







Languages
Pages
Legal


OutlineFoster’s Parallel Algorithm Design Methodology
SCK 4213: High Performance &Parallel Computing
Chapter 3: Parallel Algorithm Design
Ismail Fauzi Isnin
Department of Computer Systems & CommunicationsFaculty of Computer Science & Information Systems,
Universiti Teknologi Malaysia
Semester 1 - 2011/2012
Ismail Fauzi Isnin SCK 4213: High Performance & Parallel Computing

OutlineFoster’s Parallel Algorithm Design Methodology
Parallel Algorithm Models
Outline
1 Principles of of Parallel Algorithm Design2 Parallel Algorithm Models3 Parallel Programming Models4 Foster’s Design Methodology
1 Partitioning2 Communication3 Agglomeration4 Mapping
Ismail Fauzi Isnin SCK 4213: High Performance & Parallel Computing

OutlineFoster’s Parallel Algorithm Design Methodology
Parallel Algorithm Models
Principles of Parallel Algorithm Design
In practice, specifying a nontrivial parallel algorithmmay include some or all of the following:
Identifying portions of the problem that can beperformed concurrently.Mapping the concurrent pieces of computationonto multiple processes running in parallel.Distribute inputs, outputs and intermediatedata among the processes.Managing access to data shared by multipleprocesses.Synchronizing the processors at various stagesof the parallel program execution.
Ismail Fauzi Isnin SCK 4213: High Performance & Parallel Computing

OutlineFoster’s Parallel Algorithm Design Methodology
Parallel Algorithm Models
Parallel Algorithm Models
1 Data Parallel Modelthe tasks are statically or semi staticallymapped onto processes and each tasksperforms similar operations.
2 Task Graph ModelComputations in any parallel algorithm can beviewed a task dependency graph. Thetask-graph is used to map the task ontoprocesses.
Ismail Fauzi Isnin SCK 4213: High Performance & Parallel Computing

OutlineFoster’s Parallel Algorithm Design Methodology
Parallel Algorithm Models
Parallel Algorithm Models
1 Work Pool Model / Task Pool ModelThe work pool or task pool model ischaracterised by a dynamic mapping of tasksinto process for load balancing in which anytask may potentially be performed by anyprocess. there is no desired premapping oftasks onto processes.
Ismail Fauzi Isnin SCK 4213: High Performance & Parallel Computing

OutlineFoster’s Parallel Algorithm Design Methodology
Parallel Algorithm Models
Parallel Algorithm Models
1 The Master-Slave ModelIn the master-slave or the manager-workermodel, one or more master process generatework and allocate it to worker processes.
2 The Pipeline ModelIn the pipeline mode, a stream of data ispassed through a succession of process, each ofwhich perform different task on the data. thissimulatneous execution of different process ona data stream is called stream parallelism.
Ismail Fauzi Isnin SCK 4213: High Performance & Parallel Computing

OutlineFoster’s Parallel Algorithm Design Methodology
Parallel Algorithm ModelsParallel Programming Models
Parallel Programming Models
1 Task and Channel Model2 Message Passing Model3 Data Parallelism4 Shared Memory
Ismail Fauzi Isnin SCK 4213: High Performance & Parallel Computing
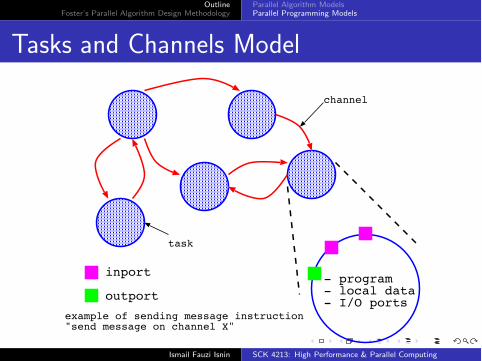
OutlineFoster’s Parallel Algorithm Design Methodology
Parallel Algorithm ModelsParallel Programming Models
Tasks and Channels Model
channel
task
- program- local data- I/O ports
inport
outport
example of sending message instruction"send message on channel X"
Ismail Fauzi Isnin SCK 4213: High Performance & Parallel Computing

OutlineFoster’s Parallel Algorithm Design Methodology
Parallel Algorithm ModelsParallel Programming Models
Tasks and Channels Model
Taska task consists of program (instructions), localmemory and collection of I/O ports.local memory contains the program instruction andlocal dataa task sending local data to other tasks throughoutports.a task receiving external data through inports.
Ismail Fauzi Isnin SCK 4213: High Performance & Parallel Computing

OutlineFoster’s Parallel Algorithm Design Methodology
Parallel Algorithm ModelsParallel Programming Models
Tasks and Channels Model
Channela channel is a message queue that connects anoutport of a task to an inport of another task.received data appear at the same order as theywere placed through outport of the sending task.
Ismail Fauzi Isnin SCK 4213: High Performance & Parallel Computing
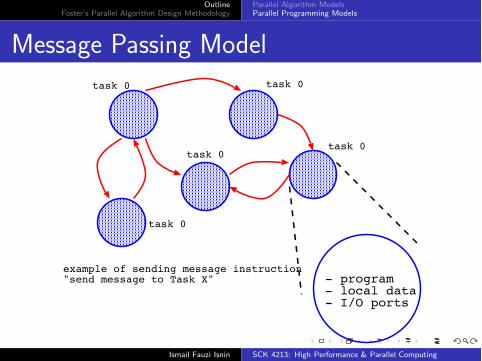
OutlineFoster’s Parallel Algorithm Design Methodology
Parallel Algorithm ModelsParallel Programming Models
Message Passing Modeltask 0
- program- local data- I/O ports
task 0
task 0task 0
task 0
example of sending message instruction"send message to Task X"
Ismail Fauzi Isnin SCK 4213: High Performance & Parallel Computing

OutlineFoster’s Parallel Algorithm Design Methodology
PartitioningCommunication
Foster’s Parallel Algorithm DesignMethodology
1 Partitioning2 Communication3 Agglomeration4 Mapping
Ismail Fauzi Isnin SCK 4213: High Performance & Parallel Computing

OutlineFoster’s Design Methodology
PartitioningCommunication
Foster’s Parallel Algorithm DesignMethodology
Ismail Fauzi Isnin SCK 4213: High Performance & Parallel Computing 13 / 29

OutlineFoster’s Parallel Algorithm Design Methodology
PartitioningCommunication
Partitioning
1 PartitioningThe process of dividing the computation task intosmaller pieces of tasks (primitive tasks).A good partitioning splits data and computationsinto many primitive tasks.
2 Aim of partitioningTo discover as much parallelism as possible.
3 Two approaches of partitioningData centric approach: Domain decomposition.Computation-centric approach: Functionaldecomposition.
Ismail Fauzi Isnin SCK 4213: High Performance & Parallel Computing

OutlineFoster’s Parallel Algorithm Design Methodology
PartitioningCommunication
Data-centric approach: Domaindecomposition
Domain decomposition divide data into piecesand then determine how to associatecomputation with the data.
Ismail Fauzi Isnin SCK 4213: High Performance & Parallel Computing
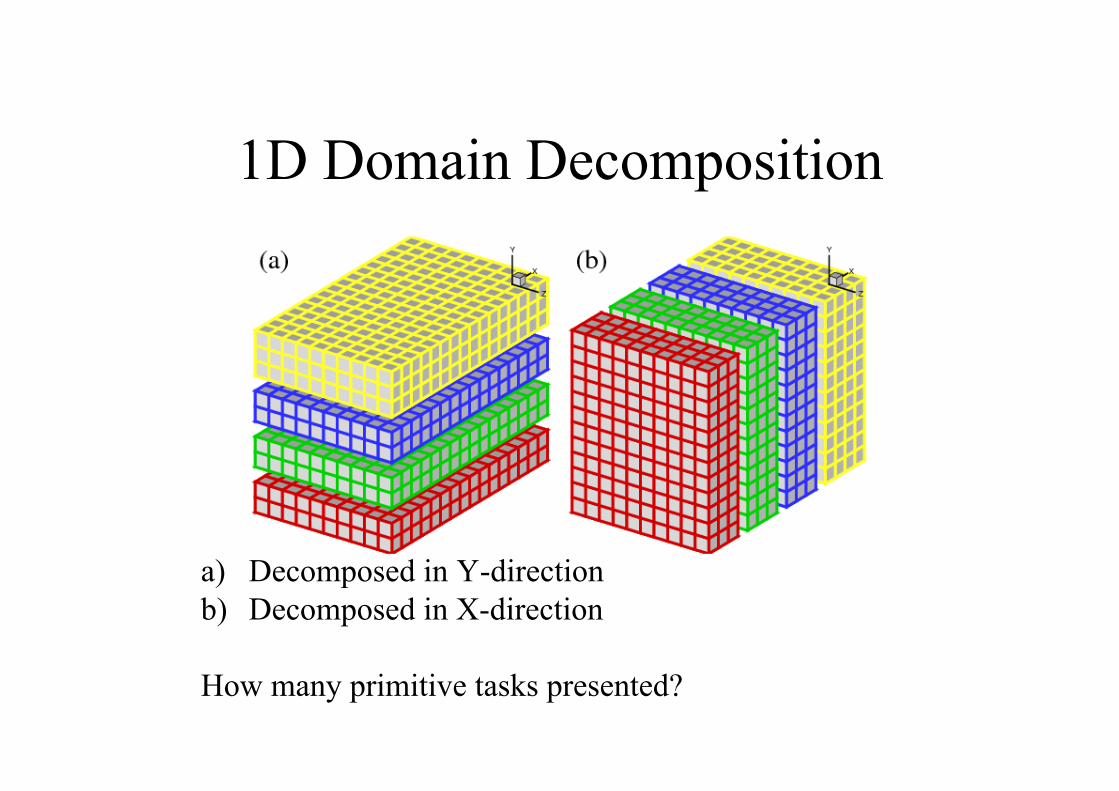
1D Domain Decomposition
a) Decomposed in Y-direction
b) Decomposed in X-direction
How many primitive tasks presented?
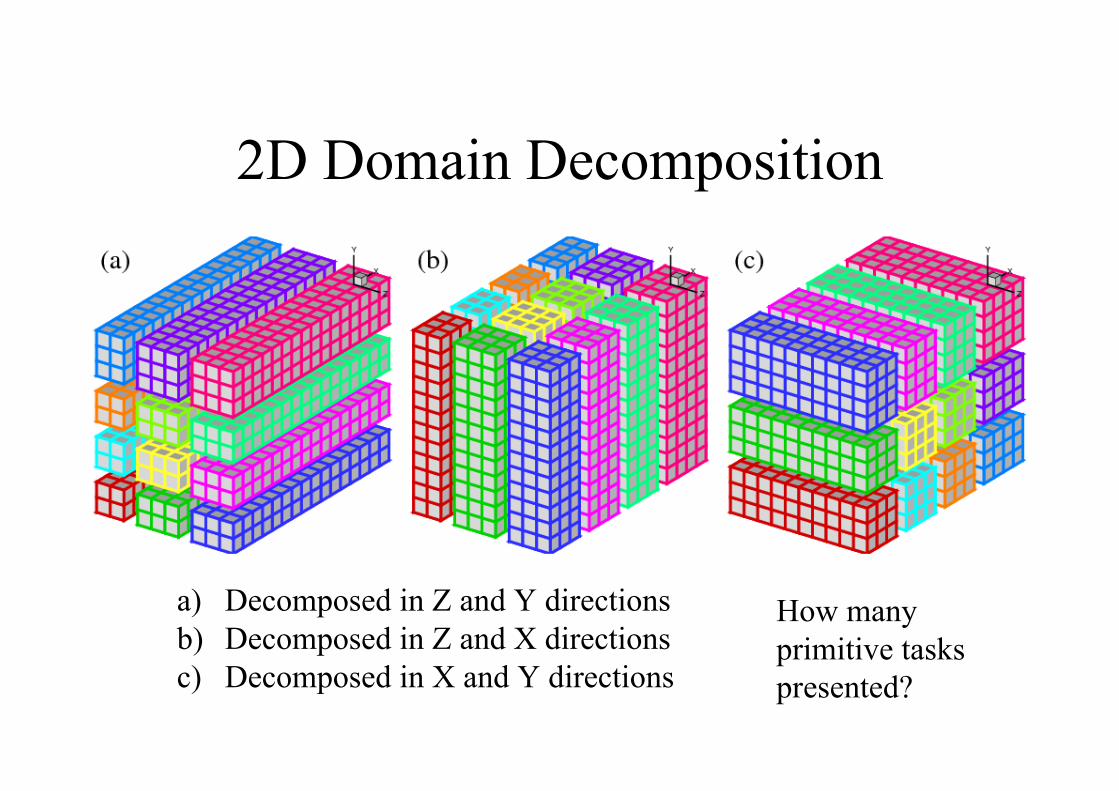
2D Domain Decomposition
a) Decomposed in Z and Y directions
b) Decomposed in Z and X directions
c) Decomposed in X and Y directions
How many
primitive tasks
presented?

3D Domain Decomposition?

OutlineFoster’s Parallel Algorithm Design Methodology
PartitioningCommunication
Computation-centric approach: Functionaldecomposition
Functional decomposition is thecomplimentary strategy that divide thecomputation into pieces, and then determinehow to associate data with the individualcomputations.
Oftenly, functional decompositions yieldcollection of tasks that achieve concurrencythrough pipeline parallelism.
Ismail Fauzi Isnin SCK 4213: High Performance & Parallel Computing

OutlineFoster’s Parallel Algorithm Design Methodology
PartitioningCommunication
Decomposition analogy
input outputWorkshop
100 cars to be fixed 100 working cars
Ismail Fauzi Isnin SCK 4213: High Performance & Parallel Computing

OutlineFoster’s Parallel Algorithm Design Methodology
PartitioningCommunication
Decomposition analogy (2)
100 cars to be fixed
50 cars 50 cars
Domain decomposition
fix air-cond(10 cars)
fix engine(10 cars)
fix wiring(30 cars)
fix air-cond(20 cars)
fix engine(10 cars)
fix wiring(20 cars)
Functional decomposition(complementary strategy)
Ismail Fauzi Isnin SCK 4213: High Performance & Parallel Computing

Decomposition Techniques
• The decomposition techniques we will
discuss :-
- Recursive decomposition
- Data decomposition
- Exploratory decomposition
- Speculative decomposition

Recursive Decomposition
• Recursive decomposition is a method for inducing
concurrency in problems that can be solved using the
divide and conquer strategy.
• A problem is solved by first dividing it into a set of
independent subproblems. Each of it is solved by
recursively applying a similar division into smaller
subproblems followed by a combination of the their
results.

Data Decomposition
• In this method, the decomposition is done in two steps. Inthe first step, the data on which the computations areperformed is partitioned. In the second step, this datapartitioning is used to induce a partitioning of thecomputation into tasks.
• The operations that these tasks performs on different datapartitions are usually similar.
• The partitioning can be done on input data, output data,both input and output data and also immediate data (outputthat is produced from one stage will be input to thesubsequent stage).

Exploratory Decomposition
• This technique is used to decomposeproblems whose underlying operationscorresponds to a search of a space forsolutions.
• The search space is partitioned into smallerparts concurrently, until the desiredsolutions are found.

Speculative Decomposition
• Speculative decomposition is used when a program may
take one of many possible computationally significant
branches depending on the output of other computations
that precede it.
• In this situation, while one task is performing the
computation whose output is used in deciding the next
computation, other tasks can concurrently start the
computation of the next stage.

OutlineFoster’s Parallel Algorithm Design Methodology
PartitioningCommunication
Foster’s Partitioning Checklist
number of primitive tasks (outcome ofpartitioning process) should be higher thannumber of processors in the target parallelcomputer. This increase the flexibility onsubsequent design stages.
minimize redundant data structure storage andredundant computations.
Ismail Fauzi Isnin SCK 4213: High Performance & Parallel Computing

OutlineFoster’s Parallel Algorithm Design Methodology
PartitioningCommunication
Foster’s Partitioning Checklist
primitive tasks are roughly the same size.
The number of primitive tasks is an increasingfunction of the problem size.
Maximize the flexibility of subsequent designstages by considering several alternativepartitioning? Domain decomposition,functional or both.
Ismail Fauzi Isnin SCK 4213: High Performance & Parallel Computing

OutlineFoster’s Parallel Algorithm Design Methodology
PartitioningCommunication
Communication
Typically, data must be transferred between tasks soas to allow computation to proceed. Thisinformation flow is specified in the communicationphase of a parallel algorithm design.
Ismail Fauzi Isnin SCK 4213: High Performance & Parallel Computing

OutlineFoster’s Parallel Algorithm Design Methodology
PartitioningCommunication
Communication categories
local and global communication
structured and unstructured communication
static and dynamic communication
synchronous and asynchronouscommunication
Ismail Fauzi Isnin SCK 4213: High Performance & Parallel Computing

OutlineFoster’s Parallel Algorithm Design Methodology
PartitioningCommunication
Communication categories
local communication - when a taskcommunicates with a small set of other tasks(its neighbours).
global communication - when a taskcommunicates with many other tasks.
Ismail Fauzi Isnin SCK 4213: High Performance & Parallel Computing 22 / 27

OutlineFoster’s Parallel Algorithm Design Methodology
PartitioningCommunication
Communication categories
structured communication - route of taskscommunication form a structured network suchas tree or grid.
unstructured communication - route oftasks communication form an arbitrary network.
Ismail Fauzi Isnin SCK 4213: High Performance & Parallel Computing

OutlineFoster’s Parallel Algorithm Design Methodology
PartitioningCommunication
Communication categories
static communication - the identity ofcommunication partners does not change overtime.
dynamic communication - identity ofcommunication partners may be determined bydata computed at runtime and may be highlyvariable.
Ismail Fauzi Isnin SCK 4213: High Performance & Parallel Computing

OutlineFoster’s Parallel Algorithm Design Methodology
PartitioningCommunication
Communication categories
synchronous communication - producer andconsumer execute in coordinated fashion.producer and consumer pairs cooperating indata transfer operations.
asynchronous communication - mayrequires that a task obtain/transmit datawithout the cooperation of the other tasks.
Ismail Fauzi Isnin SCK 4213: High Performance & Parallel Computing

OutlineFoster’s Parallel Algorithm Design Methodology
PartitioningCommunication
Issues in Communication phase
Communications between tasks may beconsidered as part of overhead of a parallelalgorithm.
Therefore, minimizing communication overheadis an important consideration to take whiledesigning a parallel algorithm.
Ismail Fauzi Isnin SCK 4213: High Performance & Parallel Computing

Methods of Containing
Interaction Overheads
• Maximizing data locality
- minimize volume of shared data
- minimize frequency of interaction among
tasks
• Minimizing contention
• Replicating data or computations

Foster’s design method:
communication checklist
• The communication operations are balancedamong tasks.
• Each tasks communicates with only a smallnumber of neighbors.
• Tasks can perform their communicationsconcurrently.
• Tasks can perform their computationsconcurrently.

Foster’s design methodology:
Agglomeration• Agglomeration
– Process of grouping tasks into larger tasks in order toimprove performance or simplify the programming.
– Goals of agglomeration:
• Lower communication overhead.
– Reduce number of communication channels.
– Reduce number of message transmissions.
• Maintain scalability of the parallel design.
– Ensure the algorithm is applicable on machine with highernumber of processors.
• Reduce software engineering cost.
– while parallelizing sequential algorithm, sometime it is better toremain some part of the sequential algorithm.

Foster’s Agglomeration checklist
• The agglomeration has increased thelocality of the parallel algorithm
• Replicated computations take less time thanthe communications they replace.
• The amount of replicated data is smallenough to allow the algorithm to scale.
• Agglomerated tasks has similarcomputational and communications costs.

Foster’s Agglomeration checklist
• The number of tasks is an increasing function ofthe problem size.
• The number of tasks is as small as possible, atleast as great as number of processors in the targetcomputers.
• The trade-off between the chosen agglomerationand the cost of modification in existing sequentialcode is reasonable.

Foster’s design method:
Mapping• Mapping
– is the process of assigning tasks to processors.
• Goals of mapping:
– Maximize processor utilization
– Minimize inter-processor communication.
• Processor Utilization
– the average percentage of time the system’s processorsare actively executing tasks necessary for the solutionof the problem.
– Processor utilization is maximized when computation isbalanced evenly.

Foster’s design method:
Mapping• Inter-processor communication decreases when
two tasks connected by a channel are mapped tothe same processor.

Mapping
• Map all tasks into a single processor will reduce
the inter-processor communication to zero, but
will results in poor processor utilization.
• Mapping tasks into a good processor utilization
sometimes will results poor inter-processor
communication.
• Increasing processor utilization and
minimizing inter-processor communication are
often conflicting goals.
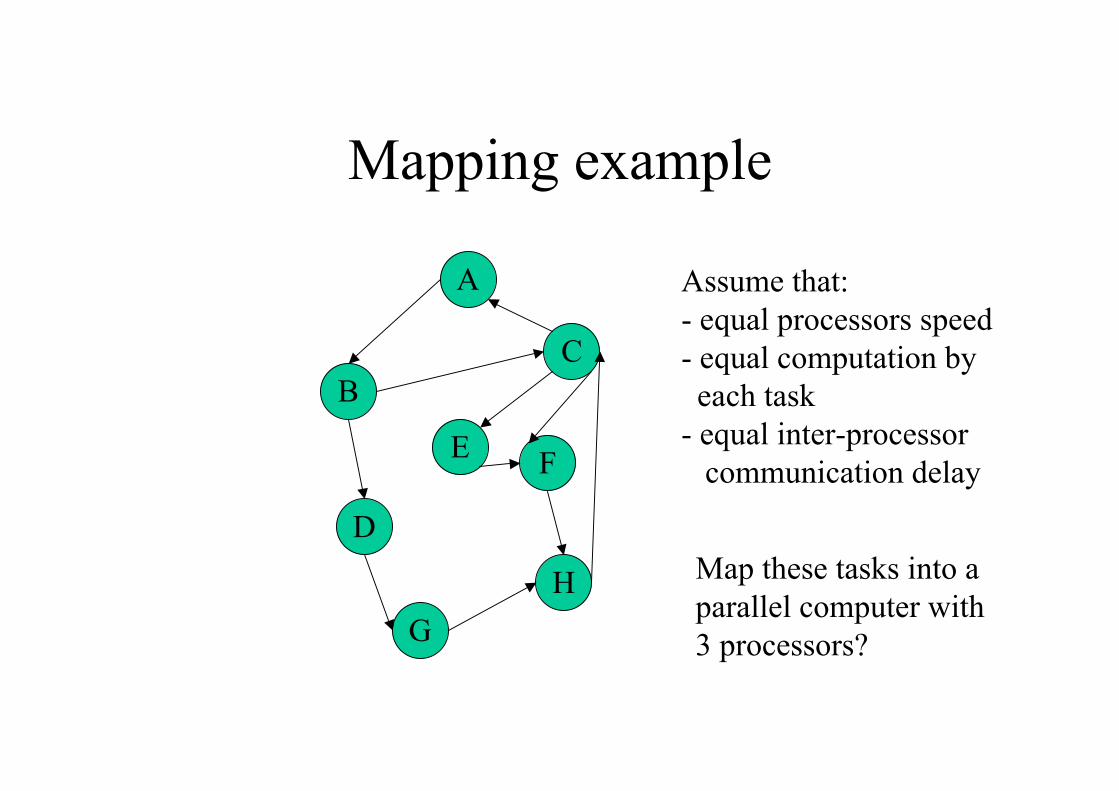
Mapping example
A
D
G
H
C
B
FE
Assume that:
- equal processors speed
- equal computation by
each task
- equal inter-processor
communication delay
Map these tasks into a
parallel computer with
3 processors?
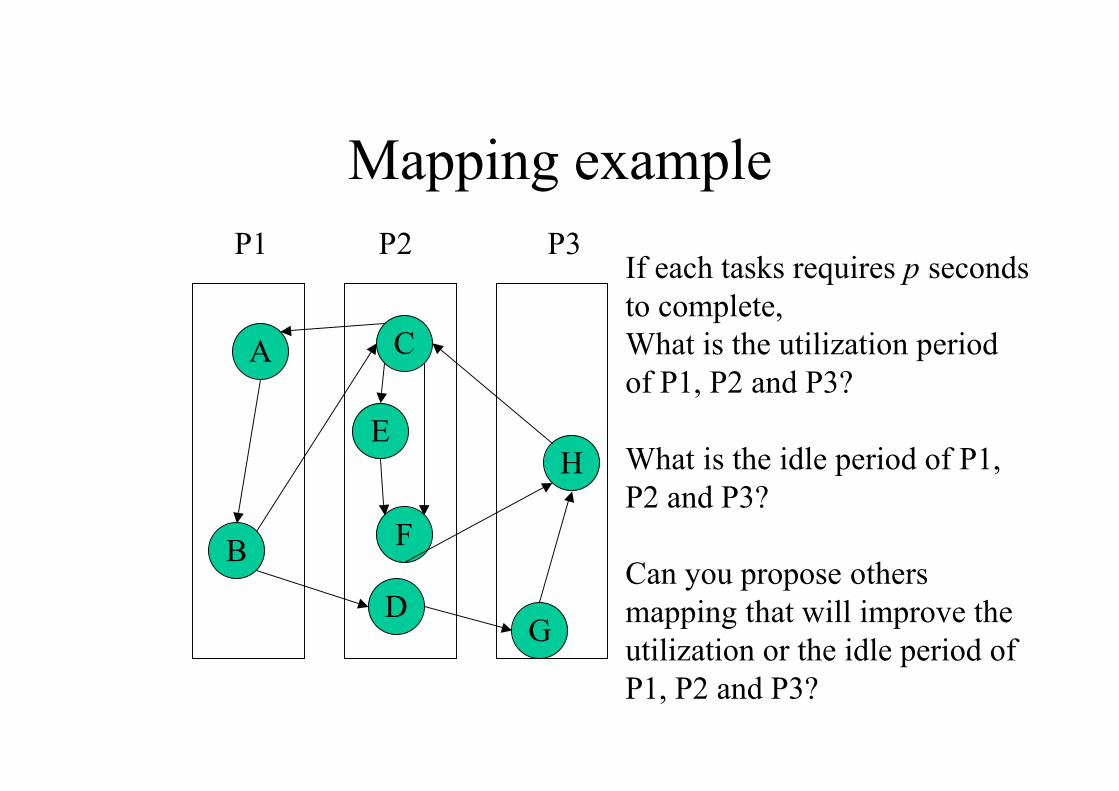
Mapping example
A
DG
H
C
BF
E
If each tasks requires p seconds
to complete,
What is the utilization period
of P1, P2 and P3?
What is the idle period of P1,
P2 and P3?
Can you propose others
mapping that will improve the
utilization or the idle period of
P1, P2 and P3?
P1 P2 P3

Mapping Techniques
• Mapping techniques can be broadly classified into two
categories: static and dynamic.
• Static mapping techniques distribute tasks among
processes prior to the execution of the algorithm.
• Dynamic mapping techniques distribute the work among
processes during the execution of the algorithm.

Schemes for Static Mapping
• Mappings base on Data Partitioning
Array Distribution Schemes
Block Distribution
In these distributions a d-dimensional array
is distributed among the processes. Each
process receives a contiguous block of arrayentries along a specified subset of arraydimensions.

Schemes for Static Mapping (2)
Array Distribution Schemes
Block Cyclic Distribution
A variation of the block distribution scheme
that can be used to alleviate load imbalance
and idling problems. The central idea behind a block cyclicdistribution is to partition an array into many more blocksthan the number of available processes. Then we assign thepartitions to processes in a round robin manner.

Schemes for Static Mapping (3)
Array Distribution Schemes
Randomized Block Distribution
In this scheme, the array is partitioned into many more
blocks than the number of the available processes. The
blocks are uniformly and randomly distributed among the
processes.

Schemes for Static Mapping (4)
• Mappings based on Task Partitioning
A mapping based on partitioning a task-dependency graph and mapping its nodesonto processes can be used when thecomputation is naturally expressible in theform of a static task-dependency graph withtask of known sizes.

Schemes for Dynamic Mapping
• Centralized Schemes
In a centralized dynamic load balancing scheme, all
executable tasks are maintained in a common central data
structure by a special process. If this process is designated
to manage a pool of available tasks, then it is often referred
as the master and other processes that depend on that
master to obtain work as slaves.

Schemes for Dynamic Mapping
(2)
• Distributed Schemes
In a distributed dynamic load balancing
scheme, the set of executable tasks are
distributed among processes which
exchange tasks at run time to balance work.
Each process can send work or receive work
from any other process.

OutlineFoster’s Design Methodology
PartitioningCommunication
References
Ian Foster, Designing and Building ParallelPrograms: Concepts and Tools for ParallelSoftware Engineering, Addison-Wesley, 1995.Barry Wilkinson and Michael Allen, ParallelProgramming: Techniques and ApplicationsUsing Networked Workstation and ParallelComputers, 2nd Edition, Pearson Prentice Hall,2005.Michael T. Heath, CSE 512 / CS 554 Lectureslides, University of Illinois.Michael J. Quinn, Parallel Programming in Cwith MPI and OpenMP, McGraw Hill, 2003.
Ismail Fauzi Isnin SCK 4213: High Performance & Parallel Computing 27 / 28
OutlineFoster’s Parallel Algorithm Design Methodology
PartitioningCommunication
Q & A
Ismail Fauzi Isnin SCK 4213: High Performance & Parallel Computing 27 / 27
Top Related