances intra-ligneToute contrainte plus sp�eci�que ou �equivalente �a une autre contrainte d'une memeligne peut etre supprim�ee.Exemple :Soit L = " �1;1[a; �; �] �1;2[b; c; �] �1;3[a; c; �] �1;4[c; a; �]�2;1[a; b; c] �2;2[b; c; a] �2;3[a; �; c] �2;4[c; a; b] �2;5[a; �; c]Comme �1;1[a; �; �] �c �1;3[a; c; �], on peut supprimer �1;3.Comme �2;3[a; �; c] �c �2;1[a; b; c], on peut supprimer �2;1.Comme �2;3[a; �; c] �c �2;5[a; �; c], on peut supprimer �2;5[a; �; c].Redondances inter-lignesSi toutes les contraintes d'une ligne sont soit plus strictes ou �equivalentes, soit in-compatibles avec toutes les contraintes d'une autre ligne, alors on peut supprimercette derni�ere.Exemple :Soit L = " �1;1[a; �; �] �1;2[b; �; �]�2;1[a; b; c] �2;2[b; c; a] �2;3[a; �; c] �2;4[b; a; �]On peut supprimer la premi�ere ligne du tableau.Cas particulier : Dans le cas o�u toutes les contraintes d'une ligne sont incompatiblesavec toutes les contraintes d'une autre ligne, aucun appariement n'est possible et ona imm�ediatement un �echec final .Exemple :Soit L = " �1;1[a; �; �] �1;2[b; a; �] �1;3[c; b; �]�2;1[b; c; a] �2;2[c; a; b] �2;3[b; c; c]Il n'y a pas appariement.Incompatibilit�es globalesS'il existe une contrainte �i;j incompatible avec l'ensemble des contraintes d'uneligne i0 6= i, alors on peut supprimer �i;j.Exemple :Soit L = " �1;1[a; �; �] �1;2[b; a; �] �1;3[c; b; �]�2;1[b; c; a] �2;2[c; b; a] �2;3[a; b; c]On peut supprimer �1;2 et �2;1.L'algorithme qui d�ecoule de ces observations est imm�ediat :

3.2. Implantation du test de subsomption 97/* Test de subsomption optimis�e pour SIAO1, partie 3/5 *//* Supp. des contraintes redondantes ou globalement insatisfiables. */8l; i1; i2 2 [1::n]� [1::pl]� [1::pl] tels que i1 6= i2Si �l;i1 �c �l;i2 Alors supprimer �l;i28l1; l2 2 [1::n]� [1::n] tels que l1 6= l2 et l1; l2 ne sont pas ind�ependantesSi 8i1; i2 2 [1::pl1 ]� [1::pl2 ] , �l1;i1 :c �l2;i2 Alors ! �echec finalSi 8i1; i2 2 [1::pl1 ]� [1::pl2 ] , (�l1;i1 :c �l2;i2) _ (�l1;i1 �c �l2;i2)Alors supprimer l1fin point fixe fauxTant que :fin point fixefin point fixe vrai8l1; i1; l2 2 [1::n]�[1::pl1 ]�[1::n] tels que l1 6= l2 et l1; l2 ne sont pas ind�ependantesSi 8i2 2 [1::pl2 ]; �l1;i1 :c �l2;i2 Alorssupprimer �l1;i1fin point fixe fauxSi 9l 2 [1::n] = l ne contient plus aucune contrainte �, Alors ! �echec finalCombinaison control�ee des contraintes et r�eorganisation de la tableApr�es avoir d�ecoup�e la table des contraintes suivant ses composantes ind�ependantes puissupprim�e au sein de chaque composante les contraintes redondantes ou incompatibles avecune autre ligne, il est encore possible d'�etudier les incompatibilit�es pour un nombre n � 2de lignes. Soit par exemple la table 3.1.L = 266664 Masque Contraintes[1; 1; 0] �1;1[a; b; �] �1;2[b; c; �] �1;3[b; a; �] �1;4[c; d; �] �1;5[d; d; �][0; 1; 1] �2;1[�; b; d] �2;2[�; c; a] �2;3[�; a; c] �2;4[�; d; b][1; 0; 1] �3;1[a; �; a] �3;2[b; �; d] �3;3[b; �; b] �3;4[c; �; c] �3;5[d; �; b]Tab. 3.1: Contraintes incompatibles par combinaison.On v�eri�e ais�ement que :1. il n'existe aucune composante ind�ependante s�eparable ;2. il n'existe aucune redondance intra-ligne ;3. il n'existe aucune redondance inter-lignes ;4. il n'existe aucune incompatibilit�e globale ;

98 CHAPITRE 3. LE BIAIS DE LANGAGEce qui implique que les m�ethodes de simpli�cation �evoqu�ees jusqu'�a pr�esent seront inef-�caces sur cette table, qui cependant est di�cile puisque la seule substitution solutionest [d; d; b], obtenue suivant le chemin �1;5 +c �2;4 +c �3;5. Comme sugg�er�e pr�ec�edemment,la di�cult�e provient du fait qu'une substitution �i;j peut etre compatible avec n ensem-bles disjoints de substitutions sans pour autant etre supprim�ee. Ainsi, dans l'exemplepr�ec�edant, il existe de nombreux groupes de substitutions f�1;x; �2;y; �3;zg tels qu'une seuledes substitutions est compatible avec les deux derni�eres (qui sont donc incompatibles entreelles). La notion d'incompatibilit�e globale est alors insu�sante, puisqu'il faut etre capablepour d�etecter l'incompatibilit�e de consid�erer la compatibilit�e d'une substitution avec unensemble de lignes du tableau. La �gure 3.9 repr�esente le probl�eme relatif au tableau 3.1d'une mani�ere tr�es proche de [Sche�er et al.96] :θ
θ
(1,1)
(2,1)
θ (3,1)
θ (1,1)
θ (1,5)θ(1,4)θ(1,3)(1,2) θ
(2,4)θ(2,3)θ(2,2)θ
(3,5)θ(3,4)θ(3,3)θ(3,2)θ
(1,5)θ(1,4)θ(1,3)θ(1,2)θFig. 3.9: Vue graphique du probl�eme d'incompatibilit�e des contraintes par combinaison.�A chaque n�ud du graphe est associ�ee une substitution partielle correspondant �aune contrainte du tableau. A�n de conserver l'organisation du tableau et d'am�eliorer lalisibilit�e, l'organisation du probl�eme en lignes est reprise, et la premi�ere ligne est r�ep�et�eeen bas du graphe. Deux n�uds appartenant �a deux lignes di��erentes sont reli�es par unarc si les substitutions associ�ees sont compatibles.Sous cette forme, la recherche d'une substitution solution pour le probl�eme de l'ap-pariement consiste �a trouver un chemin6 entre un n�ud quelconque de la premi�ere ligneet le meme n�ud �1;x r�ep�et�e sur la derni�ere ligne. L'unique solution, qui �gure en grassur le graphe, n'est trouv�ee (dans le cas d'une recherche classique) qu'apr�es un nombreimportant d'essais inutiles.Une solution pour r�eduire, voire supprimer la composante inutile du graphe consiste �acombiner les lignes entre elles :D�e�nition 3.9 �cOn appelle composition de deux ensembles de contraintes E1 et E2 l'ensemble E1 �c E2 =S�12E1;�22E2f�1 +c �2g.6A�n de dissiper toute m�eprise, il para�t n�ecessaire de pr�eciser que le probl�eme �etant ici de taille trois,la recherche d'une clique de trois n�uds dans le graphe correspondant au tableau est �equivalente �a larecherche d'un chemin dans le graphe avec r�ep�etition de ligne. Bien entendu, dans le cas g�en�eral (n > 3)la recherche d'une clique de taille n n'est pas �equivalente �a la recherche d'un chemin, et la simpli�cationapport�ee par la repr�esentation ci-dessus n'est plus exploitable.

3.2. Implantation du test de subsomption 99Cependant, la combinaison de deux lignes peut produire dans le pire des cas un accroisse-ment exponentiel de la taille de la table des contraintes, et ce meme lorsque les lignesregroup�ees ne sont pas ind�ependantes :Propri�et�e 3.9 jE1 �c E2j (cas g�en�eral).On a toujours : 0 � jE1 �c E2j � jE1j:jE2j.Propri�et�e 3.10 jE1 �c E2j (apr�es �elagage).Lorsque E1 et E2 ne sont pas ind�ependants et ne comportent aucune contrainte globalementincompatible, on a : Max(jE1j; jE2j) � jE1 �c E2j < jE1j:jE2j.D�e�nition 3.10 Taux de compressionOn appelle taux de compression le rapport : Tc(E1; E2) = 1� jE1�cE2jjE1j:jE2j .L = 26664 (1)�(k;1) ::: �(k;pk)�(k+1;1) ::: �(k+1;pk+1)(2) combinaison�! L = 264 (1)�(k0;1) ::: �(k0;jEk�cEk+1j)(2)Fig. 3.10: Gain apport�e par la combinaison de lignes.Comme le montre la �gure 3.10, le gain produit par la combinaison des deux lignes k etk+1 en une ligne k0 lors de l'exploration de l'espace peut etre mesur�e en nombre de testsde compatibilit�e �evit�es lors de la prise en compte des contraintes des deux lignes (soitjE1j:jE2j� jE1�c E2j) ou encore comme un ratio d�e�nissant un taux de compression Tc (cf.d�e�nition 3.10). Un premier �elagage est obtenu lors de l'exploration de la partie sup�erieuredu tableau. En e�et le cout de la prise en compte des lignes k et k + 1 peut etre r�eduit �achaque retour sur �echec dans la partie (1) { et il y en a dans le pire des cas un nombreexponentiel par rapport au nombre de lignes de (1) { d'un facteur Tc. La r�eduction secomporte alors comme une m�emoire �evitant de reproduire lors de chaque prise en comptede ces lignes les retour-arri�eres sur �echec entre les lignes k et k+1. De plus, l'�elagage cumul�ede plusieurs (k) combinaisons de lignes produit �egalement une d�ecroissance exponentiellede la taille de l'espace de recherche, ce dernier �etant globalement r�eduit d'un facteurQi=ki=1 Tci ( = Tck dans le cas d'un gain Tci constant ).En cons�equence, l'algorithme controlera la combinaison des lignes en fonction de la tailledes lignes r�esultant des di��erents regroupements possibles. En e�et, non seulement l'ac-croissement exponentiel de la taille de la table rend la combinaison syst�ematique de lignesimpossible, mais cette derni�ere n'est pas souhaitable puisque son int�eret du point de vuede la recherche est proportionnel au taux de compression apport�e. Comme le d�ecrit lepseudo-code ci-dessous, les lignes sont regroup�ees suivant une strat�egie de type meilleur

100 CHAPITRE 3. LE BIAIS DE LANGAGEd'abord , et ce tant que la taille de la ligne r�esultant du regroupement envisag�e ne d�epassepas une borne �x�ee et qu'il existe des lignes non ind�ependantes optimisables.Pour �nir, le tableau peut etre r�eorganis�e d'une part en for�cant la prise en compte des con-traintes in�evitables d�es le d�ebut de la recherche (ce qui r�eduit d'autant l'espace �a explorer),et d'autre part en appliquant une heuristique de type les composantes ind�ependantes lesmoins complexes d'abord , comme d�ecrit dans la seconde partie du pseudo-code./* Test de subsomption optimis�e pour SIAO1, partie 4/5 *//* Combinaison control�ee des contraintes. */8Ci (composante ind�ependante) :fin point fixe fauxTant que :fin point fixetrouver (li; lj) 2 Ci � Ci tels que(li 6= lj) ^ (jli �c ljj minimum)Si (jli �c ljj �Max) _ (jli �c ljj � li) _ (jli �c ljj � lj)Alors combiner les lignes li et ljSinon fin point fixe vrai/* R�eordonnancement de l'espace de recherche. */placer les composantes ind�ependantes par ordre de jCij croissantd�eplacer les lignes ne comportant qu'une unique contrainte en tetedu tableau3.2.5 Parcours de l'espace de rechercheLe pseudo-code ci-dessous d�ecrit la recherche proprement dite d'une substitution so-lution par le parcours du tableau L de n listes de contraintes qui a �et�e simpli��e. Lad�er�ecursivation se fait au moyen de deux tableaux qui contiennent les informations cor-respondant aux param�etres g�er�es par la pile dans le cas de l'algorithme r�ecursif. Soit ila ligne de travail courante, Indices permet de m�emoriser les num�eros des contraintes(compatibles) constituant le chemin en cours d'exploration, alors que Contraintes corre-spond �a l'accumulation des contraintes portant sur la solution en cours de construction.La notation V++, emprunt�ee au langage C, est utilis�ee a�n de gagner en concision et encompr�ehensibilit�e par rapport �a l'�ecriture V V+1.Le m�ecanisme de propagation des contraintes (de type forward checking) est d�ecrit dansla fonction Propage et met en �uvre deux tableaux suppl�ementaires. Le premier, Propa,est de meme dimension que L et associe �a chaque contrainte une valeur dans l'ensemblefcompatible; 1; 2; :::; n� 1g suivant que la contrainte associ�ee est compatible avec la solu-tion potentielle propag�ee ou non (dans ce dernier cas, le num�ero de la premi�ere ligne encon it est �egalement m�emoris�e). Le second tableau, Compatibles, contient pour chaque

3.2. Implantation du test de subsomption 101ligne de L le nombre de contraintes dont le statut est compatible avec le choix en coursde propagation. D�es que ce nombre devient nul pour une ligne, il est n�ecessaire de revenirsur le dernier choix propag�e.Finalement, l'heuristique classique les choix les plus contraints d'abord est implant�ee enchoisissant, apr�es chaque propagation, la ligne restante de la composante ind�ependantecourante dont la valeur de Compatibles est minimale. Son fonctionnement est d�ecrit dansla proc�edure R�eordonne L./* Test de subsomption optimis�e pour SIAO1, partie 5/5 */Cr�eer le tableau Contraintes[n] [[� � ::: �]; :::; [� � ::: �]]Cr�eer le tableau Indices[n + 1] [1; 1; :::; 1]Cr�eer le tableau Propa[n][pi] [[compatible; :::]; :::]Cr�eer le tableau Compatibles[n] [p1; :::; pn]i 1Tant que (i � n) ^ (Indices[1] � p1)Indices[i] Prochain indice compatible[i]Si (i = 1)Alors Contraintes[i] L[1][Indices[i]]Sinon Contraintes[i] Contraintes[i � 1] +c L[i][Indices[i]]Si Propage(Contraintes[i]; i)Alorsi++Indices[i] 1Sinon Retour arri�ere(i)Si (i = n+ 1) Alors ! succ�es final Sinon ! �echec final/* Propagation de la contrainte C de la ligne l1 */Fonction Propage(C,l1)Soit l2 l'indice maximum des lignes de meme composante ind�ependante que l1Si (l1 = l2) Alors ! succ�esSinon, 8l 2 [l1 + 1; l2] :8 contrainte c 2 L[l] telle que Propa[l][indice(c)] = compatibleSi C:cc AlorsPropa[l][indice(c)] l1Compatibles[l]--Si (Compatibles[l] = 0) Alors ! �echec! succ�es

102 CHAPITRE 3. LE BIAIS DE LANGAGE/* Retour-arri�ere sur la contrainte en cours de la i�eme ligne */Proc�edure Retour arri�ere(i)i--Tant que (i > 0) ^ (Prochain indice compatible[i] > pi)i--Remplacer dans Propa toutes les valeurs sup�erieures ou �egales �a i parla valeur compatible et r�epercuter ces modifications sur le tableauCompatibles/* Heuristique les choix les plus contraints d'abord */Proc�edure R�eordonne L(l1)Permuter dans les tableaux Contraintes, Indices, Propa et Compatibles laligne l1 + 1 avec la ligne de meme composante ind�ependante que l1, d'indicesup�erieur �a l1, pour laquelle Compatibles[l1] est minimum (si elle existe)3.2.6 Propri�et�es de l'algorithme de subsomptionAnalyse de la complexit�e de l'algorithmeLa complexit�e de la relation de subsomption propos�ee ici �etant de meme grandeur asymp-totique que la complexit�e du test de �-subsomption (voir section 3.1.3), il n'est pas�etonnant d'obtenir une fonction exponentielle de la taille des entr�ees puisque le test de�-subsomption est un probl�eme NP-di�cile. Deux points m�eritent cependant d'etre not�es :1. La complexit�e de la partie de l'algorithme consacr�ee au pr�e-traitement (construc-tion du tableau L) est une fonction polynomiale de jEj et de jDj. Du point de vuedes techniques de propagation de contraintes [Tsang93], cette partie correspond �aune v�eri�cation de la coh�erence par n�ud puis par arc associ�ee �a la d�etection descomposantes ind�ependantes. Le m�ecanisme de simpli�cation des composantes forte-ment contraintes correspond �a une proc�edure de coh�erence par chemin qui regroupecertains n�uds choisis du graphe et dont la profondeur est adapt�ee �a la complexit�ede chacune des composantes consid�er�ees.2. Par contre, la complexit�e de la recherche de la substitution solution dans le tableau Ln'est pas une fonction polynomiale. En supposant que L comporte d lignes (1 � d �jDj) d'au plus e contraintes (1 � e � jEj), la complexit�e de la recherche peut etreborn�ee par e:d:ed tests de compatibilit�e (puisque chacun des ed tests de compatibilit�eest compl�et�e par une propagation de type lookahead (il s'agit d'un forward checking)qui n�ecessite dans le pire des cas e:d tests de compatibilit�e).

3.2. Implantation du test de subsomption 103Comme beaucoup de probl�emes de satisfaction de contraintes di�ciles, il est malais�e dejusti�er a priori une m�ethode de r�eduction ou une m�ethode de recherche : ces derni�eressont toutes adapt�ees �a di��erents types de probl�emes. Il n'est pas rare en e�et de con-stater exp�erimentalement que l'�elagage de meilleure qualit�e obtenu �a l'aide d'une m�ethodede r�eduction donn�ee ne compense pas en pratique le surcout de calcul provoqu�e. Ceph�enom�ene est illustr�e par la �gure 3.11 de la section 3.2.8 dans le cas de l'�elagage bas�esur le contexte de graphe utilis�e dans le test de subsomption de T. Sche�er. Cette memesection montre (empiriquement) que le test propos�e est adapt�e aux probl�emes qui ontmotiv�e son d�eveloppement.Adaptation �a la PLI sous �-subsomptionLe cadre de la programmation logique comporte deux particularit�es non partag�ees avecSIAO1.D'une part, contrairement �a SIAO1, l'existence possible de variables dans les tetes desclauses modi�e l'�enonc�e du probl�eme qui devient :Soient deux clauses de Horn D : Dtete Dcorps et E : Etete Ecorps.D�eterminer s'il existe une substitution � v�eri�ant :(1) Dtete� = Etete,(2) Dcorps� � Ecorps .Il est cependant possible de se ramener au probl�eme de SIAO1 de la mani�ere suivante :{ Dans un premier temps, chercher une substitution �1 telle que Dtete�1 = Etete.Puisque Dtete et Etete sont deux atomes, �1 est unique (si elle existe) et la trou-ver est un probl�eme �el�ementaire.{ Si �1 n'existe pas, D ne peut subsumer E puisque la contrainte (1) n'est plus re-spect�ee.{ Dans le cas contraire, il reste �a r�esoudre (2) en propageant �1, ce qui revient �achercher �2 telle que Dcorps�1�2 � Ecorps. En posant D0corps = Dcorps�1 on retrouvealors un cas particulier du probl�eme r�esolu dans ce chapitre puisqu'il s'agit dechercher �2 telle que D0corps�2 � Ecorps dans le cas d'un langage ne comportantni arguments �etendus (disjonctions ou intervalles), ni hi�erarchies, ni symboles ? et*.D'autre part, l'impossibilit�e de traiter les symboles de fonction (ce qui est �egalementune caract�eristique de la plupart des syst�emes de PLI) pose �a premi�ere vue �egalementprobl�eme. Cependant, cette di�cult�e peut etre ais�ement contourn�ee en proc�edant paraplatissement des formules comportant de tels symboles [Rouveirol94].

104 CHAPITRE 3. LE BIAIS DE LANGAGE3.2.7 Autres approchesParmi les nombreux travaux qui portent sur les solutions pratiques �a apporter auprobl�eme de la complexit�e du test de �-subsomption, il est possible de distinguer deuxgrandes approches.Modi�er le cadre du probl�eme pour rendre la complexit�e de `� polynomialeCette premi�ere approche est r�ealis�ee soit en limitant les ressources allou�ees au test de sub-somption (ce qui conduit par exemple M. Sebag et C. Rouveirol �a d�e�nir la notion d'ap-pariement stochastique [Sebag et al.97a]), soit en contraignant la forme des clauses (parexemple [Kietz et al.94] limitent la taille k des composantes existentielles non d�etermin�eesdes clauses, appel�ees k-locales : la complexit�e du test de subsomption n'est plus alors enjEjjDj mais en jEjk).Optimiser les algorithmes implantant le test `�Les travaux faisant r�ef�erence dans ce domaine [Sche�er et al.96] proposent une m�ethodede r�esolution du test en deux temps. La premi�ere �etape consiste �a �elaguer l'espace derecherche au moyen du contexte de graphe, implant�e par l'auteur pour une taille k = 2. Laseconde �etape reformule le probl�eme de la subsomption comme un probl�eme de recherched'une clique dans un graphe dont les n�uds sont les substitutions candidates. Les aretesrepr�esentent un lien de compatibilit�e entre deux substitutions candidates.Il convient �egalement de mentionner les travaux de [Kim et al.92] qui proposent unerepr�esentation tabulaire similaire �a celle qui a �et�e pr�esent�ee ici. Cependant, si un codagedes contraintes �a l'aide de cha�nes de bits permet des tests de compatibilit�e tr�es e�caces,les seuls m�ecanismes de r�eduction de l'espace de recherche mis en �uvre correspondent�a la d�etection des incompatibilit�es globales et des composantes ind�ependantes de taillek = 1. Aucun des autres m�ecanismes de r�eduction (composantes ind�ependantes de taillek > 1, combinaison des lignes, redondances inter et intra-lignes, etc.) n'est propos�e. L'ex-ploration de l'espace de recherche est r�ealis�ee par une m�ethode exhaustive puisque toutesles contraintes d'une solution potentielle sont combin�ees avant de tester la validit�e de cettesolution. Aucun m�ecanisme de propagation de contraintes n'est utilis�e.3.2.8 �Evaluation exp�erimentaleLe test de subsomption (not�e ` SIAO1) a �et�e implant�e en C++. Du fait d'une con-ception orient�ee-objet proposant une m�ethode d'ajout incr�emental des contraintes dansL, il a b�en�e�ci�e d'une am�elioration (mineure) par rapport �a la version d�ecrite dans cechapitre : il est en e�et possible de proc�eder �a certains �elagages relatifs au pr�e-traitementau fur et �a mesure de l'arriv�ee des contraintes.La validation exp�erimentale de ` SIAO1 est tout simplement r�ealis�ee en constatant queSIAO1 est capable de travailler dans les espaces relationnels complexes qui ont motiv�e

3.2. Implantation du test de subsomption 105son �elaboration (comme par exemple le probl�eme Mutagenesis d�ecrit en annexe B sectionB.4), alors qu'auparavant le meme algorithme ne terminait pas sur ces memes probl�emes(en un temps raisonnable et avec les machines actuelles).A�n de quanti�er plus pr�ecis�ement le gain apport�e, trois tests ont �et�e r�ealis�es :{ Le premier compare sur un probl�eme tr�es simple d'appariement de graphes le com-portement du test de subsomption canonique (d�ecrit section 3.2.1) et celui du testde subsomption optimis�e.{ Le second propose une comparaison avec l'algorithme de T. Sche�er [Sche�er et al.96](d�ecrit section 3.2.7) sur un probl�eme di�cile construit �a l'aide des donn�ees de Mu-tagenesis.{ Le troisi�eme a �et�e r�ealis�e a�n d'apporter des informations plus pr�ecises quand auxcauses des di��erences de comportement constat�ees sur le probl�eme pr�ec�edent.Comparaison avec le test canoniqueA�n de montrer l'apport du test propos�e par rapport �a la version canonique classique, unprobl�eme jouet de couverture de graphes a �et�e construit :X
X X
X X
5 2
34
1
a
f
c
b
d
e
D: E:
Les graphes sont repr�esent�es au moyen des litt�eraux objet() et lien(; ). Par exemple legraphe D s'�ecrit :concept objet(X1) ^ ::: ^ objet(X5) ^ lien(X1; X2) ^ ::: ^ lien(X5; X1):Comme le montre le tableau ci-dessous, il est possible d'acc�el�erer le test de subsomptionde plus de trois ordres de grandeur sur cet exemple, qui est un probl�eme extremementsimple (les graphes ne comportent respectivement que 5 et 6 sommets).T`SIAO1 (s) T`canonique (s) Acc�el�eration5; 025:10�4 1; 287 2 561

106 CHAPITRE 3. LE BIAIS DE LANGAGEUn tel d�ecalage peut etre expliqu�e en constatant que dans le cas du test optimis�e,la r�eduction (de complexit�e polynomiale) de la table L est su�sante pour conna�trele r�esultat du test (�a savoir que D ne couvre pas E), alors que dans le cas du testcanonique, pas moins de 248 245 tests de compatibilit�e sont n�ecessaires pour arriver aumeme r�esultat. De plus, on remarquera �egalement que si le nombre de tests de compati-bilit�e est peu important par rapport au nombre de combinaisons possibles entre litt�eraux(jEjjDj = 1910 ' 6; 13:1012), il est sup�erieur au nombre de valuations possibles des vari-ables (65 = 7 776).Comparaison avec le test propos�e par T. Sche�erUne seconde �etape �a la validation du test de subsomption de SIAO1 consiste �a comparerce dernier aux meilleurs tests de �-subsomption. Cependant, il est important de soulignerque le test de subsomption sur Lh est di��erent d'un test de �-subsomption classiquepuisque si tout probl�eme de �-subsomption se ram�ene �a un probl�eme de subsomption surLh (comme l'a montr�e la section 3.2.6), la r�eciproque est fausse. Consid�erons par exemplele probl�eme de subsomption suivant :P (X;X) ? P (a; �)La relation de subsomption est v�eri��ee car le symbole * n'introduit aucune contrainte,conform�ement �a la s�emantique �etablie (la substitution solution est alors � = fX=ag).Cependant un test de �-subsomption classique ne mettant en �uvre aucun m�ecanisme detraitement sp�ecial de * sera confront�e �a l'impossibilit�e de trouver une substitution solutionpuisque d'une part dans le contexte de la PLI le probl�eme de l'appariement se r�eduit �a larecherche d'une substitution, et que d'autre part une substitution est une fonction (donc� = fX=a;X=�g n'est pas une substitution).Une autre indication quand �a la modi�cation de la nature du probl�eme induite par lesymbole * est donn�ee par l'�etude des pr�e-traitements fond�es sur les signatures. En e�et,une m�ethode tr�es e�cace d'�elagage consiste �a associer �a chaque constante ou variable (resp.litt�eral) une repr�esentation, appel�ee signature, caract�erisant l'environnement structurel del'objet consid�er�e dans la formule. Soit par exemple :F : P (X; Y ) ^ P (Y; Z) ^ P (Z;Z)L'environnement structurel de la variableX est caract�eris�e par le fait que cette derni�ere nepeut appara�tre qu'en premi�ere position dans le pr�edicat P , ce qui sera not�e par X : P1. De mani�ere analogue, les signatures des autres variables sont Y : P1 P2 et Z : P2 P12.De telles contraintes structurelles fortes permettent un �elagage tr�es e�cace de l'espacede recherche puisqu'il est possible d'�eliminer des solutions candidates toutes celles dontles �el�ements appari�es ne partagent pas la meme signature. Cependant, la s�emantiquedu symbole * rend impossible l'utilisation d'un tel m�ecanisme puisque l'�equivalence des

3.2. Implantation du test de subsomption 107signatures de deux symboles n'est plus une condition n�ecessaire pour que leur appariementpuisse g�en�erer une solution au probl�eme de la subsomption.Tobias Sche�er a eu l'extreme gentillesse de nous fournir le code source (�ecrit en langage C)du test de subsomption propos�e dans [Sche�er et al.96], qui fait r�ef�erence dans le domaine.Le protocole d'exp�erimentation mis en �uvre pour comparer les deux algorithmes est lesuivant :{ Des donn�ees r�eelles sont utilis�ees. Elles proviennent du probl�eme Mutagenesis.{ Il est possible de param�etrer la di�cult�e du test en faisant varier un param�etre nqui correspond au nombre de litt�eraux de l'hypoth�ese.{ Pour une valeur de n donn�ee, chaque test est ex�ecut�e sur les memes instances Det E, o�u E est la mol�ecule la plus complexe (en nombre de litt�eraux) de la baseMutagenesis (on a jEj = 84), et D est une hypoth�ese obtenue par extraction de nlitt�eraux di��erents de E (d�etermin�es al�eatoirement) dont les arguments relationnelssont variabilis�es.
0
0.1
0.2
0.3
0.4
0.5
0 5 10 15 20 25 30 35 40 45 50 55 60 65 70 75 80
Test de subsomption de SIAO1 Test de subsomption de SchefferScheffer + contexte de graphe
Fig. 3.11: Performance des tests de subsomption sur le probl�eme Mutagenesis.Les �gures 3.11 et 3.12 ont �et�e obtenues en g�en�erant plusieurs milliers d'hypoth�eses pourchaque valeur de n. Les temps moyens (en secondes) ainsi que les �ecarts-types ont �et�ecalcul�es. Il est possible d'observer sur ce probl�eme :{ que la croissance du cout du test de subsomption propos�e par Sche�er est bien plusimportante que ce que l'on observe dans le cas de SIAO1 ;

108 CHAPITRE 3. LE BIAIS DE LANGAGE
-0.01
0
0.01
0.02
0.03
0 5 10 15 20 25 30 35 40 45 50 55 60 65 70 75 80
Test de subsomption de SIAO1 Test de subsomption de SchefferScheffer + contexte de graphe
Fig. 3.12: Performance des tests de subsomption sur le probl�eme Mutagenesis (d�etail).{ que l'utilisation du contexte de graphe avec k = 2 pour �elaguer l'espace de recherched�egrade les performances du test de subsomption propos�e par Sche�er.L'inutilit�e du contexte de graphe peut s'expliquer ais�ement par le fait que lorsque k = 2, iln'est possible de consid�erer au mieux que des structures de type atome(X; :::)^lien(X; Y ),qui sont bien trop simples pour permettre un �elagage structurel e�cace. Par contre, il estplus di�cile de comprendre pourquoi le test fond�e sur la recherche d'une clique est moinse�cace que le test fond�e sur un algorithme de propagation de contraintes. Il est n�eanmoinspossible de remarquer que, dans le cas d'une hypoth�ese D (resp. une instance E) de jDj(resp. jEj) litt�eraux dont l'arit�e des pr�edicats est born�ee par k, la taille des structuresmanipul�ees par les deux algorithmes est di��erente. En e�et, dans le cas du test implant�epour SIAO1, la taille de la table des contraintes est born�ee par k:jEj:jDj, alors que lataille du graphe utilis�e par le test propos�e par Sche�er7 est proportionnelle �a (jEj:jDj)2.Cout en espace des algorithmesUn dernier test a �et�e r�ealis�e a�n de mesurer les tailles m�emoires respectives des deux testsde subsomption. Le probl�eme choisi est une reformulation en logique relationnelle duprobl�eme des n reines car ce dernier, consid�er�e comme di�cile, ne peut etre d�ecompos�e.Le tableau ci-apr�es d�etaille le temps T (mesur�e en secondes) n�ecessaire �a la r�esolutiondu probl�eme ainsi que la taille m�emoire M (mesur�ee en kilo-octets). Alors que la taillemaximale allou�ee reste tr�es modeste dans le cas du test de subsomption optimis�e propos�e7En e�et, ce graphe repr�esente la compatibilit�e des substitutions engendr�ees par les couples de litt�eraux(d; e) avec d 2 D et e 2 E.
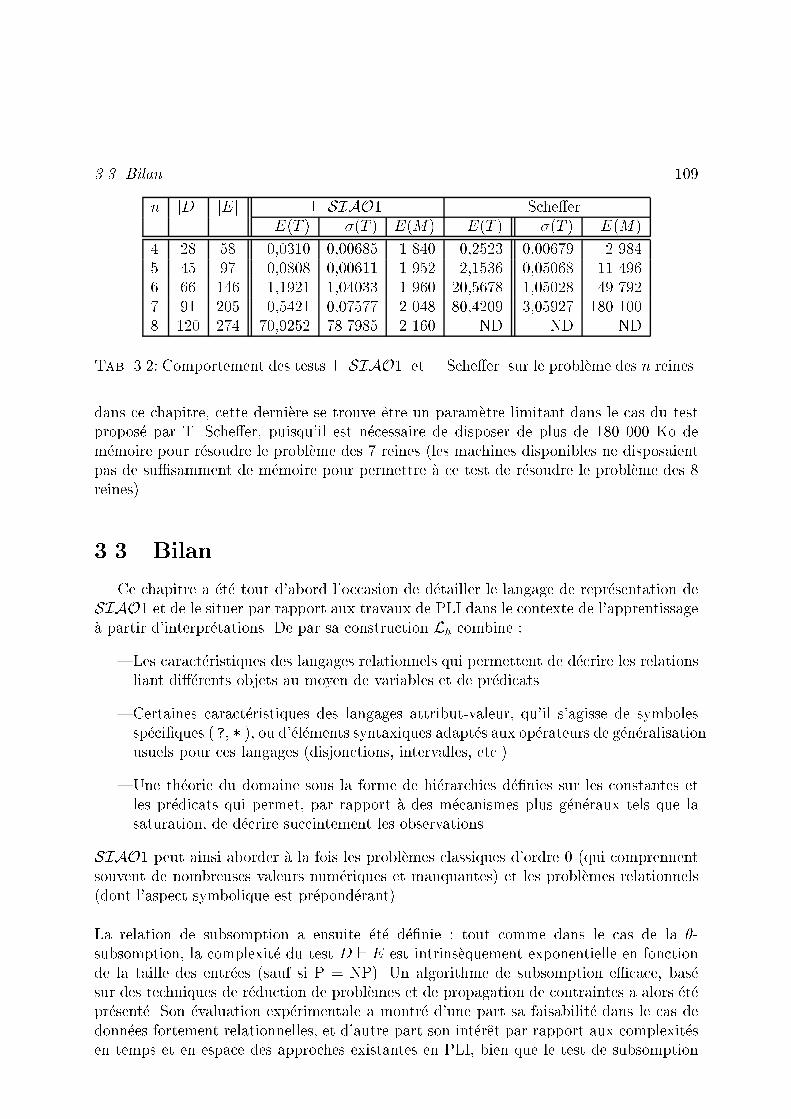
3.3. Bilan 109n jDj jEj ` SIAO1 ` Sche�erE(T ) �(T ) E(M) E(T ) �(T ) E(M)4 28 58 0,0310 0,00685 1 840 0,2523 0,00679 2 9845 45 97 0,0808 0,00611 1 952 2,1536 0,05068 11 4966 66 146 1,1921 1,04033 1 960 20,5678 1,05028 49 7927 91 205 0,5421 0,07577 2 048 80,4209 3,05927 180 1008 120 274 70,9252 78.7985 2 160 ND ND NDTab. 3.2: Comportement des tests ` SIAO1 et ` Sche�er sur le probl�eme des n reines.dans ce chapitre, cette derni�ere se trouve etre un param�etre limitant dans le cas du testpropos�e par T. Sche�er, puisqu'il est n�ecessaire de disposer de plus de 180 000 Ko dem�emoire pour r�esoudre le probl�eme des 7 reines (les machines disponibles ne disposaientpas de su�samment de m�emoire pour permettre �a ce test de r�esoudre le probl�eme des 8reines).3.3 BilanCe chapitre a �et�e tout d'abord l'occasion de d�etailler le langage de repr�esentation deSIAO1 et de le situer par rapport aux travaux de PLI dans le contexte de l'apprentissage�a partir d'interpr�etations. De par sa construction Lh combine :{ Les caract�eristiques des langages relationnels qui permettent de d�ecrire les relationsliant di��erents objets au moyen de variables et de pr�edicats.{ Certaines caract�eristiques des langages attribut-valeur, qu'il s'agisse de symbolessp�eci�ques ( ?, * ), ou d'�el�ements syntaxiques adapt�es aux op�erateurs de g�en�eralisationusuels pour ces langages (disjonctions, intervalles, etc.).{ Une th�eorie du domaine sous la forme de hi�erarchies d�e�nies sur les constantes etles pr�edicats qui permet, par rapport �a des m�ecanismes plus g�en�eraux tels que lasaturation, de d�ecrire succintement les observations.SIAO1 peut ainsi aborder �a la fois les probl�emes classiques d'ordre 0 (qui comprennentsouvent de nombreuses valeurs num�eriques et manquantes) et les probl�emes relationnels(dont l'aspect symbolique est pr�epond�erant).La relation de subsomption a ensuite �et�e d�e�nie : tout comme dans le cas de la �-subsomption, la complexit�e du test D ` E est intrins�equement exponentielle en fonctionde la taille des entr�ees (sauf si P = NP). Un algorithme de subsomption e�cace, bas�esur des techniques de r�eduction de probl�emes et de propagation de contraintes a alors �et�epr�esent�e. Son �evaluation exp�erimentale a montr�e d'une part sa faisabilit�e dans le cas dedonn�ees fortement relationnelles, et d'autre part son int�eret par rapport aux complexit�esen temps et en espace des approches existantes en PLI, bien que le test de subsomption

110 CHAPITRE 3. LE BIAIS DE LANGAGE�etudi�e soit a priori plus di�cile que le test de �-subsomption.Les fondations de SIAO1 ayant �et�e expos�ees et valid�ees, le chapitre suivant est consacr�e�a l'algorithme de recherche du syst�eme.

Chapitre 4SIAO1Ce chapitre d�ecrit le syst�eme SIAO1 qui apprend, �a partir d'exemples, des d�e�nitionsexprim�ees dans le langage relationnel Lh. La premi�ere section, qui s'appuie sur les r�esultatsmentionn�es dans le chapitre 3, pr�esente l'architecture g�en�erale du syst�eme ainsi que lastructure des chromosomes codant les formules. Les di��erentes composantes de la fonc-tion de qualit�e sont ensuite explicit�ees, ce qui permet d'analyser le biais d'�evaluation del'algorithme et de montrer son ad�equation �a la strat�egie de recherche. La section 4.3 estconsacr�ee aux op�erateurs d'�evolution (mutation et croisement), et souligne les di��erencesimportantes qui, combin�ees �a la strat�egie de recherche adopt�ee, distinguent nettement lesyst�eme propos�e des autres approches �evolutionnaires. Les deux sections suivantes sontconsacr�ees d'une part au post-traitement et �a la classi�cation de nouvelles instances �al'aide des r�egles obtenues, et d'autre part aux connaissances du domaine d'ordre sym-bolique ou num�erique pouvant etre prises en compte par le syst�eme a�n de fournir desd�e�nitions plus pr�ecises et plus intelligibles. Finalement, une derni�ere partie pr�esente lesr�esultats obtenus sur di��erentes bases d'apprentissage de r�ef�erence.4.1 Architecture g�en�eraleL'apprentissage de formules relationnelles est un probl�eme de recherche dans un espacedont la taille est gigantesque et dont la structure, bien qu'ordonn�ee, comporte de nombreuxextremums locaux. De plus, ce probl�eme est multi-crit�eres (comme le montre la section4.2, de nombreux traits, parfois antagonistes, doivent etre optimis�es), et les donn�ees sontsouvent bruit�ees. Les algorithmes d'�evolution sont donc de bons candidats pour ce typede probl�eme. La strat�egie de recherche de SIAO1 est fond�ee sur deux principes :1. L'utilisation d'une m�ethode stochastique, dont la pertinence est justi��ee par la taille,la structure et les propri�et�es de l'espace de recherche.2. L'exploitation de diverses informations relatives au probl�eme, qu'il s'agisse des ex-emples d'apprentissage ou de la relation d'ordre `2 d�ecrite au chapitre 3.Le paragraphe suivant pr�esente la m�ethode de couverture simultan�ee des exemples quiest utilis�ee ; cette derni�ere est une �evolution de la m�ethode de couverture it�erative pro-111

112 CHAPITRE 4. SIAO1pos�ee dans le cadre des algorithmes d'�evolution par G. Venturini pour le syst�eme SIA[Venturini94b].4.1.1 M�ethode de rechercheSIAO1 apprend un nombre variable (born�e par l'utilisateur) de r�egles d�ecrivant unou plusieurs concepts de la mani�ere suivante :Recherche unidirectionnelle et ascendanteSoit Ex un exemple de l'un des concepts-cible cl, d�etermin�e al�eatoirement suivantune probabilit�e de s�election proportionnelle au poids des instances. Le noyau N(Ex)est construit en rempla�cant dans la formule Ex toutes les occurrences du symbole ?par le symbole *1. N(Ex) est appel�e noyau g�en�erateur de la population P (Ex)puisque toutes les formules de P (Ex) seront plus g�en�erales que N(Ex) (au sens dela relation d'ordre `2). En pratique, la propri�et�e de couverture du noyau est garantiepar le fait que les op�erateurs d'�evolution sont ascendants : l'espace de recherche estun treillis ordonn�e par `2 dont le plus petit �el�ement est N(Ex) et le plus grand�el�ement est la clause cl : dont le corps est vide. L'�evolution de P (Ex) estd�ecrite par l'algorithme ci-dessous :/* Algorithme d'�evolution d'une population P (Ex) , partie 1/1 */1. P (Ex) fN(Ex)g ; pm 1=22. R�ep�eter(a) G�en�erer un individu r0 �a partir d'un individu r s�electionn�eproportionnellement �a sa qualit�e :i. par mutation avec la probabilit�e pm : r ! r0 ;ii. par croisement avec la probabilit�e pc = 1� pm : r; r2 ! r0.Le second parent r2 est soit un autre individu de P (Ex),soit une instance de la base d'apprentissage de memeclasse que Ex.(b) Ins�erer r0 dans P (Ex) si r0 62 P (Ex) :- si la taille maximum de la population (not�ee Pmax) n'estpas atteinte, alors ajouter r0 �a P (Ex) ;- si la taille maximum de la population est atteinte etsi la qualit�e de r0 est sup�erieure �a la qualit�e du pireindividu de P (Ex), alors remplacer cet individu par r0.(c) Mettre �a jour pm.3. Jusqu'�a ce que le crit�ere d'arret soit v�erifi�e ou qu'un messagede r�einitialisation soit re�cu.1Il n'est en e�et pas concevable qu'une description g�en�erale de concept puisse faire explicitementr�ef�erence �a une valeur d�e�nie mais inconnue relative �a une instance bien particuli�ere.

4.1. Architecture g�en�erale 113Le sch�ema d'�evolution d'une population de SIAO1 est caract�eris�e par les propri�et�essuivantes, dont les deux derni�eres proviennent du syst�eme SIA :{ Une direction de recherche ascendante. Cette derni�ere est garantie par lesop�erateurs d'�evolution construits pour fournir une hypothy�ese plus g�en�eraleau sens de `2 que la r�egle r �a laquelle ils s'appliquent, et permet une recherchee�cace puisqu'exempte de retours-arri�ere et de cycles.{ Une s�election incr�ementale et �elitiste. Conform�ement au principe de recherche,le sch�ema de s�election choisi permet une exploration stable et progressive dutreillis puisque, contrairement aux sch�emas g�en�erationnels, la s�election incr�ementaleet �elitiste assure la conservation des meilleurs individus. D'autre part, le testd'insertion maintient la diversit�e de la population qui correspond �a une listed'individus distincts tri�es en fonction de leur qualit�e. La valeur par d�efaut dela taille maximum d'une population est de Pmax = 50 individus.
N(Ex)
P(Ex)
Partie du treillisnon explorée
Définitions sur-générales (de mauvaise qualité)
cl .
Fig. 4.1: �Evolution de P (Ex) dans le treillis d�e�ni par N(Ex) et `2.La �gure 4.1 illustre le processus de recherche : les �el�ements de P (Ex) sontdes n�uds distincts du treillis g�en�er�es parmi les successeurs2 d'un �el�ement deP (Ex). Les n�uds sur-g�en�eraux (qui �gurent en noir sur le sch�ema) ne peuventetre ins�er�es dans la population car leur qualit�e (fond�ee principalement sur leurcoh�erence), est alors tr�es faible. Le processus d'�evolution se termine lorsqueP (Ex) se situe pr�es de la fronti�ere s�eparant les hypoth�eses maximalement cor-rectes des hypoth�eses sur-g�en�erales : il n'est plus possible de progresser dans letreillis et aucun retour en arri�ere ne peut etre e�ectu�e puisque les op�erateurssont ascendants. La section 4.2, qui d�etaille le calcul de la qualit�e des individus,2Il peut s'agir d'un successeur imm�ediat ou d'un ni�eme successeur.

114 CHAPITRE 4. SIAO1montre comment il est possible de d�e�nir une fonction fond�ee avant tout sur lacoh�erence, favorisant les hypoth�eses g�en�erales, et tol�erante au bruit. La stochas-ticit�e du processus combin�ee �a la taille du treillis ne permet pas d'assurer uneexploration exhaustive qui serait de toute mani�ere bien trop couteuse.{ L'auto-adaptation des taux de mutation et de croisement. Chaque populationadapte dynamiquement le taux de mutation local pm 2 [0; 1; 0; 9] suivant la loide relaxation : pm(g + 1) = (1� �):pm(g) + �:resavec :� � = 1100 ;� res = 8>>><>>>: � 0; 9 si la derni�ere op�eration est une mutation (resp: uncroisement); et l0individu g�en�er�e a pu (resp: n0a pas pu)etre ins�er�e dans la population ;� 0; 1 sinon:Les m�ecanismes d'auto-adaptation constituent un champ de recherche tr�es actifdans le domaine des algorithmes �evolutionnaires [Sebag et al.97b, Ravise et al.96,Spears91, Davis89]. En ce qui concerne SIAO1, les b�en�e�ces sont nombreuxpuisque :� l'utilisateur n'est pas sollicit�e pour ajuster les param�etres ;� ces derniers s'adaptent au type de probl�eme rencontr�e ;� de plus, ils s'adaptent �egalement pendant l'�evolution.{ Une diversit�e maximale des individus de la population. La multiplication d'in-dividus identiques au sein de la population est justi��ee dans le contexte del'algorithme g�en�etique canonique par l'argument du bandit manchot �a k bras(mentionn�e chapitre 2 section 2.1.2), qui d�emontre la validit�e de cette strat�egielorsque l'objectif de l'algorithme est d'allouer ses ressources (les individus) demani�ere �a maximiser le cumul des gains (retourn�es par la fonction de qualit�e).Cependant, le contexte de SIAO1 est sensiblement di��erent puisque l'objectifn'est pas de maximiser une somme, mais de trouver en un temps raisonnableune valeur aussi proche du maximum que possible. Le maintien de la diversit�edes individus au sein de la population, h�erit�e du syst�eme SIA, est donc jus-ti��e puisqu'il permet un meilleur �echantillonnage de l'espace de recherche etdiminue d'autant le risque de convergence pr�ematur�ee.{ L'assurance de la terminaison de l'algorithme. Ce r�esultat, qui provient dusyst�eme SIA, est partag�e par tous les syst�emes d'apprentissage �evolutionnaires.Cependant, alors qu'il est habituellement garanti par la sp�eci�cation d'uneborne au nombre maximum de g�en�erations, il d�epend dans le cas de SIAO1 (commedans le cas de SIA) du crit�ere d'arret :

4.1. Architecture g�en�erale 115Si aucun individu n'a �et�e ins�er�e depuis gmax g�en�erations,alors l'�evolution de la population est termin�ee.Le param�etre gmax permet de r�egler l'intensit�e de la recherche, dont la valeurabsolue (en nombre de g�en�erations) est adapt�ee �a l'environnement du noyau.4.1.2 D�eveloppement simultan�e de plusieurs noyauxHormis le probl�eme de la recherche d'une hypoth�ese couvrant un ensemble d'exemples,une autre source de complexit�e pour la tache d'apprentissage provient des concepts dis-jonctifs. Ces derniers ne peuvent etre caract�eris�es que par un ensemble d'hypoth�eses : lesyst�eme d'apprentissage doit alors s'e�orcer de minimiser leur nombre sous les contraintesde coh�erence et de compl�etude �etendues �a la totalit�e du mod�ele. Les solutions apport�ees�a ce probl�eme peuvent etre group�ees en deux grandes cat�egories :{ Les strat�egies locales, qui apprennent les d�e�nitions l'une apr�es l'autre. La m�ethodologiede l'�etoile, d�etaill�ee chapitre 1 section 1.3.4, est un exemple de strat�egie appartenant�a cette cat�egorie.{ Les strat�egies globales, qui isolent simultan�ement les sous-concepts. Le principe di-viser pour r�egner (chapitre 1 section 1.3.5), l'algorithme des Vraizamis [Torre99]ou, dans le domaine des algorithmes d'�evolution, la s�election au su�rage universel(chapitre 2 section 2.2.4) sont autant d'exemples de m�ethodes globales.Dans le cas de SIAO1, la strat�egie employ�ee consiste �a d�evelopper simultan�ement plusieursnoyaux. Un nombre maximum de d�e�nitionsNcl est fourni par l'utilisateur pour chacun desconcepts-cible (par d�efaut ce nombre est �x�e �a 5 pour toutes les classes). Des noyaux tousdi��erents de classe appropri�ee sont alors d�etermin�es a�n d'initialiser chaque population.Celles-ci �evoluent ind�ependamment de mani�ere synchrone conform�ement �a l'algorithmedonn�e section 4.1.1. �A intervalles r�eguliers (par d�efaut tous les Ncycle = 100 g�en�erations),un processus d'�elagage est d�eclench�e parmi les populations n'ayant pas encore converg�e.Ce dernier consiste �a tester le recouvrement du noyau Ni par la d�e�nition de meilleurequalit�e de toutes les populations Hmax(Nj); j 6= i concluant sur la meme classe. Alors,si la qualit�e de Hmax(Nj) est sup�erieure �a la qualit�e de Hmax(Ni), la i�eme population estabandonn�ee et r�e-initialis�ee. Le nouveau noyau est choisi par tirage al�eatoire pond�er�e parles poids des instances parmi les exemples de classe cl non couverts par les d�e�nitionsayant converg�e.La �gure 4.2 illustre le fonctionnement du processus d'�elagage dynamique (les deux noyauxrepr�esent�es concluent sur la meme classe) :{ Dans le premier cas, le noyau N1 sera tr�es probablement abandonn�e car d'une partil est couvert par la meilleure hypoth�ese issue du noyau N2, et d'autre part lacouverture deHmax(N2) �etant sup�erieure �a celle deHmax(N1), la qualit�e deHmax(N2)est tr�es probablement sup�erieure �a celle de Hmax(N1). Par contre, le noyau N2 nepeut etre abandonn�e car Hmax(N1) ne couvre pas N2

116 CHAPITRE 4. SIAO12N
1N
Cas 1
NN2
1
Cas 2Fig. 4.2: Processus d'�elagage au cours de l'�evolution.{ Dans le second cas, il est certain que l'un des deux noyaux sera abandonn�e puisquechacun est couvert par la meilleure hypoth�ese issue de l'autre. Les couvertures deHmax(N1) et Hmax(N1) �etant voisines, l'�elagage sera principalement fonction de lacoh�erence des meilleures hypoth�eses de chaque noyau.4.1.3 Repr�esentation des formulesUne des particularit�es des approches �evolutionnaires appliqu�ees �a l'apprentissage rela-tionnel est le caract�ere diam�etralement oppos�e des deux m�ethodes de repr�esentation misesen �uvre.La premi�ere m�ethode, employ�ee par les syst�emes fond�es sur les algorithmes g�en�etiques[Angelano et al.97, TN et al.00], consiste �a repr�esenter les formules relationnelles sous laforme de cha�nes binaires de taille �xe : il est donc n�ecessaire de fournir un mod�ele de lastructure relationnelle de la solution. En pratique, le mod�ele peut :{ Etre fourni par l'utilisateur. Toutefois, bien qu'il soit commode de reporter surce dernier un choix particuli�erement di�cile, cette m�ethode fait l'hypoth�ese quel'utilisateur puisse fournir une forme approch�ee de la solution. Ce dernier se trouvealors face �a un dilemme : soit il choisit un mod�ele tr�es expressif au risque d'unsurcout de calcul et d'une d�egradation possible de la qualit�e de la solution due �a lataille de l'espace de recherche, soit il sp�eci�e (lorsque cela est possible) une formemoins expressive et plus pr�ecise, au risque de manquer la forme optimale en casd'erreur.{ Provenir de la structure d'un exemple. Cette alternative, qui a le double avan-tage d'etre simple et de ne pas solliciter l'utilisateur, a n�eanmoins l'inconv�enientde n�egliger de nombreuses formes potentiellement utiles. En e�et, comme le montresur un exemple la �gure 4.13 de la section 4.3.2, la plus petite forme couvrant deuxexemples peut n'etre incluse dans aucune des formes de ces exemples.{ Etre construit �a partir de la base d'apprentissage. Cependant, en examinant la com-binatoire d'une telle m�ethode, il semble di�cile d'automatiser le processus de con-

4.1. Architecture g�en�erale 117struction sans contrainte d'aucune sorte. En e�et, un mod�ele g�en�er�e �a partir de nexemples de taille k peut atteindre une taille de kn, ce qui a par exemple motiv�e lamise en place de biais de repr�esentation sp�eci�ques dans le cas du syst�eme de PLIGOLEM (voir chapitre 1, section 1.5.2).L'utilisation d'un mod�ele est donc une m�ethode qui peut etre critiqu�ee. En e�et, commele montrent les trois approches d�etaill�ees ci-dessus, la structure de la solution est, dansle cas g�en�eral, une composante du probl�eme de l'apprentissage relationnel qu'il est par-ticuli�erement di�cile de r�esoudre s�epar�ement. De plus, les cha�nes binaires de taille �xeont l'inconv�enient d'etre tr�es peu adapt�ees aux probl�emes relationnels mettant en jeu desvaleurs num�eriques.La seconde m�ethode provient des algorithmes �evolutionnaires fond�es sur la program-mation g�en�etique [Wong et al.95]. Ces derniers fournissent une alternative d'autant plusint�eressante que les structures arborescentes suppriment la n�ecessit�e de sp�eci�er un mod�ele.En outre, cette approche a �et�e valid�ee �a la fois sur des probl�emes-jouets relationnels telsque les arches de Winston [Winston75], ainsi que sur des probl�emes r�ecursifs comme lad�e�nition de la fonction factorielle. Cependant, un certain nombre d'inconv�enients doiventetre consid�er�es avant d'envisager l'application de telles techniques �a des probl�emes r�eels :{ le cout de calcul est important, et ce meme lorsque le probl�eme trait�e est de taillemodeste et non bruit�e ;{ la technique d'exploration semble peu adapt�ee aux sp�eci�cit�es des probl�emes dePLI3. Par exemple, le croisement est un op�erateur hautement disruptif pour lescha�nes relationnelles.L'approche suivie par SIAO1, qui peut etre quali��ee de m�ediane par rapport aux deuxautres m�ethodes, a �et�e d�e�nie en r�epondant aux questions suivantes :1. Quelle est la plus petite unit�e d'information au sein d'une formule dont la modi�-cation pourrait avoir un sens du point de vue d'un algorithme de recherche de PLItravaillant �a l'aide d'op�erateurs de haut niveau ?2. Quels sont les blocs d'information dont la combinaison constitue une solution ?Quelle est la structure la plus simple permettant la repr�esentation d'une solution �al'aide de ces blocs ?Du point de vue de la conception d'un algorithme �evolutionnaire, la premi�ere questionisole le concept de g�ene (unit�e sur laquelle op�ere la mutation), et la deuxi�eme pr�ecise lastructure du chromosome ainsi que l'op�erateur de croisement. Au vu du langage Lh, lesr�eponses apport�ees sont les suivantes :3Ce sentiment est renforc�e par le fait que la d�e�nition du concept d'arche est trouv�ee �a la secondeg�en�eration, et la d�e�nition de la factorielle �a la quinzi�eme (le nombre maximum de g�en�erations �etant �x�e�a 20). En outre, comme la taille des populations est �x�ee �a 1000 individus, il est di�cile de d�eduire deces r�esultats l'ad�equation des op�erateurs �a un processus fond�e sur l'�evolution.

118 CHAPITRE 4. SIAO11. Un g�ene est une unit�e syntaxique de base, c'est-�a-dire soit un symbole de pr�edicat,soit un argument. Les op�erations envisag�ees pour la mutation sont en e�et des r�eglesde g�en�eralisation fond�ees soit sur la synatxe, comme Atome(X; c) ��! Atome(X; fc_hg) , soit sur la th�eorie du domaine, comme V oiture(X) ��! V �ehicule(X) .2. Un bloc de construction est un atome. En e�et, d�e�nir un point de coupure entredeux g�enes quelconques d'un chromosome peut produire un r�esultat non conformeaux signatures des pr�edicats. De meme que pour le syst�eme GABIL (voir chapitre 2,section 2.2.2), il est n�ecessaire de d�eterminer des points de coupure s�emantiquementcompatibles . Dans le cas de Lh, une solution consisterait �a choisir ces derniers avantun g�ene repr�esentant un symbole de pr�edicat.Ainsi :{ Un g�ene est une unit�e syntaxique poss�edant une forme, un type et un nombre variablede valeurs. Les di��erentes formes, d�e�nies d'apr�es Lh, sont �enum�er�ees dans le tableauci-dessous4 : Forme Type ValeursSymbole de pr�edicat | 1Symbole de variable Num / Symb 1Symbole de constante Num / Symb 1Disjonction Num / Symb > 1Intervalle num�erique Num 2Variable �etiquet�ee Num / Symb 2Tab. 4.1: Les di��erentes formes d'un g�ene.{ Un chromosome est une liste (de taille variable) de g�enes respectant les contraintesrelatives aux arit�es, aux types et aux modes d�e�nis sur Lh. La �gure 4.3 d�etaille lastructure du chromosome repr�esentant la formule Atome(X; fc _ hg).Chromosome Forme Type Valeursg�ene no 1 Pr�edicat | ! Atomeg�ene no 2 Variable Id a ! Xg�ene no 3 Disjonction �El�ement ! c hFig. 4.3: Structure d'un chromosome.4La derni�ere forme n'est pr�esente qu'au cours de calculs interm�ediaires relatifs au d�eveloppement dumoindre g�en�eralis�e.

4.2. Calcul de la qualit�e 1194.2 Calcul de la qualit�eLa fonction de qualit�e a pour objectif d'�evaluer les individus g�en�er�es lors de la recherche.Cette fonction doit non seulement prendre en compte de multiples crit�eres d'appr�eciationparfois antagonistes, mais elle doit �egalement etre adapt�ee au type de la recherche a�n deguider l'algorithme en favorisant les individus susceptibles de conduire �a la solution. Dansle cas de SIAO1, cette fonction est constitu�ee de deux composantes.La premi�ere composante { pr�epond�erante { est uniquement fond�ee sur la couverture de lar�egle �a �evaluer. Comme indiqu�e au chapitre 1, �gure 1.5 et table 1.6, la couverture peutetre d�ecrite �a l'aide des e�ectifs nC^H, n �C^H, nC^ �H et n �C^ �H du tableau de contingence.La seconde composante re �ete un biais fond�e sur la syntaxe de l'individu. Le but pour-suivi est de permettre, �a crit�ere de couverture �egal, l'insertion dans la population desdescriptions fournissant le meilleur compromis entre g�en�eralit�e et concision.Les paragraphes suivants sont consacr�es �a la description et �a l'analyse de ces deux com-posantes, ainsi qu'�a quelques consid�erations concernant la complexit�e de la fonction dequalit�e ainsi que l'optimisation de son calcul.Une derni�ere composante, correspondant �a un terme correctif permettant la prise encompte des pr�ef�erences de l'utilisateur a �et�e propos�ee d�es [Augier et al.95]. L'int�eret enest double : d'une part, le fait de permettre �a l'utilisateur de sp�eci�er des biais sp�eci�ques�a un probl�eme donn�e, et donc de guider la recherche peut pr�esenter un int�eret pratiquedans le cadre de certaines applications tr�es particuli�eres pour lesquelles il dispose deconnaissances qu'il souhaite exploiter ; d'autre part ce terme correctif peut �egalement per-mettre �a l'utilisateur de sp�eci�er ses propres crit�eres d'intelligibilit�e. Cependant, cettecomposante ne pr�esente pas d'int�eret dans un contexte exp�erimental classique, surtoutlorsqu'il s'agit d'�evaluer le comportement de l'algorithme dans un but de comparaison etsur des probl�emes dont les caract�eristiques sont parfois connues. Par cons�equent, elle n'apas �et�e utilis�ee lors des exp�erimentations.4.2.1 L'estimateur de LaplaceComme l'ont montr�e les chapitres 1 et 2, de tr�es nombreux crit�eres ont �et�e propos�espour �evaluer la couverture d'une r�egle sur les exemples. Ce paragraphe d�etaille l'estimateurde Laplace, qui fournit une approximation plus �able d'une fr�equence que le r�esultatobtenu par simple comptage, et est appliqu�e dans le cadre de SIAO1 �a l'estimation de lacoh�erence de la r�egle �a �evaluer. L'utilisation de cet estimateur repose sur des argumentsth�eoriques aussi bien que pratiques. Du point de vue th�eorique, il est possible de justi�erson emploi de par sa construction [Jaynes96, Kodrato�98].Justi�cation th�eorique de l'estimateur de Laplace

120 CHAPITRE 4. SIAO1Soit fr la fr�equence r�eelle et fe son estimation, l'objectif �etant de minimiser l'erreur vuecomme le carr�e de l'�ecart entre ces deux valeurs, soit (fr � fe)2. Ne connaissant pas fr, ilest n�eanmoins possible de reformuler le probl�eme en consid�erant la densit�e de probabilit�e,not�ee P (fr) et d�e�nie sur fr 2 [0; 1]. Le probl�eme de minimisation de l'erreur revient donc�a trouver fe minimisant l'erreur moyenne donn�ee par l'expression :Err(fe) = E((fr � fe)2) = Z 10 (fr � fe)2:P (fr) dfr (Lapl 1)Cette fonction de fe �etant continue et d�erivable sur < � [0; 1], le fe minimum ne peut etretrouv�e qu'aux bornes (ce qui est impossible puisque limfe!+1Err(fe) = limfe!�1Err(fe) =+1) ou au(x) point(s) v�eri�ant d(Err(fe))dfe = 0. Or,Err(fe) = Z 10 (f 2r � 2:fr:fe + f 2e ):P (fr) dfr= Z 10 f 2r :P (fr) dfr � 2:fe: Z 10 fr:P (fr) dfr + f 2e : Z 10 P (fr) dfr| {z }=1D'o�u : d(Err(fe))dfe = ddfe �Z 10 f 2r :P (fr) dfr�| {z }=0 + ddfe ��2:fe: Z 10 fr:P (fr) dfr�+ ddfe hf 2e i= �2: Z 10 fr:P (fr) dfr + 2:feAinsi, r�esoudre d(Err(fe))dfe = 0 revient �a chercher fe telle que :fe = Z 10 fr:P (fr) dfr (Lapl 2)La densit�e de probabilit�e P (fr) est donn�ee dans le cas d'un probl�eme de classi�cationbinaire par la formule suivante, attribu�ee �a Bayes et mentionn�ee dans [Munteanu96] :p(f) = (p+ n+ 1)!p!n! :f p:(1� f)n (D)p et n sont les e�ectifs des exemples positifs et n�egatifs. De plus, la formule pr�ec�edented�ecrivant une distribution de probabilit�e, on a :Z 10 (p+ n+ 1)!p!n! :f p:(1� f)n:df = 1; ) Z 10 f p:(1� f)n:df = p!n!(p+ n+ 1)!En posant p = k + 1, on obtient :Z 10 fk+1:(1� f)n:df = (k + 1)!n!(k + n+ 2)! (Lapl 3)

4.2. Calcul de la qualit�e 121Il est donc possible de r�esoudre l'�equation (Lapl 2) :fe = Z 10 fr:P (fr) dfr = Z 10 fr: "(p+ n+ 1)!p!n! :f pr :(1� fr)n# dfr = (p+ n + 1)!p!n! Z 10 f p+1r :(1�fr)n dfrEn utilisant (Lapl 3), on obtient :fe = (p+ n+ 1)!p!n! : (p+ 1)!n!(p+ n+ 2)! = p + 1p+ n + 2Ce r�esultat peut etre g�en�eralis�e pour un nombre quelconque k de classes :fe = Estimateur de Laplace (p; n; k) = p+ 1p+ n+ k

122 CHAPITRE 4. SIAO1Int�eret pratique de l'estimateur de LaplaceUn autre r�esultat remarquable peut etre obtenu �a partir de la densit�e de probabilit�e (D).Si, au lieu de minimiser l'erreur quadratique de l'estimation de la fr�equence (Lapl 1), onse contente de choisir la valeur r�ealisant le maximum de cette densit�e de probabilit�e, onobtient le risque empirique fmax5 :ddf [p(f)] = 0) ddf "(p+ n + 1)!p!n! :f p:(1� f)n# = 0) (p+ n+ 1)!p!n!| {z }6=0 : ddf [f p:(1� f)n] = 0) p:f p�1:(1�f)n�f p:n:(1�f)n�1 = 0) p:(1�f) = n:f ) p�f:p = n:f ) p = f:(n+p)Finalement, l'�evaluation du risque empirique donne : fmax = pn+p = coh�erence(n,p).Ce r�esultat montre que la d�e�nition classique de la coh�erence (telle qu'elle est observ�eesur un ensemble d'apprentissage) n'est qu'une premi�ere approximation de la fr�equencerecherch�ee, et que l'estimation de cette fr�equence bas�ee sur un crit�ere de minimisationd'erreur met en jeu, contrairement �a la premi�ere approximation, le nombre k de classes.En pratique, l'utilisation de l'estimateur de Laplace pour l'�evaluation des r�egles de SIAO1s'est r�ev�el�ee tout �a fait positive, et ce pour deux raisons :Prise en compte de la repr�esentativit�e statistiqueUn premier avantage de l'estimateur de Laplace est que contrairement �a la coh�erence,il est sensible aux e�ectifs (donc �a la couverture) de la r�egle consid�er�ee. Soientpar exemple deux r�egles R1 et R2, couvrant respectivement (p1 = 2; n1 = 1) et(p2 = 20; n2 = 10) exemples positifs et n�egatifs. La coh�erence ne permet pas deles distinguer, puisque fmax(R1) = fmax(R2) = 23 , alors que l'estimateur de Laplacefournira un meilleur score �a la r�egle dont la couverture est plus importante : fe(R1) =35 = 0; 6, et fe(R2) = 2132 = 0; 65 (voir �gure 4.4).En ce qui concerne SIAO1, cette propri�et�e fait de l'estimateur de Laplace un ex-cellent compromis. En e�et :{ D'une part, la coh�erence observ�ee fmax de la r�egle est une caract�eristique cri-tique, puisque l'algorithme d'apprentissage proc�edant par g�en�eralisations suc-cessives, fmax ne peut que d�ecro�tre, et il faut donc imm�ediatement p�enaliserfortement toute r�egle peu coh�erente. Cette premi�ere contrainte est bien surprise en compte puisque l'estimateur de Laplace estime une fr�equence qui cor-respond �a la coh�erence. Ce dernier est d'ailleurs tr�es proche du point de vuede son expression comme de son comportement de fmax.5(D) est bien sur continue et d�erivable sur [0; 1] ; l'�etude de la d�eriv�ee (dont le calcul est donn�e ci-apr�es)montre que D est croissante de 0 jusqu'�a un point fmax puis d�ecroissante de fmax �a 1.

4.2. Calcul de la qualit�e 123p(
f)
0 10.5
0
1
2
3
4
5
(p=2,n=1) (p=20,n=10)
Densites de probabilites
0,660,650,6
fmax(R1)
fmax(R2)fe(R2)
fe(R1)
Fig. 4.4: Comparaison entre fe et fmax pour R1 et R2.{ D'autre part, il faut �egalement etre capable de prendre en compte la couverturede la r�egle a�n de favoriser le d�eveloppement du noyau. Comme l'a montr�el'exemple pr�ec�edent, seul fe prend en compte cet aspect, alors que fmax l'ignore.Robustesse par rapport au bruitLe second avantage de l'estimateur de Laplace est qu'en corollaire �a sa prise encompte de la repr�esentativit�e statistique, il est moins sensible au bruit que la coh�erence :soient de nouveau R1 et R2, couvrant cette fois respectivement (p1 = 10; n1 = 0) et(p2 = 99; n2 = 1) exemples positifs et n�egatifs. Si la coh�erence donne une pr�ef�erence�a la premi�ere r�egle (fmax(R1) = 1, fmax(R2) = 0; 99), ce sera l'inverse dans le cas del'estimateur de Laplace (fe(R1) = 0; 92, fe(R2) = 0; 98).Conclusion sur l'estimateur de LaplaceL'estimateur de Laplace, qui est utilis�e ici a�n de mesurer la coh�erence des r�egles apprises,s'est r�ev�el�e parfaitement adapt�e de par sa simplicit�e de calcul (aucun param�etre ne doitetre ajust�e par l'utilisateur), sa capacit�e �a r�esister au bruit et sa prise en compte de lacouverture des r�egles par le biais de sa sensibilit�e aux e�ectifs mesur�es. De plus, de parsa construction, il fournit une combinaison �el�egante et math�ematiquement justi��ee desnotions de coh�erence et de compl�etude.

124 CHAPITRE 4. SIAO14.2.2 Le biais syntaxiqueIl peut arriver que la couverture mesur�ee sur la base d'apprentissage ne soit pas su�-isante pour guider le processus d'induction. En e�et, le nombre d'exemples �etant le plussouvent tr�es petit au regard de la taille de l'espace de recherche, un grand nombre d'hy-poth�eses auront des couvertures identiques. En particulier, il n'est pas rare que de nom-breux descendants d'un individu (c'est-�a-dire un grand nombre de ses g�en�eralisations)aient la meme qualit�e. Or, dans le cas o�u l'algorithme de recherche est confront�e �a unplateau, c'est-�a-dire �a une r�egion de l'espace comportant de nombreuses hypoth�eses decouvertures �equivalentes, il est possible que la population ne contienne plus que des indi-vidus ayant tous la meme qualit�e. Si de plus aucune des hypoth�eses au voisinage de cesindividus ne permet une am�elioration de la qualit�e, la recherche est bloqu�ee puisqu'au-cune insertion d'individu dans la population n'est possible. Ce ph�enom�ene a motiv�e laprise en compte par la fonction de qualit�e d'un autre type d'information bas�e sur l'aspectsyntaxique de la formule codant l'hypoth�ese.La g�en�eralit�e syntaxiqueUne solution au probl�eme expos�e ci-dessus a �et�e apport�ee sous la forme d'une fonction�a valeur dans ]0; 1] quanti�ant la g�en�eralit�e syntaxique d'une d�e�nition [Augier et al.95].Cette fonction �etait par construction croissante pour toute modi�cation syntaxique con-duisant �a une g�en�eralisation (abandon de pr�edicat, cr�eation ou �elargissement d'une dis-jonction, etc.), et son int�egration se �t de mani�ere �a garantir qu'elle ne puisse supplanter lecrit�ere de couverture en la pond�erant par un coe�cient su�samment petit. Intuitivement,l'ajout de cette fonction peut se concevoir comme une modi�cation de la topographie dupaysage de la fonction de qualit�e substituant aux plateaux parfaitement aplatis des zonesl�eg�erement orient�ees de telle sorte que l'algorithme soit guid�e vers les bords des plateauxcorrespondant aux formules les plus g�en�erales.Le principe de concisionCependant, s'il semble �evident de chercher �a favoriser dans le cadre de SIAO1 lesd�e�nitions les plus g�en�erales, il est �egalement important de prendre en compte, dansle biais syntaxique d'�evaluation des r�egles, d'autres pr�ef�erences partiellement contradic-toires avec le principe de g�en�eralit�e �enonc�e ci-dessus. Ainsi l'argument du rasoir d'Occam(expliqu�e chapitre 1 section 1.4.3), qui conduit �a pr�ef�erer { toutes choses �etant �egales parailleurs { les explications les plus courtes est apparu tr�es pertinent d�es les exp�eriencespr�eliminaires puisque l'utilisation de disjonctions internes dans le langage des pr�edicatsannot�es favorise l'apprentissage par c�ur dans les bases dont le nombre de symboles estimportant par rapport au nombre d'exemples. Il para�t donc n�ecessaire de favoriser lesd�e�nitions concises, et en particulier de p�enaliser l'ajout d'�el�ements dans les disjonctionslorsque ces derniers n'apportent aucun gain de couverture.

4.2. Calcul de la qualit�e 125D�e�nitionLa composante correspondant au biais syntaxique est prise en compte au moyen de lafonction BS d�e�nie ci-dessous. Cette fonction d'une hypoth�ese H et �a valeur dans [0; 1]r�ealise un compromis entre les crit�eres syntaxiques de g�en�eralit�e et de concision :BS(H) = 1 � 1Lmax �Xi=1 jDijXj=1P (Di(j)) (BS 1)Les notations sont les suivantes :{ H est l'hypoth�ese consid�er�ee, compos�ee de � atomes : H = D1 ^ ::: ^D�.{ Lmax correspond �a la longueur maximale des chromosomes de la base d'apprentissage(il s'agit donc �egalement du nombre maximum de g�enes de toute hypoth�ese).{ Chaque atome Di de H est d'arit�e jDij ; Di(k), avec 1 � k � jDij, d�enote alors leki�eme argument de l'atome Di.{ Di(0) fait r�ef�erence au symbole de pr�edicat de l'atome.Type du g�ene Valeur de PSymbole de pr�edicat p prof�(p)+1jjpjj�Etoile num�erique ou symbolique � 0Constante symbolique c prof�(c)+1jjcjj:disjmaxConstante num�erique n 1disjmaxDisjonction symbolique fc1 _ ::: _ ckg 1jjc1jj:disjmax :Pki=1(prof�(ci) + 1)Disjonction num�erique fn1 _ ::: _ nlg ldisjmaxIntervalle num�erique [n1:::n2] 2disjmax:lg(n1;n2)Variable symbolique X 1jjXjj:disjmax ou 0 aVariable num�erique Y 1jjY jj:disjmax ou 0 aaLa p�enalit�e de complexit�e n'est appliqu�ee qu'�a chaque nouveau symbole de variable rencontr�e.Tab. 4.2: Fonction de p�enalit�e d�e�nie sur les g�enes.{ La fonction P attribue une p�enalit�e dans [0::1] �a tout g�ene, comme d�ecrit dans letableau 4.2. prof�(x) d�enote le nombre de symboles strictement sup�erieurs �a x parla hi�erarchie d�e�nie sur son type ; jjxjj le nombre total de symboles de meme typeque x ; disjmax correspond au nombre maximum d'�el�ements que peut comporterune disjonction et lg(n1; n2) au nombre de constantes num�eriques comprises dansl'intervalle [n1; n2].

126 CHAPITRE 4. SIAO1Propri�et�esDe par sa d�e�nition d'une part, et la pond�eration de la fonction de p�enalit�e P d'autrepart, la formule (BS 1) favorisera par ordre de pr�ef�erence les traits suivants :Au niveau des pr�edicats1. L'absence de symbole de pr�edicat.2. La pr�esence d'un symbole de pr�edicat aussi g�en�eral que possible d'apr�es lahi�erarchie d�e�nie sur les pr�edicats qui provient de la th�eorie du domaine.Au niveau des types num�eriques1. La pr�esence d'une �etoile *, ce symbole ayant la propri�et�e de s'apparier avectout symbole du meme type sans propager quelque contrainte que ce soit.2. La pr�esence d'un symbole de variable, qui contrairement �a l'�etoile peut corre-spondre �a l'ajout implicite d'une contrainte d'�egalit�e dans le cas o�u au moins unautre symbole identique �gure dans l'hypoth�ese. A�n de favoriser l'intelligibilit�ede la formule (au d�etriment de sa g�en�eralit�e), la p�enalit�e appliqu�ee avantageles hypoth�eses minimisant le nombre de symboles de variable di��erents.3. La pr�esence d'un intervalle num�erique aussi large que possible. Comme la notionde largeur d'un intervalle n'a pas de sens dans l'absolu, elle est mesur�ee icipar rapport aux donn�ees comme le nombre de constantes num�eriques du typeconsid�er�e couvertes par cet intervalle.4. La pr�esence d'une constante.5. La pr�esence d'une disjonction contenant aussi peu d'�el�ements que possible.Conform�ement au crit�ere du rasoir d'Occam, la concision des hypoth�eses estici pr�ef�er�ee �a leur g�en�eralit�e puisque les disjonctions sont les structures les plusp�enalis�ees.Au niveau des types symboliques1. La pr�esence d'une �etoile *.2. La pr�esence d'un symbole de variable.3. La pr�esence d'une constante aussi g�en�erale que possible d'apr�es la hi�erarchied�e�nie sur le type consid�er�e qui provient de la th�eorie du domaine.4. La pr�esence d'une disjonction comportant aussi peu d'�el�ements que possible,ces derniers �etant aussi g�en�eraux que possible.

4.2. Calcul de la qualit�e 127Bien �evidemment, l'additivit�e des p�enalit�es provenant de (BS 1) implique que l'ordre despr�ef�erences n'est pas absolu. Par exemple, il est possible qu'une hypoth�ese combinant troistraits moyennement p�enalis�es obtienne un meilleur score qu'une hypoth�ese combinantun trait privil�egi�e et deux traits p�enalis�es. De meme, il est possible qu'une disjonctioncontenant un petit nombre de symboles tr�es g�en�eraux (au sens de la hi�erarchie) soitpr�ef�er�ee �a une constante tr�es sp�eci�que (au sens de cette meme hi�erarchie).Int�egration du biais syntaxique dans la fonction de qualit�eLe biais syntaxique �etant destin�e �a permettre une comparaison plus �ne des hypoth�esessans pour autant remettre en question le crit�ere de couverture (qui est primordial), lafonction de qualit�e est d�e�nie par :Q(H) = fe(H)| {z }estimateurde Laplace + � : BS(H)| {z }biaissyntaxiqueen choisissant un coe�cient � su�samment petit pour que les variations de fe(H) nepuissent etre couvertes par les variations de BS(H).Conclusion sur le biais syntaxiqueLa plupart des algorithmes d'apprentissage supervis�e fournissant un mod�ele compr�ehensiblepar l'utilisateur int�egrent, en sus des crit�eres classiques de couverture, des biais li�es �a laconcision ou �a l'intelligibilit�e des r�egles. Ainsi, dans le cadre de l'apprentissage attribut-valeur bas�e sur les arbres de d�ecision, l'algorithmeC4.5 (qui fait r�ef�erence dans ce domaine)int�egre une mesure permettant la mise en �uvre du principe de description de longueurminimum (MDL, cf. [Quinlan93], chapitre 5, section 2, pages 51 et suivantes). Dans le cadrede l'apprentissage relationnel (et plus pr�ecis�ement de la programmation logique inductive),les syst�emes FOIL et PROGOL (qui font r�ef�erence dans ce domaine), utilisent respective-ment les crit�eres de description de longueur minimum (MDL, cf. [Quinlan et al.93]) etde compression maximale de l'information [Muggleton95]. En�n, en ce qui concerne l'ap-prentissage relationnel bas�e sur les algorithmes g�en�etiques, le syst�eme REGAL et son suc-cesseur G-Net prennent en compte la simplicit�e des r�egles apprises (cf. [Neri97], chapitre11, section 1, pages 107-108).En ce qui concerne SIAO1, il a �et�e possible d'observer exp�erimentalement que l'ajoutdu biais syntaxique a eu des r�epercussions sur l'intelligibilit�e des r�egles induites, cettederni�ere ayant parfois pu etre notablement am�elior�ee (en particulier en ce qui concerneles bases comportant peu d'exemples et fortement relationnelles comme Mutagenesis).

128 CHAPITRE 4. SIAO14.2.3 R�eduction du cout de calculLa plus grande partie du temps de calcul des algorithmes de type g�en�erer et tester estconsacr�ee �a l'�evaluation des hypoth�eses construites, le cout d'application de l'op�erateurde ra�nement �etant dans la plupart des cas n�egligeable. Le tableau 5.2 (cf. chapitre 5)montre qu'en pratique, dans le cas de SIAO1, le temps consacr�e aux tests de subsomptiond�epasse 90% de la dur�ee totale du fonctionnement de l'algorithme d�es que la taille de labase d'apprentissage avoisine un millier d'exemples, et ce meme sur les probl�emes les moinscomplexes (qui ne sont pas relationnels). Dans le cas de probl�emes fortement relationnels,il va de soi que cette proportion augmente plus rapidement.A�n de r�eduire autant que possible cette dur�ee, qui correspond au facteur limitant {du point de vue du temps d'ex�ecution { de l'algorithme, plusieurs approches agissant �adi��erents niveaux de l'architecture s�equentielle peuvent etre envisag�ees6. Ces approchessont �enum�er�ees ci-dessous en allant du niveau le plus interne au niveau le plus externe :1. Diminuer la dur�ee de chaque test de subsomptionLa proc�edure d'appariement entre les hypoth�eses g�en�er�ees et les exemples d'appren-tissage pouvant etre extremement complexe en logique relationnelle, il est n�ecessairede pouvoir �a la fois r�esoudre tr�es rapidement les cas simples sans surcharge due �a unpr�e-traitement trop lourd tout en r�eduisant autant que possible la combinatoire desinstances plus di�ciles. Le chapitre 3 d�etaille un algorithme performant permettantla r�esolution de ce probl�eme.2. Diminuer la dur�ee de chaque �evaluationEn se basant sur la d�e�nition de la fonction de qualit�e, le cout de calcul de Q(H)d�epend des couts des fonctions fe(H) et BS(H). Cependant le cout de BS(H) esttout-�a-fait n�egligeable, alors que celui de fe(H), qui correspond �a l'�evaluation de lacouverture de H sur les exemples d'apprentissage est (exprim�e en nombre de testsde subsomption) �egal au nombre d'exemples de la base d'apprentissage. Puisque lesimple cout de ces tests repr�esente habituellement plus de 90% de la dur�ee totaledu fonctionnement de l'algorithme, toute diminution de la dur�ee des �evaluationsse basant sur une r�eduction du nombre des tests de subsomption n�ecessaires aurades r�epercussions notables. La m�ethode d'�elagage propos�ee ci-apr�es s'appuie sur ceprincipe.3. Diminuer le nombre d'�evaluationsUne derni�ere possibilit�e consiste �a r�eduire le nombre total d'�evaluations e�ectu�eespar l'algorithme. Plutot que de modi�er la strat�egie de recherche, ce qui risquerait deprovoquer une convergence pr�ematur�ee diminuant la qualit�e de la solution fournie,un syst�eme de m�emorisation (partielle) des �evaluations est propos�e et analys�e.6Le chapitre 5 sera consacr�e aux approches moins imm�ediates consistant �a modi�er les donn�ees fournies�a l'algorithme (techniques d'�echantillonnage) ou �a r�epartir l'implantation de ce dernier sur plusieursmachines.

4.2. Calcul de la qualit�e 129R�eduction de la dur�ee d'une �evaluationPuisque la quasi-totalit�e du temps de calcul de SIAO1 est consacr�ee aux tests de sub-somption, une strat�egie de r�eduction du nombre de tests a �et�e implant�ee. Celle-ci met �apro�t la contrainte pos�ee par le sch�ema de s�election �elitiste sp�eci�ant qu'un individu nepeut etre ins�er�e dans une population que si sa qualit�e est sup�erieure �a la qualit�e minimaleobserv�ee dans cette population. Plus g�en�eralement, elle peut etre utilis�ee dans le cadre detout algorithme de type g�en�erer et tester utilisant un seuil bas�e sur la couverture d�e�nipar une fonction f(p; n) croissante sur p et d�ecroissante sur n./* Test de couverture fe(H) optimis�e pour SIAO1 , partie 1/1 */max pos couv jfex 2 E=ex est de meme classe que Hgjmin neg couv 0i 1FaireSi apparie(H;Ei)Alors :Si ex n'est pas de la classe de H Alorsmin neg couv++Si (fe(max pos couv;min neg couv) < fe min) Alors�echanger Ei et Ei� 2! 0Sinon :Si ex est de la classe de H Alorsmax pos couv--Si (fe(max pos couv;min neg couv) < fe min) Alors�echanger Ei et Ei�2! 0i++Tant que (i � jBj)! fe(max pos couv;min neg couv)Le test de couverture optimis�e repose sur la constatation qu'il est possible, connaissant lavaleur fe min en dessous de laquelle l'hypoth�ese �evalu�ee ne sera pas ins�er�ee, de ra�ner aufur et �a mesure que les appariements sont e�ectu�es une estimation de la borne sup�erieurefe max(H) de l'�evaluation de la couverture de H. D�es que fe max(H) < fe min, l'�evaluationde la couverture est court-circuit�ee et l'individu est rejett�e. Si la complexit�e en nombre de

130 CHAPITRE 4. SIAO1tests de subsomption e�ectu�es dans le pire des cas de cette technique reste inchang�ee parrapport au test de couverture na��f, il est possible de noter une nette variation en moyenne.Il est �egalement possible de constater que cette variation devient d'autant plus forte quel'algorithme, au cours de son d�eroulement, travaille sur des sous-populations de qualit�ecroissante dont le seuil fe min augmente.De plus, les performances du �ltrage ont �et�e am�elior�ees en d�epla�cant les exemples n�egatifscouverts par H ainsi que les exemples positifs non couverts par H de telle mani�erequ'ils soient test�es en premier : selon l'application, les premiers exemples de la based'apprentissage correspondront donc aux soit aux exemples les plus discriminants (ap-pel�es nuances critiques ou near-misses), soit aux exemples bruit�es. Un compromis valid�eexp�erimentalement a �et�e trouv�e a�n de minimiser le cout de la r�eorganisation de B, �ala fois en nombre de d�eplacements ainsi que du point de vue de la complexit�e de lam�ethode utilis�ee. Ce dernier consiste �a ne proc�eder qu'�a un d�eplacement au maximum par�evaluation de couverture en �echangeant les exemples d'indices i et i� 2 lorsque le i�eme ex-emple permet l'application imm�ediate d'un court-circuit. En e�et, d'une part cet exemplen'est autre que l'exemple discriminant d'indice maximal dont on peut avoir connaissance(compte-tenu de la strat�egie adopt�ee), et d'autre part l'�echange des exemples i et i � 2correspond �a un d�eplacement vers le d�ebut de la liste des exemples qui est proportion-nel �a l'�eloignement et de cout tr�es faible (contrairement, par exemple, �a un d�ecalage deplusieurs indices dans une liste).Validation exp�erimentaleA�n de valider globalement l'optimisation propos�ee, des donn�ees relatives au d�eveloppementd'un noyau choisi al�eatoirement ont �et�e r�ecolt�ees sur di��erents probl�emes d'apprentissage(cf. tableau 4.3). Il d�ecoule de ces r�esultats que le gain observ�e en pratique est important,qu'il s'agisse de la r�eduction du nombre d'appariements ou du temps d'ex�ecution. D'autrepart, le fait que les gains en nombre d'appariements et en temps soient voisins d�emontre �ala fois la pr�epond�erance du cout relatif aux tests de couverture ainsi que le faible surcoutde calcul de fe min et du ra�nement progressif de l'estimation de fe.Base Gain Gain Appariements(temps)a (appariements) M�ethode normale M�ethode optimis�eeIris 51; 56% 60; 02% 8; 8641 � 106 3; 5437 � 1061000 Trains 55; 37% 57; 96% 9; 6230 � 106 4; 0451 � 106Mushrooms 73; 78% 75; 14% 2; 0360 � 107 5; 0616 � 106Census-Income ND 25; 83% 2; 1369 � 109 1; 5848 � 109Tab. 4.3: R�eduction observ�ee du nombre d'appariements sur di��erentes bases.aCette mesure comprend le chargement des donn�ees, le d�eveloppement du noyau et le post-traitement.

4.2. Calcul de la qualit�e 131Les graphes 4.5 { 4.8 d�etaillent la variation du nombre moyen d'appariements n�ecessaires�a l'�evaluation d'un individu au cours du d�eveloppement d'un noyau. Chaque �evolution a�et�e d�ecoup�ee en 50 parties �egales ; pour chacune de ces parties le ratio moyen du nombred'appariements m�ethode optimis�eem�ethode normale et son �ecart-type ont �et�e calcul�es (les courbes correspon-dent donc �a des donn�ees normalis�ees). Le ph�enom�ene de r�eduction progressive du nombremoyen d'appariements n�ecessaires �a l'�evaluation des individus est tr�es nettement percep-tible sur les bases d'apprentissage peu bruit�ees. Ce ph�enom�ene combine d'une part lese�ets du d�eplacement des exemples les plus discriminants et d'autre part l'augmentationdu seuil fe min au cours de l'�evolution. Par contre, dans le cas des bases comportant untaux de bruit important (c'est-�a-dire lorsqu'il est n�ecessaire de relaxer la coh�erence desr�egles a�n d'obtenir une bonne couverture), la r�eduction du nombre d'appariements estmoindre et non d�ecroissante dans la dur�ee.
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
1.1
0 10 20 30 40 50 60 70 80 90 100
Iris
Fig. 4.5: Iris 0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
1.1
0 10 20 30 40 50 60 70 80 90 100
Trains
Fig. 4.6: 1000 Trains
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
1.1
0 10 20 30 40 50 60 70 80 90 100
Mushrooms
Fig. 4.7: Mushrooms 0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
1.1
0 10 20 30 40 50 60 70 80 90 100
Census Income
Fig. 4.8: Census-Income

132 CHAPITRE 4. SIAO1R�eduction du nombre d'�evaluationsUn technique utilis�ee par bien des algorithmes de recherche travaillant dans des domaineso�u le cout d'�evaluation d'un individu est prohibitif consiste �a s'appuyer sur une m�emoireconservant les r�esultats des �evaluations. Dans le cadre des algorithmes d'�evolution, cetteid�ee vient d'autant plus facilement que la population tient d�ej�a ce role pour l'algorithme.De plus, comme SIAO1 est dot�e d'un sch�ema de s�election �elitiste non redondant, l'id�eede l'ajout d'un �ltre �ecartant les individus similaires en amont du test d'inclusion { c'est-�a-dire avant �evaluation { est imm�ediate.Il est cependant possible de compl�eter ce �ltre puisque ce dernier ne s'appuie que surune m�emoire des individus performants d�ej�a pr�esents. Une autre m�emoire (de taille iden-tique �a la population), structur�ee sous forme de �le et fonctionnant comme un ensembletabou [Glover et al.93], a donc �et�e ajout�ee a�n de prendre en compte les individus peuperformants ne faisant pas partie de la population.Validation exp�erimentaleLes r�esultats ci-dessous montrent que si le premier �ltre classique ne diminue pas notable-ment le nombre d'�evaluations, le second, bas�e sur la m�emorisation des individus tabous,se r�ev�ele plus e�cace.Base Gain total �Evaluations(�evaluations) Sans �ltres Filtre simple Filtre tabouIris 72; 31% 63 764 7 256 (11,38%) 38 855 (60,93%)1000 Trains 65; 78% 74 341 5 357 ( 7,21%) 43 544 (58,57%)Mushrooms 70; 52% 75 474 8 584 (11,37%) 44 648 (59,15%)Census-Income 38; 43% 2 211 304 400 620 (18,11%) 449 247 (20,32%)Tab. 4.4: R�eduction observ�ee du nombre d'�evaluations sur di��erentes bases.4.3 Les op�erateurs d'�evolutionLes op�erateurs de mutation et de croisement de SIAO1, qui se distinguent tr�es claire-ment des variantes �evolutionnaires habituelles, sont d�ecrits en d�etail dans cette section.Les principales di��erences, qui sont motiv�ees par les principes fondant la strat�egie derecherche de SIAO1, sont rappel�ees et r�esum�ees �a la section 4.3.3, consacr�ee �a l'analysedu biais de recherche.

4.3. Les op�erateurs d'�evolution 1334.3.1 La mutationTout comme la mutation classique utilis�ee dans l'AGC, il s'agit d'un op�erateur unairestochastique dont la fonction est de permettre l'exploration du voisinage imm�ediat d'unindividu. Intuitivement, l'application de la mutation peut donc se concevoir du point devue de l'exploration de l'espace de recherche comme une marche al�eatoire ayant pourorigine l'individu et proc�edant par petits pas.Son fonctionnement est le suivant :1. D�eterminer l'ensemble G des g�enes g�en�eralisables (il s'agit des g�enes ne valant pas* et n'appartenant pas �a un atome abandonn�e). Soit par exemple le chromosome :Chromosome Forme Type Valeursg�ene no 1 Pr�edicat | ! P�ereg�ene no 2 Variable Personne ! Xg�ene no 3 Constante Personne ! jeang�ene no 4 Pr�edicat | ! �g�ene no 5 Variable Personne ! Yg�ene no 6 Constante Personne ! christopheg�ene no 7 Pr�edicat | ! M�ereg�ene no 8 Variable Personne ! Xg�ene no 9 Constante Personne ! *G = f1; 2; 3; 7; 8g puisque le neuvi�eme g�ene (qui vaut *) ne peut etre g�en�eralis�e etque l'atome relatif aux g�enes 4 �a 6 est abandonn�e (� d�enote un symbole de pr�edicatabandonn�e).2. S�electionner al�eatoirement (�equiprobabilit�e) un g�ene-cible g 2 G.3. S�electionner en fonction du type de g et des biais sur ce type l'une des r�egles R1...R6de g�en�eralisation et l'appliquer.Les r�egles de g�en�eralisation, qui sont d�ecrites ci-dessous, sont pour la plupart adapt�eesde celles propos�ees par Michalski dans le cadre du calcul des pr�edicats annot�es (APC,[Michalski84]). A la description de la r�egle ont �et�e ajout�es entre crochets les noms desr�egles �gurant dans [Michalski84] qui s'en approchent le plus. L'�el�ement soulign�e dans lesexemples fournis correspond au g�ene g sur lequel porte la mutation.R1 G�en�eralisation d'un symbole de pr�edicat[Constructive generalization rule, Dropping condition rule]Le symbole de pr�edicat s�electionn�e est remplac�e par son p�ere dans la hi�erarchie. S'iln'a pas de p�ere, l'atome est abandonn�e.

134 CHAPITRE 4. SIAO1Exemples :Voiture(X) ��! V�ehicule(X)V�ehicule(X) ��! VraiR2 G�en�eralisation fonctionnelle d'une constante symbolique[Climbing generalization rule, Extending reference rule]Cette r�egle applique al�eatoirement l'une des deux transformations suivantes : soit lesymbole de constante g s�electionn�e est remplac�e par son p�ere dans la hi�erarchie, soitil donne naissance �a une disjonction interne le contenant et �a laquelle on ajoute unautre symbole de constante choisi. Si g n'a pas de p�ere, ou ne peut etre compl�et�e parun autre symbole de constante (l'ensemble de choix est vide), alors il est remplac�epar *.Exemples :�El�ement(X,rectangle,rouge) ��! �El�ement(X,polygone,rouge)�El�ement(X,polygone,rouge) ��! �El�ement(X,*,rouge)�El�ement(X,rectangle,rouge) ��! �El�ement(X,frectangle _ cercleg,rouge)R3 G�en�eralisation relationnelle d'une constante symbolique[Turning constraints into variable rule]Les occurrences du symbole de constante s�electionn�e sont remplac�ees par un nouveausymbole de variable7 avec une probabilit�e donn�ee.Exemples :P�ere(pierre,jean) ^ P�ere(jean,christophe) ^ M�ere(jean,elisabeth)��! P�ere(pierre,X) ^ P�ere(X,christophe) ^ M�ere(X,elisabeth)P�ere(pierre,jean) ^ P�ere(jean,christophe) ^ M�ere(jean,elisabeth)��! P�ere(pierre,X) ^ P�ere(X,christophe) ^ M�ere(jean,elisabeth)R4 G�en�eralisation fonctionnelle d'une constante num�erique[Extending reference rule, Closing interval rule]La constante num�erique g s�electionn�ee donne naissance soit �a une disjonction internela contenant et �a laquelle on ajoute une autre constante num�erique choisie, soit �a unintervalle num�erique g�en�er�e en choisissant une constante sup�erieure ou inf�erieure.7En e�et, la variabilisation �a l'aide d'un symbole de variable d�ej�a pr�esent ne produit pas une formulestrictement plus g�en�erale comme le montre la transformation suivante : P (a; b; c) �:fX=ag�! P (X; b; c) �:fX=cg�!P (X; b;X).

4.3. Les op�erateurs d'�evolution 135Exemples :Temp�erature(X,97,3) ��! Temp�erature(X,[97,3 .. 98,5])Temp�erature(X,97,3) ��! Temp�erature(X,f86,2 _ 97,3g)R5 G�en�eralisation relationnelle d'une constante num�erique[Turning constraints into variable rule]Les occurrences du symbole de constante s�electionn�e sont remplac�ees par un nouveausymbole de variable6 avec une probabilit�e donn�ee.Exemple :Plus(3,0,3) ��! Plus(X,0,X)R6 Extension des domaines[Extending reference rule]Il est possible de poursuivre la relaxation des contraintes en continuant de g�en�eraliserdes domaines g lorsque ceux-ci sont s�electionn�es.Exemples :�El�ement(X,f rectangle _ cercleg,rouge)��! �El�ement(X,f rectangle _ cercle _ triangleg,rouge)P�ere(pierre,X) ^ P�ere(X,christophe) ^ M�ere(X,elisabeth)��! P�ere(pierre,Y) ^ P�ere(Y,christophe) ^ M�ere(X,elisabeth)Temp�erature(X,[97,3 .. 98,5]) ��! Temp�erature(X,[97,3 .. 102,4])Temp�erature(X,f97,3 _ 86,2g) ��! Temp�erature(X,f86,2 _ 97,3 _ 98,5g)Bien que la mutation de SIAO1 partage quelques points communs (mentionn�es aupara-vant) avec l'op�erateur de mutation de l'AGC, son adaptation �a la strat�egie de rechercheainsi qu'�a la repr�esentation utilis�ees lui conf�ere des propri�et�es qui l'en di��erencient nette-ment :Orientation ascendanteA�n de se conformer au type de recherche envisag�e (la croissance de noyaux parg�en�eralisations successives), la mutation est ici un op�erateur unidirectionnel pour larelation d'ordre `2. Contrairement �a la mutation de l'AGC, il n'existe donc aucunepossibilit�e de retour en arri�ere , puisqu'une telle op�eration correspondrait �a unesp�ecialisation de la formule.Fr�equence �elev�eeDans le cadre de l'AGC (expliqu�e par [Goldberg89]), le role de la mutation se r�eduit�a perturber avec une faible probabilit�e les individus de la population a�n de s'assurer

136 CHAPITRE 4. SIAO1que tout point de l'espace de recherche peut etre atteint. En ce qui concerne SIAO1,le role de la mutation est aussi important que celui du croisement puisqu'il s'agit depermettre une ascension du treillis de g�en�eralisation dans le voisinage de l'individuconsid�er�e. L'importance de cet op�erateur peut etre mesur�ee par le fait que son tauxd'utilisation, d�etermin�e par la strat�egie d'allocation des ressources aux op�erateurs,peut etre voisin de 50% sur certains probl�emes.Comportement non localBien qu'elle s'applique �a partir d'un unique g�ene s�electionn�e et qu'elle ait pourbut d'explorer le voisinage imm�ediat de l'individu, la mutation de SIAO1 peut etreamen�ee �a modi�er ou avoir des r�epercussions directes sur plus d'un g�ene dans le chro-mosome (par exemple lors d'une variabilisation). Ce ph�enom�ene est du au fait que lesespaces g�enotypiques et ph�enotypiques ne sont pas structur�es de la meme mani�ere,puisque certaines modi�cations de faible distance ph�enotypique ne peuvent etreobtenues que par des modi�cations plus importantes du point de vue g�enotypique.Les �gures 4.9 et 4.10 montrent les distances entre di��erentes g�en�eralisations d'uneformule du point de vue du g�enotype (il s'agit du nombre de g�enes modi��es) et dupoint de vue du ph�enotype (il s'agit de la distance dans le treillis des g�en�eralis�es quiest structur�e par la relation de subsomption).P(X,X) P(X,Y) P(Y,X)
P(a,X)P(X,a)
P(a,a)
2
1
0
distance
Fig. 4.9: Structure de l'espace (g�enotype)P(a,a)
P(X,a) P(a,X)P(X,X)
P(X,Y) P(Y,X)
distance
0
2
1Fig. 4.10: Structure de l'espace (ph�enotype)11 La relation `2 �etant transitive, les liens redondants du treillis n'ont pas �et�e repr�esent�es.Fonctionnement (faiblement) dirig�e par les donn�eesUne derni�ere caract�eristique de la mutation propos�ee, qui la di��erencie de l'op�erateurclassique, provient des crit�eres mis en jeu lors des choix n�ecessaires �a l'applicationdes r�egles. En e�et, malgr�e l'aspect stochastique et peu inform�e de l'op�erateur, ilest possible de prendre en compte certaines informations simples collect�ees lors dupr�e-traitement de la base d'apprentissage, comme par exemple la distribution desconstantes symboliques ou num�eriques au sein des exemples d'apprentissage en fonc-tion de leur classe. Ne faisant aucune hypoth�ese sur les relations possibles au sein desdonn�ees, les crit�eres de choix sp�eci��es ci-dessous peuvent tout de meme guider dansune certaine mesure la recherche d'une solution et �eviter certaines surg�en�eralisationsde disjonctions internes.{ Le choix du symbole de constante num�erique (resp. symbolique) �a ajouter pourcr�eer ou �etendre une disjonction num�erique (resp. symbolique) interne se fait �a
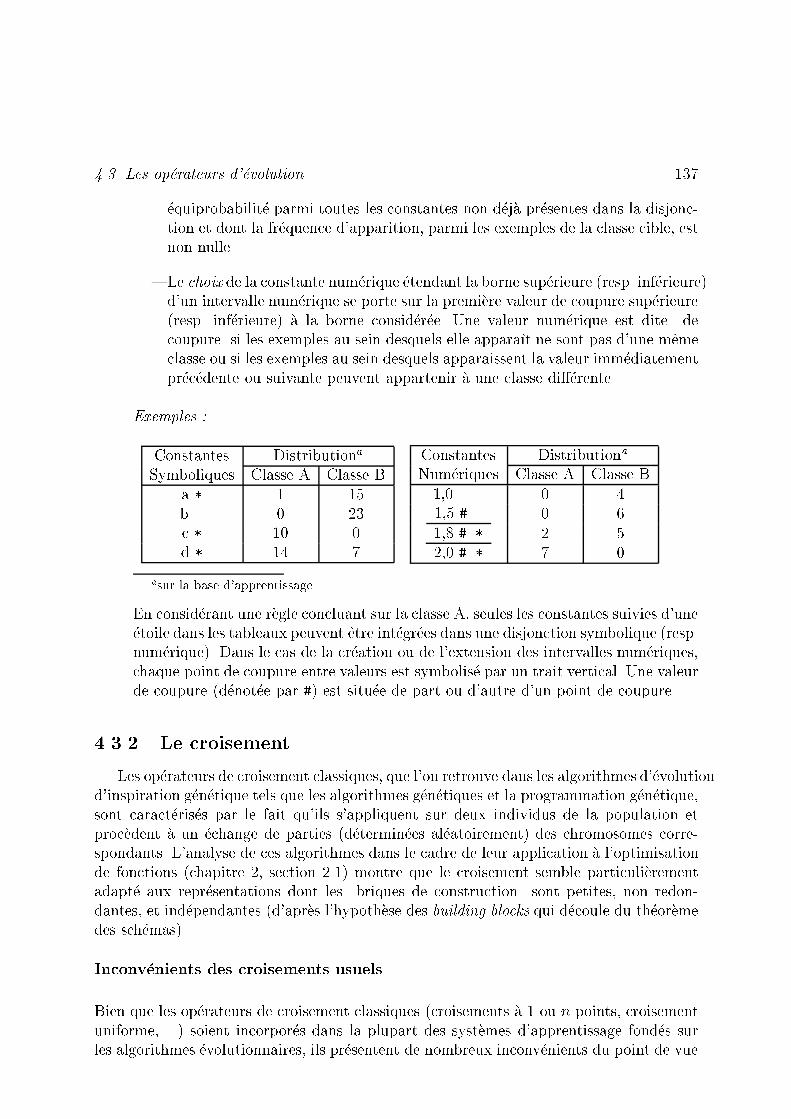
4.3. Les op�erateurs d'�evolution 137�equiprobabilit�e parmi toutes les constantes non d�ej�a pr�esentes dans la disjonc-tion et dont la fr�equence d'apparition, parmi les exemples de la classe cible, estnon nulle.{ Le choix de la constante num�erique �etendant la borne sup�erieure (resp. inf�erieure)d'un intervalle num�erique se porte sur la premi�ere valeur de coupure sup�erieure(resp. inf�erieure) �a la borne consid�er�ee. Une valeur num�erique est dite decoupure si les exemples au sein desquels elle appara�t ne sont pas d'une memeclasse ou si les exemples au sein desquels apparaissent la valeur imm�ediatementpr�ec�edente ou suivante peuvent appartenir �a une classe di��erente.Exemples :Constantes DistributionaSymboliques Classe A Classe Ba * 1 15b 0 23c * 10 0d * 14 7Constantes DistributionaNum�eriques Classe A Classe B1,0 0 41,5 # 0 61,8 # * 2 52,0 # * 7 0asur la base d'apprentissage.En consid�erant une r�egle concluant sur la classe A, seules les constantes suivies d'une�etoile dans les tableaux peuvent etre int�egr�ees dans une disjonction symbolique (resp.num�erique). Dans le cas de la cr�eation ou de l'extension des intervalles num�eriques,chaque point de coupure entre valeurs est symbolis�e par un trait vertical. Une valeurde coupure (d�enot�ee par #) est situ�ee de part ou d'autre d'un point de coupure.4.3.2 Le croisementLes op�erateurs de croisement classiques, que l'on retrouve dans les algorithmes d'�evolutiond'inspiration g�en�etique tels que les algorithmes g�en�etiques et la programmation g�en�etique,sont caract�eris�es par le fait qu'ils s'appliquent sur deux individus de la population etproc�edent �a un �echange de parties (d�etermin�ees al�eatoirement) des chromosomes corre-spondants. L'analyse de ces algorithmes dans le cadre de leur application �a l'optimisationde fonctions (chapitre 2, section 2.1) montre que le croisement semble particuli�erementadapt�e aux repr�esentations dont les briques de construction sont petites, non redon-dantes, et ind�ependantes (d'apr�es l'hypoth�ese des building blocks qui d�ecoule du th�eor�emedes sch�emas).Inconv�enients des croisements usuelsBien que les op�erateurs de croisement classiques (croisements �a 1 ou n points, croisementuniforme, ...) soient incorpor�es dans la plupart des syst�emes d'apprentissage fond�es surles algorithmes �evolutionnaires, ils pr�esentent de nombreux inconv�enients du point de vue

138 CHAPITRE 4. SIAO1de l'AS. Les paragraphes suivants d�etaillent ces d�efauts et motivent la conception d'unop�erateur di��erent pour SIAO1.Les croisements classiques sont des op�erateurs aveugles pour l'ASContrairement au cadre de l'optimisation qui caract�erise le contexte d'applicationdes algorithmes g�en�etiques, le domaine de l'apprentissage supervis�e permet, rien quede par sa sp�eci�cation, de disposer de connaissances (d�eriv�ees, par exemple, de larelation de g�en�eralit�e) qui pourraient etre exploit�ees par les op�erateurs de recherche.La �gure 4.11 illustre le comportement multidirectionnel du croisement du point devue de la relation de g�en�eralit�e8 : �etant donn�es les parents (P1; P 01) et (P2; P 02), ilest possible de g�en�erer par �echange de g�enes des enfants (E1; E 01) et (E2; E 02) plusg�en�eraux, plus sp�eci�ques ou encore incomparables par rapport �a leurs parents ;et ce meme lorsque le langage est d'ordre 0 et que tous les individus proviennentd'un noyau commun (dans cet exemple : a b c d ). D'autre part, comme il aP1 * * c dP 01 a b * * ��! E1 a b c dE 01 * * * *P2 a * c *P 02 * b * d ��! E2 a * * dE 02 * b c *E1 est plus g�en�eral que P1 et P 01, alors que E 01 est plus sp�eci�que que P1 et P 01.E2 et E 02 sont incomparables avec P2 et P 02. Les points de coupure sont repr�esent�espar jj . Fig. 4.11: Exemples de croisements par �echange de g�enes.�et�e montr�e dans la section pr�ec�edente, des op�erateurs unaires tels que la mutationpeuvent etre faiblement dirig�es par les donn�ees �a l'aide de connaissances concernantles distributions des symboles par rapport aux classes. Il devrait donc etre possiblede faire b�en�e�cier des op�erateurs binaires tels que le croisement de connaissancesencore plus sp�eci�ques telles que les exemples de la base d'apprentissage.Les op�erateurs de croisement classiques sont donc aveugles sur les probl�emes d'ap-prentissage puisqu'ils ne tirent pas parti d'informations sp�eci�ques �a ce contextetelles que :{ la relation de g�en�eralit�e qui structure l'espace de recherche ;{ la base d'apprentissage qui fonde en grande partie le crit�ere d'�evaluation deshypoth�eses.8Sous l'hypoth�ese, toujours v�eri��ee en pratique, qu'un g�ene repr�esente un �el�ement syntaxique pouvantetre g�en�eralis�e.

4.3. Les op�erateurs d'�evolution 139Cas des concepts fortement disjonctifs ou non convexesL'une des premi�eres intuitions9 concernant le fonctionnement du croisement est quece dernier est d'autant plus satisfaisant que la combinaison des points forts desparents produit des enfants performants. Cependant cette propri�et�e n'est pas v�eri��eedans le domaine de l'apprentissage supervis�e de concepts disjonctifs, puisque lesbriques de construction correspondent, pour la plupart des repr�esentations choisies,aux domaines des descripteurs. Comme le montre la �gure 4.12 dans le cas d'unX1
X2
P2
P1
P3E2
E1
E3
Concept cibleFig. 4.12: Croisements dans un espace �a deux descripteurs.domaine �a deux descripteurs, o�u chaque r�egle est de la forme \X1 2 [a1; b1] ^X2 2[a2; b2]", il est tr�es peu probable que le croisement de deux individus appartenant �ades sous-concepts distincts cr�ee des individus viables : les r�egles P1 et P3 ne peuventque produire E2 ou E3 dont la capacit�e pr�edictive du concept cible est nulle. Deplus, d�es que les r�egles ont une couverture importante, et �a moins que le conceptcible soit convexe, le croisement d'individus d'un meme sous-concept risque d'etreine�cace : la combinaison de P1 et P2 produit soit un individu moins g�en�eral queses parents, soit l'individu E1 de faible coh�erence. Cette �gure illustre �egalement lecomportement erratique des croisements classiques, autant du point de vue de lastructure de l'espace de recherche que du point de vue des connaissances relativesau probl�eme. En e�et, l'exploitation judicieuse de la relation de g�en�eralit�e conduittypiquement les op�erateurs �a dilater ou r�eduire les rectangles, alors que la prise encompte des exemples d'apprentissage consiste par exemple �a ajuster un rectangle detelle mani�ere qu'il couvre (resp. ne couvre pas) un exemple (resp. contre-exemple).Les briques de construction ne sont pas ind�ependantesLe probl�eme de la pertinence des croisements �evolutionnaires classiques est encoreplus aigu dans le cadre de l'apprentissage supervis�e relationnel parce que les briquesde construction sont tr�es fortement interd�ependantes. Les liens cr�e�es par les symboles9Il s'agit ici d'une reformulation intuitive des r�esultats qui d�ecoulent du th�eor�eme des sch�emas perme-ttant de caract�eriser les fonctions AG-di�ciles.

140 CHAPITRE 4. SIAO1de variable sont en e�et autant de contraintes non locales ayant une tr�es grandein uence sur la qualit�e de la r�egle cod�ee.Une multitude de travaux en PLI soulignent cet aspect du domaine, d'autant plusque les nombreux syst�emes bas�es sur des approches descendantes (par sp�ecialisation)sont particuli�erement sensibles �a ce ph�enom�ene. Ainsi, le fait que FOIL ([Quinlan et al.93,Quinlan et al.95], voir �egalement chapitre 1 section 1.5.2) ne puisse induire certainsconcepts �a cause de l'heuristique locale du gain d'information qui est bas�ee sur le cal-cul de l'avantage �a ajouter un atome est un inconv�enient reconnu. Une multitude destrat�egies, telles que la recherche de chemins relationnels [Richards et al.92] �a l'aidedu graphe des liens entre constantes, ou encore la sp�eci�cation de clich�es relation-nels [Silverstein et al.91] (motifs g�en�eriques associant plusieurs pr�edicats ainsi quedes liens sp�eci�ques) ont �et�e d�evelopp�ees a�n d'�echapper �a la myopie des approcheslocales : elle permettent de simuler partiellement un m�ecanisme d'anticipation (look-ahead), tout en maintenant l'explosion combinatoire dans des bornes raisonnables.D'autres syst�emes n�ecessitent une intervention de l'utilisateur a�n que ce derniersp�eci�e des biais qui conduiront �a la d�ecouverte du chemin relationnel : PROGOL([Muggleton95], voir �egalement chapitre 1 section 1.5.2) se r�ef�ere par exemple �a unensemble M de modes qui doit lui etre fourni. Ces modes, qui d�e�nissent l'espacede recherche contraint L(M) d�ecrivent entre autres :{ les pr�edicats pouvant �gurer dans la tete ou le corps des clauses g�en�er�ees(d�eclarations modeh et modeb) ;{ le type des arguments des pr�edicats (+type et -type font r�ef�erence �a un symbolede variable typ�e et orient�e, #type demande la pr�esence d'un terme clos typ�e) ;{ la structure des liens reliant les pr�edicats (un symbole de variable �etiquet�e +dans le corps de la clause doit obligatoirement avoir au moins une occurrenced�ej�a pr�esente dans le corps de la clause et �etiquet�ee -, ou dans la tete de laclause et �etiquet�ee +) ;{ une borne (�eventuellement in�nie) au nombre maximum d'occurrences de chaquesymbole de pr�edicat.Les biais de recherche et de langage �evoqu�es ci-dessus sont autant d'indices soulig-nant d'une part l'interd�ependance souvent tr�es forte entre les di��erentes composantesde formules solution aux probl�emes de PLI, et d'autre part la complexit�e prohibitivede la recherche de ces liens lorsqu'elle n'est pas contrainte.Le croisement n'est pas adapt�e �a SIAO1La strat�egie sous-tendant l'algorithme de SIAO1 �etant bas�ee sur le d�eveloppementde noyaux �a l'aide d'une recherche unidirectionnelle ascendante, cette derni�ere con-duit �a pr�ef�erer des op�erateurs aussi monotones ascendants et minimaux que possi-ble. Comme l'ont montr�e les remarques pr�ec�edentes, les croisements �evolutionnaires

4.3. Les op�erateurs d'�evolution 141classiques ne sont ni monotones ascendants, ni minimaux puisqu'ils g�en�erent des in-dividus plus g�en�eraux, sp�eci�ques ou incomparables �a leurs parents et que l'�echangede sous-cha�nes brise les liens relationnels.Les premi�eres versions de SIAO1 [Augier et al.95] mettaient en �uvre deux typesde croisements proc�edant par �echange de g�enes. Puisque toutes les formules d'unepopulation proviennent d'un meme noyau et que l'op�erateur de mutation ne modi�epas la structure des formules, ces op�erateurs g�en�eraient des chromosomes s�emantiquementcorrects. Cependant, leur int�eret �etait limit�e puisqu'ils se comportaient au mieuxcomme des op�erateurs d'hypermutation.Le paragraphe qui suit est consacr�e �a l'op�erateur de croisement actuel qui procure, parrapport �a la version pr�ec�edente, plusieurs avantages majeurs :{ Il peut etre dirig�e par les donn�ees, et g�en�ere des individus dont la structure rela-tionnelle est adapt�ee au probl�eme et non obligatoirement incluse dans la structuredu noyau.{ Il est ascendant (par rapport �a `2), rapidement calculable et non disruptif.L'op�erateur de croisement de SIAO1L'ensemble des remarques portant sur l'ad�equation des croisements �evolutionnaires clas-siques aux probl�emes d'apprentissage relationnel et �a la strat�egie de recherche de SIAO1ont motiv�e la cr�eation d'un op�erateur s'�eloignant sensiblement des canons du domaine.Le croisement propos�e est fond�e sur une approximation du moindre g�en�eralis�e relationnel(lgg : least general generalization, [Plotkin70]) not�e mg en fran�cais :D�e�nition 4.1 Moindre g�en�eralis�e de deux atomesSoient A1 = P1(t(1;1); :::; t(1;k)) et A2 = P2(t(2;1); :::; t(2;l)) deux atomes. Alors, si les sym-boles de pr�edicat sont �egaux (et donc de meme arit�e),mg(A1; A2) = P1(mg(t(1;1); t(2;1)); :::; mg(t(1;k); t(2;k)))avec :{ mg(t(1;i); t(2;i)) = t(1;i) si t(1;i) = t(2;i){ mg(t(1;i); t(2;i)) = X(t(1;i);t(2;i)) si t(1;i) 6= t(2;i).X(t(1;i);t(2;i)) est un symbole de variable �etiquet�e.D�e�nition 4.2 Moindre g�en�eralis�e de deux formulesSoient F1 = A(1;1) ^ ::: ^ A(1;n) et F2 = A(2;1) ^ ::: ^ A(2;m) deux formules. Alors,mg(F1; F2) = ^i2[1;n];j2[1;m]mg(A(1;i); A(2;j))

142 CHAPITRE 4. SIAO1Ces deux d�e�nitions sont imm�ediatement applicables dans le cadre du langage Lh parextension des d�e�nitions de mg(A1; A2) :{ Lorsque deux pr�edicats P1 et P2 ont un plus petit ancetre commun dans la hi�erarchierepr�esentant la th�eorie du domaine, ce dernier est par d�e�nition mg(P1; P2).{ Par contre, le moindre g�en�eralis�e de deux constantes symboliques t(1;i) et t(2;j) esttoujours la disjonction symbolique ft(1;i)_t(2;j)g dans le cas d'une modalit�e fonction-nelle, ou un symbole de variable �etiquet�e dans le cas d'une modalit�e relationnelle.L'exclusion mutuelle des modalit�es relationnelles et fonctionnelles assure l'unicit�edu moindre g�en�eralis�e de deux termes.{ Dans le cas des constantes num�eriques, il a �et�e d�ecid�e pour des raisons d'intelligibilit�ede g�en�erer, plutot qu'une disjonction, un intervalle. Cette r�egle ne produit pas lemoindre g�en�eralis�e des deux termes mais un presque moindre g�en�eralis�e .Les �gures 4.13 et 4.14 repr�esentent graphiquement le calcul des moindres g�en�eralis�es :{ mg( P (A;B) ^ P (B;C) ^ P (C;D) ^ P (D;A) ; P (X; Y ) ^ P (Y; Z) ^ P (Z;X) ) ;{ mg( P (A;B) ^ P (B;C) ^ P (C;A) ; P (X; Y ) ^ P (Y; Z) ).Les chi�res correspondent aux symboles de variable du r�esultat. Ces derniers sont issusdu regroupement d'une variable de chaque formule fournie en argument. Par exemple,dans le cas de la �gure 4.13, le chi�re 1 correspond �a la variable �etiquet�ee VAX issue desvariables A et X.4
910
111
2
8
12
3
7
6
5P
P
P P
P
P
P
PP
P P
P
X
YZP
PP
A B
CD
PP
P
P
Fig. 4.13: Exemple 1X
Y
P
ZP
P
P
1
2
7
P
P
8
3
4
P
P
5
6
9
PPP
A
BC
Fig. 4.14: Exemple 2Il est possible d'observer :{ que la taille maximale du moindre g�en�eralis�e de deux formules F1 et F2 est jF1j:jF2j(voir �gure 4.13) ;{ que la formule r�esultant du calcul n'est pas toujours sous forme simpli��ee (voir �gure4.14).

4.3. Les op�erateurs d'�evolution 143A�n d'att�enuer, comme dans le cas de GOLEM, l'explosion combinatoire des tailles desformules g�en�er�ees, une strat�egie a �et�e propos�ee dans le but d'extraire rapidement dupresque moindre g�en�eralis�e une composante de taille N aussi sp�eci�que que possible10.En notant Res le r�esultat construit par ajout successif d'atomes du presque moindreg�en�eralis�e Pmg, le pseudo-code de l'algorithme d'extraction est le suivant :{ G�en�erer la matrice de connexion entre les litt�eraux du presque moindre g�en�eralis�e{ Tant que (N > jResj) ^ (Pmg 6= ;){ Placer dans Res un atome de Pmg dont le taux de connection avec les �el�ementsde Res est maximum.Les avantages de la solution propos�ee sont nombreux :Contrairement aux croisements classiques, l'op�erateur propos�e peut etre dirig�e par lesdonn�ees (lorsqu'il s'applique �a un exemple de la base d'apprentissage de classe ad�equate) :il est donc capable de construire une formule relationnelle dont la structure est adapt�eeau probl�eme. De plus, le croisement de SIAO1 n'est pas disruptif puisque les blocs deconstruction consid�er�es ne sont pas relatifs aux �el�ements syntaxiques des chromosomes,mais aux positions des formules dans le treillis `2.Contrairement �a [Sebag98], qui propose dans le cadre de l'identit�e d'objet un op�erateurstochastique dont l'avantage est d'etre extremement rapide, la forme g�en�er�ee par le croise-ment peut etre di��erente des formes des exemples de la base d'apprentissage.Du point de vue de SIAO1, cet op�erateur est monotone ascendant pour la relation `2.L'heuristique utilis�ee permet de g�erer le compromis entre la taille des hypoth�eses g�en�er�eeset leur proximit�e (dans le treillis) du moindre g�en�eralis�e des formules sur lesquelles ils'applique : la recherche �etant ascendante, il est en e�et pr�ef�erable d'�eviter autant quepossible les surg�en�eralisations.4.3.3 R�ecapitulatif : le biais de recherche de SIAO1Le biais de recherche de SIAO1 est caract�eris�e au niveau des op�erateurs d'�evolutionpar deux grands principes qui le distinguent clairement des autres approches �evolutionnaires.Les op�erateurs sont ascendants et proc�edent par petits pasUne premi�ere caract�eristique de SIAO1 est l'exploration dirig�ee du treillis d�e�ni par larelation de g�en�eralit�e `2. Cette prise en compte de la structure de l'espace de recherche,associ�ee au sch�ema de s�election, assure une exploration e�cace puisque les cycles et lesredondances sont rendus impossibles. Par contre, cette meme propri�et�e suppose que les10Le param�etre N est un biais de langage pouvant etre ajust�e par l'utilisateur.

144 CHAPITRE 4. SIAO1op�erateurs puissent parfois g�en�erer des individus su�samment proches de leurs parentsa�n de fournir une solution de bonne qualit�e : puisqu'aucun retour en arri�ere n'est possible,l'algorithme doit etre capable de se rapprocher de la solution par petits pas ascendantsdans le treillis.Les op�erateurs sont dirig�es par les donn�eesUne seconde caract�eristique de SIAO1 vient de l'utilisation, par les op�erateurs, de donn�eesprovenant de la base d'apprentissage, qu'il s'agisse de la structure relationnelle des exem-ples ou de la distribution des symboles en fonction des classes des instances dans lesquellesils apparaissent. Deux points de vue peuvent alors etre port�es sur cette d�emarche.Une premi�ere analyse, pragmatique, permet de constater que l'introduction d'op�erateursdirig�es par les donn�ees peut sensiblement acc�el�erer la recherche et am�eliorer les r�esultats.En e�et, en supposant que les instances d'apprentissage soient repr�esentatives des concepts-cible, il semble l�egitime que les sauts inductifs fond�es sur les caract�eristiques de ces in-stances occasionnent de bonnes performances en g�en�eralisation.Une seconde analyse, plus dogmatique, critique cette approche du point de vue des algo-rithmes �evolutionnaires car elle s'apparente �a un sch�ema Lamarckien plutot que Darwin-iste. Ce jugement doit n�eanmoins etre temp�er�e en observant que si les autres approches,qui suivent le mod�ele g�en�erer et tester , ont e�ectivement un aspect Darwiniste bien plusprononc�e, ces derni�eres mettent �egalement en place { de mani�ere bien plus t�enue { de telsm�ecanismes. Par exemple REGAL et G-NET utilisent un op�erateur (le seeding) dirig�e parles donn�ees puisqu'il g�en�ere un nouvel individu �a l'aide d'un exemple du concept-cible.4.4 Post-traitement et Classi�cationCette section concerne le regroupement des r�egles de classi�cation fournies par l'al-gorithme d'�evolution a�n d'obtenir l'ensemble de r�egles �nal d�ecrivant les donn�ees, ainsique l'exploitation de cet ensemble pour la classi�cation de nouvelles instances.Contrairement �a SIA, la d�e�nition d'une distance entre formules est beaucoup plus di�cile�a obtenir dans le cas de la logique relationnelle que dans le cadre attribut-valeur. Cettedi��erence a motiv�e l'�elaboration de nouvelles strat�egies pour �elaguer l'ensemble des r�eglesobtenues et pour utiliser cet ensemble a�n de classer de nouvelles instances. A une strat�egiede d�ecision bas�ee sur la distance des instances aux r�egles et dans le cas d'un con its'appuyant sur la qualit�e normalis�ee des r�egles en d�esaccord, on a pr�ef�er�e un syst�emede vote bas�e sur la coh�erence observ�ee des r�egles ainsi que l'adjonction d'une classe pard�efaut. Par un e�et r�etroactif, la prise en compte de la coh�erence des r�egles lors duvote a n�ecessit�e le d�eveloppement d'un algorithme d'�elagage bas�e prioritairement sur lacoh�erence, et ne prenant en compte que dans un second temps l'aspect li�e �a la couverturede la r�egle consid�er�ee.

4.4. Post-traitement et Classi�cation 1454.4.1 Classi�cation des nouvelles instancesDe tr�es nombreux travaux en apprentissage automatique traitent des m�ethodes decombinaison de pr�edicteurs a�n d'obtenir un nouveau pr�edicteur plus performant. Lesdeux m�ethodes les plus connues sont le bagging (bootstrap aggregating) et le boosting[Breimann96, Freund et al.96, Bauer et al.99]. Bien que d'une part ces m�ethodes aientpour but de combiner di��erents r�esultats obtenus en utilisant plusieurs fois un memealgorithme d'apprentissage (chaque pr�edicteur correspond ainsi �a un r�esultat �nal con-cernant toutes les classes cibles sur l'ensemble de l'espace de recherche), et que d'autrepart la variation des conditions initiales n�ecessite la possibilit�e d'extraire di��erentes basesd'apprentissage (bagging) ou encore d'etre capable de modi�er les poids des instances(boosting), il est possible de se placer dans le contexte des r�egles apprises par SIAO1. Ene�et, les conditions issues du cadre d'o�u proviennent ces travaux sont les suivantes :1. Les pr�edicteurs obtenus doivent pouvoir etre en d�esaccord ;2. Les erreurs des pr�edicteurs doivent etre peu ou pas corr�el�ees ;3. L'algorithme d'apprentissage doit s'adapter facilement �a toute variation des donn�eesfournies en entr�ee.Il est ais�e de constater que les trois propri�et�es ci-dessus sont v�eri��ees par SIAO1 puisqu'ilest possible de consid�erer chaque d�eveloppement d'un noyau donn�e comme un algorithmed'apprentissage ind�ependant. Le fait que l'estimateur de Laplace utilis�e pour �evaluer lesr�egles g�en�er�ees tol�ere un certain niveau de bruit implique qu'il peut exister des portions del'espace o�u di��erents pr�edicteurs entreront en con it. D'autre part, chaque pr�edicteur estparticuli�erement sensible aux contraintes relatives �a la portion de l'espace d'o�u provient lenoyau �a partir duquel il a �et�e g�en�er�e. Ce ph�enom�ene de localit�e rend donc les pr�edicteurstr�es peu corr�el�es (bien qu'il soit impossible de supprimer toute corr�elation sur les erreursdues au bruit). En�n, le ph�enom�ene de localit�e implique �egalement qu'un noyau d�evelopp�epar SIAO1 est bien plus sensible aux variations dans son environnement qu'une m�ethodetr�es stable comme k les plus proches voisins (lorsque k devient su�samment important).En cons�equence, il semble tout �a fait opportun dans le cadre de SIAO1 de s'appuyersur les travaux concernant la combinaison de pr�edicteurs. Ces travaux ayant d�emontr�el'int�eret du vote pour la gestion des con its entre pr�edicteurs peu corr�el�es, c'est cettem�ethode qui a �et�e implant�ee. De plus, d'autres travaux (par exemple [Clark et al.91]) ontd�emontr�e un gain de performance lors de l'utilisation d'une proc�edure de vote pond�er�epar rapport �a la m�ethode classique d'ordonnancement des r�egles en liste de d�ecision. Auvu des r�esultats obtenus, il semble en e�et que cette m�ethode, qui consiste �a classer uneinstance par la classe de la premi�ere r�egle la couvrant, soit �a la fois moins performante(car la combinaison des r�egles est bien trop simpliste) et moins intelligible (car une listede d�ecision contient de nombreuses n�egations implicites).En ce qui concerne la m�ethode de vote, le choix s'est port�e sur une pond�eration des r�egles

146 CHAPITRE 4. SIAO1proportionnelle �a l'estimation de leur coh�erence pour diverses raisons : d'une part, lagrande majorit�e des travaux du domaine ont adopt�e soit cette m�ethode, soit le vote nonpond�er�e, et d'autre part, cette m�ethode est intuitive dans le sens o�u il semble raisonnabled'a�ecter un degr�e de croyance inversement proportionnel au taux d'erreur des r�egles. Deplus, bien que certains travaux proposent de conserver la totalit�e des r�egles apprises etd'ajuster leur poids de mani�ere �a minimiser le taux d'erreur sur la base d'apprentissage[Merz99], de nombreuses raisons jouent en faveur de la combinaison d'un algorithme devote et d'un algorithme d'�elagage :{ la proc�edure d'�elagage simpli�e la base de r�egles, ce qui am�eliore son intelligibilit�e ;{ les poids des r�egles ont une signi�cation pour l'utilisateur ;{ l'ajustement des poids combin�e au ph�enom�ene de localit�e augmente les risques desurapprentissage lorsque la base est bruit�ee.SIAO1 classe donc une nouvelle instance en faisant voter l'ensemble des r�egles la couvrantproportionnellement �a l'estimateur de Laplace de leur coh�erence. Comme dans tout vote,les contributions des r�egles concluant sur une meme classe sont ajout�ees. Dans le caso�u plusieurs classes obtiennent la contribution maximum, la d�ecision r�esulte d'un tirageal�eatoire parmi celles-ci. Lorsqu'aucune r�egle ne couvre l'instance �a classer, une classe pard�efaut est choisie.Le paragraphe suivant d�etaille l'obtention de l'ensemble de r�egles �nal ainsi que le choixde la classe par d�efaut.4.4.2 �Elagage des r�eglesDescription de l'algorithme d'�elagageL'objectif de cette proc�edure de post-traitement est de r�eduire autant que possible lenombre de r�egles de d�ecision tout en garantissant de bonnes performances par le syst�emede vote (le choix porte donc sur les r�egles candidates ainsi que sur la r�egle par d�efaut qu'ilest possible d'ajuster en fonction du sous-ensemble consid�er�e). En partant du constat quetout algorithme cherchant l'ensemble de r�egles optimal (du point de vue de la pr�ecision)sera dans le pire des cas de complexit�e exponentielle en fonction du nombre de r�egles(puisqu'�a partir de n r�egles il est possible de g�en�erer 2n ensembles de r�egles), la recherched'un algorithme d'�elagage s'oriente presque obligatoirement vers une solution approch�ee.L'algorithme propos�e, qui ne teste dans le pire des cas que n:(n+1)2 ensembles de r�egles, estle dual de celui propos�e par [Quinlan87]. En e�et, alors que dans le cas de l'apprentissage(par sp�ecialisation) d'arbres de d�ecision, l'ensemble de r�egles R �nal est cr�ee en retirant�a chaque �etape la r�egle r dont l'avantage11 est le plus important ; dans le cas de l'appren-11Il s'agit du nombre d'instances pour lesquelles la classe correcte est fournie par R n r et non par R,soustrait au nombre d'instances pour lesquelles le contraire se produit.

4.4. Post-traitement et Classi�cation 147tissage par g�en�eralisation de SIAO1 l'approche est inverse : R est construit �a partir dez�ero en ajoutant �a chaque �etape la r�egle fournissant le meilleur gain en pr�ecision sur labase d'apprentissage :/* Algorithme d'�elagage final pour SIAO1, partie 1/1 */Soit Reste = fr�egles ayant converg�eg et R = ;FaireSoit r 2 Reste = pr�ecision(r [ R) soit maximumSoit GainP = pr�ecision (r [ R)� pr�ecision (R) (*)Si (GainP > 0) AlorsR R[ rReste Reste n rTant que ((GainP > 0) ^ (Reste 6= ;))A�n de maximiser la pr�ecision, la classe par d�efaut { qui est r�e�evalu�ee et prise en compte�a chaque calcul de pr�ecision { correspond �a la classe la plus probable parmi les instancesnon couvertes par R.L'algorithme d'�elagage propos�e a pour principaux avantages d'etre simple, rapide, et defournir en pratique des solutions de bonne qualit�e. Par contre, il a l'inconv�enient d'etreine�cace lorsque toutes les hypoth�eses ont une couverture peu importante et caract�erisentla classe majoritaire. Dans ce dernier cas, l'algorithme s'arrete imm�ediatement sans con-sid�erer les ensembles constitu�es de plusieurs hypoth�eses qui pourraient am�eliorer la qualit�ede la solution. En pratique, il est possible d'�eviter cette con�guration d�efavorable enajoutant parmi les classes-cible les classes non majoritaires.Complexit�e de l'algorithme d'�elagageSoit r le nombre total de r�egles et n le nombre d'exemples de la base d'apprentissage. Ensupposant que l'implantation de l'algorithme m�emorise pr�ecision(R) (a�n d'�eviter sonrecalcul lors de chaque �evaluation de la ligne (*)), la complexit�e dans le pire des cas del'algorithme d'�elagage, not�ee C1, est d�etermin�ee par le fait qu'�a chaque �etape 1 � k � rde l'algorithme,R contiendra k�1 r�egles et Reste en contiendra r�k+1. Il faudra doncmesurer la pr�ecision de r � k + 1 ensembles contenant chacun k r�egles, pour un cout den:k:(n�k+1) tests de couverture. De plus, le calcul unique de pr�ecision(R) n�ecessiteran:(k � 1) tests de couverture. Ainsi :C1(n; k) = n: rXk=1 k:(r � k + 1) + (k � 1)) C1(n; k) = n: rXk=1 k:(r + 2)� k2 � 1 = n: "r:(r + 1)2 :(r + 2)� r:(r + 1):(2:r + 1)6 � r#
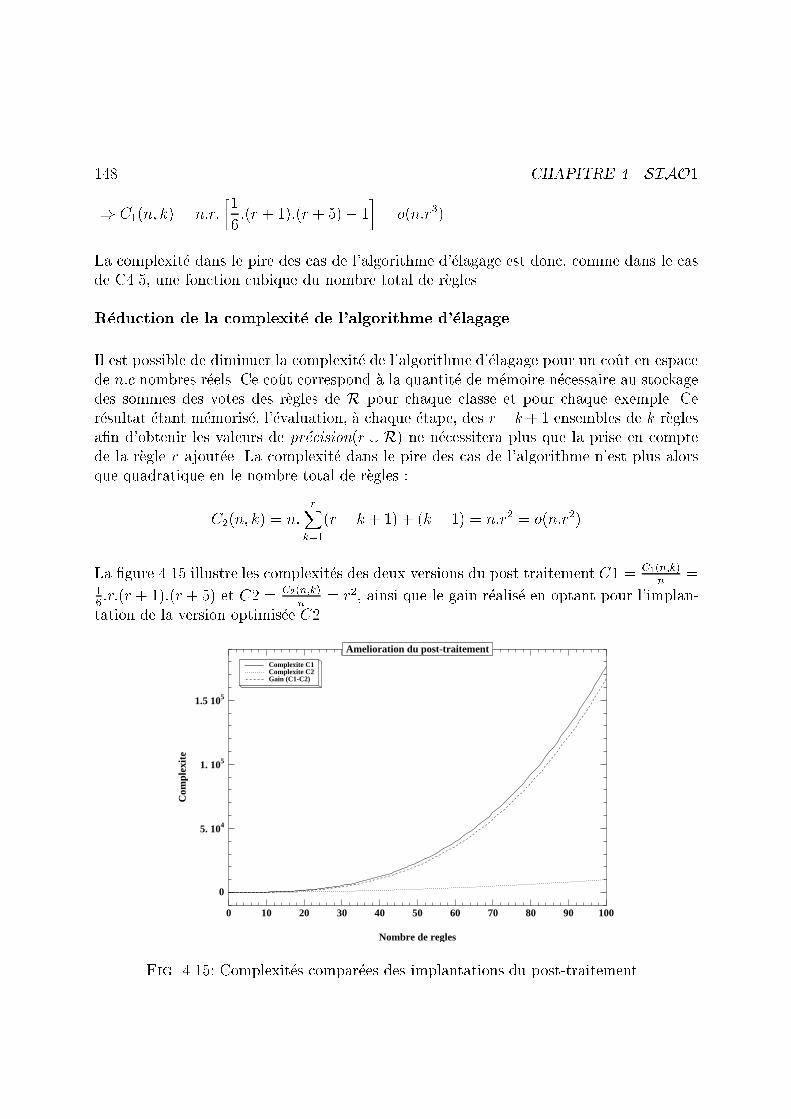
148 CHAPITRE 4. SIAO1) C1(n; k) = n:r: �16 :(r + 1):(r + 5)� 1� = o(n:r3)La complexit�e dans le pire des cas de l'algorithme d'�elagage est donc, comme dans le casde C4.5, une fonction cubique du nombre total de r�egles.R�eduction de la complexit�e de l'algorithme d'�elagageIl est possible de diminuer la complexit�e de l'algorithme d'�elagage pour un cout en espacede n:c nombres r�eels. Ce cout correspond �a la quantit�e de m�emoire n�ecessaire au stockagedes sommes des votes des r�egles de R pour chaque classe et pour chaque exemple. Cer�esultat �etant m�emoris�e, l'�evaluation, �a chaque �etape, des r� k+ 1 ensembles de k r�eglesa�n d'obtenir les valeurs de pr�ecision(r [ R) ne n�ecessitera plus que la prise en comptede la r�egle r ajout�ee. La complexit�e dans le pire des cas de l'algorithme n'est plus alorsque quadratique en le nombre total de r�egles :C2(n; k) = n: rXk=1(r � k + 1) + (k � 1) = n:r2 = o(n:r2)La �gure 4.15 illustre les complexit�es des deux versions du post traitement C1 = C1(n;k)n =16 :r:(r + 1):(r + 5) et C2 = C2(n;k)n = r2, ainsi que le gain r�ealis�e en optant pour l'implan-tation de la version optimis�ee C2.
Nombre de regles
Com
plex
ite
0 10 20 30 40 50 60 70 80 90 100
0
51. 10
45. 10
51.5 10
Complexite C1Complexite C2Gain (C1-C2)
Amelioration du post-traitement
Fig. 4.15: Complexit�es compar�ees des implantations du post-traitement.

4.5. Connaissances du domaine 149Remarque :Poursuivant toujours dans cette direction, il semble possible d'obtenir une solution encoreplus performante en m�emorisant la couverture de chaque exemple par chaque r�egle. Le couten espace est alors de r:n:c nombres r�eels et le cout en temps de r:n appariements. Cette so-lution n'apporte cependant pas les gains attendus car si le nombre d'appariements diminuee�ectivement, la complexit�e reste globalement inchang�ee puisqu'aux appariements �evit�esse sont substitu�ees des acc�es �a la m�emoire et des additions.4.5 Connaissances du domaineDeux m�ecanismes de pr�e-traitement ont �et�e implant�es dans SIAO1 a�n de permettre�a l'utilisateur d'enrichir les donn�ees fournies au syst�eme �a l'aide de connaissances propresau domaine.Compl�etion symbolique relationnelleUne premi�ere technique, appel�ee saturation et d�ecrite plus formellement dans [Rouveirol94],permet d'ajouter �a chaque exemple les connaissances du domaine le concernant.Par exemple, dans le cas du probl�eme Mutagenesis dont une repr�esentation simpli��ee �etaitdonn�ee en �gure 3.1 du chapitre 3, la saturation permet de compl�eter chaque descriptionde mol�ecule qui ne comporte initialement que la classe (canc�erig�ene ou non) et l'identi�antde la mol�ecule par l'ensemble des atomes et des liens qui lui sont li�es.Cette technique est compl�ementaire des connaissances du domaine exprim�ees sous formede hi�erarchies sur les constantes ou les pr�edicats. En e�et, il est pr�ef�erable de d�e�nir larelation V oiture(X)! V �ehicule(X) plutot que d'ajouter dans chaque formule contenantune occurrence du pr�edicat V oiture une occurrence du pr�edicat V �ehicule appliqu�e auxmemes arguments puisque d'une part le gain en concision est un gain en espace m�emoireet en intelligibilit�e, et que d'autre part une telle connaissance pourra etre exploit�ee parles op�erateurs de SIAO1.Compl�etion num�eriqueDans le but d'am�eliorer le traitement des bases num�eriques, un syst�eme de compl�etionnum�erique a �egalement �et�e implant�e. Ce dernier permet la d�erivation de nouvelles con-stantes �a l'aide d'une technique d'analyse de donn�ees appel�ee analyse discriminante (AD).Pour chaque nouvelle valeur num�erique devant etre cr�e�ee l'utilisateur fournit au syst�eme :{ la classe-cible cl �a discriminer ;{ des r�egles d'extraction de v valeurs num�eriques ;

150 CHAPITRE 4. SIAO1L'AD fournit alors la combinaison lin�eaire des v valeurs permettant de discriminer aumieux les instances de classe cl des instances de classe cl.Soit n le nombre d'instances de la base d'apprentissage dont toutes les valeurs �a extraireexistent et sont d�e�nies. La matrice obtenue est alors de taille n�v, et la matrice d'inertie(sym�etrique) est de taille v�v. La complexit�e de l'AD est donc peu importante puisque laseule op�eration r�eellement couteuse (une inversion de matrice) s'applique sur une matricede taille v � v, et ne d�epend donc que du nombre de valeurs extraites et non du nombred'instances de la base d'apprentissage.La �gure 4.16 illustre le comportement de SIAO1 lors d'une pr�e-�etude portant sur l'es-timation du risque cardio-vasculaire r�ealis�ee en collaboration avec une partie de l'�equipedu service d'informatique m�edicale de l'hopital Broussais.
0
0.2
0.4
0.6
0.8
1
1.2
0 0.2 0.4 0.6 0.8 1 1.2
Cou
vert
ure
Taux d’erreur
RNSIAO1
Fig. 4.16: Pr�ediction du risque cardio-vasculaire.Les courbes ROC [Provost et al.97] repr�esent�ees permettent de comparer le comporte-ment d'un r�eseau de neurones avec celui de SIAO1 sur la base de donn�ees Indana qui estbruit�ee et dont les 11 attributs sont num�eriques. Chaque point de la courbe correspond�a un mod�ele obtenu par apprentissage, avec port�e en abscisse le taux d'erreur du mod�eleet en ordonn�ee sa couverture. Il est possible de constater que les mod�eles fournis parSIAO1, qui ont l'avantage d'etre intelligibles, sont de qualit�e �equivalente �a ceux obtenus�a l'aide de r�eseaux de neurones (m�ethodes tr�es performantes dans le domaine num�erique).La qualit�e des mod�eles fournis par SIAO1 est due en grande partie �a l'AD portant surles 11 attributs initiaux qui a g�en�er�e un nouvel attribut tr�es discriminant.

4.6. �Evaluation 1514.6 �EvaluationCette section pr�esente les r�esultats obtenus par SIAO1 sur des bases vari�ees faisantr�ef�erence et d�ecrites en annexe B. Les r�esultats sont compar�es, lorsque cela est possible,�a ceux obtenus par di��erentes autres m�ethodes :{ C4.5, ID3 et CART sont trois syst�emes d'apprentissage fond�es sur les arbres ded�ecision qui font r�ef�erence pour ces techniques. Ils sont pr�esent�es au chapitre 1.{ G-Net et REGAL ont �et�e d�ecrits au chapitre 2. Les r�esultats mentionn�es proviennentrespectivement des th�eses [Lo bello98] et [Neri97].{ PPV (1) et PPV (3) sont deux m�ethodes bas�ees sur les plus proches voisins etmentionn�ees dans les travaux de R. Kohavi.{ RBN correspond au r�eseau bay�esien na��f qui est une m�ethode extremement simpleet rapide, fournissant dans de nombreux cas un classeur pr�ecis [Zheng et al.00].{ FOIL, PROGOL et TILDE sont des syst�emes de PLI qui ont �et�e pr�esent�es auchapitre 1.4.6.1 R�esultats sur Iris et MushroomsIris et Mushrooms (cf. annexe B sections B.2 et B.3) sont deux bases tr�es utilis�ees enapprentissage automatique : la premi�ere est de nature num�erique (mais les 3 classes nesont pas lin�eairement s�eparables), et la seconde est de nature symbolique (et fait r�ef�erencedu point de vue de l'apprentissage de concepts disjonctifs).Syst�eme Taux d'erreur (%)C4.5 5,7SIAO1 6,0RBN 6,3CART 7,0Tab. 4.5: �Evaluation sur la base IrisDans les deux cas SIAO1 se montre aussi performant que les m�ethodes de r�ef�erence.En ce qui concerne la base Mushrooms, un taux d'erreur de 0% n'a rien d'exceptionnelpour les m�ethodes actuelles car il est tr�es facile de caract�eriser le concept de champignoncomestible. Par contre, SIAO1 est capable de caract�eriser le concept de champignonempoisonn�e avec uniquement 3 r�egles et une pr�ecision de 100%, ce qui correspond aumeilleur r�esultat obtenu par les m�ethodes sp�ecialis�ees dans l'apprentissage de conceptsdisjonctifs.

152 CHAPITRE 4. SIAO1Syst�eme Taux d'erreur (%)SIAO1 0,0C4.5 0,0G-NET 0,0REGAL 0,0RBN 0,3STAGGER 5,0HILLARY 5,0Tab. 4.6: �Evaluation sur la base Mushrooms4.6.2 R�esultats sur 1000-trains et MutagenesisLes bases 1000-trains etMutagenesis permettent d'�evaluer le comportement de SIAO1sur des bases relationnelles.Bien que SIAO1 induise des concepts totalement corrects et complets sur la base d'ap-prentissage des 1000-trains, les d�e�nitions obtenues ne couvrent pas 20 des 1000 instancesde test. Syst�eme Taux d'erreur (%)G-Net 0,0 %SIAO1 2,0 %REGAL 2,6 %Tab. 4.7: �Evaluation sur la base 1000-trainsLa base Mutagenesis a �et�e choisie a�n de montrer que SIAO1 est capable de travaillersur des probl�emes fortement relationnels :Syst�eme Connaissances du domaine Taux d'erreur (%)PROGOL B2 19%TILDE B2 21%SIAO1 B2 22%FOIL B2 39%Tab. 4.8: �Evaluation sur la base Mutagenesis (B2)Remarque : Pour ces deux bases, le nombre de noyaux d�evelopp�es a �et�e port�e �a 15.4.6.3 R�esultats sur Census-Income et AdultCensus-Income (d�ecrit annexe B section B.1) est la plus grande base publique �a notredisposition. Elle permet de d�emontrer la capacit�e de l'architecture parall�ele de SIAO1 �a

4.6. �Evaluation 153g�erer un grand nombre d'exemples (environ 200 000 en apprentissage et 100 000 en test),dans le cas d'une base r�eelle extremement bruit�ee. Les seules �evaluations disponibles,fournies par R. Kohavi, concernent les m�ethodes fond�ees sur les arbres de d�ecision tellesque C4.5 et la m�ethode du r�eseau bay�esien na��f, qui sont toutes deux connues pour leurrapidit�e. Syst�eme Taux d'erreur (%)C4.5a 4,8SIAO1 4,9C4.5b 6,2RBN 23,2Tab. 4.9: �Evaluation sur la base Census-IncomeaAssoci�e �a une autre m�ethode (sans doute le boosting).bParam�etrage par d�efaut.Il est possible de remarquer que SIAO1 obtient des r�esultats comparables �a ceux de C4.5,et ce uniquement grace �a l'utilisation de la fonction de qualit�e fond�ee sur l'estimateur delaplace12. Syst�eme Taux d'erreur (%)NBTree 14,10C4.5 15,54CN2 16,00RBN 16,12SIAO1 16,38ID3 (vote) 16,47T2 16,841R 19,54PPV (3) 20,35PPV (1) 21,42Pebls CrashedTab. 4.10: �Evaluation sur la base AdultAdult est une base g�en�er�ee par R. Kohavi �a partir de Census-income par extraction d'en-viron 10% de la base et suppression de certains attributs. Son principal interet est de per-mettre l'�evaluation de nombreux autres syst�emes ne pouvant traiter le volume de donn�eesde Census-Income. Dans ce cas encore, SIAO1 se classe correctement sans n�ecessiteraucun biais d'�evaluation particulier adapt�e aux bases bruit�ees ou de grande taille.12Conform�ement aux conditions d'exp�erimentation pr�econis�ees par R. Kohavi, les couvertures des hy-poth�eses sont �evalu�ees sur les occurrences des instances et aucun m�ecanisme de pond�eration n'est mis enplace.

154 CHAPITRE 4. SIAO1Remarque :Les bases Adult et Census-income �etant tr�es fortement bruit�ees, le nombre de noyauxd�evelopp�es pour caract�eriser le concept Sup 50K a �et�e �x�e �a 100, et les implantationsparall�eles d�etaill�ees au chapitre suivant ont �et�e utilis�ees. Dans le cas de Census-income,la dur�ee d'un apprentissage est d'environ 5 jours sur un ensemble de 6 machines dont lafr�equence des processeurs varie de 500 �a 733 MHz. La dur�ee d'apprentissage pour la baseAdult est d'environ 8 heures et demie dans les memes conditions. Dans les deux cas, cesmachines �etaient partag�ees avec d'autres utilisateurs : les dur�ees, fournies �a titre indicatif,sont donc sur-estim�ees.4.6.4 Analyse des r�esultats exp�erimentauxLes r�esultats ont montr�e que SIAO1 peut fournir des r�egles de qualit�e satisfaisantesur une tr�es grande vari�et�e de probl�emes, qu'ils soient de nature symbolique ou num�erique,fortement relationnels ou propositionnels, y compris lorsque les volumes de donn�ees sontimportants. De plus, le seul param�etre ayant �et�e modi��e en fonction des applicationsrencontr�ees est le nombre de noyaux. Ce dernier n'a pas une importance critique puisquela complexit�e de SIAO1 augmente dans le pire des cas lin�eairement en fonction de ceparam�etre.4.7 BilanNous avons d�ecrit dans ce chapitre le syst�eme SIAO1, qui propose une solutionoriginale au probl�eme de l'apprentissage supervis�e relationnel, fond�ee sur une recherche�evolutionnaire, ascendante et dirig�ee par les donn�ees dans l'espace des formules du langageLh. Il a pour principales caract�eristiques :{ De pouvoir etre appliqu�e �a la fois dans le contexte de l'apprentissage relationnel,qui est caract�eris�e par la pr�epond�erance de l'aspect symbolique, et dans le contexteattribut-valeur o�u les donn�ees num�eriques jouent un role plus important. La vari�et�edes probl�emes trait�es montre une bonne adaptation du syst�eme �a des contextes tr�esvari�es.{ Une �evolution control�ee par les donn�ees de la structure des hypoth�eses qui n'estpas limit�ee �a la forme des exemples ou �a un mod�ele fourni par l'utilisateur. Enparticulier, les r�esultats exp�erimentaux ont �et�e obtenus sans que l'utilisateur ait asp�eci�er les biais d'�evaluation (la fonction de qualit�e est toujours la meme) ou derecherche (il n'est pas n�ecessaire de fournir la forme des hypoth�eses ou de guider �al'aide de r�egles bas�ees sur la syntaxe la construction de la solution).{ La prise en compte de connaissances du domaine de type symbolique et num�erique.SIAO1 est donc polyvalent et sollicite peu l'utilisateur en ce qui concerne des questions

4.7. Bilan 155assez techniques telles que les biais de recherche ou d'�evaluation.

156 CHAPITRE 4. SIAO1

Chapitre 5Parall�elisme et r�epartition5.1 Probl�ematiqueL'application des algorithmes d'apprentissage �a des probl�emes de grande taille [Dietterich97]est un th�eme de recherche qui s'est particuli�erement d�evelopp�e ces derni�eres ann�ees.L'enjeu est en e�et important car les applications de tels syst�emes dans des domainesen d�eveloppement rapide comme par exemple l'extraction de connaissances �a partir desdonn�ees ne sont envisageables dans la plupart des cas que s'il est possible d'exploiter desquantit�es importantes de donn�ees en un temps raisonnable.Plus g�en�eralement, l'�etude de la capacit�e des algorithmes d'apprentissage automatique �achanger d'�echelle est centrale dans beaucoup d'aspects de la recherche en apprentissageautomatique [Provost et al.96].Du point de vue du changement d'�echelle en espace, le d�e� vient du fait que les techniquesd'�echantillonnage, bien qu'utiles, ont montr�e leurs limites dans de nombreux cas. En e�et,ces derni�eres occasionnent la plupart du temps une perte globale de pr�ecision qui peutetre expliqu�ee par le fait que plus on supprime d'information, plus on augmente les risquesde sur-apprentissage. Par ailleurs, ces techniques rendent plus di�cile l'apprentissage descas particuliers qu'elles r�eduisent (d'un point de vue statistique) au bruit.Du point de vue du changement d'�echelle en temps, de nouveaux domaines n�ecessitentdes syst�emes tr�es rapides. En ce qui concerne l'apprentissage automatique interactif, danslequel un humain et un syst�eme d'apprentissage automatique interagissent en temps r�eel,la contrainte provient du temps de r�eponse qu'un utilisateur est pret �a supporter. Dansd'autres domaines tels que la s�election automatique de biais, pour laquelle il est n�ecessaired'obtenir des r�esultats statistiquement signi�catifs portant sur de nombreuses ex�ecutionspour di��erents biais de plusieurs syst�emes d'apprentissage, la contrainte provient de l'ex-plosion combinatoire qui limite d'autant la dur�ee d'un apprentissage.La parall�elisation de SIAO1 a donc pour principal objectif de faire b�en�e�cier autantque possible ce syst�eme des possibilit�es de changement d'�echelle o�ertes par les machines157

158 CHAPITRE 5. PARALL�ELISME ET R�EPARTITIONparall�eles, a�n d'�etendre par exemple son utilisation aux applications n�ecessitant l'ex-ploitation de volumes de donn�ees importants.Ce chapitre commence par une pr�esentation du domaine du parall�elisme et introduitles d�e�nitions des concepts qui serviront de base �a la description et �a l'�evaluation desdi��erentes approches des travaux �etudi�es et r�ealis�es. Un certain nombre de r�esultatsth�eoriques g�en�eraux relatifs aux performances des algorithmes r�epartis permettront depr�eciser la probl�ematique et de proposer des mesures destin�ees �a quanti�er la r�eussite(ou l'�echec) d'une architecture au regard des objectifs �x�es. Les algorithmes d'�evolutionr�epartis sont ensuite pr�esent�es �a l'aide d'une classi�cation g�en�erale des architecturescouramment rencontr�ees, ainsi que par une description plus sp�eci�que de di��erents travauxrepr�esentatifs. Le paragraphe 5.4 pr�esente le cadre du travail qui a men�e �a l'implantationdes deux architectures �etudi�ees. Les r�esultats exp�erimentaux sont ensuite fournis, puisl'�etude d'un mod�ele de pr�ediction du comportement des architectures est r�ealis�ee.5.2 Concepts fondamentaux5.2.1 Les sources de parall�elismeCe paragraphe regroupe les principaux crit�eres permettant de cat�egoriser l'architecturedes machines parall�eles. Ce sont ces crit�eres qui vont guider l'approche choisie, celle-cidevant exploiter au mieux la structure de l'algorithme �a parall�eliser ainsi que les car-act�eristiques de la machine parall�ele.La classi�cation de FlynnFlynn a propos�e dans [Flynn66] une classi�cation des syst�emes r�epartis prenant pourcrit�ere la fa�con dont les instructions et les donn�ees sont r�eparties sur les processeurs.Cette classi�cation regroupe donc quatre cat�egories de machines, puisque les ots dedonn�ees ou d'instructions peuvent etre chacun unique ou multiple. Le cas le plus simple,SISD ( Single Instruction stream, Single Data stream ), dans lequel la machine travaillesur un unique ux de donn�ees et un unique ux d'instructions, correspond �a la machines�equentielle classique de von Neumann. Les trois autres cas (non triviaux) sont :SIMD Single Instruction stream, Multiple Data streamCette classe regroupe les machines poss�edant une unique unit�e de controle appel�ees�equenceur qui distribue les donn�ees aux processeurs, chaque processeur ex�ecutantla meme instruction. On parle alors de machine vectorielle (array processor), cessyst�emes �etant principalement destin�es �a e�ectuer des traitements sur les vecteurs.MISD Multiple Instruction stream, Single Data streamLes syst�emes MISD implantent le parall�elisme en faisant travailler les processeurs �ala cha�ne le long de l'unique ux de donn�ees. Ce fonctionnement est plus connu sousle nom �evocateur de pipeline.

5.2. Concepts fondamentaux 159MIMD Multiple Instruction stream, Multiple Data streamCe type d'architecture est de loin la plus courante. Chaque processeur ex�ecute sonpropre programme �a partir de ses donn�ees, rang�ees dans une m�emoire pouvant etrelocale ou au contraire commune, et les communications se font de mani�ere asyn-chrone.L'int�eret de cette classi�cation est qu'elle fait ressortir �egalement les di��erentes mani�eresd'envisager l'exploitation du parall�elisme intrins�eque d'un algorithme.Autres crit�eresIl existe trois autres caract�eristiques qui permettent de situer de mani�ere encore pluspr�ecise l'approche de parall�elisme envisag�ee :1. L'organisation de la m�emoire (ou couplage)Le couplage rend compte du degr�e d'interaction entre les di��erentes unit�es �el�ementaires.Par exemple on parle de syst�emes fortement coupl�es lorsque les processeurs travail-lent sur une m�emoire partag�ee, c'est-�a-dire une m�emoire directement adressable partout processeur. Inversement, on parle de syst�emes faiblement coupl�es dans le cas desmachines �a m�emoires distribu�ees, pour lesquelles chaque processeur dispose d'unem�emoire propre.2. Le degr�e de parall�elismeLe degr�e de parall�elisme est une �evaluation du nombre de taches �el�ementaires ex�ecut�eessimultan�ement. Cette mesure permet d'estimer l'ordre de grandeur du changementd'�echelle qu'on pourra envisager ; ainsi le degr�e de parall�elisme maximal donne uneborne sup�erieure au nombre de processeurs qu'on utilisera, alors que le degr�e deparall�elisme moyen donne une id�ee du nombre de processeurs n�ecessaires a�n deconserver un bon rapport performances / cout.3. Le grain de parall�elismeOn le d�e�nit habituellement comme la taille moyenne des taches �el�ementaires quiont guid�e la parall�elisation [Gengler et al.96]. De ce point de vue id�eal, qui envisageun utilisateur pouvant construire ou se procurer une machine d�edi�ee �a son projet,on peut d�etailler ce crit�ere dans le tableau suivant :Grain Taches �el�ementaires �Echellegros programmes, proc�edures syst�eme r�epartimoyen instructions, expressions variable�n op�erateurs, bits microprocesseurCependant, du point de vue plus courant d'un utilisateur qui doit travailler dansun environnement donn�e, et n'agit par cons�equent qu'au niveau logiciel et nonmat�eriel, le grain est �etroitement associ�e au degr�e de parall�elisme. Ainsi, dans lalitt�erature concernant les algorithmes d'�evolution parall�eles, le grain �n corre-spond aux machines massivement parall�eles, dont le nombre important de pro-cesseurs est mis �a pro�t la plupart du temps en r�epartissant la population sur

160 CHAPITRE 5. PARALL�ELISME ET R�EPARTITIONceux-ci [Spiessens et al.91, Manderick et al.89], avec dans le cas extreme un indi-vidu par processeur. Le probl�eme de surcout du aux communications devient alorstr�es important.Contexte actuelLa plupart des machines parall�eles actuelles sont construites autour de processeurs or-dinaires et utilisent des r�eseaux de communication �a tr�es haut d�ebit (il s'agit donc demachines de type MIMD). Cette tendance, qui s'est con�rm�ee de mani�ere tr�es signi�ca-tive ces derni�eres ann�ees peut se justi�er en partie par le gain en termes de cout deproduction de la machine et de portabilit�e des programmes.D'autre part, le d�eveloppement e�r�en�e des r�eseaux a vu la multiplication de machinesparall�eles d'un type nouveau, constitu�ees de stations de travail ou de micro-ordinateursinter-connect�es. Ces ordinateurs-r�eseaux (network computers), plus polyvalents et decout plus faible que les machines sp�ecialis�ees peuvent etre class�es dans la cat�egorie desmachines MIMD h�et�erog�enes1 faiblement coupl�ees. Compte tenu des d�ebits assur�es parles r�eseaux actuels, seul un parall�elisme �a grain �epais est envisageable sur ce type demachines.En cons�equence, il n'est pas �etonnant de constater qu'un grand nombre des travaux con-cernant les AE r�epartis sont valid�es, pour leur partie exp�erimentale, sur des machinesMIMD. Pour des raisons �a la fois scienti�ques et pratiques, la parall�elisation de SIAO1 adonc �et�e envisag�ee, puis r�ealis�ee et �etudi�ee sur ce type de machine.5.2.2 La loi d'AmdahlLa loi d'Amdahl est centrale en parall�elisme car non seulement elle borne les perfor-mances des algorithmes r�epartis, mais surtout parce qu'elle fournit un cadre th�eoriquesimple permettant d'�etudier et de mod�eliser leur comportement en pratique. C'est �a cecadre qu'il sera fait r�ef�erence tout au long de ce chapitre lorsqu'il s'agira de quanti�erl'int�eret d'une architecture parall�ele. Dans un souci de simpli�cation, on suppose parla suite que les caract�eristiques mat�erielles des processeurs (machines �el�ementaires) sontstrictement identiques.Acc�el�eration et e�cacit�eSoit Tp(n) le temps n�ecessaire �a l'algorithme �etudi�e pour r�esoudre une instance de taillen avec p processeurs, et Mp(n) la quantit�e de m�emoire requise.D�e�nition 5.1 Facteur d'acc�el�eration d'un algorithme parall�eleOn appelle acc�el�eration le rapport A(n; p) = T1(n)Tp(n) .1puisque les processeurs, les capacit�es m�emoire et disque, voire meme les syst�emes d'exploitationvarient souvent d'une machine �a l'autre.

5.2. Concepts fondamentaux 161D�e�nition 5.2 E�cacit�e d'un algorithme parall�eleOn appelle e�cacit�e le rapport E(n; p) = A(n;p)p = T1(n)p:Tp(n) .Propri�et�esUn raisonnement souvent utile en parall�elisme, appel�e argument de la simulation, per-met de borner grossi�erement l'acc�el�eration et l'e�cacit�e de tout algorithme r�eparti. Cetargument consiste �a consid�erer la possibilit�e de simuler un algorithme r�eparti destin�e �autiliser p processeurs identiques sur une unique machine monoprocesseur fonctionnanten temps partag�e. En supposant que les temps de commutation entre processus sur lamachine monoprocesseur sont inf�erieurs aux temps de communication entre processeurssur la machine parall�ele d'une part, et que les temps de traitement de la machine mono-processeur et de l'un des p �el�ements de la machine parall�ele sont identiques (processeursidentiques, m�emoire su�sante) d'autre part, cet argument montre que l'acc�el�eration esttoujours plus faible ou dans le cas id�eal �egale au nombre de processeurs. En e�et, si unalgorithme sur-lin�eaire existait, il su�rait de le simuler sous les conditions pr�ecit�ees pourmontrer que tel n'est pas le cas. Sous les hypoth�eses (tr�es raisonnables) de cet argument,on a donc les propri�et�es suivantes :Propri�et�e 5.1L'acc�el�eration est au mieux lin�eaire en fonction du nombre de processeurs.Propri�et�e 5.2L'e�cacit�e ne peut d�epasser l'unit�e.La loi d'AmdahlLa loi d'Amdahl [Amdahl67] fait l'hypoth�ese que les algorithmes parall�eles et s�equentielsex�ecutent les memes instructions (hormis la surcharge due �a la mise en parall�ele que l'onpeut n�egliger puisqu'on cherche une borne sup�erieure au gain de performance), chaqueinstruction �etant ex�ecut�ee en un temps unitaire.Loi 5.1 AmdahlSoit T1(n) = TSeq(n) + TPar(n) ; avec :{ TSeq(n) = f(n):T1(n) ; temps pris pour ex�ecuter la partie de l'algorithme ne pouvantetre parall�elis�ee.{ TPar(n) = (1� f(n)):T1(n) ; temps pris pour ex�ecuter la partie de l'algorithme quipeut etre parall�elis�ee.Alors, le meilleur temps d'ex�ecution possible sur p processeurs (not�e T �p ) est obtenu lorsqu'onr�epartit de mani�ere optimale la partie de l'algorithme qui peut etre parall�elis�ee sur tousles processeurs disponibles :

162 CHAPITRE 5. PARALL�ELISME ET R�EPARTITIONT �p (n) = TSeq(n) + TPar(n)p = (f(n) + 1�f(n)p ):T1(n) (Amd 1)De plus, on a :{ 0 � A(n; p) � 1f(n)+(1�f(n))=p (Amd 2) et limp!1A(n; p) = 1f(n) .{ 0 � E(n; p) � 11+(p�1):f(n) (Amd 3) et pour n �x�e limp!1E(n; p) = 0.Cons�equenceComme le montre la �gure 5.1 ci-apr�es, une des cons�equences de la loi d'Amdahl est quele taux d'instructions ne pouvant etre r�eparties sur la machine parall�ele f(n) doit etreextremement faible d�es que le nombre de processeurs devient assez important si l'on veutconserver une e�cacit�e correcte.
f(n)
0 10.5
0
1
0.5
4 processeurs 8 processeurs 16 processeurs 32 processeurs 64 processeurs 1024 processeurs
Variation de la borne superieure de l’efficacite
Fig. 5.1: Comportement de la borne sup�erieure de l'e�cacit�e pr�edite par la loi d'Amdahl.Plus pr�ecis�ement, en se pla�cant dans le cas le plus favorable - lorsque la borne sup�erieurede l'in�equation (Amd 3) est atteinte - on remarque que pour conserver une e�cacit�econstante, f(n) doit etre inversement proportionnelle au nombre de processeurs, soitf(n) = 1p�1 :( 1E � 1). Le tableau 5.1 illustre cette contrainte en donnant une estimation def(n) pour di��erentes valeurs de E lorsqu'on fait varier le nombre p de processeurs.Cette contrainte tr�es forte limite a priori toute approche de parall�elisme massif aux algo-rithmes dont la quasi-totalit�e du code peut etre reparti.
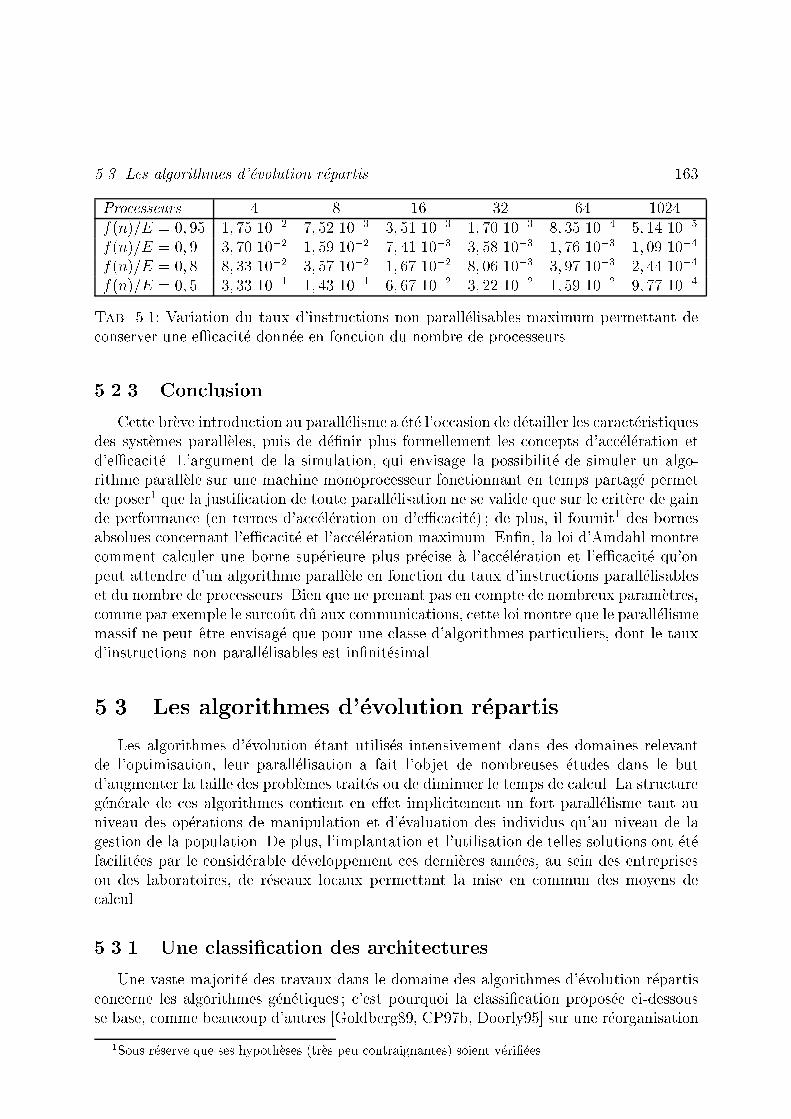
5.3. Les algorithmes d'�evolution r�epartis 163Processeurs 4 8 16 32 64 1024f(n)=E = 0; 95 1; 75 10�2 7; 52 10�3 3; 51 10�3 1; 70 10�3 8; 35 10�4 5; 14 10�5f(n)=E = 0; 9 3; 70 10�2 1; 59 10�2 7; 41 10�3 3; 58 10�3 1; 76 10�3 1; 09 10�4f(n)=E = 0; 8 8; 33 10�2 3; 57 10�2 1; 67 10�2 8; 06 10�3 3; 97 10�3 2; 44 10�4f(n)=E = 0; 5 3; 33 10�1 1; 43 10�1 6; 67 10�2 3; 22 10�2 1; 59 10�2 9; 77 10�4Tab. 5.1: Variation du taux d'instructions non parall�elisables maximum permettant deconserver une e�cacit�e donn�ee en fonction du nombre de processeurs.5.2.3 ConclusionCette br�eve introduction au parall�elisme a �et�e l'occasion de d�etailler les caract�eristiquesdes syst�emes parall�eles, puis de d�e�nir plus formellement les concepts d'acc�el�eration etd'e�cacit�e. L'argument de la simulation, qui envisage la possibilit�e de simuler un algo-rithme parall�ele sur une machine monoprocesseur fonctionnant en temps partag�e permetde poser1 que la justi�cation de toute parall�elisation ne se valide que sur le crit�ere de gainde performance (en termes d'acc�el�eration ou d'e�cacit�e) ; de plus, il fournit1 des bornesabsolues concernant l'e�cacit�e et l'acc�el�eration maximum. En�n, la loi d'Amdahl montrecomment calculer une borne sup�erieure plus pr�ecise �a l'acc�el�eration et l'e�cacit�e qu'onpeut attendre d'un algorithme parall�ele en fonction du taux d'instructions parall�elisableset du nombre de processeurs. Bien que ne prenant pas en compte de nombreux param�etres,comme par exemple le surcout du aux communications, cette loi montre que le parall�elismemassif ne peut etre envisag�e que pour une classe d'algorithmes particuliers, dont le tauxd'instructions non parall�elisables est in�nit�esimal.5.3 Les algorithmes d'�evolution r�epartisLes algorithmes d'�evolution �etant utilis�es intensivement dans des domaines relevantde l'optimisation, leur parall�elisation a fait l'objet de nombreuses �etudes dans le butd'augmenter la taille des probl�emes trait�es ou de diminuer le temps de calcul. La structureg�en�erale de ces algorithmes contient en e�et implicitement un fort parall�elisme tant auniveau des op�erations de manipulation et d'�evaluation des individus qu'au niveau de lagestion de la population. De plus, l'implantation et l'utilisation de telles solutions ont �et�efacilit�ees par le consid�erable d�eveloppement ces derni�eres ann�ees, au sein des entreprisesou des laboratoires, de r�eseaux locaux permettant la mise en commun des moyens decalcul.5.3.1 Une classi�cation des architecturesUne vaste majorit�e des travaux dans le domaine des algorithmes d'�evolution r�epartisconcerne les algorithmes g�en�etiques ; c'est pourquoi la classi�cation propos�ee ci-dessousse base, comme beaucoup d'autres [Goldberg89, CP97b, Doorly95] sur une r�eorganisation1Sous r�eserve que ses hypoth�eses (tr�es peu contraignantes) soient v�eri��ees.

164 CHAPITRE 5. PARALL�ELISME ET R�EPARTITIONet une augmentation des quatre prototypes d'algorithmes g�en�etiques parall�eles envisag�espar Grefenstette dans [Grefenstette81].L'organisation propos�ee s'oriente tout d'abord en fonction du choix du type de gestionde la m�emoire de l'algorithme. Dans le cas d'une m�emoire (population) unique, on s'ori-ente vers une architecture centralis�ee de type ma�tre-esclave, alors que lorsque chaqueprocesseur travaille sur une m�emoire qui lui est propre, on obtient une architecture enr�eseau. Ce choix est particuli�erement important car il d�etermine si la version s�equentiellede l'algorithme va etre int�egralement conserv�ee (cas de l'architecture centralis�ee), ou si aucontraire l'algorithme va �evoluer en autre chose (cas de l'architecture en r�eseau). Dansce dernier cas, une attention toute particuli�ere doit etre port�ee sur la m�ethodologie miseen �uvre pour �etudier le nouvel algorithme obtenu.5.3.2 Les architectures ma�tre-esclaveComme le montre la �gure 5.2, ces architectures sont centr�ees autour d'un processus,appel�e ma�tre, qui g�ere l'unique population et distribue le travail aux autres processusappel�es esclaves. La m�emoire �etant commune, les op�erateurs d'�evolution travaillent ex-actement dans les memes conditions que l'algorithme s�equentiel. Le crit�ere d'�evaluationde ce type d'architecture est donc tout simplement l'acc�el�eration qu'elle produit, puisquele comportement de l'algorithme parall�ele et celui de l'algorithme s�equentiel sont stricte-ment identiques.Processus Esclave Processus Esclave
Processus Esclave Processus Esclave
Processus Maître
Fig. 5.2: L'architecture ma�tre-esclave.Dans ce cadre, la vitalit�e du processus ma�tre est essentielle car si ce dernier perd pied, ilralentit l'ensemble du syst�eme. Cette architecture n'est donc envisageable que lorsque ladur�ee de l'�evaluation d'un individu est longue par rapport au temps pris pour l'envoyersur le r�eseau et g�erer la population.Les sous-paragraphes suivants d�etaillent les trois types d'architectures ma�tre-esclave quel'on peut rencontrer (du plus simple au plus �evolu�e), et d�etaillent leurs avantages etinconv�enients.Ma�tre-esclave synchroneL'architecture ma�tre-esclave synchrone est �a la fois la plus simple et la plus r�epandue

5.3. Les algorithmes d'�evolution r�epartis 165des architectures ma�tre-esclave. Au d�ebut de chaque g�en�eration, le processus ma�tres�electionne les individus pour la reproduction et leur applique les op�erateurs d'�evolution,puis il distribue ces derniers aux esclaves pour �evaluation. En�n, il attend que l'ensembledes r�esultats lui aient �et�e retourn�es avant de recommencer. Il y a donc synchronisationsur le top du compteur de g�en�erations.Esclave 1
Esclave 2
Tempsg(n) g(n+1) g(n+2) g(n+3)
Maître
Fig. 5.3: Architecture ma�tre-esclave synchrone.Le temps est ici �a l'�echelle des dur�ees de traitementet de transmission de la population.La �gure 5.3 d�etaille l'utilisation des processeurs d'un syst�eme ma�tre - deux esclavestypique au cours du temps (port�e en abscisse). Les rectangles gris�es le long des axesd�enotent un travail de la part du processus correspondant ; pour le processus ma�tre, ils'agit de la s�election des individus et de l'application des op�erateurs d'�evolution a�n decr�eer la nouvelle population, tandis que pour les processus esclaves, il s'agit de l'�evaluationdes individus transmis. Les �eches d�enotent des communications entre processus (envoiet r�eception des individus et de leur qualit�e).En contrepartie de sa simplicit�e d'implantation, cette approche montre certaines faiblessesdu point de vue de son e�cacit�e :{ Il est tr�es di�cile de r�epartir e�cacement la charge de travail sur les di��erentsesclaves. En e�et, dans le cas d'un environnement partag�e dynamique, d'autres util-isateurs peuvent �a tout moment modi�er le taux d'utilisation des processeurs dur�eseau lorsqu'ils e�ectuent d'autres travaux. De plus, �a supposer que le syst�eme soituniquement d�edi�e �a l'algorithme d'�evolution, il faut �egalement que la variance dutemps d'�evaluation des individus soit faible.{ Par ailleurs, comme le montre la �gure 5.3, les esclaves sont inactifs pendant que lema�tre g�ere la population au d�ebut de chaque g�en�eration.Comme on va le voir, les deux autres types d'architectures ma�tre-esclave rem�edient �a cesinconv�enients.Ma�tre-esclave asynchroneLes modi�cations permettant d'aboutir au mode asynchrone sont les suivantes :

166 CHAPITRE 5. PARALL�ELISME ET R�EPARTITION{ Les esclaves traitent les individus un par un et non plus par lots : d�es qu'un individuest �evalu�e, il est renvoy�e au ma�tre avec sa qualit�e mise �a jour.{ De meme, le ma�tre g�ere les individus �a la vol�ee : d�es qu'il re�coit un individu, lema�tre en renvoie un �a l'esclave correspondant.Esclave 1
Esclave 2
Temps
Maître
Fig. 5.4: Architecture ma�tre-esclave asynchrone.Le temps est ici �a l'�echelle des dur�ees de traitementet de transmission des individus.Cette architecture fait donc dispara�tre l'attente bloquante de la terminaison des esclaves.Dans le cas des algorithmes g�en�erationnels �evaluant toute la population, cette m�ethodepermet d'�equilibrer dynamiquement la charge en fonction du travail qu'est capable defournir chaque processeur ; cependant l'attente bloquante de la terminaison du ma�trelorsque ce dernier cr�ee la nouvelle population est toujours pr�esente. Par contre, dans lecas des algorithmes incr�ementaux, si le cout de gestion d'un individu est assez faible parrapport au temps n�ecessaire pour l'�evaluer, alors il n'y a plus d'attente li�ee �a la terminaisondu ma�tre (voir �gure 5.4).Il faut en�n remarquer que l'asynchronisme, qui permet d'un cot�e de lever des contraintesassez fortes au niveau de l'attente entre processus, introduit en contrepartie un degr�ed'incertitude suppl�ementaire d'une part, et un risque de d�es�equilibre d'exploitation entreindividus d'autre part :{ Le degr�e d'incertitude suppl�ementaire se constate de la mani�ere suivante : lorsqu'onfournit �a un algorithme d'�evolution �a architecture s�equentielle ou ma�tre-esclavesynchrone un meme noyau lui permettant de g�en�erer une suite de nombres pseudo-al�eatoire donn�ee, on obtient toujours des d�eroulements d'ex�ecutions strictementidentiques. Or cette propri�et�e n'est plus valable dans le contexte asynchrone, puisquedes �el�ements ext�erieurs, comme l'accroissement de la charge d'un processeur, peuventmodi�er le comportement de l'algorithme. Cette modi�cation, aussi insigni�antesoit-elle (par exemple la r�eception - et donc l'insertion - d'un individu avant ou apr�esun autre), a des r�epercussions sur l'�etat du syst�eme et donc sur son d�eroulement.{ Le risque de d�es�equilibre d'exploitation se produit lorsqu'il existe une tr�es forte vari-ance du temps d'�evaluation des individus. En e�et, cette variance introduit unedistorsion qui provoque une meilleure exploitation de l'espace couvert par les in-dividus �evalu�es rapidement. Dans un cas extreme, ce d�es�equilibre pourrait causer

5.3. Les algorithmes d'�evolution r�epartis 167une modi�cation du comportement de l'algorithme ma�tre-esclave asynchrone parrapport au comportement de l'algorithme s�equentiel original.Ma�tre-esclave asynchrone avec m�emoire partag�eeIl est possible d'accro�tre la proportion des instructions ex�ecut�ees en parall�ele de l'ar-chitecture asynchrone en transf�erant aux esclaves la charge d'appliquer les op�erateursd'�evolution modi�ant les individus (par exemple, dans le cas des algorithmes g�en�etiques,il s'agit des op�erateurs de mutation et de croisement). Le ma�tre se comporte alors commeune m�emoire partag�ee par les esclaves, et ne proc�ede plus qu'�a l'extraction et au rem-placement des individus.Bien que s�eduisant �a premi�ere vue, ce type d'architecture a deux inconv�enients quidoivent etre examin�es avant d'envisager toute implantation, et ce meme sur les machines�a m�emoire partag�ee qui semblent particuli�erement adapt�ees :1. Dans le cadre des algorithmes g�en�erationnels, cette approche est souvent inutilevoire p�enalisante. En e�et, d'une part la phase de cr�eation de la nouvelle popu-lation s'ex�ecute �a l'exclusivit�e de toute autre tache, et d'autre part les op�erateursd'�evolution modi�ant les individus sont presque toujours extremement simples (ilsu�t de consid�erer par exemple la mutation et le croisement g�en�etiques classiques).Le temps n�ecessaire pour envoyer et recevoir les individus par le r�eseau est alorsbien sup�erieur au temps mis par le ma�tre pour appliquer ces memes op�erateurs.2. Les op�erateurs d'�evolution plus complexes d�ependent souvent de donn�ees autres quel'individu auquel ils s'appliquent, ce qui peut �egalement etre un inconv�enient pourleur mise en parall�ele.5.3.3 Les architectures en r�eseauD'apr�es ce qui a �et�e dit dans les paragraphes pr�ec�edents d'une part, et la loi d'Amdahld'autre part, les limites des architectures ma�tre-esclave sont g�en�eralement atteintes :{ lorsque le temps d'�evaluation d'un individu est trop court par rapport aux tempsde communication et de gestion de la population ;{ lorsqu'on augmente le degr�e de parall�elisme au del�a des contraintes pr�evues (parexemple lors du portage du syst�eme sur des machines massivement parall�eles).Dans ces cas extremes, il faut essayer de parall�eliser la partie non encore r�epartie de l'al-gorithme qui comprend la gestion de la m�emoire centralis�ee via les op�erations de s�electionet de remplacement des individus. Il est cependant tr�es di�cile de r�epartir e�cacementla s�election car cet op�erateur n�ecessite le plus souvent des renseignements concernantl'ensemble de la population. Par exemple, dans le cas des algorithmes g�en�etiques, las�election proportionnelle �a la qualit�e et ses nombreuses variantes n�ecessitent la connais-

168 CHAPITRE 5. PARALL�ELISME ET R�EPARTITIONsance de la somme des qualit�es des individus alors que les m�ethodes bas�ees sur le rangn�ecessitent la connaissance de leur ordre.Dème Dème Dème
Dème
Dème
Dème
Dème Dème
Dème
Fig. 5.5: L'architecture en r�eseau.La topologie du r�eseau est ici une grille.

5.3. Les algorithmes d'�evolution r�epartis 169Ces contraintes ont conduit au d�eveloppement des architectures en r�eseau, qui sontcaract�eris�ees par une r�epartition de la m�emoire sur les processeurs grace au d�eploiement deprocessus identiques g�erant localement leur propre population, appel�ee d�eme. Dans ce con-texte, la conservation du comportement de l'algorithme s�equentiel n'est plus garantie, parexemple [De jong et al.95] puis [Sarma et al.97] montrent dans le cadre des algorithmesg�en�etiques qu'�a sch�ema de s�election identique, la pression s�elective globale obtenue auniveau de la version parall�ele est toujours inf�erieure �a celle de la version s�equentielle (ceph�enom�ene peut etre expliqu�e par le temps de propagation sur les d�emes du r�eseau desmeilleurs individus). L'�etude du nouvel algorithme obtenu doit alors prendre en comptedeux caract�eristiques li�ees �a son implantation : la taille des d�emes et le type des commu-nications.Remarque m�ethodologiqueUn certain nombre de travaux2 concernant les AE r�epartis pr�esentent des r�esultats faisant�etat d'acc�el�erations sur-lin�eaires. Ces r�esultats, en contradiction apparente avec ce qui a�et�e pr�esent�e ant�erieurement dans le cadre g�en�eral des algorithmes r�epartis, peuvent etreexpliqu�es par un protocole exp�erimental ne respectant pas les contraintes relatives �a lad�e�nition canonique de ce concept.Plus g�en�eralement, il est important de faire attention aux points suivants lors de l'�evaluationdes performances d'une architecture :1. Tout d'abord les questions d'e�cacit�e et de qualit�e ne doivent jamais etre trait�eesind�ependamment. En e�et, la d�e�nition de l'acc�el�eration suppose que l'algorithmeparall�ele et l'algorithme s�equentiel travaillent sur le meme probl�eme et fournissent lameme solution. En cons�equence, l'�etude de la variation du temps de terminaison del'algorithme lorsque le nombre de processeurs varie doit se faire �a qualit�e de solutionobtenue constante.2. De meme, la question du param�etrage joue un role important. Par exemple, dansle cas des AE r�epartis suivant une architecture en r�eseau, les caract�eristiques del'algorithme d�ependent �etroitement du nombre de processeurs, ce qui fausse la sig-ni�cation des mesures. En e�et, le cadre th�eorique ne permet pas de justi�er lacomparaison du meme AE g�en�erique utilisant soit un processeur et un d�eme uniquede n individus, soit p processeurs, et p d�emes de n individus ou encore p d�emes de n=pindividus, puisqu'il s'agit alors d'algorithmes di��erents3. Une mani�ere de proc�ederconsisterait alors �a consid�erer non une instance de l'algorithme dont les param�etresseraient �x�es, mais la classe de toutes ces instances, ce qui implique qu'il faudraittrouver pour chaque con�guration les meilleurs param�etres a�n de proc�eder �a unecomparaison. Bien que des travaux th�eoriques [CP98] puissent etre exploit�es �a ces�ns, ce point de vue n'a pas �et�e mis en pratique.2Ces derniers sont d'autant plus nombreux qu'ils sont anciens.3Par contre l'argument de la simulation qui permet toujours de travailler �a algorithme identiquegarantit encore que quels que soient les param�etres, l'acc�el�eration ne pourra jamais etre sur-lin�eaire.

170 CHAPITRE 5. PARALL�ELISME ET R�EPARTITION3. En�n, les conditions exp�erimentales doivent �egalement garantir autant que possibledes �el�ements de calcul identiques en termes de puissance, d'espace m�emoire et decapacit�e de communication. Ces facteurs doivent etre constants au cours du temps,l'�etude de la robustesse de l'architecture aux variations de charge, si elle a lieu,devant etre faite dans un second temps.En particulier, dans le cas des AE r�epartis suivant une architecture ma�tre-esclave, il estsouvent facile de montrer que le fonctionnement global de l'algorithme reste inchang�e. Encons�equence la qualit�e des solutions obtenues d'une part, et le param�etrage de l'algorithmed'autre part ne n�ecessitent pas d'�etude particuli�ere. Par contre, le cas des AE r�epartissuivant une architecture en r�eseau est di��erent et plus complexe.En conclusion, il est important de s'assurer d'apr�es la description du contexte exp�erimentalque la d�e�nition normative des termes acc�el�eration et e�cacit�e est e�ectivement utilis�eelorsque l'on veut �evaluer une nouvelle approche.5.3.4 Mod�elisationParmi les travaux concernant la mod�elisation dans un cadre aussi g�en�eral que pos-sible du comportement des AE r�epartis, on peut citer dans le domaine des algorithmesg�en�etiques [Pettey et al.89] qui �etudie la conservation du th�eor�eme des sch�emas dans lesarchitectures en r�eseau. Toujours dans le cadre des architectures en r�eseau [CP et al.97]mod�elise l'acc�el�eration obtenue pour deux topologies extremes (cas des d�emes totalementisol�es ne communiquant pas, ou des d�emes totalement inter-connect�es avec un taux demigration maximum). Ces travaux sont suivis dans [CP98] par l'�etude des relations liantle degr�e de connexion, le taux de migration, la taille des d�emes et la qualit�e de la solutionobtenue.En ce qui concerne la mod�elisation des architectures ma�tre-esclave dont il sera partic-uli�erement question dans la suite, on pr�esente bri�evement l'analyse donn�ee par [CP97a]�a laquelle il sera fait r�ef�erence. Cette analyse se place dans le contexte { commun �ala quasi-totalit�e des architectures ma�tre-esclave d�evelopp�ees pour les AE { de l'archi-tecture ma�tre-esclave synchrone, dans laquelle le ma�tre, g�erant un algorithme de typeg�en�erationnel, r�epartit �a chaque g�en�eration l'�evaluation de la population sur les esclaves.On n�eglige le temps pris �a chaque it�eration par le ma�tre pour g�en�erer la nouvelle popu-lation. On note :{ p le nombre d'esclaves ;{ n la taille de la population ;{ � le temps d'�evaluation d'un individu ;{ tc(pop) le temps de communication n�ecessaire pour transmettre la fraction de la pop-ulation �a �evaluer (sens ma�tre-esclave) ou �evalu�ee (sens esclave-ma�tre) ;

5.3. Les algorithmes d'�evolution r�epartis 171{ teval le temps n�ecessaire �a un esclave pour �evaluer la fraction de la population quilui a �et�e transmise ; on a : teval = n:�p .Le premier esclave re�coit les donn�ees �a l'instant tc(pop) et termine �a tc(pop) + teval. Commed'autre part le ma�tre a �ni l'envoi des donn�ees �a l'instant p:tc(pop), on en d�eduit que ladur�ee d'inactivit�e du ma�tre est : ti = tc(pop) + teval � p:tc(pop), soit :ti = teval � (p� 1):tc(pop) (M-E Sync 1)Ainsi, le temps total n�ecessaire au ma�tre pour traiter une g�en�eration est : tgen = 2:p:tc(pop)+ti = 2:p:tc(pop) + teval � (p� 1):tc(pop) = (p+ 1):tc(pop) + teval, soit :tgen = (p+ 1):tc(pop) + n:�p (M-E Sync 2)Cependant, le temps de communication n'est pas constant puisqu'on peut supposer qu'ild�epend lin�eairement de la quantit�e d'information �a transmettre, soit dans ce cas : tc(pop) =a:n:l=p + c ; o�u a et c sont des constantes d�ependantes du mat�eriel, et l est la longueur(en bits) du codage d'un individu. On obtient �nalement :tgen = (p+ 1):(a:n:l=p+ c) + n:�p (M-E Sync 3)Le mod�ele a �et�e valid�e exp�erimentalement, et pr�edit correctement les performances dece type d'algorithme r�eparti une fois d�etermin�es les multiples param�etres (�, l, a etc). Comme d'autre part �a partir d'un certain nombre d'esclaves les performances vontd�ecro�tre (puisque la diminution du temps de calcul au niveau des esclaves ne compenseraplus le cout croissant des communications au niveau du ma�tre), il est possible de l'utiliserpour estimer le nombre d'esclaves optimal, not�e p�, (en r�esolvant l'�equation @tgen@p = 0) ;on obtient alors : p� = q (a:l+�):nc (M-E Sync 4)

172 CHAPITRE 5. PARALL�ELISME ET R�EPARTITION5.4 Parall�elisation de SIAO15.4.1 ObjectifsLes buts de la mise en parall�ele de SIAO1 d�ecoulent logiquement des r�esultatspr�esent�es au paragraphe 5.2 qui concernent les algorithmes r�epartis en g�en�eral, ainsi quede contraintes plus g�en�erales relatives �a l'implantation et au domaine d'application. Ilspermettent de pr�eciser, au vu de ce qui a �et�e pr�esent�e, la probl�ematique du paragraphe5.1.L'objectif principal est de permettre l'utilisation de SIAO1 sur des bases dedonn�ees de grande taillePuisque l'algorithme converge en un temps tr�es raisonnable sur des bases comportantquelques centaines d'instances (par exemple, moins d'une minute est n�ecessaire sur unmicro-ordinateur pour traiter la base Iris), la parall�elisation a pour objectif une utilisa-tion de l'algorithme dans le cadre de l'ECD sur des bases importantes. Il s'agit donc depermettre un changement d'�echelle en temps ou en espace aussi performant que possible.L'architecture doit conserver les propri�et�es de fonctionnement de l'algorithmes�equentielCette contrainte est centrale pour la coh�erence de l'approche puisqu'il semble logique devouloir conserver un algorithme �elabor�e pour etre adapt�e au probl�eme �a r�esoudre. Lerappel de l'argument de la simulation appliqu�e �a ce contexte pr�ecis, qui �gure dans leslignes suivantes, permet une justi�cation plus pr�ecise de cet objectif.La parall�elisation se valide uniquement par des crit�eres de performance entemps ou en espaceCe crit�ere unique de validation provient directement de l'argument de la simulation. En ef-fet, d'apr�es cet argument, tout algorithme r�eparti4 peut etre simul�e sur une machine mono-processeur fonctionnant en temps partag�e, et on peut donc en conclure que la comparai-son d'un algorithme r�eparti dont le fonctionnement g�en�eral serait di��erent de l'algorithmes�equentiel servant de r�ef�erence n'a pas lieu d'etre. En e�et, si l'algorithme s�equentiel estmoins bien adapt�e au probl�eme que l'algorithme r�eparti, il y a alors une sorte de tromperieconcernant la m�ethode de validation puisqu'il su�rait de simuler ce dernier pour obtenirun meilleur cas de r�ef�erence. En cons�equence, dans le cas o�u la qualit�e de la solutionprime, et puisque l'algorithme de r�ef�erence peut toujours etre ajust�e par l'argument de lasimulation1 sur le mod�ele de l'algorithme r�eparti, et donc fournir un r�esultat strictementidentique, il ne reste comme crit�ere d'�evaluation qu'une comparaison des performances entemps ou en espace. En particulier, la notion de changement d'�echelle, qui est au c�ur de4Les conditions d'application de cet argument �etant extremement peu contraignantes, on suppose iciqu'elles sont r�ealis�ees.

5.4. Parall�elisation de SIAO1 173la probl�ematique de ce chapitre, doit etre pr�ecis�ee et formalis�ee si possible.L'architecture doit etre aussi ind�ependante que possible de la machine physiqueUne fois les contraintes de conservation des r�esultats de l'algorithme et de gain de perfor-mances en temps ou en espace remplies, on peut �egalement souhaiter que l'architectureenvisag�ee soit aussi ind�ependante que possible de la machine physique. Il est en e�etpr�ef�erable de favoriser l'adaptabilit�e de l'architecture �a di��erentes machines MIMD, qu'ils'agisse d'un syst�eme homog�ene et sp�ecialis�e comme l'IBM SP2, ou plus simplement d'unr�eseau h�et�erog�ene de stations de travail. Pour r�epondre �a ce besoin, des librairies de fonc-tions de gestion de processus et de leurs communications coupl�ees �a des interfaces ont �et�ed�evelopp�ees ces derni�eres ann�ees. PVM [Geist et al.94], qui a �et�e utilis�ee dans le cadrede cette th�ese, est �a ce jour la librairie la plus r�epandue. De plus, il est pr�ef�erable derendre les param�etres de l'algorithme d'�evolution (comme, par exemple, le nombre ded�emes) ind�ependants des caract�eristiques de la machine disponible (comme, par exemple,le nombre de processeurs) a�n qu'il soit possible d'exploiter au mieux les con�gurationsmat�erielles disponibles et ce, quel que soit le probl�eme �a r�esoudre.5.4.2 Formalisation de la notion de changement d'�echelleChangement d'�echelle en espace et en tempsLe changement d'�echelle est la mesure de la capacit�e d'un algorithme �a travailler surdes probl�emes de taille croissante lorsque l'on augmente les ressources en m�emoire eten puissance de calcul mises �a sa disposition. Dans le contexte des algorithmes r�epartis,l'accroissement des ressources correspond �a l'augmentation du nombre p de machinesidentiques disponibles, ce qui conduit �a proposer les d�e�nitions suivantes reprenant lesnotations �etablies au paragraphe 5.2.2 :D�e�nition 5.3 Facteur de changement d'�echelle en espace d'un algorithme parall�eleOn appelle facteur de changement d'�echelle en espace le rapport FE(n; p) = T1(n)Tp(p:n) .D�e�nition 5.4 Facteur de changement d'�echelle en temps d'un algorithme parall�eleOn appelle facteur de changement d'�echelle en temps le rapport FT (n; p) = T1(n)p:Tp(n) .Tout comme le facteur d'acc�el�eration, le facteur de changement d'�echelle d�e�nit un taux derendement prenant comme r�ef�erence une machine monoprocesseur. Dans le cas du facteurde changement d'�echelle en espace, il s'agit d'�etudier le comportement du programmeparall�ele lorsqu'on augmente la complexit�e du probl�eme �a r�esoudre proportionnellementau nombre de processeurs, alors que dans le cas du facteur de changement d'�echelle entemps, on revient �a la notion d'acc�el�eration qui se d�e�nit �a probl�eme constant.

174 CHAPITRE 5. PARALL�ELISME ET R�EPARTITIONIso-e�cacit�eUne autre possibilit�e pour d�eterminer la capacit�e d'un algorithme �a changer d'�echelleconsiste �a �etudier la relation existant entre la taille n du probl�eme et le nombre p deprocesseurs lorsqu'on �xe l'e�cacit�e �a une constante donn�ee.D�e�nition 5.5 Courbe d'iso-e�cacit�e de niveau kEOn appelle courbe d'iso-e�cacit�e de niveau kE la courbe de niveau obtenue par l'intersec-tion du plan d'�equation E = kE avec la fonction E(n; p) dans l'espace E(n; p; E).Si il semble �evident que lorsque le nombre de processeurs augmente, il est n�ecessaired'accro�tre �egalement la taille des probl�emes a�n de conserver une e�cacit�e constante,di��erents algorithmes n�ecessiteront des accroissements plus ou moins importants. Orplus cet accroissement de la taille des instances sera important, plus l'algorithme �etudi�en�ecessitera des probl�emes de taille importante pour fonctionner e�cacement sur un grandnombre de processeurs. En conclusion la capacit�e de changement d'�echelle de l'algorithme�etudi�e sera d'autant plus r�eduite que l'accroissement de la taille des instances sera impor-tant sur la courbe d'iso-e�cacit�e.Point de vue exp�erimentalUn premier probl�eme qui appara�t lors de la mesure exp�erimentale des grandeurs d�etaill�eesci-dessus concerne la di�cult�e qu'il y a �a d�e�nir en toute g�en�eralit�e la complexit�e n d'uneinstance. Une pratique, commune �a de nombreux travaux du domaine et suivie ici, consiste�a poser que n est proportionnelle �a la taille de l'ensemble d'apprentissage. Ainsi, lorsqu'ildevient n�ecessaire de faire varier n, on choisit une base d'apprentissage su�sammentgrande , puis on obtient di��erentes valeurs de n en proc�edant �a plusieurs �echantillonnages.D'autre part, il est important de noter que si, du point de vue de la faisabilit�e desmesures, les facteurs de changement d'�echelle en espace et en temps peuvent etre facile-ment d�etermin�es, il en est tout autrement de l'iso-e�cacit�e. En e�et, la d�eterminationdes courbes d'iso-e�cacit�e ne peut se faire qu'�a l'aide d'un mod�ele su�samment pr�ecisde E(n; p), �a moins de disposer de ressources permettant de faire un grand nombre detests destin�es �a trouver pour chaque valeur de p la valeur de n associ�ee qui permet des'approcher autant que possible de l'e�cacit�e recherch�ee.Par ailleurs, une d�e�nition alternative de l'acc�el�eration, motiv�ee et pr�esent�ee dans [Gustafson88],pose �egalement des probl�emes quand �a sa mise en �uvre. L'id�ee �a la base de cette mesureconsiste �a prendre la r�eciproque exacte de l'acc�el�eration T1(n)Tp(n) qui est d�e�nie �a taille duprobl�eme n constante, alors qu'on fait varier le temps T d'ex�ecution. On se place donc �atemps d'ex�ecution t constant, et l'on �etudie le comportement de la taille N du probl�emeque l'on peut traiter pendant la meme dur�ee avec p processeurs :A0(t; p) = Np(t)N1(t)

5.4. Parall�elisation de SIAO1 175Bien que di�cile d'application, la d�e�nition alternative du facteur de changement d'�echelleen espace qui en d�ecoule est particuli�erement adapt�ee �a la probl�ematique de ce chapitre :F 0E(t; p) = Np(t)p:N1(t)En conclusion, on remarquera que le facteur de changement d'�echelle en espace est unbon compromis puisqu'il est �a la fois facile �a mesurer et adapt�e au contexte de l'ECDdans lequel on dispose d'algorithmes s�equentiels r�esolvant d�ej�a en temps raisonnable desprobl�emes de taille raisonnable, et pour lesquels il s'agit de savoir si une fois r�epartis ilspourront r�esoudre en temps raisonnable des probl�emes de taille importante.5.4.3 Deux architectures adapt�ees �a la fouille de donn�eesM�ethodologie g�en�eraleLa d�emarche sous-tendant la conception de bien des algorithmes parall�eles consiste �ad�ecomposer l'algorithme initial en sous-taches �a peu pr�es �equivalentes en termes de tempsd'ex�ecution. De plus, cette d�ecomposition doit id�ealement minimiser la partie s�equentielle(qui ne pourra etre distribu�ee) ainsi que les surcouts li�es aux communications (�echangesd'informations entre les taches et attentes bloquantes). Les paragraphes suivants pr�esententles deux architectures propos�ees et �etudi�ees pour atteindre les objectifs expos�es en 5.4.1.�Etude pr�eliminaireUne premi�ere �etude du fonctionnement de l'algorithme �a l'aide d'un optimiseur de code(gprof) montre d'une part que la grande majorit�e du temps d'ex�ecution est pass�ee �a�evaluer la couverture des d�e�nitions g�en�er�ees par l'algorithme, et d'autre part que laproportion du temps d'ex�ecution total d�edi�ee �a cette �evaluation augmente en meme tempsque la taille de la base d'apprentissage. Le tableau 5.2 d�etaille ce ph�enom�ene sur les basesIris et Mushrooms en fonction de la taille jEj de la base d'apprentissage. L'acc�el�erationmaximum envisageable d'apr�es la loi d'Amdahl est �egalement report�ee pour un nombrevariable de processeurs.Si les r�esultats obtenus ci-dessus impliquent clairement que toute parall�elisation de l'algo-rithme devra imp�erativement inclure dans la fraction du code r�epartie sur les processeursle calcul de la couverture, le choix { encore vaste { du type d'architecture doit etrepr�ecis�e. Puisque les objectifs poursuivis posent comme contrainte d'assurer autant quepossible la conservation des propri�et�es de fonctionnement de l'algorithme s�equentiel ainsique l'ind�ependance entre les architectures logicielles et physiques, seule une parall�elisationse r�eduisant uniquement au calcul de la couverture peut etre envisag�ee. En e�et uneparall�elisation d'une plus grande partie de l'algorithme doit obligatoirement r�epartir auminimum soit des instructions (qui correspondront donc �a l'application des op�erateursd'�evolution), soit des donn�ees, c'est-�a-dire les noyaux en cours de g�en�eralisation. Or ces

176 CHAPITRE 5. PARALL�ELISME ET R�EPARTITIONAcc�el�eration maximale (Amdahl)Base jEj %Tcouv p = 2 p = 4 p = 8 p = 16 p = 32Iris 50 64.6% 1.47 1.93 2.30 2.53 2.67Iris 100 77.6% 1.63 2.39 3.11 3.67 4.03Iris 150 83.0% 1.71 2.65 3.65 4.50 5.10Mushrooms 500 91.5% 1.84 3.18 5.01 7.03 8.80Mushrooms 1000 94.9% 1.90 3.46 5.89 9.06 12.39Mushrooms 1500 95.9% 1.92 3.56 6.21 9.90 14.09Mushrooms 2000 96.7% 1.93 3.63 6.49 10.70 15.81Mushrooms 4000 97.4% 1.94 3.71 6.76 11.51 17.71Mushrooms 6000 97.7% 1.95 3.74 6.89 11.89 18.68Mushrooms 8000 97.7% 1.95 3.74 6.89 11.89 18.68Tab. 5.2: Proportion du temps d'ex�ecution pass�ee en tests de couverture lorsque l'on faitvarier la taille de la base d'apprentissage.deux cas de �gure doivent etre �ecart�es, car le cas de la parall�elisation des noyaux conduit�a introduire une d�ependance entre l'architecture mat�erielle (le nombre de processeurs) etl'architecture logicielle (le nombre de noyaux que l'on va r�epartir) ; alors que dans le cas o�ul'on envisage la r�epartition des op�erateurs d'�evolution, on aboutit �a l'architecture de typema�tre-esclave asynchrone avec m�emoire partag�ee d�ecrite en 5.3.2, qui n'est pas adapt�ee�a l'algorithme : en e�et, les op�erateurs d'�evolution repr�esentent une partie n�egligeable dutemps d'ex�ecution ; leur parall�elisation n'apporte donc rien, d'autant plus que le tempsn�ecessaire pour envoyer et recevoir les individus est bien sup�erieur au temps n�ecessaire �al'application de ces op�erateurs.ConclusionL'�etude pr�eliminaire conduit �a la s�election d'un type d'architecture dont le traitementr�eparti se limite �a l'�evaluation des r�egles g�en�er�ees. Cette architecture g�en�erique, sch�ematis�ee�gure 5.6, doit permettre d'assurer un degr�e de parall�elisme important, comme l'ontmontr�e les mesures e�ectu�ees sur l'algorithme s�equentiel.Parmi les d�ecompositions possibles de l'architecture g�en�erique, la premi�ere id�ee venant �al'esprit consiste �a consid�erer l'exploitation du parall�elisme au niveau des donn�ees, ce quicorrespond au sch�ema bien connu de l'AE de type ma�tre-esclave expos�e en 5.3.2. Cepen-dant, cette approche n'est pas la seule : il est �egalement possible d'envisager l'exploitationdu parall�elisme au niveau des instructions.Les paragraphes suivants d�etaillent ces deux types d'architectures autant du point devue th�eorique que de l'implantation pratique, cette derni�ere ayant parfois n�ecessit�e uneadaptation aux contraintes du domaine. De plus, un mod�ele simple destin�e �a �evaluer lecomportement et les contraintes de chaque architecture est �egalement pr�esent�e.

5.4. Parall�elisation de SIAO1 177Instructions centralisées Instructions réparties
Pré-traitement
Lecture de la description dulangage et de la théorie dudomaine.
Lecture des bases
Initialisation desprocessus répartis
Evolution des règles
Gestion des noyaux
Application des opérateursd’évolution
Post-traitement
Post-élagage
Calcul de la couverturedes règles (évaluation)
Les éléments représentés en pointilléssont causés par la parallélisation etoccasionnent un surcoût.Fig. 5.6: Architecture g�en�erique propos�ee.5.4.3.1 Parall�elisme de donn�eesL'architecture implant�eeBien que l'architecture ma�tre-esclave synchrone soit la plus r�epandue et la plus facile �amettre en �uvre, la conception de SIAO1 plaide en faveur d'une architecture asynchrone.En e�et :{ l'algorithme �etant incr�emental, il est possible d'�eviter le temps d'attente des esclavespendant la gestion de la population ;{ de plus, l'asynchronisme permet d'adapter la charge de travail aux esclaves lorsqueles temps d'�evaluation varient d'un individu �a l'autre.On peut remarquer que l'�equation provenant du mod�ele propos�e par E. Cant�u-Paz :tgen = (p+ 1):(a:n:l=p+ c) + n:�p (M-E Sync 3)ne permet pas de mod�eliser ces deux types de d�eperditions, puisque :{ le temps de gestion de la population par le processus ma�tre est suppos�e n�egligeable(et n'est par cons�equent pas pris en compte dans le mod�ele) ;{ le temps d'�evaluation � d'un individu �etant suppos�e constant, il n'y a aucune vari-ance du temps d'�evaluation teval = n:�p de la fraction de la population envoy�ee �achaque esclave.Par contre, cette �equation fait ressortir le principal goulot d'�etranglement de ce typed'architecture. En e�et, le terme n:�p correspond �a la charge de travail incompressible,alors que le terme restant (p + 1):(a:n:l=p + c) est la partie du mod�ele correspondant

178 CHAPITRE 5. PARALL�ELISME ET R�EPARTITIONau surcout de la parall�elisation. Comme d'une part les exp�erimentations men�ees sur cemod�ele ont montr�e qu'il �etait �able, et que d'autre part son unique terme r�eductible d�ecritles temps de communication, une technique destin�ee �a augmenter encore l'e�cacit�e desesclaves a �et�e propos�ee. Elle consiste �a envoyer plusieurs individus pour �evaluation lors del'initialisation du processus (comme dans le cas de l'architecture ma�tre- esclave synchrone,on utilisera une m�emoire tampon, ici structur�ee en �le d'attente). L'existence de cette �led'attente permet �a l'esclave de travailler, meme pendant les communications, du momentque le ma�tre est capable de l'alimenter (c'est-�a-dire qu'il ne perd pas pied, ce qui estl'hypoth�ese de base). Comme le montre la �gure 5.7, cette am�elioration doit permettreun meilleur taux d'utilisation des esclaves par rapport �a ce que l'on peut attendre d'unearchitecture asynchrone classique (cf. �gure 5.4).Esclave 1
Esclave 2
Temps
Maître
Fig. 5.7: Architecture ma�tre-esclave asynchrone avec �le d'attente.Le temps est ici �a l'�echelle des dur�ees de traitementet de transmission des individus.Mod�elisationOn suppose dans un premier temps que l'on peut n�egliger les contraintes li�ees au d�ebitdu r�eseau ainsi qu'�a la charge du ma�tre. Soit :{ p le nombre d'esclaves ;{ i le nombre d'individus trait�es ;{ tc le temps de communication (en secondes) n�ecessaire pour transmettre un individu ;{ te le temps n�ecessaire (en secondes) pour �evaluer (s�equentiellement) un individu ;La dur�ee d'ex�ecution de l'algorithme s�equentiel de r�ef�erence est :Tseq = i:te (T seq)Puisque les i individus sont r�epartis sur les p esclaves d'une part, et qu'une �evaluationn�ecessite te secondes de la part d'un esclave d'autre part, la dur�ee d'ex�ecution de l'algo-rithme ma�tre-esclave est donc5 :5Dans le cas de l'architecture ma�tre-esclave asynchrone avec �le d'attente, les seuls temps de com-munication non couverts par les dur�ees d'�evaluation des individus sont relatifs �a l'envoi du premier et dudernier message.

5.4. Parall�elisation de SIAO1 179Tm�escp = i:tep + 2:tc (T m-esc)Pour que ces performances soient atteintes, il faut cependant que le temps tm de gestiond'un individu par le ma�tre et que le temps tc de communication d'un individu (d�ependantdu d�ebit du r�eseau) satisfassent les contraintes suivantes :{ tout d'abord il faut au ma�tre tm+2:tc secondes pour servir un esclave ; or le ma�tredoit servir p esclaves pendant te secondes, d'o�u tm + 2:tc � tep , soit :tm � tep � 2:tc (C1 m-esc){ en�n, il faut que le r�eseau puisse transmettre les 2:p messages pendant la memedur�ee de base te, ce qui impose :tc � te2:p (C2 m-esc)5.4.3.2 Parall�elisme de uxL'architecture implant�eeLa seconde d�ecomposition possible �a partir de l'architecture g�en�erique d�etaill�ee �gure 5.6consiste �a exploiter le parall�elisme au niveau des instructions, ce qui conduit �a r�epartirl'�evaluation des individus sur les esclaves, ces derniers travaillant �a la cha�ne sur un unique ux de donn�ees. On obtient alors un fonctionnement en pipeline :Processus Esclave Processus Esclave Processus Esclave Processus Esclave
Processus MaîtreFig. 5.8: L'architecture pipeline.Le fait que ce type de d�ecomposition se focalisant sur la fonction d'�evaluation n'aitjamais �et�e propos�e pour les AE peut s'expliquer d'une part parce qu'il existe d�ej�a desd�ecompositions op�erant �a un niveau sup�erieur (que l'on pouvait donc supposer plus ef-�caces), et d'autre part parce que l'on consid�ere habituellement l'�evaluation d'un indi-vidu comme atomique au niveau de ces algorithmes, puisqu'il s'agit tr�es souvent d'uneop�eration rapide et di�cile �a r�epartir e�cacement.Cependant, cette d�ecomposition est tout �a fait adapt�ee au contexte de l'ECD, et plusparticuli�erement au changement d'�echelle en espace. En e�et, dans le cas de la fouille degrandes bases de donn�ees, la taille m�emoire requise par l'algorithme devient proportion-nelle au nombre d'exemples. Par cons�equent, cette architecture permet de diviser l'espacem�emoire n�ecessaire pour chaque processus esclave par le nombre de processeurs. On ob-tient alors, pour p su�samment grand (quelques milliers d'exemples, cf tableau 5.4) :

180 CHAPITRE 5. PARALL�ELISME ET R�EPARTITIONMp(n) � M1(n)p

5.4. Parall�elisation de SIAO1 181Mod�elisationEn conservant les notations utilis�ees pour l'�etude du comportement de l'architecturema�tre-esclave asynchrone avec �le d'attente, on obtient dans le cas du pipeline :T pipelinep = (p+ 1):tc + te + (i�1):tep (T pipeline)En e�et, la mise en marche du pipeline, qui correspond au temps que met le premierindividu pour le traverser dure (p + 1):tc + te secondes, puis tous les autres individussortent un par un toutes les tep secondes.Les contraintes sur tm et tc sont les suivantes :{ pour que le pipeline tourne �a plein r�egime, le ma�tre doit envoyer un individu toutesles tep secondes, soit : tm � tep (C1 pipeline){ de plus, le r�eseau doit pouvoir faire transiter (p+1) messages lors de chaque �evaluation(de dur�ee tep lorsque le pipeline tourne �a plein r�egime), ce qui impose :tc � tep:(p+1) (C2 pipeline)Comparaison avec l'architecture ma�tre-esclaveEn contrepartie du gain en espace m�emoire n�ecessaire r�ealis�e qui peut etre un crit�ered�ecisif dans le choix d'une architecture lors de la fouille de bases de donn�ees importantes,le pipeline a quelques inconv�enients qui le rendent moins performant en temps que l'ar-chitecture ma�tre-esclave. En premier lieu le cout des communications est plus importantdans le cas du pipeline puisque le nombre de messages n�ecessaires �a l'�evaluation d'unindividu est �egal au nombre total de processus (ma�tre et esclaves), alors qu'il est con-stant dans le cas de l'architecture ma�tre-esclave (deux messages su�sent). Ce cout plusimportant des communications peut etre observ�e en comparant les contraintes portantsur tc dans les deux mod�eles. D'autre part, contrairement �a l'architecture ma�tre-esclaveasynchrone qui s'adapte aux variations de charge en environnement dynamique, le pipelined�epend pour son e�cacit�e de chaque �el�ement qui le compose. Par exemple, dans le caso�u un processeur du syst�eme est ralenti (soit c > 1 le facteur de charge ralentissant ceprocesseur), l'architecture ma�tre-esclave asynchrone avec �le d'attente ne verra qu'un deses processeurs ralenti, soit :Tm�esc ralentip = (1 + c�1p ): i:tep + 2:tc (m-esc ralenti)Dans le cas de l'architecture pipeline, ce meme processeur ralenti diminuera le d�ebit du ux d'individus, ce qui aura une cons�equence pour tous les processeurs en introduisantdes temps d'attente sur l'ensemble de la cha�ne :

182 CHAPITRE 5. PARALL�ELISME ET R�EPARTITIONT pipeline ralentip = (p+ 1):tc + (p�1+c):tep + c: (i�1):tep (pipeline ralenti)5.4.4 Du d�epassement de la loi d'AmdahlPour conclure cette partie descriptive des architectures propos�ees, il convient de faireun retour sur la Loi d'Amdahl �a la lumi�ere de la probl�ematique et de l'architectureg�en�erique propos�ees. En e�et, le paragraphe 5.2.2 soulignait la tr�es grande di�cult�e�a atteindre une e�cacit�e correcte dans le cas du parall�elisme massif, puisque le tauxd'instructions non parall�elisables devait alors devenir in�nit�esimal (comme le montraitle tableau 5.1). Or l'argument �a l'origine de cette assertion, qui est une cons�equencemath�ematique directe de l'in�equation (Amd 3), peut sembler contradictoire avec lesr�esultats exp�erimentaux pr�esent�es dans les paragraphes suivants. Bien entendu, il n'en estrien.La d�emarche pr�esidant �a la preuve de la loi d'Amdahl consiste �a �etudier les performancesen temps d'un programme parall�ele appliqu�e �a une instance d'un probl�eme de taille n�x�ee, que l'on borne (entre autres) en fonction du nombre de processeurs. Les in�equationsobtenues contiennent donc l'hypoth�ese implicite que la taille n du probl�eme �a r�esoudre etle nombre p de processeurs sont ind�ependants, ce qui n'est pas le cas de la probl�ematiquede ce travail, le changement d'�echelle consistant �a augmenter la taille des probl�emes trait�esde pair avec le nombre de processeurs.En particulier on a pris soin d'inclure autant que possible les instructions d�ependant de lataille du probl�eme �a traiter dans la partie de l'algorithme g�en�erique devant etre r�epartiesur les processeurs. En cons�equence, et contrairement �a ce que suppose la loi d'Amdahl,le temps TPar(n) pris pour ex�ecuter la partie de l'algorithme qui peut etre parall�elis�een'est plus une constante, puisque comme le montrent les mesures exp�erimentales cettevaleur augmente avec la taille du probl�eme. Ainsi, dans le cadre du changement d'�echelle,les deux architectures parall�eles propos�ees pour SIAO1 sont de bonnes candidates auparall�elisme massif (si elles sont appliqu�ees �a des bases de donn�ees importantes).5.5 R�esultats exp�erimentaux5.5.1 Protocole de validationConditions d'exp�erimentationA�n de quanti�er aussi pr�ecis�ement que possible l'apport des deux architectures propos�ees,un environnement permettant de s'approcher autant que possible des conditions de mesureid�eales a �et�e recherch�e. Les exp�eriences d�etaill�ees ci-dessous ont toutes �et�e r�ealis�ees sur unemachine IBM SP2 disposant de huit �el�ements identiques, construits autour de processeursRS-6000 et disposant chacun de 256 Mo de m�emoire. Bien que cette machine parall�ele

5.5. R�esultats exp�erimentaux 183poss�ede un canal de communication �a haut d�ebit entre les �el�ements le constituant (leswitch), le canal Ethernet classique (assurant un d�ebit de 10Mo/s) a �et�e pr�ef�er�e a�nde se placer dans des conditions identiques �a celles d'un r�eseau local standard, ce quirend possibles des comparaisons avec d'autres travaux. En�n, un syst�eme de supervision(appel�e loadleveller) g�ere les travaux soumis �a la machine et permet la r�eservation deprocesseurs d�edi�es �a une application, ce qui garantit alors une puissance de calcul identiqueet constante des �el�ements utilis�es.Mesures e�ectu�eesIl a �et�e possible de v�eri�er exp�erimentalement que la qualit�e des solutions ainsi que ladur�ee (en nombre de g�en�erations) des versions parall�ele et s�equentielle de l'algorithme�etaient identiques. Cependant, �a la mesure bruteT brutep (n) =Dur�ee d'ex�ecution du programme tournant sur p processeurs,on a pr�ef�er�e une autre mesure :T ratiop (n) = Dur�ee d0ex�ecution du programme tournant sur p processeursNombre d0individus evalu�es .En e�et, l'algorithme n'�etant pas d�eterministe, la variance du nombre de g�en�erationsd'un test �a l'autre provoque dans certains cas une variance non n�egligeable des dur�eesd'ex�ecution. De plus, le nombre de valeurs des param�etres d'une part et la dur�ee decertains apprentissages d'autre part ne permettent pas de faire un nombre de tests su�santpour estimer dans ces cas les valeurs moyennes avec une pr�ecision su�sante. Par contre,l'ajustement provoqu�e par l'�evaluation de T ratiop (n) permet de fournir avec certitude desr�esultats tr�es pr�ecis �equivalents car strictement proportionnels �a T brutep (n).Les mesures �etudi�ees sont donc :{ T ratiop (n) = T brutep (n)Nombre d0individus evalues ;{ Mp(n) =Taille m�emoire (en Mo) des esclaves.Il convient en�n de noter que {sauf mention du contraire{ il a �et�e a�ect�e un processusesclave par processeur. La charge du processus ma�tre �etant en e�et tr�es peu importante,ce dernier partageait un processeur avec un processus esclave.5.5.2 Premiers r�esultatsUne premi�ere s�erie d'exp�eriences6 destin�ees �a estimer grossi�erement le gain que l'onpeut obtenir grace aux architectures propos�ees a �et�e conduite sur deux bases dont lescaract�eristiques d�etaill�ees �gurent en annexe B. Ce choix r�esulte ici simplement du faitque Mushrooms est une base de taille moyenne (0,37 Mo, plusieurs milliers d'exemples),6Ces exp�erimentations pr�eliminaires ont �et�e r�ealis�ees avant que le m�ecanisme de m�emoire tamponauquel il est fait r�ef�erence au paragraphe 5.4.3.1 ne soit envisag�e et implant�e.

184 CHAPITRE 5. PARALL�ELISME ET R�EPARTITIONalors que Census-income est une base de grande taille (155 Mo, plusieurs centaines demilliers d'exemples), ce qui permet d'estimer les performances des deux architectures surun probl�eme habituel ainsi que du point de vue du changement d'�echelle en espace.
Nombre de processeurs
Acc
eler
atio
n
1 2 3 4 5 6 7 8 9
1
2
3
4
5
6
7 Architecture M-EsclaveArchitecture Pipeline G-Net
Fig. 5.9: Acc�el�eration (Mushrooms) Nombre de processeurs
Effi
caci
te
1 2 3 4 5 6 7 8 90
1
0.5
Architecture M-EsclaveArchitecture Pipeline G-Net Fig. 5.10: E�cacit�e (Mushrooms)Les �gures 5.9 et 5.10 permettent de comparer les performances obtenues pour les deuxarchitectures de SIAO1 sur la base Mushrooms (4000 exemples d'apprentissage, 4128exemples de test) avec des r�esultats concernant G-Net publi�es dans [Angelano et al.97].Le tableau suivant pr�ecise les conditions exp�erimentales qui ne sont pas exactement lesmemes : Syst�eme SIAO1 G-NetMachine RS-6000 Sparc20�el�ementaireD�ebit du 10 Mb/s 10 Mb/sR�eseauBase Mushrooms Thousand trainsExemples 4000 1000d'apprentissage (attribut-valeur) (relationnels)Tab. 5.3: Conditions d'exp�erimentation.La seconde partie de l'exp�erimentation, dont les r�esultats sont montr�es �gures 5.11 et 5.12,concerne l'�evaluation de l'architecture pipeline sur la base Census-income. Cette base estparticuli�erement int�eressante car il s'agit d'un probl�eme r�eel de grande taille (voir annexeB, section B.1).Les r�esultats montrent que l'on obtient dans ce cas des performances quasi-optimales,alors que le pipeline est en th�eorie la plus lente des deux architectures �etudi�ees.Cette pr�e-�etude ayant �et�e r�ealis�ee alors que les n�uds de l'IBM SP2 ne disposaient quede 128 Mo de m�emoire RAM, ces derniers se sont �ecroul�es lors du test des versions

5.5. R�esultats exp�erimentaux 185
Processeurs
Acc
eler
atio
n
1 2 3 4 5 6 7 81
2
3
4
5
6
7
8
Pipeline
Fig. 5.11: Acc�el�eration Processeurs
Effi
caci
te
1 2 3 4 5 6 7 80
1
0.5
PipelineFig. 5.12: E�cacit�es�equentielles et ma�tre-esclave du syst�eme. Bien qu'il ne soit pas possible de conna�treavec certitude les causes de ce probl�eme, il semble n�eanmoins qu'elles soient relatives �a lagestion des �chiers de recouvrement (swap) par le syst�eme d'exploitation. L'architecturepipeline utilisant deux esclaves a donc servi de point de r�ef�erence avec une e�cacit�e �x�ee�a l'unit�e et une acc�el�eration �x�ee �a 2.En�n, une �etude de la taille m�emoire requise par les processus esclaves pour l'architecturepipeline, dont les r�esultats �gurent dans le tableau 5.4, a �et�e r�ealis�ee sur des PCs connect�esen r�eseau. La d�ecroissance deMp(n) est bien en 1p �a partir de p = 2 esclaves. Le fait que lesmesures concernant le processus s�equentiel d�enotent une taille m�emoire plus importanteque pr�evu est sans doute en partie du aux di��erentes structures prises en charge par leprocessus ma�tre et non r�eparties sur les esclaves (populations, etc. ).Nombre d'esclaves 1a 2 3 4 5 6 7 8BaseMushrooms 4048 1672 1400 1260 1164 1116 1080 1052Census-income 143360 52008 34916 26308 21160 17732 15236 13396aTaille de l'unique processus de la version s�equentielle.Tab. 5.4: Espace m�emoire requis par les processus du pipeline (en Ko).5.5.3 �Etude sur les bases Mushrooms et IrisProbl�ematiqueLes r�esultats pr�ec�edents ont permis la validation des architectures en prouvant leurs tr�esbonnes performances sur di��erents types de probl�emes. Cependant, cette premi�ere val-idation, succincte et empirique, soul�eve �egalement la question de savoir s'il est possible

186 CHAPITRE 5. PARALL�ELISME ET R�EPARTITIONd'�evaluer plus pr�ecis�ement les capacit�es de changement d'�echelle du syst�eme. Comme l'amontr�e le paragraphe 5.4.2, la plupart des grandeurs caract�erisant la capacit�e d'un al-gorithme �a changer d'�echelle n�ecessitent un tr�es grand nombre de mesures, ce qui estnon seulement couteux en terme d'allocation de ressources informatiques, mais �egalementdi�cile �a justi�er en pratique.Une solution �a ce probl�eme consiste �a trouver un mod�ele du comportement des architec-tures, id�ealement aussi simple �a mettre en �uvre et pr�ecis que possible. Le mod�ele de[CP97a] d�ej�a d�ecrit au paragraphe 5.3.4 �etant sp�eci�que aux architectures ma�tre-esclavessynchrones sans �les d'attentes ne peut etre utilis�e, et ce d'autant plus que c'est l'�etudedes termes r�eductibles de l'�equation (M-E Sync 3) de ce meme mod�ele qui a guid�e laconception des architectures implant�ees. D'autre part, les �equations (T m-esc) et (Tpipeline) des paragraphes 5.4.3.1 et 5.4.3.2 sont beaucoup trop optimistes puisque lacharge �etant r�epartie de mani�ere optimale sur les processeurs, et les couts de communi-cations �etant presque totalement �elimin�es grace au m�ecanisme des �les d'attente, on a :limi!1 T m�esci = limi!1 T pipelinei = tepce qui, du point de vue d'un mod�ele et au vu des r�esultats obtenus ne semble pas r�ealistememe lorsque les contraintes respectives (C1 m-esc) et (C2 m-esc) ou (C1 pipeline)et (C2 pipeline) { qui portent entre autres sur p { sont v�eri��ees.Construction du mod�eleUne �etude plus compl�ete est donc n�ecessaire a�n de caract�eriser les nouveaux facteurs deralentissement. Ces derniers devant etre d'autant plus visibles que les temps de traitementdes esclaves sont courts, la baseMushrooms a �et�e utilis�ee. Les r�esultats, d�etaill�es en annexeC sont r�esum�es par les graphiques ci-apr�es. Les acronymes RCD et RCS font respective-ment r�ef�erence aux architectures �a R�epartition de Charge Dynamique (il s'agit alorsdu ma�tre-esclave asynchrone) et �a R�epartition de Charge Statique (c'est le pipeline).On s'est non seulement attach�e �a faire varier le nombre de processeurs, mais �egalement �a�etudier l'in uence de la taille du tampon de m�emorisation des messages ( Norm. d�enoteune communication sans utilisation d'aucune m�emoire tampon, et L(i) l'utilisation d'uneliste de taille i). Chaque point repr�esente la valeur moyenne obtenue pour cinq ex�ecutions,et les barres l'entourant ont leurs extr�emit�es �a une distance de un �ecart-type de la valeurmoyenne7.Comme attendu, on remarque que d'une part l'architecture RCD est l�eg�erement plus per-formante que l'architecture RCS, et d'autre part que la d�ecroissance de l'acc�el�eration,bien que l�eg�ere, est notable et ne peut etre expliqu�ee par les mod�eles mentionn�es aupara-vant. Par contre, l'incidence de la variation de la taille des tampons de m�emorisation des7Sur les graphiques d�etaillant les r�esultats obtenus sur la base Mushrooms, ces derni�eres sont troppetites pour pouvoir etre vues avec discernement

5.5. R�esultats exp�erimentaux 187
0.9
1.4
1.9
2.4
2.9
3.4
3.9
0 1 2 3 4 5
NormalL (1)L (2)L (3)
Fig. 5.13: Acc�el�eration RCD 0.9
1.4
1.9
2.4
2.9
3.4
3.9
0 1 2 3 4 5
NormalL (1)L (2)L (3)
Fig. 5.14: Acc�el�eration RCS
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
1.1
0 1 2 3 4 5
NormalL (1)L (2)L (3)
Fig. 5.15: E�cacit�e RCD 0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
1.1
0 1 2 3 4 5
NormalL (1)L (2)L (3)
Fig. 5.16: E�cacit�e RCSmessages est nulle sur les performances de l'architecture RCD et tr�es faible dans le casde l'architecture RCS. En fait, une observation plus d�etaill�ee de la charge des processeursmontre que la partie logicielle du syst�eme de gestion des messages (en l'occurrence leprocessus-demon pvmd) n�ecessite une puissance de calcul de moins en moins n�egligeablelorsque le nombre d'esclaves s'accro�t.Contrairement �a la loi d'Amdahl, qui pose T1(n) = TSeq(n) + TPar(n) puis en d�eduitque de mani�ere optimale { en n�egligeant le surcout du aux communications { T �p (n) =TSeq(n) + TPar(n)p , les observations exp�erimentales conduisent ici �a n�egliger TSeq(n) mais �aajouter un terme correcteur li�e au surcout logiciel caus�e par la gestion des communicationsTCom(n; p). Contrairement �a TSeq(n), TCom(n; p) d�epend bien �evidemment du nombre deprocesseurs. On pose donc :Tp(n) = 1p(TCom(n; p) + T1(n)) (Eq-M 1)De plus, on d�eduit des conditions initiales en p = 1 que TCom(n; 1) = 0. Ainsi, on a :TCom(n; p) = p:Tp(n)� T1(n) (Eq-M 2)
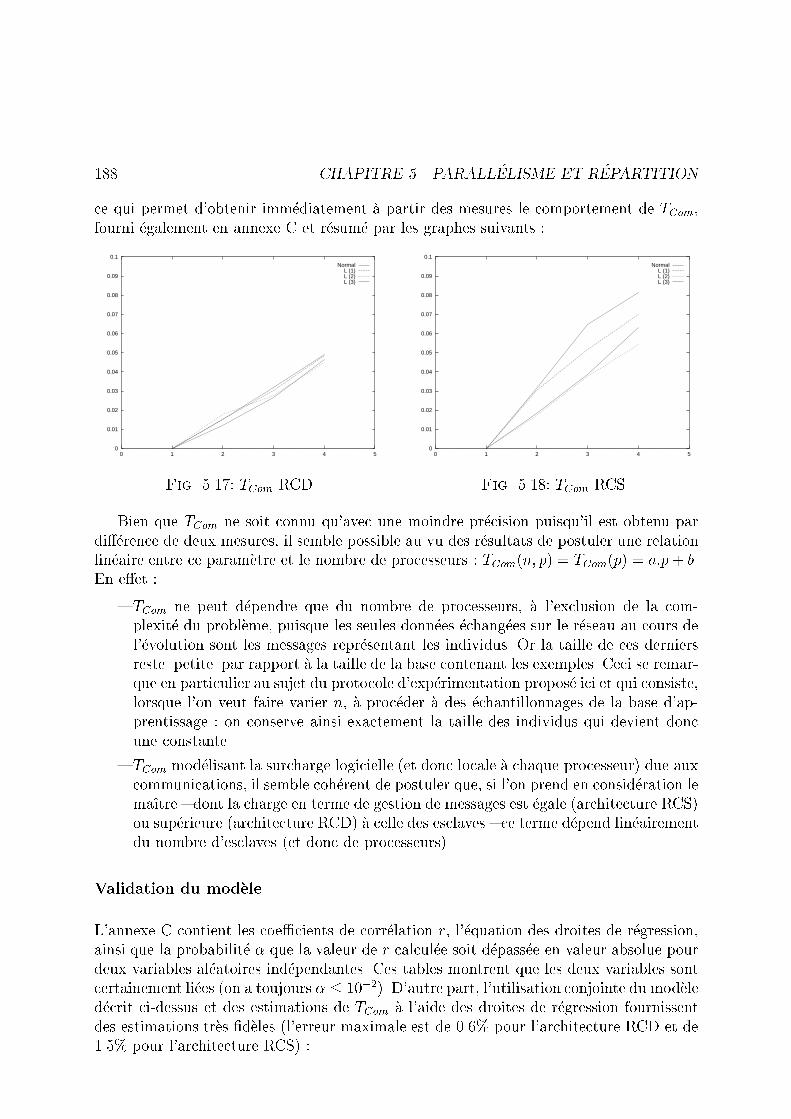
188 CHAPITRE 5. PARALL�ELISME ET R�EPARTITIONce qui permet d'obtenir imm�ediatement �a partir des mesures le comportement de TCom,fourni �egalement en annexe C et r�esum�e par les graphes suivants :
0
0.01
0.02
0.03
0.04
0.05
0.06
0.07
0.08
0.09
0.1
0 1 2 3 4 5
NormalL (1)L (2)L (3)
Fig. 5.17: TCom RCD 0
0.01
0.02
0.03
0.04
0.05
0.06
0.07
0.08
0.09
0.1
0 1 2 3 4 5
NormalL (1)L (2)L (3)
Fig. 5.18: TCom RCSBien que TCom ne soit connu qu'avec une moindre pr�ecision puisqu'il est obtenu pardi��erence de deux mesures, il semble possible au vu des r�esultats de postuler une relationlin�eaire entre ce param�etre et le nombre de processeurs : TCom(n; p) = TCom(p) = a:p+ b.En e�et :{ TCom ne peut d�ependre que du nombre de processeurs, �a l'exclusion de la com-plexit�e du probl�eme, puisque les seules donn�ees �echang�ees sur le r�eseau au cours del'�evolution sont les messages repr�esentant les individus. Or la taille de ces derniersreste petite par rapport �a la taille de la base contenant les exemples. Ceci se remar-que en particulier au sujet du protocole d'exp�erimentation propos�e ici et qui consiste,lorsque l'on veut faire varier n, �a proc�eder �a des �echantillonnages de la base d'ap-prentissage : on conserve ainsi exactement la taille des individus qui devient doncune constante.{ TCom mod�elisant la surcharge logicielle (et donc locale �a chaque processeur) due auxcommunications, il semble coh�erent de postuler que, si l'on prend en consid�eration lema�tre { dont la charge en terme de gestion de messages est �egale (architecture RCS)ou sup�erieure (architecture RCD) �a celle des esclaves { ce terme d�epend lin�eairementdu nombre d'esclaves (et donc de processeurs).Validation du mod�eleL'annexe C contient les coe�cients de corr�elation r, l'�equation des droites de r�egression,ainsi que la probabilit�e � que la valeur de r calcul�ee soit d�epass�ee en valeur absolue pourdeux variables al�eatoires ind�ependantes. Ces tables montrent que les deux variables sontcertainement li�ees (on a toujours � � 10�2). D'autre part, l'utilisation conjointe du mod�eled�ecrit ci-dessus et des estimations de TCom �a l'aide des droites de r�egression fournissentdes estimations tr�es �d�eles (l'erreur maximale est de 0.6% pour l'architecture RCD et de1.5% pour l'architecture RCS) :

5.5. R�esultats exp�erimentaux 189RCD Norm. RCD L(1) RCD L(2) RCD L(3)p r�eel mod�ele err. r�eel mod�ele err. r�eel mod�ele err. r�eel mod�ele err.1 1,000 1,001 0,1% 1,000 1,001 0,1% 1,000 0,997 0,3% 1,000 1,005 0,5%2 0,959 0,958 0,1% 0,960 0,959 0,1% 0,953 0,959 0,6% 0,968 0,964 0,4%3 0,919 0,918 0,1% 0,923 0,920 0,3% 0,930 0,924 0,6% 0,932 0,926 0,6%4 0,881 0,881 0,0% 0,882 0,884 0,2% 0,890 0,892 0,2% 0,887 0,892 0,5%RCS Norm. RCS L(1) RCS L(2) RCS L(3)p r�eel mod�ele err. r�eel mod�ele err. r�eel mod�ele err. r�eel mod�ele err.1 1,000 0,992 0,8% 1,000 0,990 1,0% 1,000 1,000 0,0% 1,000 1,004 0,4%2 0,917 0,919 0,2% 0,919 0,929 1,0% 0,952 0,950 0,2% 0,950 0,947 0,3%3 0,844 0,857 1,5% 0,870 0,875 0,5% 0,903 0,905 0,2% 0,900 0,896 0,4%4 0,811 0,802 1,1% 0,833 0,827 0,7% 0,865 0,864 0,1% 0,848 0,851 0,3%Tab. 5.5: Performance du mod�ele appliqu�e au calcul de l'e�cacit�e (Mushrooms).Puisque le comportement de l'algorithme parall�ele est correctement captur�e par le mod�ele,la derni�ere �etape de validation concerne l'�etude de sa capacit�e de g�en�eralisation, c'est-�a-dire de pr�ediction dans des cas non pris en compte lors de son �elaboration. Pour ce faire,deux types de variations ont �et�e prises en compte :1. Variation de la taille de la base d'apprentissage.Ce param�etre, particuli�erement important pour toute �etude de changement d'�echelle,peut etre imm�ediatement pris en compte en appliquant un coe�cient repr�esentantl'accroissement (ou la diminution) de charge sur T1, le comportement de TCom restantinchang�e. Les r�esultats ci-dessous montrent que le mod�ele obtenu pr�ec�edemmentpour un apprentissage sur 4000 exemples de la base Mushrooms s'adapte parfaite-ment �a des apprentissages sur 2000 ou 6000 exemples de cette meme base.Archi. Com. jEj p T ratiop pr�edit T ratiop observ�e ErreurRCD Norm. 2000 3 0,0712 0,0679 4,8%RCD Norm. 6000 2 0,280 0,283 1,0%2. Variation du nombre de processeurs.Le second param�etre crucial pour toute �etude de changement d'�echelle est bien en-tendu le nombre p de processeurs. Le tableau ci-apr�es compare les r�esultats exp�erimentauxobserv�es sur 5 et 6 processeurs avec les r�esultats pr�edits �a l'aide du mod�ele �elabor�e�a partir des donn�ees pour 1 �a 4 processeurs. Dans ce cas �egalement, la pr�ecisionobtenue est tout-�a-fait satisfaisante.Archi. Com. jEj p T ratiop pr�edit T ratiop observ�e ErreurRCD Norm. 4000 5 0,0856 0,0864 0,9 %RCD Norm. 4000 6 0,0740 0.0752 1,6 %

190 CHAPITRE 5. PARALL�ELISME ET R�EPARTITIONCas de la base IrisA�n d'etre compl�ete, l'�etude du comportement des architectures parall�eles propos�ees pourSIAO1 et du mod�ele de pr�ediction de leurs performances a �et�e �egalement r�ealis�ee dans uncas limite. Pour ce faire, la base Iris, ne contenant que 150 exemples, a �et�e utilis�ee. Bien quen'ayant aucun int�eret pratique (puisqu'un apprentissage sur cette base dure moins d'uneminute sur un IBM PC classique, ce qui retire tout int�eret �a une parall�elisation), cette�etude de cas permet de se placer dans des conditions extremes : le temps d'�evaluationd'un individu est si peu important que d'une part la charge du ma�tre (gestion de lapopulation, ...) n'est plus du tout n�egligeable, et que d'autre part le d�ebit du r�eseau n'estplus su�sant pour assurer des communications uides lorsqu'on augmente le nombre deprocesseurs.
0.9
1
1.1
1.2
1.3
1.4
1.5
1.6
1.7
1.8
1.9
2
2.1
2.2
2.3
2.4
2.5
2.6
2.7
2.8
2.9
3
0 1 2 3 4 5
NormalL (1)L (2)L (3)
Fig. 5.19: Acc�el�eration RCD 0.9
1
1.1
1.2
1.3
1.4
1.5
1.6
1.7
1.8
1.9
2
2.1
2.2
2.3
2.4
2.5
2.6
2.7
2.8
2.9
3
0 1 2 3 4 5 6
NormalL (1)L (2)L (3)
Fig. 5.20: Acc�el�eration RCS
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
1.1
0 1 2 3 4 5 6
NormalL (1)L (2)L (3)
Fig. 5.21: E�cacit�e RCD 0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
1.1
0 1 2 3 4 5 6
NormalL (1)L (2)L (3)
Fig. 5.22: E�cacit�e RCSLes �gures 5.19, 5.20, 5.21 et 5.22 illustrent bien le fait que le ma�tre perd peu �a peu pied,l'acc�el�eration n'�etant plus du tout lin�eaire et l'e�cacit�e tr�es mauvaise. Contrairement �ace qui se passait dans l'exemple pr�ec�edent, on peut remarquer deux faits nouveaux :

5.5. R�esultats exp�erimentaux 191{ Les performances de l'architecture RCS sont consid�erablement plus d�egrad�ees quecelles de l'architecture RCD. En e�et, l'acc�el�eration semble se stabiliser �a 2,5 dansle cas de l'architecture RCD au del�a de 4 processeurs, alors qu'elle reste inf�erieure �a1,9 dans le cas de l'architecture RCS sans conna�tre de progression notable au del�ade 2 processeurs.{ L'ajout d'un tampon m�emorisant un message accro�t notablement les performances,cependant aucune am�elioration n'est constat�ee si l'on continue d'augmenter la tailledu tampon. Malgr�e la plus grande incertitude sur les r�esultats (observable aux �ecarts-types mesur�es), ce constat est valable quelle que soit l'architecture utilis�ee.Par contre, comme le montrent intuitivement les �gures 5.23 et 5.24 (ceci est con�rm�e parles r�esultats d�etaill�es de l'annexe C), on peut toujours postuler une d�ependance entre TComet p, et il semble que cette d�ependance puisse encore etre mod�elis�ee (plus grossi�erementcette fois) par une droite. Bien que le mod�ele obtenu en ajustant TCom sur sa droite
0
0.01
0.02
0.03
0.04
0.05
0.06
0.07
0.08
0.09
0.1
0 1 2 3 4 5 6
NormalL (1)L (2)L (3)
Fig. 5.23: TCom RCD 0
0.01
0.02
0.03
0.04
0.05
0.06
0.07
0.08
0.09
0.1
0 1 2 3 4 5 6
NormalL (1)L (2)L (3)
Fig. 5.24: TCom RCSRCD Norm. RCD L(1) RCD L(2) RCD L(3)p r�eel mod�ele err. r�eel mod�ele err. r�eel mod�ele err. r�eel mod�ele err.1 1.000 1.070 7.0% 1.000 1.005 0.5% 1.000 1.056 5.6% 1.000 1.097 9.7%2 0.775 0.777 0.2% 0.816 0.821 0.6% 0.853 0.842 1.2% 0.872 0.846 2.9%3 0.653 0.611 6.4% 0.697 0.693 5.7% 0.736 0.700 4.8% 0.726 0.689 5.0%4 0.521 0.503 3.4% 0.612 0.600 1.9% 0.614 0.599 2.4% 0.619 0.581 6.1%5 0.410 0.427 4.1% 0.523 0.529 1.1% 0.506 0.524 3.5% 0.473 0.502 6.1%RCS Norm. RCS L(1) RCS L(2) RCS L(3)p r�eel mod�ele err. r�eel mod�ele err. r�eel mod�ele err. r�eel mod�ele err.1 1.000 1.125 12.5% 1.000 0.986 1.4% 1.000 1.003 0.3% 1.000 1.011 1.1%2 0.645 0.605 6.2% 0.715 0.682 4.6% 0.734 0.691 5.8% 0.737 0.683 7.3%3 0.409 0.413 0.9% 0.495 0.522 5.4% 0.508 0.527 3.7% 0.494 0.516 4.4%4 0.336 0.314 6.5% 0.412 0.422 2.4% 0.410 0.426 3.9% 0.398 0.415 4.2%5 0.244 0.253 3.6% 0.365 0.355 2.7% 0.368 0.358 2.7% 0.358 0.347 3.0%Tab. 5.6: Performance du mod�ele appliqu�e au calcul de l'e�cacit�e (Iris).

192 CHAPITRE 5. PARALL�ELISME ET R�EPARTITIONde r�egression soit moins pr�ecis qu'auparavant (cf. tableau 5.6), on peut observer que ceparam�etre, ainsi que les hypoth�eses concernant sa variation, permettent encore de rendrecompte de mani�ere correcte de l'�evolution de l'e�cacit�e. En conclusion, l'�etude du caslimite (qui a lieu lorsque le temps de gestion de la population par le ma�tre n'est plusn�egligeable devant le temps d'�evaluation des individus) montre que le ralentissement du�a la partie logicielle de la gestion des messages (mod�elis�ee par le param�etre TCom) est lefacteur limitant de plus grande importance. La mod�elisation de ce facteur s'av�ere etresu�sante pour rendre compte et pr�evoir les performances du syst�eme.ConclusionUn mod�ele simple des performances des architectures ma�tre-esclave et pipeline a �et�epropos�e. Il a �et�e montr�e exp�erimentalement que le comportement du principal param�etre,TCom, peut etre d�ecrit par une loi lin�eaire, que l'on peut d�eterminer par r�egression �a partird'un tr�es petit nombre de tests, soit :TCom = �:p+ � (�)Il a �et�e �egalement observ�e que cette relation permet de g�en�eraliser correctement le com-portement de TCom pour des valeurs de p voisines non prises en compte lors de la con-struction du mod�ele. D'autre part, l'impact de la variation de la complexit�e du probl�eme(suppos�ee ici proportionnelle �a sa taille, c'est-�a-dire au nombre d'exemples d'apprentis-sage) est �egalement pr�edite correctement. En conclusion, la relationTp(m) = 1p : h�:p+ � + mn :T1(n)i (Eq-M 3)est un mod�ele pr�edictif �able.5.5.4 �A propos du changement d'�echelle de SIAO1Une application imm�ediate concerne l'estimation des capacit�es de changement d'�echelledes architectures implant�ees pour le probl�eme Mushrooms sur la machine IBM-SP2.La �gure 5.25 montre l'e�cacit�e pr�edite par le mod�ele dans le cas de l'architecture ma�tre-esclave utilisant une �le d'attente de taille un. La complexit�e de la tache varie de 2.000 �a8.000 exemples d'apprentissage et le nombre p de processeurs de 1 �a 8. Il est int�eressant denoter que si la conservation d'une e�cacit�e presque parfaite (par exemple 90%) semble dif-�cile (le nombre d'exemples �a soumettre au syst�eme s'accro�t beaucoup trop rapidement),il est n�eanmoins possible d'obtenir de bonnes performances (comme le montre, par exem-ple, la r�egion E 2 [0; 8::0; 9]) pour un facteur de changement d'�echelle tr�es raisonnable.

5.6. Bilan 193 0.7 0.8 0.9
12
34
56
78 2000
30004000
50006000
70008000
0.60.65
0.70.75
0.80.85
0.90.95
11.05
Fig. 5.25: Surface E(n; p) calcul�ee d'apr�es le mod�ele pour le probl�eme Mushrooms. Lescourbes d'iso-e�cacit�e associ�ees �gurent sur le plan (n; p).5.6 BilanCe chapitre a permis la validation de deux architectures parall�eles implant�ees a�n depermettre �a SIAO1 de changer d'�echelle tout en conservant int�egralement le fonction-nement de l'algorithme.Dans le cas o�u l'accroissement de la complexit�e est du �a une forte composante relationnelledu probl�eme, ou lorsque la base d'apprentissage est de taille moyenne (500 �a 20 000exemples), l'architecture de type ma�tre-esclave doit etre pr�ef�er�ee. En e�et, d'une part sonasynchronisme lui permet de s'adapter �a la variation des dur�ees d'�evaluation, et d'autrepart il a �et�e montr�e qu'elle est plus performante dans ce contexte d'utilisation.Par contre, lorsqu'on se place dans une perspective de mont�ee en charge a�n de traiter degrandes bases d'apprentissage, dont la taille est �eventuellement sup�erieure �a la m�emoiredisponible sur une machine, on utilisera l'architecture bas�ee sur un pipeline puisqu'eller�epartit les donn�ees sur les processeurs. De plus, les temps d'�evaluation devenant tr�esimportants, le probl�eme du d�ebit du r�eseau n'est plus un obstacle et les performancesobtenues approchent la limite th�eorique pr�edite par la loi d'Amdahl.En�n, un mod�ele simple et pr�ecis des performances des architectures a �et�e propos�e, et samise en �uvre a permis d'�evaluer plus pr�ecis�ement les capacit�es de changement d'�echellede SIAO1 par le biais du comportement de l'iso-e�cacit�e.

194 CHAPITRE 5. PARALL�ELISME ET R�EPARTITION

Chapitre 6Conclusion6.1 BilanCette th�ese a pr�esent�e la conception, l'implantation et la validation du syst�eme d'ap-prentissage automatique supervis�e symbolique (AS) SIAO1 fond�e sur les algorithmesd'�evolution. La premi�ere caract�eristique de ce syst�eme est sa polyvalence, puisqu'il peuts'appliquer dans des contextes extremement vari�es sans pour autant n�ecessiter la sp�eci�cationde nombreux biais :{ les donn�ees peuvent etre de nature symbolique, num�erique ou mixte ;{ le langage de description des concepts peut etre de type attribut-valeur ou relation-nel ;{ dans le cas de l'induction de concepts relationnels, la forme de la solution s'adapteau cours de l'�evolution1 ;{ la taille des bases d'apprentissage peut varier de quelques dizaines �a plusieurs cen-taines de milliers d'instances.Parmi les diverses probl�ematiques abord�ees, deux directions de recherche sont centralespour les domaines de l'AS et de l'extraction de connaissances �a partir des donn�ees.La premi�ere direction est issue du dilemme liant l'expressivit�e des langages de descriptiondes instances et des hypoth�eses au cout de l'induction. L'approche adopt�ee, qui met en�uvre des techniques de propagation de contraintes, montre qu'il est possible { y com-pris dans le cas des probl�emes relationnels r�eels complexes { de relaxer certains biaisde recherche ou de repr�esentation classiques par l'utilisation de proc�edures optimis�eesadapt�ees au langage consid�er�e.La seconde direction concerne la probl�ematique du changement d'�echelle des m�ethodes1En particulier, il n'est pas n�ecessaire de fournir la forme de l'hypoth�ese ou de sp�eci�er de biais derecherche d�ecrivant le nombre et le type des liens qui la constituent.195

196 CHAPITRE 6. CONCLUSIONd'AS, r�esolue ici en parall�elisant l'algorithme SIAO1. Ce travail a permis de montrerqu'une premi�ere alternative, commune �a de nombreux travaux du domaine, qui consiste�a r�epartir les �evaluations des hypoth�eses suivant un sch�ema ma�tre-esclave, peut etream�elior�ee et compl�et�ee, lorsque le volume des donn�ees est important, par une architecturer�epartissant les instances d'apprentissage et de test sur les di��erentes machines a�n dediminuer les besoins en m�emoire. Un mod�ele pr�edictif permettant d'�evaluer le gain procur�epar les architectures propos�ees a �egalement �et�e pr�esent�e et valid�e.Un autre apport de cette th�ese a trait �a l'application des algorithmes �evolutionnaires (entant que proc�edures d'optimisation) aux probl�emes d'AS. SIAO1 prend en e�et le partid'int�egrer nettement dans la strat�egie de recherche les deux principales caract�eristiquesqui distinguent les taches d'apprentissage des autres probl�emes d'optimisation. En e�et,d'une part la relation de g�en�eralit�e qui structure l'espace des hypoth�eses est un �el�ementcentral de la strat�egie de recherche puisqu'elle est ascendante, et d'autre part la based'apprentissage est mieux exploit�ee puisque les op�erateurs d'�evolution sont, contrairementaux approches classiques, dirig�es par les donn�ees.6.2 PerspectivesAu stade actuel de son �evolution, SIAO1 pourrait b�en�e�cier de deux types d'exten-sions.1. Une architecture r�ealisant un pont avec un syst�eme de gestion de bases de donn�ees(SGBD). L'ajout de cette fonctionnalit�e est un travail complexe car il pose { entreautres { le probl�eme de l'acc�es aux donn�ees. Ces derni�eres peuvent en e�et etre g�er�eessoit par le SGBD (SIAO1 �evaluant chaque hypoth�ese au moyen d'une requete), soitpar SIAO1 (le pont se limite alors �a un syst�eme de traduction).2. Une interface g�erant l'ensemble du cycle visualisation des donn�ees / apprentissage/ �etude et modi�cation du mod�ele et permettant �egalement un interaction directeavec le syst�eme en cours d'apprentissage.Ces deux extensions feraient de SIAO1 un syst�eme complet d'extraction des connais-sances �a partir des donn�ees.Une autre orientation possible concerne la modi�cation du m�ecanisme d'�evolution simul-tan�ee de plusieurs noyaux a�n d'augmenter les interactions entre les di��erentes popu-lations. �A ce titre, les strat�egies mises en �uvre dans [Angelano et al.97] et [Torre99]pourraient etre adapt�ees au contexte de SIAO1 qui est caract�eris�e par un petit nombrede populations et une recherche ascendante. De telles strat�egies permettraient �egalement�a l'utilisateur de ne plus avoir �a sp�eci�er le nombre de noyaux devant �evoluer.

Annexe ANotations - D�e�nitionsCette annexe contient une table r�ecapitulant les diverses notations et abr�eviationsutilis�ees au cours de cette th�ese, ainsi que certaines d�e�nitions non rappel�ees dans lecorps du document concernant :1. Les ensembles ordonn�es et les treillis ;2. La construction et la manipulation des formules de la logique du premier ordre.A.1 NotationsEnsembles :2 �el�ement de l'ensemble.� sous-ensemble strict.� sous-ensemble.\ intersection.[ union.n di��erence ensembliste.; ensemble vide.jAj cardinal de l'ensemble A.A compl�ement de l'ensemble A.@ l'ensemble des nombres entiers, ou, par abus, son approximation parl'ensemble des entiers repr�esentables en machine.< l'ensemble des r�eels, ou, par abus, son approximation parl'ensemble des nombres ottants repr�esentables en machine.197

198 ANNEXE A. NOTATIONS - D�EFINITIONSLogique :^ conjonction (et)._ disjonction (ou).: n�egation (non).8 quanti�cateur universel pour tout .9 quanti�cateur existentiel il existe . implication (dans le cadre de la notation des clauses).! implication (notation usuelle, de gauche �a droite).j= implication logique (non d�ecidable en logique d'ordre 1).` d�eduction syntaxique (par des r�egles d'inf�erence, par la th�eorie du domaine).$ �equivalence.C ensemble �ni de symboles de constantes.F ensemble �ni de symboles de fonctions.P ensemble �ni de symboles de pr�edicats.T ensemble des termes du langage de la logique du premier ordre.V ensemble in�ni de symboles de variables.Algorithmique : op�erateur d'a�ectation.Apn nombre d'arrangements (ens. ordonn�es) de p objets pris parmi n.Def : Apn = n!(n�p)!Cpn nombre de combinaisons (ens. non ordonn�es) de p objets pris parmi n.Def : Cpn = n!p!(n�p)!f = O(g) f est domin�ee asymptotiquement par g.Def : f = O(g) ssi 9c 2 <+�; 9n0 2 @=8n > n0; f(n) � c:g(n)f = �(g) f et g ont meme ordre de grandeur asymptotique.Def : f = �(g) ssi f = O(g) et g = O(f)Apprentissage :�g relation de g�en�eralit�e d�e�nie sur Lh (c'est un ordre partiel).`� relation de �-subsomption (voir chapitre 3)B base d'apprentissage de cardinal jBj.B+ l'ensemble des exemples (du concept-cible) de la base d'apprentissage.B� l'ensemble des contre-exemples de la base d'apprentissage.Ce un contre-exemple du concept-cible, exprim�e dans le langage Le.Ex un exemple du concept-cible, exprim�e dans le langage Le.Le langage de description des exemples.Lh langage de description des hypoth�eses.T base de test de cardinal jT j.T h th�eorie du domaine.

A.2. De�nitions 199A.2 De�nitionsA.2.1 Ensembles ordonn�es - TreillisD�e�nition A.1 Relation d'ordre, relation d'ordre strict, relation d'ordre largeUne relation d'ordre (not�ee R) est une relation d'ordre large ou une relation d'ordrestrict. Une relation d'ordre large (not�ee �) est une relation r�e exive, antisym�etrique ettransitive. Une relation d'ordre strict (not�ee >) est une relation irr�e exive, antisym�etriqueet transitive.D�e�nition A.2 Ordre total et ordre partielSi la relation d'ordre R permet de comparer deux �el�ements quelconques (ie. si elle v�eri�e8 e; e0 2 E; e 6= e0 ) (e R e0 ou e0 R e)), alors R est un ordre total, sinon R est un ordrepartiel.D�e�nition A.3 Ensemble ordonn�eUn ensemble E muni d'une relation d'ordre � est dit ordonn�e.D�e�nition A.4 Borne sup�erieure et borne inf�erieureUn �el�ement x est la borne sup�erieure d'une partie E 0 d'un ensemble ordonn�e E si etseulement si x est le plus petit majorant de E 0 : (8y 2 E 0; x � y) et (8z 2 E; ((8y 2E 0; z � y)) z � x)).Un �el�ement x est la borne inf�erieure d'une partie E 0 d'un ensemble ordonn�e E si etseulement si x est le plus grand minorant de E 0.Propri�et�e A.1Les bornes sup�erieures et inf�erieures n'existent pas toujours dans le cas d'ensembles or-donn�es quelconques. Par contre, s'il existe une borne sup�erieure ou inf�erieure, alors elleest unique.D�e�nition A.5 Sup-demi treillis et inf-demi treillisUn ensemble ordonn�e est un sup-demi (resp. inf-demi) treillis si et seulement si toutepaire d'�el�ements admet une borne sup�erieure (resp. inf�erieure).D�e�nition A.6 TreillisUn ensemble ordonn�e est un treillis si et seulement si toute paire d'�el�ements admet uneborne sup�erieure et une borne inf�erieure.

200 ANNEXE A. NOTATIONS - D�EFINITIONSA.2.2 Le langage de la logique relationnelleCette partie d�e�nit les �el�ements n�ecessaires �a la construction des formules de la logiquedu premier ordre. La �gure A.1 donne une vue d'ensemble sur l'imbrication des di��erents�el�ements du langage.bien forméesFormules
Connecteurs
Quantificateurs
Prédicats
Termes
Variables
ConstantesLittéraux
Négation
Formulesatomiques
Fig. A.1: Construction des formules de la logique relationnelle.D�e�nition A.7 Symboles du langage de la logique du premier ordreLe langage de la logique du premier ordre est compos�e d'un alphabet contenant :{ les connecteurs :,^,_,!, ,$ ;{ les parenth�eses (,) ;{ les quanti�cateurs universels 8 et existentiels 9 ;ainsi que les ensembles de symboles suivants :{ un ensemble in�ni V de symboles de variables ;{ un ensemble �ni C de symboles de constantes ;{ un ensemble �ni F de symboles de fonctions ;{ un ensemble �ni P de symboles de pr�edicats.�A chaque �el�ement de P (resp. F), est associ�e un entier positif (resp. strictement positif)appel�e arit�e, repr�esentant le nombre d'arguments du pr�edicat (resp. de param�etres de lafonction).D�e�nition A.8 Terme et terme clos (ou ferm�e){ L'ensemble T des termes du langage est le plus petit ensemble satisfaisant :1. tout symbole de constante ou de variable est un terme ;2. si f est un symbole de fonction d'arit�e k et si t1; t2; :::; tk sont des termes alorsf(t1; t2; :::; tk) est �egalement un terme.{ Un terme ne comportant aucun symbole de variable est dit clos (ou encore ferm�e).D�e�nition A.9 Formule atomique ou atomeOn appelle atome un pr�edicat appliqu�e �a un nombre correct de termes : si P est un symbolede pr�edicat d'arit�e k et t1; t2; :::; tk sont des termes, alors P (t1; t2; :::; tk) est un atome. Uneformule constitu�ee uniquement d'un et un seul atome est dite atomique.

A.2. De�nitions 201D�e�nition A.10 Litt�eral, litt�eral positif, litt�eral n�egatif{ Un litt�eral est une formule atomique ou la n�egation d'une formule atomique.{ Un litt�eral positif est un atome.{ Un litt�eral n�egatif est la n�egation d'un atome.D�e�nition A.11 Formule (bien form�ee)L'ensemble des formules (bien form�ees) de la logique du premier ordre est le plus petitensemble satisfaisant :{ toute formule atomique est une formule ;{ si F est une formule, alors :F est une formule ;{ si F;G sont des formules, alors (F ^G); (F _G); (F ! G); (F G); (F $ G) sont�egalement des formules ;{ si F est une formule et v une variable, alors 8vF et 9vF sont des formules.D�e�nition A.12 Clause, clause de Horn, clause d�e�nie, requete{ Une clause est une disjonction �nie de litt�eraux universellement quanti��es. Onnotera que si Q1; :::; Qn et T1; :::; Tm sont des atomes, alors la clause :Q1 _ ::: _:Qn _ T1 _ ::: _ Tm peut s'�ecrire T1 _ ::: _ Tm Q1 ^ ::: ^Qn.{ Une clause est dite de Horn si elle comporte au plus un litt�eral positif.{ Une clause est dite d�e�nie si c'est une clause de Horn comportant exactement unlitt�eral positif, elle est alors not�ee : T Q1 ^ ::: ^ Qn, T est la tete de la clause,l'ensmble des fQig; 1 � i � n est la queue de la clause.{ Une clause unitaire est une clause d�e�nie ne comportant aucun litt�eral n�egatif etsera not�ee : T .{ Une requete est une clause d�e�nie dont la tete est vide et peut donc etre mise sousla forme : Q1 ^ ::: ^Qn.D�e�nition A.13 ExpressionUne expression peut etre :{ un terme ;{ un litt�eral ;{ une conjonction ou une disjonction de litt�eraux.Entre autres, les clauses sont des expressions.D�e�nition A.14 Occurrence d'une variable, variable libre, variable li�ee, formule close{ Une occurrence d'une variable dans une formule est un couple constitu�e de cettevariable et d'une place e�ective, c'est-�a-dire tout endroit dans la formule o�u �gurecette variable autre qu'imm�ediatement apr�es un quanti�cateur.

202 ANNEXE A. NOTATIONS - D�EFINITIONS{ Une occurrence d'une variable v dans une formule F est une occurrence libre si ellene se trouve dans aucune sous-formule de F qui commence par une quanti�cation8v ou 9v.{ Une variable est libre dans une formule si elle a au moins une occurrence libre danscette formule. Dans le cas contraire elle est dite li�ee.{ Une formule close est une formule ne contenant aucune variable libre.D�e�nition A.15 Substitution, substitution de renommage, application d'une substitution{ Une substitution � est un ensemble �ni de la forme fx1=t1; :::; xn=tng; n � 0 o�u lesxi sont des variables distinctes et les ti sont des termes ; on dit alors que xi estsubstitu�e par ti.{ Soit E une expression et V l'ensemble des variables de E. Une substitution de renom-mage sur E est une substitution telle que les xi appartiennent �a V et les ti soientdes variables distinctes n'appartenant pas �a l'ensemble des variables de E non sub-stitu�ees.{ Soit � = fx1=t1; :::; xn=tng une substitution et E une expression. On note E� l'in-stanciation de E par �, c'est-�a-dire l'expression obtenue en rempla�cant dans E toutesles occurrences des variables xi par les termes associ�es ti.

Annexe BBases d'apprentissage utilis�eesCette annexe pr�esente les principales bases d'apprentissage sur lesquelles SIAO1 a �et�etest�e au chapitre 4. Elles ont �et�e choisies a�n de montrer la grande vari�et�e de probl�emessur lesquels ce syst�eme peut travailler avec succ�es :{ certains probl�emes sont tr�es fortement relationnels alors que d'autres sont d�e�nis �al'aide d'une repr�esentation attribut-valeur ;{ certains concepts peuvent etre caract�eris�es de mani�ere exacte alors que d'autres sontparticuli�erement bruit�es ou ous ;{ la taille des bases varie de quelques centaines �a plusieurs centaines de milliers d'in-stances ;{ les probl�emes peuvent etre de nature symbolique, num�erique, ou mixte ;{ certaines bases peuvent comporter des valeurs manquantes.B.1 La base Census-IncomeCette base a �et�e extraite par T. Lane et R. Kohavi �a partir de donn�ees de 1994 et 1995provenant du bureau du recensement am�ericain (http ://www.census.gov/ftp/pub/DES/www/welcome.html) a�n de conduire des �etudes sur l'application de techniques d'appren-tissage �a de gros volumes de donn�ees bruit�ees. La tache consiste �a caract�eriser les individusdont les revenus sont sup�erieurs �a 50 000 $ US, et en cons�equence toutes les donn�ees forte-ment corr�el�ees �a ce concept ont �et�e retir�ees de la base originale (AGI (adjusted grossincome), PEARNVAL (total person earnings), PTOTVAL (total person income),TAXINC (taxable income amount), etc.).Census-Income comprend 299 285 instances r�eparties en 199 523 instances d'apprentissageet 99 762 instances de test. Ces donn�ees occuppent environ 155 Mo. Le nombre d'instancesmultiples potentiellement con ictuelles s'�el�eve �a 46 716 dans la base d'apprentissage et20 936 dans la base de test. Chacune des instances est d�ecrite �a l'aide de 40 attributs, dont33 sont symboliques et 7 num�eriques. Les attributs symboliques (par exemple ADTIND) ont203

204 ANNEXE B. BASES D'APPRENTISSAGE UTILIS�EESjusqu'�a 52 valeurs di��erentes, alors que les attributs num�eriques peuvent en avoir plusieursmilliers. Le tableau ci-dessous r�esume les donn�ees contenues dans la base :Contenu du champ Code Contenu du champ Codeage AAGE class of worker ACLSWKRindustry code ADTIND occupation code ADTOCCeducation AHGA wage per hour AHRSPAYenrolled in edu inst last wk AHSCOL marital status AMARITLmajor industry code AMJIND major occupation code AMJOCCmace ARACE hispanic Origin AREORGNsex ASEX member of a labor union AUNMEMreason for unemployment AUNTYPE full or part time employment stat AWKSTATcapital gains CAPGAIN capital losses CAPLOSSdivdends from stocks DIVVAL federal income tax liability FEDTAXtax filer status FILESTAT region of previous residence GRINREGstate of previous residence GRINST detailed household and family stat HHDFMXdetailed household summary in household HHDREL migration code-change in msa MIGMTR1migration code-change in reg MIGMTR3 migration code-move within reg MIGMTR4live in this house 1 year ago MIGSAME migration prev res in sunbelt MIGSUNnum persons worked for employer NOEMP family members under 18 PARENTcountry of birth father PEFNTVTY country of birth mother PEMNTVTYcountry of birth self PENATVTY citizenship PRCITSHPown business or self employed SEOTR fill inc quest for veteran's admin VETQVAveterans benefits VETYN weeks worked in year WKSWORKTab. B.1: Les 40 attributs de la base census-income.B.2 La base IrisCette base, qui fait r�ef�erence dans le domaine de la reconnaissance des formes, d�ecrit150 exemples de eurs de la famille des iris �a l'aide de 4 attributs num�eriques repr�esentantla longueur et la largeur des p�etales et des s�epales. Les donn�ees ont �et�e r�ecolt�ees en 1936par R. A. Fisher [Fisher36]. Trois classes de eurs sont repr�esent�ees : Iris Setosa, IrisVersicolor et Iris Virginica. S'il est facile de caract�eriser les Iris Setosa grace �a la largeurde leurs s�epales, les classes Iris Versicolor et Iris Virginica sont plus di�ciles �a distinguercar elles ne sont pas lin�eairement s�eparables.B.3 La base MushroomsMushrooms (�egalement connue sous le nom agaricus-lepiota) d�ecrit un �echantillon de 23esp�eces de champignons �a lamelles appartenant aux familles des l�epiotes et des amanites.Les donn�ees, g�en�er�ees �a partir de [Linco�81], comprennent 8 124 instances repr�esent�ees�a l'aide de 23 attributs symboliques. 2 480 valeurs sont manquantes. Le but de l'appren-tissage consiste �a distinguer les champignons comestibles des champignons empoisonn�esou non recommand�es. Ce probl�eme fait r�ef�erence dans le cadre de l'apprentissage disjonc-tif, car il n'existe pas, dans le formalisme attribut-valeur, de r�egle unique d�eterminant laclasse d'un champignon.

B.4. La base Mutagenesis 205B.4 La base MutagenesisCette base issue de donn�ees r�eelles provient d'une recherche conjointe men�ee par A.Srinivasan et S.H. Muggleton de l'Oxford University Computing Laboratory d'une part,et R.D. King et M.J.E Sternberg du Biomolecular Modelling Laboratory de l'ImperialCancer Research Fund de Londres d'autre part, dont le but �etait d'�etudier l'applicationde m�ethodes de PLI dans le cadre de la chimie mol�eculaire [Srinivasan et al.94].Le probl�eme mutagenesis consiste �a d�eterminer parmi les mol�ecules nitro-aromatiques quel'on trouve dans les gaz d'�echappement des voitures celles dont le logarithme du degr�emutag�ene est positif (on sait que l'activit�e mutag�ene d'une mol�ecule est li�ee �a son e�etcanc�erig�ene). L'�etude porte sur 230 mol�ecules, dont 138 sont class�ees mutag�enes.Dans un premier temps, les auteurs de [Debnath et al.91] ont propos�e un mod�ele pour lelogarithme du degr�e mutag�ene obtenu par regression lin�eaire sur quatre attributs jug�espertinents et extraits des donn�ees dont ils disposaient :1. logP est le logarithme du ratio octane/eau, qui donne une mesure de l'hydropho-bicit�e ;2. "LUMO est l'�energie de la plus basse orbitale non satur�ee des compos�es de la mol�ecule(obtenu �a l'aide d'un mod�ele de m�ecanique mol�eculaire quantique) ;3. I1 est un indicateur vrai pour toutes les mol�ecules comportant trois cycles ou plus ;4. Ia est un indicateur vrai pour :\ ... �ve examples of acenthrylenes and shows that these are much lessactive than expected for some unknown reason" ( [Srinivasan et al.94] p.219, citant [Debnath et al.91] p.788).Le mod�ele est obtenu �a l'aide de 188 mol�ecules int�egrables dans la r�egression, les 42 autres�etant des points isol�es et �eloign�es inad�equats.Dans un second temps [Srinivasan et al.94] ont entrepris de d�ecrire les mol�ecules de cettebase en logique relationnelle �a l'aide du syst�eme de mod�elisation mol�eculaire QUANTA,ce qui a permi l'obtention rapide d'une description bas�ee sur les pr�edicats bond(compound,atom1, atom2, bondtype) et atm(compound, atom, element, atomtype, charge) o�u :{ compound, atom, atom1 et atom2 sont des variables permettant de lier les �el�ementsde la structure ;{ bondtype est l'un des 8 types de liens g�en�er�es automatiquement par QUANTA ;{ element correspond au symbole de l'atome correspondant dans le tableau de laclassi�cation p�eriodique ;

206 ANNEXE B. BASES D'APPRENTISSAGE UTILIS�EES{ atomtype correspond au num�ero atomique de l'atome ;{ charge correspond �a la charge �electrique.La base obtenue comporte 12 203 faits d�ecrivant les 230 mol�ecules.B.5 La base 1000-trainsCette base a �et�e cr�e�ee dans le but d'�etendre le fameux probl�eme des trains de Michalski[Michalski80]. La tache consiste �a distinguer deux concepts (les trains allant �a l'est et lestrains allant �a l'ouest ), le concept-cible �etant uniquement trains allant �a l'est . Chaquetrain est un objet compos�e de parties (les wagons) li�ees par une relation de succession.La base comporte 1000 exemples d'apprentissage et 1000 exemples de test, les concepts�etant parfaitement �equilibr�es.La repr�esentation utilis�ee dans SIAO1 met en �uvre deux symboles de pr�edicat :{ Coach(pos, n pos, shape, color, length, nwheel, load){ Next(pos, pos)Ce codage est s�emantiquement �equivalent �a celui de REGAL et G-Net.

Annexe CD�etail des r�esultats exp�erimentauxC.1 Parall�elisation de SIAO1Les tableaux ci-apr�es, dont sont extraits les graphiques du paragraphe 5.5.3, conti-ennent les r�esultats qui proviennent des ex�ecutions du programme r�eparti sur des pro-cesseurs d�edi�es de la machine IBM SP2. Ils d�etaillent donc le comportement exp�erimentalde T ratiop en fonction du type d'architecture (\RCD", acronyme de \R�epartition de ChargeDynamique" fait r�ef�erence �a l'architecture ma�tre-esclave asynchrone, alors que \RCS",acronyme de \R�epartition de Charge Statique" fait r�ef�erence �a l'architecture pipeline),du nombre p de processeurs et du type de communication (\Norm." d�enote une commu-nication sans utilisation d'aucune m�emoire tampon, et \L(i)" l'utilisation d'une liste detaille i). A partir des estimations obtenues pour T ratiop , il a �et�e possible de d�eriver desestimations pour l'e�cacit�e (not�ee Eff) et pour p:T ratiop � T ratio1 . Les donn�ees �gurantsur chaque ligne du tableau correspondent �a cinq essais ; on note E les valeurs moyenneset � les �ecarts-types.C.2 Etude de T ratiop sur la base MushroomsArchi. Com. p E(T ratiop ) �(T ratiop ) E(Eff) �(Eff) p:E(Tratiop )� E(Tratio1 )RCD Norm. 1 0.363097 0.00201095 1 0.00551486 0RCD Norm. 2 0.189208 0.00068182 0.959528 0.0034527 0.015320RCD Norm. 3 0.131698 0.00033530 0.919022 0.0023392 0.031996RCD Norm. 4 0.103006 0.00008547 0.881254 0.0007308 0.048926RCD L(1) 1 0.365462 0.00072737 1 0.0019887 0RCD L(1) 2 0.190203 0.00061168 0.960724 0.0030886 0.014944RCD L(1) 3 0.131952 0.00027620 0.923227 0.0019296 0.030392RCD L(1) 4 0.103485 0.00010841 0.882889 0.0009259 0.048477207

208 ANNEXE C. D�ETAIL DES R�ESULTATS EXP�ERIMENTAUXArchi. Com. p E(T ratiop ) �(T ratiop ) E(Eff) �(Eff) p:E(Tratiop )� E(Tratio1 )RCD L(2) 1 0.366237 0.00185994 1 0.0050636 0RCD L(2) 2 0.192010 0.00324938 0.953966 0.0160544 0.017782RCD L(2) 3 0.131220 0.00049326 0.930288 0.0034790 0.027423RCD L(2) 4 0.102776 0.00011465 0.890865 0.0009939 0.044866RCD L(3) 1 0.367054 0.00113307 1 0.0030866 0RCD L(3) 2 0.189446 0.00070741 0.968768 0.0036121 0.011838RCD L(3) 3 0.131185 0.00032556 0.932668 0.0023064 0.026501RCD L(3) 4 0.103392 0.00054071 0.887557 0.0046471 0.046512Archi. Com. p E(T ratiop ) �(T ratiop ) E(Eff) �(Eff) p:E(Tratiop )� E(Tratio1 )RCS Norm. 1 0.3507960 0.00243458 1 0.0069406 0RCS Norm. 2 0.1910900 0.00014345 0.917882 0.0006892 0.0313839RCS Norm. 3 0.1385230 0.00035440 0.844140 0.0021615 0.0647731RCS Norm. 4 0.1081100 0.00026616 0.811205 0.0019965 0.0816446RCS L(1) 1 0.3486020 0.00099018 1 0.0028351 0RCS L(1) 2 0.1895110 0.00050533 0.919746 0.0024529 0.0304205RCS L(1) 3 0.1334410 0.00034971 0.870809 0.0022779 0.0517202RCS L(1) 4 0.1045690 0.00023443 0.833433 0.0018693 0.0696726Archi. Com. p E(T ratiop ) �(T ratiop ) E(Eff) �(Eff) p:E(Tratiop )� E(Tratio1 )RCS L(2) 1 0.3502370 0.00135740 1 0.0038696 0RCS L(2) 2 0.1837590 0.00022265 0.952982 0.0011537 0.0172803RCS L(2) 3 0.1292810 0.00029074 0.903044 0.0020302 0.0376054RCS L(2) 4 0.1011530 0.00007348 0.865611 0.0006287 0.0543758RCS L(3) 1 0.3499780 0.00102326 1 0.0029204 0RCS L(3) 2 0.1841050 0.00072569 0.950501 0.0037247 0.0182313RCS L(3) 3 0.1295010 0.00034476 0.900847 0.0023918 0.0385235RCS L(3) 4 0.1032150 0.00246166 0.848159 0.0195525 0.0628813C.3 Etude de TCom sur la base MushroomsLe tableau ci-dessous fournit pour chaque type d'architecture : le coe�cient de corr�elationr calcul�e �a partir des di��erentes valeurs de TCom calcul�ees plus haut ( TCom(n; p) =p:Tp(n) � T1(n) ), la probabilit�e � que cette valeur de r soit d�epass�ee en valeur ab-solue pour deux variables al�eatoires ind�ependantes, ainsi que l'�equation � de la droite der�egression obtenue.Archi. Com. r � �RCD Norm. 0.999735 � � 10�2 TCom = 0:0163454 p � 0:016803RCD L(1) 0.998961 � � 10�2 TCom = 0:0160879 p � 0:0167665RCD L(2) 0.993933 � � 10�2 TCom = 0:0144239 p � 0:013542RCD L(3) 0.992919 � � 10�2 TCom = 0:0154199 p � 0:017337RCS Norm. 0.991108 � � 10�2 TCom = 0:0278323 p � 0:0251303RCS L(1) 0.992446 � � 10�2 TCom = 0:0230317 p � 0:019626RCS L(2) 0.999334 � � 10�2 TCom = 0:0183452 p � 0:0185477RCS L(3) 0.997812 � � 10�2 TCom = 0:0208936 p � 0:022325

C.4. Etude de T ratiop sur la base Iris 209C.4 Etude de T ratiop sur la base IrisArchi. Com. p E(T ratiop ) �(T ratiop ) E(Eff) �(Eff) p:E(Tratiop )� E(Tratio1 )RCD Norm. 1 0.0178160 0.00015164 1 0.0084945 0RCD Norm. 2 0.0114988 0.00026217 0.775095 0.0176325 0.00518160RCD Norm. 3 0.0090883 0.00011115 0.653538 0.0080934 0.00944896RCD Norm. 4 0.0085565 0.00027230 0.521067 0.0165671 0.01641000RCD Norm. 5 0.0086933 0.00016213 0.410018 0.0076883 0.02565095RCD L(1) 1 0.0168298 0.00034286 1 0.0200593 0RCD L(1) 2 0.0103092 0.00013362 0.816387 0.0106519 0.00378860RCD L(1) 3 0.0080433 0.00011496 0.697602 0.0100120 0.00730037RCD L(1) 4 0.0068722 0.00012439 0.612437 0.0110522 0.01066124RCD L(1) 5 0.0064373 0.00023442 0.523581 0.0192572 0.01535695Archi. Com. p E(T ratiop ) �(T ratiop ) E(Eff) �(Eff) p:E(Tratiop )� E(Tratio1 )RCD L(2) 1 0.0166946 0.00022074 1 0.0132025 0RCD L(2) 2 0.0097839 0.00016595 0.853410 0.0146600 0.00287332RCD L(2) 3 0.0075666 0.00029314 0.736534 0.0281995 0.00600547RCD L(2) 4 0.0067959 0.00016023 0.614476 0.0143032 0.01048916RCD L(2) 5 0.0065874 0.00595656 0.506931 0.0059565 0.01624260RCD L(3) 1 0.0168944 0.00026722 1 0.0160129 0RCD L(3) 2 0.0096817 0.00010739 0.872591 0.0096505 0.00246916RCD L(3) 3 0.0077640 0.00027975 0.726247 0.0256306 0.00639781RCD L(3) 4 0.0068169 0.00013658 0.619824 0.0125552 0.01037344RCD L(3) 5 0.0071408 0.00021935 0.473624 0.0144765 0.01880960Archi. Com. p E(T ratiop ) �(T ratiop ) E(Eff) �(Eff) p:E(Tratiop )� E(Tratio1 )RCS Norm. 1 0.0198672 0.00007902 1 0.0039718 0RCS Norm. 2 0.0153950 0.00002710 0.645249 0.0011330 0.01092280RCS Norm. 3 0.0161954 0.00033298 0.409075 0.0081835 0.02871900RCS Norm. 4 0.0148133 0.00101485 0.336726 0.0209228 0.03938600RCS Norm. 5 0.0162968 0.00068873 0.244249 0.0102168 0.06161680RCS L(1) 1 0.0181054 0.00002710 1 0.0014936 0RCS L(1) 2 0.0126440 0.00008131 0.715998 0.0046013 0.0071826RCS L(1) 3 0.0121727 0.00005224 0.495803 0.0021143 0.0184127RCS L(1) 4 0.0109674 0.00006762 0.412724 0.0025406 0.0257642RCS L(1) 5 0.0099197 0.00005347 0.365047 0.0019769 0.0314935

210 ANNEXE C. D�ETAIL DES R�ESULTATS EXP�ERIMENTAUXArchi. Com. p E(T ratiop ) �(T ratiop ) E(Eff) �(Eff) p:E(Tratiop )� E(Tratio1 )RCS L(2) 1 0.0181553 0.00017989 1 0.0097963 0RCS L(2) 2 0.0123599 0.00003248 0.734447 0.0019282 0.0065645RCS L(2) 3 0.0118997 0.00003231 0.508567 0.0013795 0.0175438RCS L(2) 4 0.0110592 0.00003180 0.410415 0.0011785 0.0260815RCS L(2) 5 0.0098239 0.00008069 0.369638 0.0030214 0.0309644RCS L(3) 1 0.0179156 0.00003231 1 0.0018050 0RCS L(3) 2 0.0121504 0.00006463 0.737264 0.0039301 0.0063852RCS L(3) 3 0.0120661 0.00010619 0.494968 0.0043889 0.0182827RCS L(3) 4 0.0112421 0.00011964 0.398451 0.0042238 0.0270528RCS L(3) 5 0.0099890 0.00005126 0.358715 0.0018379 0.0320296C.5 Etude de TCom sur la base IrisArchi. Com. r � �RCD Norm. 0.987943 � � 10�2 TCom = 0:00625303 p � 0:00742079RCD L(1) 0.998292 � � 10�2 TCom = 0:00375865 p � 0:00385453RCD L(2) 0.988587 � � 10�2 TCom = 0:0040101 p � 0:0049082RCD L(3) 0.97305 � � 10�2 TCom = 0:00455235 p � 0:00604704RCS Norm. 0.992565 � � 10�2 TCom = 0:0151697 p � 0:0173801RCS L(1) 0.994053 � � 10�2 TCom = 0:00815686 p � 0:00789998RCS L(2) 0.993009 � � 10�2 TCom = 0:00814458 p � 0:0082029RCS L(3) 0.991683 � � 10�2 TCom = 0:00847268 p � 0:00866798

Annexe DInterface graphique de SIAO1L'algorithme SIAO1 pr�esent�e dans cette th�ese a �et�e implant�e en C++ et pourvu d'uneinterface graphique appel�ee EvoMiner. La premi�ere section de cette annexe d�ecrit commentutiliser cette interface pour e�ectuer un apprentissage, et �eventuellement modi�er lesparam�etres par d�efaut de l'algorithme. La seconde section d�ecrit un certain nombre defonctionnalit�es graphiques o�ertes par EvoMiner. Cette extension permet �a l'utilisateurd'obtenir visuellement un grand nombre d'informations sur la base d'apprentissage encours d'exploitation.D.1 Exemple d'apprentissage sur la base des Iris
Fig. D.1: Menu de lancement de SIAO1.211

212 ANNEXE D. INTERFACE GRAPHIQUE DE SIAO1Le menu de lancement (�gure D.1) permet �a l'utilisateur de sp�eci�er les donn�ees fourniesen entr�ee et les param�etres de SIAO1 :{ Un �chier (dont l'extension est .t) d�ecrit la grammaire du langage (les pr�edicatset leurs arit�es, les di��erents types des constantes, les relations de g�en�eralit�e entrepr�edicats et entre constantes, etc.).{ Un �chier (dont l'extension est .b) contient la description de toutes les instances.Di��erents mots-cl�e permettent soit de d�elimiter une base d'apprentissage et une basede test �g�ees, soit d'extraire une base de test (par tirage al�eatoire respectant ou nonles pond�erations des di��erentes classes), soit de sp�eci�er un sch�ema de validationsp�eci�que (par exemple la k-validation crois�ee).{ Un �chier (dont l'extension est .a) n'est utilis�e que lors d'une session distribu�ee etfournit les noms des machines exploit�ees. Le reste de l'architecture (ma�tre-esclaveou pipeline, taille { �eventuellement nulle { de la m�emoire tampon) est par contre�x�e d�es la compilation de SIAO1.{ Les param�etres sp�eci�ques �a l'algorithme (nombre de noyaux par classe-cible, taillemaximum des populations, etc.) peuvent �egalement etre modif�es �a cette �etape.Une fois le menu de lancement valid�e, l'�editeur (dont certaines fonctionnalit�es serontd�ecrites dans la section suivante) appara�t. Entrer Quit (ou Q) dans cet �editeur permet delancer imm�ediatement l'algorithme d'apprentissage. Au cours de l'ex�ecution, une fenetrerend compte de l'�etat d'avancement de l'algorithme (�evolution des noyaux, couverture desconcepts, taux d'utilisation des op�erateurs d'�evolution, etc.).
Fig. D.2: Fenetre d'�etat de SIAO1.

D.1. Exemple d'apprentissage sur la base des Iris 213Lorsque l'apprentissage est termin�e, l'�editeur est mis �a jour avec les r�esultats obtenus,qui peuvent etre facilement extraits par copier-coller pour utilisation �a l'ext�erieur ou dansl'�editeur lui-meme. Ces derniers comprennent :{ Le r�esultat de l'apprentissage : les r�egles, ainsi que leur qualit�e, leur coh�erence etleur compl�etude.{ Des mesures de la qualit�e du r�esultat de l'apprentissage : la pr�ecision et les matricesde confusion sur les bases d'apprentissage et de test sont �egalement fournies.{ Des traces concernant l'apprentissage : il est par exemple possible de tracer leprocessus d'�elagage des r�egles. Pour des raisons �evidentes de performance, les tracesd�esir�ees doivent etre sp�eci��ees lors de la compilation du code de SIAO1.{ Des mesures de performance : ces derni�eres comprennent la dur�ee d'ex�ecution del'algorithme et di��erents indices de performance comme par exemple le nombred'appariements par seconde ou encore la performance des di��erents �ltres (�ltresimple, �ltre tabou). Dans le cas de la version parall�ele de l'algorithme, des mesuresglobales et d�etaill�ees (machine par machine) sont �egalement fournies.
Fig. D.3: Le r�esultat de l'apprentissage �gure dans l'�editeur.

214 ANNEXE D. INTERFACE GRAPHIQUE DE SIAO1D.2 Les fonctionnalit�es de visualisation des donn�eesL'�editeur d'EvoMiner a �et�e enrichi d'une interface de visualisation des donn�ees per-mettant �a l'utilisateur de prendre connaissance de nombreuses informations concernant :{ la base en cours de traitement ;{ le fonctionnement de SIAO1.En e�et, bien que le cycle d'extraction de la connaissance �a partir des donn�ees dans sonensemble (tel qu'il est d�ecrit �gure 1.2) soit un sujet tr�es { trop { vaste, il est rapide-ment apparu que le d�eveloppement d'un environnement autour de l'algorithme faciliteconsid�erablement son utilisation dans des contextes tr�es vari�es. Les deux principales fonc-tions exploratoires sont :{ ShowNumericType (ou SNT) a�che les principales caract�eristiques {relev�ees sur labase d'apprentissage{ d'un type num�erique. La fenetre Statistics montre surl'ensemble de la base d'apprentissage ou pour chaque classe-cible les bornes min-imum et maximum des valeurs, leur moyenne et leur �ecart-type, alors que la fenetreStats View fournit cette information de mani�ere graphique et intuitive.
Fig. D.4: Fenetre de description d'un type num�erique.La �gure D.4 montre que les fonctionnalit�es exploratoires comportent �egalementdes m�ecanismes interactifs : dans le cas pr�esent l'utilisateur peut g�en�erer �a l'aide dela souris une plage de valeurs (dans la partie inf�erieure de la fenetre Stats View)et obtenir des informations sur la r�epartition des classes dans cet ensemble. Cette

D.2. Les fonctionnalit�es de visualisation des donn�ees 215partie de l'interface permet �egalement d'observer la distibution absolue ou relativedes valeurs (l'utilisateur �xe le nombre de segments d�esir�es), ou encore d'obtenirune courbe ROC montrant le comportement d'un classeur primitif n'exploitant quele type num�erique s�electionn�e pour classer les instances de la base.{ ShowSymbolicType (ou SST) a�che les principales caract�eristiques {relev�ees sur labase d'apprentissage{ d'un type symbolique :
Fig. D.5: Fenetre de description d'un type num�erique.On mentionnera �egalement quelques autres commandes utiles :{ ShowNumericGraph (ou SNG) permet de visualiser une relation possible entre deuxtypes num�eriques.{ HyperplaneAnalysis (ou HA) fournit des informations sur les attributs num�eriquesintroduits lors de la phase de compl�etion num�erique par la m�ethode d'analyse dis-criminante.{ FitnessStatistics (ou FS) permet d'analyser la qualit�es des individus au cours del'ex�ecution, entre autres en fonction des op�erateurs g�en�etiques qui les ont g�en�er�es.L'analyse des graphiques produits par cette commande a motiv�e l'auto-adaptationdes taux de mutation et de croisement.{ FilterHitMissStats (ou FHMS) permet de visualiser et analyser le comportementdes �ltres (simple et tabou).L'utilisateur se rapportera �a l'aide de l'�editeur (Help ou H) pour obtenir une liste exhaus-tive des commandes (test d'hypoth�eses sur la base d'apprentissage (TestDefinition ouTD), etc.).

216 ANNEXE D. INTERFACE GRAPHIQUE DE SIAO1

Bibliographie[Adriaans et al.96] Adriaans (P.) et Zantinge (D.). { Data Mining. { Addison-Wesley,1996.[Aler et al.98] Aler (R.), Borrajo (D.) et Isasi (P.). { Genetic programming anddeductive-inductive learning : a multi-strategy approach. In : Pro-ceedings of the �fteenth international conference on machine learn-ing ICML'98, pp. 10{18.[Alphonse et al.99] Alphonse (�E.) et Rouveirol (C.). { Selective propositionalization forrelational learning. In : Third European Conference on Principlesof Data Mining and Knowledge Discovery PKDD'99, Prague, CzechRepublic, J.M. Zytkow et J. Rauch (Eds), LNAI 1704, pp. 271{276.[Amdahl67] Amdahl (G.M.). { Validity of the single-processor approach toachieving large scale computing capabilities. In : AFIPS Confer-ence Proceedings. pp. 483{485. { AFIPS Press, Reston, VA.[Angelano et al.97] Angelano (C.), Giordana (A.), Lo Bello (G.) et Saitta (L.). { A net-work genetic algorithm for concept learning. In : Proceedings of theseventh International Conference on Genetic Algorithms ICGA'97,pp. 434{441.[Angelano et al.98] Angelano (C.), Giordana (A.), Lo Bello (G.) et Saitta (L.). { Anexperimental evaluation of coevolutive concept learning. In : Pro-ceedings of the �fteenth international conference on machine learn-ing ICML'98, pp. 19{27.[Antonisse89] Antonisse (J.). { A new interpretation of schema notation thatoverturns the binary encoding constraint. In : Proceedings of thethird International Conference on Genetic Algorithms ICGA'89,J.D. Scha�er (Ed), Morgan Kaufmann, pp. 86{91.[Atmar92] Atmar (W.). { On the rules and nature of simulated evolutionaryprogramming. In : Proceedings of the �rst Annual Conference onEvolutionary Programming EP'92, D.B. Fogel et W. Atmar (Eds),Evolutionary Programming Society, pp. 17{26.[Augier et al.95] Augier (S.), Venturini (G.) et Kodrato� (Y.). { Learning �rst or-der logic rules with a genetic algorithm. In : KDD-95 Proceedingsof The First International Conference on Knowledge Discovery &Data Mining, Montr�eal (Canada), U.M. Fayyad and R. Uthurusamy(Eds), pp. 21{26. 217

218 BIBLIOGRAPHIE[Augier et al.96] Augier (S.) et Venturini (G.). { SIAO1, a �rst order logic ma-chine learning system using genetic algorithms. In : ICML'96 13thInternational Conference on Machine Learning, Bari (Italy), Pro-ceedings of the pre-conference workshop on Evolutionary Algorithmsand Machine Learning, pp. 9{16.[Augier99] Augier (S.). { Changement d'�echelle d'un algorithme d'apprentis-sage automatique. In : Actes de la Conf�erence d'ApprentissageCAP'99, Plate-forme AFIA'99, Palaiseau, Ecole Polytechnique, M.Sebag (Ed), 1999, pp. 235{242.[Back et al.96] B�ack (T.) et Schwefel (H.-P.). { Evolutionary computation : Anoverview. In : Proceedings of the third IEEE Conference on Evo-lutionary Computation ICEC'96, IEEE Press, Piscataway NJ, pp.20{29.[Back96] B�ack (T.). { Evolutionary Algorithms in Theory and Practice. {Oxford University Press, 1996.[Badea et al.99] Badea (L.) et Stanciu (M.). { Re�nement operators can be (weakly)perfect. In : Inductive Logic Programming, Ninth InternationalWorkshop ILP'99, LNAI 1634, pp. 21{32.[Baker87] Baker (J.E.). { Reducing bias and ine�ciency in the selection algo-rithm. In : Genetic Algorithms and their Applications : Proceedingsof the second International Conference ICGA'87, J.J. Grefenstette(Ed), Lawrence Erlbaum Associates, Hillsdale, NJ, pp. 14{21.[Bauer et al.99] Bauer (E.) et Kohavi (R.). { An empirical comparison of votingclassi�cation algorithms : Bagging, boosting and variants. MachineLearning, vol. 36, 1999, pp. 105{139.[Baxter77] Baxter (L.D.). { The NP-completeness of subsumption. In :manuscrit souvent cit�e mais non publi�e.[Belding95] Belding (T.C.). { The distributed genetic algorithm revisited. In :Proceedings of the sixth International Conference on Genetic Al-gorithms ICGA'95, L.J. Eshelman (Ed), Morgan Kaufmann, pp.114{121.[Blockeel et al.98] Blockeel (H.) et De Raedt (L.). { Top-down induction of �rst-orderlogical decision trees. Arti�cial Intelligence, vol. 101 (1-2), 1998, pp.285{297.[Blockeel et al.99] Blockeel (H.), De Raedt (L.), Jacobs (N.) et Demoen (B.). { Scalingup inductive logic programming by learning from interpretations.Data Mining and Knowledge Discovery, vol. 3 (1), 1999, pp. 59{93.[Blumer et al.87] Blumer (A.), Ehrenfeucht (A.), Haussler (D.) et Warmuth (M.K.).{ Occam's razor. Information Processing Letters, no24, 1987, pp.377{380. { �Edit�e �egalement dans Readings in Machine Learning,J.W. Shavlik et T.G. Dietterich (Eds), Morgan Kaufmann, 1990.

BIBLIOGRAPHIE 219[Breimann96] Breimann (L.). { Bagging predictors. Machine Learning, vol. 24,1996, pp. 123{140.[Brezellec99] Br�ezellec (P.). { Sondage et apprentissage. In : Actes dela Conf�erence d'Apprentissage CAP'99, Plate-forme AFIA'99,Palaiseau, Ecole Polytechnique, M. Sebag (Ed), 1999, pp. 63{68.[Brunet93] Brunet (T.). { Le probl�eme de la r�esistance aux valeurs inconnuesdans l'induction : une foret de branches. In : Actes des huiti�emesjourn�ees francophones sur l'apprentissage JFA'93, Saint Rapha�el. {Les pages du recueil ne sont pas num�erot�ees.[Brunet94] Brunet (T.). { Pr�esentation de StatLog (projet ESPRIT 5170). In :Actes des 4�emes Journ�ees sur l'Induction Symbolique / Num�erique,pp. 145{148.[BT et al.96] Brunie-Taton (A.) et Cornu�ejols (A.). { Classi�cation en program-mation g�en�etique. In : 11�emes Journ�ees Fran�caises d'Apprentis-sage (JFA'96), S�ete, France, pp. 303{316.[Cerf94] Cerf (R.). { Une th�eorie asymptotique des algorithmes g�en�etiques.{ PhD thesis, Universit�e de Montpellier II, 1994.[Clark et al.89] Clark (P.) et Niblett (T.). { The CN2 induction algorithm.MachineLearning, vol. 3 (4), 1989, pp. 261{283.[Clark et al.91] Clark (P.) et Boswell (R.). { Rule induction with CN2 : Some re-cent improvements. In : Proceedings of the �fth European WorkingSession on Learning EWSL'91, Y. Kodrato� (Ed), Springer-Verlag,LNAI 482, pp. 151{163.[Cochran77] Cochran (W.G.). { Sampling Techniques. { Wiley, 1977.[Collins et al.91] Collins (R.J.) et Je�erson (D.R.). { Selection in massively parallelgenetic algorithms. In : Proceedings of the fourth InternationalConference on Genetic Algorithms ICGA'91, R.K. Belew et L.B.Booker (Eds), Morgan Kaufmann, pp. 249{256.[CP et al.97] Cant�u-Paz (E.) et Goldberg (D.E.). { Predicting speedups of ideal-ized bounding cases of parallel genetic algorithms. In : Proceedingsof the seventh International Conference on Genetic Algorithms IC-GA'97, pp. 113{120.[CP97a] Cant�u-Paz (E.). { Designing E�cient Master-Slave Parallel Ge-netic Algorithms. { Technical Report 97004, Nashville, TN, IllinoisGenetic Algorithms Laboratory, May 1997. IlliGAL Report.[CP97b] Cant�u-Paz (E.). { A Survey of Parallel Genetic Algorithms. { Tech-nical Report 97003, Nashville, TN, Illinois Genetic Algorithms Lab-oratory, May 1997. IlliGAL Report.[CP98] Cant�u-Paz (E.). { Designing Scalable Multi-Population Parallel Ge-netic Algorithms. { Technical Report 98009, Nashville, TN, IllinoisGenetic Algorithms Laboratory, May 1998. IlliGAL Report.

220 BIBLIOGRAPHIE[Cramer85] Cramer (N.L.). { A representation for the adaptive generation ofsimple sequential programs. In : Proceedings of the �rst Interna-tional Conference on Genetic Algorithms and their applications IC-GA'85, J.J. Grefenstette (Ed), Lawrence Erlbaum Associates Pub-lishers, pp. 183{187.[Davis89] Davis (L.). { Adapting operator probabilities in genetic algorithms.In : Proceedings of the third International Conference on GeneticAlgorithms ICGA'89, J.D. Scha�er (Ed), Morgan Kaufmann, pp.61{69.[De jong et al.91] De Jong (K.A.) et Spears (W.M.). { Learning concept classi�ca-tion rules using genetic algorithms. In : Proceedings of the TwelfthInternational Joint Conference on Arti�cial Intelligence IJCAI'91,pp. 651{656.[De jong et al.93] De Jong (K.A.), Spears (W.M.) et Gordon (D.F.). { Using geneticalgorithms for concept learning. Machine Learning, vol. 13, 1993,pp. 161{188.[De jong et al.95] De Jong (K.A.) et Sarama (J.). { On decentralizing selection algo-rithms. In : Proceedings of the sixth International Conference onGenetic Algorithms ICGA'95, L.J. Eshelman (Ed), Morgan Kauf-mann, pp. 17{23.[De jong90] De Jong (K.A.). { Machine Learning - An Arti�cial Intelligence Ap-proach, Volume III, chap. Genetic-Algorithm-Based Learning, pp.611{638. { Morgan Kaufmann, 1990.[De jong92] De Jong (K.A.). { Genetic algoritms are NOT function optimizers.In : Foundations of Genetic Algorithms 2 FOGA'92, L.D. Whitley(Ed), Morgan Kaufmann, pp. 5{18.[De raedt97] De Raedt (L.). { Logical settings for concept-learning. Arti�cialIntelligence, vol. 95, 1997, pp. 187{201.[Debnath et al.91] Debnath (A.K.), de Compadre (R.L. Lopez), Debnath (G.), Schus-terman (A.J.) et Hansch (C.). { Structure-activity relationship ofmutagenic aromatic and heteroaromatic nitro compounds. Correla-tion with molecular orbital energies and hydrophobicity. Journal ofMedicinal Chemistry, vol. 34(2), 1991, pp. 786{797.[Diday et al.00] Diday (E.), Kodrato� (Y.), Brito (B.) et Moulet (M.). { Inductionsymbolique-num�erique �a partir de donn�ees. { C�epadu�es-�Edtions,2000.[Dietterich97] Dietterich (T.G.). { Machine learning research - four current direc-tions. AI Magazine, vol. 18 (4), Winter 1997, pp. 97{136.[Doorly95] Doorly (D.). { Genetic Algorithms in Engeneering and ComputerScience, chap. Parallel Genetic Algorithms for Optimization inCFD, pp. 251{270. { Wiley, 1995.

BIBLIOGRAPHIE 221[Ehrenburg96] Ehrenburg (H.). { Improved directed acyclic graph evaluation andthe combine operator in genetic programming. In : Genetic Pro-gramming 1996 : Proceedings of the �rst annual conference GP'96,J.R. Koza, D.E. Goldberg, D.B. Fogel et R.L. Riolo (Eds), MITPress, pp. 285{291.[Fisher36] Fisher (R. A.). { The use of multiple measurements in taxonomicproblems. Annual Eugenics, no7, Part II, 1936, pp. 179{188.[Fleury96] Fleury (L.). { Mesure de la Qualit�e d'une R�egle, Elimination desRedondances, Proposition d'Algorithmes. { PhD thesis, Universit�ede Nantes, Ecole Doctorale, 1996. No : 210.[Flynn66] Flynn (M.J.). { Very high speed computing systems. ProceedingsIEEE, vol. 54 (12), 1966, pp. 1901{1909.[Frawley et al.91] Frawley (W.J.), Piatetsky-Shapiro (G.) et Matheus (C.J.). {Knowledge Discovery in Databases, chap. Knowledge Discovery inDatabases : An Overview. { AAAI Press, 1991.[Freund et al.96] Freund (Y.) et Schapire (R.E.). { Experiments with a new boostingalgorithm. In : Proceedings of the thirteenth International Confer-ence on Machine Learning ICML'96, Bari (Italy), July 3-6th, pp.148{156.[Geist et al.94] Geist (A.), Beguelin (A.), Dongarra (J.), Jiang (W.), Manchek (R.)et Sunderam (V.). { PVM : Parallel Virtual Machine - A User'sGuide and Tutorial for Networked Parallel Computing. { The MITPress, 1994.[Gengler et al.96] Gengler (M.), Ub�eda (S.) et Desprez (F.). { Initiation au Par-all�elisme. Concepts, Architectures et Algorithmes. { Masson, 1996.[Giordana et al.92] Giordana (A.) et Sale (C.). { Genetic algorithms for learning rela-tions. In : ICML'92, pp. 169{178.[Giordana et al.97] Giordana (A.), Neri (F.), Saitta (L.) et Botta (M.). { Integratingmultiple learning strategies in �rst order logics. Machine Learning,vol. 27 (3), 1997, pp. 209{240.[Glover et al.93] Glover (F.), Taillard (E.) et de Werra (D.). { A user's guide to tabusearch. Annals of Operations Research, vol. 41, 1993, pp. 3{28.[Goldberg et al.87] Goldberg (D.E.) et Richardson (J.). { Genetic algorithms withsharing for multimodal function optimization. In : Genetic Algo-rithms and their Applications : Proceedings of the second Interna-tional Conference ICGA'87, J.J. Grefenstette (Ed), Lawrence Erl-baum Associates, Hillsdale, NJ, pp. 41{49.[Goldberg87] Goldberg (D.E.). { Simple genetic algorithms and the minimal, de-ceptive problem. In : Genetig Algorithms and Simulated Annealing,�ed. par Davis (L.). pp. 74{88. { Morgan Kaufmann.[Goldberg89] Goldberg (D.E.). { Genetic Algorithms in Search, Optimization andMachine Learning. { Addison-Wesley, 1989.

222 BIBLIOGRAPHIE[Gottlob et al.93] Gottlob (G.) et Ferm�uller (C.G.). { Removing redundancy from aclause. Arti�cial Intelligence, vol. 61, 1993, pp. 263{289.[Gottlob87] Gottlob (G.). { Subsumption and implication. Information process-ing letters, vol. 24(2), 1987, pp. 109{111.[GR et al.92] Germain-Renaud (C.) et Sansonnet (J.P.). { Les ordinateurs Mas-sivement Parall�eles. { Armand Collin, Paris, 1992.[Greene et al.92] Greene (D.P.) et Smith (S.F.). { COGIN : Symbolic induction withgenetic algorithms. In : Proceedings of the tenth national conferenceon arti�cial intelligence AAAI'92, pp. 111{116.[Greene et al.93] Greene (D.P.) et Smith (S.F.). { Competition-based induction ofdecision models from examples. Machine Learning, vol. 13, 1993,pp. 229{257.[Grefenstette81] Grefenstette (J.J.). { Parallel Adaptive Algorithms for Function Op-timization. { Technical Report CS-81-19, Nashville, TN, VanderbiltUniversity, Computer Science Department, 1981.[Grefenstette95] Grefenstette (J.). { Virtual Genetic Algorithms : First Results. {Technical Report AIC-95-013, NCARAI, 1995. Internal Report.[Gustafson88] Gustafson (J.L.). { Reevaluating Amdahl's Law. Communicationsof the ACM, vol. 31 (5), 1988, pp. 532{533.[Haussler88] Haussler (D.). { Quantifying inductive bias : AI learning algorithmsand valiant's learning framework. Arti�cial Intelligence, vol. 36 (2),1988, pp. 177{221.[Haynes et al.96] Haynes (T.D.), Schoenefeld (D.A.) et Wainwright (R.L.). { Ad-vances in Genetic Programming 2, K.E. Kinnear Jr and P.J. Ange-line (Eds), 1996. Chapter 18 : Type Inheritance in Strongly TypedGenetic Programming.[Haynes96] Haynes (T.). { Duplication of coding segments in genetic program-ming. In : Proceedings of the thirteenth national conference onarti�cial intelligence AAAI'96, AAAI Press/The MIT Press, pp.344{349.[Hekanaho97] Hekanaho (J.). { GA-based rule enhancement in concept-learning.In : Proceedings of the Third International Conference on Knowl-edge Discovery and Data Mining, KDD'97, �ed. par Heckerman (D.),Mannila (H.) et Uthurusamy (R.), pp. 183{186.[Hekanaho98] Hekanaho (J.). { DOGMA : A GA-based relational learner.In : Inductive Logic Programming, Eighth International ConferenceILP'98, D. Page (Ed), Madison, Wisconsin, USA, LNAI 1446.[Holland75] Holland (J.H.). { Adaptation in Natural and Arti�cial Systems. {Ann Arbor, University of Michigan Press, 1975.[Holland86] Holland (J.H.). { Machine Learning - An Arti�cial IntelligenceApproach, Volume II, chap. Escaping Brittleness : the Possibilities

BIBLIOGRAPHIE 223of General-Purpose Learning Algorithms Applied to Parallel Rule-Based Systems, pp. 593{623. { Morgan Kaufmann, 1986.[Holmes et al.00] Holmes (J.H.), Lanzi (P.L.), Stolzmann (W.) et Wilson (S.W.). {Learning Classi�er Systems : New Models, Successful Applications.{ Technical Report 2000-44, Politecnico di Milano, 2000.[Horn et al.94] Horn (J.), Goldberg (D.E.) et Deb (K.). { Long path problems. In :Proceedings of the third Conference on Parallel Problems Solvingfrom Nature PPSN'94, Y. Davidor, H.-P. Schwefel et R. Manner(Eds), Springer Verlag, LNCS 866, pp. 149{158.[Janikow93] Janikow (C.Z.). { A knowledge-intensive genetic algorithm for su-pervised learning. Machine Learning, vol. 13, 1993, pp. 189{228.[Jaynes96] Jaynes (E.T.). { Probability Theory : The Logic of Science. { 1996.Fragmentary Edition of March 1996.[Jones95] Jones (T.). { Crossover, macromutation, and population-basedsearch. In : Proceedings of the sixth International Conference onGenetic Algorithms ICGA'95, L.J. Eshelman (Ed), Morgan Kauf-mann, pp. 73{80.[Kaufman et al.99] Kaufman (K.A.) et Michalski (R.S.). { Learning in an inconsistentworld : rule selection in AQ18. { Technical Report MLI 99-2, P99-2, George Mason University, Fairfax, VA 22030-4444, 1999. MachineLearning and Inference Laboratory.[Kietz et al.94] Kietz (J-U.) et L�ubbe (L.). { An e�cient subsumption algorithm forinductive logic programming. In : Proceedings of the Eleventh In-ternational Conference on Machine Learning ML'94, W.W. Cohenet H. Hirsh (Eds), 1994, pp. 130{138.[Kim et al.92] Kim (B.M.) et Cho (J.W.). { A new subsumption method in theconnection graph proof procedure. Theoretical Computer Science,vol. 103, 1992, pp. 283{309.[Kodrato� et al.91] Kodrato� (Y.) et Diday (E.). { Induction symbolique et num�erique.{ C�epadu�es-�Edtions, 1991.[Kodrato�94] Kodrato� (Y.). { Guest Editor's Introduction ( The Comprehensi-bility Manifesto ). AI Communications, vol. 7 (2), 1994, pp. 83{85.[Kodrato�95] Kodrato� (Y.). { Algorithmic Learning Theory, chap. Technical andScienti�c Issues of KDD (or : Is KDD a Science ?). { Springer-Verlag,1995, Lecture Notes in Arti�cial Intelligence, volume 997.[Kodrato�98] Kodrato� (Y.). { IBM Data-Mining Course (Li�ege). { 1998.[Kodrato�00] Kodrato� (Y.). { chap. Applications de l'apprentissage automatiqueet de la fouille de donn�ees. { 2000. �a para�tre.[Kohavi95] Kohavi (R.). { A study of cross-validation and bootstrap for ac-curacy estimation and model selection. In : Proceedings of theFourteenth International Joint Conference on Arti�cial Intelligence(IJCAI'95), Montr�eal, Qu�ebec, Canada, pp. 1137{1143.

224 BIBLIOGRAPHIE[Koza89] Koza (J.R.). { Hierarchical genetic algorithms operating on pop-ulations of computer programs. In : Proceedings of the EleventhInternational Joint Conference on Arti�cial Intelligence IJCAI'89,N.S. Sridharan (Ed), Morgan Kaufmann, pp. 768{774.[Koza92] Koza (J.R.). { Genetic Programming. { MIT Press, 1992.[Koza94] Koza (J.R.). { Genetic Programming 2. { MIT Press, 1994.[Lavrac et al.99] Lavra�c (N.), D�zeroski (S.) et Numao (M.). { Inductive logic pro-gramming for relational knowledge discovery. New Generation Com-puting, vol. 17 (1), 1999, pp. 3{23.[Linco�81] Linco� (G.H.). { The Audubon Society Field Guide to North Amer-ican Mushrooms. { New York : A.A. Knopf, 1981.[Lo bello98] Lo Bello (G.). { A Coevolutionary Distributed Approach to Learn-ing Classi�cation Programs (preliminary version). { PhD thesis,Dipartimento di Informatica, Universit�a di Torino, 1998.[Maloberti00] Maloberti (J.). { Apports de la Satisfaction de Contraintes �ala Programmation Logique Inductive : un nouvel algorithme de �-subsomption. { Technical report, LRI, 5 septembre 2000. Rapportde Stage de DEA.[Manderick et al.89] Manderick (B.) et Spiessens (P.). { Fine-grained parallel geneticalgorithms. In : Proceedings of the third International Conferenceon Genetic Algorithms ICGA'89, J.D. Scha�er (Ed), Morgan Kauf-mann, pp. 428{433.[Merz99] Merz (C.J.). { Using correspondance analysis to combine classi�ers.Machine Learning, vol. 36, 1999, pp. 33{58.[Michalski80] Michalski (R.). { Pattern recognition as a rule-guided inductiveinference. IEEE transactions on Pattern Analysis and Machine In-telligence, PAMI-2, 1980, pp. 349{361.[Michalski84] Michalski (R.S.). { Machine Learning : An AI Approach, Volume 1,chap. A theory and methodology of inductive learning, pp. 83{129.{ Springer Verlag, 1984.[Mitchell et al.92] Mitchell (M.), Forrest (S.) et Holland (J.H.). { The royal roadfor genetic algorithms : Fitness landscapes and GA performance.In : Toward a Practice of Autonomous Systems : Proceedings of theFirst European Conference on Arti�cial Life, �ed. par Varela (F.J.)et Bourgine (P.). { MIT Press.[Mitchell77] Mitchell (T.M.). { Version spaces : A candidate elimination ap-proach to rule learning. In : Fifth International Joint Conferenceon Arti�cial Intelligence IJCAI'77, pp. 305{310.[Mitchell80] Mitchell (T.M.). { The need for biases in learning generalizations. {Technical Report CBM-TR-117, Department of Computer Science,Rutgers University, May 1980. �Edit�e �egalement dans Readings in

BIBLIOGRAPHIE 225Machine Learning, J.W. Shavlik et T.G. Dietterich (Eds), MorganKaufmann, 1990.[Mitchell82] Mitchell (T.M.). { Generalization as search. Arti�cial Intelligence,vol. 18 (2), 1982, pp. 203{226.[Mitchell97] Mitchell (T.M.). { Machine Learning. { McGraw-Hill, 1997.[Montana95] Montana (D.J.). { Strongly typed genetic programming. Evolution-ary Computation, vol. 3 (2), 1995, pp. 199{230.[Muggleton et al.88] Muggleton (S.) et Buntine (W.). { Machine invention of �rst orderpredicates by inverting resolution. In : Proceedings of the Fifthinternational Machine Learning Workshop, Morgan Kaufmann, pp.339{352.[Muggleton et al.90] Muggleton (S.) et Feng (C.). { E�cient induction of logic programs.In : Proceedings of the �rst conference on Algorithmic LearningTheory ALT'90, Tokyo, Ohmsha.[Muggleton et al.92] Muggleton (S.) et Buntine (W.). { Machine invention of �rst-orderpredicates by inverting resolution. In : Inductive Logic Program-ming, �ed. par Muggleton (S.), pp. 261{280. { Associated Press,1992.[Muggleton et al.94] Muggleton (S.) et De Raedt (L.). { Inductive logic programming :Theory and methods. Journal of Logic Programming, vol. 19, 1994,pp. 629{679.[Muggleton90] Muggleton (S.). { Inductive logic programming. New GenerationComputing, vol. 8 (4), 1990, pp. 295{318.[Muggleton92] Muggleton (S.). { Inductive Logic Programming. { Academic Press,1992. The A.P.I.C. Series, No 38.[Muggleton95] Muggleton (S.). { Inverse entailment and Progol. New GenerationComputing, vol. 13 (3-4), 1995, pp. 245{286.[Munteanu96] Munteanu (P.). { Extraction de Connaissances dans les Bases deDonn�ees Parole : Apport de l'Apprentissage Symbolique. { PhDthesis, Institut National Polytechnique de Grenoble, 1996.[NC et al.97] Nienhuys-Cheng (S.-H.) et de Wolf (R.). { Foundations of InductiveLogic Programming. { Springer, LNAI 1228, 1997.[Nedellec et al.96] N�edellec (C.), Rouveirol (C.), Ad�e (H.), Bergadano (F.) et Tausend(B.). { Advances in Inductive Logic Programming, chap. DeclarativeBias in Inductive Logic Programming, pp. 82{103. { IOS Press,1996.[Neri97] Neri (F.). { First Order Logic Concept Learning by Means of aDistributed Genetic Algorithm. { PhD thesis, Dipartimento di In-formatica, Universit�a di Torino, 1997.[Pei et al.97] Pei (M.), Goodman (E.D.) et Punch (W.F.). { Pattern discoveryfrom data using genetic algorithms. In : First Paci�c-Asia Con-ference on Knowledge Discovery and Data Mining, PAKDD'97.

226 BIBLIOGRAPHIE[Periaux et al.95] P�eriaux (J.), Sefrioui (M.), Stou�et (B.), Mantel (B.) et Laporte(E.). { Genetic Algorithms in Engeneering and Computer Science,chap. Robust Genetic Algorithms for Optimization Problems inAerodynamic Design, pp. 371{396. { Wiley, 1995.[Pettey et al.89] Pettey (C.C.) et Leuze (M.R.). { A theoretical investigation of aparallel genetic algorithm. In : Proceedings of the third Interna-tional Conference on Genetic Algorithms ICGA'89, J.D. Scha�er(Ed), Morgan Kaufmann, pp. 398{405.[Plotkin70] Plotkin (G.D.). { Machine Intelligence, Volume 5, chap. A Noteon Inductive Generalization, pp. 153{163. { Edinburgh UniversityPress, 1970.[Provost et al.96] Provost (F.J.) et Aronis (J.M.). { Scaling up inductive machinelearning with massive parallelism. Machine Learning, vol. 23, 1996,pp. 33{46.[Provost et al.97] Provost (F.) et Fawcett (T.). { Analysis and visualization of clas-si�er performance : Comparison under imprecise class and cost dis-tributions. In : Proceedings of the Third International Conferenceon Knowledge Discovery and Data Mining KDD'97.[Quinlan et al.93] Quinlan (J.R.) et Cameron-Jones (R.M.). { FOIL : A midtermreport. In : European Conference on Machine Learning, pp. 3{20.[Quinlan et al.95] Quinlan (J.R.) et Cameron-Jones (R.M.). { Induction of logic pro-grams : FOIL and related systems. New Generation Computing,vol. 13 (3-4), 1995, pp. 287{312.[Quinlan86] Quinlan (J.R.). { Induction of decision trees. Machine Learning,vol. 1 (1), 1986, pp. 81{106.[Quinlan87] Quinlan (J.R.). { Generating production rules from decision trees.In : Proceedings of the Tenth International Joint Conference onArti�cial Intelligence IJCAI'87, pp. 304{307. { Volume 1.[Quinlan93] Quinlan (J.R.). { C4.5 - Programs For Machine Learning. { MorganKaufmann, 1993.[Radcli�e91] Radcli�e (N.J.). { Forma analysis and random respectful recom-bination. In : Proceedings of the fourth International Conferenceon Genetic Algorithms ICGA'91, R.K. Belew et L.B. Booker (Eds),Morgan Kaufmann, pp. 222{229.[Radcli�e92] Radcli�e (N.J.). { Genetic set recombination. In : Foundations ofGenetic Algorithms 2 FOGA'92, L.D. Whitley (Ed), Morgan Kauf-mann, pp. 203{219.[Rakotomalala97] Rakotomalala (R.). { Graphes d'Induction. { PhD thesis, Universit�eClaude-Bernard Lyon I, 1997.[Ravise et al.96] Ravis�e (C.) et Sebag (M.). { An advanced evolution should not re-peat its past errors. In : Proceedings of the thirteenth International

BIBLIOGRAPHIE 227Conference on Machine Learning ICML'96, Bari (Italy), July 3-6th,pp. 400{408.[Raymer et al.96] Raymer (M.L.), Punch (W.F.), Goodman (E.D.) et Kuhn (L.A.).{ Genetic programming for improved data mining { application tothe biochemistry of protein interactions. In : Genetic Programming1996 : Proceedings of the �rst annual conference GP'96, J.R. Koza,D.E. Goldberg, D.B. Fogel et R.L. Riolo (Eds), MIT Press, pp. 375{380.[Rechenberg73] Rechenberg (I.). { Evolutionsstrategie : Optimierung technischerSysteme nach Prinzipien der biologischen Evolution. { Frommann-Holzboog, Stuttgart, 1973.[Reiser et al.99] Reiser (P.G.K) et Riddle (P.J.). { Evolution of logic programs : Part-of-speech tagging. In : Proceedings of the Congress on EvolutionaryComputation CEC'99, Washington DC, pp. 1338{1345.[Richards et al.92] Richards (B.L.) et Mooney (R.J.). { Learning relations by path�nd-ing. In : Proceedings of the tenth national conference on arti�cialintelligence AAAI'92, pp. 51{55.[Robinson65] Robinson (J.). { A machine-oriented logic based on the resolutionprinciple. Journal of the ACM, vol. 12(1), 1965, pp. 23{41.[Rouveirol91] Rouveirol (C.). { ITOU : Induction de Th�eories en Ordre Un. Ex-tensions de l'inversion de la r�esolution appliqu�ee �a la compl�etion deth�eories. { PhD thesis, Universit�e Paris-Sud - Centre d'Orsay, 1991.no d'ordre : 1536.[Rouveirol94] Rouveirol (C.). { Flattening and Saturation : Two RepresentationChanges for Generalization. Machine Learning, vol. 14, 1994, pp.219{232.[Rudolph97] Rudolph (G.). { Convergence Properties of Evolutionary Algo-rithms. { Hamburg : Kovac, 1997.[Sarma et al.97] Sarma (J.) et De Jong (K.A.). { An analysis of local selectionalgorithms in a spatially structured evolutionary algorithm. In :Proceedings of the seventh International Conference on Genetic Al-gorithms ICGA'97, pp. 181{186.[Scha�er et al.91] Scha�er (J.D.), Eshelman (L.J.) et O�ut (D.). { Spurious correla-tions and premature convergence in genetic algorithms. In : Foun-dations of Genetic Algorithms 1 FOGA'90, G.J.E. Rawlins (Ed),Morgan Kaufmann, pp. 102{112.[Scha�er94] Scha�er (C.). { A conservation law for generalization performance.In : Proceedings of the Eleventh International Conference on Ma-chine Learning ML'94, W.W. Cohen et H. Hirsh (Eds), 1994, pp.259{265.[Sche�er et al.96] Sche�er (T.), Herbrich (R.) et Wysotzki (F.). { E�cient algorithmsfor �-subsumption. In : Inductive Logic Programming, 6th Interna-tional Workshop, LNAI1314, pp. 212{228.

228 BIBLIOGRAPHIE[Schoenauer et al.97] Schoenauer (M.) et Michalewicz (Z.). { Evolutionary computation.Control and Cybernetics, vol. 26 (3), 1997, pp. 307{338.[Sebag et al.97a] Sebag (M.) et Rouveirol (C.). { Tractable induction and classi�-cation in �rst order logic via stochastic matching. In : FifteenthInternational Joint Conference on Arti�cial Intelligence IJCAI'97,M.E. Pollack (Ed), Nagoya, Japan, Morgan Kaufmann, pp. 888{893.[Sebag et al.97b] Sebag (M.), Schoenauer (M.) et Ravis�e (C.). { Inductive learning ofmutation step-size in evolutionary parameter optimization. In : 6thAnnual Conference on Evolutionary Programming EP'97, Indiana(USA), LNCS 1213, pp. 247{261.[Sebag94] Sebag (M.). { Using constraints to building version spaces. In :ECML'94, European Conference on Machine Learning, Catania,Italy, F. Bergadano et L. De Raedt (Eds), 1994, pp. 257{271.[Sebag96] Sebag (M.). { Delaying the choice of bias : A disjunctive versionspace approach. In : Proceedings of the thirteenth InternationalConference on Machine Learning ICML'96, Bari (Italy), July 3-6th, pp. 444{452.[Sebag98] Sebag (M.). { A stochastic simple similarity. In : Inductive LogicProgramming, Eighth International Conference ILP'98, D. Page(Ed), Madison, Wisconsin, USA, LNAI 1446, pp. 95{105.[Silverstein et al.91] Silverstein (G.) et Pazzani (M.J.). { Relational clich�es : Constrain-ing constructive induction during relational learning. In : Pro-ceedings of the Eight International Workshop on Machine LearningML'91, pp. 203{207.[Smith83] Smith (S.F.). { Flexible learning of problem solving heuristicsthrough adaptive search. In : Proceedings of the Eighth Inter-national Joint Conference on Arti�cial Intelligence IJCAI'83, A.Bundy (Ed), distributed by William Kaufmann, Inc., pp. 422{425.[Sommer95] Sommer (E.). { An approach to quantifying the quality of inducedtheories. In : Proceedings of IJCAI'95 Workshop on Machine Learn-ing and Comprehensibility, �ed. par Nedellec (C.).[Spears et al.93] Spears (W.M.), De Jong (K.A.), B�ack (T.), Fogel (D.B.) et de Garis(H.). { An overview of evolutionary computation. In : Sixth Euro-pean Conference on Machine Learning ECML'93, Vienna Austria,April 5-7th, P.B. Brazdil (Ed), LNAI 667, pp. 443{459.[Spears91] Spears (W.). { Adapting crossover in a genetic algorithm. In :Proceedings of the fourth International Conference on Genetic Al-gorithms ICGA'91, R.K. Belew et L.B. Booker (Eds), Morgan Kauf-mann, pp. 166{173.[Spiessens et al.91] Spiessens (P.) et Manderick (B.). { A massively parallel geneticalgorithm. In : Proceedings of the fourth International Conference

BIBLIOGRAPHIE 229on Genetic Algorithms ICGA'91, R.K. Belew et L.B. Booker (Eds),Morgan Kaufmann, pp. 279{286.[Srinivasan et al.94] Srinivasan (A.), Muggleton (S.H.), King (R.D.) et Sternberg(M.J.E). { Mutagenesis : ILP experiments in a non-determinatebiological domain. In : Proceedings of the Fourth InternationalWorkshop on Inductive Logic Programming ILP'94, Stefan Wrobel(Ed), GMD-Studien Nr. 237, pp. 217{232.[SS88] Schmidt-Schauss (M.). { Implication of clauses is undecidable. The-oretical Computer Science, vol. 59, 1988, pp. 287{296.[Syswerda89] Syswerda (G.). { Uniform crossover in genetic algorithms. In :Proceedings of the third International Conference on Genetic Algo-rithms ICGA'89, J.D. Scha�er (Ed), Morgan Kaufmann, pp. 2{9.[TN et al.00] Tamaddoni-Nezhad (A.) et Muggleton (S.). { Searching the sub-sumption lattice by a genetic algorithm. In : Inductive Logic Pro-gramming, Tenth International Conference ILP'2000, London, UK,J. Cussens et A. Frisch (Eds), LNAI 1866, pp. 243{252.[Torre99] Torre (F.). { Les vraizamis. In : Actes de la Conf�erence d'Appren-tissage CAP'99, Plate-forme AFIA'99, Palaiseau, Ecole Polytech-nique, M. Sebag (Ed), 1999, pp. 177{184.[Tsang93] Tsang (E.). { Foundations of Constraint Satisfaction. { AcademicPress, 1993.[Utgo�86] Utgo� (P.E.). { Machine Learning - An Arti�cial Intelligence Ap-proach, Volume II, chap. Shift of bias for inductive concept learning,pp. 107{148. { Morgan Kaufmann, 1986.[Vapnik98] Vapnik (V.). { Advances in Kernel Methods - Support Vector Learn-ing, chap. Three Remarks on the Support Vector Method of Func-tion Estimation, pp. 25{41. { The MIT Press, 1998.[Venturini93] Venturini (G.). { SIA : a supervised inductive algorithmwith geneticsearch for learning attributes based concepts. In : Sixth EuropeanConference on Machine Learning ECML'93, Vienna Austria, April5-7th, P.B. Brazdil (Ed), LNAI 667, pp. 280{296.[Venturini94a] Venturini (G.). { Analyzing french justice with a genetic-basedinductive algorithm. Applied Arti�cial Intelligence, vol. 8 (4), 1994,pp. 565{577.[Venturini94b] Venturini (G.). { Apprentissage Adaptatif et Apprentissage Super-vis�e par Algorithme G�en�etique. { PhD thesis, Universit�e de Paris-Sud - Centre d'Orsay, 1994. no d'ordre : 3050.[Venturini95] Venturini (G.). { Towards a genetic theory of easy and hard func-tions. In : Arti�cial Evolution - European Conference AE'95, J.M.Alliot, E. Lutton, E. Ronald, M. Schoenauer et D. Snyers (Eds),Springer, LNCS 1063, pp. 54{66.

230 BIBLIOGRAPHIE[Venturini96] Venturini (G.). { Algorithmes g�en�etiques et apprentissage. Revued'Intelligence Arti�cielle, vol. 10 (2-3), 1996, pp. 345{387.[Vose92] Vose (M.D.). { Modeling simple genetic algorithm. In : Founda-tions of Genetic Algorithms 2 FOGA'92, L.D. Whitley (Ed), Mor-gan Kaufmann, pp. 63{73.[Whitley91] Whitley (L.D.). { Fundamental principles of deception in geneticsearch. In : Foundations of Genetic Algorithms 1 FOGA'90, G.J.E.Rawlins (Ed), Morgan Kaufmann, pp. 221{241.[Wilson85] Wilson (S.W.). { Knowledge growth in an arti�cial animal. In :Proceedings of the �rst International Conference on Genetic Al-gorithms and their applications ICGA'85, J.J. Grefenstette (Ed),Lawrence Erlbaum Associates Publishers, pp. 16{23.[Wilson87] Wilson (S.W.). { Classi�er systems and the animat problem. Ma-chine Learning, vol. 2 (3), 1987, pp. 199{228.[Wilson91] Wilson (S.W.). { GA-easy does not imply steepest-ascent optimiz-able. In : Proceedings of the fourth International Conference onGenetic Algorithms ICGA'91, R.K. Belew et L.B. Booker (Eds),Morgan Kaufmann, pp. 85{89.[Wilson98] Wilson (S.W.). { Generalization in the XCS classi�er system. In :Genetic Programming 1998 : Proceedings of the Third Annual Con-ference, �ed. par et al. (J. Koza). { Morgan Kaufmann.[Wilson99] Wilson (S.W.). { State of XCS Classi�er System Research. { Techni-cal Report 99.1.1, Prediction Dynamics, 1999. Concord, MA 01742USA.[Winston75] Winston (P.H.). { The Psychology of Computer Vision, chap. Learn-ing Structural Descriptions from Examples, pp. 157{209. { Mc-Graw-Hill, 1975.[Winston92] Winston (P.H.). { Arti�cial Intelligence (third edition). { Addison-Wesley, 1992.[Wolpert et al.96a] Wolpert (D.H.) et Macready (W.G.). { No Free Lunch Theorems forOptimization. { Technical report, IBM Almaden Research Center /The Santa Fe Institute, December 31, 1996.[Wolpert et al.96b] Wolpert (D.H.) et Macready (W.G.). { No Free Lunch Theoremsfor Search. { Technical Report SFI-TR-95-02-010, The Santa FeInstitute, February 23, 1996.[Wong et al.95] Wong (M.L.) et Leung (K.S.). { The genetic logic programmingsystem. IEEE Expert, vol. 10 (5), 1995, pp. 68{76.[Zheng et al.00] Zheng (Z.) et Webb (G.I.). { Lazy learning of bayesian rules. Ma-chine Learning, vol. 41 (1), 2000, pp. 53{84.[Zighed et al.00] Zighed (D.A.) et Rakotomalala (R.R.). { Graphes d'Induction -Apprentissage en Data Mining. { Hermes, 2000.

BIBLIOGRAPHIE 231[Zitzler99] Zitzler (E.). { Evolutionary Algorithms for Multiobjective Optimiza-tion : Methods and Applications. { PhD thesis, Institut f�ur Technis-che Informatik und Kommunikationsnetze, 1999. TIK NR. 30, Diss.ETH No. 13398.[Zucker et al.96] Zucker (J.-D.) et Ganascia (J.-G.). { Representation changes fore�cient learning in structural domains. In : Proceedings of thethirteenth International Conference on Machine Learning ICML'96,Bari (Italy), July 3-6th, pp. 543{551.[Zucker et al.98] Zucker (J.-D.) et Ganascia (J.-G.). { Learning structurally inde-terminate clauses. In : Inductive Logic Programming, Eighth In-ternational Conference ILP'98, D. Page (Ed), Madison, Wisconsin,USA, LNAI 1446, pp. 235{244.

232 BIBLIOGRAPHIE

Liste des �gures1.1 Pluridisciplinarit�e de l'ECD. . . . . . . . . . . . . . . . . . . . . . . . . . . 31.2 Le processus d'ECD. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31.3 Utilisation d'un algorithme d'AS. . . . . . . . . . . . . . . . . . . . . . . . 41.4 Un exemple de hi�erarchie sur des constantes. . . . . . . . . . . . . . . . . . 51.5 Diagramme pour H ! C. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 91.6 Tableau de contingence (H; C). . . . . . . . . . . . . . . . . . . . . . . . . . 91.7 Structure de Lh dans le cas d'un langage attribut-valeur simple. . . . . . . 141.8 L'approche diviser pour r�egner. . . . . . . . . . . . . . . . . . . . . . . . . 171.9 Adaptation de la direction de la recherche aux probl�emes d'apprentissage. 192.1 Interaction g�enotype/ph�enotype au cours du processus d'�evolution. . . . . 362.2 Algorithme d'�evolution g�en�erique. . . . . . . . . . . . . . . . . . . . . . . . 372.3 Op�erateurs de reproduction de l'AGC. . . . . . . . . . . . . . . . . . . . . 402.4 D�eroulement d'un cycle de l'algorithme g�en�etique canonique. . . . . . . . . 412.5 Principaux croisements sur les chromosomes binaires de taille �xe. . . . . . 452.6 Mutation auto-adaptative des strat�egie (�; �)� ES et (� + �)� ES pourn = 2. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 482.7 Exemple de croisement en programmation g�en�etique. . . . . . . . . . . . . 522.8 Contexte d'application et structure interne d'un syst�eme de classeurs. . . . 562.9 D�eroulement d'un cycle de l'algorithme bucket brigade. . . . . . . . . . . . 582.10 Repr�esentation d'un individu dans GABIL. . . . . . . . . . . . . . . . . . . 592.11 Op�erateur de recombinaison de GABIL. . . . . . . . . . . . . . . . . . . . . 602.12 Codage de la formule g�en�erique � = �LP ^�CP dans une cha�ne binaire detaille �xe � [Giordana et al.97]. . . . . . . . . . . . . . . . . . . . . . . . . 673.1 Repr�esentations de donn�ees relationnelles. . . . . . . . . . . . . . . . . . . 783.2 La relation `2 g�en�ere un treillis sur le graphe d�e�ni par la relation `,permettant ainsi une exploration e�cace. . . . . . . . . . . . . . . . . . . . 833.3 Complexit�e du test de subsomption en logique d'ordre 0. . . . . . . . . . . 853.4 Complexit�e du test de subsomption dans le cas de SIAO1. . . . . . . . . . 853.5 Description relationnelle classique de la mol�ecule de dioxyde de soufre. . . 863.6 Description aplatie de la mol�ecule de dioxyde de soufre. . . . . . . . . . . . 873.7 Repr�esentation tabulaire du test de subsomption. . . . . . . . . . . . . . . 913.8 R�esolution du test de subsomption. . . . . . . . . . . . . . . . . . . . . . . 923.9 Vue graphique du probl�eme d'incompatibilit�e des contraintes par combi-naison. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 98233

234 LISTE DES FIGURES3.10 Gain apport�e par la combinaison de lignes. . . . . . . . . . . . . . . . . . . 993.11 Performance des tests de subsomption sur le probl�eme Mutagenesis. . . . . 1073.12 Performance des tests de subsomption sur le probl�eme Mutagenesis (d�etail). 1084.1 �Evolution de P (Ex) dans le treillis d�e�ni par N(Ex) et `2. . . . . . . . . 1134.2 Processus d'�elagage au cours de l'�evolution. . . . . . . . . . . . . . . . . . . 1164.3 Structure d'un chromosome. . . . . . . . . . . . . . . . . . . . . . . . . . . 1184.4 Comparaison entre fe et fmax pour R1 et R2. . . . . . . . . . . . . . . . . 1234.5 Iris . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1314.6 1000 Trains . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1314.7 Mushrooms . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1314.8 Census-Income . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1314.9 Structure de l'espace (g�enotype) . . . . . . . . . . . . . . . . . . . . . . . . . 1364.10 Structure de l'espace (ph�enotype)1 . . . . . . . . . . . . . . . . . . . . . . . . 1364.11 Exemples de croisements par �echange de g�enes. . . . . . . . . . . . . . . . 1384.12 Croisements dans un espace �a deux descripteurs. . . . . . . . . . . . . . . . 1394.13 Exemple 1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1424.14 Exemple 2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1424.15 Complexit�es compar�ees des implantations du post-traitement. . . . . . . . 1484.16 Pr�ediction du risque cardio-vasculaire. . . . . . . . . . . . . . . . . . . . . 1505.1 Comportement de la borne sup�erieure de l'e�cacit�e pr�edite par la loi d'Am-dahl. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1625.2 L'architecture ma�tre-esclave. . . . . . . . . . . . . . . . . . . . . . . . . . 1645.3 Architecture ma�tre-esclave synchrone. . . . . . . . . . . . . . . . . . . . . 1655.4 Architecture ma�tre-esclave asynchrone. . . . . . . . . . . . . . . . . . . . . 1665.5 L'architecture en r�eseau. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1685.6 Architecture g�en�erique propos�ee. . . . . . . . . . . . . . . . . . . . . . . . 1775.7 Architecture ma�tre-esclave asynchrone avec �le d'attente. . . . . . . . . . 1785.8 L'architecture pipeline. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1795.9 Acc�el�eration (Mushrooms) . . . . . . . . . . . . . . . . . . . . . . . . . . . 1845.10 E�cacit�e (Mushrooms) . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1845.11 Acc�el�eration . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1855.12 E�cacit�e . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1855.13 Acc�el�eration RCD . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1875.14 Acc�el�eration RCS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1875.15 E�cacit�e RCD . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1875.16 E�cacit�e RCS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1875.17 TCom RCD . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1885.18 TCom RCS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1885.19 Acc�el�eration RCD . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1905.20 Acc�el�eration RCS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1905.21 E�cacit�e RCD . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1905.22 E�cacit�e RCS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1905.23 TCom RCD . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 191

LISTE DES FIGURES 2355.24 TCom RCS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1915.25 Surface E(n; p) calcul�ee d'apr�es le mod�ele pour le probl�eme Mushrooms.Les courbes d'iso-e�cacit�e associ�ees �gurent sur le plan (n; p). . . . . . . . 193A.1 Construction des formules de la logique relationnelle. . . . . . . . . . . . . 200D.1 Menu de lancement de SIAO1. . . . . . . . . . . . . . . . . . . . . . . . . 211D.2 Fenetre d'�etat de SIAO1. . . . . . . . . . . . . . . . . . . . . . . . . . . . 212D.3 Le r�esultat de l'apprentissage �gure dans l'�editeur. . . . . . . . . . . . . . . 213D.4 Fenetre de description d'un type num�erique. . . . . . . . . . . . . . . . . . 214D.5 Fenetre de description d'un type num�erique. . . . . . . . . . . . . . . . . . 215

236 LISTE DES FIGURES

Liste des tableaux1.1 Cout de d�eveloppement et de maintenance de di��erents syst�emes experts,suivant qu'ils mettent en �uvre ou non des techniques d'apprentissage au-tomatique (source : [Muggleton92]). . . . . . . . . . . . . . . . . . . . . . . 22.1 Inconv�enients des strat�egies classiques de traitement des valeurs non d�e�nies. 633.1 Contraintes incompatibles par combinaison. . . . . . . . . . . . . . . . . . 973.2 Comportement des tests ` SIAO1 et ` Sche�er sur le probl�eme des nreines. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1094.1 Les di��erentes formes d'un g�ene. . . . . . . . . . . . . . . . . . . . . . . . . 1184.2 Fonction de p�enalit�e d�e�nie sur les g�enes. . . . . . . . . . . . . . . . . . . . 1254.3 R�eduction observ�ee du nombre d'appariements sur di��erentes bases. . . . . 1304.4 R�eduction observ�ee du nombre d'�evaluations sur di��erentes bases. . . . . . 1324.5 �Evaluation sur la base Iris . . . . . . . . . . . . . . . . . . . . . . . . . . . 1514.6 �Evaluation sur la base Mushrooms . . . . . . . . . . . . . . . . . . . . . . . 1524.7 �Evaluation sur la base 1000-trains . . . . . . . . . . . . . . . . . . . . . . . 1524.8 �Evaluation sur la base Mutagenesis (B2) . . . . . . . . . . . . . . . . . . . 1524.9 �Evaluation sur la base Census-Income . . . . . . . . . . . . . . . . . . . . . 1534.10 �Evaluation sur la base Adult . . . . . . . . . . . . . . . . . . . . . . . . . . 1535.1 Variation du taux d'instructions non parall�elisables maximum permettantde conserver une e�cacit�e donn�ee en fonction du nombre de processeurs. . 1635.2 Proportion du temps d'ex�ecution pass�ee en tests de couverture lorsque l'onfait varier la taille de la base d'apprentissage. . . . . . . . . . . . . . . . . 1765.3 Conditions d'exp�erimentation. . . . . . . . . . . . . . . . . . . . . . . . . 1845.4 Espace m�emoire requis par les processus du pipeline (en Ko). . . . . . . . 1855.5 Performance du mod�ele appliqu�e au calcul de l'e�cacit�e (Mushrooms). . . 1895.6 Performance du mod�ele appliqu�e au calcul de l'e�cacit�e (Iris). . . . . . . 191B.1 Les 40 attributs de la base census-income. . . . . . . . . . . . . . . . . . . 204237

238 LISTE DES TABLEAUX

Table des mati�eres d�etaill�ee1 Apprentissage Automatique Symbolique Supervis�e 11.1 Historique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11.2 Poser le probl�eme . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 31.2.1 Probl�ematique g�en�erale . . . . . . . . . . . . . . . . . . . . . . . . . 31.2.2 Structure du processus de r�esolution . . . . . . . . . . . . . . . . . 41.2.3 Apprentissage supervis�e et optimisation . . . . . . . . . . . . . . . . 61.3 Strat�egies de r�esolution . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 81.3.1 Sp�eci�cit�e du probl�eme . . . . . . . . . . . . . . . . . . . . . . . . . 81.3.2 Application du th�eor�eme de conservation . . . . . . . . . . . . . . . 101.3.3 Structure de l'espace de recherche . . . . . . . . . . . . . . . . . . . 131.3.4 Apprendre c'est oublier . . . . . . . . . . . . . . . . . . . . . . . . . 141.3.5 Apprendre c'est discriminer . . . . . . . . . . . . . . . . . . . . . . 171.3.6 De l'importance de la direction de la recherche . . . . . . . . . . . . 191.3.7 Autres m�ethodes . . . . . . . . . . . . . . . . . . . . . . . . . . . . 201.4 Biais et Apprentissage . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 241.4.1 D�e�nition et caract�erisation des biais . . . . . . . . . . . . . . . . . 241.4.2 Un apprentissage non biais�e . . . . . . . . . . . . . . . . . . . . . . 251.4.3 Les biais en pratique . . . . . . . . . . . . . . . . . . . . . . . . . . 261.5 Apprentissage en logique du premier ordre . . . . . . . . . . . . . . . . . . 291.5.1 Le langage de la logique relationnelle . . . . . . . . . . . . . . . . . 301.5.2 La programmation logique inductive . . . . . . . . . . . . . . . . . 321.6 R�ecapitulatif . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 342 Algorithmes d'�Evolution pour l'AS 352.1 Les algorithmes d'�evolution . . . . . . . . . . . . . . . . . . . . . . . . . . 352.1.1 Introduction . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 352.1.2 Les algorithmes g�en�etiques . . . . . . . . . . . . . . . . . . . . . . . 392.1.3 Les strat�egies d'�evolution . . . . . . . . . . . . . . . . . . . . . . . . 462.1.4 La programmation �evolutionnaire . . . . . . . . . . . . . . . . . . . 502.1.5 La programmation g�en�etique . . . . . . . . . . . . . . . . . . . . . . 512.2 Algorithmes d'�evolution et apprentissage automatique . . . . . . . . . . . . 542.2.1 Approche de Michigan - Les syst�emes de classeurs . . . . . . . . . . 552.2.2 Approche de Pittsburgh - GABIL . . . . . . . . . . . . . . . . . . . 592.2.3 SIA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 60239

240 TABLE DES MATI�ERES D�ETAILL�EE2.2.4 REGAL et G-Net . . . . . . . . . . . . . . . . . . . . . . . . . . . . 662.3 R�ecapitulatif - Motivation de SIAO1 . . . . . . . . . . . . . . . . . . . . . 703 Le biais de langage 733.1 Le langage de repr�esentation de SIAO1 . . . . . . . . . . . . . . . . . . . 743.1.1 Contexte th�eorique . . . . . . . . . . . . . . . . . . . . . . . . . . . 743.1.2 Repr�esentation des hypoth�eses et des instances dans SIAO1 . . . . 763.1.3 La relation de subsomption sur Lh . . . . . . . . . . . . . . . . . . 803.2 Implantation du test de subsomption . . . . . . . . . . . . . . . . . . . . . 833.2.1 Raisons motivant l'optimisation . . . . . . . . . . . . . . . . . . . . 833.2.2 Architecture g�en�erale . . . . . . . . . . . . . . . . . . . . . . . . . . 893.2.3 Traitement de la partie �xe . . . . . . . . . . . . . . . . . . . . . . 893.2.4 Simpli�cation de la partie contrainte . . . . . . . . . . . . . . . . . 903.2.5 Parcours de l'espace de recherche . . . . . . . . . . . . . . . . . . . 1003.2.6 Propri�et�es de l'algorithme de subsomption . . . . . . . . . . . . . . 1023.2.7 Autres approches . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1043.2.8 �Evaluation exp�erimentale . . . . . . . . . . . . . . . . . . . . . . . . 1043.3 Bilan . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1094 SIAO1 1114.1 Architecture g�en�erale . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1114.1.1 M�ethode de recherche . . . . . . . . . . . . . . . . . . . . . . . . . . 1124.1.2 D�eveloppement simultan�e de plusieurs noyaux . . . . . . . . . . . . 1154.1.3 Repr�esentation des formules . . . . . . . . . . . . . . . . . . . . . . 1164.2 Calcul de la qualit�e . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1194.2.1 L'estimateur de Laplace . . . . . . . . . . . . . . . . . . . . . . . . 1194.2.2 Le biais syntaxique . . . . . . . . . . . . . . . . . . . . . . . . . . . 1244.2.3 R�eduction du cout de calcul . . . . . . . . . . . . . . . . . . . . . . 1284.3 Les op�erateurs d'�evolution . . . . . . . . . . . . . . . . . . . . . . . . . . . 1324.3.1 La mutation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1334.3.2 Le croisement . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1374.3.3 R�ecapitulatif : le biais de recherche de SIAO1 . . . . . . . . . . . . 1434.4 Post-traitement et Classi�cation . . . . . . . . . . . . . . . . . . . . . . . . 1444.4.1 Classi�cation des nouvelles instances . . . . . . . . . . . . . . . . . 1454.4.2 �Elagage des r�egles . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1464.5 Connaissances du domaine . . . . . . . . . . . . . . . . . . . . . . . . . . . 1494.6 �Evaluation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1514.6.1 R�esultats sur Iris et Mushrooms . . . . . . . . . . . . . . . . . . . . 1514.6.2 R�esultats sur 1000-trains et Mutagenesis . . . . . . . . . . . . . . . 1524.6.3 R�esultats sur Census-Income et Adult . . . . . . . . . . . . . . . . . 1524.6.4 Analyse des r�esultats exp�erimentaux . . . . . . . . . . . . . . . . . 1544.7 Bilan . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 154

TABLE DES MATI�ERES D�ETAILL�EE 2415 Parall�elisme et r�epartition 1575.1 Probl�ematique . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1575.2 Concepts fondamentaux . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1585.2.1 Les sources de parall�elisme . . . . . . . . . . . . . . . . . . . . . . . 1585.2.2 La loi d'Amdahl . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1605.2.3 Conclusion . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1635.3 Les algorithmes d'�evolution r�epartis . . . . . . . . . . . . . . . . . . . . . . 1635.3.1 Une classi�cation des architectures . . . . . . . . . . . . . . . . . . 1635.3.2 Les architectures ma�tre-esclave . . . . . . . . . . . . . . . . . . . . 1645.3.3 Les architectures en r�eseau . . . . . . . . . . . . . . . . . . . . . . . 1675.3.4 Mod�elisation . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1705.4 Parall�elisation de SIAO1 . . . . . . . . . . . . . . . . . . . . . . . . . . . 1725.4.1 Objectifs . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1725.4.2 Formalisation de la notion de changement d'�echelle . . . . . . . . . 1735.4.3 Deux architectures adapt�ees �a la fouille de donn�ees . . . . . . . . . 1755.4.3.1 Parall�elisme de donn�ees . . . . . . . . . . . . . . . . . . . 1775.4.3.2 Parall�elisme de ux . . . . . . . . . . . . . . . . . . . . . . 1795.4.4 Du d�epassement de la loi d'Amdahl . . . . . . . . . . . . . . . . . 1825.5 R�esultats exp�erimentaux . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1825.5.1 Protocole de validation . . . . . . . . . . . . . . . . . . . . . . . . . 1825.5.2 Premiers r�esultats . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1835.5.3 �Etude sur les bases Mushrooms et Iris . . . . . . . . . . . . . . . . . 1855.5.4 �A propos du changement d'�echelle de SIAO1 . . . . . . . . . . . . 1925.6 Bilan . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1936 Conclusion 1956.1 Bilan . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1956.2 Perspectives . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 196A Notations - D�e�nitions 197A.1 Notations . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 197A.2 De�nitions . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 199A.2.1 Ensembles ordonn�es - Treillis . . . . . . . . . . . . . . . . . . . . . 199A.2.2 Le langage de la logique relationnelle . . . . . . . . . . . . . . . . . 200B Bases d'apprentissage utilis�ees 203B.1 La base Census-Income . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 203B.2 La base Iris . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 204B.3 La base Mushrooms . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 204B.4 La base Mutagenesis . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 205B.5 La base 1000-trains . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 206

242 TABLE DES MATI�ERES D�ETAILL�EEC D�etail des r�esultats exp�erimentaux 207C.1 Parall�elisation de SIAO1 . . . . . . . . . . . . . . . . . . . . . . . . . . . 207C.2 Etude de T ratiop sur la base Mushrooms . . . . . . . . . . . . . . . . . . . . 207C.3 Etude de TCom sur la base Mushrooms . . . . . . . . . . . . . . . . . . . . 208C.4 Etude de T ratiop sur la base Iris . . . . . . . . . . . . . . . . . . . . . . . . . 209C.5 Etude de TCom sur la base Iris . . . . . . . . . . . . . . . . . . . . . . . . . 210D Interface graphique de SIAO1 211D.1 Exemple d'apprentissage sur la base des Iris . . . . . . . . . . . . . . . . . 211D.2 Les fonctionnalit�es de visualisation des donn�ees . . . . . . . . . . . . . . . 214Bibliographie 231Liste des �gures 235Liste des tableaux 237Table des mati�eres d�etaill�ee 242


















