![Journal of Technology Survey of Routing Protocols for ... of Routing Protocols for... · Dynamic source routing protocol [7] is a reactive protocol. DSR requires no periodic updates](https://static.fdocuments.us/doc/165x107/5f37c487d286fb5893336dad/journal-of-technology-survey-of-routing-protocols-for-of-routing-protocols-for.jpg)
Adaptive Path Accumulation for Reactive Routing Protocolscedric/papers/westphal2008adaptive.pdf ·...
10
Adaptive Path Accumulation for Reactive Routing Protocols Cedric Westphal *, Karim Seadat, Charles E. Perkins+, Ryuji Wakikawa§ *DoCoMo Labs USA, tNokia Research Center, +WiChorus.com §Keio University Email: *[email protected]@nokia.com. [email protected] §[email protected] Abstract-We study the overhead of some mechanisms for information dissemination. We use reactive routing protocols in mobile ad hoc networks as our illustrative example. However, while reactive routing protocols are the main application for our results, they apply to different settings as well, which include publish/subscribe information dissemination mechanisms, infor- mation dissemination in sensor networks, and location services. We use a performance measure, defined in [8], which we call the efficiency of the information dissemination process, and use this efficiency to evaluate the overhead. The overhead is influenced by the use of a mechanism to increase the amount of information disseminated, at the cost of a higher overhead, called path accumulation. We compare the overhead of routing protocols with and without path accumulation. We observe that path accumulation is always more efficient at disseminating route information in the network, but the gain in efficiency decreases when it is normalized by the number of extra routes discovered, as more is known about the network. This means that the marginal return of path accumulation decreases over not using path accumulation. We propose a new route discovery mechanism which applies to most of the reactive protocols using a route request/route reply exchange. Our route discovery mechanism, denoted adaptive path accumulation adjusts the accumulated path in order to either: scale its bandwidth overhead down as more information is distributed in the network, or improve the network discovery by carefully selecting the routes to be propagated. We assess a range of adaptive path accumulation policies using numerical evaluation and show the effect of these policies on route discovery and packet overhead. Index Terms-Wireless ad hoc networks, route discovery, path accumulation, control overhead. I. INTRODUCTION Information dissemination is an in important building block for many applications in mobile ad hoc and sensor systems. For example, publish/subscribe systems, resource discovery, sensor data dissemination, and location services all require an efficient information dissemination mechanism to propagate and access information along the multi-hop network. In ad- dition to these applications, the basic routing itself rely on efficient node information dissemination to discover routes and build its routing tables. In this paper, we will focus on the route discovery problem as our case study due to its critical importance in building efficient multi-hop networks. The models and insights obtained from this study can be applied to the other applications as well. Although, routing in ad hoc networks has a long history of research, these fundamental issues are still not clearly understood and there This research was sponsored in part by a grant from the Japan Society for Promotion of Science (JSPS). 978-1-4244-2575-4/08/$20.00 @2008 IEEE is an obvious lack of analytical models to classify these problems. Many reactive routing protocols ([1], [2], [3], [4]) in mobile ad hoc networks (MANETs) use a route discovery process to populate the route table in each node. Upon receiving a packet from the application layer, the protocol, if it does not already possess a route to the destination, generates a route request (RREQ) from source s for destination d. The RREQ is broadcast through the network, establishing a route back to s at each node forwarding the RREQ. When d receives the RREQ, it sends a route reply (RREP) along one of the routes created by the RREQ. The RREP then establishes a route to d. These routes are then cached in the network for a length of time, in order to be re-used by subsequent connection attempts. The more valid routes are cached, the fewer RREQs are flooded through the network. Flooding causes negative effects on the network: it consumes a lot of bandwidth; all nodes relaying the RREQ compete for the wireless medium in a synchronous manner, creating congestion and race conditions. Since flooding the network has adverse consequences [5], increasing the number of cached routes is a valid goal. One mechanism to increase the number of cached routes is to use path accumulation. A protocol which does not use path accumulation, such as AODV [1], includes only information about the source s in the RREQ. Thus, the RREQ only sets up routes back to s for the RREQ (and d for the RREP). Path accumulation on the other hand requires each node receiving the RREQ (resp., the RREP) to insert its own identifier in the header, so that the RREQ (resp., the RREP) now carries the whole path from s to the node which receives it. The node which receives the RREQ can thus set up routes in its route table not only for s but for all the nodes on the path traversed by the RREQ. Figure 1 describes the path accumulation process: node A sends a RREQ towards E, which sends the RREP. Without path accumulation, nodes B, C, D only discover the path to nodes A and E after completion of the RREQIRREP exchange. With path accumulation, all nodes know a path to all the other nodes. However, while path accumulation increases the number of routes set up by the route discovery process, it also comes at the expense of a higher overhead: the size of a RREQ or a RREP increases linearly with the number of hops. The trade- off is thus between the size of the overhead, and the efficiency of the route discovery process. The key contribution of this paper is to study the trade- off between the overhead of the route discovery process, 203
Transcript of Adaptive Path Accumulation for Reactive Routing Protocolscedric/papers/westphal2008adaptive.pdf ·...

Adaptive Path Accumulation for Reactive Routing Protocols
Cedric Westphal* , Karim Seadat, Charles E. Perkins+, Ryuji Wakikawa§*DoCoMo Labs USA, tNokia Research Center, +WiChorus.com
§Keio UniversityEmail: *[email protected]@nokia.com. [email protected]
Abstract-We study the overhead of some mechanisms forinformation dissemination. We use reactive routing protocols inmobile ad hoc networks as our illustrative example. However,while reactive routing protocols are the main application for ourresults, they apply to different settings as well, which includepublish/subscribe information dissemination mechanisms, information dissemination in sensor networks, and location services.We use a performance measure, defined in [8], which we callthe efficiency ~ of the information dissemination process, anduse this efficiency to evaluate the overhead. The overhead isinfluenced by the use of a mechanism to increase the amountof information disseminated, at the cost of a higher overhead,called path accumulation. We compare the overhead of routingprotocols with and without path accumulation.
We observe that path accumulation is always more efficientat disseminating route information in the network, but the gainin efficiency decreases when it is normalized by the number ofextra routes discovered, as more is known about the network.This means that the marginal return of path accumulationdecreases over not using path accumulation. We propose a newroute discovery mechanism which applies to most of the reactiveprotocols using a route request/route reply exchange. Our routediscovery mechanism, denoted adaptive path accumulation adjuststhe accumulated path in order to either: scale its bandwidthoverhead down as more information is distributed in the network,or improve the network discovery by carefully selecting theroutes to be propagated. We assess a range of adaptive pathaccumulation policies using numerical evaluation and show theeffect of these policies on route discovery and packet overhead.
Index Terms-Wireless ad hoc networks, route discovery, pathaccumulation, control overhead.
I. INTRODUCTION
Information dissemination is an in important building blockfor many applications in mobile ad hoc and sensor systems.For example, publish/subscribe systems, resource discovery,sensor data dissemination, and location services all require anefficient information dissemination mechanism to propagateand access information along the multi-hop network. In addition to these applications, the basic routing itself rely onefficient node information dissemination to discover routesand build its routing tables. In this paper, we will focus onthe route discovery problem as our case study due to itscritical importance in building efficient multi-hop networks.The models and insights obtained from this study can beapplied to the other applications as well. Although, routingin ad hoc networks has a long history of research, thesefundamental issues are still not clearly understood and there
This research was sponsored in part by a grant from the Japan Society forPromotion of Science (JSPS).
978-1-4244-2575-4/08/$20.00 @2008 IEEE
is an obvious lack of analytical models to classify theseproblems.
Many reactive routing protocols ([1], [2], [3], [4]) in mobilead hoc networks (MANETs) use a route discovery processto populate the route table in each node. Upon receiving apacket from the application layer, the protocol, if it does notalready possess a route to the destination, generates a routerequest (RREQ) from source s for destination d. The RREQis broadcast through the network, establishing a route back tos at each node forwarding the RREQ. When d receives theRREQ, it sends a route reply (RREP) along one of the routescreated by the RREQ. The RREP then establishes a route tod. These routes are then cached in the network for a length oftime, in order to be re-used by subsequent connection attempts.
The more valid routes are cached, the fewer RREQs areflooded through the network. Flooding causes negative effectson the network: it consumes a lot of bandwidth; all nodesrelaying the RREQ compete for the wireless medium in asynchronous manner, creating congestion and race conditions.Since flooding the network has adverse consequences [5],increasing the number of cached routes is a valid goal.
One mechanism to increase the number of cached routes isto use path accumulation. A protocol which does not use pathaccumulation, such as AODV [1], includes only informationabout the source s in the RREQ. Thus, the RREQ only setsup routes back to s for the RREQ (and d for the RREP). Pathaccumulation on the other hand requires each node receivingthe RREQ (resp., the RREP) to insert its own identifier in theheader, so that the RREQ (resp., the RREP) now carries thewhole path from s to the node which receives it.
The node which receives the RREQ can thus set up routesin its route table not only for s but for all the nodes onthe path traversed by the RREQ. Figure 1 describes the pathaccumulation process: node A sends a RREQ towards E, whichsends the RREP. Without path accumulation, nodes B, C, Donly discover the path to nodes A and E after completion ofthe RREQIRREP exchange. With path accumulation, all nodesknow a path to all the other nodes.
However, while path accumulation increases the number ofroutes set up by the route discovery process, it also comes atthe expense of a higher overhead: the size of a RREQ or aRREP increases linearly with the number of hops. The tradeoff is thus between the size of the overhead, and the efficiencyof the route discovery process.
The key contribution of this paper is to study the tradeoff between the overhead of the route discovery process,
203

AOOVRREQ
----------_-----------_-----------(0----------8
AOOV-PA RREQ
iEI . ";1\11
to all routing protocols which use a route discovery processwhich floods the network. Our route discovery schemes areorthogonal to most of these reactive routing protocols, and canbe adapted to work with them. The results, while presentedwithin an AODV framework, have an applicability which ismuch wider.
AOOVRREP
AOOV-PA RREP'--1E-.I-o----
Fig. 1. Route Discovery With and Without Path Accumulation
and the acquired knowledge of the network topology. Wewill observe that in relatively stable topologies, the marginalreturn of the route discovery process decreases with pathaccumulation, while the overhead does not. This means thatthe extra bandwidth used by path accumulation brings in fewerroutes as the knowledge of the topology grows, and at somepoint becomes wasteful.
In order to reduce the overhead, but not the efficiency ofthe route discovery process, we then propose a route discoverymechanism which adapts to the knowledge of the topology.Our mechanism, which we call adaptive path accumulation,ensures that the overhead carried by the route discoveryprocess adapts to the gains reaped from the route discoveryprocess. With adaptive path accumulation, as the number ofroutes discovered by the route discovery process decreases, sodoes the amount of bandwidth used by the route discoveryprocess.
The paper is organized as follows. In Section II, we highlight the performance trade-off for the route discovery processand see that, as more is known about the network, less islearned by using path accumulation. We highlight the point atwhich path accumulation starts losing its efficiency, and startsbecoming wasteful. In Section III, we introduce our adaptivepath accumulation mechanism. The mechanism reduces thesize of the RREQ enough to be efficient, and reduce thebandwidth waste. Another tack in the face of diminishingefficiency is to keep the packet size of the RREQ as largeas with path accumulation, but to increase the route discoveryreturn. This is studied in Section IV, where we see how theinformation disseminated by the RREQs can be tailored tomaximize the number of discovered routes. Section V presentsextensive simulation results to validate the mechanisms weintroduced. Section VI and VII present related work andfurther application contexts for our results. Finally, we offersome concluding remarks in Section VIII.
We use AODV as a basis to describe our route discoverymechanisms. AODV is convenient to illustrate our ideas asit is widely known, it is standardized as an experimentalRFC [6], and it offers a variant without path accumulation [1]and one with path accumulation [7]. However, the ideas apply
II. ROUTE DISCOVERY WITH AND WITHOUT PATH
ACCUMULATION
We now describe the route discovery process in more detail,and make explicit the trade-off between path accumulation andits return in terms of discovered routes. We assume in oursimulation and in the mathematical models, that the networkarea is a square. We also assume that the network is connectedand that the nodes are uniformly distributed over the area.
First, we define the efficiency of the route discovery processto be the number of routes established by the route discoveryprocess, normalized by the total number of possible routesin the network. A route here is meant as a directed pair(source,destination). There might be several distinct paths fora packet to go from the source to the destination. However,for our route definition, a route is discovered if anyone pathis discovered from the source to the destination. Discovery offurther paths between the same (source,destination) pair doesnot increase our knowledge of the network with respect tothat route: while it might make the routing qualitatively moreefficient, it does not change our ability to forward a packetfrom the source to the destination.
In a network of n nodes, we thus have n (n - 1) routes inthe network, which we approximate by n 2 , since we considera large network.
We consider the route discovery process at the network layerand ignore MAC layer effects. We assume that the propagationtimes are short with respect to the time scale of the connectionattempts. Namely, connection attempts happen within seconds,while the RREQ crosses the network in milliseconds. Ourmodel considers a time scale of the same order as thetime scale of the connection attempts and thus approximatesRREQs as propagated immediately. We now describe ourreactive routing protocol model. We index quantities with "np"when no path accumulation is used, and with "pa" when £ath~ccumulation is used.
A. Without Path Accumulation
When an application requests a connection, it gives thepacket to the routing layer. The routing protocol then looksup its route table. If there is no route in the route table, thenode s then generates a route request (RREQ) for destinationd.
When no path accumulation is used, the RREQ is thenforwarded to all the neighbors of s. Upon receiving a RREQ,each node sets up, or refreshes, a route back to s in its routetable. Each node then performs a route table look-up, to checkif it has a route to d. If it does, then it issues a route reply(RREP). If it does not, then it re-broadcasts the RREQ, untilthe RREQ eventually reaches d.
204

One key observation from Equation (2) is that the gaindepends on time only through ~np. Knowing ~np is enough tocharacterize the gain in efficiency for the next route request.This ensures that the gain described in Equation (2), and laterin Equation (3), is valid in dynamic networks, provided ~np, orlater ~pa, is known at some snapshot in time. In the remainderof the paper, we drop the reference to time, unless specificallyrequired.
The number of routes established by this route discoveryprocess will be at best n - 1 + h(n), where n is the numberof pairs (k, s) for all the nodes k in the network minus s,and h(n) is the hop count of the route (d, s). Since h(n) isproportional to yri << n under our network assumptions, wecan approximate the maximum number of routes discoveredby a RREQ to be equal to n.
In the general case, some nodes will know where s is, orwhere d is, and the RREQ will not reach all the nodes, andwill not set up a new route at all the nodes it reaches. Theroute discovery process will not discover n new routes, but afraction of n.
Define by TJnp (t) the number of valid routes known at timet by the routing protocol with no path accumulation. TJnp (t) isthe sum of all the distinct valid routes in all the route tablesof all nodes in the network. Define by €np the efficiency ofthe route discovery process:
€np = TJn:. (1)n
The efficiency of a route request corresponds to how manynew routes are discovered by a RREQ issued at time t,knowing €np at time t- prior to t. If at time t-, the efficiency€np (t - ) is known, then the efficiency at time t, after the RREQis issued, is ~np(t) = €np(t-) + b..~np, where b..~np is givenby [8]:
1b..€np = (1 - ~np)-
n(2)
In the best case, the number of routes set up by the RREQwith path accumulation will be at best n times the average pathlength, that is nyri/2 with our model assumptions. Again,the RREQ will not reach all the nodes, as a node might issuea RREP and stop flooding the RREQ. Also, the informationcarried by the RREQ might not be all new to the nodes whichreceives it. For instance, node C might have a route to Aalready, and the RREQ from A to E does not set up a newpath to A. Also, since a flooded packet will follow propagationpaths from one RREQ to the next which overlap, the gainbrought by path accumulation decreases.
Consider Figure 1 again, and assume A now issues a RREQto D, which replies with the RREP. This sets up routes inbetween all the nodes A, B, C and D. If next, B issues aRREQ to E, then the RREQ only add one route, that from Eto B, and the RREP adds routes from B, C and D to E. Thefirst RREQ exchange set up 12 routes, while the second added4. Yet, both used the same amount of bandwidth.
Figure 1 is a peculiar case, as it is a linear network.However, RREQs are broadcast along a broadcast tree! rootedat the source of the RREQ, and each branch of the tree isin essence a linear network. One can see that the broadcasttree of a node A will significantly overlap with that of anothernode B. For instance, as a RREQ is issued by B, it will reachA and be rebroadcast by A. From that point on, it will followa path similar to a broadcast by A, minus the nodes whichhave already received that RREQ from B.
We can similarly define r]pa (t) to be the number of routesdiscovered by the route discovery process at time t, and ~pa (t)to be the corresponding efficiency. [8] expresses a tight fittingapproximation of the variation of efficiency brought by a newRREQ to be:
(3)
B. With Path Accumulation
When path accumulation is used, the RREQ and RREPare generated according to the same rule as described above.The key difference happens in the forwarding of these controlpackets. When a node receives a RREQ issued by s for d, theprocessing is slightly different: it still checks whether it has anentry for d in its route table, and issues the RREP if it does.If it does not, it rebroadcasts the RREQ, but inserting its ownidentifier in the RREQ.
Going back to Figure 1, upon receiving the RREQ, nodeC inserts its own address in the header, so that the RREQ itbroadcasts now contains the path A-B-C, and the RREQ sentby D contains A-B-C-D. The nodes also insert their addressin the RREP, which grows in the same manner as the RREQ.Each node learns the path to all the nodes between itself andthe source of the control packet. For the RREQ, B learns aboutA, C about A and B, D about A, Band C, and E about A,B, C and D. Thus each nodes discovers a number of routesequal to the hop count between itself and the source.
One can see that Equation (3) defines a marginal increasewhich is equal to the marginal increase without path accumulation of Equation (2), plus another term which correspondsto the benefit of path accumulation.
C. Efficiency Trade-Off
Consider two systems, one with path accumulation, and onewithout, on the same underlying network. Assume both havereached the same value ~ = €np = €pa of their respectiveefficiency. This means both systems have the same knowledgeof the topology. As a consequence, a connection request willgenerate a route request with the same probability in bothnetworks. Upon arrival of the next route request, ~np and ~pa
will then evolve according to Equation (2) and (3) respectively.
1This is an implied tree based on the topology of the network, and thepropagation mechanisms; we do not assume the routing protocol actuallymanages such tree, but observe that the path followed by broadcasts issuedby the same node will exhibit a similar tree structure.
205

(4)
(5)
Namely, the gain in efficiency can be written as:
(1 - ~).!.n1 3 1
(1 - ~)~ + (1 -~) 2y'n
When starting from the same efficiency ~, the difference inthe number of new routes discovered by path accumulationversus no path accumulation is thus:
3 1(1 -~) 2y'n
As more is known about the network, ~ goes to 1, andthe gain of path accumulation over route discovery withoutpath accumulation vanishes in equation (5). On the other hand,when little is known about the network, this term is actuallythe dominant term in equation (3), and the gain from pathaccumulation is significant.
Define ~c = 1 - a,. For ~ < ~c, path accumulation
returns significantly more routes than not using path accumulation. As ~ gets bigger than ~c, the efficiency of theroute discovery process with and without path accumulationbecomes equivalent, and thus it is not worth using the extrabandwidth of path accumulation to achieve the same return.
Route Discovery Efficiency for a 100 Nodes Network
1 7 13 19 25 31 37 43 49 55 61 67 73 79 85 91 97
RREQ
Fig. 2. Route Discovery Efficiency for a 100 Nodes Network
Figure 2 depicts the two phases of path accumulation,as well as the match of the models in equation (2) andequation (3) with simulation results. Since we are interestedin the number of routes discovered conditioned on knowinga fraction ~, we simulate a static network with no routedisappearing, and plot the gain after each route request. We useAODV as a protocol without path accumulation, and AODVPA as a protocol with path accumulation.
One can see that equations (2) and (3) provide a goodenough approximation to support our discussion. In particular,we plotted on the graph the asymptotic behavior of theefficiency of route discovery with path accumulation. We seeit converges to a tail phase asymptote which behaves exactlylike AODV, that is, without path accumulation.
In summary, path accumulation is always more efficientto discover routes. But this gain in efficiency diminishes as~ ---t 1, while the extra bandwidth cost does not diminish.What is needed in order to keep a tight lid on the bandwidthoverhead, is to either reduce the bandwidth cost as the efficiency diminishes, or to increase the efficiency while keepingthe same bandwidth cost. These two tacks are the subjects ofthe next two Sections.
III. ADAPTIVE PATH ACCUMULATION
A. Route Discovery Discussion and Requirements
We now present our adaptive path accumulation mechanism.We base our description on AODV, but keep in mind that itis applicable to most route discovery protocols which use asimilar route discovery process. AODV keeps active entries inits route table for a length of time called the Active RouteTime-out (ART). A nicely engineered network will have anART of similar length as the lifetime of routes in the network.
The key observation from Section II is that path accumulation becomes redundant when two RREQs are broadcast alongsimilar broadcast trees within a period of time much shorterthan the ART. In particular, consider the following scenario.Node j receives at time t a RREQ with path accumulation(RREQ-PA) from node l, denoted TI. Assume this RREQ-PAcontains in its header the address of node k. j rebroadcaststhe RREQ-PA TI at time t. At time t + 8t, where 8t < ART,j receives another RREQ-PA containing the address k fromnode i. Denote this RREQ-PA by T2.
When j rebroadcasts the second RREQ-PA T2, it will sendinformation about k twice within the period of time 8t. Nodei will receive T2 again, but will not rebroadcast it, since it hassent T2 to j in the first place. However, neighbors of i alreadyhad received r2 (and thus, information about k) the first timei sent T2. Most other neighbors of j will receive both T2 andTI, and thus duplicate information regarding k.
In any case, the inclusion of k in rebroadcasting r2 does notbring any benefit to the neighbors of j, beside refreshing theroute at time t + 8t. The inclusion of j's own address whenforwarding both T2 and TI however makes a difference. When lreceives TI after j rebroadcasts it, l stops forwarding it, since itjust broadcast a RREQ TI with this sequence number already.l's neighbors thus might not know about j. l does rebroadcastj's version of T2, and l's neighbors learn about j through T2.
SO unlike k's address, even though j's address was broadcastrecently in rl, it is not redundant in T2.
The requirements that we impose on any route discoveryprotocol are as follows:
• Simple: the route discovery process must be a lightweightprotocol in order to be implementable on a mobile adhoc node, which does not necessarily support heavycomputations.
• Scalable: the route discovery process, and the size ofthe control messages in particular, must not grow worsethan the current route discovery mechanisms as the sizen of the network grows. The size of a RREQ with path
206

accumulation grows as Vii, and this sets our upper boundfor our route discovery process.
• Distributed : no additional protocol messages should beintroduced, and each node should be able to participate inthe route discovery process based only on its own localinformation.
• Small Footprint: the state at each node must also be ofthe same order of magnitude as for an AODV route table,with or without path accumulation.
With this framework in mind, we are now ready to describeour route discovery process.
B. APA Protocol
We call our novel route discovery process adaptive pathaccumulation. We focus on the route request rules, but similarrules apply to the route reply. We denote by RREQ-APA aroute request using adaptive path accumulation. We denote bybtj (k) the broadcast time of address k by node j, that is, thelast time that node j broadcast a RREQ-APA which containedthe address k in its path accumulation field.
The structure of the protocol messages is almost identicalto AODV-PA.
The protocol design is thus as follows. Define t to be thecurrent time, and T to be a time threshold such that 0 < T <ART.
• When a node j receives a RREQ-APA r, it looks up allthe addresses inserted in the path accumulation field of rand create/update the corresponding route table entries.The route table entry for the route to k contains anadditional field which holds btj (k). j fills or updates thisfield for all addresses in the path accumulation field ofany RREQ it broadcasts.
• j looks up the sequence number to see if this is a RREQj has already forwarded. If j did forward r previously,it discards the RREQ-APA without further processing. Ifnot, it proceeds to the next item.
• j looks up the route table for a route to the destinationd of the RREQ-APA r. If there is one, then j issues aroute reply. If there is none, then it proceeds as follows.
• For every address k in r's header, j checks if t - btj(k)is above a threshold T. If t - btj (k) > T, then j keeps kin the RREQ-APA. If t - btj(k) < T, then it removes kfrom r.
• j always inserts its own address in the RREQ-APA, andre-broadcasts the updated RREQ-APA r.
The key idea is to avoid the duplication of redundantinformation in the route discovery process. APA prunes outaddresses which have been recently forwarded, and keeps theother addresses. It also delegates the decision to prune its ownaddress to its neighbors. This ensures that the informationis propagated according to different directions, depending onwhich neighbor transmitted the RREQ already.
The parameter T is a function of the ART. We use T =0.8ART in the simulations, so as to refresh nodes only in thelast 20% of time before they expire. However, many decision
rules could be used. For instance, one could toss a coin withprobability min[(t - btj (k)) / ART, 1] to decide to not removek. The value of T should be optimized with respect to the rateof RREQs being issued.
IV. ADAPTIVE PATH ACCUMULATION VARIANTS
A. APA-h
We introduce now a different version of adaptive pathaccumulation, which attempts not to reduce the size of theRREQ packet, but to increase its efficiency in discovering newroutes. The idea is again to identify the addresses which couldbe redundant in the RREQ header, but instead of pruning themout, we replace them with addresses which are not redundant.We denote it by APA-h, as it keeps the size of the pathaccumulation field in the header of length proportional tothe hop count. Unlike path accumulation, APA-h selects theaddresses it includes in the RREQ header, instead of the choicebeing imposed by the path followed by the RREQ.
Since the validity of the route inserted in the header isnot probed by the RREQ, a mechanism has to be devised topropagate an indication of the route's freshness. We appenda new field in so that addresses in the path accumulation listare now replaced by a pair (address,age). The age is a bytefield which indicates which percentile of its ART the routehad lived through at the node which inserts the address inthe RREQ-APA-h. A pair (k,70%) inserted by node j meansthat j has last refreshed k in its route table for a time equalto 0.7ART. This field is used to set the value of the ART atthe nodes which receive the RREQ-APA-h to be consistent. Anode which receives (k,70%) will enter k in its route table,but will pro-rate the ART so that the route expires in O.3ART.
The age parameter is needed to keep active routes atdifferent nodes synchronized and is important for the correctoperation of APA. Ignoring this parameter has shown a significant drop in delivery rate, due to nodes forwarding packetsbased on routes that expired at their neighbors. The overheadof this field is a single byte and is included in the simulations.
APA-h has overhead close to adaptive path accumulation,but without wasting the overhead bandwidth to retransmitduplicate information.
The protocol is as follows:
• When a node j receives a RREQ-APA-h r, it looksup all the addresses inserted in r and create/update thecorresponding route table entries. The route table entryfor the route to k contains an additional field which holdsbtj (k).
• j looks up the sequence number to see if its a RREQ ithas already forwarded. If it did, it discards the RREQAPA-h without further processing. If not, it proceeds tothe next item.
• j looks up the route table for a route to the destinationd of the RREQ-APA-h r. If there is one, then j issues aroute reply. If there is none, then it proceeds as follows.
• For every address k in r's header, j checks at time t ift - btj(k) is above a threshold T. If t - btj(k) > T, then
207
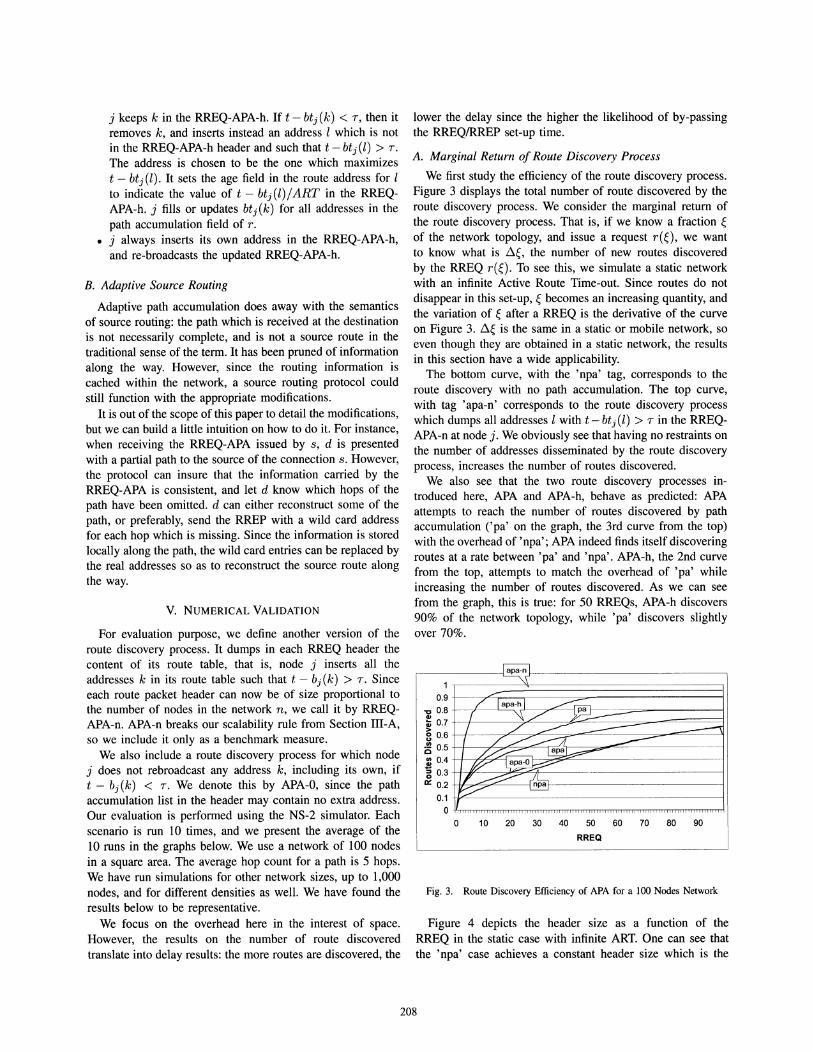
Fig. 3. Route Discovery Efficiency of APA for a 100 Nodes Network
10 20 30 40 50 60 70 80 90
RREQ
j keeps k in the RREQ-APA-h. If t - btj(k) < T, then itremoves k, and inserts instead an address 1 which is notin the RREQ-APA-h header and such that t - btj(l) > T.
The address is chosen to be the one which maximizest - btj (l). It sets the age field in the route address for 1to indicate the value of t - btj (l) / ART in the RREQAPA-h. j fills or updates btj (k) for all addresses in thepath accumulation field of r.
• j always inserts its own address in the RREQ-APA-h,and re-broadcasts the updated RREQ-APA-h.
B. Adaptive Source Routing
Adaptive path accumulation does away with the semanticsof source routing: the path which is received at the destinationis not necessarily complete, and is not a source route in thetraditional sense of the term. It has been pruned of informationalong the way. However, since the routing information iscached within the network, a source routing protocol couldstill function with the appropriate modifications.
It is out of the scope of this paper to detail the modifications,but we can build a little intuition on how to do it. For instance,when receiving the RREQ-APA issued by s, d is presentedwith a partial path to the source of the connection s. However,the protocol can insure that the information carried by theRREQ-APA is consistent, and let d know which hops of thepath have been omitted. d can either reconstruct some of thepath, or preferably, send the RREP with a wild card addressfor each hop which is missing. Since the information is storedlocally along the path, the wild card entries can be replaced bythe real addresses so as to reconstruct the source route alongthe way.
V. NUMERICAL VALIDATION
For evaluation purpose, we define another version of theroute discovery process. It dumps in each RREQ header thecontent of its route table, that is, node j inserts all theaddresses k in its route table such that t - bj (k) > T. Sinceeach route packet header can now be of size proportional tothe number of nodes in the network n, we call it by RREQAPA-n. APA-n breaks our scalability rule from Section III-A,so we include it only as a benchmark measure.
We also include a route discovery process for which nodej does not rebroadcast any address k, including its own, ift - bj(k) < T. We denote this by APA-O, since the pathaccumulation list in the header may contain no extra address.Our evaluation is performed using the NS-2 simulator. Eachscenario is run 10 times, and we present the average of the10 runs in the graphs below. We use a network of 100 nodesin a square area. The average hop count for a path is 5 hops.We have run simulations for other network sizes, up to 1,000nodes, and for different densities as well. We have found theresults below to be representative.
We focus on the overhead here in the interest of space.However, the results on the number of route discoveredtranslate into delay results: the more routes are discovered, the
lower the delay since the higher the likelihood of by-passingthe RREQIRREP set-up time.
A. Marginal Return of Route Discovery Process
We first study the efficiency of the route discovery process.Figure 3 displays the total number of route discovered by theroute discovery process. We consider the marginal return ofthe route discovery process. That is, if we know a fraction ~
of the network topology, and issue a request r(~), we wantto know what is ~~, the number of new routes discoveredby the RREQ r(~). To see this, we simulate a static networkwith an infinite Active Route Time-out. Since routes do notdisappear in this set-up, ~ becomes an increasing quantity, andthe variation of ~ after a RREQ is the derivative of the curveon Figure 3. ~~ is the same in a static or mobile network, soeven though they are obtained in a static network, the resultsin this section have a wide applicability.
The bottom curve, with the 'npa' tag, corresponds to theroute discovery with no path accumulation. The top curve,with tag 'apa-n' corresponds to the route discovery processwhich dumps all addresses 1with t - btj (l) > T in the RREQAPA-n at node j. We obviously see that having no restraints onthe number of addresses disseminated by the route discoveryprocess, increases the number of routes discovered.
We also see that the two route discovery processes introduced here, APA and APA-h, behave as predicted: APAattempts to reach the number of routes discovered by pathaccumulation Cpa' on the graph, the 3rd curve from the top)with the overhead of 'npa'; APA indeed finds itself discoveringroutes at a rate between 'pa' and 'npa'. APA-h, the 2nd curvefrom the top, attempts to match the overhead of 'pa' whileincreasing the number of routes discovered. As we can seefrom the graph, this is true: for 50 RREQs, APA-h discovers90% of the network topology, while 'pa' discovers slightlyover 70%.
1-,------~----------------,
0.9 +--~~=..--------==-----------1"C 0.8 --+--------T----L..----". r'----7""'-------l
~ 0.7 +--J----------=-~--__?~=---______:::::;;o;-~:::=:=======l
80.6 -+------I'---------7'''-------~'''''--------_=__'=------______:::::;;o;~=-----______'I
is 0.5 +-----f--~~~~___r_~t_--------=....."".,,=--------__1
:: 0.4~ 0.3 ++---I/----=~~/I------------------j0:: 0.2 -+--t+-~~=--------l
0.1 -+-V"---------------------I
OiTIn"1TrTTTITTTTTTTTmTnITTTTTITTTTTTTTmTnrTTTT1TTTTTTITTTTTTTTmTnTrTnTTTTTTITTTTTTTTrTTTTTT"1
o
Figure 4 depicts the header size as a function of theRREQ in the static case with infinite ART. One can see thatthe 'npa' case achieves a constant header size which is the
208
90
8060
RREQ
4020
4"'C
: 3.5.c
~ 3
~ 2.5CD
~ 2
~ 1.5
~ 1 ~&_-==============================ta'-==================r-
~ 0.5 r-~----=~~~~~~~~~~~~~~~~
,---- 0.45.---------------------,
0.4 ~~;;;:::::-------------==--=~
0.35 ~;;;::---~~~~~~;=======._-_____i.,
0.3 ~~---=s-==:::::~~~~~~---=:::=:::::::::::~:::=1
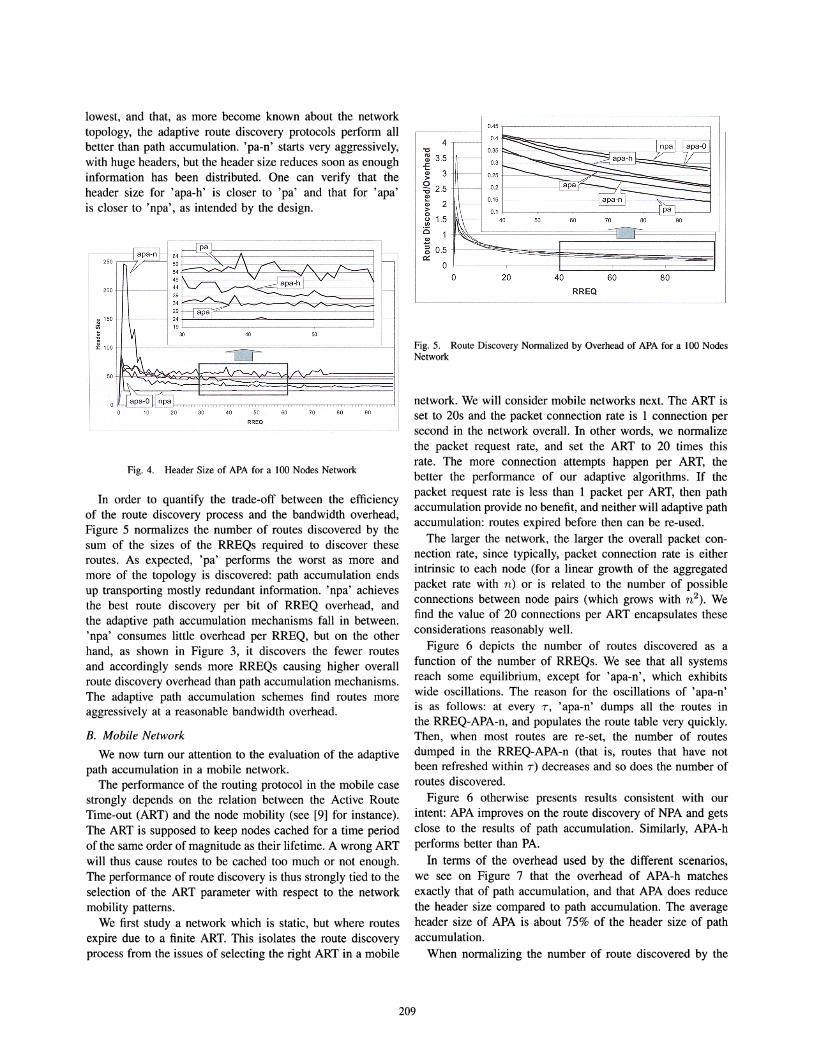
Fig. 5. Route Discovery Nonnalized by Overhead of APA for a 100 NodesNetwork
network. We will consider mobile networks next. The ART isset to 20s and the packet connection rate is 1 connection persecond in the network overall. In other words, we normalizethe packet request rate, and set the ART to 20 times thisrate. The more connection attempts happen per ART, thebetter the performance of our adaptive algorithms. If thepacket request rate is less than 1 packet per ART, then pathaccumulation provide no benefit, and neither will adaptive pathaccumulation: routes expired before then can be re-used.
The larger the network, the larger the overall packet connection rate, since typically, packet connection rate is eitherintrinsic to each node (for a linear growth of the aggregatedpacket rate with n) or is related to the number of possibleconnections between node pairs (which grows with n 2 ). Wefind the value of 20 connections per ART encapsulates theseconsiderations reasonably well.
Figure 6 depicts the number of routes discovered as afunction of the number of RREQs. We see that all systemsreach some equilibrium, except for 'apa-n', which exhibitswide oscillations. The reason for the oscillations of 'apa-n'is as follows: at every T, 'apa-n' dumps all the routes inthe RREQ-APA-n, and populates the route table very quickly.Then, when most routes are re-set, the number of routesdumped in the RREQ-APA-n (that is, routes that have notbeen refreshed within T) decreases and so does the number ofroutes discovered.
Figure 6 otherwise presents results consistent with ourintent: APA improves on the route discovery of NPA and getsclose to the results of path accumulation. Similarly, APA-hperforms better than PA.
In terms of the overhead used by the different scenarios,we see on Figure 7 that the overhead of APA-h matchesexactly that of path accumulation, and that APA does reducethe header size compared to path accumulation. The averageheader size of APA is about 75% of the header size of pathaccumulation.
When normalizing the number of route discovered by the
90807040 50 60
RREQ
302010
Fig. 4. Header Size of APA for a 100 Nodes Network
200+-++-------1
250
u 150 +-+-t-------1
c5i"g
::E: 100 ++-----\------':===============~===========================~---J
In order to quantify the trade-off between the efficiencyof the route discovery process and the bandwidth overhead,Figure 5 normalizes the number of routes discovered by thesum of the sizes of the RREQs required to discover theseroutes. As expected, 'pa' performs the worst as more andmore of the topology is discovered: path accumulation endsup transporting mostly redundant information. 'npa' achievesthe best route discovery per bit of RREQ overhead, andthe adaptive path accumulation mechanisms fall in between.'npa' consumes little overhead per RREQ, but on the otherhand, as shown in Figure 3, it discovers the fewer routesand accordingly sends more RREQs causing higher overallroute discovery overhead than path accumulation mechanisms.The adaptive path accumulation schemes find routes moreaggressively at a reasonable bandwidth overhead.
B. Mobile Network
We now tum our attention to the evaluation of the adaptivepath accumulation in a mobile network.
The performance of the routing protocol in the mobile casestrongly depends on the relation between the Active RouteTime-out (ART) and the node mobility (see [9] for instance).The ART is supposed to keep nodes cached for a time periodof the same order of magnitude as their lifetime. A wrong ARTwill thus cause routes to be cached too much or not enough.The performance of route discovery is thus strongly tied to theselection of the ART parameter with respect to the networkmobility patterns.
We first study a network which is static, but where routesexpire due to a finite ART. This isolates the route discoveryprocess from the issues of selecting the right ART in a mobile
lowest, and that, as more become known about the networktopology, the adaptive route discovery protocols perform allbetter than path accumulation. 'pa-n' starts very aggressively,with huge headers, but the header size reduces soon as enoughinformation has been distributed. One can verify that theheader size for 'apa-h' is closer to 'pa' and that for 'apa'is closer to 'npa', as intended by the design.
209
0.3 ~----------------------,
0.05 +W-I--_1J.__-------l \----------j
0.25 +-----&----'\/-----1~-----------_1
9080706050
RREQ
40302010
1.------------------------,
0.9 -l-------------------------i
"t:J 0.8CP~ 0.7 -l--~~=-----------------------i
80.6 +--I---\--------------j
is 0.5 +---+---+--'----, ~--+-4.~--~+----/~--;:--~--~_______==____-_____1
=0.4 +-+-------j~;:k¥-_+_-___\___::___/;;.~~~_d_~~~~~-~~"c1
~ 0.3 -+---l----lU-+-------}J~==_~~~~~~~~~""""""'~~~~=l
~ 0.2 llJ~~~~~~~~~~~:::::::::~~~=::======::::::::~
0.1 -+-bo""-----------j
O-t'rrrTITTTrrmTT1TITrTTlTTTTl~rTTTTm=n=ITrnrrmTTTT1TTTT1TTTTrTTTTTTTTTTTITTTTITTTTTT1'"TTm_,_,_rl
o
RREQ
Fig. 6. Route Discovery Efficiency of APA for a 100 Nodes Network, Fig. 8. Route Discovery Nonnalized by Overhead of APA for a 100 NodesART=20s Network, ART=20s
10 20 30 40 50 60 70 80 90
RREQ
0.05 -+J-....------===-------------_
O-t'rn-nTTTmrrmrnmTllmTllTrrT1TTTT1TITTTTITTTTTTTTTTITTTTTTTTTTTTnTTTnTTTrTTTTlrTTTTlmTllTTT"T1
o
0.35 --.----..---------------.---,
0.3"t:J
~ 0.25 +-It-------j~~f____H_----f+---H-++-l+_-jH______f_1k________+_+__I I-------I--\--J-+--.-I---\-------Ij
>8 0.2 ++-!~~~ol::I---I+-~~~-f----L\I-__\._I______\_I_+~_+\___N~-~--+--J,~VI
~ 0.15 +J.i'~~\d-----,...__\__}~~~~~~~~~¥_____=_..y!~~~~~oSg 0.1-1-11-~~
~
4030
150 +-+-t--I\------I-»+-------I---------===--~_1
250
200 +-----J.-II------t------------------l
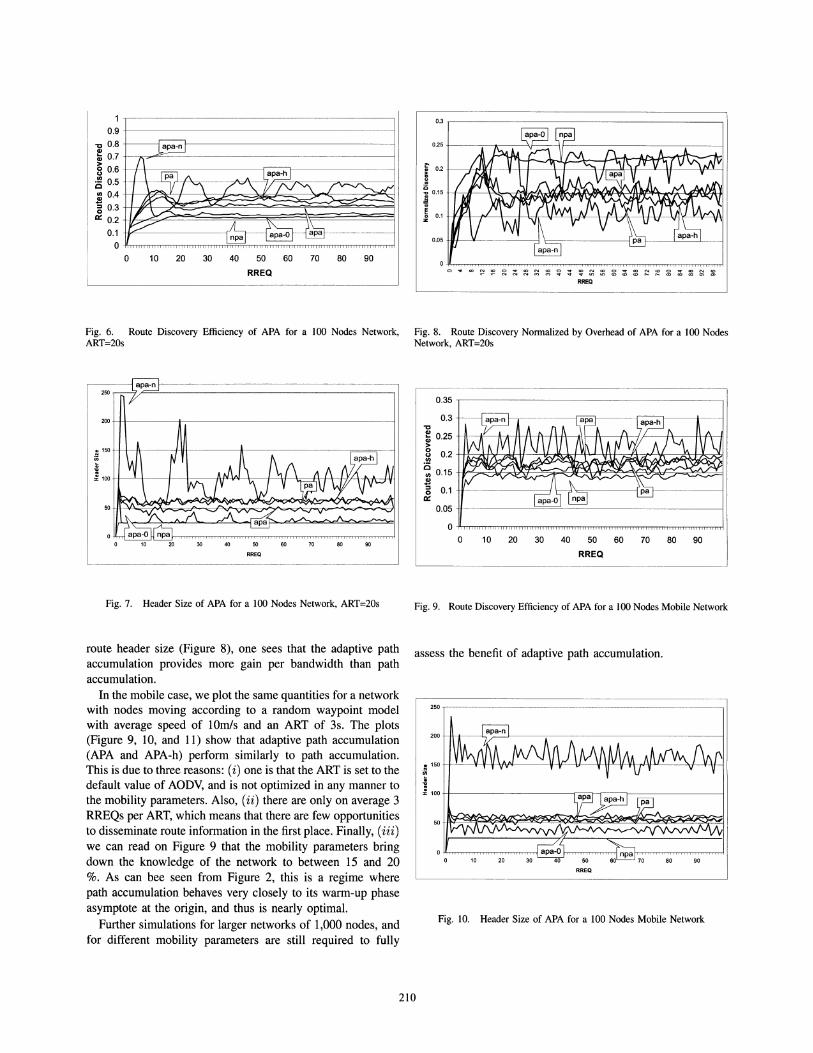
Fig. 7. Header Size of APA for a 100 Nodes Network, ART=20s Fig. 9. Route Discovery Efficiency of APA for a 100 Nodes Mobile Network
route header size (Figure 8), one sees that the adaptive pathaccumulation provides more gain per bandwidth than pathaccumulation.
In the mobile case, we plot the same quantities for a networkwith nodes moving according to a random waypoint modelwith average speed of 10mls and an ART of 3s. The plots(Figure 9, 10, and 11) show that adaptive path accumulation(APA and APA-h) perform similarly to path accumulation.This is due to three reasons: (i) one is that the ART is set to thedefault value of AODV, and is not optimized in any manner tothe mobility parameters. Also, (ii) there are only on average 3RREQs per ART, which means that there are few opportunitiesto disseminate route information in the first place. Finally, (iii)we can read on Figure 9 that the mobility parameters bringdown the knowledge of the network to between 15 and 20%. As can bee seen from Figure 2, this is a regime wherepath accumulation behaves very closely to its warm-up phaseasymptote at the origin, and thus is nearly optimal.
Further simulations for larger networks of 1,000 nodes, andfor different mobility parameters are still required to fully
assess the benefit of adaptive path accumulation.
250 , - - - - - ···························1
200 +--H-+--~ _J---------------------J
100 +-t-------------r-::----r--,---;.--------_1
Fig. 10. Header Size of APA for a 100 Nodes Mobile Network
210

0.16,------------------j
0.02 -a-----------=J I-----------------j
RREQ
Fig. 11. Route Discovery Nonnalized by Overhead of APA for a 100 NodesMobile Network
VI. RELATED WORK
The design of reactive routing protocols [1], [2], [3], [4]did not explicitly focus on improving the efficiency of routediscovery. A similar route discovery process is used in theseprotocols, but the route discovery mechanism is, to the bestof our knowledge, never addressed in any systematic way.Proactive routing protocols, which includes such protocols asOLSR [10], DSDV [11] or WRP [12], do not discover thetopology, but maintain it: the topology is assumed to be knownat all times, and the protocols attempt to update the route statebased on link breaks as they happen.
The overhead of ad hoc routing protocols has been coveredmostly within comparisons of the performance of reactive vs.proactive (see for instance [13], [14], [15], [16], [17]). Ourresults focus on reducing the overhead of reactive protocols.Other relatively recent results [18], [19] analyze the overheadof proactive protocols.
How long reactive routing protocols should keep a pathactive in the route table is a key issue for path accumulationin general, and adaptive path accumulation in particular: themore efficient the route discovery, the more paths are cached,and the more carefully the ART should be defined [9], [20],[21], [22]. A more efficient route discovery process increasesthe burden on setting the right ART, since more routes aremaintained at any node. We conjecture that different adaptivepath accumulation schemes should determinate different ARTvalues, all other parameters being equal.
A related topic is to estimate the lifetime of a route in amobile network, which is another area which has motivatedsome work [23], [24], [25]. Keeping paths too long leads tohaving stale states in the route table, and to packets beingsent on invalid paths. This generates route errors and createmore overhead. Our study of the overhead currently ignoresthe issue of route errors (RERR) and path breaks.
Hierarchical protocols [26], [27] give a different weight toinformation based on its proximity. They organize the routediscovery in a more scalable manner, which would lead to
a lower overhead. Our study focused initially on AODV andDSR-like protocol, but we intend to see if the relationshipbased on proximity has an impact on the routes that wecan select in APA-h. The backbone of a hierarchical networkmight replicate the information dissemination mechanism overa subgraph of the entire network, and in some contexts, ourresults apply to the embedded subgraph.
Doing away with the route discovery process altogetherhas been considered in [28]. However, it is replaced by theproactive maintenance of a routing overlay, which also comesat a cost. It would be interesting to see if the motivationfor replacing the route discovery process with a distributedhash table-like mechanism still holds when the route discoveryprocess is optimized.
VII. FURTHER ApPLICATIONS
While route discovery is a practical problem of paramountimportance in ad hoc networks, our analysis and protocolsapply to other problems in multi-hop networks where similarsituations arise.
Publish/Subscribe: Publish/Subscribe is a well-knownparadigm for many avenues including wireless multi-hop networks [29], [30], [31]. The idea is mainly used in applicationswhere nodes offering services or resources, announce theirservices by flooding their information through the networkor send it to a set of specific servers. Nodes interested inthe service or resource, access and use this information whenneeded. It is obvious that our model of route discovery can bemapped to the publish operation, where nodes forwarding thepublish request can choose between adding their informationto these requests or not, creating similar tradeoff betweenlarger packet overheads and submitting new requests.
Information Dissemination in Sensor Networks: Information dissemination is an important problem in sensor networkswhere a large amount of data gathered needs to be delivered oraccessed [32], [33], [34]. There was significant research donein this area recently on how to aggregate this data efficiently,preserving the network resources. Similar issues to our modelarise in this problem, where path accumulation can be mappedto data aggregation in general, and the goal is to find the rightbalance between aggregating more information in a singlepacket and sending more packets when needed.
Location Services: Location services used for locatingnodes across the network are an important component ingeographic protocols (e.g. geographic routing) and variouslocation-based services in general [35], [36]. The basic mechanism is for nodes to relay their current information so thatother nodes can reach them when needed. Relevant to ourwork, the route discovery in this case will become locationdiscovery, where the. tradeoff will be between how muchlocation information propagated and stored at intermediatenode to avoid later expensive location searches.
VIII. CONCLUSIONS
We have observed that the route discovery process inreactive routing in ad hoc networks can be approximated by an
211

analytical model which matches very closely the behavior of asimulated system. From the model, as well as from observingsimulations, we see that the benefit of path accumulation inthe route discovery process vanishes as the knowledge of thenetwork topology increase.
This has lead us to define two adaptive path accumulationmechanisms: one mechanism attempts to keep the same routediscovery efficiency of path accumulation, but decrease theoverhead. We called this adaptive path accumulation, APA.The other mechanism intends to keep the overhead of pathaccumulation, but increase the efficiency. Since the overheadof this mechanism stays proportional to the hop count traversedby the RREQ, we call this mechanism APA-h. Both mechanisms are lightweight, distributed, of similar complexity toAODV, and with the same scalability properties as AODV-PA.
We have simulated these mechanisms against AODV andAODV-PA, and we see that these mechanisms meet the designgoals: APA is close to PA in efficiency, but with loweroverhead, while APA-h is close to PA in overhead, but withhigher efficiency.
Future work includes studying the relationship of other protocol parameters with the difference in performance achievedby the adaptive path accumulation. In particular, the relationship of T with respect to the ART, and the relationship of theART with respect to the different flavors of path accumulation,offer many research challenges.
REFERENCES
[1] C. Perkins, E. Royer, Ad hoc On-Demand Distance Vector Routing.Proceedings of the 2nd IEEE Workshop on Mobile Computing Systemsand Applications, New Orleans, LA, February 1999, pp. 90-100.
[2] D. Johnson, D. Maltz and Y.-C. Hu, The Dynamic Source RoutingProtocol for Mobile Ad Hoc Networks (DSR) , IETF MANET workinggroup, draft-ietf-manet-dsr-l0.txt, work in progress, July 2004.
[3] I. Chakeres, C. Perkins, Dynamic MANET On-demand Routing Protocol.IETF Internet Draft, draft-ietf-manet-dymo-06.txt, October 2006.
[4] H. Rangarajan, J.1. Garcia-Luna-Aceves, Using Labeled Paths for Loopfree On-Demand Routing in Ad Hoc Networks, in Proc. MobiHoc'04,Tokyo, Japan, May 2004.
[5] S.-Y. Ni, Y.-C. Tseng, Y.-S. Chen and J.-P. Sheu, The Broadcast StonnProblem in a Mobile Ad Hoc Network in Proceedings of the 5thannual ACMlIEEE international conference on Mobile computing andnetworking, pp.151-62, 1999.
[6] C. Perkins, E. Belding-Royer, S. Das, Ad Hoc On Demand DistanceVector (AODV) Routing. IETF RFC 3561, July 2003.
[7] S. Gwalani, E. Belding-Royer, C. Perkins, AODV-PA: AODV with PathAccumulation in Proc. of IEEE ICC'03.
[8] C. Westphal, K. Seada, C. Perkins, R. Wakikawa, A Study of the RouteDiscovery Process in Reactive MANETs Technical Report 11/2007,available at http://people.nokia.net/cedriclPapers/routediscover.pdf
[9] B. Liang, Z. Haas, Optimizing Route Cache Lifetime in Ad Hoc Networksin Proc. of IEEE Infocom'03.
[10] T. Clausen, P. Jacquet, Optimized Link State Routing Protocol (OLSR),IETF RFC3626, Experimental Standard, October 2003.
[11] C. Perkins, P. Bhagwat, Highly Dynamic Destination-SequencedDistance-Vector Routing (DSDV) for Mobile Computers, ACM ComputerCommunications Review, vol. 24, no.4, pp.234-44, Oct. 1994.
[12] S. Murthy, J.1. Garcia-Luna-Aceves, An Efficient Routing Protocol forWireless Networks, ACM Mobile Networks and Applications Journal,Special Issue on Routing in Mobile Communication Networks, Oct. 1996.
[13] 1. Broch, D. A. Maltz, D. B. Johnson, Y.-C. Hu, and 1. Jetcheva. APerformance Comparison ofMulti-Hop Wireless Ad Hoc Network RoutingProtocols. In Proc. of ACM MobiCom'98, Dallas, TX, October 1998.
[14] S. Das, R. Castafieda, 1. Yan, R. Sengupta, Comparative PerformanceEvaluation of Routing Protocols for Mobile Ad Hoc Networks, in Proc.of IC3N, 1998, pp. 153-61.
[15] P. Johansson, T. Larsson, N. Hedman, B. Mielczarek, M. Degermark,Scenario-based perfonnance analysis of routing protocols for mobile adhoc networks, in Proc. ACMIIEEE Mobicom'99, pp.195-206.
[16] E. Borgia, Experimental Evaluation of Ad Hoc Routing Protocols inProc. of IEEE PerCom'05 workshops.
[17] S. Das, C. Perkins, E. Royer, M. Marina. Perfonnance Comparison ofTwo On-demand Routing Protocols for Ad hoc Networks. IEEE PersonalCommunications Magazine February 2001, pp. 16-28.
[18] X. Wu, H. Sadjadpour, J.1. Garcia-Luna-Aceves, Routing Overhead asa Function of Node Mobility: Modeling Framework and Implications onProactive Routing in Proc. IEEE MASS'07, Pisa, Italy, October 2007.
[19] N. Zhou and A.A. Abouzeid, Infonnation Theoretic Analysis ofProactive Routing Overhead in Mobile Ad Hoc Networks to appear inIEEE Transactions on Information Theory.
[20] Y.-C. Hu, D. Johnson, Caching Strategies in On-Demand RoutingProtocols for Wireless Networks in Proc. of ACM Mobicom'oo, August2000, pp. 231-42.
[21] W. Lou, Y. Fang, Predictive Caching Strategy for On-Demand RoutingProtocols in Ad Hoc Networks in ACM Wireless Networks, Vol.8, No.6, pp 671-9, November 2002.
[22] N. Zhou, A. Abuzeid, Infonnation-Theoretic Bounds for Mobile AdHoc Netwoks Routing Protocols in Lecture Notes in Computer Science:Information Networking, vol. 2662, pp. 651-661, October 2003.
[23] F. Bai, N. Sadagopan, B. Krishnamachari, A. Helmy, Modeling PathDuration Distributions in MANETs and their Impact on Routing Performance, IEEE JSAC, Vol. 22, No.7, pp. 1357-73, Sept. 2004.
[24] Y. Han, R. La, A. Makowski, S. Lee, Distribution of Path Durations inMobile Ad Hoc Networks -Palm's Theorem to the Rescue in ComputerNetworks (Special Issue on Network Modeling and Simulation), Vol. 50,Issue 12 (August 2006), pp. 1887-900.
[25] R. La, Y. Han, Distribution of Path Durations in Mobile Ad-hocNetworks and Path Selection, in IEEE!ACM Transactions on Networking,vol 15, No.5, October 2007, pp.993-1oo6.
[26] C.-C. Chiang, G. Pei, M. Gerla, T.-W. Chen, Scalable Routing Strategiesfor Ad Hoc Wireless Networks, IEEE Journal on Selected Areas inCommunications, vol. 17, pp. 1369-79, 1999.
[27] G. Pei, M. Gerla, T.-W. Chen, Fisheye State Routing: A Routing Schemefor Ad Hoc Wireless Networks, in Proc. of IEEE ICC'OO, June 2000.
[28] M. Caesar, M. Castro, E. Nightingale, G. O'Shea, A. Rowstron, VirtualRing Routing: Network Routing Inspired by DHTs in Proc. of ACMSIGCOMM'06, Pisa, Italy, pp.351-62.
[29] Y. Huang, H. Garcia-Molina, Publish/Subscribe Tree Construction inWireless Ad-Hoc Networks, in Proc. of the 4th International Conferenceon Mobile Data Management (MDM), 2003.
[30] P. Costa, C. Mascolo, M. Musolesi and G. P. Picco, Socially-aware Routing for Publish-Subscribe in Delay-tolerant Mobile Ad Hoc Networks, inIEEE Journal on Selected Areas in Communications. To Appear.
[31] K. Seada and A. Helmy, Rendezvous Regions: a Scalable Architecturefor Service Location and Data-centric Storage in lLlrge-scale WirelessNetworks, in Proc. of the IEEE!ACM IPDPS 4th International Workshopon Algorithms for Wireless, Mobile, Ad Hoc and Sensor Networks(WMAN), April 2004.
[32] T. Abdelzaher, Y. Anokwa, P. Boda, 1. Burke, D. Estrin, L. Guibas, A.Kansal, S. Madden, and 1. Reich, Mobiscopes for Human Spaces, inIEEE Pervasive Computing - Mobile and Ubiquitous Systems, Vol. 6,No.2, April - June 2007.
[33] A. Parker, S. Reddy, T. Schmid, G. Saurabh, D. Chang, 1. Burke, M.Hansen, M. Srivastava, D. Estrin, V. Paxson, and M. Allman. NetworkSystem Challenges in Selective Sharing and Verification for Personal ,Social, and Urban-Scale Sensing Applications, in Proc. of the FifthWorkshop on Hot Topics in Networks (HotNets-V), November 2006.
[34] J. Heidemann, F. Silva, and D. Estrin, Matching Data DisseminationAlgorithms to Application Requirements, in Proc. ACM SenSys'03.
[35] S.M. Das, H. Pucha, Y. C. Hu, Perfonnance Comparison ofScalable Location Services for Geographic Ad Hoc Routing, in Proc. INFOCOM'05,March 2005.
[36] 1. Li, 1. Jannotti, D. Couto, D. Karger, R. Morris, A Scalable LocationService for Geographic Ad-Hoc Routing, in Proc. ACM MOBICOM'oo.
212





![A Novel Hybrid Routing Protocol for Mobile Adhoc Network · A Novel Hybrid Routing Protocol for Mobile Adhoc Network ... routing overhead, ... Reactive routing protocol [2, 8, 9]](https://static.fdocuments.us/doc/165x107/5ac806c47f8b9a42358bf340/a-novel-hybrid-routing-protocol-for-mobile-adhoc-network-novel-hybrid-routing-protocol.jpg)












