
1. Social-Network Analysis Using Topic Models 2. Web Event Topic Analysis by Topic Feature...
32
1. Social-Network Analysis Using Topic Models 2. Web Event Topic Analysis by Topic Feature Clustering and Extended LDA Model I4310/COMP4332 Big Data Mining: Presentation Chung Yin 07547265
-
Upload
loren-potter -
Category
Documents
-
view
225 -
download
0
Transcript of 1. Social-Network Analysis Using Topic Models 2. Web Event Topic Analysis by Topic Feature...

1. Social-Network Analysis Using Topic Models2. Web Event Topic Analysis by Topic Feature Clustering and Extended LDA Model RMBI4310/COMP4332 Big Data Mining: Presentation CHAN Chung Yin 07547265

Topic modeling
• statistical methods that analyze the words of the original texts to – discover the themes that run through them– how those themes are connected to each other– how they change over time

Latent Dirichlet Allocation (LDA)
• The simplest, the most common and basic• Idea:
– Represents documents as mixtures of topics– Defines collections of words and find a set of topics that are likely
to have generated the collection – I like to eat broccoli and bananas.– I ate a banana and spinach smoothie for breakfast.– Chinchillas and kittens are cute.– My sister adopted a kitten yesterday.– Look at this cute hamster munching on a piece of broccoli.
• Sentences 1 and 2: 100% Topic A• Sentences 3 and 4: 100% Topic B• Sentence 5: 60% Topic A, 40% Topic B Topic A (food): 30% broccoli, 15% bananas, 10% breakfast, 10%
munching, … Topic B(cute animals): 20% chinchillas, 20% kittens, 20% cute, 15%
hamster, …

Latent Dirichlet Allocation (LDA)
• Learning:– Go through each document (d), and randomly assign
each word (w) in the document to one of the K topics (t).
– Go through each word in a document• Calculate, for each topic t,
– p(topic t | document d) = the proportion of words in document d that are currently assigned to topic
– p(word w | topic t) = the proportion of assignments to topic t over all documents that come from this word w
– Reassign w a new topic p(topic t | document d) * p(word w | topic t)
• Assume that all topic assignments except for the current word in question are correct
– Repeat above step until steady state
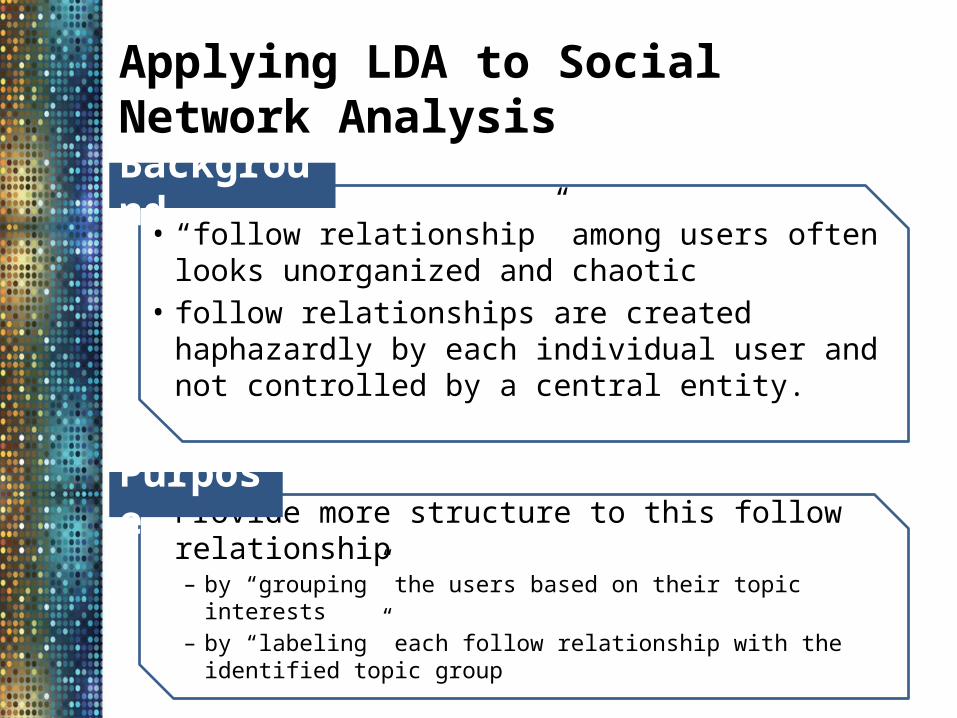
Applying LDA to Social Network Analysis
• “follow relationship” among users often looks unorganized and chaotic
• follow relationships are created haphazardly by each individual user and not controlled by a central entity.
• Provide more structure to this follow relationship – by “grouping” the users based on their topic interests– by “labeling” each follow relationship with the identified topic
group
Background
Purpose

Applying LDA to Social Network Analysis
• Represent E in matrix form by putting F in the rows and G in the columns
• Symbol Meaning u A Twitter userU A set of all uf A followerF A set of all fg A followed userG A set of all gz A topic (interest)Z A set of all ze(f, g) A follow edge from f to ge'(f, g) A follow edge from g to fe(f) A set of all outgoing edges from fe'(g) A set of all incoming edges to gE A set of all e(f, g) f F, g G∀ ∈ ∀ ∈

Applying LDA to Social Network Analysis
• SimilarLDA Edge Generative ModelTopic Interest (z)
Document Follower (f)
Word Followed user (g)

Applying LDA to Social Network Analysis
• DifferentLDA Edge Generative Modelmultinomial distribution multivariate hypergeometric distribution
documents are in the rows and words are in the columns
rows and the columns are from the same entity
integer binary
Smaller magnitude Larger magnitude (|f|X|g|)
Power-law distribution Do not show power-law distribution

Handling Popular Users
• Alternative 1: Setting Asymmetric Priors– Over-fitting: Dirichlet priors and constrain 𝞪 𝞫
P(z|f) and P(g|z), respectively– In the standard LDA, each element of and 𝞪 𝞫
is assumed to have the same value– 𝞫 : Distribution of followed user per-interest– we set each prior value proportional to the 𝞫
number of incoming edges of each followed user.

Handling Popular Users
• Alternative 2: Hierarchical LDA– Generate a topic hierarchy and more frequent
topics are located at higher levels– bottom level topics are expected to be more
specific– Infinite topic number– Topics are not
independent

Handling Popular Users
• Alternative 3: Two-Step Labeling– Topic establishment step• We run LDA after removing popular users from the
dataset similar to how we remove stop words before applying LDA to a document corpus.
– Labeling step• we apply LDA only to popular users in the dataset

Handling Popular Users
• Alternative 4: Threshold Noise Filtering– the smallest number of times a popular user is
assigned to a topic group could outnumber the largest number of times a non-popular user is assigned to that topic group.
– Set a cut-off value to determine whether to label a user with each topic
– filter out less relevant topics by keeping only the top-K topics for each user
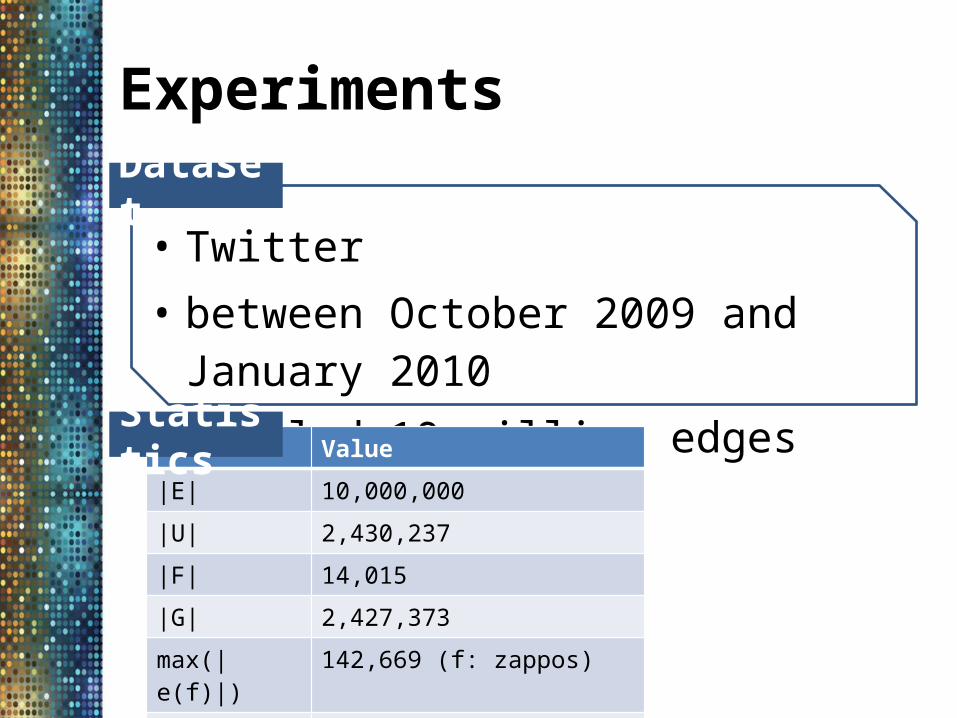
Experiments
• Twitter• between October 2009 and January 2010 • Sampled 10 million edges
Dataset
Value
|E| 10,000,000
|U| 2,430,237
|F| 14,015
|G| 2,427,373
max(|e(f)|) 142,669 (f: zappos)
max(|e’(g)|) 7,410 (g: barackobama)
Statistics
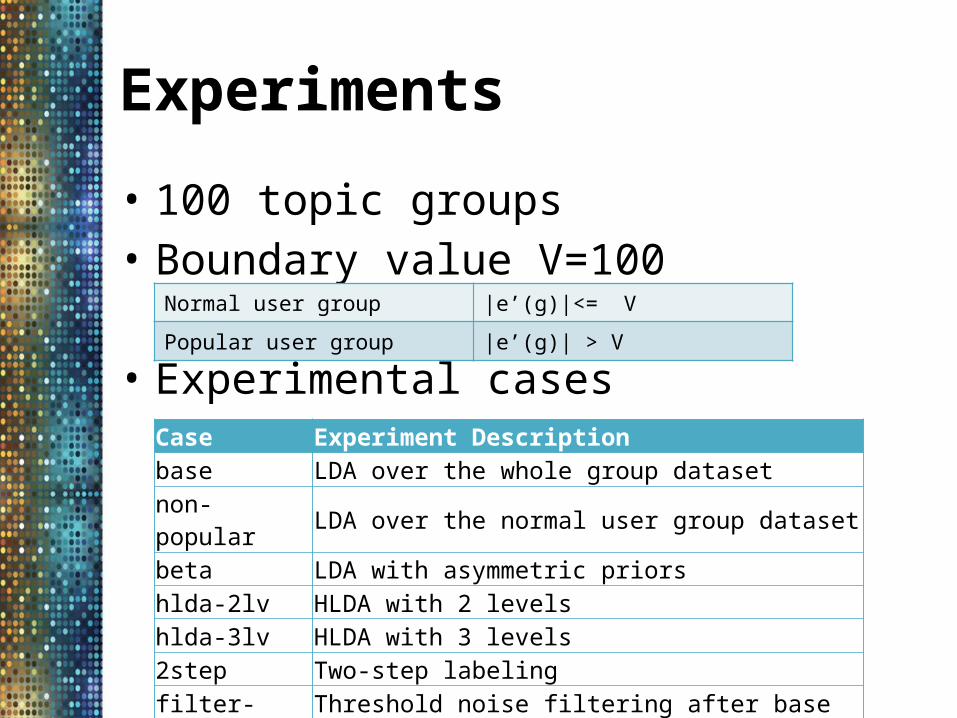
Experiments
• 100 topic groups• Boundary value V=100
• Experimental cases
Normal user group |e’(g)|<= V
Popular user group |e’(g)| > V
Case Experiment Descriptionbase LDA over the whole group datasetnon-popular LDA over the normal user group datasetbeta LDA with asymmetric priorshlda-2lv HLDA with 2 levelshlda-3lv HLDA with 3 levels2step Two-step labelingfilter-base Threshold noise filtering after base (C=0.05)filter-2step Threshold noise filtering after 2step (C=0.05)

Experiments
• Measurement 1: Perplexity– how well the trained model deals with an
unobserved test data– A perplexity means that you are as surprised on
average as you would have been if you had had to guess between k equiprobable choices at each step.
– Smaller perplexity, better the model is
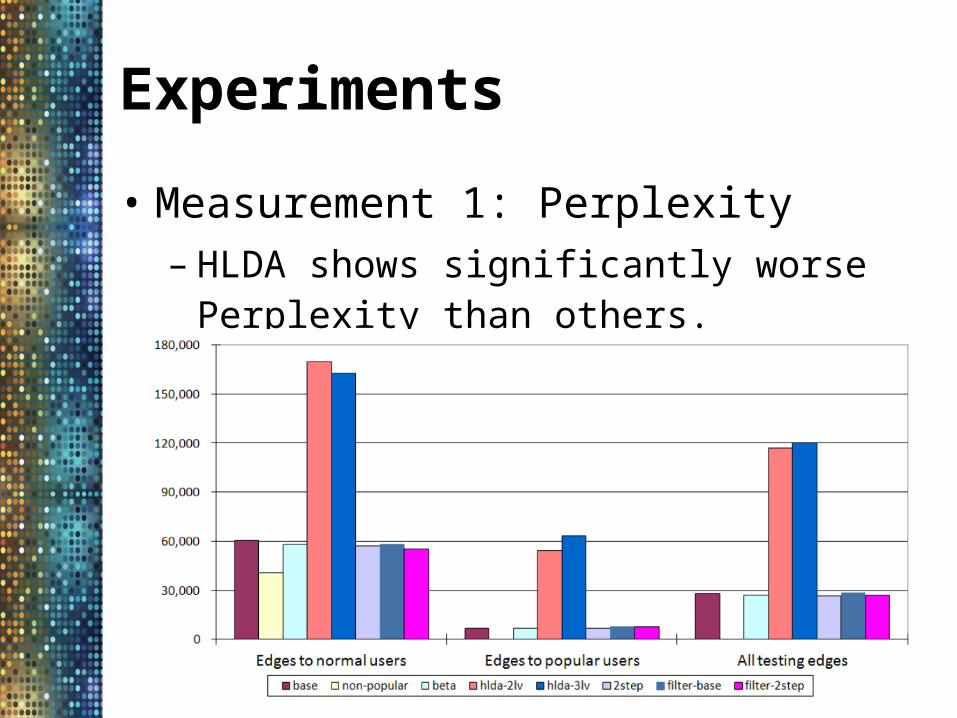
Experiments
• Measurement 1: Perplexity– HLDA shows significantly worse Perplexity than
others.
Experiments
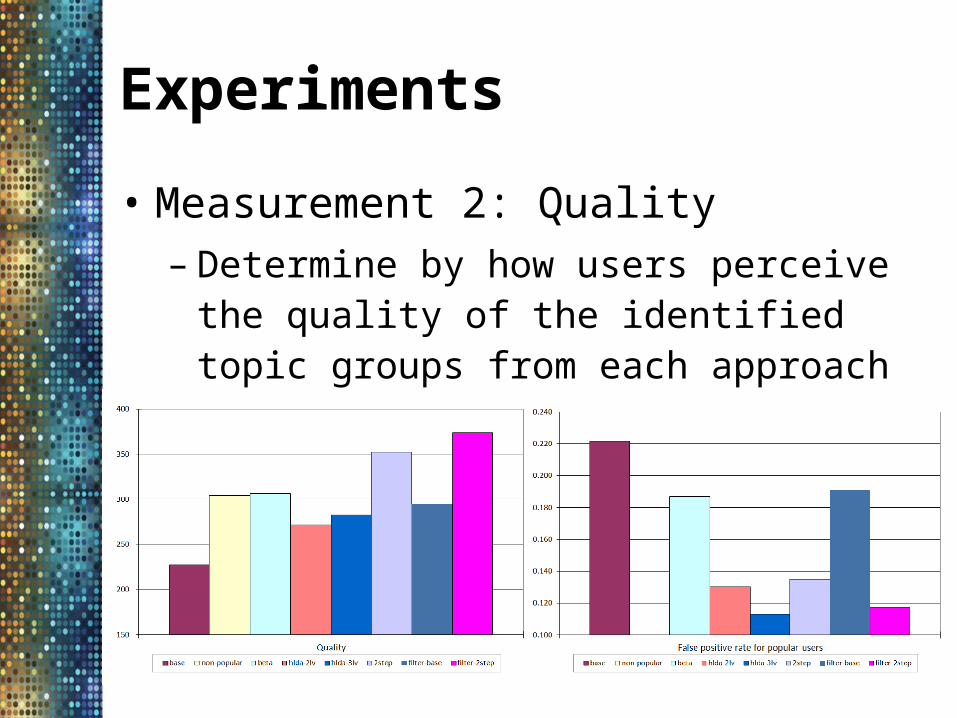
• Measurement 2: Quality– Determine by how users perceive the quality of
the identified topic groups from each approach– Conduct a survey with a total of 14 participants

Experiments
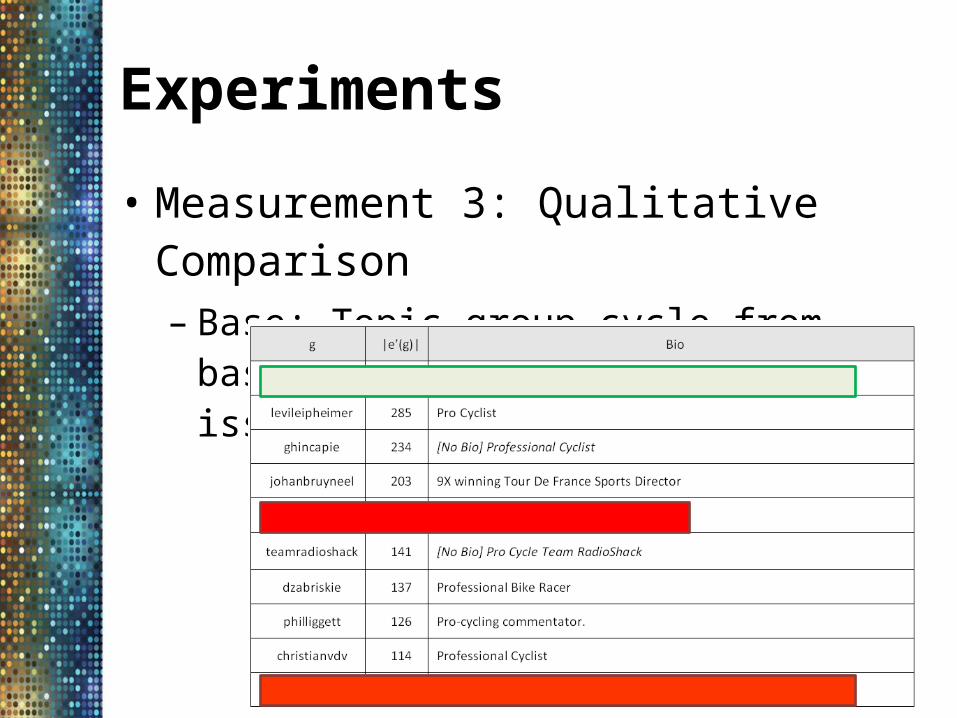
• Measurement 3: Qualitative Comparison– The top ten users in a topic group– By going over the users' bios, we see that many
of the users in the group have the same interest
Experiments
• Measurement 3: Qualitative Comparison– Base: Topic group cycle from base showing the
popular user issue

Experiments
• Measurement 3: Qualitative Comparison– Base• Barack Obama appears in 15 groups out of 100 topic
groups produced by base. • Among the 15 groups, only one of them is related to
his specialty, politics• the standard LDA suffers from the noise from
popular users if applied directly to our social graph dataset
Experiments
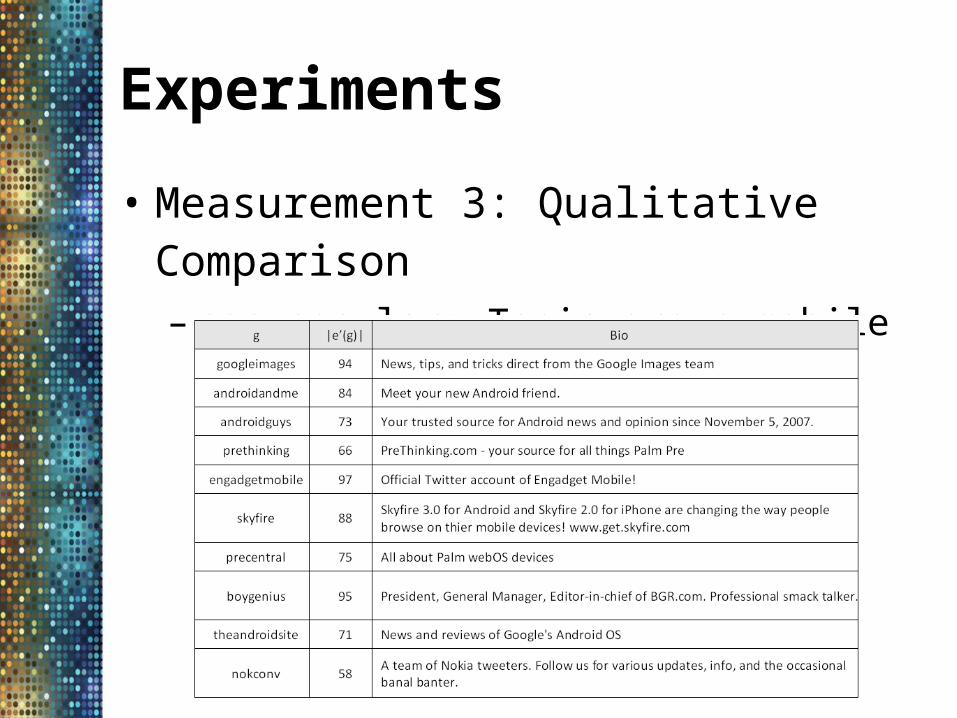
• Measurement 3: Qualitative Comparison– non-popular: Topic group mobile gadget blog
from non-popular

Experiments
• Measurement 3: Qualitative Comparison– 2step : Topic group corresponding to mobile
gadget blog • many users in this group are very popular, tech
media

Experiments
• Measurement 3: Qualitative Comparison– Filter-2step : Topic group corresponding to
mobile gadget blog • many users in this group are very popular, tech
media• cnnbrk and
breakingnews are removed

Conclusion
• Two-step labeling with threshold noise filtering, are very effective in handling this popular user issue
• showing 1.64 times improvement in the quality of the produced topic groups, compared to the standard LDA model.

Web Event Topic Analysis
• Analyze a common topic of many different web events
• Cluster events which belong to a topic • Choose suitable topic terms for clusters

Web Event Topic Analysis
• Dimension LDA (DLDA) – Represent an event as a multi-dimensions
vector– {agent, activity, object, time, location, cause,
purpose, manner} • K-means Clustering

Web Event Topic Analysis

Dimension LDA (DLDA)
• Perform LDA analysis• Add a parameters vector on the weighting
of each dimension• Select some dimensions as topic feature
dimensions

Topic Feature Clustering
• Cluster the content of topic feature dimensions to analyze the common topic for events

Topic Feature Words Selection
• Use DLDA model to select topic feature words
• Find the words within same cluster group• By maximize the probability of topic given
dimension and word

Topic Terms Generating
• Merge 2 words together• Replace existing keyword from dictionary• => candidate topic terms• Finally, Compute probability distribution
of topic candidate terms

Results
• Using Topic Feature Clustering with Extended LDA Model is better than using clustering or LDA model alone



![IEEE TRANSACTIONS ON KNOWLEDGE AND DATA ENGINEERING, …€¦ · clude PLSA (Probabilistic Latent Semantic Analysis) [2] and LDA (Latent Dirichlet Allocation) [3]. By using topic](https://static.fdocuments.us/doc/165x107/5f9771fa1c32a515fd44cc61/ieee-transactions-on-knowledge-and-data-engineering-clude-plsa-probabilistic-latent.jpg)




![Mr. LDA: A Flexible Large Scale Topic Modeling Package ...jbg/docs/2012_First LDA implementation [Blei et al. 2003] Master-Slave LDA [Nallapati et al. 2007] Apache Mahout MCMC / Gibbs](https://static.fdocuments.us/doc/165x107/6011a885841efa62be1578ae/mr-lda-a-flexible-large-scale-topic-modeling-package-jbgdocs2012-first.jpg)









