







Languages
Pages
Legal


Julien Plu
@julienplu
Populating DBpedia FR and using it for
Extracting Information

Agenda
Mapping the French infoboxes
How is DBpedia FR used at Orange?
Presentation of the Orange challenge
Project: ExtSem
Module 1: ParseText
Module 2: BuildDepGraph
Module 3: ExtractRDF
Module 4: SelectRDF
Experiments
09/02/2015 - 3rd DBpedia Community Meeting – Dublin, Ireland - 2

Mapping the French infoboxes
The set of mappings has grown significantly
during the last three years (2012-2015)
208 infoboxes have mappings
I contribute to 100 mappings
This amounts to 50% of the articles in the French
Wikipedia which have an infobox
Example:
Infobox Communes de France (mapping): 36765
occurrences
Infobox Musique (œuvre) (mapping): 29429 occurrences
09/02/2015 - 3rd DBpedia Community Meeting – Dublin, Ireland - 3

How is DBpedia FR used at Orange?
Used as a knowledge graph for the in-house
Web search engine
Used to interlink background knowledge with
internal data about films (AlloCine) and music
(Deezer)
Used as a knowledge provider for public tools
in IPTV
Used for recommendation system in VOD
service
09/02/2015 - 3rd DBpedia Community Meeting – Dublin, Ireland - 4

Presentation of the Orange challenge
Team members:
Guillaume Viland
Jonathan Marchand
Julien Plu
Internal challenge for getting new research
projects
Only two weeks to get something to present
09/02/2015 - 3rd DBpedia Community Meeting – Dublin, Ireland - 5
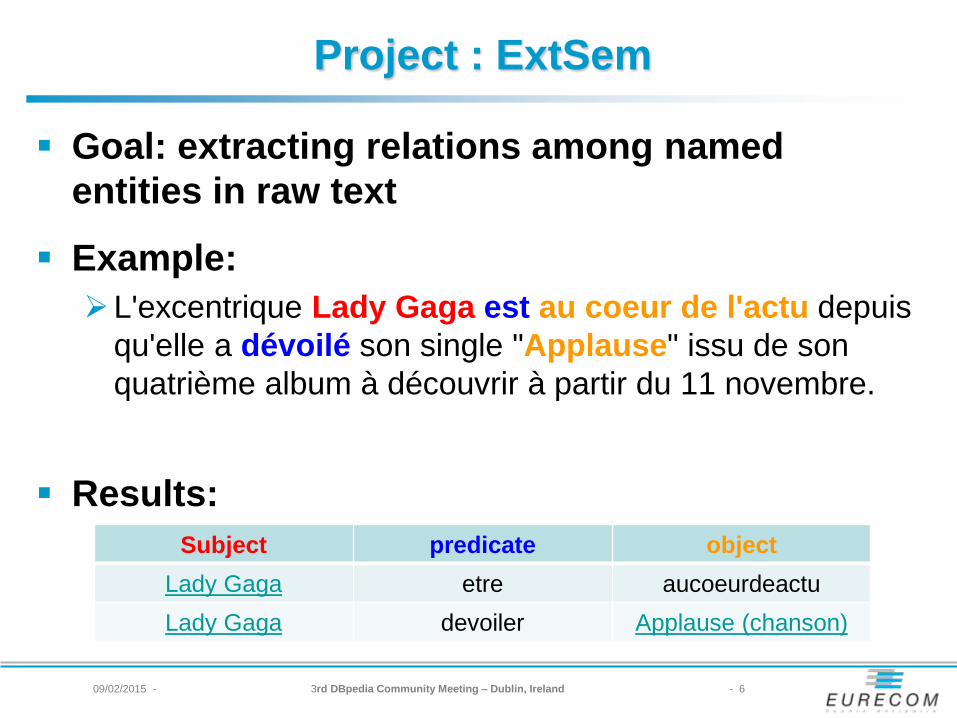
Project : ExtSem
Goal: extracting relations among named
entities in raw text
Example:
L'excentrique Lady Gaga est au coeur de l'actu depuis
qu'elle a dévoilé son single "Applause" issu de son
quatrième album à découvrir à partir du 11 novembre.
Results:
Subject predicate object
Lady Gaga etre aucoeurdeactu
Lady Gaga devoiler Applause (chanson)
09/02/2015 - 3rd DBpedia Community Meeting – Dublin, Ireland - 6

Module 1: ParseText
.txt
Tokenizer
et PoS
Tagger :
Melt
.conll06
.inmalt
Parser :
MaltParser
• Part of Speech Tagger and
Parser are stochastic and
trained with the French
Dependency Treebank
• Deep syntactic analysis with
dependencies
09/02/2015 - 3rd DBpedia Community Meeting – Dublin, Ireland - 7
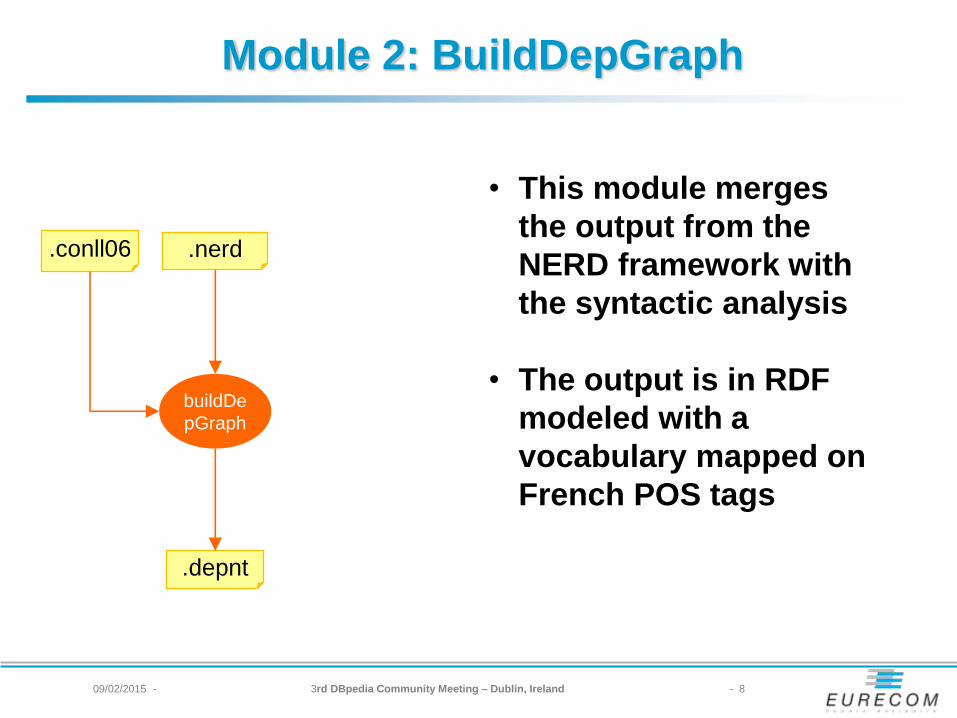
Module 2: BuildDepGraph
.conll06 .nerd
buildDe
pGraph
.depnt
• This module merges
the output from the
NERD framework with
the syntactic analysis
• The output is in RDF
modeled with a
vocabulary mapped on
French POS tags
09/02/2015 - 3rd DBpedia Community Meeting – Dublin, Ireland - 8

Module 3: ExtractRDF
.depnt example
.depnt
extractRdf .fullnt
09/02/2015 - 3rd DBpedia Community Meeting – Dublin, Ireland - 9

Module 4: selectRDF
.fullnt
selectRd
f
.nt
• This module enables to select
the triples who has a URI as
subject
• One can also customize this
module according to a topic
to map the predicate to
properties from well-known
vocabularies
09/02/2015 - 3rd DBpedia Community Meeting – Dublin, Ireland - 10

Experiments
We have processed, for one month, the (480) daily
articles from the “Closer” Magazine.
Some statistics:
2800 triples extracted
971 distinct entities
657 distinct predicates
At least 4 triples extracted per articles
Qualitative analysis:
57% of the triples are about relationship between
celebrities (wedding, cheating, rumors, etc.)
43% of the triples are about diverse topics such as sport,
fashion or politics09/02/2015 - 3rd DBpedia Community Meeting – Dublin, Ireland - 11

Conclusion
Good results for two weeks of work (3rd
position on 7 participants for this challenge)
The idea behind this project has been taken by
Orange Labs for being exploited
Possible evolutions:
Automatic mapping of the predicates
Add more grammar rules to get more triples
Improve the performance (slow and long process)
Machine learning algorithm to classify which triple can be
useful (interesting) or not.
09/02/2015 - 3rd DBpedia Community Meeting – Dublin, Ireland - 12
Top Related