







Languages
Pages
Legal


CMPE 665:Multiple Processor Systems
CUDA-AWARE MPI
VIGNESH GOVINDARAJULU KOTHANDAPANIRANJITH MURUGESAN

Graphics Processing Unit
Accelerate the creation of images in a frame buffer intended for the output display.
Used for image processing and computer graphics. Term was popularized by NVIDIA in the year 1999. Also known as Visual Processing Unit. ATI technologies released the first GPU in the year 2002.

History of GPU development
1970’s and 1980’s Video shifters and video address generators. They acted as a
hardware between the main processor and display unit. RCA’s – “Pixie” Video chip(1976): Capable of outputting a signal of
62*128 resolution. MC6845 video address generator by Motorola(1978): Became the
basis for IBM display and Apple II display adapter. IBM Professional Graphics Controller (PGA) (1984): Was one of the
very first video cards for PC. Silicon Graphics Inc. (SGI) introduced the OpenGL technology in
the year in 1989.

History of GPU development
1990’s SGI’s graphics hardware was mainly used in workstations. Vodoo’s 3dfx was one of the first true game cards, it operated at a
speed of 50 Mhz with a 4MB of 64-Bit DRAM. NVIDIA’s GeForce256 offered many features such as multi-texering,
bump map, light maps and hardware geometry transforms and lighting. It operated at a clock speed of 120 Mhz and 32 MB of 128-Bit DRAM. It had a fixed pipeline model.
This is the time when the GPU hardware and computer gaming market took off.

History of GPU development
2000’s Programmable pipeline was introduced. Cards popular at this time
include Nvidia’s GeForce3 and ATI Radeon 8500. Fully programmable graphic cards were introduced in the year
2002, NVIDIA GeForce FX, ATI Radeon 9700. In 2004, GPU programming was starting to take off. In 2006, GPU started being exposed as massively parallel processors.
More programmability was added to the pixel and vertex shaders Current GPU’s are highly programmable and trend is towards GPU
accelerated processing.

CUDA - Compute Unified Device Architecture
CUDA is a parallel computing platform and programming model invented by NVIDIA.
It enables dramatic increases in computing performance by harnessing the power of the graphics-processing unit (GPU).
CUDA gives developers direct access to the virtual instruction set and memory of the parallel computational elements in CUDA GPUs.

CUDA - Compute Unified Device Architecture
Using CUDA, the GPUs can be used for general purpose processing,this approach is known as GPGPU- General-purpose computing on graphics processing units
Unlike CPUs, however, GPUs have a parallel throughput architecture that emphasizes executing many concurrent threads slowly, rather than executing a single thread very quickly.

Processing Flow
Copy data from main memory to GPU memory
CPU instructs the process to GPU
GPU execute parallel in each core
Copy the result from GPU memory to main memory

Advantages
With millions of CUDA-enabled GPUs sold to date, software developers, scientists and researchers are finding broad ranging uses for GPU computing with CUDA. Scattered reads – code can read from arbitrary addresses in
memory Unified Memory – Bridges CPU – GPU divide Faster downloads and read back to and from the GPU Full support for integer and bitwise operations, including integer
texture lookups

Disadvantages
Unlike OpenCL, CUDA-enabled GPUs are only available from Nvidia
CUDA does not support the full C standard,
Copying between host and device memory may incur a performance hit due to system bus bandwidth and latency
Valid C/C++ may sometimes be flagged and prevent compilation due to optimization techniques the compiler is required to employ to use limited resources.

Real Time Applications
Identify hidden plaque in arteries: Heart attacks are the leading cause of death worldwide. GPUs can be used to simulate blood flow and identify hidden arterial plaque without invasive imaging techniques or exploratory surgery.
Analyze air traffic flow: The National Airspace System manages the nationwide coordination of air traffic flow. Computer models help identify new ways to alleviate congestion and keep airplane traffic moving efficiently.

Real Time Applications
Using the computational power of GPUs, a team at NASA obtained a large performance gain, reducing analysis time from ten minutes to three seconds.
Visualize molecules: A molecular simulation called NAMD (nanoscale molecular dynamics) gets a large performance boost with GPUs. The speed-up is a result of the parallel architecture of GPUs, which enables NAMD developers to port compute-intensive portions of the application to the GPU using the CUDA Toolkit.

Message Passing Interface (MPI) MPI process runs on a system with distributed memory space, such
as a cluster. MPI actually defines a message-passing API which covers point-to-point messages as well as collective operations like reductions.
In MPI each processor is called as a rank.

Reason for combining CUDA and MPI
To solve problems with a data size too large to fit into the memory of a single GPU
To solve problems that would require unreasonably long compute time on a single node
To accelerate an existing MPI application with GPUs
To enable a single-node multi-GPU application to scale across multiple nodes

CUDA-AWARE MPI
In normal MPI if one wants to send GPU gpu buffers, one would need to stage it through the host memory as shown in the code below.//MPI Rank 0
cudaMemcpy(s_buf_h,s_buf_d,size,cudaMemcpyDeviceToHost);
MPI_Send(s_buf_h,size,MPI_CHAR,1,100,MPI_COMM_WORLD);
//MPI Rank 1
MPI_Recv(r_buf_h,size,MPI_CHAR,0,100,MPI_COMM_WORLD,&status);
cudaMemcpy(r_buf_d,r_buf_h,size,cudaMemcpyHostToDevice);

CUDA-AWARE MPI
With Cuda-Aware MPI the GPU buffers can be directly passed on to MPI.
//MPI Rank 0
MPI_Send(s_buf_h,size,MPI_CHAR,1,100,MPI_COMM_WORLD);
//MPI Rank 1
MPI_Recv(r_buf_h,size,MPI_CHAR,0,100,MPI_COMM_WORLD,&status);
CUDA-AWARE MPI
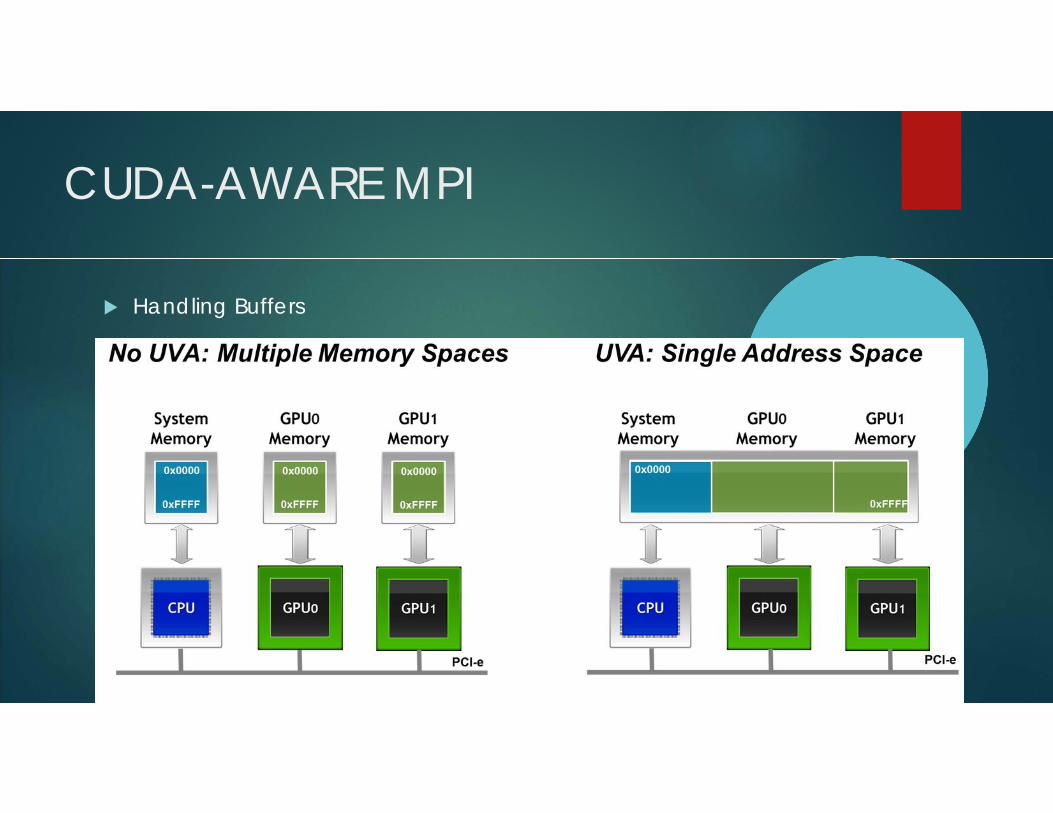
Handling Buffers

CUDA-AWARE MPI
All operation that require message transfer can be pipelined. Acceleration technologies like GPU direct can be utilized by the MPI
library. GPU buffers can be directly passed to the network adapter.

CUDA-AWARE MPI

CUDA-Aware MPI
Working of CUDA-AWARE MPIThe below diagram shows the various process involved:

CUDA-AWARE MPI
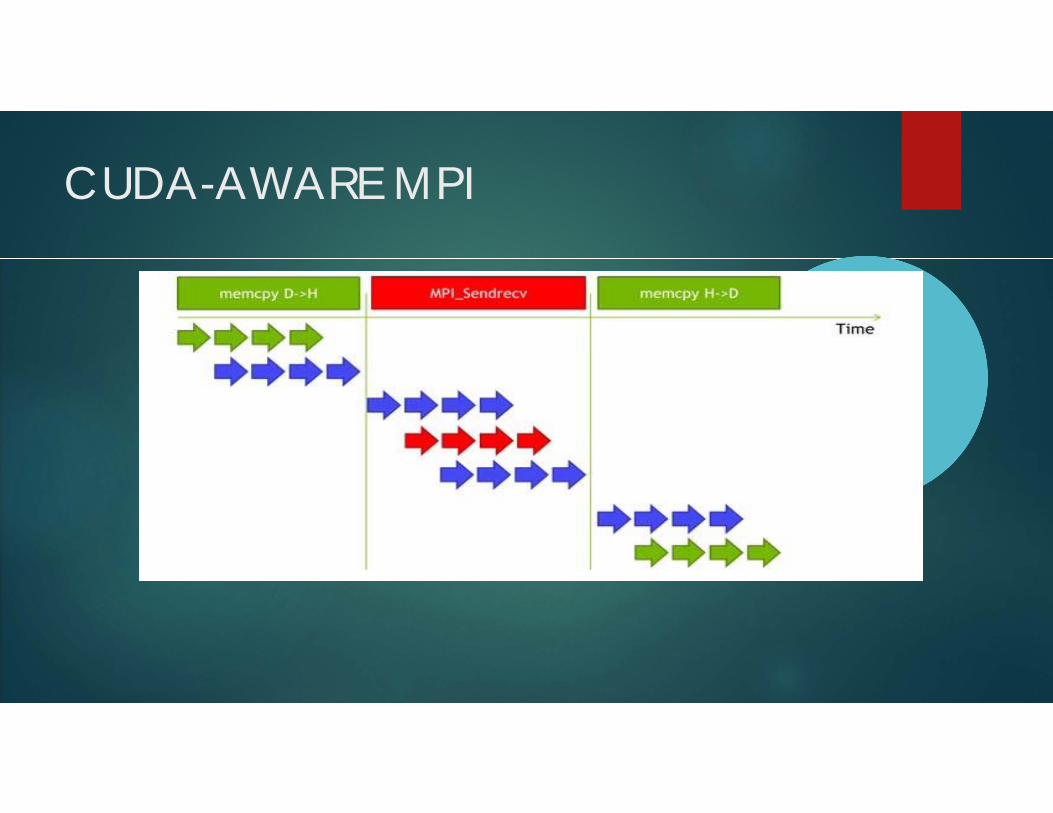
CUDA-AWARE MPI

MPI vs. CUDA-AWARE MPI PERFORMANCE
For tasks where communication between processors is low.
MPI vs. CUDA-AWARE MPI PERFORMANCE
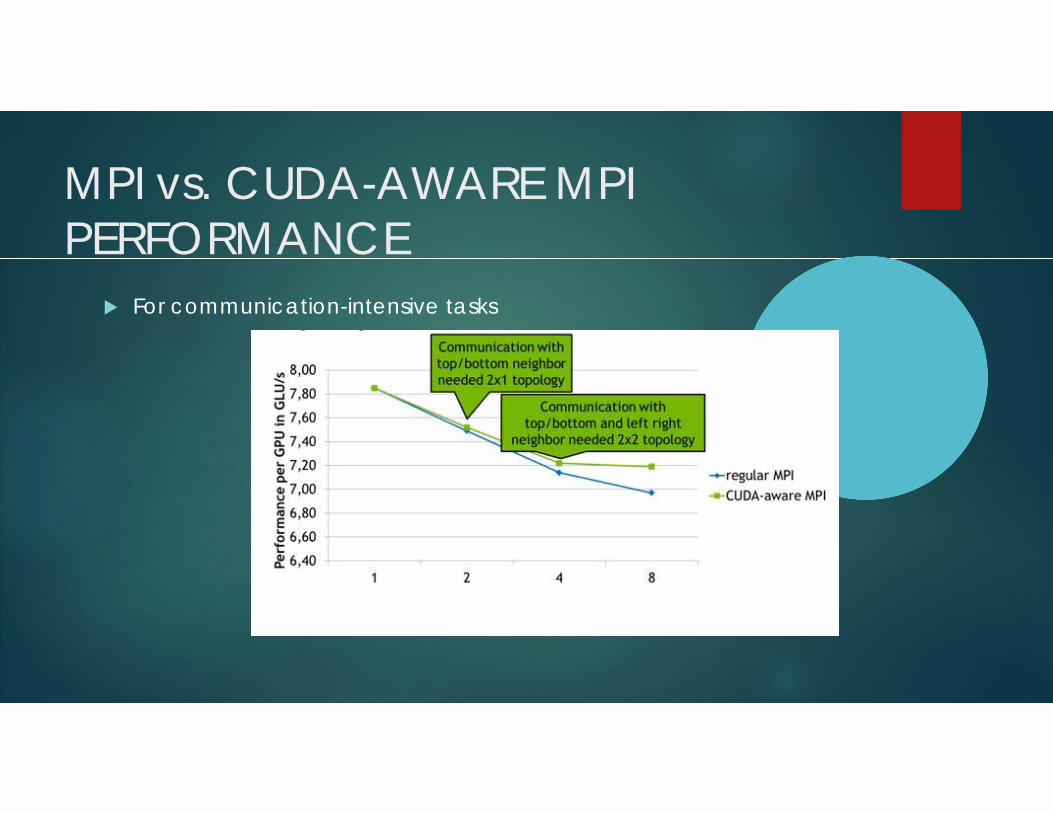
For communication-intensive tasks

MPI vs. CUDA-AWARE MPI PERFORMANCE
Ease of use Pipelined data transfers that automatically provide optimizations
when available.

CUDA-AWARE MPI Implementations
OpenMPI 1.7 (beta)
Better interactions with streams Better small message performance – eager protocol Support for reduction operations Support for non-blocking collectives

CUDA-AWARE MPI Implementations
IBM Platform MPI(8.3)
Obtain higher quality results faster Reduce development and support costs Improve engineer and developer productivity Supports the broadest range of industry-standard platforms,
interconnects, and operating systems helping ensure that parallel applications can run almost anywhere
Top Related