







Languages
Pages
Legal


GGoooogglleePageRank and ArchitecturePageRank and Architecture
GGoooogglleePageRank and ArchitecturePageRank and Architecture
Presentation by Georgi Chulkov,Networks and Distributed Systems Seminar,Spring 2007,Jacobs University Bremen

GGoooogglleePageRank and ArchitecturePageRank and ArchitectureThe Google Challenge
● How to build a large-scale search engine that gives important results?
● Easy in principle, made difficult by scale– 100 q/s in 1999, 1300 q/s in 2005
– 250 GB in 1999, 16000 TB (rumored) in 2005
– 150 million web pages in 1999, 11.5 billion in 2005
– 11 links l/p in 1999, 110 l/p in 2005

GGoooogglleePageRank and ArchitecturePageRank and ArchitecturePageRank
● An importance rating of a page– Importance =
number of backlinks
● Random surfer model

GGoooogglleePageRank and ArchitecturePageRank and ArchitectureThe PageRank Formula
● Rank = probability of ending up on that page
● Simplified
– PR(A) = PR(T1) / C(T1) + ... + PR(Tn) / C(Tn)
– Problem: rank sinks
● Full
– PR(A) = (1 – d) / N + d * (PR(T1) / C(T1) + ... + PR(Tn) / C(Tn))
– d is the probability of not getting bored (0.85)
● Linear system in theory, iteration in practice

GGoooogglleePageRank and ArchitecturePageRank and ArchitectureMore on PageRank
● Dangling links are ignored
● Convergence in log(n)– 50 iterations in 1999, 100 iterations today
● Initial vector can be played with
● Applications– Search
– Broken link detection
– Discovering the truth about porn

GGoooogglleePageRank and ArchitecturePageRank and ArchitectureOn to Google...
● Designed for accuracy– Uses PageRank, anchor text, proximity, font size...
● Huge and scalable– 1 googol = 10100
– Largest distributed cluster in the world
(100000 x = a lot of penguins!)

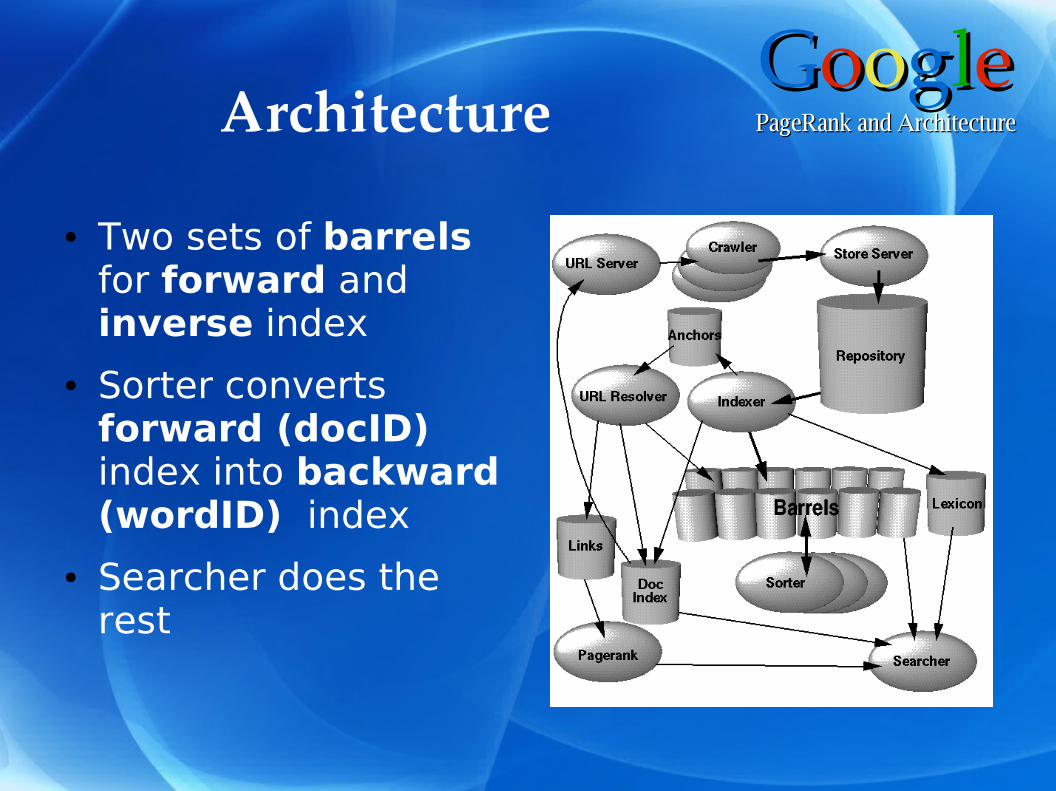
GGoooogglleePageRank and ArchitecturePageRank and ArchitectureArchitecture
● Distributed crawlers store the web
● Indexer parses HTML and creates hits, anchors, lexicon, document index
● Resolver creates link DB, stores anchor text, creates docIDs
GGoooogglleePageRank and ArchitecturePageRank and ArchitectureArchitecture
● Two sets of barrels for forward and inverse index
● Sorter converts forward (docID) index into backward (wordID) index
● Searcher does the rest

GGoooogglleePageRank and ArchitecturePageRank and ArchitectureImplementation
● Custom code from the ground up– Own file system, own data structures, etc.
– CPUs and disks get faster, but not seek times
● Magic everywhere– Position of word in a document, font size and type of
occurrence is encoded in 2 bytes
– Concurrent writing to a 14-million-word lexicon with no locking

GGoooogglleePageRank and ArchitecturePageRank and ArchitectureImplementation
● Crawling– Web crawlers crawl 100 p/s at 600 KB/s with 300
open connections and have own DNS cache... in 1999
● Parsing, indexing, sorting– Very little is mentioned, other than how difficult it is :(

GGoooogglleePageRank and ArchitecturePageRank and ArchitectureLet's search!
● Single word: get wordID, find docIDs for that word, sort them by score
● Multiple words: do the same, filter, and multiply final score by proximity score
● Score = PageRank + IR score calculated from anchor text, position, and font size

GGoooogglleePageRank and ArchitecturePageRank and ArchitectureThe End
● References– Papers
Lawrence Page, Sergey Brin, Rajeev Motwani, Terry Winograd, The PageRank Citation Ranking: Bringing Order to the Web, Stanford University, SIDL-WP-1999-0120, November 1999.
Brin, S. and Page, L. 1998. The anatomy of a large-scale hypertextual Web search engine. In Proceedings of the Seventh international Conference on World Wide Web 7 (Brisbane, Australia). P. H. Enslow and A. Ellis, Eds. Elsevier Science Publishers B. V., Amsterdam, The Netherlands, 107-117. DOI= http://dx.doi.org/10.1016/S0169-7552(98)00110-X
– Websiteshttp://www.1cog.com/search-engine-statistics.html
http://en.wikipedia.org/wiki/PageRank
http://www.google.com/
Top Related