







Languages
Pages
Legal


Performance Testing ofBig Data
26 april 2016

2
Mobile PerformanceTesting
Roland van LeusdenPerformance Architect

3
WDM1.6 Tbit/s !

4 13-04-2016

5

6
Big Data refers to data that, because of its size, speed, or format-- that is, its volume, velocity, or variety-- cannot be easily stored, manipulated or analyzed with traditional methods, like spreadsheets, relational databases, or common statistical software.
7

8
Production likeBig Data Cluster
TestdataTeraBytes / PetaBytes
TestdataManagement ?
Load Generating Cluster

9

10
Corporate Data ArchitectureData is Fast Before it’s Big. Data often comes in streams into data systems. Events happening hundreds to tens of thousands of times a second.
http://www.internetlivestats.com/
The things we do with Fast Data :
• Ingest – get millions of events per second into the system• Decide – make a data-driven decision on each event• Analyze in real time – provide visibility into operational trends of the events

11
Lambda
http://www.ericsson.com/research-blog/data-knowledge/data-processing-architectures-lambda-and-kappa/

12
Kappa
http://www.ericsson.com/research-blog/data-knowledge/data-processing-architectures-lambda-and-kappa/
13
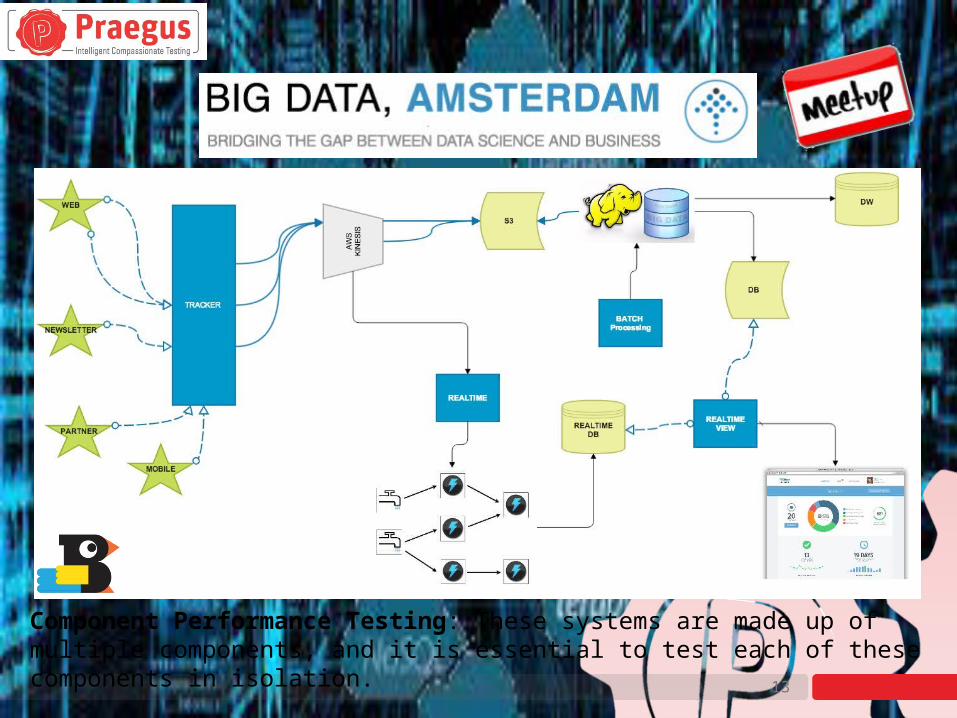
Component Performance Testing: These systems are made up of multiple components, and it is essential to test each of these components in isolation.
14
15
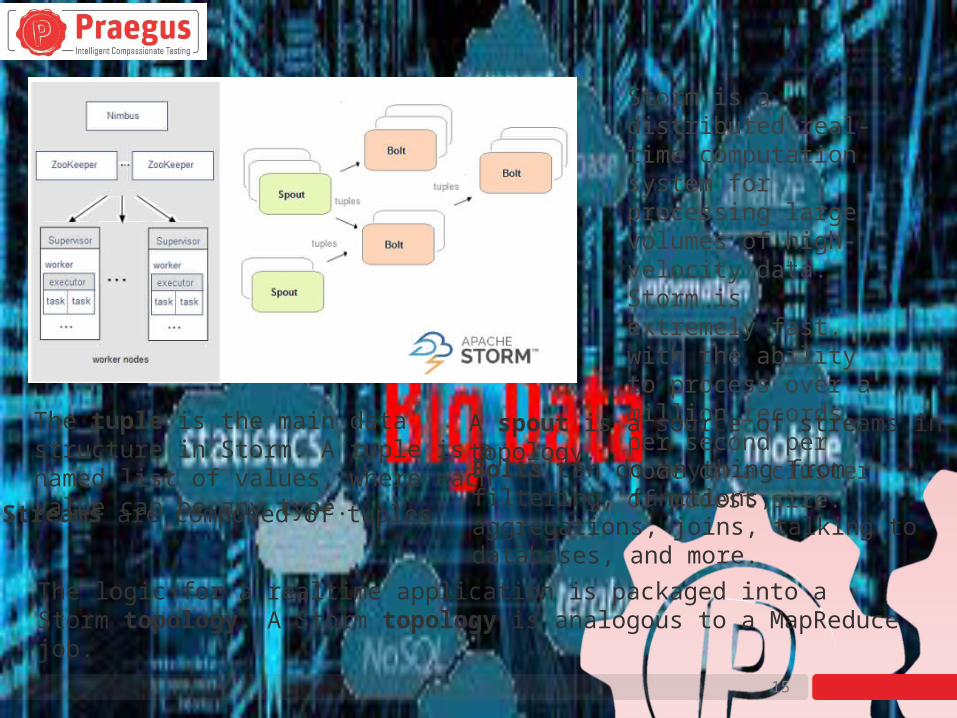
Storm is a distributed real-time computation system for processing large volumes of high-velocity data. Storm is extremely fast, with the ability to process over a million records per second per node on a cluster of modest size.
Bolts can do anything from filtering, functions, aggregations, joins, talking to databases, and more.
A spout is a source of streams in a topology.
Streams are composed of tuples
The logic for a realtime application is packaged into a Storm topology. A Storm topology is analogous to a MapReduce job.
The tuple is the main data structure in Storm. A tuple is a named list of values, where each value can be any type.

16

17
Due to a lack of real-world streaming benchmarks, we developed one to compare Apache Flink, Apache Storm and Apache Spark Streaming. It is released as open source: https://github.com/yahoo/streaming-benchmarks
Storm Benchmark tools authored by Taylor Goetz - https://github.com/ptgoetz/storm-benchmark
Storm Benchmark authored by Manu Zhang - https://github.com/manuzhang/storm-benchmark

18 13-04-2016
Apache distribution
• TestDFSIO read and write test for HDFS• TeraSort The goal of TeraSort is to sort 1TB of data (or any other amount)
as fast as possible. It is a benchmark that combines testing the HDFSand MapReduce layers of an Hadoop cluster.
• NNBench Is used for load testing the NameNode hardware and configuration.• MRBench Checks whether small jobs are responsive and running efficiently on
your cluster.
HiBench, a Hadoop benchmark suite consisting of both micro-benchmarks and real world applicationshttps://software.intel.com/en-us/blogs/2012/10/15/use-hibench-as-a-representative-proxy-for-benchmarking-hadoop-applications

19
Chukwa is an open source data collection system for monitoring andanalyzing large distributed systems. It is built on top of Hadoop andincludes a powerful and flexible toolkit for monitoring, analyzing, andviewing results. Many components of Chukwa are pluggable, allowingeasy customization and enhancement.
Monitoring
20
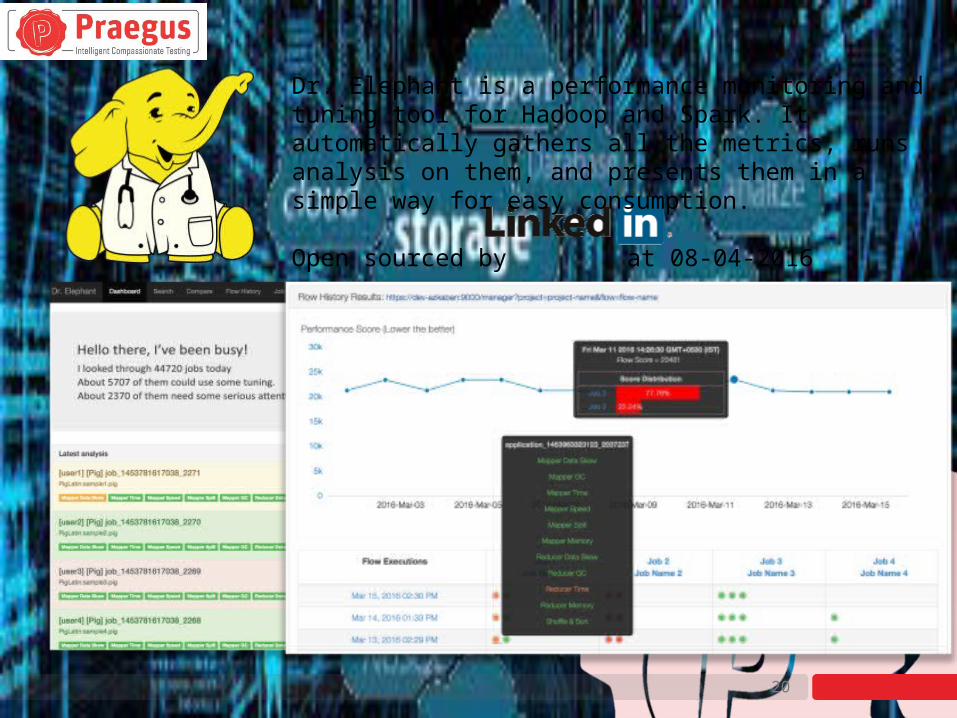
Dr. Elephant is a performance monitoring and tuning tool for Hadoop and Spark. It automatically gathers all the metrics, runs analysis on them, and presents them in a simple way for easy consumption.
Open sourced by at 08-04-2016

21
Thinking Scalability
Scalability is the ability of the software to keep up the performance even under increasing load by adding resources linearly. But achieving scalability requires more than just adding resources and tuning performance. To achieve scalability one needs to think holistically about software design, quality, maintainability and performance aspects.
Necessary conditions for Scalability
• Software has sound architecture and high quality• Software is easy to release, monitor and tweak.• Software performance can keep up with additional load by adding resources linearly.

22
23

Q & A
www.praegus.nl

25

26
Docker lets you limit a container’s CPU resources with the –cpu-shares flag
DataBase@1024 ~66%
WebServer@512 ~14%
Total Shares 1536
DataBase@1024 ~28%
WebServer@512 ~33%
Total Shares 3584ApplicationServer@2048 ~57%
CPU shares differ from memory limits in that they’re enforced only when there is contention for time on the CPU. If other processes and containers are idle, then the container may burst well beyond its limits.
Top Related