







Languages
Pages
Legal


Christophe Marchal | Software Architect
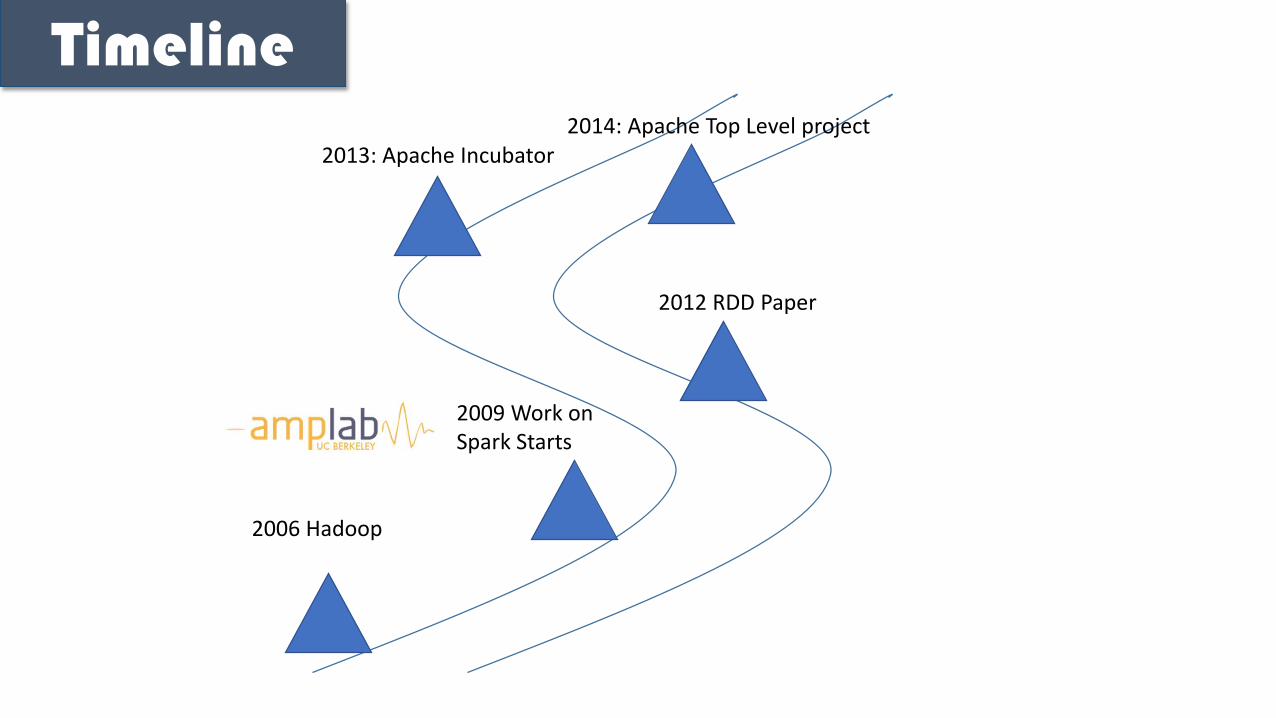
2006 Hadoop
2009 Work on Spark Starts
2012 RDD Paper
2013: Apache Incubator2014: Apache Top Level project
Timeline

Companies involved

What problem does it solve?
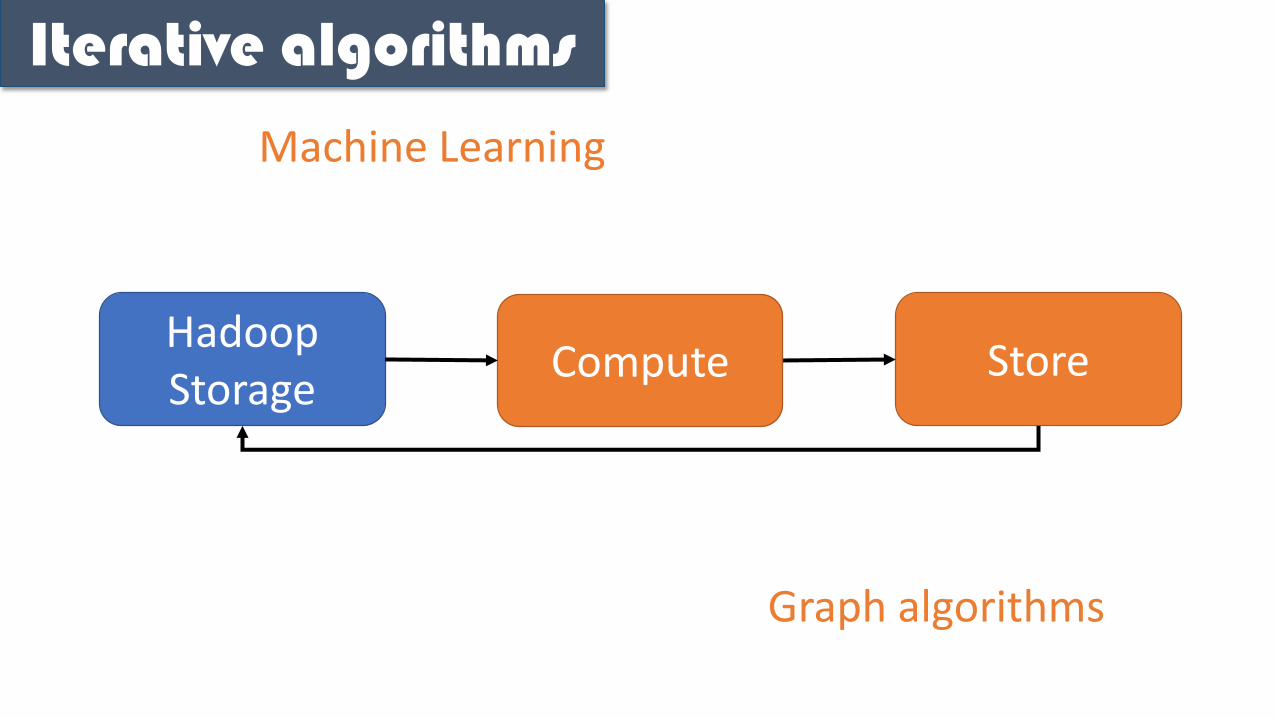
Hadoop Storage
Compute Store
Machine Learning
Graph algorithms
Iterative algorithms

Interactive Data Mining
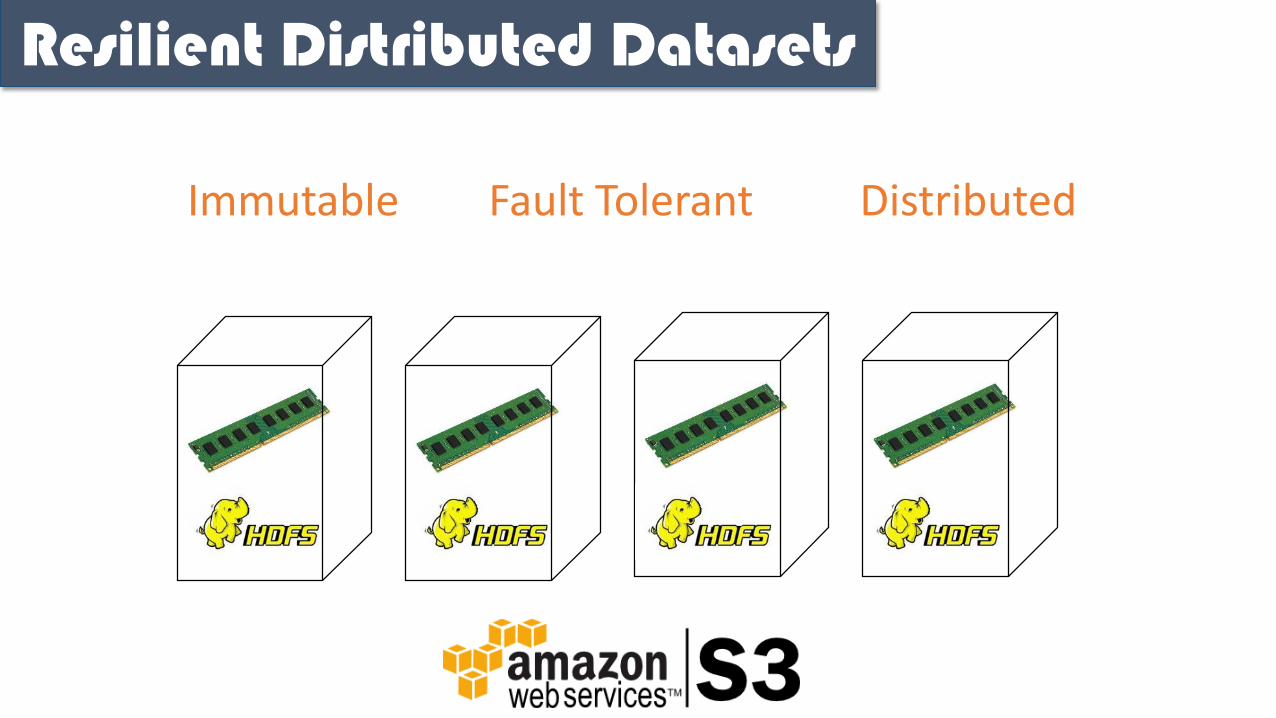
Resilient Distributed Datasets
Immutable Fault Tolerant Distributed

RDD Manipulation
Pure Lazy Functions
• map• flatMap• filter• mapPartitions• join• groupByKey• reduceByKey• …
Greedy Actions
• reduce• collect• count• first• take• saveAsTextFile• countByKey• …
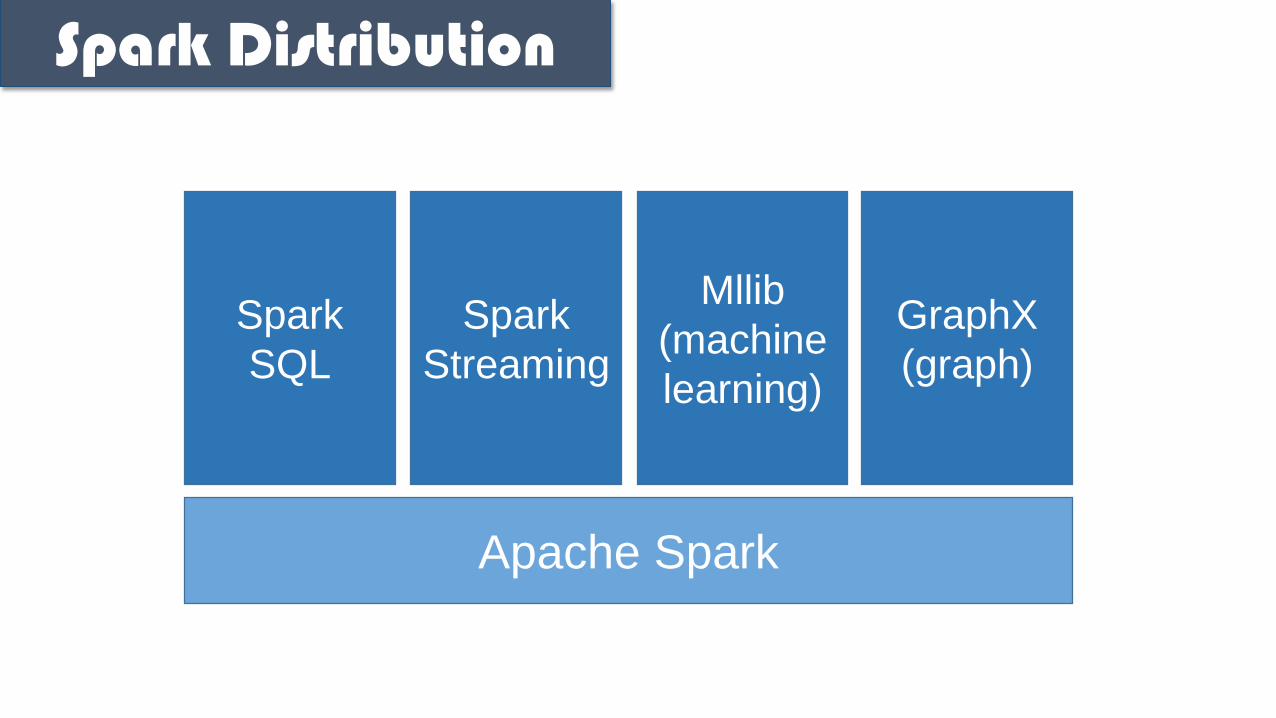
Spark Distribution
Apache Spark
Spark
SQL
Spark
Streaming
Mllib
(machine
learning)
GraphX
(graph)

Data Structure: RDD
RDD Any SERIALIZABLE Java Type
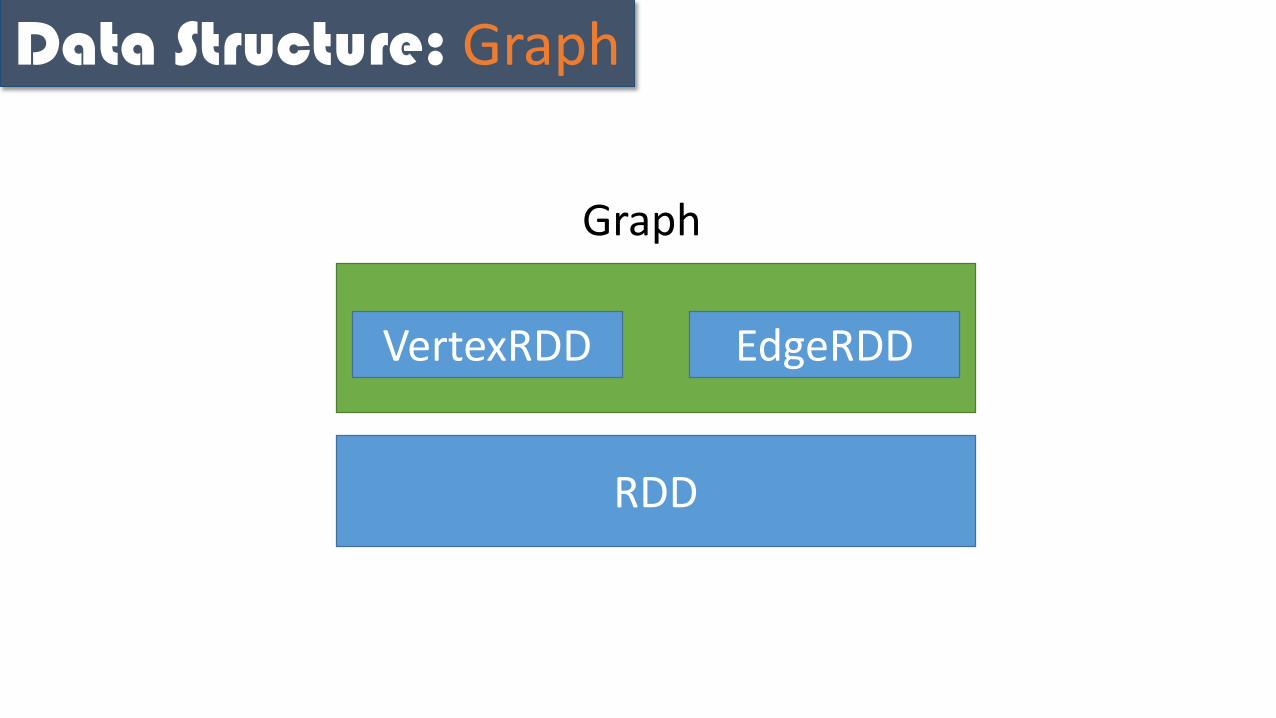
Data Structure: Graph
RDD
VertexRDD EdgeRDD
Graph

Data Structure: DataFrame
RDD
DataFrame
Any SERIALIZABLE Java Type
SQLML

Data Structure: DStream
data from 0 to 1
RDD @ time 1
data from 1 to 2
RDD @ time 2
data from 2 to 3
RDD @ time 3
data from 3 to 4
RDD @ time 4
data from 4 to 5
RDD @ time 5
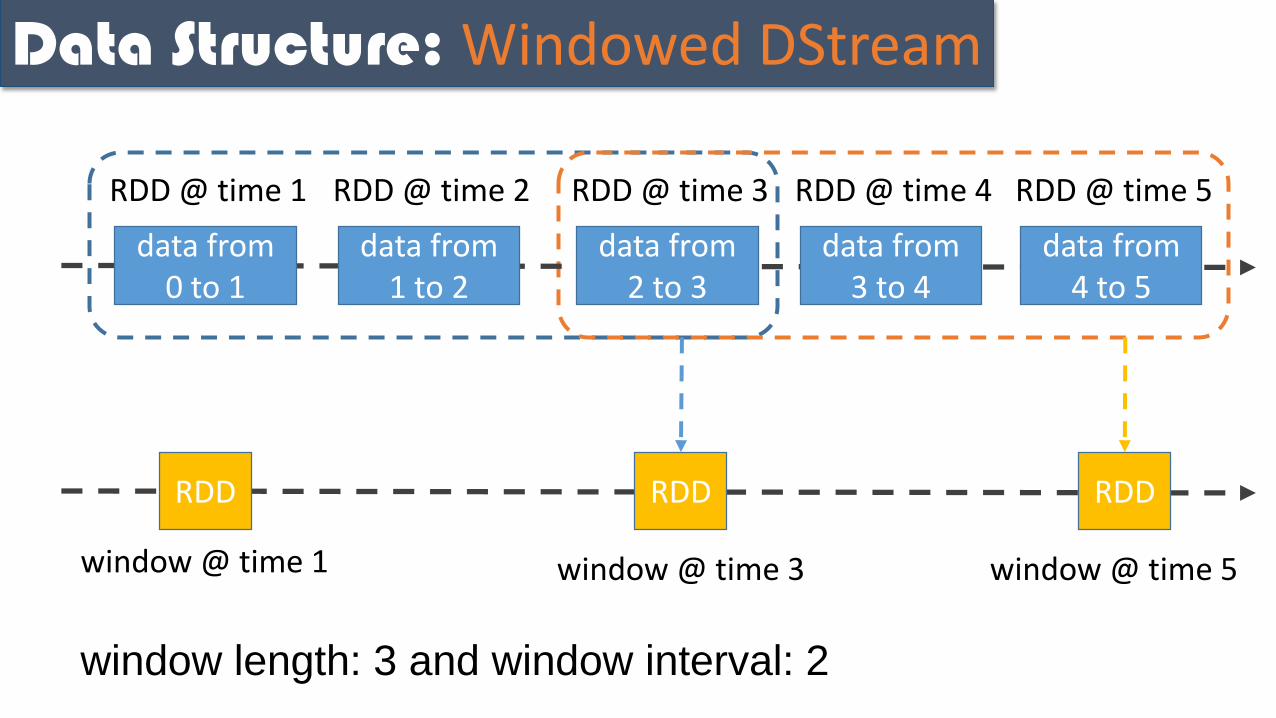
Data Structure: Windowed DStream
data from 0 to 1
RDD @ time 1
data from 1 to 2
RDD @ time 2
data from 2 to 3
RDD @ time 3
data from 3 to 4
RDD @ time 4
data from 4 to 5
RDD @ time 5
RDD
window @ time 1
RDD
window @ time 3
RDD
window @ time 5
window length: 3 and window interval: 2

ML, SQL, R on top of Stream
data from 0 to 1
RDD @ time 1
data from 1 to 2
RDD @ time 2
data from 2 to 3
RDD @ time 3
data from 3 to 4
RDD @ time 4
data from 4 to 5
RDD @ time 5
RDD RDD RDD
DF DF DF
SQLML


Supported Languages

Count words

Count words: Stream

Recommendation: Collaborative Filtering

Movie Recommendation

Movie Recommendation

Movie Recommendation

Movie Recommendation

Deploy
YARN
Standalone

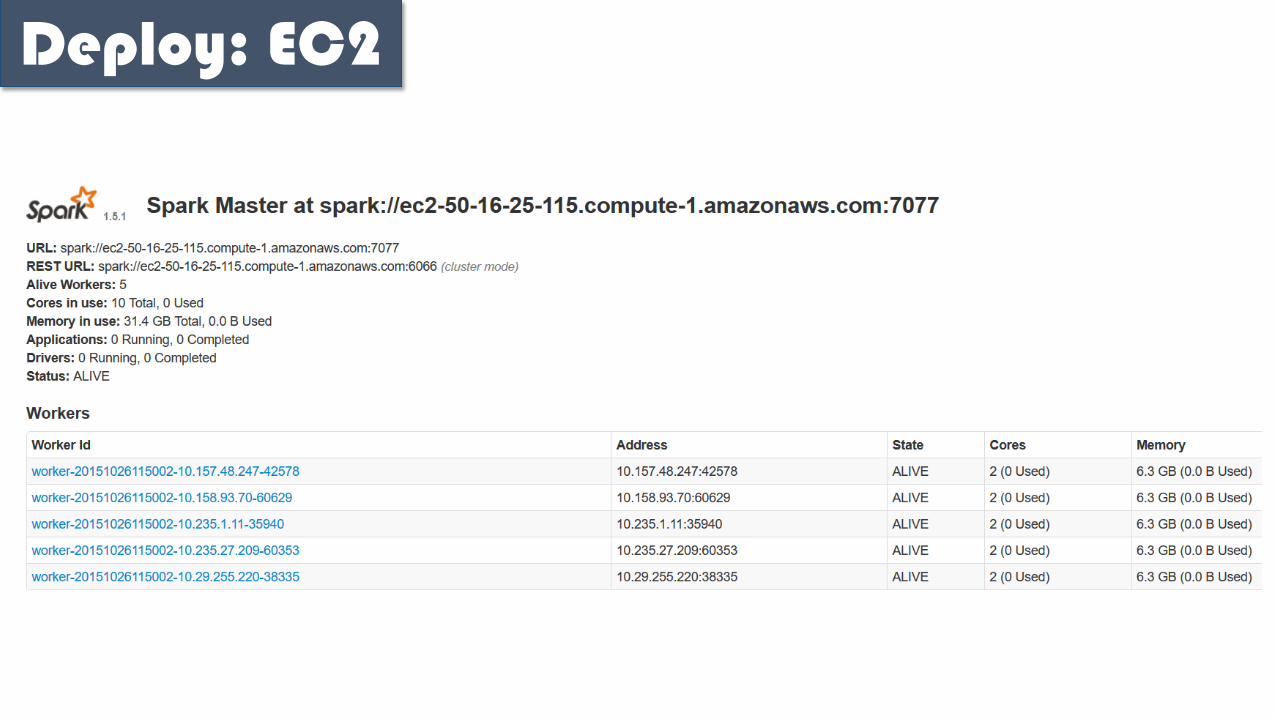
Deploy: EC2
spark-1.5.1-bin-hadoop2.6/ec2 $ ./spark-ec2 -k spark -ispark.pem -s 5 launch dojo-pacheco-spark-demo
EC2 cluster provisionning
root@ip-10-232-76-111 ephemeral-hdfs]$ ./bin/hadoop fs -put /home/ec2-user/ml-latest .
Insert dataset into HDFS
Deploy: EC2

Running Application
root@ip-10-232-76-111 spark]$ ./bin/spark-submit --master spark://ec2-50-16-25-115.compute-1.amazonaws.com:7077 --class MovieLensALS/home/ec2-user/movielens-als-assembly-0.1.jar . /home/ec2-user/personalRatings.txt > result 2>&1

Spark Execution monitoring
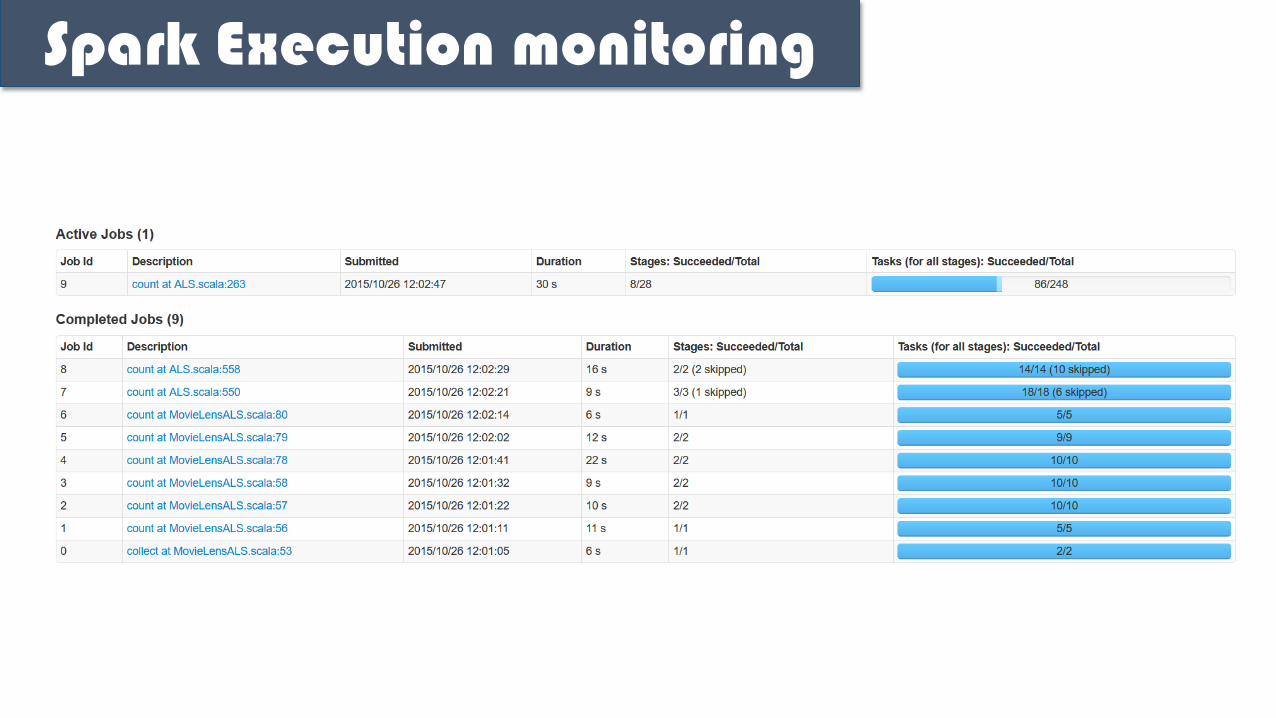
Spark Execution monitoring
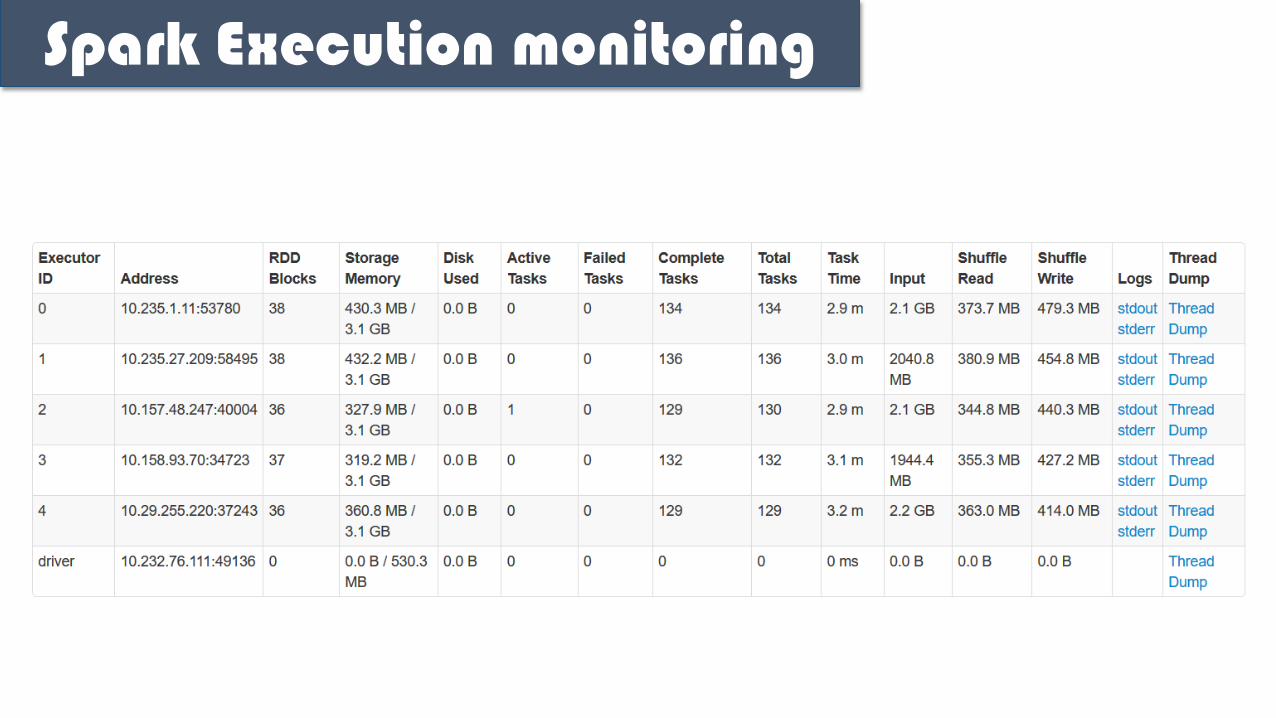
Spark Execution monitoring
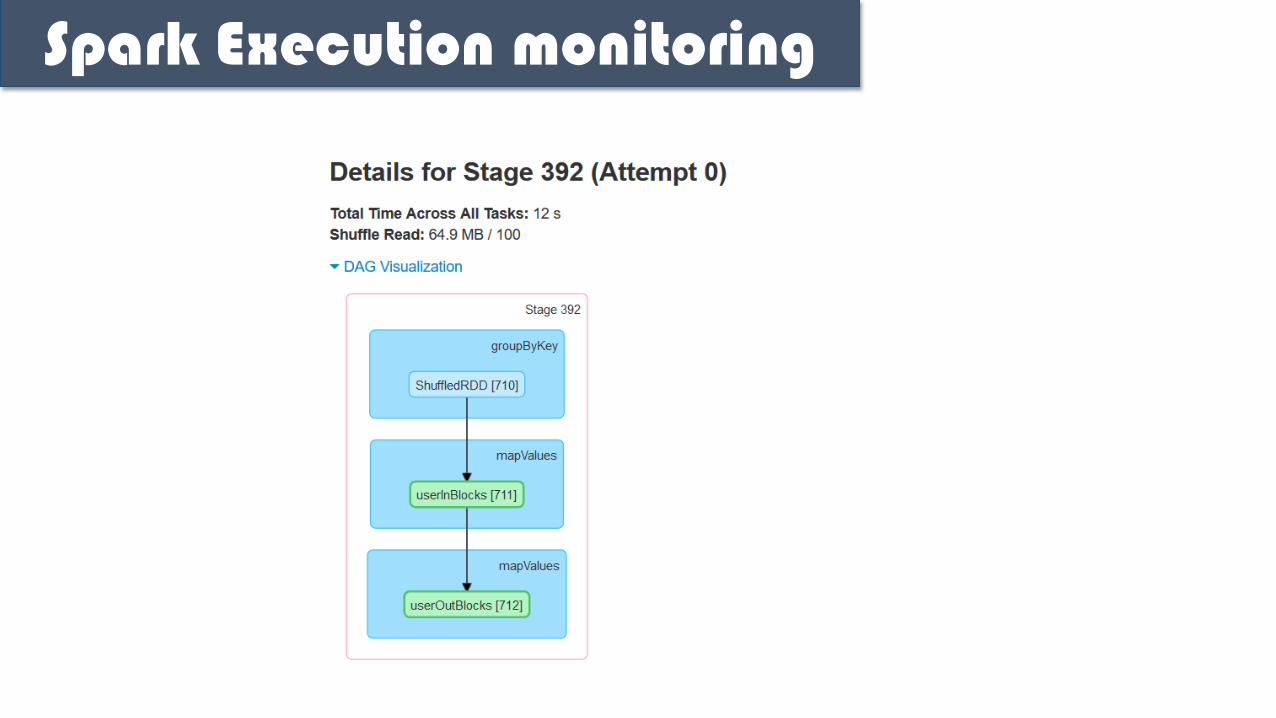
Spark Execution monitoring

Spark Execution monitoring

Christophe Marchal | Software Architect
Top Related