







Languages
Pages
Legal


VoiceGrid™
VOICE RECOGNITION TECHNOLOGY WHITE PAPER
October 2011
Voice recognion technology can be ulized to provide unique and valuable
enhancements to law enforcement invesgaons and idenficaon opera-
ons. When discussing voice recognion as it is applicable to law enforcement,
it is important to define the modality to avoid any confusion with its intent or
purpose. Unlike speech recognion which is intended to understand the spo-
ken word or voice verificaon which is ulized primarily for physical or logical
access in a 1:1 modality, voice recognion is the ability to idenfy who is
speaking, independent of text or language as well as other variables which will
be discussed later in this paper. Addionally the idenficaon of the voice
should be able to be performed in a 1:N method against a few, hundreds,
thousands and even millions of other voice samples. This whitepaper will dis-
cuss how voice recognion can be used in the law enforcement environment,
the challenges that the technology must address to be effecve and the possi-
ble use cases.
In order to understand where we are now and the direcon we are moving
towards with voice recognion in the law enforcement environment it is im-
portant to understand a li*le history of voice and audio technology in general.
Audio evidence has been accepted in US courts since 1958 as determined by
the decision of United States v. McKeever, 169 F. Supp. 426 (SDNY 1958)1. Ad-
dionally audio evidence has passed Frye, Daubert and Federal Rules of Evi-
dence challenges. Historically however and as is sll the case today, one would
need to enlist the experse of a Forensic Audiologist or an “Audio Expert” in
order to produce the data, reports, charts etc. required to tesfy as to the va-
lidity and authencity of audio evidence. The process of extracng and pro-
ducing this informaon in a format that could be comprehended by a layper-
son (i.e. jury) was a manual and somemes tedious pracce. SpeechPro was
and connues to be a world leader in developing technology for the manual
processing and analysis of audio data and it was largely upon this technology
that the company was founded in 1990. However during the evoluon of
SpeechPro in the last 21 years, it was recognized that if some of these manual
processes could be automated and performed by a non-expert or praconer,
and further if said processes could be delivered to perform in real-me or near
INTRODUCTION SCOPE
SpeechPro offers
leading edge voice
recognion tech-
nologies under the
VoiceGrid™ brand-
ing. Automated
voice recognion is
now being ulized
by law enforcement
agencies and can
leverage both ex-
isng and new au-
dio data to provide
value in invesga-
ve and operaon-
al efforts. This ar-
cle describes the
principles and ap-
plicaons of the
VoiceGrid™ tech-
nology.
© 2011 SpeechPro, Inc.—All rights reserved 1

real-me, the resulng technology could have dramac posive ramificaons
to law enforcement endeavors. To that end SpeechPro assembled a team of
over 100 developers, technical specialists and research sciensts whose work
has led to the current set of VoiceGrid™ voice recognion deliverables availa-
ble today.
Voice recognion draws similar parallels to fingerprint and face recognion
biometrics in that a voiceprint also has available parameters that provide
unique informaon about a person. These parameters are individual to each
person, are created through the specific anatomical makeup of a person and
therefore can provide disncve informaon about the person’s identy.
However while there are similaries to other biometrics, voice recognion has
some unique challenges which must be overcome in order to employ it in a
praccal and effecve manner. Voice recognion requires not only the ability
to do the core voice matching but also a significant amount of pre-processing
in order to normalize the samples and account for variables which include,
background noise, differences in the microphones used to obtain the record-
ings and differences in the devices from which the recording was obtained.
Collecvely these are known as Channel Effects. Addionally, once the voice
sample has been collected, the technology must compensate for voice variabil-
ity such as emoonal state, illness and physical condion such as slurring of
THE VoiceGrid™ PROCESS
FINGERPRINT FACEPRINT
VOICEPRINT
SpeechPro VoiceGrid™ Voice Recognion White Paper |
© 2011 SpeechPro, Inc.—All rights reserved 2
Voice recognion
shares similaries
with other biomet-
rics for unique hu-
man idenfiers but
is subject to other
challenges beyond
matching capabili-
es which must be
addressed in order
for praccal imple-
mentaon. Voice-
Grid™ technology
accounts for these
obstacles.

words if the subject is under the influence of drugs or alcohol. SpeechPro
VoiceGrid™ technology uses an automac mul-layer pre-process which in-
cludes the following steps:
• Voice data is separated from other sounds – music, clicks, buzzing, horns,
crackling, etc.
• Sound to noise rao and reverb levels are calculated
• Type of channel is detected
• Data is re-sampled to 11.025 kHz
• Noise suppression, equalizaon & distoron compensaon algorithms are
applied
Once the audio sample is pre-processed the system then performs the Feature
Extracon, Voice Model Building & Idenficaon steps which include:
• Automac extracon of voice data
• The extracted biometric traits are saved as individual voice models
The voice models are then compared to voice models in the database. The sys-
tem uses three independent methods to achieve this which are:
⇒ Pitch Sta�s�cs
⇒ Spectral-Formant
⇒ Gaussian Mixture Models & Support Vector Machine Classifica�ons
(GMM & SVM)
Pitch Sta�s�cs
The Pitch Stascs Method (PSM) contains 16 different pitch parameters, in-
cluding average pitch value, maximum, minimum, median, percent of areas
with rising pitch, pitch logarithm variaon, pitch logarithm asymmetry, pitch
logarithm excess and 8 addional parameters.
The image above is an example of automated pitch extracon in the phrase
“forensic audio” pronounced by two different persons.
SpeechPro VoiceGrid™ Voice Recognion White Paper |
© 2011 SpeechPro, Inc.—All rights reserved 3
The VoiceGrid™
technology uses
three unique and
disnct methods to
achieve a high de-
gree of matching
accuracy.
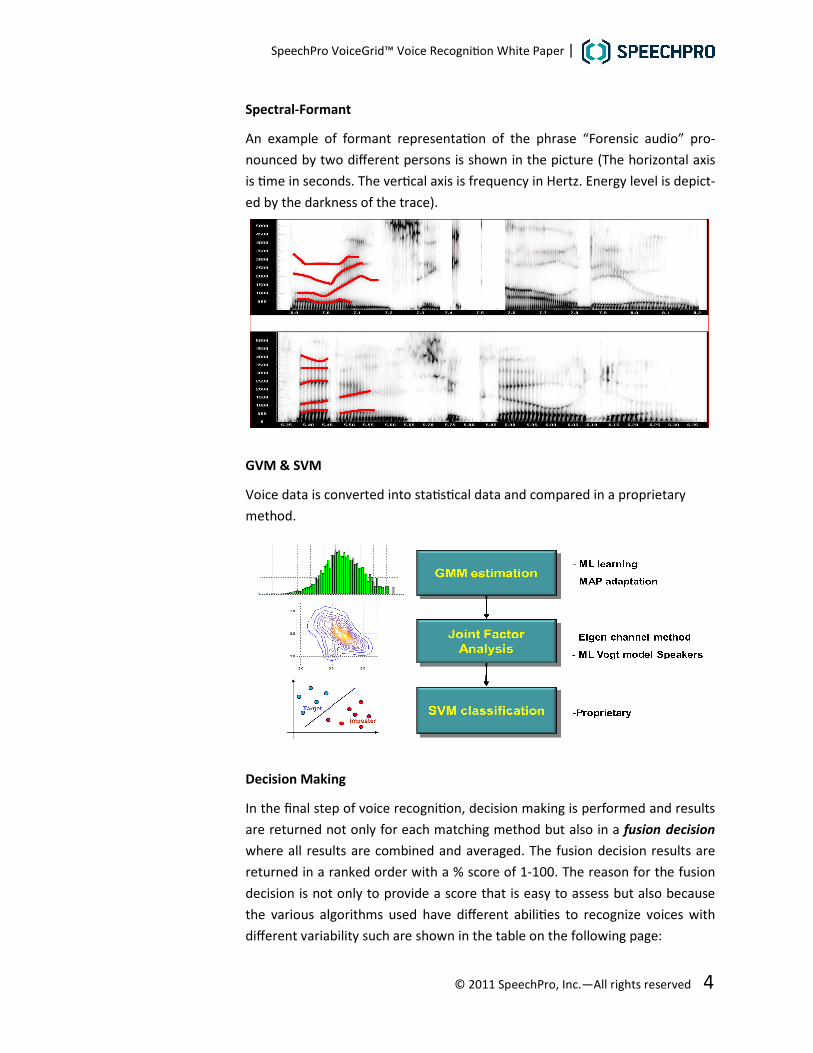
Spectral-Formant
An example of formant representaon of the phrase “Forensic audio” pro-
nounced by two different persons is shown in the picture (The horizontal axis
is me in seconds. The vercal axis is frequency in Hertz. Energy level is depict-
ed by the darkness of the trace).
GVM & SVM
Voice data is converted into stascal data and compared in a proprietary
method.
Decision Making
In the final step of voice recognion, decision making is performed and results
are returned not only for each matching method but also in a fusion decision
where all results are combined and averaged. The fusion decision results are
returned in a ranked order with a % score of 1-100. The reason for the fusion
decision is not only to provide a score that is easy to assess but also because
the various algorithms used have different abilies to recognize voices with
different variability such are shown in the table on the following page:
SpeechPro VoiceGrid™ Voice Recognion White Paper |
© 2011 SpeechPro, Inc.—All rights reserved 4

The Fusion Decision Example:
It should be noted here that the results returned by the technology should be
interpreted for the purpose of inclusion or exclusion of subjects and that if
posive idenficaon is required for court evidenary purposes, the services
of a forensic audio expert should be enlisted.
Accuracy
As with all 1:N biometrics, overall accuracy will be a product of the quality of
the data but with voice recognion it is also dependent on the quanty or
length of the voice data collected. In the following graph a sharp increase in
accuracy is noted within the first 15 seconds of voice data aOer which the ac-
curacy levels off .
VoiceGrid™ PERFORMANCE
SpeechPro VoiceGrid™ Voice Recognion White Paper |
© 2011 SpeechPro, Inc.—All rights reserved 5
The fusion decision
combines the re-
sults from each al-
gorithmic match
into a single score
which provides for
greater overall
compensaon of
speech signal char-
acterisc strengths.
Matching accuracy
is a product not just
of quality but also
of quanty.

System Scaling
The VoiceGrid™ technology can be scaled to address most any performance
needs. System performance will be a product of three factors which are data-
base size, enrollment quanty and response me. The average performance
based on a single core 2 Duo CPU @ 2GHz with 2GB RAM would be enrollment
of 6-12 records per minute and 3,000 to 40,000 comparisons per minute how-
ever the system can be opmized to perform over 1 Million matches per mi-
nute.
A key element in applying voice recognion technology is the creaon of the
voice databases. One reason that voice recognion is ideal for law enforce-
ment is the availability of data already being collected. 911 calls, suspect inter-
views, court recordings, voice mail, recordings made while speaking to com-
mercial service providers such as banks, cell phone companies, cable TV com-
panies can all provide a passive source for collecng data. Acve recording
such as during the booking process can provide an ideal known voice sample.
SpeechPro has developed a “best pracces” document for consideraon when
collecng voice data during the booking process. This includes such elements
as prompng the subject to say the alphabet, counng to 30 and stang their
name and address. However because of the text independent nature of the
technology it is not so important what the subject says as how much they say
or in other words as long as they are talking, the necessary data can be collect-
ed. In all cases the SpeechPro VoiceGrid™ technology has the ability to analyze
each recording, collect the necessary amount of audio informaon and pro-
vide a prompt back to the operator as to whether the sample is adequate for
matching. In the most recent VoiceGrid™ update the ability to automacally
separate the voices within a 2-person dialog and send each voice individually
for matching has been added.
Use cases for voice recognion are many and varied but overall voice recogni-
on is applicable in any situaon where audio may be the only lead or evi-
dence. Such cases include domesc abuse or calls in violaon of protecon
orders, prank or false emergency calls to 911, terrorisc threat calls, agency
radio communicaon abuse, inmate call monitoring, kidnapping, extoron,
corrupon, gang & organized crime communicaons and audio from video
VOICE DATA COLLECTION
USE CASES
SpeechPro VoiceGrid™ Voice Recognion White Paper |
© 2011 SpeechPro, Inc.—All rights reserved 6

recordings where the speakers are not visually idenfiable. In the following
scenarios the voice recordings of interest (VROI) could be obtained from any
number of different sources from both crimes and invesgaons including ter-
rorisc threats, kidnapping ransom calls, messages leO in violaon of protec-
on orders, gang or organized crime acvity etc.
Voice Recogni�on without a known database – 1). A VROI is obtained . 2.)
Invesgators interview a suspect pool and record the sessions. 3.) VoiceGrid™
Voice recognion is employed to match the original (latent) recording against
the suspect pool. 4.) Results are returned with confidence ranking and inves-
gators can include or exclude suspects.
Voice Recogni�on with a known database – 1.) A VROI is obtained . 2.) Inves-
gators employ VoiceGrid™ to send the unknown recording for possible match
against the previously obtained known database. 3.) A possible candidate list is
returned with confidence ranking. 4.) Invesgators can include or exclude sus-
pects.
Real Time Voice Recogni�on with a known watch list database – 1.) Invesga-
tors set up the lawful intercepon of mulple phone lines looking for a specific
individual whose voice is in a known VoiceGrid™ database. 2.) VoiceGrid™
technology monitors each phone line connually sampling the voices. 3.)
VoiceGrid™ technology idenfies a match and alerts the invesgator to which
phone line contains the voice of the suspect.
Audio Recording Indexing with a known watch list database – 1.) Invesga-
tors collect a large amount of recorded dialog from a lawful phone or eaves-
dropping intercepon. 2.) Invesgators are only interested in specific suspect
voices. Recordings are played into the VoiceGrid™ technology. 3.) VoiceGrid™
technology returns a report on where the specific voices have been idenfied
within the recordings. 4.) Invesgators can review the recordings which con-
tain voices only germane to their invesgaon.
In the preceding examples, voice recognion is employed by non-expert oper-
ators for inclusionary or exclusionary purposes. In all cases a decision could be
made to send the collected voice data on to a forensic audio expert for further
evidenary development but the inial assessment has now potenally pro-
vided value that would not otherwise be appreciated in the absence of the
automated capabilies.
SpeechPro VoiceGrid™ Voice Recognion White Paper |
© 2011 SpeechPro, Inc.—All rights reserved 7

The VoiceGrid™ technology has been developed to opmize voice recognion
matching performance and to compensate for typical variability of audio sam-
ples. It however is not fool-proof nor can it correct all issues with poor sam-
ples. As with any biometric technology the results will only be as good as the
quality of the data a*empng to be matched. In the early days of facial recog-
nion, inial a*empts to use exisng mug shot photos would in many cases
produce disappoinng results as the photographs had not been inially ac-
quired with facial recognion in mind and therefore lacked the quality re-
quired due to challenges with resoluon, pose or lighng. In much the same
way, some audio recordings have not been obtained and/or saved in the best
condions or formats to provide opmal voice recognion performance. While
one of the major benefits of voice recognion is that no “special” equipment
needs to be employed other than a good quality microphone, one should be
cognizant of the recording environment and also understand the difference
between high quality recording devices and their inferior low quality counter-
parts. As an example, a high quality microphone poorly placed within a room
where it is suscepble to echoes, ambient noise from fluorescent lighng and
too far away from the subject will most likely not produce a quality recording.
Conversely, a low quality recorder with a low sampling rate and no built-in
noise suppression will also most likely provide poor recording quality. This
does not mean that recordings for voice recognion need to take place within
a “sound studio” environment but rather it is an example to illustrate that re-
cordings of acceptable quality can be obtained at a negligible cost and equip-
ment difference if forethought is applied to the fact that they will be used at
some point for voice recognion and consideraons to that end are made in
advance.
Implementaon of the VoiceGrid™ technology can be achieved in several
ways. SpeechPro offers turn-key applicaons in various configuraons to ac-
commodate different size databases and system architectures from single
stand-alone applicaons which can run on a laptop or PC to LAN or WAN sys-
tems which support mulple workstaons, enrollment staons and databases.
Addionally SpeechPro can offer development support to interface Voice-
Grid™ technology to an exisng system. SpeechPro also offers the VoiceGrid™
SDK which allows an exisng soluons provider who has development re-
sources to integrate the VoiceGrid™ technology as an addional or new mo-
dality to an exisng idenficaon plaTorm.
ADDITIONAL CONSIDERATIONS
VoiceGrid™ IMPLEMENTATION
SpeechPro VoiceGrid™ Voice Recognion White Paper |
© 2011 SpeechPro, Inc.—All rights reserved 8
Consideraon
should now be giv-
en to the fact that
voices are now be-
ing recorded for
eventual voice
matching and not
just for playback
and review at a lat-
er date.
The VoiceGrid™
product line in-
cludes several ap-
plicaons and tools
to accommodate a
wide-range of cus-
tomer needs.

Voice recognion for law enforcement has been implemented primarily out-
side of the United States at this me. The best example is the naonwide sys-
tem put into place by the Mexican Federal Police. First implemented in 2010,
this system ulizes VoiceGrid™ technology to provide voice recognion against
a database of over 600,000 records accessed by over 250 jurisdicons across
the country. The system is projected to grow to over 1 million records during
2012 and has been instrumental in assisng to solve both kidnapping and cor-
rupon cases. The database is comprised primarily of voice samples obtained
during the criminal booking process as well as voice records from public work-
ers.
In the United States, SpeechPro has obtained commitment from a State Jusce
Agency to deploy a pilot system for the purposes of performance studies and
further development of best pracces for obtaining voice samples in a booking
environment and is currently working with a systems integrator to deliver the
beta version of the system by the end of 2011.
Addionally, voice recognion is a recognized emerging technology at the fed-
eral level in the United States as demonstrated by the endeavors and com-
ments of the following agencies:
NIST
• Developing Standards for Type 11 Record for Voice Biometrics
• Yearly Evaluaons Since 1996
FBI NGI
“The future of iden�fica�on systems is currently progressing beyond the de-
pendency of a unimodal (e.g., fingerprint) biometric iden�fier towards mul�-
modal biometrics (i.e., voice, iris, facial, etc.).”
FBI Biometric Center of Excellence
“A popular choice for remote authen�ca�on due to the availability of devices
for collec�ng speech samples (e.g., telephone network and computer micro-
phones) and its ease of integra�on.”
CURRENT USE
SpeechPro VoiceGrid™ Voice Recognion White Paper |
© 2011 SpeechPro, Inc.—All rights reserved 9

Voice recognion technology can add new and useful funconality to law en-
forcement invesgave and idenficaon operaons. The technology is cur-
rently viable for implementaon and has already been proven successful in
large naonal installaons.
Voice recognion certainly can be used in an individual modality but should
also be strongly considered as part of a mul-modal biometric program and as
an addional crime solving tool for law enforcement agencies.
In addion to voice matching, other voice and audio soluons & applicaons
should be considered as part of a comprehensive plan to best leverage exisng
and new audio data. Audio acquision, recording, noise filtering, audio au-
thencity and forensic audio processing are all integral elements to an effi-
cient, praccal and producve law enforcement audio program.
SpeechPro offers soluons to address all these aspects and is proud to be a
world leader in audio and voice technology. Our VoiceGrid™ technology repre-
sents the “best of breed” in commercially deployable voice recognion solu-
ons, but as with any biometric it is the sum of the performance capabilies,
operaonal procedures, quality of data and management of expectaons that
will define its effecveness in the long term.
For more informaon please contact:
SpeechPro
369 Lexington Avenue, Suite 316
New York, NY 10017
(646) 237-7895
www.speechpro.com
For immediate inquiries please contact:
Bill Michael
Na�onal Sales Director
(610) 867-8165
References—1 LAW AND THE EXPERT WITNESS- THE ADMISSIBILITY OF RECORDED EVI-
DENCE - Tom Owen, Jennifer Owen, Jill Lindsay, Michael McDermo*, Owl Invesga-
ons, Inc., Frank M. McDermo* Ltd. 2005
SpeechPro VoiceGrid™ Voice Recognion White Paper |
© 2011 SpeechPro, Inc.—All rights reserved 10
CONCLUSION The VoiceGrid™
Product Line
VoiceGrid™ Lab – stand-
alone applica�on for 1:N
searches of up to 100
records per individual
inves�ga�on.
VoiceGrid™ LN – single
server network solu�on
for 1:N searches, supports
a database of up to
10,000 records and up to
10 worksta�ons.
VoiceGrid™ ID – net-
worked 1:N search and
voice data management
solu�on with unlimited
database size and web
client worksta�on con-
nec�vity.
VoiceGrid™ X – a stand-
alone applica�on for
speaker iden�fica�on in
mul�ple files. Performs a
N:N search of up to 100
target speakers in up to
10,000 records per day.
VoiceGrid™ RT – distribut-
ed solu�on for real-�me
speaker iden�fica�on in
communica�on channels.
Integrates with voice
database up to 10,000
target speakers.
VoiceGrid™ SDK provides
the same tools and algo-
rithms available within
the VoiceGrid™ line but
with the ability for busi-
ness partners with devel-
opment resources to inte-
grate the technology into
their own plaForms.
Top Related