
20150425 experimenting with openstack sahara on docker
35
-
Upload
wei-ting-chen -
Category
Technology
-
view
58 -
download
6
Transcript of 20150425 experimenting with openstack sahara on docker

Big Data Technologies
Experimenting with Openstack Sahara on Docker
Weiting Chen

BIG DATA TECHNOLOGY
Legal Disclaimers
No license (express or implied, by estoppel or otherwise) to any intellectual property rights is granted by this document.Intel disclaims all express and implied warranties, including without limitation, the implied warranties of merchantability, fitness for a particular purpose, and non-infringement, as well as any warranty arising from course of performance, course of dealing, or usage in trade.This document contains information on products, services and/or processes in development. All information provided here is subject to change without notice. Contact your Intel representative to obtain the latest forecast, schedule, specifications and roadmaps.The products and services described may contain defects or errors known as errata which may cause deviations from published specifications. Current characterized errata are available on request.
© 2015 Intel Corporation.

BIG DATA TECHNOLOGY
Agenda
Background
How to use Docker with Sahara
Performance Testing
Conclusion

BIG DATA TECHNOLOGY
Who We AreWe are from Intel Big Data Technology Group.
We push big data technology forward into OpenStack
We contribute Sahara source code in OpenStack, bring Cloudera CDH 5.3 plugin in Kilo.

BIG DATA TECHNOLOGY
Sahara Background
• Sahara becomes a core project in Juno
• Bring Hadoop into OpenStack
• Add more features to Kilo release
• Two Key Features
1. To provide users easily provisioning Hadoop clusters by specifying several parameters
2. Analytics as a Service for data scientist or analyst

BIG DATA TECHNOLOGY
Sahara Key Features - Provision Cluster
Create/Terminate Cluster
• Heat API/Nova Direct API
• Integrate with Neutron/Nova Network
• Use Guide as a template
• Anti-affinity
Cluster Scaling
• Add Node/Remove Node
Support More Plugins in Kilo
• Vanilla/Hortonworks Data Platform/Cloudera/Spark/MapR/Storm

BIG DATA TECHNOLOGY
Sahara Key Features - Elastic Data Processing
Support Job Type
• Hive/Pig/MapReduce/MapReduce Streaming/Java/Spark/Shell/HBase
Support Data Locality
• Rack/Hypervisor/Swift
Data Source
• Internal: Internal HDFS(Ephemeral Disk/Cinder)
• External: Swift/HDFS
Run Job in Transient Cluster
*Different Plugin provide different capabilities

BIG DATA TECHNOLOGY
Sahara Working Flow
Fast Cluster Provisioning
Select Hadoop Version
Select Base Image w/ Hadoop
Define Cluster
Configuration
Provision Cluster
Operate Cluster
Terminate Cluster
Analytic as a Service using Elastic Data Processing
Select Hadoop Version
Configure JobsSet Limit for Cluster
Execute Jobs Get The Result
• Choose type of the job: pig, hive, jar-file, etc.• Select input and output data location (Swift support)• Cluster will be removed automatically after the job completion
• Provide the details Hadoop configuration, like size, topology, and others• Sahara will provision VMs, install and configure Hadoop• Support Scale out Cluster to add/remove nodes

BIG DATA TECHNOLOGY
Sahara Data Processing
Swift
OpenStack
Virtual Clusters
OpenStack
Virtual Clusters
HDFS
Collector Agent
Data Stream
Pattern 2: External - SwiftPattern 1: Internal - HDFS Only
Collector Agent
Collecting DataCollecting Data
OpenStack use Swift as a data source to store input and output data. The benefit is to process the data directly and persist the data via Swift.
OpenStack support to create HDFS on Cinder or Ephemeral Disk. This method can provide a better data processing performance via Ephemeral Disk or to persist the data via Cinder with lower performance.
Cinder
Ephemeral Disk
MapReduce MapReduce

BIG DATA TECHNOLOGY
Docker Background
• An open source project
• The latest version is v1.6
• Automates the deployment of applications inside software containers
• Provide fast and application portability
• Use libcontainer library to use virtualization facilities from Linux kernel
• Resource isolation using cgroups, kernel namespaces, …etc

BIG DATA TECHNOLOGY
Sahara + Docker
• Deliver Better Performance (compare with hypervisors)
• Optimize Resource Utilization
• Reduce Cost
• Fast Deployment
BIG DATA TECHNOLOGY
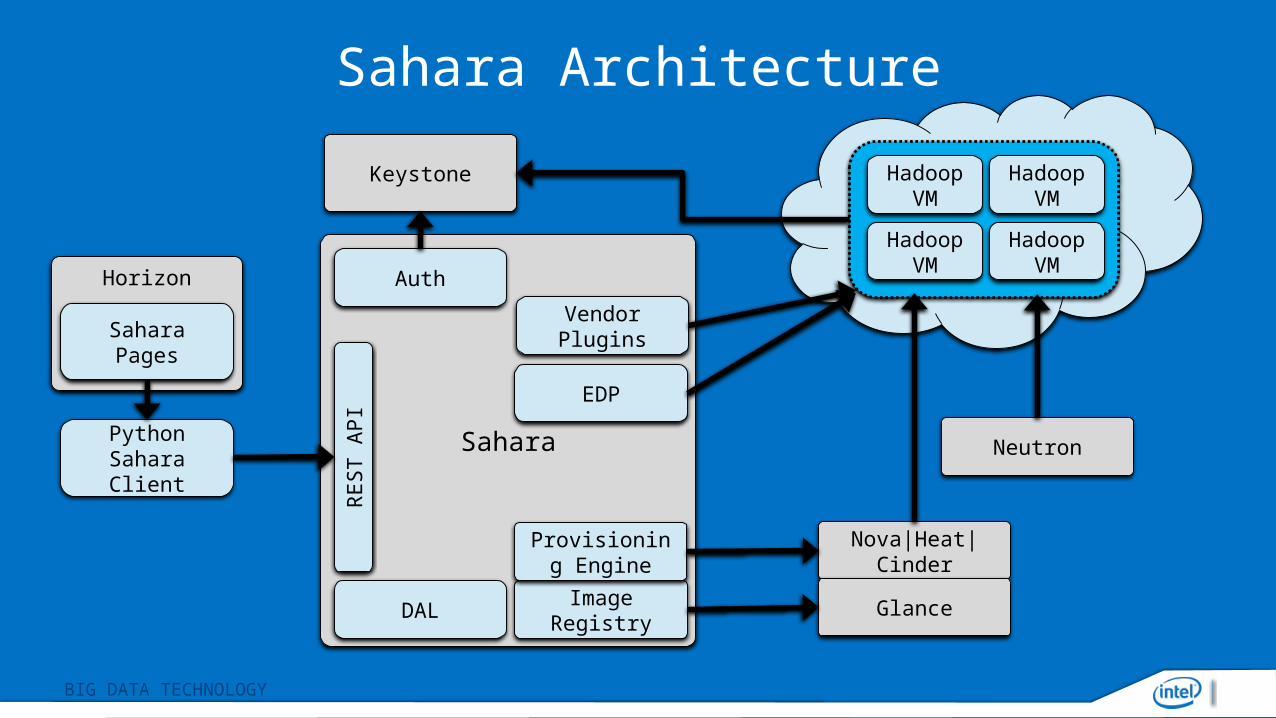
Sahara Architecture
Sahara
REST A
PI
Horizon
Python Sahara Client
Sahara Pages
Keystone
Auth
DALImage
Registry
Provisioning Engine
Vendor Plugins
EDP
Hadoop VM
Hadoop VM
Hadoop VM
Hadoop VM
Nova|Heat|Cinder
Glance
Neutron
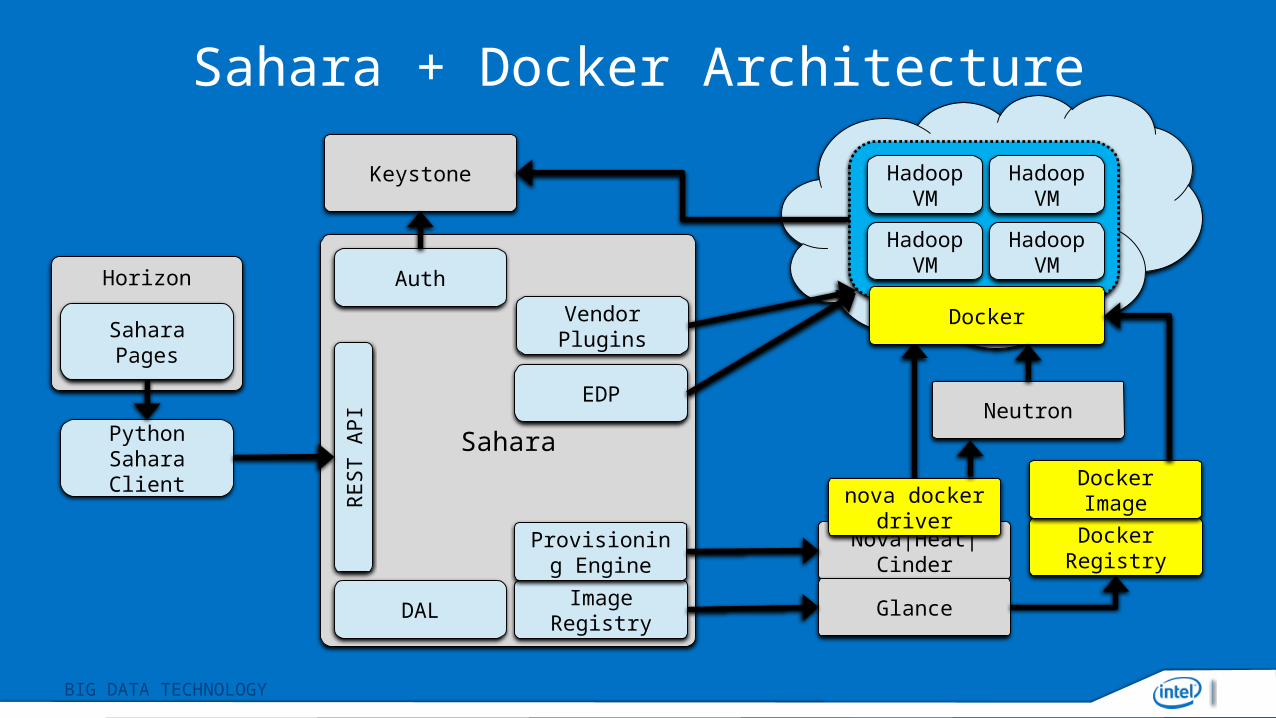
BIG DATA TECHNOLOGY
Sahara + Docker Architecture
Sahara
REST A
PI
Horizon
Python Sahara Client
Sahara Pages
Keystone
Auth
DALImage
Registry
Provisioning Engine
Vendor Plugins
EDP
Hadoop VM
Hadoop VM
Hadoop VM
Hadoop VM
Nova|Heat|Cinder
Glance
nova docker driver
Docker Registry
Docker Image
Docker
Neutron
BIG DATA TECHNOLOGY
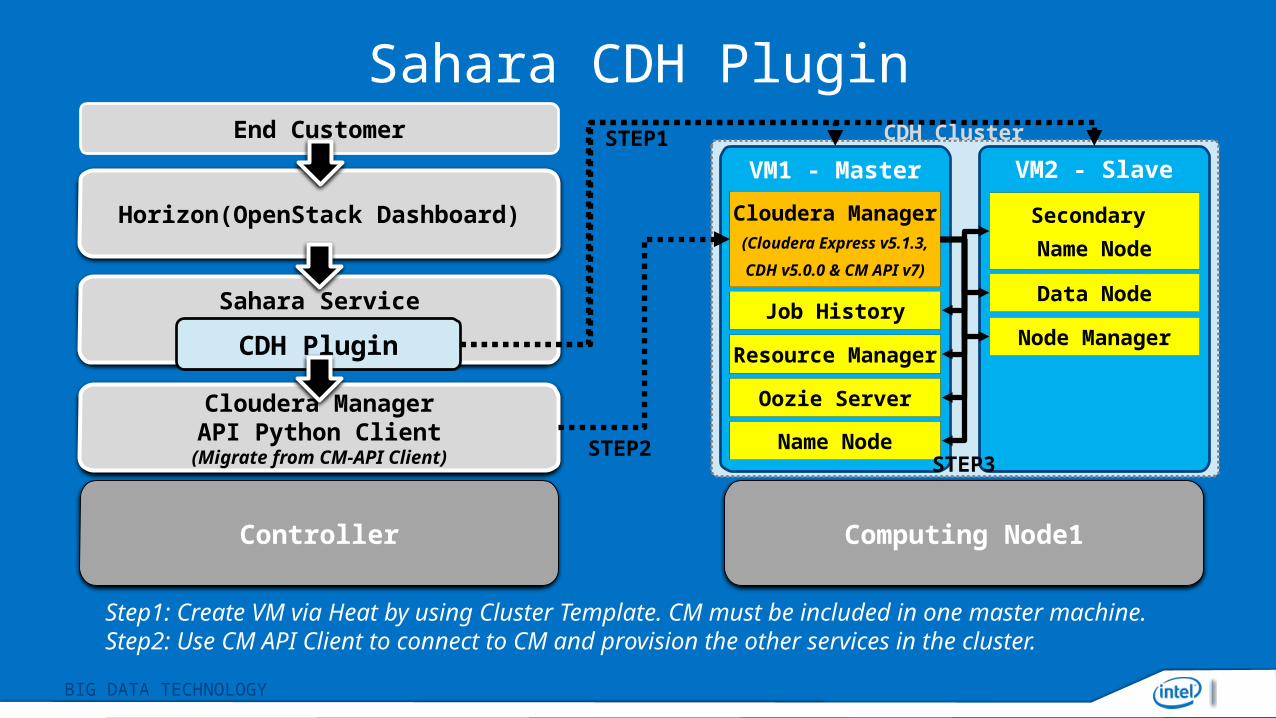
Sahara CDH Plugin
Controller Computing Node1
Cloudera Manager API Python Client
(Migrate from CM-API Client)
Sahara Service
Horizon(OpenStack Dashboard)
CDH Plugin
Step1: Create VM via Heat by using Cluster Template. CM must be included in one master machine.Step2: Use CM API Client to connect to CM and provision the other services in the cluster.
STEP1
STEP2
End Customer
VM1 - Master VM2 - Slave
Cloudera Manager(Cloudera Express v5.1.3,
CDH v5.0.0 & CM API v7)
Job History
Resource Manager
Oozie Server
Name Node
Secondary
Name Node
Data Node
Node Manager
STEP3
CDH Cluster

BIG DATA TECHNOLOGY
Nova Docker Driver
Introduced with Havana, move out Icehouse and Juno
For Juno,• Must install an older version novadocker
# git checkout -b pre-i18n 9045ca43b645e72751099491bf5f4f9e4bddbb91
• Implement a RESTFul client via httplib to communicate with Docker
For Kilo(Upstream),• Need to install docker-py
• Use Docker API Client to communicate with Docker

BIG DATA TECHNOLOGY
Authenticate & Hostname Issue
Use username & password instead of inject authorized key into instance
• No cloud-init in docker image, use username & password instead of inject key
Upgrade Docker version to support change hostname
• Docker v1.2 or later can support to change hostname
Change “sudo mv etc-host /etc/hosts” to “sudo cp etc-host /etc/hosts”
• Docker v1.3 response the device is busy when using “mv”. By using “cp” to replace “mv” can be success to run the change

BIG DATA TECHNOLOGY
Network Port Issue
Open Privilege Mode to expose all the ports in the container
• Modify nova docker driver source code to add “privileged=True” and publish all ports

BIG DATA TECHNOLOGY
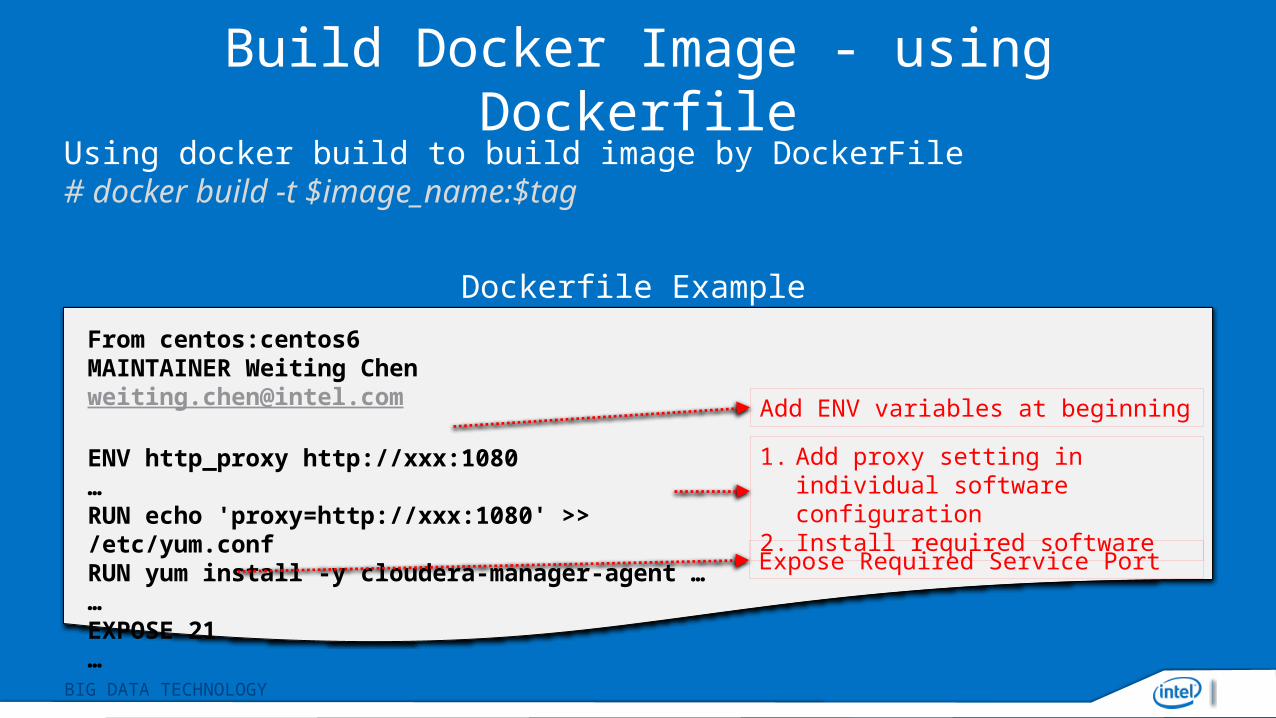
Docker Image
Build a docker image by using Dockerfile• Refer sahara-image-elements to build a CDH5 docker image
• Build a docker image may take a lot of time(try-and-error)
• Better use Dockerfile cache to reduce the time building the image
Copy docker image to every compute node manually• Must copy docker image to all the compute nodes, currently glance cannot
support to copy the image to compute node
• If the image cannot be found in docker images, nova will raise an error during starting an instance
BIG DATA TECHNOLOGY
Build Docker Image - using DockerfileUsing docker build to build image by DockerFile# docker build -t $image_name:$tag
From centos:centos6MAINTAINER Weiting Chen [email protected]
ENV http_proxy http://xxx:1080…RUN echo 'proxy=http://xxx:1080' >> /etc/yum.confRUN yum install -y cloudera-manager-agent ……EXPOSE 21…
Add ENV variables at beginning
1. Add proxy setting in individual software configuration
2. Install required software
Expose Required Service Port
Dockerfile Example

BIG DATA TECHNOLOGY
Register & Copy Docker Image to Compute Nodes
Register docker image to glance# docker save cdh5:20150425 | glance image-create --is-public=True --container-format=docker --disk-format=raw --name cdh5:20150425
Copy image to all compute nodes# scp cdh5:20150425.tar $compute_node:./
Load image to docker registry# docker load -i cdh5:20150425.tar
If no image can be used in computing node, it will raise an error from nova.

BIG DATA TECHNOLOGY
Nova Docker Driver Network• Set network to “none”
• Nova docker driver would leverage existing network configuration from Neutron
• Support Linux Bridge or OVS
• NOT use docker0
• Use VXLAN in our experiment • Create a bridge to OVS automatically
• Set Privilege Mode to True for convenience• Need to set port mapping during docker run if not use privilege mode

BIG DATA TECHNOLOGY
Docker Network
Host1
Docker
Container1
Container2
Container3
eth0172.17.42.1
0
eth0172.17.42.1
1
eth0172.17.42.1
2
docker0172.17.42.1
Host1
Docker
Container1
Container2
Container3
eth0192.168.0.1
eth110.10.10.1
docker0172.17.42.1
Host1
Docker
Container1
Container2
Container3
docker0172.17.42.1
Bridge Mode Host Mode None Mode
• Default Mode• Support multiple
namespaces
• Only one namespace • Nova Docker Driver use this
• Configure network and connect to bridge via driver
BIG DATA TECHNOLOGY
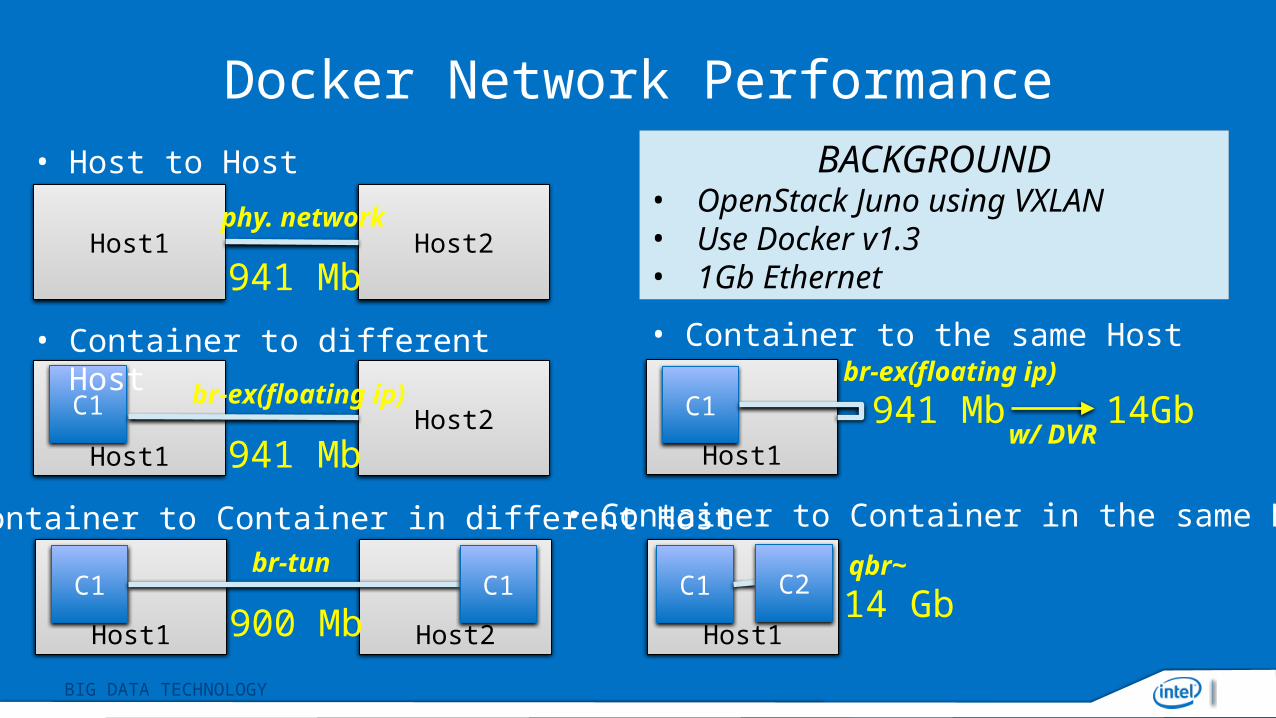
Docker Network Performance
Host1 Host2
Host1
C1
941 Mb
Host2941 Mb
Host1
C1
Host2900 MbC1
Host1
C1 941 Mb
Host1
C1 C214 Gb
• Container to the same Host
• Container to Container in the same Host• Container to Container in different Host
• Container to different Host
• Host to Host
phy. network
br-ex(floating ip)
br-tun
BACKGROUND• OpenStack Juno using VXLAN• Use Docker v1.3• 1Gb Ethernet
br-ex(floating ip)
qbr~
14Gbw/ DVR
BIG DATA TECHNOLOGY
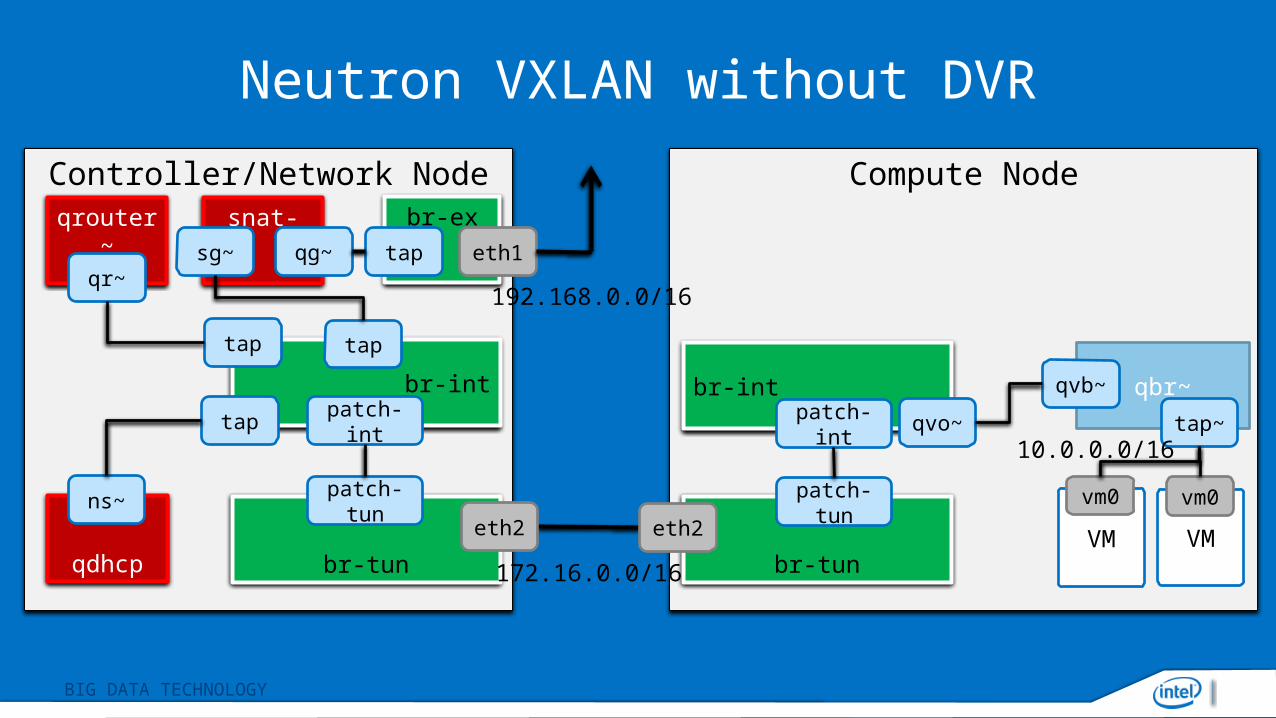
Neutron VXLAN without DVR
Controller/Network Node Compute Node
br-tun
patch-tun
br-int
br-ex
eth1
br-tun
patch-tun
br-intqvo~
172.16.0.0/16
192.168.0.0/16
VM
vm0
eth2 eth2 VM
vm0
qbr~qvb~
patch-int
tap~10.0.0.0/16
tap
patch-int
tap
qdhcp
ns~
snat-sg~ qg~
qrouter~
qr~
tap
tap
BIG DATA TECHNOLOGY
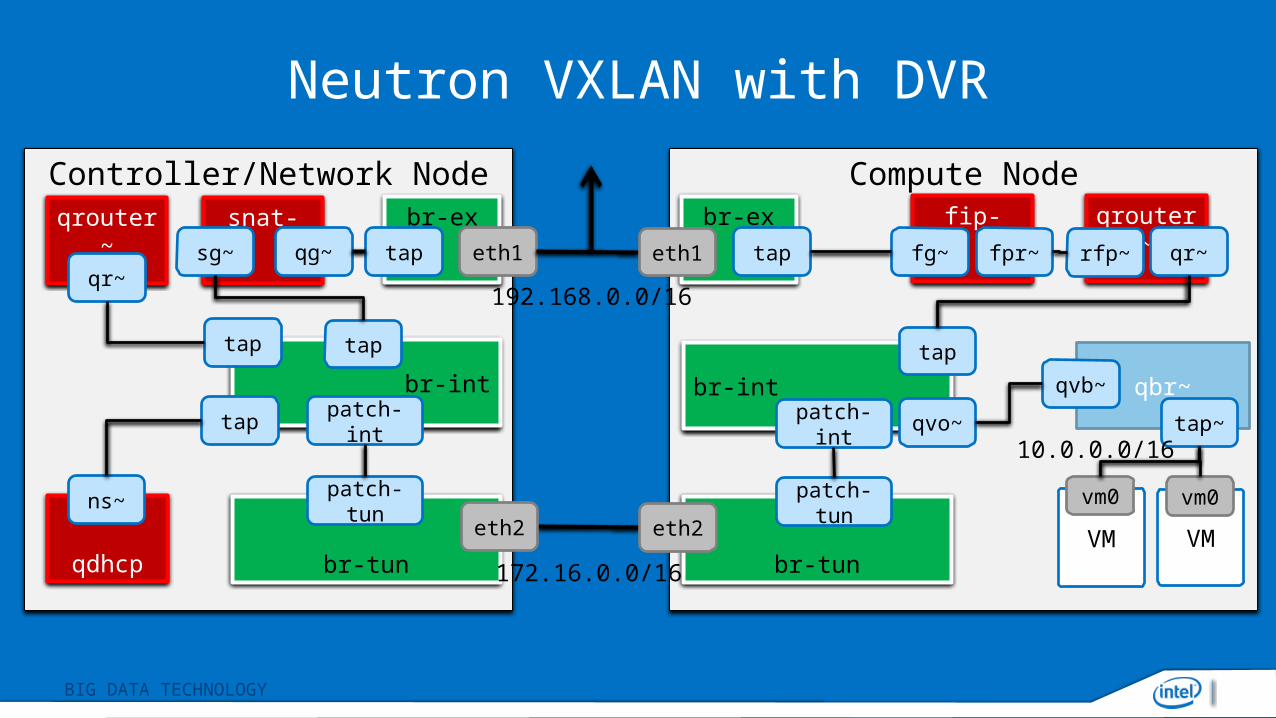
Neutron VXLAN with DVR
Controller/Network Node Compute Node
br-tun
patch-tun
br-int
br-ex
eth1
br-tun
patch-tun
br-int
tap
qvo~
172.16.0.0/16
192.168.0.0/16
br-ex
eth1
VM
vm0
eth2 eth2 VM
vm0
tap
qbr~qvb~
patch-int
tap~
fip- qrouter~fpr~ rfp~
10.0.0.0/16
fg~ qr~
tap
patch-int
tap
qdhcp
ns~
snat-sg~ qg~
qrouter~
qr~
tap
tap

BIG DATA TECHNOLOGY
Change MTU Size
• Change MTU Size if you are using VXLAN
• Impact:MTU size could impact the network performance. If the MTU size is not change, create instances still can work, but network performance is going down to 1MB.
• Solution: Change MTU Size in VM#sudo ifconfig eth1 mtu 1400 up

BIG DATA TECHNOLOGY
Container Disk Space
• Default image disk space only use 10 GB
• Impact:Default reserve 10GB space for HDFS configuration, there is no space to put data in HDFS
• Solution: Assign parameters when starting Docker service# sudo ./docker -d --storage-opt dm.basesize=20G --storage-opt dm.loopdatasize=200G &*To enable the parameters must clean up /var/lib/docker/ and restart docker

BIG DATA TECHNOLOGY
vCPU Numbers
The number of vCPU is always 1.
• Impact:vCPUs calculation may be fail.
• Solution:In Juno, change the number in nova docker driver source code and set it equal to the number of physical cores.

BIG DATA TECHNOLOGY
Docker in OpenStack Performance
Network Performance
Instance Boot/Cluster Provision
Disk Performance using DD
HiBench Testing

BIG DATA TECHNOLOGY
Our Testing EnvironmentCLUSTER CONFIGURATION
Role Details
Controller w/ Compute x 1 Controller, Network, Compute
Compute x 5 Compute
HARDWARE CONFIGURATION
Items Details
CPU Intel Xeon X5670 2.93Ghz
Memory 64GB(1333Mhz 8GB x 8)
Storage 1TB SATA HDD
SOFTWARE CONFIGURATION
Software Name Versions
CentOS 7.0
Docker v1.6
OpenStack Juno
BIG DATA TECHNOLOGY
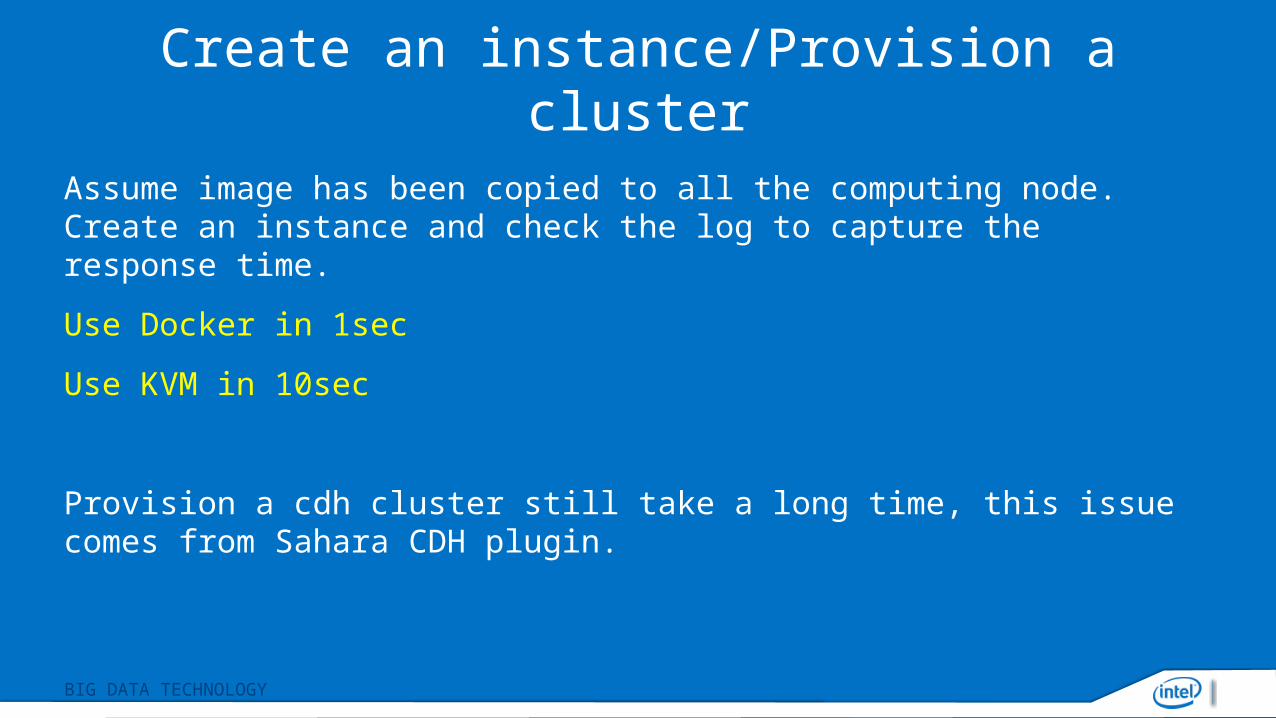
Create an instance/Provision a cluster
Assume image has been copied to all the computing node. Create an instance and check the log to capture the response time.
Use Docker in 1sec
Use KVM in 10sec
Provision a cdh cluster still take a long time, this issue comes from Sahara CDH plugin.

BIG DATA TECHNOLOGY
DD Test
Docker Container use CentOS6.6 in Host with CentOS7.
File System is XFS
Use DD Command: dd if=/dev/zero of=test1 bs=1M count=8192 conv=fdatasync
Host: 140~160MB/s
Host w/ OpenStack: 100~130MB/s(Controller), 140~160MB/s(Compute)
Container Result: 100~140MB/s
Docker can provide almost closer disk IO performance with Bare Metal

BIG DATA TECHNOLOGY
Conclusion
• Docker can bring benefit to boot mass instances
• Docker can provide good performance in Disk and Network with a little overhead
• How to optimize resource utilization will be the focus

BIG DATA TECHNOLOGY
Call-For-Action
• Contribute more for Docker and OpenStack
• Find the critical components for Big Data on Cloud and let it become better
• Need more customer use cases for Sahara
Contact: [email protected]



















