







Languages
Pages
Legal


10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.1
CS152Computer Architecture and Engineering
Lecture 16
Dynamic Scheduling (Cont), Speculation, and ILP
October 25, 1999
John Kubiatowicz (http.cs.berkeley.edu/~kubitron)
lecture slides: http://www-inst.eecs.berkeley.edu/~cs152/
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.2
Review: Compiler techniques for parallelism
° Loop unrolling ⇒ Multiple iterations of loop insoftware:
• Amortizes loop overhead over several iterations• Gives more opportunity for scheduling around stalls
° Software Pipelining ⇒ Take one instruction from eachof several iterations of the loop
• Software overlapping of loop iterations• Today will show hardware overlapping of loop iterations
° Very Long Instruction Word machines (VLIW) ⇒Multiple operations coded in single, long instruction
• Requires sophisticated compiler to decide whichoperations can be done in parallel
• Trace scheduling ⇒ find common path and schedulecode as if branches didn’t exist (+ add “fixup code”)
° All of these require additional registers
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.3
Review: Dynamic hardware for out-of-order execution° HW exploitation of ILP
• Works when can’t know dependence at compile time.• Code for one machine runs well on another
° Key idea of Scoreboard: Allow instructions behind stallto proceed (Decode => Issue instr & read operands)
• Enables out-of-order execution => out-of-order completion
• ID stage checked both for structural & data dependencies
• Original version didn’t handle forwarding.
• No automatic register renaming⇒stalls for WAR and WAW hazards
• Are these fundamental limitations??? (No)
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.4
° The Five Classic Components of a Computer
° Today’s Topics:• Recap last lecture
• Hardware loop unrolling with Tomasulo algorithm
• Administrivia
• Speculation, branch prediction
• Reorder buffers
The Big Picture: Where are We Now?
Control
Datapath
Memory
Processor
Input
Output
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.5
Another Dynamic Algorithm: Tomasulo Algorithm
° For IBM 360/91 about 3 years after CDC 6600 (1966)
° Goal: High Performance without special compilers
° Differences between IBM 360 & CDC 6600 ISA• IBM has only 2 register specifiers/instr vs. 3 in CDC 6600
• IBM has 4 FP registers vs. 8 in CDC 6600
• IBM has memory-register ops
° Why Study? lead to Alpha 21264, HP 8000, MIPS 10000,Pentium II, PowerPC 604, …
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.6
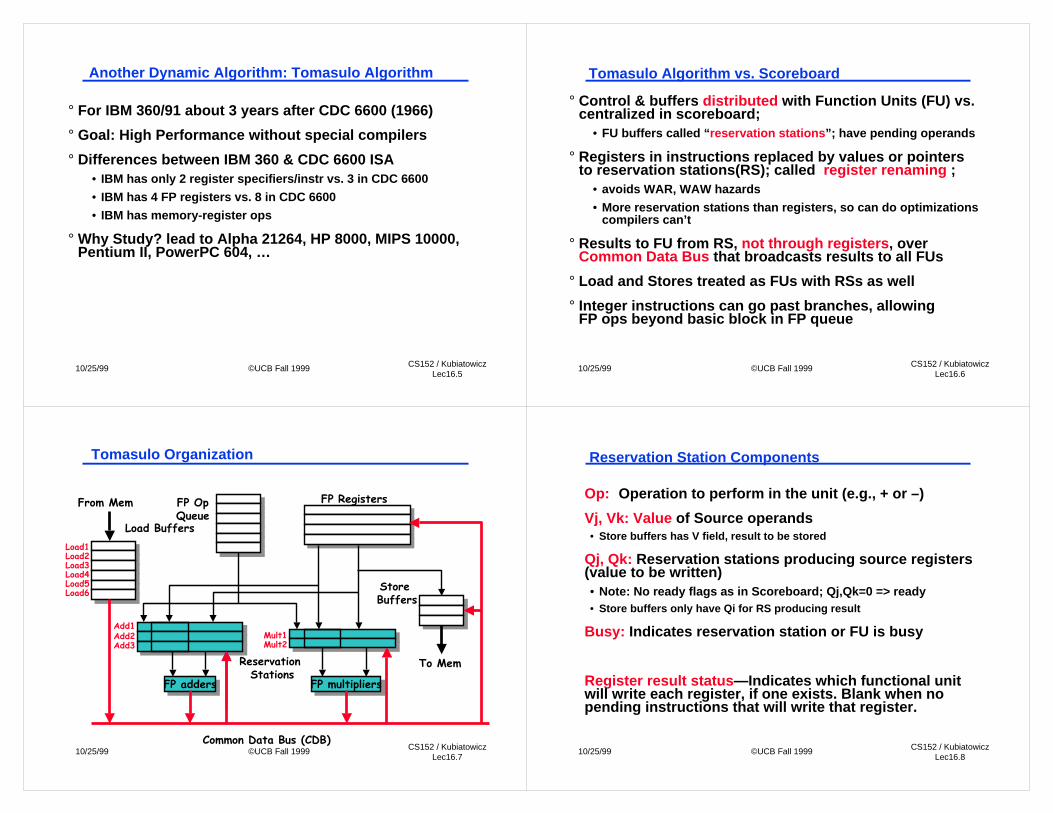
Tomasulo Algorithm vs. Scoreboard
° Control & buffers distributed with Function Units (FU) vs.centralized in scoreboard;
• FU buffers called “reservation stations”; have pending operands
° Registers in instructions replaced by values or pointersto reservation stations(RS); called register renaming ;
• avoids WAR, WAW hazards
• More reservation stations than registers, so can do optimizationscompilers can’t
° Results to FU from RS, not through registers, overCommon Data Bus that broadcasts results to all FUs
° Load and Stores treated as FUs with RSs as well
° Integer instructions can go past branches, allowingFP ops beyond basic block in FP queue
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.7
Tomasulo Organization
������������������
��������
��� ������������� ����������
���������
��� ��� ������������
��������������������
�� �����������������
�����
��� �!����
"������##���
��������##���
"���"����"����"���$"���%"���&
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.8
Reservation Station Components
Op: Operation to perform in the unit (e.g., + or –)
Vj, Vk: Value of Source operands• Store buffers has V field, result to be stored
Qj, Qk: Reservation stations producing source registers(value to be written)• Note: No ready flags as in Scoreboard; Qj,Qk=0 => ready• Store buffers only have Qi for RS producing result
Busy: Indicates reservation station or FU is busy
Register result status—Indicates which functional unitwill write each register, if one exists. Blank when nopending instructions that will write that register.

10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.9
Three Stages of Tomasulo Algorithm
1. Issue—get instruction from FP Op Queue If reservation station free (no structural hazard),
control issues instr & sends operands (renames registers).
2. Execution—operate on operands (EX) When both operands ready then execute;
if not ready, watch Common Data Bus for result
3. Write result—finish execution (WB) Write on Common Data Bus to all awaiting units;
mark reservation station available
° Normal data bus: data + destination (“go to” bus)
° Common data bus: data + source (“come from” bus)• 64 bits of data + 4 bits of Functional Unit source address
• Write if matches expected Functional Unit (produces result)
• Does the broadcast
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.10
Tomasulo Example
Instruction status: Exec Write
Instruction j k Issue Comp Result Busy AddressLD F6 34+ R2 Load1 NoLD F2 45+ R3 Load2 NoMULTD F0 F2 F4 Load3 NoSUBD F8 F6 F2DIVD F10 F0 F6ADDD F6 F8 F2
Reservation Stations: S1 S2 RS RS
Time Name Busy Op Vj Vk Qj QkAdd1 NoAdd2 NoAdd3 NoMult1 NoMult2 No
Register result status:Clock F0 F2 F4 F6 F8 F10 F12 ... F30
0 FU
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.11
Tomasulo Example Cycle 1
Instruction status: Exec Write
Instruction j k Issue Comp Result Busy AddressLD F6 34+ R2 1 Load1 Yes 34+R2LD F2 45+ R3 Load2 NoMULTD F0 F2 F4 Load3 NoSUBD F8 F6 F2DIVD F10 F0 F6ADDD F6 F8 F2
Reservation Stations: S1 S2 RS RS
Time Name Busy Op Vj Vk Qj QkAdd1 NoAdd2 NoAdd3 NoMult1 NoMult2 No
Register result status:Clock F0 F2 F4 F6 F8 F10 F12 ... F30
1 FU Load1
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.12
Instruction status: Exec Write
Instruction j k Issue Comp Result Busy AddressLD F6 34+ R2 1 Load1 Yes 34+R2LD F2 45+ R3 2 Load2 Yes 45+R3MULTD F0 F2 F4 Load3 NoSUBD F8 F6 F2DIVD F10 F0 F6ADDD F6 F8 F2
Reservation Stations: S1 S2 RS RS
Time Name Busy Op Vj Vk Qj QkAdd1 NoAdd2 NoAdd3 NoMult1 NoMult2 No
Register result status:Clock F0 F2 F4 F6 F8 F10 F12 ... F30
2 FU Load2 Load1
������������� ��������������������������������
Tomasulo Example Cycle 2

10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.13
Instruction status: Exec Write
Instruction j k Issue Comp Result Busy AddressLD F6 34+ R2 1 3 Load1 Yes 34+R2LD F2 45+ R3 2 Load2 Yes 45+R3MULTD F0 F2 F4 3 Load3 NoSUBD F8 F6 F2DIVD F10 F0 F6ADDD F6 F8 F2
Reservation Stations: S1 S2 RS RS
Time Name Busy Op Vj Vk Qj QkAdd1 NoAdd2 NoAdd3 NoMult1 Yes MULTD R(F4) Load2Mult2 No
Register result status:Clock F0 F2 F4 F6 F8 F10 F12 ... F30
3 FU Mult1 Load2 Load1
� ���������������������������������������������������������������� �!�"#���������$������%����
� "���&��������� �'������'�����(���"���&)
Tomasulo Example Cycle 3
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.14
Instruction status: Exec Write
Instruction j k Issue Comp Result Busy AddressLD F6 34+ R2 1 3 4 Load1 NoLD F2 45+ R3 2 4 Load2 Yes 45+R3MULTD F0 F2 F4 3 Load3 NoSUBD F8 F6 F2 4DIVD F10 F0 F6ADDD F6 F8 F2
Reservation Stations: S1 S2 RS RS
Time Name Busy Op Vj Vk Qj QkAdd1 Yes SUBD M(A1) Load2Add2 NoAdd3 NoMult1 Yes MULTD R(F4) Load2Mult2 No
Register result status:Clock F0 F2 F4 F6 F8 F10 F12 ... F30
4 FU Mult1 Load2 M(A1) Add1
� "���*��������� �'������'�����(���"���&)
Tomasulo Example Cycle 4
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.15
Instruction status: Exec Write
Instruction j k Issue Comp Result Busy AddressLD F6 34+ R2 1 3 4 Load1 NoLD F2 45+ R3 2 4 5 Load2 NoMULTD F0 F2 F4 3 Load3 NoSUBD F8 F6 F2 4DIVD F10 F0 F6 5ADDD F6 F8 F2
Reservation Stations: S1 S2 RS RS
Time Name Busy Op Vj Vk Qj Qk2 Add1 Yes SUBD M(A1) M(A2)
Add2 NoAdd3 No
10 Mult1 Yes MULTD M(A2) R(F4)Mult2 Yes DIVD M(A1) Mult1
Register result status:Clock F0 F2 F4 F6 F8 F10 F12 ... F30
5 FU Mult1 M(A2) M(A1) Add1 Mult2
Tomasulo Example Cycle 5
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.16
Instruction status: Exec Write
Instruction j k Issue Comp Result Busy AddressLD F6 34+ R2 1 3 4 Load1 NoLD F2 45+ R3 2 4 5 Load2 NoMULTD F0 F2 F4 3 Load3 NoSUBD F8 F6 F2 4DIVD F10 F0 F6 5ADDD F6 F8 F2 6
Reservation Stations: S1 S2 RS RS
Time Name Busy Op Vj Vk Qj Qk1 Add1 Yes SUBD M(A1) M(A2)
Add2 Yes ADDD M(A2) Add1Add3 No
9 Mult1 Yes MULTD M(A2) R(F4)Mult2 Yes DIVD M(A1) Mult1
Register result status:Clock F0 F2 F4 F6 F8 F10 F12 ... F30
6 FU Mult1 M(A2) Add2 Add1 Mult2
� +�����,---��������$������%����)
Tomasulo Example Cycle 6

10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.17
Instruction status: Exec Write
Instruction j k Issue Comp Result Busy AddressLD F6 34+ R2 1 3 4 Load1 NoLD F2 45+ R3 2 4 5 Load2 NoMULTD F0 F2 F4 3 Load3 NoSUBD F8 F6 F2 4 7DIVD F10 F0 F6 5ADDD F6 F8 F2 6
Reservation Stations: S1 S2 RS RS
Time Name Busy Op Vj Vk Qj Qk0 Add1 Yes SUBD M(A1) M(A2)
Add2 Yes ADDD M(A2) Add1Add3 No
8 Mult1 Yes MULTD M(A2) R(F4)Mult2 Yes DIVD M(A1) Mult1
Register result status:Clock F0 F2 F4 F6 F8 F10 F12 ... F30
7 FU Mult1 M(A2) Add2 Add1 Mult2
� ,��&��������� �'������'�����(����)
Tomasulo Example Cycle 7
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.18
Instruction status: Exec Write
Instruction j k Issue Comp Result Busy AddressLD F6 34+ R2 1 3 4 Load1 NoLD F2 45+ R3 2 4 5 Load2 NoMULTD F0 F2 F4 3 Load3 NoSUBD F8 F6 F2 4 7 8DIVD F10 F0 F6 5ADDD F6 F8 F2 6
Reservation Stations: S1 S2 RS RS
Time Name Busy Op Vj Vk Qj QkAdd1 No
2 Add2 Yes ADDD (M-M) M(A2)Add3 No
7 Mult1 Yes MULTD M(A2) R(F4)Mult2 Yes DIVD M(A1) Mult1
Register result status:Clock F0 F2 F4 F6 F8 F10 F12 ... F30
8 FU Mult1 M(A2) Add2 (M-M) Mult2
Tomasulo Example Cycle 8
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.19
Instruction status: Exec Write
Instruction j k Issue Comp Result Busy AddressLD F6 34+ R2 1 3 4 Load1 NoLD F2 45+ R3 2 4 5 Load2 NoMULTD F0 F2 F4 3 Load3 NoSUBD F8 F6 F2 4 7 8DIVD F10 F0 F6 5ADDD F6 F8 F2 6
Reservation Stations: S1 S2 RS RS
Time Name Busy Op Vj Vk Qj QkAdd1 No
1 Add2 Yes ADDD (M-M) M(A2)Add3 No
6 Mult1 Yes MULTD M(A2) R(F4)Mult2 Yes DIVD M(A1) Mult1
Register result status:Clock F0 F2 F4 F6 F8 F10 F12 ... F30
9 FU Mult1 M(A2) Add2 (M-M) Mult2
Tomasulo Example Cycle 9
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.20
Instruction status: Exec Write
Instruction j k Issue Comp Result Busy AddressLD F6 34+ R2 1 3 4 Load1 NoLD F2 45+ R3 2 4 5 Load2 NoMULTD F0 F2 F4 3 Load3 NoSUBD F8 F6 F2 4 7 8DIVD F10 F0 F6 5ADDD F6 F8 F2 6 10
Reservation Stations: S1 S2 RS RS
Time Name Busy Op Vj Vk Qj QkAdd1 No
0 Add2 Yes ADDD (M-M) M(A2)Add3 No
5 Mult1 Yes MULTD M(A2) R(F4)Mult2 Yes DIVD M(A1) Mult1
Register result status:Clock F0 F2 F4 F6 F8 F10 F12 ... F30
10 FU Mult1 M(A2) Add2 (M-M) Mult2
� ,��*��������� �'������'�����(����)
Tomasulo Example Cycle 10

10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.21
Instruction status: Exec Write
Instruction j k Issue Comp Result Busy AddressLD F6 34+ R2 1 3 4 Load1 NoLD F2 45+ R3 2 4 5 Load2 NoMULTD F0 F2 F4 3 Load3 NoSUBD F8 F6 F2 4 7 8DIVD F10 F0 F6 5ADDD F6 F8 F2 6 10 11
Reservation Stations: S1 S2 RS RS
Time Name Busy Op Vj Vk Qj QkAdd1 NoAdd2 NoAdd3 No
4 Mult1 Yes MULTD M(A2) R(F4)Mult2 Yes DIVD M(A1) Mult1
Register result status:Clock F0 F2 F4 F6 F8 F10 F12 ... F30
11 FU Mult1 M(A2) (M-M+M(M-M) Mult2
� .�����������(�,---��������$������%����)� ,�/������������������������������0��1
Tomasulo Example Cycle 11
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.22
Instruction status: Exec Write
Instruction j k Issue Comp Result Busy AddressLD F6 34+ R2 1 3 4 Load1 NoLD F2 45+ R3 2 4 5 Load2 NoMULTD F0 F2 F4 3 Load3 NoSUBD F8 F6 F2 4 7 8DIVD F10 F0 F6 5ADDD F6 F8 F2 6 10 11
Reservation Stations: S1 S2 RS RS
Time Name Busy Op Vj Vk Qj QkAdd1 NoAdd2 NoAdd3 No
3 Mult1 Yes MULTD M(A2) R(F4)Mult2 Yes DIVD M(A1) Mult1
Register result status:Clock F0 F2 F4 F6 F8 F10 F12 ... F30
12 FU Mult1 M(A2) (M-M+M(M-M) Mult2
Tomasulo Example Cycle 12
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.23
Instruction status: Exec Write
Instruction j k Issue Comp Result Busy AddressLD F6 34+ R2 1 3 4 Load1 NoLD F2 45+ R3 2 4 5 Load2 NoMULTD F0 F2 F4 3 Load3 NoSUBD F8 F6 F2 4 7 8DIVD F10 F0 F6 5ADDD F6 F8 F2 6 10 11
Reservation Stations: S1 S2 RS RS
Time Name Busy Op Vj Vk Qj QkAdd1 NoAdd2 NoAdd3 No
2 Mult1 Yes MULTD M(A2) R(F4)Mult2 Yes DIVD M(A1) Mult1
Register result status:Clock F0 F2 F4 F6 F8 F10 F12 ... F30
13 FU Mult1 M(A2) (M-M+M(M-M) Mult2
Tomasulo Example Cycle 13
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.24
Instruction status: Exec Write
Instruction j k Issue Comp Result Busy AddressLD F6 34+ R2 1 3 4 Load1 NoLD F2 45+ R3 2 4 5 Load2 NoMULTD F0 F2 F4 3 Load3 NoSUBD F8 F6 F2 4 7 8DIVD F10 F0 F6 5ADDD F6 F8 F2 6 10 11
Reservation Stations: S1 S2 RS RS
Time Name Busy Op Vj Vk Qj QkAdd1 NoAdd2 NoAdd3 No
1 Mult1 Yes MULTD M(A2) R(F4)Mult2 Yes DIVD M(A1) Mult1
Register result status:Clock F0 F2 F4 F6 F8 F10 F12 ... F30
14 FU Mult1 M(A2) (M-M+M(M-M) Mult2
Tomasulo Example Cycle 14

10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.25
Instruction status: Exec Write
Instruction j k Issue Comp Result Busy AddressLD F6 34+ R2 1 3 4 Load1 NoLD F2 45+ R3 2 4 5 Load2 NoMULTD F0 F2 F4 3 15 Load3 NoSUBD F8 F6 F2 4 7 8DIVD F10 F0 F6 5ADDD F6 F8 F2 6 10 11
Reservation Stations: S1 S2 RS RS
Time Name Busy Op Vj Vk Qj QkAdd1 NoAdd2 NoAdd3 No
0 Mult1 Yes MULTD M(A2) R(F4)Mult2 Yes DIVD M(A1) Mult1
Register result status:Clock F0 F2 F4 F6 F8 F10 F12 ... F30
15 FU Mult1 M(A2) (M-M+M(M-M) Mult2
Tomasulo Example Cycle 15
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.26
Instruction status: Exec Write
Instruction j k Issue Comp Result Busy AddressLD F6 34+ R2 1 3 4 Load1 NoLD F2 45+ R3 2 4 5 Load2 NoMULTD F0 F2 F4 3 15 16 Load3 NoSUBD F8 F6 F2 4 7 8DIVD F10 F0 F6 5ADDD F6 F8 F2 6 10 11
Reservation Stations: S1 S2 RS RS
Time Name Busy Op Vj Vk Qj QkAdd1 NoAdd2 NoAdd3 NoMult1 No
40 Mult2 Yes DIVD M*F4 M(A1)
Register result status:Clock F0 F2 F4 F6 F8 F10 F12 ... F30
16 FU M*F4 M(A2) (M-M+M(M-M) Mult2
Tomasulo Example Cycle 16
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.27
Faster than light computation(skip a couple of cycles)
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.28
Instruction status: Exec Write
Instruction j k Issue Comp Result Busy AddressLD F6 34+ R2 1 3 4 Load1 NoLD F2 45+ R3 2 4 5 Load2 NoMULTD F0 F2 F4 3 15 16 Load3 NoSUBD F8 F6 F2 4 7 8DIVD F10 F0 F6 5ADDD F6 F8 F2 6 10 11
Reservation Stations: S1 S2 RS RS
Time Name Busy Op Vj Vk Qj QkAdd1 NoAdd2 NoAdd3 NoMult1 No
1 Mult2 Yes DIVD M*F4 M(A1)
Register result status:Clock F0 F2 F4 F6 F8 F10 F12 ... F30
55 FU M*F4 M(A2) (M-M+M(M-M) Mult2
Tomasulo Example Cycle 55

10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.29
Instruction status: Exec Write
Instruction j k Issue Comp Result Busy AddressLD F6 34+ R2 1 3 4 Load1 NoLD F2 45+ R3 2 4 5 Load2 NoMULTD F0 F2 F4 3 15 16 Load3 NoSUBD F8 F6 F2 4 7 8DIVD F10 F0 F6 5 56ADDD F6 F8 F2 6 10 11
Reservation Stations: S1 S2 RS RS
Time Name Busy Op Vj Vk Qj QkAdd1 NoAdd2 NoAdd3 NoMult1 No
0 Mult2 Yes DIVD M*F4 M(A1)
Register result status:Clock F0 F2 F4 F6 F8 F10 F12 ... F30
56 FU M*F4 M(A2) (M-M+M(M-M) Mult2
� !��*����������� �'������'�����(����)
Tomasulo Example Cycle 56
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.30
Instruction status: Exec Write
Instruction j k Issue Comp Result Busy AddressLD F6 34+ R2 1 3 4 Load1 NoLD F2 45+ R3 2 4 5 Load2 NoMULTD F0 F2 F4 3 15 16 Load3 NoSUBD F8 F6 F2 4 7 8DIVD F10 F0 F6 5 56 57ADDD F6 F8 F2 6 10 11
Reservation Stations: S1 S2 RS RS
Time Name Busy Op Vj Vk Qj QkAdd1 NoAdd2 NoAdd3 NoMult1 No
0 Mult2 Yes DIVD M*F4 M(A1)
Register result status:Clock F0 F2 F4 F6 F8 F10 F12 ... F30
56 FU M*F4 M(A2) (M-M+M(M-M) Mult2
� 2����������+�3���������������3�(3�������4������������������$
Tomasulo Example Cycle 57
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.31
Instruction status: Read Exec Write Exec WriteInstruction j k Issue Oper Comp Result Issue Compl ResultLD F6 34+ R2 1 2 3 4 1 3 4
LD F2 45+ R3 5 6 7 8 2 4 5
MULTD F0 F2 F4 6 9 19 20 3 15 16
SUBD F8 F6 F2 7 9 11 12 4 7 8
DIVD F10 F0 F6 8 21 61 62 5 56 57
ADDD F6 F8 F2 13 14 16 22 6 10 11
� .�0��������������������%����5�� )����������6�7����"�����(�(��'�����
Compare to Scoreboard Cycle 62
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.32
Pipelined Functional Units Multiple Functional Units
(6 load, 3 store, 3 +, 2 x/÷) (1 load/store, 1 + , 2 x, 1 ÷)
window size: ~ 14 instructions ~ 5 instructions
No issue on structural hazard same
WAR: renaming avoids stall completion
WAW: renaming avoids stall issue
Broadcast results from FU Write/read registers
Control: reservation stations central scoreboard
Tomasulo v. Scoreboard (IBM 360/91 v. CDC 6600)

10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.33
° Complexity• delays of 360/91, MIPS 10000, IBM 620?
° Many associative stores (CDB) at high speed
° Performance limited by Common Data Bus• Multiple CDBs => more FU logic for parallel assoc stores
Tomasulo Drawbacks
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.34
Administrivia
° Should be debugging Lab 5 by now!• Remember: a Working processor is necessary for full credit…
° Tomorrow: Sections are back in classroom
° More info on some of the things that we have beentalking about last two lectures:
• Computer Architecture: A Quantitative Approach by JohnHennesy and David Patterson
° Next: Memory systems• Start reading Chapter 7 (of your text) now…
• Lab 6 will be using memory systems.
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.35
Administrivia: Be careful about clock edges in lab5!
Exe
c
Reg
. F
ile
Mem
Acc
ess
Dat
aM
em
A
B
S
M
Reg
File
Equ
al
PC
Nex
t PC
IR
Inst
. Mem
Valid
IRex
Dcd
Ctr
l
IRm
em
Ex
Ctr
l
IRw
b
Mem
Ctr
l
WB
Ctr
l
D
° Since Register file has edge-triggered write:• Must have everything set up at end of memory stage• This means that “M” register here is not actual register!
° Same with edge-triggered memory ⇒ “D” register appears“inside” memory
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.36
Tomasulo Loop Example
Loop:LD F0 0 R1MULTD F4 F0 F2SD F4 0 R1SUBI R1 R1 #8BNEZ R1 Loop
° Assume Multiply takes 4 clocks
° Assume first load takes 8 clocks (cache miss),second load takes 1 clock (hit)
° To be clear, will show clocks for SUBI, BNEZ
° Reality: integer instructions ahead

10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.37
Loop Example
Instruction status: Exec Write
ITER Instruction j k Issue Comp esult Busy Addr Fu1 LD F0 0 R1 Load1 No1 MULTD F4 F0 F2 Load2 No1 SD F4 0 R1 Load3 No2 LD F0 0 R1 Store1 No2 MULTD F4 F0 F2 Store2 No2 SD F4 0 R1 Store3 No
Reservation Stations: S1 S2 RS Time Name Busy Op Vj Vk Qj Qk Code:
Add1 No LD F0 0 R1Add2 No MULTD F4 F0 F2Add3 No SD F4 0 R1Mult1 No SUBI R1 R1 #8Mult2 No BNEZ R1 Loop
Register result status
Clock R1 F0 F2 F4 F6 F8 F10 F12 ... F300 80 Fu
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.38
Instruction status: Exec Write
ITER Instruction j k Issue Comp esult Busy Addr Fu1 LD F0 0 R1 1 Load1 Yes 801 MULTD F4 F0 F2 Load2 No1 SD F4 0 R1 Load3 No2 LD F0 0 R1 Store1 No2 MULTD F4 F0 F2 Store2 No2 SD F4 0 R1 Store3 No
Reservation Stations: S1 S2 RS Time Name Busy Op Vj Vk Qj Qk Code:
Add1 No LD F0 0 R1Add2 No MULTD F4 F0 F2Add3 No SD F4 0 R1Mult1 No SUBI R1 R1 #8Mult2 No BNEZ R1 Loop
Register result status
Clock R1 F0 F2 F4 F6 F8 F10 F12 ... F301 80 Fu Load1
Loop Example Cycle 1
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.39
Instruction status: Exec Write
ITER Instruction j k Issue Comp esult Busy Addr Fu1 LD F0 0 R1 1 Load1 Yes 801 MULTD F4 F0 F2 2 Load2 No1 SD F4 0 R1 Load3 No2 LD F0 0 R1 Store1 No2 MULTD F4 F0 F2 Store2 No2 SD F4 0 R1 Store3 No
Reservation Stations: S1 S2 RS Time Name Busy Op Vj Vk Qj Qk Code:
Add1 No LD F0 0 R1Add2 No MULTD F4 F0 F2Add3 No SD F4 0 R1Mult1 Yes Multd R(F2) Load1 SUBI R1 R1 #8Mult2 No BNEZ R1 Loop
Register result status
Clock R1 F0 F2 F4 F6 F8 F10 F12 ... F302 80 Fu Load1 Mult1
Loop Example Cycle 2
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.40
Instruction status: Exec Write
ITER Instruction j k Issue Comp esult Busy Addr Fu1 LD F0 0 R1 1 Load1 Yes 801 MULTD F4 F0 F2 2 Load2 No1 SD F4 0 R1 3 Load3 No2 LD F0 0 R1 Store1 Yes 80 Mult12 MULTD F4 F0 F2 Store2 No2 SD F4 0 R1 Store3 No
Reservation Stations: S1 S2 RS Time Name Busy Op Vj Vk Qj Qk Code:
Add1 No LD F0 0 R1Add2 No MULTD F4 F0 F2Add3 No SD F4 0 R1Mult1 Yes Multd R(F2) Load1 SUBI R1 R1 #8Mult2 No BNEZ R1 Loop
Register result status
Clock R1 F0 F2 F4 F6 F8 F10 F12 ... F303 80 Fu Load1 Mult1
° Implicit renaming sets up “DataFlow” graph
Loop Example Cycle 3

10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.41
What does this mean physically?
addr: 80addr: 80
F0: Load 1 F0: Load 1
F4: Mult1 F4: Mult1
������������������
��������
��� ������������� ����������
���������
��� ��� ������������
��������������������
�� �����������������
�����
��� �!����
"������##���"���"����"����"���$"���%"���&
R(F2) Load1mul
�������##���
Addr: 80Addr: 80 Mult1Mult1
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.42
Instruction status: Exec Write
ITER Instruction j k Issue Comp esult Busy Addr Fu1 LD F0 0 R1 1 Load1 Yes 801 MULTD F4 F0 F2 2 Load2 No1 SD F4 0 R1 3 Load3 No2 LD F0 0 R1 Store1 Yes 80 Mult12 MULTD F4 F0 F2 Store2 No2 SD F4 0 R1 Store3 No
Reservation Stations: S1 S2 RS Time Name Busy Op Vj Vk Qj Qk Code:
Add1 No LD F0 0 R1Add2 No MULTD F4 F0 F2Add3 No SD F4 0 R1Mult1 Yes Multd R(F2) Load1 SUBI R1 R1 #8Mult2 No BNEZ R1 Loop
Register result status
Clock R1 F0 F2 F4 F6 F8 F10 F12 ... F304 80 Fu Load1 Mult1
° Dispatching SUBI Instruction
Loop Example Cycle 4
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.43
Instruction status: Exec Write
ITER Instruction j k Issue Comp esult Busy Addr Fu1 LD F0 0 R1 1 Load1 Yes 801 MULTD F4 F0 F2 2 Load2 No1 SD F4 0 R1 3 Load3 No2 LD F0 0 R1 Store1 Yes 80 Mult12 MULTD F4 F0 F2 Store2 No2 SD F4 0 R1 Store3 No
Reservation Stations: S1 S2 RS Time Name Busy Op Vj Vk Qj Qk Code:
Add1 No LD F0 0 R1Add2 No MULTD F4 F0 F2Add3 No SD F4 0 R1Mult1 Yes Multd R(F2) Load1 SUBI R1 R1 #8Mult2 No BNEZ R1 Loop
Register result status
Clock R1 F0 F2 F4 F6 F8 F10 F12 ... F305 72 Fu Load1 Mult1
° And, BNEZ instruction
Loop Example Cycle 5
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.44
Instruction status: Exec Write
ITER Instruction j k Issue Comp esult Busy Addr Fu1 LD F0 0 R1 1 Load1 Yes 801 MULTD F4 F0 F2 2 Load2 Yes 721 SD F4 0 R1 3 Load3 No2 LD F0 0 R1 6 Store1 Yes 80 Mult12 MULTD F4 F0 F2 Store2 No2 SD F4 0 R1 Store3 No
Reservation Stations: S1 S2 RS Time Name Busy Op Vj Vk Qj Qk Code:
Add1 No LD F0 0 R1Add2 No MULTD F4 F0 F2Add3 No SD F4 0 R1Mult1 Yes Multd R(F2) Load1 SUBI R1 R1 #8Mult2 No BNEZ R1 Loop
Register result status
Clock R1 F0 F2 F4 F6 F8 F10 F12 ... F306 72 Fu Load2 Mult1
° Notice that F0 never sees Load from location 80
Loop Example Cycle 6
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.45
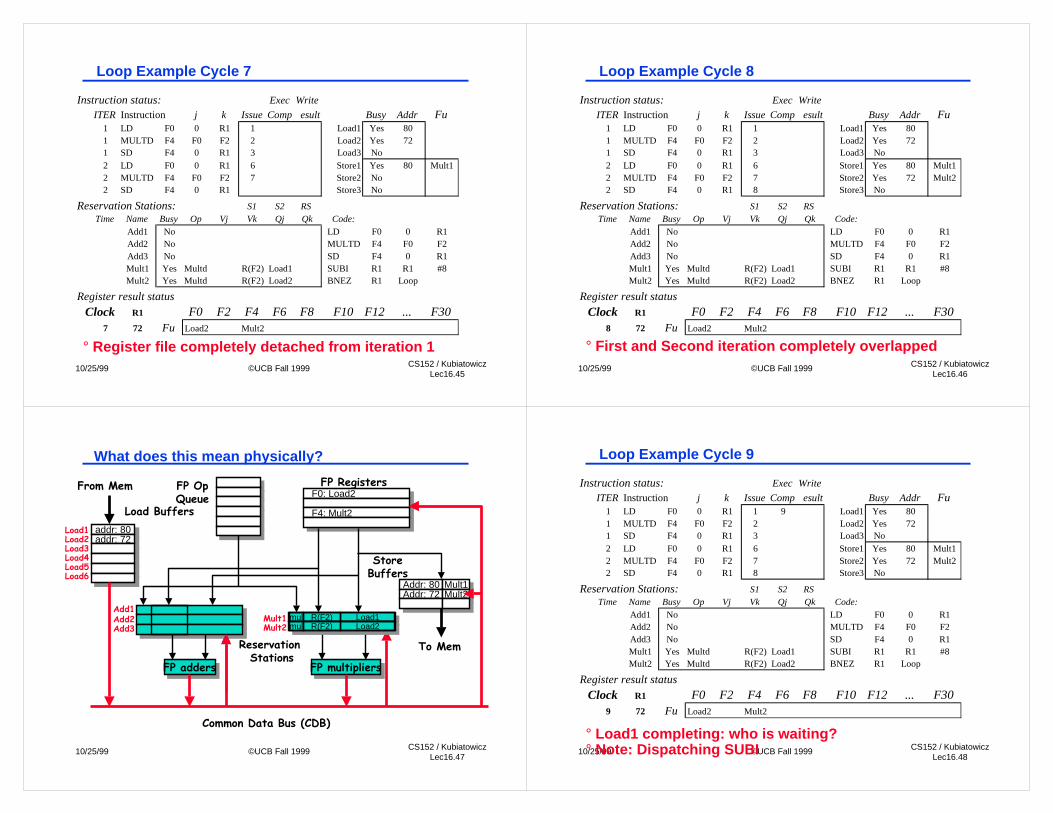
Instruction status: Exec Write
ITER Instruction j k Issue Comp esult Busy Addr Fu1 LD F0 0 R1 1 Load1 Yes 801 MULTD F4 F0 F2 2 Load2 Yes 721 SD F4 0 R1 3 Load3 No2 LD F0 0 R1 6 Store1 Yes 80 Mult12 MULTD F4 F0 F2 7 Store2 No2 SD F4 0 R1 Store3 No
Reservation Stations: S1 S2 RS Time Name Busy Op Vj Vk Qj Qk Code:
Add1 No LD F0 0 R1Add2 No MULTD F4 F0 F2Add3 No SD F4 0 R1Mult1 Yes Multd R(F2) Load1 SUBI R1 R1 #8Mult2 Yes Multd R(F2) Load2 BNEZ R1 Loop
Register result status
Clock R1 F0 F2 F4 F6 F8 F10 F12 ... F307 72 Fu Load2 Mult2
° Register file completely detached from iteration 1
Loop Example Cycle 7
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.46
Instruction status: Exec Write
ITER Instruction j k Issue Comp esult Busy Addr Fu1 LD F0 0 R1 1 Load1 Yes 801 MULTD F4 F0 F2 2 Load2 Yes 721 SD F4 0 R1 3 Load3 No2 LD F0 0 R1 6 Store1 Yes 80 Mult12 MULTD F4 F0 F2 7 Store2 Yes 72 Mult22 SD F4 0 R1 8 Store3 No
Reservation Stations: S1 S2 RS Time Name Busy Op Vj Vk Qj Qk Code:
Add1 No LD F0 0 R1Add2 No MULTD F4 F0 F2Add3 No SD F4 0 R1Mult1 Yes Multd R(F2) Load1 SUBI R1 R1 #8Mult2 Yes Multd R(F2) Load2 BNEZ R1 Loop
Register result status
Clock R1 F0 F2 F4 F6 F8 F10 F12 ... F308 72 Fu Load2 Mult2
Loop Example Cycle 8
° First and Second iteration completely overlapped
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.47
What does this mean physically?
addr: 80addr: 80addr: 72addr: 72
F0: Load2 F0: Load2
F4: Mult2 F4: Mult2
������������������
��������
��� ������������� ����������
���������
��� ��� ������������
��������������������
�� �����������������
�����
��� �!����
"������##���"���"����"����"���$"���%"���&
R(F2) Load1mulR(F2) Load2mul
�������##���
Addr: 80Addr: 80 Mult1Mult1Addr: 72Addr: 72 Mult2Mult2
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.48
Instruction status: Exec Write
ITER Instruction j k Issue Comp esult Busy Addr Fu1 LD F0 0 R1 1 9 Load1 Yes 801 MULTD F4 F0 F2 2 Load2 Yes 721 SD F4 0 R1 3 Load3 No2 LD F0 0 R1 6 Store1 Yes 80 Mult12 MULTD F4 F0 F2 7 Store2 Yes 72 Mult22 SD F4 0 R1 8 Store3 No
Reservation Stations: S1 S2 RS Time Name Busy Op Vj Vk Qj Qk Code:
Add1 No LD F0 0 R1Add2 No MULTD F4 F0 F2Add3 No SD F4 0 R1Mult1 Yes Multd R(F2) Load1 SUBI R1 R1 #8Mult2 Yes Multd R(F2) Load2 BNEZ R1 Loop
Register result status
Clock R1 F0 F2 F4 F6 F8 F10 F12 ... F309 72 Fu Load2 Mult2
° Load1 completing: who is waiting?° Note: Dispatching SUBI
Loop Example Cycle 9

10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.49
Instruction status: Exec Write
ITER Instruction j k Issue Comp esult Busy Addr Fu1 LD F0 0 R1 1 9 10 Load1 No1 MULTD F4 F0 F2 2 Load2 Yes 721 SD F4 0 R1 3 Load3 No2 LD F0 0 R1 6 10 Store1 Yes 80 Mult12 MULTD F4 F0 F2 7 Store2 Yes 72 Mult22 SD F4 0 R1 8 Store3 No
Reservation Stations: S1 S2 RS Time Name Busy Op Vj Vk Qj Qk Code:
Add1 No LD F0 0 R1Add2 No MULTD F4 F0 F2Add3 No SD F4 0 R1
4 Mult1 Yes Multd M[80] R(F2) SUBI R1 R1 #8Mult2 Yes Multd R(F2) Load2 BNEZ R1 Loop
Register result status
Clock R1 F0 F2 F4 F6 F8 F10 F12 ... F3010 64 Fu Load2 Mult2
° Load2 completing: who is waiting?° Note: Dispatching BNEZ
Loop Example Cycle 10
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.50
Instruction status: Exec Write
ITER Instruction j k Issue Comp esult Busy Addr Fu1 LD F0 0 R1 1 9 10 Load1 No1 MULTD F4 F0 F2 2 Load2 No1 SD F4 0 R1 3 Load3 Yes 642 LD F0 0 R1 6 10 11 Store1 Yes 80 Mult12 MULTD F4 F0 F2 7 Store2 Yes 72 Mult22 SD F4 0 R1 8 Store3 No
Reservation Stations: S1 S2 RS Time Name Busy Op Vj Vk Qj Qk Code:
Add1 No LD F0 0 R1Add2 No MULTD F4 F0 F2Add3 No SD F4 0 R1
3 Mult1 Yes Multd M[80] R(F2) SUBI R1 R1 #84 Mult2 Yes Multd M[72] R(F2) BNEZ R1 Loop
Register result status
Clock R1 F0 F2 F4 F6 F8 F10 F12 ... F3011 64 Fu Load3 Mult2
° Next load in sequence
Loop Example Cycle 11
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.51
Instruction status: Exec Write
ITER Instruction j k Issue Comp esult Busy Addr Fu1 LD F0 0 R1 1 9 10 Load1 No1 MULTD F4 F0 F2 2 Load2 No1 SD F4 0 R1 3 Load3 Yes 642 LD F0 0 R1 6 10 11 Store1 Yes 80 Mult12 MULTD F4 F0 F2 7 Store2 Yes 72 Mult22 SD F4 0 R1 8 Store3 No
Reservation Stations: S1 S2 RS Time Name Busy Op Vj Vk Qj Qk Code:
Add1 No LD F0 0 R1Add2 No MULTD F4 F0 F2Add3 No SD F4 0 R1
2 Mult1 Yes Multd M[80] R(F2) SUBI R1 R1 #83 Mult2 Yes Multd M[72] R(F2) BNEZ R1 Loop
Register result status
Clock R1 F0 F2 F4 F6 F8 F10 F12 ... F3012 64 Fu Load3 Mult2
° Why not issue third multiply?
Loop Example Cycle 12
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.52
Instruction status: Exec Write
ITER Instruction j k Issue Comp esult Busy Addr Fu1 LD F0 0 R1 1 9 10 Load1 No1 MULTD F4 F0 F2 2 Load2 No1 SD F4 0 R1 3 Load3 Yes 642 LD F0 0 R1 6 10 11 Store1 Yes 80 Mult12 MULTD F4 F0 F2 7 Store2 Yes 72 Mult22 SD F4 0 R1 8 Store3 No
Reservation Stations: S1 S2 RS Time Name Busy Op Vj Vk Qj Qk Code:
Add1 No LD F0 0 R1Add2 No MULTD F4 F0 F2Add3 No SD F4 0 R1
1 Mult1 Yes Multd M[80] R(F2) SUBI R1 R1 #82 Mult2 Yes Multd M[72] R(F2) BNEZ R1 Loop
Register result status
Clock R1 F0 F2 F4 F6 F8 F10 F12 ... F3013 64 Fu Load3 Mult2
Loop Example Cycle 13

10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.53
Instruction status: Exec Write
ITER Instruction j k Issue Comp esult Busy Addr Fu1 LD F0 0 R1 1 9 10 Load1 No1 MULTD F4 F0 F2 2 14 Load2 No1 SD F4 0 R1 3 Load3 Yes 642 LD F0 0 R1 6 10 11 Store1 Yes 80 Mult12 MULTD F4 F0 F2 7 Store2 Yes 72 Mult22 SD F4 0 R1 8 Store3 No
Reservation Stations: S1 S2 RS Time Name Busy Op Vj Vk Qj Qk Code:
Add1 No LD F0 0 R1Add2 No MULTD F4 F0 F2Add3 No SD F4 0 R1
0 Mult1 Yes Multd M[80] R(F2) SUBI R1 R1 #81 Mult2 Yes Multd M[72] R(F2) BNEZ R1 Loop
Register result status
Clock R1 F0 F2 F4 F6 F8 F10 F12 ... F3014 64 Fu Load3 Mult2
° Mult1 completing. Who is waiting?
Loop Example Cycle 14
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.54
Instruction status: Exec Write
ITER Instruction j k Issue Comp esult Busy Addr Fu1 LD F0 0 R1 1 9 10 Load1 No1 MULTD F4 F0 F2 2 14 15 Load2 No1 SD F4 0 R1 3 Load3 Yes 642 LD F0 0 R1 6 10 11 Store1 Yes 80 [80]*R22 MULTD F4 F0 F2 7 15 Store2 Yes 72 Mult22 SD F4 0 R1 8 Store3 No
Reservation Stations: S1 S2 RS Time Name Busy Op Vj Vk Qj Qk Code:
Add1 No LD F0 0 R1Add2 No MULTD F4 F0 F2Add3 No SD F4 0 R1Mult1 No SUBI R1 R1 #8
0 Mult2 Yes Multd M[72] R(F2) BNEZ R1 Loop
Register result status
Clock R1 F0 F2 F4 F6 F8 F10 F12 ... F3015 64 Fu Load3 Mult2
° Mult2 completing. Who is waiting?
Loop Example Cycle 15
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.55
Instruction status: Exec Write
ITER Instruction j k Issue Comp esult Busy Addr Fu1 LD F0 0 R1 1 9 10 Load1 No1 MULTD F4 F0 F2 2 14 15 Load2 No1 SD F4 0 R1 3 Load3 Yes 642 LD F0 0 R1 6 10 11 Store1 Yes 80 [80]*R22 MULTD F4 F0 F2 7 15 16 Store2 Yes 72 [72]*R22 SD F4 0 R1 8 Store3 No
Reservation Stations: S1 S2 RS Time Name Busy Op Vj Vk Qj Qk Code:
Add1 No LD F0 0 R1Add2 No MULTD F4 F0 F2Add3 No SD F4 0 R1Mult1 Yes Multd R(F2) Load3 SUBI R1 R1 #8Mult2 No BNEZ R1 Loop
Register result status
Clock R1 F0 F2 F4 F6 F8 F10 F12 ... F3016 64 Fu Load3 Mult1
Loop Example Cycle 16
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.56
Instruction status: Exec Write
ITER Instruction j k Issue Comp esult Busy Addr Fu1 LD F0 0 R1 1 9 10 Load1 No1 MULTD F4 F0 F2 2 14 15 Load2 No1 SD F4 0 R1 3 Load3 Yes 642 LD F0 0 R1 6 10 11 Store1 Yes 80 [80]*R22 MULTD F4 F0 F2 7 15 16 Store2 Yes 72 [72]*R22 SD F4 0 R1 8 Store3 Yes 64 Mult1
Reservation Stations: S1 S2 RS Time Name Busy Op Vj Vk Qj Qk Code:
Add1 No LD F0 0 R1Add2 No MULTD F4 F0 F2Add3 No SD F4 0 R1Mult1 Yes Multd R(F2) Load3 SUBI R1 R1 #8Mult2 No BNEZ R1 Loop
Register result status
Clock R1 F0 F2 F4 F6 F8 F10 F12 ... F3017 64 Fu Load3 Mult1
Loop Example Cycle 17

10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.57
Instruction status: Exec Write
ITER Instruction j k Issue Comp esult Busy Addr Fu1 LD F0 0 R1 1 9 10 Load1 No1 MULTD F4 F0 F2 2 14 15 Load2 No1 SD F4 0 R1 3 18 Load3 Yes 642 LD F0 0 R1 6 10 11 Store1 Yes 80 [80]*R22 MULTD F4 F0 F2 7 15 16 Store2 Yes 72 [72]*R22 SD F4 0 R1 8 Store3 Yes 64 Mult1
Reservation Stations: S1 S2 RS Time Name Busy Op Vj Vk Qj Qk Code:
Add1 No LD F0 0 R1Add2 No MULTD F4 F0 F2Add3 No SD F4 0 R1Mult1 Yes Multd R(F2) Load3 SUBI R1 R1 #8Mult2 No BNEZ R1 Loop
Register result status
Clock R1 F0 F2 F4 F6 F8 F10 F12 ... F3018 64 Fu Load3 Mult1
Loop Example Cycle 18
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.58
Instruction status: Exec Write
ITER Instruction j k Issue Comp esult Busy Addr Fu1 LD F0 0 R1 1 9 10 Load1 No1 MULTD F4 F0 F2 2 14 15 Load2 No1 SD F4 0 R1 3 18 19 Load3 Yes 642 LD F0 0 R1 6 10 11 Store1 No2 MULTD F4 F0 F2 7 15 16 Store2 Yes 72 [72]*R22 SD F4 0 R1 8 19 Store3 Yes 64 Mult1
Reservation Stations: S1 S2 RS Time Name Busy Op Vj Vk Qj Qk Code:
Add1 No LD F0 0 R1Add2 No MULTD F4 F0 F2Add3 No SD F4 0 R1Mult1 Yes Multd R(F2) Load3 SUBI R1 R1 #8Mult2 No BNEZ R1 Loop
Register result status
Clock R1 F0 F2 F4 F6 F8 F10 F12 ... F3019 64 Fu Load3 Mult1
Loop Example Cycle 19
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.59
Instruction status: Exec Write
ITER Instruction j k Issue Comp esult Busy Addr Fu1 LD F0 0 R1 1 9 10 Load1 No1 MULTD F4 F0 F2 2 14 15 Load2 No1 SD F4 0 R1 3 18 19 Load3 Yes 642 LD F0 0 R1 6 10 11 Store1 No2 MULTD F4 F0 F2 7 15 16 Store2 No2 SD F4 0 R1 8 19 20 Store3 Yes 64 Mult1
Reservation Stations: S1 S2 RS Time Name Busy Op Vj Vk Qj Qk Code:
Add1 No LD F0 0 R1Add2 No MULTD F4 F0 F2Add3 No SD F4 0 R1Mult1 Yes Multd R(F2) Load3 SUBI R1 R1 #8Mult2 No BNEZ R1 Loop
Register result status
Clock R1 F0 F2 F4 F6 F8 F10 F12 ... F3020 64 Fu Load3 Mult1
Loop Example Cycle 20
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.60
Why can Tomasulo overlap iterations of loops?
° Register renaming
• Multiple iterations use different physical destinationsfor registers (dynamic loop unrolling).
• Replace static register names from code with dynamicregister “pointers”
• Effectively increases size of register file
• Permit instruction issue to advance past integercontrol flow operations.
° Crucial: integer unit must “get ahead” of floating pointunit so that we can issue multiple iterations
° Other idea: Tomasulo building “DataFlow” graph.

10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.61
Recall: Unrolled Loop That Minimizes Stalls
1 Loop:LD F0,0(R1)2 LD F6,-8(R1)3 LD F10,-16(R1)4 LD F14,-24(R1)5 ADDD F4,F0,F26 ADDD F8,F6,F27 ADDD F12,F10,F28 ADDD F16,F14,F29 SD 0(R1),F410 SD -8(R1),F811 SD -16(R1),F1212 SUBI R1,R1,#3213 BNEZ R1,LOOP14 SD 8(R1),F16 ; 8-32 = -24
&8�������0��������9$:�������������������'����������;<����������������1
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.62
Why issue in order?
° In-order issue permits us to analyze data flow of program° This way, we know exactly which results should flow to
which subsequent instructions• If we issued out-of-order, we would confuse RAW and
WAR hazards!• The most advanced machines that I know of all issue
in order.° This idea works perfectly well “in principle” with multiple
instructions issued per clock:• Need to multi-port “rename table” and be able to rename a
sequence of instructions together• Need to be able to issue to multiple reservation stations in a
single cycle.• Need to have 2x number of read ports and 1x number of
write ports in register file.° In-order issue can be serious bottleneck when issuing
multiple instructions per clock-cycle
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.63
Branches must be resolved quickly for loop overlap!
° In our example, we relied on the fact that brancheswere under control of “fast” integer unit in order toget overlap!
Loop: LD F0 0 R1MULTD F4 F0 F2SD F4 0 R1SUBI R1 R1 #8BNEZ R1 Loop
° What happens if branch depends on result of multd??• We completely lose all of our advantages!
• Need to be able to “predict” branch outcome.
• If we were to predict that branch was taken, this wouldbe right most of the time.
° Problem much worse for superscalar machines!10/25/99 ©UCB Fall 1999 CS152 / Kubiatowicz
Lec16.64
Independent “Fetch” unit
Instruction Fetchwith
Branch Prediction
Out-Of-OrderExecution
Unit
Correctness FeedbackOn Branch Results
Stream of InstructionsTo Execute
° Instruction fetch decoupled from execution
° Often issue logic (+ rename) included with Fetch

10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.65
° Prediction has become essential to getting goodperformance from scalar instruction streams.
° We will discuss predicting branches. However,architects are now predicting everything: datadependencies, actual data, and results of groups ofinstructions:
• At what point does computation become a probabilistic operation +verification?
• We are pretty close with control hazards already…
° Why does prediction work?• Underlying algorithm has regularities.
• Data that is being operated on has regularities.
• Instruction sequence has redundancies that are artifacts of way thathumans/compilers think about problems.
° Prediction ⇒ Compressible information streams?
Prediction: Branches, Dependencies, Data
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.66
Dynamic Branch Prediction
° Prediction could be “Static” (at compile time) or“Dynamic” (at runtime)
• For our example, if we were to statically predict“taken”, we would only be wrong once each passthrough loop
° Is dynamic branch prediction better than staticbranch prediction?
• Seems to be. Still some debate to this effect
• Today, lots of hardware being devoted to dynamicbranch predictors.
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.67
° Address of branch index to get prediction AND branchaddress (if taken)• Must check for branch match now, since can’t use wrong branch address
• Grab predicted PC from table since may take several cycles to compute
° Update predicted PC when branch is actually resolved
° Return instruction addresses predicted with stack
����'(��� �����'������
)*
����#�������'�����+�
�,
�����'����-����������-��
Simple dynamic prediction: Branch Target Buffer (BTB)
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.68
Dynamic Branch Prediction
° Performance = ƒ(accuracy, cost of misprediction)
° Branch History Table: Lower bits of PC addressindex table of 1-bit values
• Says whether or not branch taken last time
• No address check
° Problem: in a loop, 1-bit BHT will cause twomispredictions (avg is 9 iteratios before exit):
• End of loop case, when it exits instead of looping as before
• First time through loop on next time through code, when itpredicts exit instead of looping

10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.69
° Solution: 2-bit scheme where change predictiononly if get misprediction twice: (Figure 4.13, p. 264)
° Red: stop, not taken
° Green: go, taken
° Adds hysteresis to decision making process
Dynamic Branch Prediction
T
TNT
NT
Predict Taken
Predict Not Taken
Predict Taken
Predict Not TakenT
NT
T
NT
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.70
BHT Accuracy
° Mispredict because either:• Wrong guess for that branch
• Got branch history of wrong branch when index the table
° 4096 entry table programs vary from 1%misprediction (nasa7, tomcatv) to 18% (eqntott),with spice at 9% and gcc at 12%
° 4096 about as good as infinite table(in Alpha 211164)
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.71
Correlating Branches
° Hypothesis: recent branches are correlated; that is,behavior of recently executed branches affects predictionof current branch
° Two possibilities; Current branch depends on:• Last m most recently executed branches anywhere in program
Produces a “GA” (for “global address”) in the Yeh and Pattclassification (e.g. GAg)
• Last m most recent outcomes of same branch.Produces a “PA” (for “per address”) in same classification (e.g. PAg)
° Idea: record m most recently executed branches as takenor not taken, and use that pattern to select the properbranch history table entry
• A single history table shared by all branches (appends a “g” at end),indexed by history value.
• Address is used along with history to select table entry (appends a “p”at end of classification)
• If only portion of address used, often appends an “s” to indicate “set-indexed” tables (I.e. GAs)
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.72
Correlating Branches
(2,2) GAs predictor• First 2 means that we keep two
bits of history
• Second means that we have 2bit counters in each slot.
• Then behavior of recentbranches selects between,say, four predictions of nextbranch, updating just thatprediction
• Note that the original two-bitcounter solution would be a(0,2) GAs predictor
• Note also that aliasing ispossible here...
Branch address
2-bits per branch predictors
PredictionPrediction
2-bit global branch history register
° For instance, consider global history, set-indexedBHT. That gives us a GAs history table.
+�'(���������./���'������

10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.73
Accuracy of Different Schemes
Fre
quen
cy o
f M
ispr
edic
tion
s
0%
2%
4%
6%
8%
10%
12%
14%
16%
18%
nasa
7
mat
rix3
00
tom
catv
dodu
cd
spic
e
fppp
p gcc
espr
esso
eqnt
ott li
0%
1%
5%
6% 6%
11%
4%
6%
5%
1%
4,096 entries: 2-bits per entry Unlimited entries: 2-bits/entry 1,024 entries (2,2)
4096 Entries 2-bit BHTUnlimited Entries 2-bit BHT1024 Entries (2,2) BHT
0%
18%
Fre
qu
ency
of
Mis
pre
dic
tio
ns
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.74
HW support for More ILP
° Avoid branch prediction by turning branches intoconditionally executed instructions:
if (x) then A = B op C else NOP• If false, then neither store result nor cause exception
• Expanded ISA of Alpha, MIPS, PowerPC, SPARC haveconditional move; PA-RISC can annul any following instr.
• EPIC: 64 1-bit condition fields selected so conditional execution
° Drawbacks to conditional instructions• Still takes a clock even if “annulled”
• Stall if condition evaluated late
• Complex conditions reduce effectiveness;condition becomes known late in pipeline
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.75
Now what about exceptions???
° Out-of-order commit really messes up our chance toget precise exceptions!
• When committing results out-of-order, register filecontains results from later instructions while earlierones have not completed yet.
• What if need to cause exception on one of those earlyinstructions??
° Need to be able to “rollback” register file toconsistent state
• Remember that “precise” means that there is some PCsuch that: all instructions before have committedresults, and none after have committed results.
° Big problem for branch prediction as well:What if prediction wrong??
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.76
° Speculation is a form of guessing.
° Important for branch prediction:• Need to “take our best shot” at predicting branch direction.
• If we issue multiple instructions per cycle, lose lots of potentialinstructions otherwise:
- Consider 4 instructions per cycle
- If take single cycle to decide on branch, waste from 4 - 7instruction slots!
° If we speculate and are wrong, need to back up andrestart execution to point at which we predictedincorrectly:
• This is exactly same as precise exceptions!
° Technique for both precise interrupts/exceptions andspeculation: in-order completion or commit
Relationship between precise interrupts and specultation:

10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.77
HW support for precise interrupts
° Need HW buffer for results ofuncommitted instructions:reorder buffer
• 3 fields: instr, destination, value
• Reorder buffer can be operandsource => more registers like RS
• Use reorder buffer number instead ofreservation station when executioncompletes
• Supplies operands betweenexecution complete & commit
• Once operand commits,result is put into register
• Instructionscommit
• As a result, its easy to undospeculated instructionson mispredicted branchesor on exceptions
ReorderBuffer
FPOp
Queue
FP Adder FP Adder
Res Stations Res Stations
FP Regs
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.78
1. Issue—get instruction from FP Op Queue• If reservation station and reorder buffer slot free, issue instr & send
operands & reorder buffer no. for destination (this stage sometimescalled “dispatch”)
2. Execution—operate on operands (EX)• When both operands ready then execute; if not ready, watch CDB for
result; when both in reservation station, execute; checks RAW(sometimes called “issue”)
3. Write result—finish execution (WB)• Write on Common Data Bus to all awaiting FUs & reorder buffer;
mark reservation station available.
4. Commit—update register with reorder result• When instr. at head of reorder buffer & result present, update
register with result (or store to memory) and remove instr fromreorder buffer.
• Mispredicted branch or interrupt flushes reorder buffer (sometimescalled “graduation”)
Four Steps of Speculative Tomasulo Algorithm
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.79
3 DIVD ROB2,R(F6)3 DIVD ROB2,R(F6)2 ADDD R(F4),ROB12 ADDD R(F4),ROB1
Tomasulo With Reorder buffer:
���� ��0
������������������ ��� ������������� ����������
��������������������
��� �!����
� �1� �&
� �%
� �%
� ��
� ��
� �
----
F0F0<val2><val2>
<val2><val2>ST 0(R3),F0ST 0(R3),F0
ADDD F0,F4,F6ADDD F0,F4,F6YY
ExEx
F4F4 M[10]M[10] LD F4,0(R3)LD F4,0(R3) YY
---- BNE F2,<…>BNE F2,<…> NN
F2F2
F10F10
F0F0
DIVD F2,F10,F6DIVD F2,F10,F6
ADDD F10,F4,F0ADDD F10,F4,F0
LD F0,10(R2)LD F0,10(R2)
NN
NN
NN
����*
���� ����
�����
2�3���
#�� ��� ��0
1 10+R21 10+R2����
����������##��
���������
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.80
Dynamic Scheduling in PowerPC 604 and Pentium Pro
° Both In-order Issue, Out-of-order execution, In-order Commit
PPro central reservation station for anyfunctional units with one bus shared by abranch and an integer unit

10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.81
Dynamic Scheduling in PowerPC 604 and Pentium Pro
Parameter PPC PPro
Max. instructions issued/clock 4 3
Max. instr. complete exec./clock 6 5
Max. instr. commited/clock 6 3
Instructions in reorder buffer 16 40
Number of rename buffers 12 Int/8 FP 40
Number of reservations stations 12 20
No. integer functional units (FUs) 2 2No. floating point FUs 1 1No. branch FUs 1 1No. complex integer FUs 1 0No. memory FUs 1 1 load +1 store
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.82
Dynamic Scheduling in Pentium Pro
° PPro doesn’t pipeline 80x86 instructions
° PPro decode unit translates the Intel instructions into72-bit micro-operations (- MIPS)
° Sends micro-operations to reorder buffer & reservationstations
° Takes 1 clock cycle to determine length of 80x86instructions + 2 more to create the micro-operations
° Most instructions translate to 1 to 4 micro-operations
° Complex 80x86 instructions are executed by aconventional microprogram (8K x 72 bits) that issueslong sequences of micro-operations
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.83
Limits to Multi-Issue Machines
° Inherent limitations of ILP• 1 branch in 5: How to keep a 5-way superscalar busy?
• Latencies of units: many operations must be scheduled
• Need about Pipeline Depth x No. Functional Units of independentinstructions to keep fully busy
• Increase ports to Register File
- VLIW example needs 7 read and 3 write for Int. Reg.& 5 read and 3 write for FP reg
• Increase ports to memory
• Current state of the art: Many hardware structures (such asissue/rename logic) has delay proportional to square of number ofinstructions issued/cycle
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.84
° Conflicting studies of amount• Benchmarks (vectorized Fortran FP vs. integer C programs)
• Hardware sophistication
• Compiler sophistication
° How much ILP is available using existingmechanims with increasing HW budgets?
° Do we need to invent new HW/SW mechanisms tokeep on processor performance curve?
• Intel MMX
• Motorola AltaVec
• Supersparc Multimedia ops, etc.
Limits to ILP

10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.85
Initial HW Model here; MIPS compilers.
Assumptions for ideal/perfect machine to start:
1. Register renaming–infinite virtual registers and allWAW & WAR hazards are avoided
2. Branch prediction–perfect; no mispredictions
3. Jump prediction–all jumps perfectly predicted =>machine with perfect speculation & an unboundedbuffer of instructions available
4. Memory-address alias analysis–addresses areknown & a store can be moved before a load providedaddresses not equal
1 cycle latency for all instructions; unlimited number ofinstructions issued per clock cycle
Limits to ILP
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.86
Programs
0
20
40
60
80
100
120
140
160
gcc espresso li fpppp doducd tomcatv
54.862.6
17.9
75.2
118.7
150.1
Integer: 18 - 60
FP: 75 - 150
IPC
Upper Limit to ILP: Ideal Machine
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.87
Program
0
10
20
30
40
50
60
gcc espresso li fpppp doducd tomcatv
35
41
16
61
5860
9
1210
48
15
67 6
46
13
45
6 6 7
45
14
45
2 2 2
29
4
19
46
Perfect Selective predictor Standard 2-bit Static None
Change from Infinitewindow to examine to2000 and maximumissue of 64 instructionsper clock cycle
ProfileBHT (512)Pick Cor. or BHTPerfect No prediction
FP: 15 - 45
Integer: 6 - 12
IPC
More Realistic HW: Branch Impact
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.88
Program
0
10
20
30
40
50
60
gcc espresso li fpppp doducd tomcatv
11
15
12
29
54
10
15
12
49
16
10
1312
35
15
44
910
11
20
11
28
5 5 6 5 57
4 45
45 5
59
45
Infinite 256 128 64 32 None
Change 2000 instrwindow, 64 instrissue, 8K 2 levelPrediction
Integer: 5 - 15
FP: 11 - 45
IPC
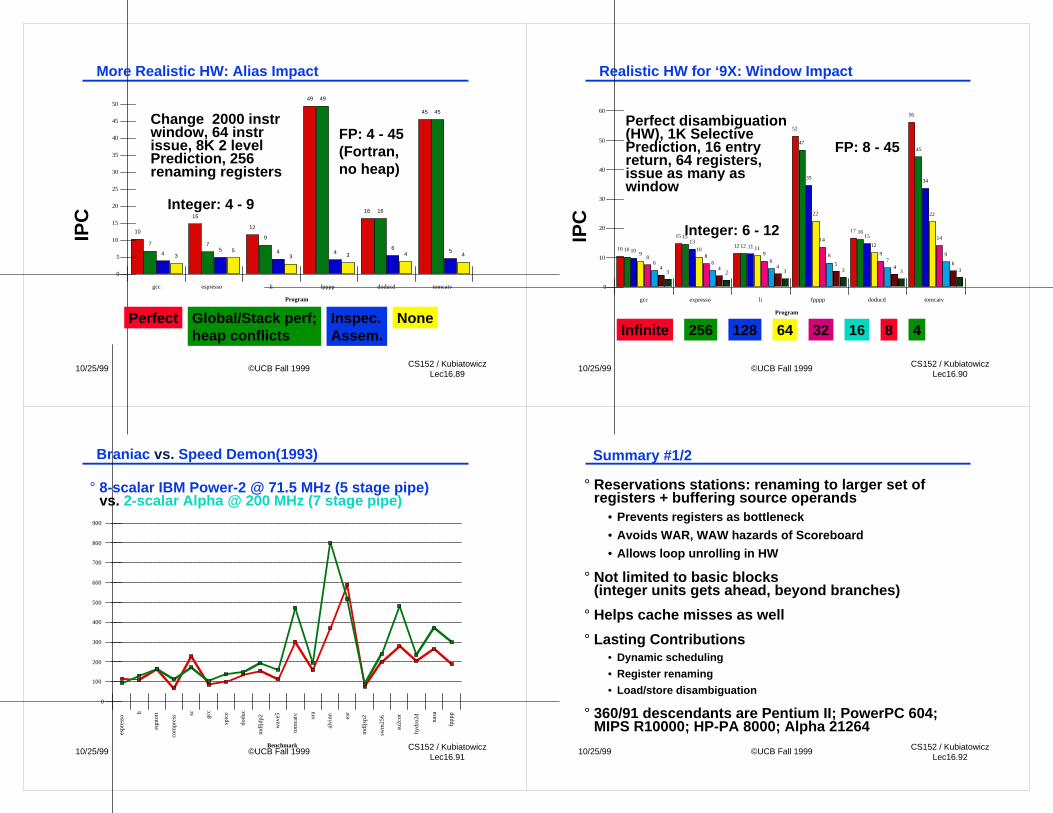
More Realistic HW: Register Impact (rename regs)
64 None256Infinite 32128
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.89
Program
0
5
10
15
20
25
30
35
40
45
50
gcc espresso li fpppp doducd tomcatv
10
15
12
49
16
45
7 79
49
16
45 4 4
6 53
53 3 4 4
45
Perfect Global/stack Perfect Inspection None
Change 2000 instrwindow, 64 instrissue, 8K 2 levelPrediction, 256renaming registers
FP: 4 - 45(Fortran,no heap)
Integer: 4 - 9
IPC
More Realistic HW: Alias Impact
NoneGlobal/Stack perf;heap conflicts
Perfect Inspec.Assem.
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.90
Program
0
10
20
30
40
50
60
gcc expresso li fpppp doducd tomcatv
10
15
12
52
17
56
10
15
12
47
16
10
1311
35
15
34
910 11
22
12
8 8 9
14
9
14
6 6 68
79
4 4 4 54
6
3 2 3 3 3 3
45
22
Infinite 256 128 64 32 16 8 4
Perfect disambiguation(HW), 1K SelectivePrediction, 16 entryreturn, 64 registers,issue as many aswindow
Integer: 6 - 12
FP: 8 - 45
IPC
Realistic HW for ‘9X: Window Impact
64 16256Infinite 32128 8 4
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.91
° 8-scalar IBM Power-2 @ 71.5 MHz (5 stage pipe)vs. 2-scalar Alpha @ 200 MHz (7 stage pipe)
Benchmark
0
100
200
300
400
500
600
700
800
900
espr
esso
li
eqnt
ott
com
pres
s sc gcc
spic
e
dodu
c
mdl
jdp2
wav
e5
tom
catv or
a
alvi
nn ear
mdl
jsp2
swm
256
su2c
or
hydr
o2d
nasa
fppp
pBraniac vs. Speed Demon(1993)
10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.92
Summary #1/2
° Reservations stations: renaming to larger set ofregisters + buffering source operands
• Prevents registers as bottleneck
• Avoids WAR, WAW hazards of Scoreboard
• Allows loop unrolling in HW
° Not limited to basic blocks(integer units gets ahead, beyond branches)
° Helps cache misses as well
° Lasting Contributions• Dynamic scheduling
• Register renaming
• Load/store disambiguation
° 360/91 descendants are Pentium II; PowerPC 604;MIPS R10000; HP-PA 8000; Alpha 21264

10/25/99 ©UCB Fall 1999 CS152 / KubiatowiczLec16.93
° Dynamic hardware schemes can unroll loopsdynamically in hardware
° Branch prediction very important to good performance
° Precise exceptions/Speculation: Out-of-orderexecution, In-order commit (reorder buffer)
° Superscalar and VLIW: CPI < 1 (IPC > 1)• Dynamic issue vs. Static issue
• More instructions issue at same time => larger hazard penalty
• Limitation is often number of instructions that you can successfullyfetch and decode per cycle ⇒ “Flynn barrier”
° SW Pipelining• Symbolic Loop Unrolling to get most from pipeline with little code
expansion, little overhead
Summary #2/2
Top Related