
1 An Efficient Algorithm for Mining Frequent Sequences by a New Strategy without Support Counting...
22
1 An Efficient Algorithm for Mining Frequent Sequences by a New Strategy without Support Counting Ding-Ying Chiu Yi-Hung Wu Arbee L.P. Chen ICDE2004 peaker: Ming Jing Tsai
-
Upload
brice-owens -
Category
Documents
-
view
213 -
download
0
Transcript of 1 An Efficient Algorithm for Mining Frequent Sequences by a New Strategy without Support Counting...

1
An Efficient Algorithm for Mining Frequent Sequences by a New Strategy without Support Counting
Ding-Ying Chiu Yi-Hung Wu Arbee L.P. Chen
ICDE2004 peaker: Ming Jing Tsai

2
Strategies
Candidate Pruning Database partitioning Customer reducing DISC : Direct Sequence Comparison
Reducing the costs for support counting Reducing decomposition of customer sequ
ences

3
Order of sequences
Identify the leftmost items located in different transactions in two sequences having common prefixes <(a,c,b)(cd)> <(a,c)(b,c)(a)>
Exam the leftmost distinct items in alphabetic order <(a)(c,f)> <(a)(b)(h)>>
<

4
DISC frequent k sequences
(a)(b)(b)(b)(d)(e)(b,f,g)(a)(b)(b)
CID Customer Sequences 3-minimum Subsequences
1 (a,e,g)(b)(h)(f)(c)(b,f)2 (b)(d,f)(e)3 (b,f,g)4 (f)(a,g)(b,f,h)(b,f)

5
3-sorted database
CID Customer Sequences 3-minimum Subsequences
1 (a,e,g)(b)(h)(f)(c)(b,f) (a)(b)(b)
4 (f)(a,g)(b,f,h)(b,f) (a)(b)(b)
2 (b)(d,f)(e) (b)(d)(e)
3 (b,f,g) (b,f,g)

6
Compare α1,αδ
k-minimum subsequence in k-sorted database at first position α1
at δ-th positionαδ : conditional k-minimum sequence
α1=αδ , α1 is frequent next potential frequent k-sequence > αδ
α1≠αδ, α1 is not frequent Next potential frequent k-sequence ≧ αδ
7
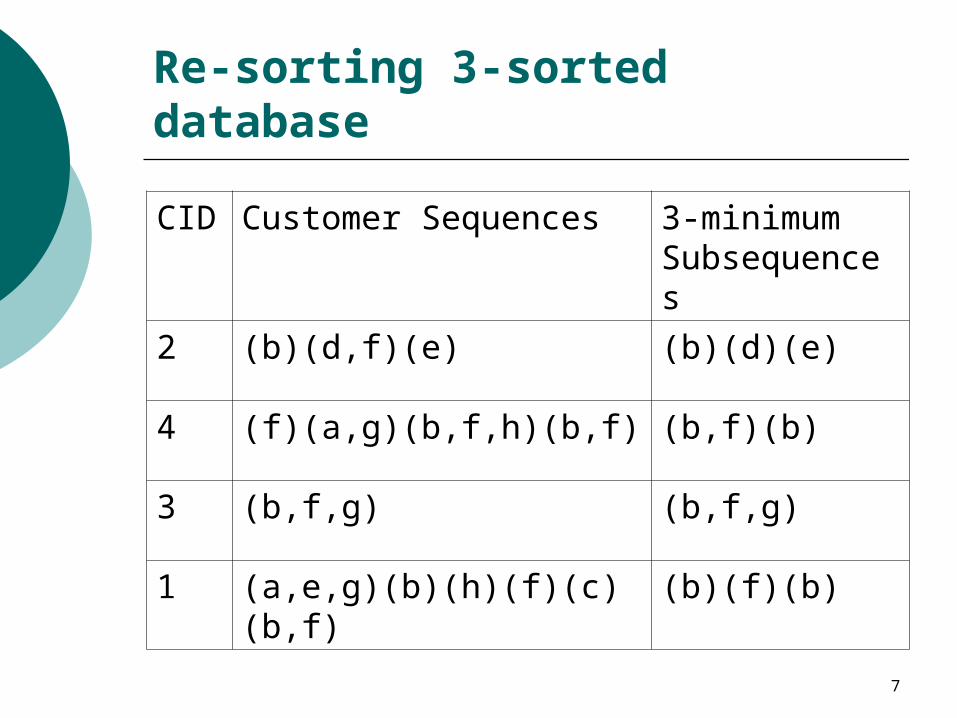
Re-sorting 3-sorted database
CID Customer Sequences 3-minimum Subsequences
2 (b)(d,f)(e) (b)(d)(e)
4 (f)(a,g)(b,f,h)(b,f) (b,f)(b)
3 (b,f,g) (b,f,g)
1 (a,e,g)(b)(h)(f)(c)(b,f) (b)(f)(b)

8
Advantage
No candidate sequence is generated Cost of decomposing customer
sequences are reduced Frequent k-sequences can be
directly discovered.

9
DISC_ALL

10
Running example δ=3
CID Customer Sequences
1 (a,d)(d)(a,g,h)(c)2 (b)(a)(f)(a,c,e,g)(c)3 (a,g)4 (a,f,g)(a,e,g,h)(c,g,h)5 (b,f)(b,e)(e,f,h)6 (d,f)(d,f,g,h)7 (b,f,g)(c,e,h)
a 4
b 3
c 4
d 2
e 4
f 5
g 6
h 5
(a)
(b)
(a)
(a)
(a)
(b)(d)
First-level partition

11
First-level Partition1 λ=a,δ=3 CID Customer
Sequences
1 (a,d)(d)(a,g,h)(c)
2 (b)(a)(f)(a,c,e,g)(c)
3 (a,g)
4 (a,f,g)(a,e,g,h)(c,g,h)
(a) (b)
(c) (d)
(e) (f)
(g)
(h)
Sup
Last_CID
(_a) (_b) (_c) (_d)
(_e) (_f) (_g) (_h)
Sup
Last_CID
Frequent 2-sequences:(a)(a) , (a)(c) , (a)(g) , (ag)
3 0 3 1 2 1 3 2
3 0 3 1 3 2 3 3
0 0 1 1 2 1 5 2
0 0 2 1 3 3 5 3

12
Whether an item to the right of the min point can be removed or not
Condition1:The transaction having x contains λ
Condition2:The min point is to the left of the transaction having x
X can be removed Condition1 does not hold, and <(λ)(x)> is not freque
nt. Condition1 holds, condition2 does not hold, and <
(λ,x)> is not frequent Condition1 and2 both hold, and <(λ)(x)> and <(λ,x)>
are not frequent.

13
DISC λ=(a), δ=3
CID 3-minimum subsequences
Customer Sequences
Apriori pointer
1 (a)(a,g)(c)2 (b)(a)(a,c,g)(c)4 (a,g)(a,g)(c,g)
The 2-sorted ListNo Frequent 2-
sequences
1 (a)(a)2 (a)(c)3 (a)(g)4 (a,g)(a)(a)(c)
(a)(a,c)(a)(a)(c)
1
1
1
CID 3-order DB
2 (a)(a,c)
1 (a)(a)(c)4 (a)(a)(c)
(a)(a,g)
CID 3-order DB
1 (a)(a)(c)
4 (a)(a)(c)2 (a)(a,g)
(a)(a,g)
(a)(a,g)
Frequent 3-sequences : (a)(a,g)
removed
(a)(c,g)(a)(c,g)
2
2
2

14
Bi-level
(a) (b)
(c) (d)
(e) (f)
(g)
(h)
Sup 0 0 3 0 0 0 1 0Last_CID 0 0 4 0 0 0 4 0
(_a) (_b) (_c) (_d)
(_e) (_f) (_g) (_h)
Sup 0 0 0 0 0 0 0 0Last_CID 0 0 0 0 0 0 0 0
CID Customer Sequences
1 (a)(a,g)(c)2 (b)(a)(a,c,g)(c)4 (a,g)(a,g)(c,g)
Frequent 4-sequence (a)(a,g)(c)

15
First-level partition 2
CID Customer Sequences First-level partitioning
1 (a,d)(d)(a,g,h)(c)2 (b)(a)(f)(a,c,e,g)(c)3 (a,g)4 (a,f,g)(a,e,g,h)(c,g,h)5 (b,f)(b,e)(e,f,h)6 (d,f)(d,f,g,h)7 (b,f,g)(c,e,h)
(c)
(b)removed
(c)
(b)
(d)
(b)

16
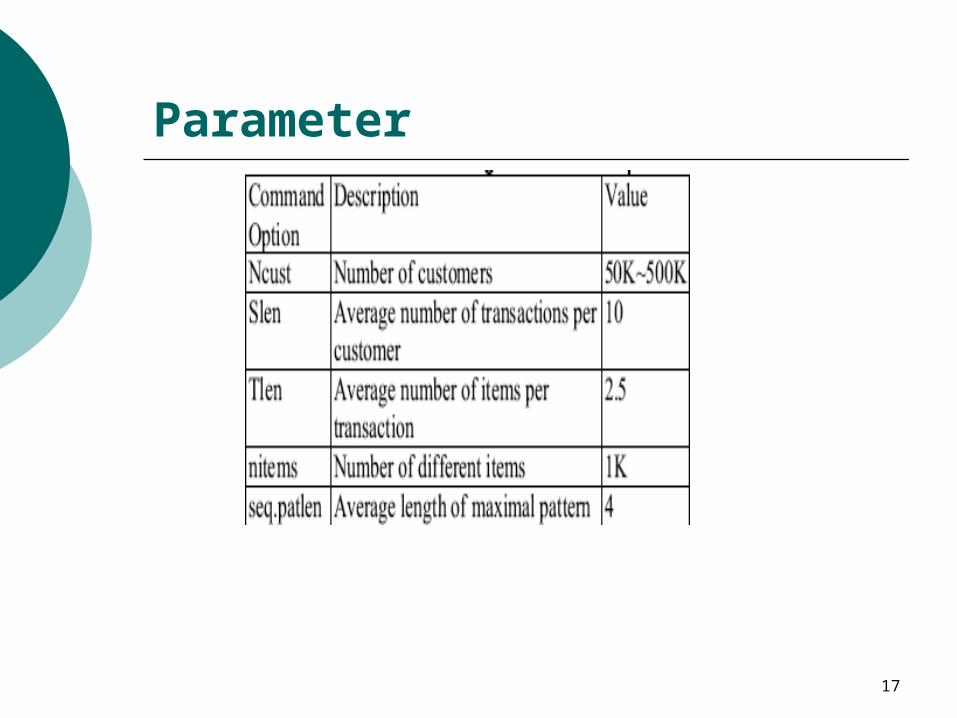
Experiment
Intel P4 2.8GHz with 512 MB main memory Windows XP
IBM data generator Compared with PrefixSpan
Pseudo-projection named Pseudo
17
Parameter
18
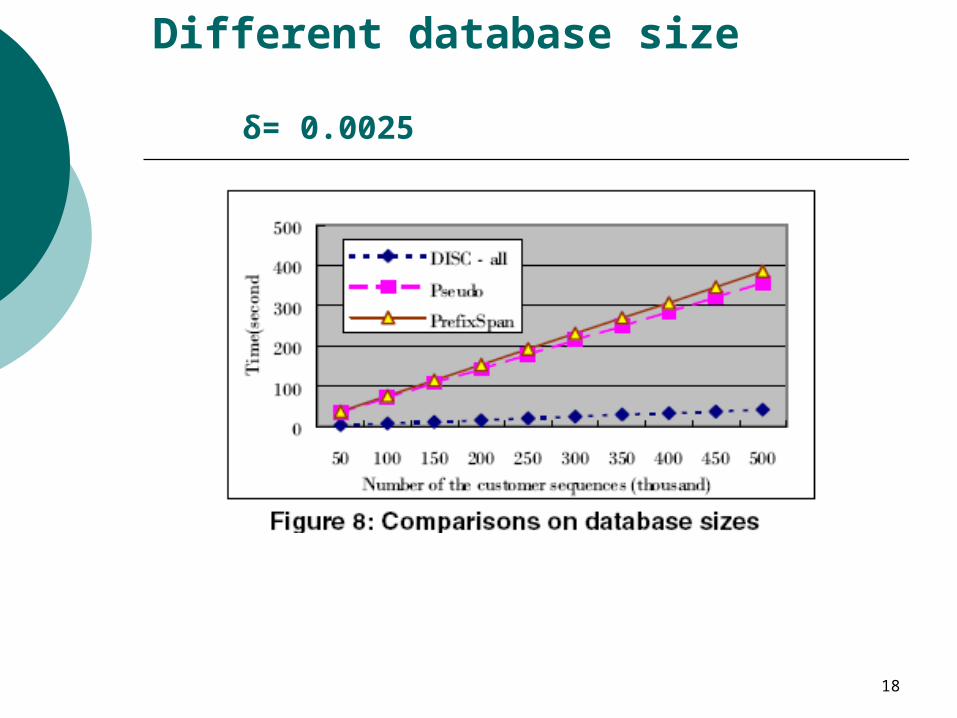
Different database size δ= 0.0025

19
Different minimum sup DB=10k
Slen=8
Tlen=8
Seq.patlen=8

20
Multi-level partitioning
DB=10k
NRRQ=1/NQ ∑ SizeP/SizeQP is a child partition of Q

21
Dynamic DISC-all
Customer =50k
Items = 1000
θ:transactions#
customer

22
Compare on different θ


















