







Languages
Pages
Legal


Paraphrase Generation from Latent-Variable PCFGsfor Semantic Parsing
Shashi Narayan, Siva Reddy, Shay B. Cohen
School of Informatics, University of Edinburgh
INLG, September 2016
1 / 51

Semantic Parsing for Question Answering
Semantically parsing questions into Freebase logical forms for thegoal of question answering
I task-specific grammars (Berant et al., 2013)
I strongly-typed CCG grammars (Kwiatkowski et al., 2013;Reddy et al., 2014, 2016)
I neural networks without requiring any grammar (Yih et al.,2015)
Sensitive to words used in a question and their word order
Vulnerable to unseen words and phrases
2 / 51

Semantic Parsing for Question Answering
Semantically parsing questions into Freebase logical forms for thegoal of question answering
I task-specific grammars (Berant et al., 2013)
I strongly-typed CCG grammars (Kwiatkowski et al., 2013;Reddy et al., 2014, 2016)
I neural networks without requiring any grammar (Yih et al.,2015)
Sensitive to words used in a question and their word order
Vulnerable to unseen words and phrases
2 / 51

Semantic Parsing for Question Answering: An Example
What language do people in Czech Republic speak?
Freebase knowledge graph
language.human language
target
Czech mCzech
Republiclocation.country.official language.2
location.country.official language.1
type
3 / 51

Semantic Parsing for Question Answering: An Example
What language do people in Czech Republic speak?
Freebase knowledge graph
language.human language
target
Czech mCzech
Republiclocation.country.official language.2
location.country.official language.1
type
3 / 51

Graph Matching Problem
What language do people in Czech Republic speak?
language target people
x e1 y e2Czech
Republicspeak.arg2
speak.arg1
people.in.arg1
people.in.arg2
type
type
Freebase knowledge graph
language.human language
target
Czech mCzech
Republiclocation.country.official language.2
location.country.official language.1
type
4 / 51
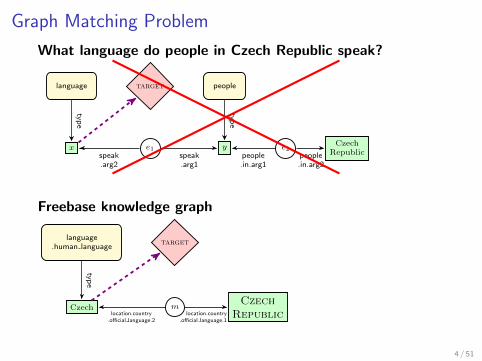
Graph Matching Problem
What language do people in Czech Republic speak?
language target people
x e1 y e2Czech
Republicspeak.arg2
speak.arg1
people.in.arg1
people.in.arg2
type
type
Freebase knowledge graph
language.human language
target
Czech mCzech
Republiclocation.country.official language.2
location.country.official language.1
type
4 / 51
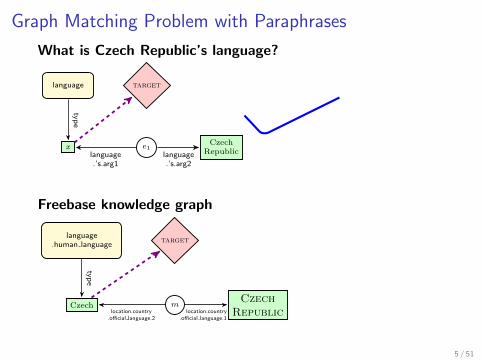
Graph Matching Problem with Paraphrases
What is Czech Republic’s language?
language target
x e1Czech
Republiclanguage.’s.arg1
language.’s.arg2
type
Freebase knowledge graph
language.human language
target
Czech mCzech
Republiclocation.country.official language.2
location.country.official language.1
type
5 / 51

Graph Matching Problem with Paraphrases
What language do people speak in Czech Republic?
people y
target e1
x e1
language e1
CzechRepublic
speak.a
rg2
speak.arg1
speak.in
speak.arg
1
speak.arg2
speak.in
type
type
6 / 51

Question Answering with Paraphrases
Paraphrasing with phrase-based machine translation fortext-based QA (Duboue and Chu-Carroll, 2006; Riezler et al.,2007)
Paraphrasing with hand annotated grammars for KB-based QA(Berant and Liang, 2014)
7 / 51

This talk ...
Paraphrase Generation with Latent-Variable PCFGs(L-PCFGs)
I Uses spectral method of Narayan and Cohen (EMNLP 2015)to learn sparse and robust grammar to sample paraphrases,and
I generates lexically and syntactically diverse paraphrases
Improving semantic parsing of questions into Freebase logicalforms using paraphrases
8 / 51

This talk ...
Paraphrase Generation with Latent-Variable PCFGs(L-PCFGs)
I Uses spectral method of Narayan and Cohen (EMNLP 2015)to learn sparse and robust grammar to sample paraphrases,and
I generates lexically and syntactically diverse paraphrases
Improving semantic parsing of questions into Freebase logicalforms using paraphrases
8 / 51

This talk ...
Paraphrase Generation with Latent-Variable PCFGs(L-PCFGs)
I Uses spectral method of Narayan and Cohen (EMNLP 2015)to learn sparse and robust grammar to sample paraphrases,and
I generates lexically and syntactically diverse paraphrases
Improving semantic parsing of questions into Freebase logicalforms using paraphrases
8 / 51

This talk ...
Paraphrase Generation with Latent-Variable PCFGs(L-PCFGs)
I Uses spectral method of Narayan and Cohen (EMNLP 2015)to learn sparse and robust grammar to sample paraphrases,and
I generates lexically and syntactically diverse paraphrases
Improving semantic parsing of questions into Freebase logicalforms using paraphrases
8 / 51

Outline of this talk
Spectral Learning of Latent-variable PCFGs
Paraphrase Generation using L-PCFGs
Semantic Parsing using Paraphrases
Results and Discussion
9 / 51

Outline of this talk
Spectral Learning of Latent-variable PCFGs
Paraphrase Generation using L-PCFGs
Semantic Parsing using Paraphrases
Results and Discussion
10 / 51

Probabilistic CFGs with Latent States (Matsuzaki et al., 2005;
Prescher 2005)
S
VP
NP
N
cat
D
the
V
saw
NP
N
dog
D
the
⇒
S1
VP2
NP5
N4
cat
D1
the
V4
saw
NP3
N2
dog
D1
the
Latent states play the role of nonterminal subcategorization, e.g.,NP → {NP1, NP2, . . . , NP24}
I analogous to syntactic heads as in lexicalization (Charniak 1997)
?
They are not part of the observed data in the treebank11 / 51

Estimating PCFGs with Latent States (L-PCFGs)
EM Algorithm (Matsuzaki et al., 2005; Petrov et al., 2006)
⇓ Problems with local maxima; it fails to provide certain typeof theoretical guarantees as it doesn’t find global maximum ofthe log-likelihood
Spectral Algorithm (Cohen et al., 2012, 2014, Narayan and Cohen, 2015,
2016)
⇑ Statistically consistent algorithms that make use of spectraldecomposition
⇑ Much faster training than the EM algorithm
12 / 51

Estimating PCFGs with Latent States (L-PCFGs)
EM Algorithm (Matsuzaki et al., 2005; Petrov et al., 2006)
⇓ Problems with local maxima; it fails to provide certain typeof theoretical guarantees as it doesn’t find global maximum ofthe log-likelihood
Spectral Algorithm (Cohen et al., 2012, 2014, Narayan and Cohen, 2015,
2016)
⇑ Statistically consistent algorithms that make use of spectraldecomposition
⇑ Much faster training than the EM algorithm
12 / 51

Intuition behind the Spectral Algorithm
Inside and outside treesAt node VP:
S
VP
P
him
V
saw
NP
N
dog
D
the
Outside tree o = S
VPNP
N
dog
D
the
Inside tree t = VP
P
him
V
saw
Conditionally independent given the label and the hidden state
p(o, t|VP, h) = p(o|VP, h)× p(t|VP, h)
13 / 51

Inside Features used
Consider the VP node in the following tree:
S
VP
NP
N
dog
D
the
V
saw
NP
N
cat
D
the
The inside features consist of:
I The pairs (VP, V) and (VP, NP)
I The rule VP → V NP
I The tree fragment (VP (V saw) NP)
I The tree fragment (VP V (NP D N))
I The pair of head part-of-speech tag with VP: (VP, V)14 / 51

Outside Features used
Consider the D node in the following tree:
S
VP
NP
N
dog
D
the
V
saw
NP
N
cat
D
the
The outside features consist of:I The pairs (D, NP) and (D, NP, VP)I The pair of head part-of-speech tag with D: (D, N)I The tree fragments NP
ND*
, VP
NP
ND*
V
and S
VP
NP
ND*
V
NP
15 / 51

Recent Advances in Spectral Estimation
=
Singular value decomposition (SVD) of cross-covariancematrix for each nonterminal
16 / 51

Recent Advances in Spectral Estimation
=
SVD Step
Method of moments (Cohen et al., 2012, 2014)
I Averaging with SVD parameters ⇒ Dense estimates
Clustering variants (Narayan and Cohen 2015)
(1, 1, 0, 1, . . .)
S
VP
N
w3
V
w2
NP
N
w1
D
w0
S[1]
VP[3]
N[1]
w3
V[1]
w2
NP[4]
N[4]
w1
D[7]
w0
Sparse estimates
17 / 51

Recent Advances in Spectral Estimation
=
SVD Step
Method of moments (Cohen et al., 2012, 2014)
I Averaging with SVD parameters ⇒ Dense estimates
Clustering variants (Narayan and Cohen 2015)
(1, 1, 0, 1, . . .)
S
VP
N
w3
V
w2
NP
N
w1
D
w0
S[1]
VP[3]
N[1]
w3
V[1]
w2
NP[4]
N[4]
w1
D[7]
w0
Sparse estimates
17 / 51

Outline of this talk
Spectral Learning of Latent-variable PCFGs
Paraphrase Generation using L-PCFGs
Semantic Parsing using Paraphrases
Results and Discussion
18 / 51

Outline of this talk
Spectral Learning of Latent-variable PCFGs
Paraphrase Generation using L-PCFGs
Semantic Parsing using Paraphrases
Results and Discussion
19 / 51

Paraphrase Generation Algorithm
Given an input sentence
I Word lattice construction to constrain our paraphrases to aspecific choice of words and phrases
what kind
just what
what
exactly what
what sort
language
linguistic
do
people
members of the public
human beings
people ’s
the population
the citizens
in
Czech Republic
Czech
the Czech Republic
Czech
Cze
Republic
speak
talking about
express itself
talk about
to talk
is speaking
?
What language do people in Czech Republic speak?
I Sampling paraphrases using L-PCFGs, constrained by theword lattice
I Paraphrase classification to improve precision
20 / 51

Paraphrase Generation Algorithm
Given an input sentence
I Word lattice construction to constrain our paraphrases to aspecific choice of words and phrases
I Sampling paraphrases using L-PCFGs, constrained by theword lattice
I Paraphrase classification to improve precision
20 / 51

Paraphrase Generation Algorithm
Given an input sentence
I Word lattice construction to constrain our paraphrases to aspecific choice of words and phrases
I Sampling paraphrases using L-PCFGs, constrained by theword lattice
I Paraphrase classification to improve precision
20 / 51

L-PCFG Estimation for Sampling Paraphrases
The Paralex Corpus, 18m paraphrase pairs with 2.4M distinctquestions (Fader et. al. 2013)
Parse all the questions using the BLLIP Parser (Charniak andJohnson, 2005)
Estimate a robust and sparse L-PCFG Gsyn with m = 24 (Narayanand Cohen 2015)
21 / 51

L-PCFG Estimation for Sampling Paraphrases
The Paralex Corpus, 18m paraphrase pairs with 2.4M distinctquestions (Fader et. al. 2013)
Parse all the questions using the BLLIP Parser (Charniak andJohnson, 2005)
Estimate a robust and sparse L-PCFG Gsyn with m = 24 (Narayanand Cohen 2015)
21 / 51

Sampling Sentential Paraphrases using L-PCFG Gsyn
Given an input word lattice and a grammar Gsyn:
Lexical pruning: Extract a grammar G ′syn from Gsyn which is
constrained to the lattice
what kind
just what
what
exactly what
what sort
language
linguistic
do
people
members of the public
human beings
people ’s
the population
the citizens
in
Czech Republic
Czech
the Czech Republic
Czech
Cze
Republic
speak
talking about
express itself
talk about
to talk
is speaking
?
What language do people in Czech Republic speak?
22 / 51

Sampling Sentential Paraphrases using L-PCFG Gsyn
Given an input word lattice and a grammar Gsyn:
Controlled sampling: Sample a question from G ′syn by recursively
sampling nodes in the derivation tree, together with their latentstates, over the lattice
what kind
just what
what
exactly what
what sort
language
linguistic
do
people
members of the public
human beings
people ’s
the population
the citizens
in
Czech Republic
Czech
the Czech Republic
Czech
Cze
Republic
speak
talking about
express itself
talk about
to talk
is speaking
?
(what, language, do, people ’s, in, Czech, Republic, is speaking, ?)⇓
what is Czech Republic ’s language?22 / 51

Paraphrase Classification
Filter with a classifier to improve the precision of the generatedparaphrases
MT metrics for paraphrase identification (Madnani et al. 2012)
23 / 51

Word Lattice Construction
Two approaches:
1. Lexical and phrasal paraphrase rules from the ParaphraseDatabase (Ganitkevitch et al., 2013)
what kind
just what
what
exactly what
what sort
language
linguistic
do
people
members of the public
human beings
people ’s
the population
the citizens
in
Czech Republic
Czech
the Czech Republic
Czech
Cze
Republic
speak
talking about
express itself
talk about
to talk
is speaking
?
What language do people in Czech Republic speak?
2. Lexical paraphrases from Bi-layered L-PCFG
24 / 51

Word Lattice Construction
Two approaches:
1. Lexical and phrasal paraphrase rules from the ParaphraseDatabase (Ganitkevitch et al., 2013)
2. Lexical paraphrases from Bi-layered L-PCFG
24 / 51

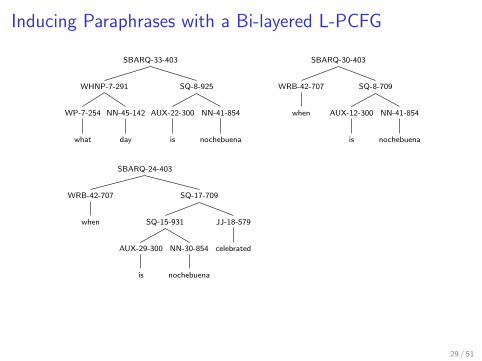
Inducing Paraphrases with a Bi-layered L-PCFG
L-PCFG Glayered with two layers of latent states:
one layer is intended to capture the usual syntactic information(traditional Gsyn with m = 24), and
the other aims to capture semantic and topical information byusing a large set of states (Gpar with m = 1000)
25 / 51

Training trees for Bi-layered L-PCFG Training
SBARQ-33-403
SQ-8-925
NN-41-854
nochebuena
AUX-22-300
is
WHNP-7-291
NN-45-142
day
WP-7-254
what
SBARQ-30-403
SQ-8-709
NN-41-854
nochebuena
AUX-12-300
is
WRB-42-707
when
SBARQ-24-403
SQ-17-709
JJ-18-579
celebrated
SQ-15-931
NN-30-854
nochebuena
AUX-29-300
is
WRB-42-707
when
26 / 51

Features for Second Layer
Design feature functions ψ and φ:
S
VPNP
N
dog
D
the
VP
P
him
V
saw
Outside tree o ⇒ Inside tree t ⇒ψ(o) = [0, 1, 0, 0, . . . , 0, 1] ∈ Rd′ φ(t) = [1, 0, 0, 0, . . . , 1, 0] ∈ Rd
Bag of aligned words Bag of aligned words(the, dog, pet, . . . ) (saw, him, notice, . . . )
27 / 51

Training a Bi-layered L-PCFG
The Paralex Corpus, 18m paraphrase pairs (Fader et. al. 2013)
28 / 51

Inducing Paraphrases with a Bi-layered L-PCFG
SBARQ-33-403
SQ-8-925
NN-41-854
nochebuena
AUX-22-300
is
WHNP-7-291
NN-45-142
day
WP-7-254
what
29 / 51
Inducing Paraphrases with a Bi-layered L-PCFG
SBARQ-33-403
SQ-8-925
NN-41-854
nochebuena
AUX-22-300
is
WHNP-7-291
NN-45-142
day
WP-7-254
what
SBARQ-30-403
SQ-8-709
NN-41-854
nochebuena
AUX-12-300
is
WRB-42-707
when
SBARQ-24-403
SQ-17-709
JJ-18-579
celebrated
SQ-15-931
NN-30-854
nochebuena
AUX-29-300
is
WRB-42-707
when
29 / 51

Inducing Paraphrases with a Bi-layered L-PCFG
SBARQ-33-403
SQ-8-925
NN-41-854
nochebuena
AUX-22-300
is
WHNP-7-291
NN-45-142
day
WP-7-254
what
SBARQ-30-403
SQ-8-709
NN-41-854
nochebuena
AUX-12-300
is
WRB-42-707
when
SBARQ-24-403
SQ-17-709
JJ-18-579
celebrated
SQ-15-931
NN-30-854
nochebuena
AUX-29-300
is
WRB-42-707
when
SBARQ-1-403
SQ-22-809
VBN-29-682
born
SQ-21-910
NP-24-60
NNP-21-290
montez
NNP-21-567
gabuella
AUX-10-866
was
WRB-23-103
where
29 / 51
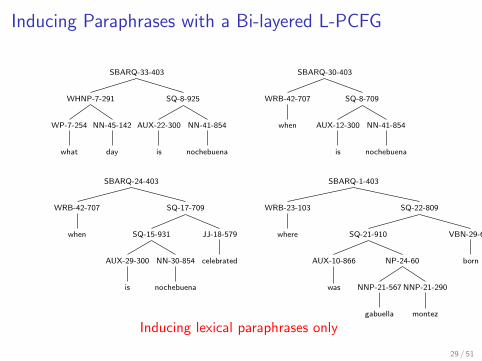
Inducing Paraphrases with a Bi-layered L-PCFG
SBARQ-33-403
SQ-8-925
NN-41-854
nochebuena
AUX-22-300
is
WHNP-7-291
NN-45-142
day
WP-7-254
what
SBARQ-30-403
SQ-8-709
NN-41-854
nochebuena
AUX-12-300
is
WRB-42-707
when
SBARQ-24-403
SQ-17-709
JJ-18-579
celebrated
SQ-15-931
NN-30-854
nochebuena
AUX-29-300
is
WRB-42-707
when
SBARQ-1-403
SQ-22-809
VBN-29-682
born
SQ-21-910
NP-24-60
NNP-21-290
montez
NNP-21-567
gabuella
AUX-10-866
was
WRB-23-103
where
Inducing lexical paraphrases only
29 / 51

Outline of this talk
Spectral Learning of Latent-variable PCFGs
Paraphrase Generation using L-PCFGs
Semantic Parsing using Paraphrases
Results and Discussion
30 / 51

Outline of this talk
Spectral Learning of Latent-variable PCFGs
Paraphrase Generation using L-PCFGs
Semantic Parsing using Paraphrases
Results and Discussion
31 / 51

Semantic Parsing using Paraphrases (Reddy et. al., 2014)
What language do people in Czech Republic speak?
32 / 51

Semantic Parsing using Paraphrases (Reddy et. al., 2014)
What language do people in Czech Republic speak?
What language do people in CzechRepublic speak? What is Czech Republic’s
language? What language do people speak inCzech Republic? . . .
32 / 51

Semantic Parsing using Paraphrases (Reddy et. al., 2014)
What language do people in Czech Republic speak?
What language do people in CzechRepublic speak? What is Czech Republic’s
language? What language do people speak inCzech Republic? . . .
λe.speak.arg1(e, people)∧speak.arg2(e, language?)
∧speak.in(e,CzechRepublic)
CCG
32 / 51
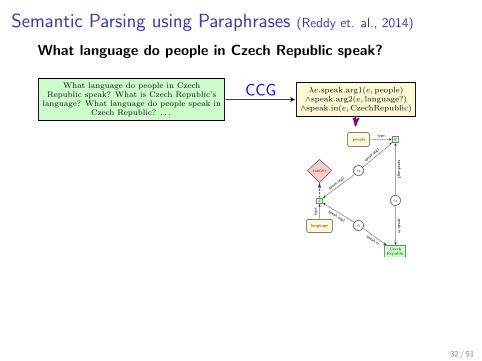
Semantic Parsing using Paraphrases (Reddy et. al., 2014)
What language do people in Czech Republic speak?
What language do people in CzechRepublic speak? What is Czech Republic’s
language? What language do people speak inCzech Republic? . . .
λe.speak.arg1(e, people)∧speak.arg2(e, language?)
∧speak.in(e,CzechRepublic)
people y
target e1
x e1
language e1
CzechRepublic
speak.a
rg2
speak.arg1
speak.in
speak.arg
1
speak.arg2
speak.in
type
type
CCG
32 / 51

Semantic Parsing using Paraphrases (Reddy et. al., 2014)
What language do people in Czech Republic speak?
32 / 51

Semantic Parsing using Paraphrases (Reddy et. al., 2014)
What language do people in Czech Republic speak?
(p, u, g) = arg max(p,u,g)
θ · Φ(p, u, g , q,K)
where, Φ(p, u, g , q,K) ∈ Rn denotes the features for the tuple ofparaphrase p, ungrounded u and grounded g graphs
32 / 51

Model
Structured Perceptron: Ranks a tuple of paraphrase, grounded andungrounded graph.
(p, u, g) = arg max(p,u,g)
θ · Φ(p, u, g , q,K)
Features: Φ is defined over sentence, grounded and ungroundedgraph.
Training: Use surrogate gold graph to update weights
θt+1 ← θt + Φ(p+, u+, g+, q,K)− Φ(p, u, g , q,K) ,
More details: We use Margin-Sensitive Averaged Peceptron.
33 / 51

Outline of this talk
Spectral Learning of Latent-variable PCFGs
Paraphrase Generation using L-PCFGs
Semantic Parsing using Paraphrases
Results and Discussion
34 / 51

Outline of this talk
Spectral Learning of Latent-variable PCFGs
Paraphrase Generation using L-PCFGs
Semantic Parsing using Paraphrases
Results and Discussion
35 / 51

Experimental Setup
WebQuestions (Berant et al., 2013)
I Google search queries starting with wh question words
I 5,810 question-answer pairs (3,778 training and 2,032 test)
I Development experiments: held-out data consisting of30% training questions
Evaluation metric
I Average precision, average recall and average F1 (Berant etal., 2013)
36 / 51

Experimental Setup
WebQuestions (Berant et al., 2013)
I Google search queries starting with wh question words
I 5,810 question-answer pairs (3,778 training and 2,032 test)
I Development experiments: held-out data consisting of30% training questions
Evaluation metric
I Average precision, average recall and average F1 (Berant etal., 2013)
36 / 51

Experimental Setup
Our systems
I naive: Word lattice representing the input sentence itself
I ppdb: Word lattice constructed using the PPDB rules
I bilayered: Word lattice constructed using the bi-layeredL-PCFG
Baselines
I original: Semantic parser (Reddy et. al., 2014) withoutparaphrases
I mt: Monolingual machine translation based model forparaphrase generation (Quirk et al., 2004; Wubben et al.,2010)
37 / 51

Experimental Setup
Our systems
I naive: Word lattice representing the input sentence itself
I ppdb: Word lattice constructed using the PPDB rules
I bilayered: Word lattice constructed using the bi-layeredL-PCFG
Baselines
I original: Semantic parser (Reddy et. al., 2014) withoutparaphrases
I mt: Monolingual machine translation based model forparaphrase generation (Quirk et al., 2004; Wubben et al.,2010)
37 / 51

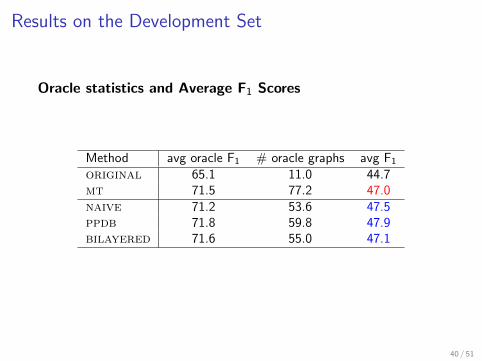
Results on the Development Set
Oracle statistics and Average F1 Scores
Method avg oracle F1 # oracle graphs avg F1
original 65.1 11.0 44.7mt 71.5 77.2 47.0naive 71.2 53.6 47.5ppdb 71.8 59.8 47.9bilayered 71.6 55.0 47.1
38 / 51

Results on the Development Set
Oracle statistics and Average F1 Scores
Method avg oracle F1 # oracle graphs avg F1
original 65.1 11.0 44.7mt 71.5 77.2 47.0naive 71.2 53.6 47.5ppdb 71.8 59.8 47.9bilayered 71.6 55.0 47.1
39 / 51
Results on the Development Set
Oracle statistics and Average F1 Scores
Method avg oracle F1 # oracle graphs avg F1
original 65.1 11.0 44.7mt 71.5 77.2 47.0naive 71.2 53.6 47.5ppdb 71.8 59.8 47.9bilayered 71.6 55.0 47.1
40 / 51

Results on the Development Set
Oracle statistics and Average F1 Scores
Method avg oracle F1 # oracle graphs avg F1
original 65.1 11.0 44.7mt 71.5 77.2 47.0naive 71.2 53.6 47.5ppdb 71.8 59.8 47.9bilayered 71.6 55.0 47.1
41 / 51

Results on the Development Set
Oracle statistics and Average F1 Scores
Method avg oracle F1 # oracle graphs avg F1
original 65.1 11.0 44.7mt 71.5 77.2 47.0naive 71.2 53.6 47.5ppdb 71.8 59.8 47.9bilayered 71.6 55.0 47.1
42 / 51

Results on the Development Set
Oracle statistics and Average F1 Scores
Method avg oracle F1 # oracle graphs avg F1
original 65.1 11.0 44.7mt 71.5 77.2 47.0naive 71.2 53.6 47.5ppdb 71.8 59.8 47.9bilayered 71.6 55.0 47.1
43 / 51

Results on the Development Set
Oracle statistics and Average F1 Scores
Method avg oracle F1 # oracle graphs avg F1
original 65.1 11.0 44.7mt 71.5 77.2 47.0naive 71.2 53.6 47.5ppdb 71.8 59.8 47.9bilayered 71.6 55.0 47.1
44 / 51

Results on the Test Set
Method avg P. avg R. avg F1
original 53.2 54.2 45.0mt 48.0 56.9 47.1naive 48.1 57.7 47.2ppdb 48.4 58.1 47.7bilayered 47.0 57.6 47.2
45 / 51

Results on the Test Set
Method avg P. avg R. avg F1
original 53.2 54.2 45.0mt 48.0 56.9 47.1naive 48.1 57.7 47.2ppdb 48.4 58.1 47.7bilayered 47.0 57.6 47.2
OthersBerant and Liang ’14 40.5 46.6 39.9Bordes et al. ’14 - - 39.2Dong et al. ’15 - - 40.8Yao ’15 52.6 54.5 44.3Bao et al. ’15 44.7 52.5 45.3Bast and Haussmann ’15 49.8 60.4 49.4Berant and Liang ’15 50.4 55.7 49.7Yih et al. ’15 52.8 60.7 52.5
46 / 51

Results on the Test Set
Method avg P. avg R. avg F1
original 53.2 54.2 45.0mt 48.0 56.9 47.1naive 48.1 57.7 47.2ppdb 48.4 58.1 47.7bilayered 47.0 57.6 47.2
OthersBerant and Liang ’14 40.5 46.6 39.9Bordes et al. ’14 - - 39.2Dong et al. ’15 - - 40.8Yao ’15 52.6 54.5 44.3Bao et al. ’15 44.7 52.5 45.3Bast and Haussmann ’15 49.8 60.4 49.4Berant and Liang ’15 50.4 55.7 49.7Yih et al. ’15 52.8 60.7 52.5
47 / 51

Results on the Test Set
Method avg P. avg R. avg F1
original 53.2 54.2 45.0mt 48.0 56.9 47.1naive 48.1 57.7 47.2ppdb 48.4 58.1 47.7bilayered 47.0 57.6 47.2
OthersBerant and Liang ’14 40.5 46.6 39.9Bordes et al. ’14 - - 39.2Dong et al. ’15 - - 40.8Yao ’15 52.6 54.5 44.3Bao et al. ’15 44.7 52.5 45.3Bast and Haussmann ’15 49.8 60.4 49.4Berant and Liang ’15 50.4 55.7 49.7Yih et al. ’15 52.8 60.7 52.5
48 / 51

Results on the Test Set
Method avg P. avg R. avg F1
original 53.2 54.2 45.0mt 48.0 56.9 47.1naive 48.1 57.7 47.2ppdb 48.4 58.1 47.7bilayered 47.0 57.6 47.2
OthersBerant and Liang ’14 40.5 46.6 39.9Bordes et al. ’14 - - 39.2Dong et al. ’15 - - 40.8Yao ’15 52.6 54.5 44.3Bao et al. ’15 44.7 52.5 45.3Bast and Haussmann ’15 49.8 60.4 49.4Berant and Liang ’15 50.4 55.7 49.7Yih et al. ’15 52.8 60.7 52.5
49 / 51

Error Mining
78.4% of the errors are partially correct answers occurring due toincomplete gold answer annotations or partially correct groundings
13.5% are due to bad paraphrases, and
the rest 8.1% are due to wrong entity annotations
50 / 51

Conclusion
Our method is rather generic and can be applied to any questionanswering system
Bi-layered L-PCFG for semantic similarity tasks
51 / 51
Top Related