
1 Lecture 6 Performance Measurement and Improvement.
37
1 Lecture 6 Performance Measurement and Improvement
-
date post
19-Dec-2015 -
Category
Documents
-
view
220 -
download
2
Transcript of 1 Lecture 6 Performance Measurement and Improvement.

1
Lecture 6
Performance Measurement
and
Improvement

2
How to make the code faster
Measurement and Profiling Hot Spots Practical Hints

3
Rationale for this unit
This lecture is about making programs run fast. Usually speed is not the most important concern while writing a program.
The professional programmer is usually most concerned with making a program that is easy to
write, debug, and maintain.
A programmer is not just coding.

4
Reason on simple program (1)
A correct program, even if is slow, computes right answers faster than a program that is not. It is often better to use a simple but slow algorithm.
A program that is finished computes right answers much faster than a program that is not.
Fast programs often take much more time to develop, and they are useless until they are finished.
Simple but fast program

5
Reason on simple program (2)
Computers’ performance is double in speed every 18 months. Computer technology changes so fast that improvements in speed can often be obtained simply by waiting for the next generation of hardware.Speed improvements of less than a factor of two are barely noticeable to users in an interactive setting.

6
Procedure of developing a program
A slow but correctProgram
Modify the programto make it faster

7
Measurement and Profiling
First, how to measure program’s performance
What to Measure (execution speed)
Timing Mechanisms (use wall clock, such as your watch)

8
What to Measure (CPU time and Wall clock)
The most common thing to measure is CPU time.
CPU time is the time a process spends executing instructions.
It does not count any time spent executing other programs or just waiting.

9
What to Measure (Wall clock)
An alternative is to measure real time or "wall clock time“This is the time an ordinary clock on the wall or a wrist watch shows.
The difference between CPU time and wall time can give some indication of the time spent waiting for I/O.
Wall time
CPU time
I/O time

10
CPU time
It can be divided between user time, the time spent directly executing your program code, and
system time, the time spent by the operating system on behalf of your program

11
Timing MechanismsThere are two ways to measure the timing behavior of a program. The most obvious is direct measurement with a timer (wall clock – difference between start and end times.)An alternative to using timers directly is to use statistical sampling. A timer periodically interrupts the program and records the program counter or increments a counter. (profiling)

12
High-Resolution on Pentium Systems
Typical operating system clocks are not very precise because they rely on hardware to interrupt the processor every clock period.
The operating system then increments a counter
Intel Pentium processors (among others) have a very high-speed internal 64-bit counter that can be accessed by special instructions.
13
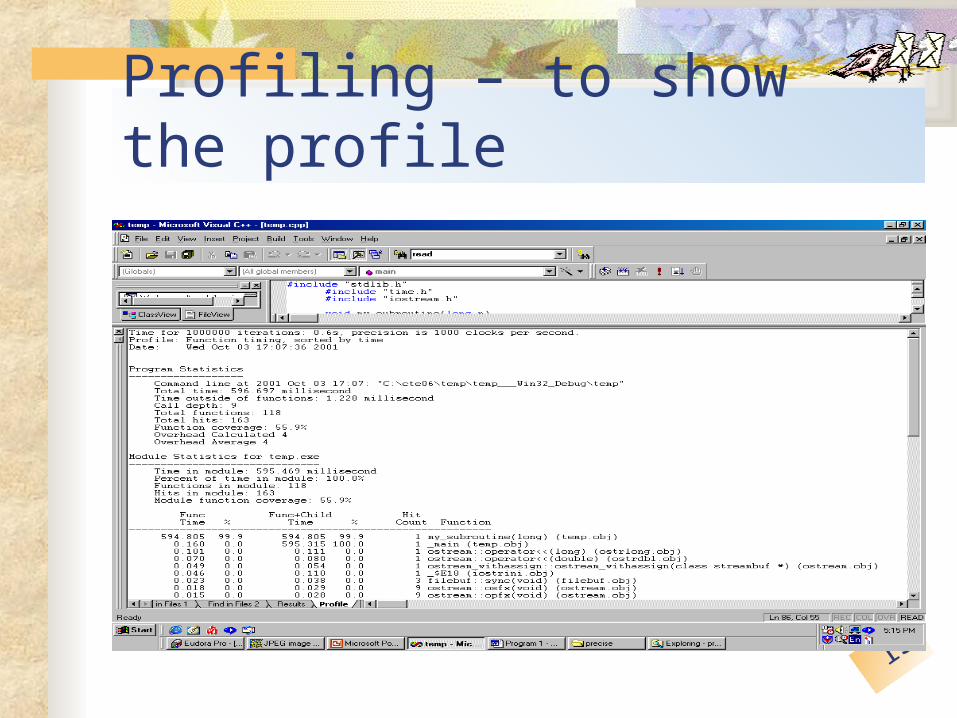
Profiling – to show the profile

14
System Monitoring - example

15
Principles - Performance
The 80/20 Rule – It means 80% of the CPU time is spent in 20% of the program.
In this case, you can have better performance by looking at this 20%.
Amdahl's Law – for parallel processing, the performance is limited by sequential part of the program.

16
Explanation
Suppose the program really spends 80% of its time in one spot, and suppose you can rewrite this spot to take a negligible mount of time.
The program will now execute in 20% of its original time, meaning that it now runs 5 times as fast.

17
Example of 80/20: 10% on one module means 2% as a whole
A module consists of 5 modules
20 ms
20 ms
20 ms
20 ms
20 ms
20 ms
18 ms
20 ms
20 ms
20 ms

18
Example of 80/20: 10% on one means 5% as a whole
A module consists of 5 modules
10 ms
50 ms
10 ms
10 ms
10 ms
10 ms
45 ms
10 ms
10 ms
10 ms
Conclusion: focus on module with more CPU
time

19
Example – Before enhancement

20
Example – After enhancementFasterFrom
24222 to 7471
FasterFrom
24222 to 7471

21
Example – a simple for loop
#include <stdio.h>
#include <stdlib.h>
void main() {
for (int i = 0; i < 1000; i++)
printf("The value is %d \n", i, i^2);
}

22
Example – Result of a simple for loop – total time is 509 ms, print i, i^i

23
Example – Result of a simple for loop – total time is 533 ms, print i, i*i*i – 4.7% difference

24
Procedure (1) – setting

25
Procedure (2) – enable profiling
26
Procedure (3) – rebuild

27
Procedure (4) – run with profiling

28
Example – a simple while loop
#include <stdio.h>
#include <stdlib.h>
void main() {
int i = 0;
while (i < 1000) {
printf("The value is %d \n", i, i^2);
i++;
}

29
Example – result in million second

30
Example with a sub-routine

31
Example with a sub-routine
Main()
subroutine

32
A program that can be used to determine Mega flop
// This is matrix multiplication#include <stdio.h>#include <stdlib.h>#include <memory.h>void main(){
float a[250][250], b[250][250], c[250][250];int i, j, k;for (i = 0; i< 250; i++)
for (j = 0; j < 250; j++)for (k =0; k <250; k++)
c[i][j] += a[i][k] * b[k][j]; // matrix multiplication
}

33
Performance is 349ms

34
Determination of Mega Flop
The time it takes for my machine is 349ms.This program involves 250^3 steps including two floating point operations, an add and a multiply 250 x 250 x 250 = 15625000.The performance for this loop is 15625000/349ms = 15.625 x 10^6 /0.349 s = 44 MFLOPs (mega floating point operation). Note that for super computer, the value is about 1000 MFLOPs. You can try your computer at home to determine your machine’s performance.

35
Same output but change the program#include <stdio.h>
#include <stdlib.h>#include <memory.h>// this program uses a temporary location t// to store the valuevoid main(){
float a[250][250], b[250][250], c[250][250];int i, j, k;float r = 0.0;for (i = 0; i< 250; i++){
for (j = 0; j < 250; j++) {for (k =0; k <250; k++) {
r += a[i][k] * b[k][j]; //this is matrix multiplication}c[i][j] = r;}
}}

36
Same machine – 254ms, why?
This is related to the cache memory effect, as the data is stored in cache. This will be explained later.

37
Summary
It is better to write a simple but fast program. The procedure is to write a program that works, then makes it faster.There is a rule called 80/20 which means 80% of CPU time spends on 20% of program. You should focus on these 20%.To measure the performance – ProfilingTo determine which causes the delay.


















